Шахматные алгоритмы, которые думают почти так же, как человек, только лучше

Когда создавались первые вычислительные машины, их воспринимали только как дополнение к человеческому разуму. И до недавнего времени так и было. Программисты учили компьютеры играть в шахматы с 1960-х годов. И тогда победа у игрока-новичка уже считалась большим прогрессом. О серьёзных матчах даже не задумывались.
В 1980-х программа Belle достигла рейтинга Эло в 2250 пунктов, что примерно соответствует рейтингу мастера спорта. И с того времени развитие компьютерных шахмат вышло на совершенно новый уровень.
Сначала честь человечества не смог защитить Гарри Каспаров в 1996 году, а сегодня уже создана нейросеть с рейтингом около 5000 Эло, что в разы превосходит даже сильнейших игроков.
Сегодня разберёмся, как работают шахматные алгоритмы и почему нейросеть Alpha Zero думает практически так же, как человек, только лучше.
Как работает шахматный движок: от механического перебора вариантов до «умного» выбора
У шахмат довольно простые правила. Две противоборствующие стороны, шесть разновидностей фигур и одна цель — дать мат сопернику.
Но при этом вариативность шахмат просто огромна. Существует 400 уникальных комбинаций первого хода — 20 вариантов первого полухода белых и 20 вариантов ответа чёрных. С каждым последующим ходом количество уникальных позиций увеличивается на степень.
Общее количество уникальных партий в шахматы составляет примерно 10120, что на 1040 превышает количество атомов во Вселенной.
Шахматам не грозит быть посчитанными полностью. Поэтому в бой вступают алгоритмы оценки позиции и дерево возможных ходов.
В шахматной теории у каждой фигуры есть своя ценность, которая измеряется в пешках:
Конь — 3 пешки;
Слон — 3 пешки;
Ладья — 5 пешек;
Ферзь — 9 пешек;
Пешка — 1 пешка.
Король — бесценен, потому что его потеря означает проигрыш партии.
Анализ современных машин подтверждает истинность такой оценки. Так, в зависимости от позиции на доске компьютер оценивает ферзя в 9–12 пешек, ладью — в 5–6, коня и слона — в 3–5. Короля же машина оценивает в 300 пешек. Это задаёт максимальную границу оценки.
Анализ современных машин подтверждает истинность такой оценки. Так, в зависимости от позиции на доске компьютер оценивает ферзя в 9–12 пешек, ладью — в 5–6, коня и слона — в 3–5. Короля же машина оценивает в 300 пешек. Это задаёт максимальную границу оценки.
Чтобы было более понятно, преимущество в 0,5 пешки — это уже неплохо для шахматиста. В целую пешку — серьёзный перевес. В 3 пешки — подавляющее преимущество, которое можно практически без проблем довести до победы.
Но счётные возможности машины ограниченны. Иногда она показывает оценку в +51 или что-то вроде. Это означает, что алгоритм видит колоссальное преимущество белых в позиции и материале, но не может найти конкретный путь к мату.
Минимакс, или прямой перебор вариантов, в таком случае не работает. Даже КМС без проблем найдёт на доске мат в 3 хода в миттельшпиле, когда на доске ещё много фигур. А программе для этого нужно будет перебрать свыше 750 млн. полуходов.
Даже если программа перебирает 1 млн вариантов в секунду, чтобы найти мат в 3 хода, ей понадобится до 750 секунд, или 12,5 минут.
И это глубина в 3 хода. В стратегических позициях, где развитие игры идёт с учетом на пять или десять ходов вперёд, такие программы и вовсе будут бесполезными.
Поэтому для анализа позиции используется алгоритм под названием «альфа-бета-отсечение».

Система анализирует начальные варианты ходов и сразу отсекает те из них, которые ведут к мгновенному ухудшению оценки.
Программа отметает те варианты, в которых она сразу проигрывает материал или которые включают комбинации со стороны соперника, в ходе которых она выигрывает материал или партию.
Это позволяет сократить количество рабочих линий на порядки, сосредотачивая вычислительные ресурсы только на тех ветвях дерева, которые в перспективе ведут к улучшению позиции.
В варианте кода это может быть реализовано примерно следующим образом:
function alphabeta(node, depth, α, β, maximizingPlayer) is
if depth = 0 or node is a terminal node then
return the heuristic value of node
if maximizingPlayer then
value := −∞
for each child of node do
value := max(value, alphabeta(child, depth − 1, α, β, FALSE))
α := max(α, value)
if α ≥ β then
break (* β cutoff *)
return value
else
value := +∞
for each child of node do
value := min(value, alphabeta(child, depth − 1, α, β, TRUE))
β := min(β, value)
if β ≤ α then
break (* α cutoff *)
return valueЗа код особо не ругайте.
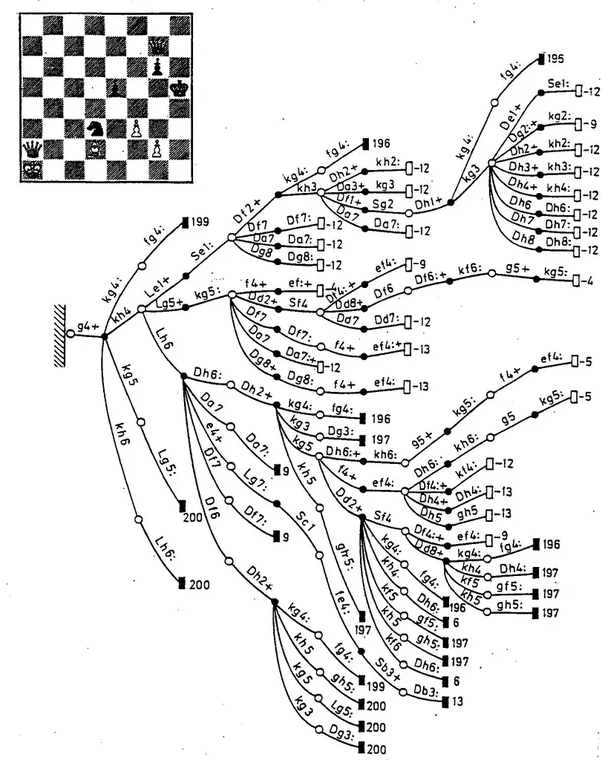
Рассмотрим на примере. Движок Stockfish считается сегодня одной из самых сильных компьютерных шахматных программ. Обратите внимание на первые пять линий.
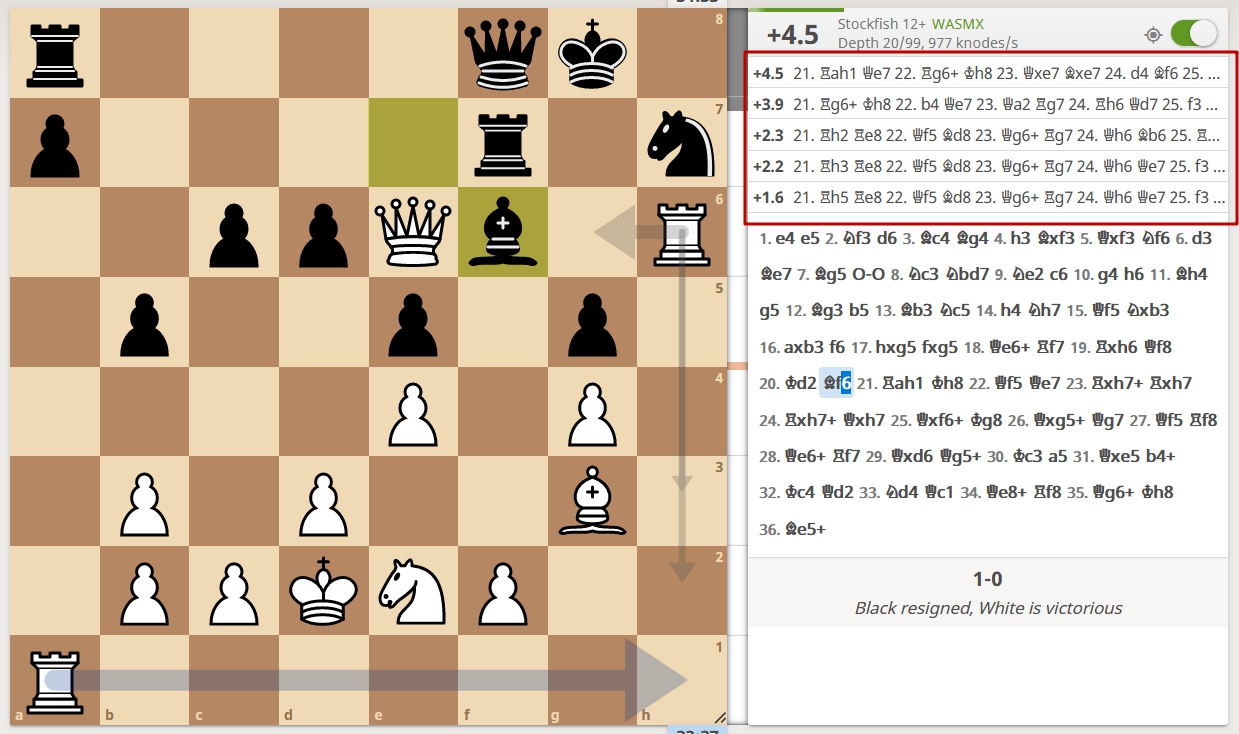
Из всего множества вариантов развития событий программа выбирает ряд линий, которые в перспективе ведут к улучшению позиции. Их она анализирует более глубоко — на 15–20 ходов вперёд, чтобы отсечь возможные проигрышные варианты. В результате она выбирает лучшую из возможных линий и делает ход.
После ответа соперника ситуация снова анализируется по тому же алгоритму. Сначала отсекаются заведомо проигрышные линии (таких порядка 95%), а затем путём более глубокого анализа перспективных вариантов выбирается лучший из них.
Новая эра в шахматных движках: нейросеть Alpha Zero
В 2017 году компания Deep Mind объявила о создании нейросети Alpha Zero. Тестировать её решили на трёх самых популярных стратегических настольных играх: шахматы, го и сёги.
Обучение и подготовка нейросети отличаются от классических компьютерных движков.
Stockfish и другие движки используют для своей работы существующие дебютные базы и анализ позиций огромного количества сыгранных партий.
Alpha Zero не использует ничего, кроме правил. Ей просто дали стартовую позицию, объяснили, как ходят фигуры, и цель игры — поставить мат сопернику. И всё.
За 24 часа игры с самой собой нейросеть смогла достичь сверхчеловеческого уровня игры и по сути изобрести заново всю шахматную теорию, которую человечество по крупицам разрабатывало веками.
В декабре 2018 года Alpha Zero во второй раз сразилась с самой последней версией движка Stockfish.
Исследователи провели 1000 партий с контролем 3 часа на партию плюс 15 секунд на ход. Alpha Zero одержала уверенную победу, выиграв в 155 партиях, сыграв вничью 839 партий и проиграв только 6.
Более того, Alpha Zero одерживала победу даже в партиях с форой по времени на обдумывание. Имея в 10 раз меньше времени, чем у противника, нейросеть всё равно победила в суммарном итоге. Только 30-кратная фора во времени смогла уравнять шансы и дать Stockfish примерно равную игру — 3 часа у движка и всего лишь 6 минут у нейросети.
Alpha Zero анализирует лишь 60 000 позиций в секунду, а тестируемая версия Stockfish — 60 млн. позиций. Для достижения аналогичных результатов анализа нейросети нужно в 1000 раз меньше ресурсов, чем движку.
Секрет успеха — в качественно другом уровне анализа. Нейросеть использует метод Монте-Карло, который высчитывает математическое ожидание комплекса ходов.
Если альфа-бета отсечение способно убрать большинство заведомо проигрышных вариантов, то проверять перспективные всё равно нужно механическим перебором, нейросеть сосредоточена на вариантах, которые ведут к улучшению позиции фигур, материальному перевесу, стеснению фигур соперника или созданию комплексных угроз, включающих матовые атаки.
И, что гораздо более важно, при оценке ситуации Alpha Zero учитывает стратегическую позицию.
Давайте рассмотрим на примере одной из партий.

После 20-го хода на доске творится невообразимая стратегическая борьба. Но если нейросеть шаг за шагом минимально укрепляет свою позицию, избавляясь даже от призрачных слабостей, то движок с 24-го по 29-й ход просто топчется на месте ладьёй.
Интересно, что Stockfish в упор не видит стратегических решений Alpha Zero, оценивая позицию как абсолютно ничейную. Но в результате минимальных укреплений позиции к 39-му ходу оказывается, что все фигуры белых активны, а чёрный конь и слон занимают пассивную оборонительную позицию. А после размена ферзей и ладей даже Stockfish оценивает преимущество нейросети в +2,2. Ещё несколько ходов — и король черных зажат в углу доски, а конь в одиночку не способен справиться с проходной пешкой. Поэтому программа сдалась.
Позиционная игра — это то, что отличает нейросеть от классического шахматного движка. Ведь она подразумевает длительные игровые планы, которые часто превышают вычислительные возможности машин.
Тем не менее нейросеть умеет играть позиционно не хуже человека и при этом идеально играет тактические позиции, где преимущество достигается в течение 5 или меньше ходов.
Более того, нейросеть уже помогла найти теоретикам шахмат целый ряд неочевидных, но при этом очень сильных разветвлений дебютов, которые никогда не рассматривали ранее.
Многие теоретики считают, что благодаря шахматным компьютерам повысился и средний рейтинг топовых шахматистов. Ведь современные тренировки включают глубокую проработку компьютерных вариантов и разбора партий движками. Средний рейтинг ведущих топ-100 шахматистов в 2000 году составлял 2644 пункта Эло, а в январе 2021 года — 2715. За 20 лет среднее значение увеличилось на 71 пункт.
Сегодня человек уже не способен соревноваться с компьютером в шахматах. Нейросеть вобрала в себя все преимущества человеческого шахматного мышления, но при этом лишена его недостатков.
Она умеет мыслить позиционно и при этом не допускает зевков и ошибок. И самое интересное в этом ситуации — шахматы для Alpha Zero являются только тестировочным полигоном, где система оттачивает навыки работы. Реальные же её цели Google не раскрывает. Поэтому здесь может быть всё что угодно: от анализа изменений климатической ситуации до создания системы идеально персонифицированной рекламы. А как вы считаете, для чего создают настолько мощную нейросеть?

Создать своего гениального цифрового шахматиста или получить Level Up по навыкам и зарплате можно пройдя онлайн-курсы SkillFactory со скидкой 40% и промокодом HABR, который даст еще +10% скидки на обучение. Узнайте подробности.
Другие профессии и курсыПРОФЕССИИ
КУРСЫ
