Рубрика «Читаем статьи за вас». Октябрь — Ноябрь 2017

Привет, Хабр! По традиции, представляем вашему вниманию дюжину рецензий на научные статьи от членов сообщества Open Data Science из канала #article_essense. Хотите получать их раньше всех — вступайте в сообщество ODS!
Статьи выбираются либо из личного интереса, либо из-за близости к проходящим сейчас соревнованиям. Напоминаем, что описания статей даются без изменений и именно в том виде, в котором авторы запостили их в канал #article_essence. Если вы хотите предложить свою статью или у вас есть какие-то пожелания — просто напишите в комментариях и мы постараемся всё учесть в дальнейшем.
Статьи на сегодня:
- Combining Infinity Number Of Neural Networks Into One
- AutoEncoder by Forest
- Application of a Hybrid Bi-LSTM-CRF model to the task of Russian Named Entity Recognition (NLP)
- Densely Connected Convolutional Networks (CV)
- Dual Path Networks (CV)
- A Large Self-Annotated Corpus for Sarcasm (NLP)
- Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms (CV)
- Dynamic Routing Between Capsules (Hinton’s capsules)
- DeepXplore: Automated Whitebox Testing of Deep Learning Systems
- One-Shot Learning for Semantic Segmentation (CV)
- Field-aware Factorization Machines in a Real-world Online Advertising System
- The Marginal Value of Adaptive Gradient Methods in Machine Learning
- FractalNet: Ultra-Deep Neural Networks without Residuals (CV)
- Сентябрь 2017
- Август 2017
1. Combining Infinity Number Of Neural Networks Into One
Авторы статьи: Bo Tian, 2016
→ Оригинал статьи
Автор обзора: BelerafonL
Идея в добавлении к весам нейронов гауссовского шума, чтобы получилось что-то типа дропаута. Только если дропаут действует обычно на выходы узлов, то здесь шум добавляется к весам. Но не это главное, а то, что автор находит аналитическое решение для выхода сети при бесконечном ансамбле таких сетей с разным сочетанием семплов шума в весах. Т.е. задается желаемый уровень шума весов (сигма), а найденное решение показывает, что выдала бы сеть если бы долго семплировать выход такой шумной сети и усреднять результат.
Автор для задачи разделения двух спиралей на плоскости показывает, как отличается решение обычной сети и его. Он рисует карту активации, и для обычной сети и она получается изрезанная и рваная, а для его решения гладкая и точно повторяет форму спиралей.
К сожалению, автор не проверяет предложенный способ на других задачах и использует сеть всего с одним скрытым слоем. Кроме того, он использует метод оптимизации LMA (Алгоритм Левенберга—Марквардта), но говорит, что можно использовать любой другой, в том числе обычный бекпроп.
Посыл статьи простой — бесконечный ансамбль сетей, отличающихся на величину шума в весах отлично обобщает и находит лучший минимум, кроме того, уровень шума весов можно изменять по мере обучения сети, и тогда можно найти желаемое соотношение точность/обобщение. И так как решение найдено аналитическое, то вычислительных затрат на это почти никаких.
В статье много формул, отчего я не понял применимость метода для практических сложных задач, есть ли там какие подводные камни. Поэтому прошу более опытных исследователей посмотреть и прокомментировать статью, уж больно красивый получается результат эдакой регуляризации.
Также есть заметка автора на stackexchange где он в двух словах объясняет концепцию.
2. AutoEncoder by Forest
Авторы статьи: Zhou Z, Feng J, 2017
→ Оригинал статьи
Автор обзора: Dumbris
В пейпере AutoEncoder by Forest, авторы Zhou Z, Feng J предложили альтернативный метод построения авто-энкодеров, основанный на ансамбле (Random Forest, Gradient boosted tree) деревьев. Предложенный метод они назвали eForest.
Согласно экспериментам авторов, eForest показывает лучшие результаты на задачах MNIST и CIFAR-10, в сравнении с авто-энкодерами, построенными на основе Multilayer Perceptron и Convolutional Neural Network. А в задаче восстановления текста на датасете IMDB — eForest в 200 раз превзошел по точности MLP.

Основные преимущества метода eForest:
- точность: reconstruction error меньше, чем у основанных на NN авто-энкодерах
- эффективность: обучение на multi-core CPU происходит быстрее, чем NN c использованием GPU (но, фаза декодирования в eForest пока работает медленно)
- damage-tolerable — модель работает при частичном стирании закодированного представления. В экспериментах с текстом даже на оставшихся 10%, модель смогла показать приемлемый результат.
- reusable обученные eForest авто-энкодеры, можно использовать на других данных, из той же доменной области.
Как работает предложенный метод
Автоэнкодер имеет две основные функции кодирование и декодирование.
Кодирование. Для получения закодированного представления, нужно построить лес F деревьев T и сохранить индексы листов из всех деревьев для каждого x. Таким образом для входных данных x получим вектор длинной T.

Декодирование — имея лес F и индексы листов для всех x можно восстановить путь в дереве от листа к вершине. Этот путь авторы записывают в виде конъюнкции логических выражений, взятых из узлов решающего дерева. Пример (x1=>0)^(x2=>5)^:(x3==RED)^:(x1>2:7)^:(x4 == NO). Такое выражение они называют RULE.
Множество RULEs для конкретного сэмпла из всех деревьев T можно упростить, до одного правила, которое Zhou Z, Feng J называют: Maximal-Compatible Rule (MCR). Авторы утверждают, в форме теоремы, что все оригинальные сэмплы буду находиться внутри регионов определенных MCR.
По правилам записанным в MCR, можно сгенерировать данные, которые будут похожи на исходные. В пейпере есть описание алгоритмов, в формате псевдокода.
Судя по Table 4, процедура построения MCR и декодирования занимает сильно больше времени, по сравнению с фазой декодирования в NN. Но авторы надеются этот момент оптимизировать в будущем.
В начале года, от этих же авторов был более общий paper: Deep Forest: Towards An Alternative to Deep Neural Networks.
3. Application of a Hybrid Bi-LSTM-CRF model to the task of Russian Named Entity Recognition
Авторы статьи: Anh L.T. Arkhipov M. Y, Burtsev M. S, 2017
→ Оригинал статьи
Автор обзора: Dumbris
Первая публикация в рамках проекта iPavlov. По утверждениям авторов — SOTA для NER на русских текстах.
Датасеты
Для экспериментов были использованы датасеты Gareev«s (топ цитируемых статей из Yandex News), Person-1000 и FactRuEval. В качестве бейзлайна, была взята Bi-LSTM сеть с Conditional Random Fields (CRF) слоем. Применение CRF дает существенный прирост точности по сравнению с чистым Bi-LSTM на задаче NER.
Архитектура сети, эксперименты
На входе для каждого слова вычисляется его word level и char level представление, оба представления конкатенируются в один вектор и подаются на вход Bi-LSTM. После Bi-LSTM, CRF слой присваивает каждому слову тэг, по которому можно определить является ли слово именем человека, или названием организации.
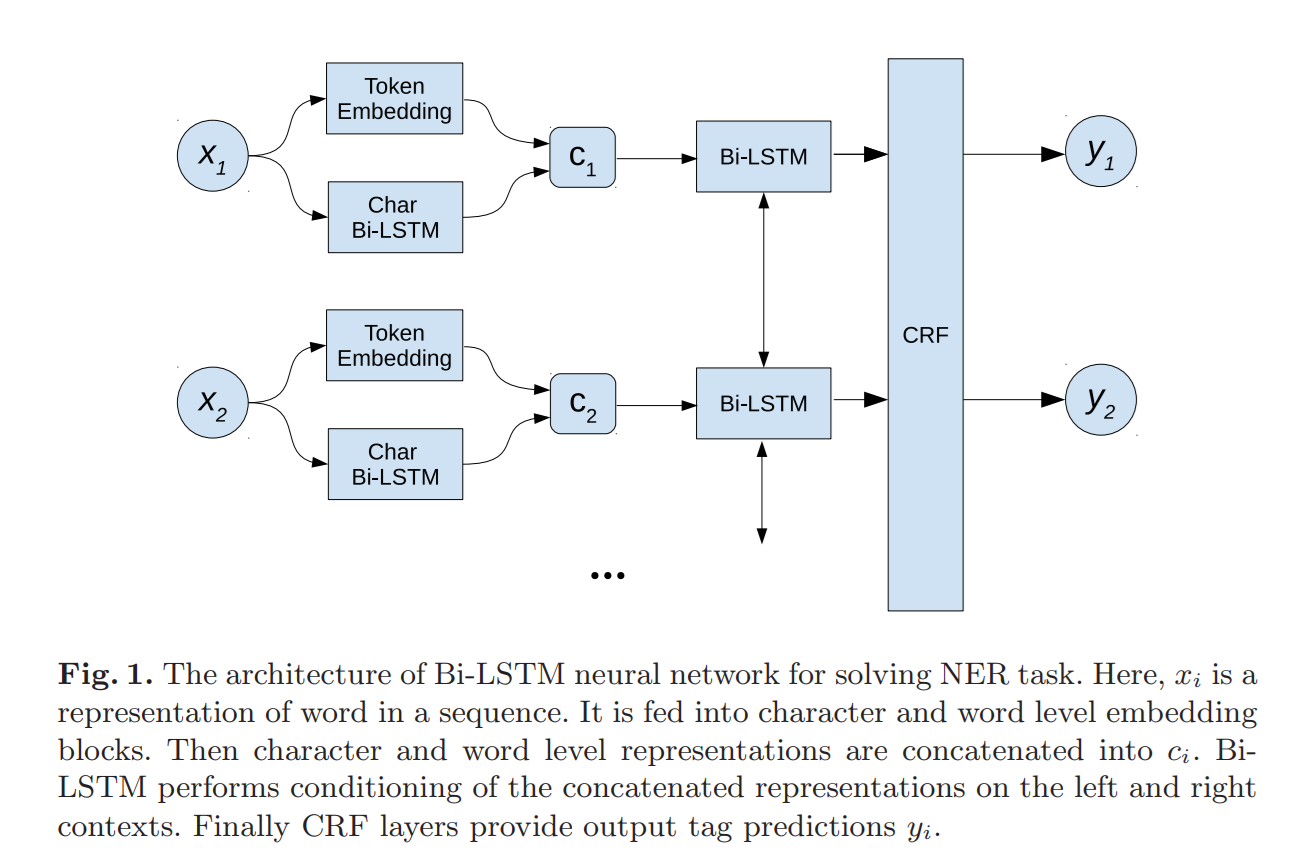
В ходе экспериментов, также были исследованы расширения известной архитектуры NeuroNER при помощи highway network. C highway network сеть получает возможность учиться «отключать» некоторые из внутренних слоев (carry gate), пропуская низкоуровневые представления входных данных ближе к выходным слоям. Реализуется этот механизм с помощью sigmoid layer. Получается, что сеть может сама управлять сложностью архитектуры в зависимости от входных данных.

Вместе с тем, на практике было выяснено, что использование правильно приготовленных word embeddings дает прирост точности в комбинации с Bi-LSTM-CRF. Для тренировки эмбедингов, были использованы корпуса News by Kutuzov и Lenta.
Результаты
Наиболее точной оказалась модель Bi-LSTM-CRF + word embedding, созданные на основе корпусов русских новостей. Комбинация NeuroNER + highway network тоже показала себя хорошо. Одно из перспективных направлений использование character level CNN архитектуры, вместо LSTM. В рамках данной работы оно не было исследовано.
4. Densely Connected Convolutional Networks
Авторы статьи: Gao Huang, Zhuang Liu, Kilian Q. Weinberger, Laurens van der Maaten, 2016
→ Оригинал статьи
Автор обзора: N01Z3
Относительно свежая идея архитектуры, которая прошла как-то незаметно, но показала в нашем чатике лучшую single model performance на Kaggle Amazon from Space.

Итак, парни предложили Dense Block. Каждый базовый элемент это BN → ReLU → Conv. И каждый базовый элемент прокидывает свои фичи к всем следующем элементам в блоке. Фичи конкатенируются, а не суммируются, поэтому линейно числу фильтров (авторы называют это Growth rate) растет количество каналов. Но это компенсируется тем, что сами базовые элементы более узкие. Также чтобы уменьшить рост числа каналов после каждого Dense Block«a втыкают базовый элемент с свертками (1, 1) и количеством фильтров в два раза меньше, чем каналов к этому моменту в основном бранче. А затем, обычный Pooling с Stride«ом 2.
Все. А дальше идет размахивание руками, что фичи более грамотно переиспользуются, что за счет этого эффективно все считается. Еще в этом случае дропаут в свертках выглядит как-то более осмысленным. Также в следующих работах парни показали, что можно получать оценочную классификацию уже после первых блоков и тем самым не гнать инференс дальше в случае уверенных предсказаний.
5. Dual Path Networks
Авторы статьи: Yunpeng Chen, Jianan Li, Huaxin Xiao, Xiaojie Jin, Shuicheng Yan, Jiashi Feng, 2017
→ Оригинал статьи, → Исходный код
Автор обзора: N01Z3
Очередное переосмысления связи между сверточными и рекурентными сетями. Для начала авторам понравился Resnet и Densnet. Первый это суть рекурентная сеть развернутая вдоль основного бранча, а вторая это рекурентная сесть высокого порядка (HORNN) (серия картинок 1). И парни решили, что надо слить обе идеи в одну. Так родилась DPN.
Чтобы понять как они объединили, серия картинок 2

a) классический Resnet — основная бранч фиксированного размера, фичи складываются
b) обычный Densenet — основной бранч растет, фичи конкатинируются
c) обычный Densenet — эквивалентная схема. Переосмысление в том плане, что все-таки есть основной бранч фиксированного размера от входа в DenseBlock и вспомогательный, которые растет.
d) моднейший Dual Path блок — есть бранч фиксированного размера, есть бранч который растет. Фичи берутся из каждого, прогоняются через слой сверток, разделяются и докидываются в каждый бранч. В фикcированный бранч — складываются, в растущий — конкатенируются
e) моднейший Dual Path блок — эквивалентная схема Dual Path.
В каждом блоке на входе и выходе используются свертки (1,1), чтобы каналы сошлись. А основные свертки (3,3) используются не обычные, а Separable. То есть по сути за базу взят не Resnet, а ResNeXt.
6. A Large Self-Annotated Corpus for Sarcasm
Авторы статьи: Mikhail Khodak, Nikunj Saunshi, Kiran Vodrahalli, 2017
→ Оригинал статьи
Автор обзора: yorko
Распознавание сарказма — очень нетривиальная задача, с которой не то что сетки, а люди далеко не всегда справляются. Если уж человек с его 10^10 нейронов порой спрашивает «Погодь…, а ты меня случаем не троллишь?», то можно представить, что распознавание сарказма — это действительно один из большущих челленджей машинного обучения.
Чуваки разметили самый большой на текущий момент датасет по сарказму — 1.3 млн. саркастических утверждений с Reddit. К тому же, рядом валяются еще полмиллиарда несаркастических фраз, так, чтобы на досуге попрактиковаться в imbalanced classification.
Ребята сразу заявили, что их основной вклад — это датасет, а не методология выявления сарказма. Зато датасет на порядок больше прежних и намного качественней, по их словам, чем с Твиттера, где люди сами ставят теги #sarcasm или #irony. На Реддите юзеры тоже отмечают, что троллят тегом »/s», и авторы признают, что такая разметка тоже шумная.
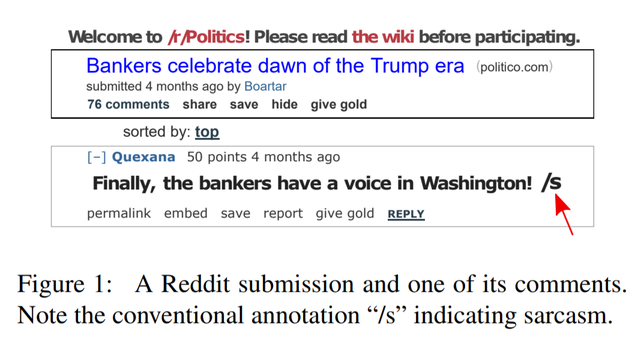
Любопытно, что чуваки не собирали сообщения, идущие в треде после саркастического утверждения. Типа там дальше идет треш-угар-троллинг, сарказмом отвечают на сарказм, и разметка слишком шумной получается.
Авторы оценили качество полученной разметки, выбрав по 500 случайных саркастических и обычных сообщений и проверив разметку самостоятельно. Зарепортили 1% False Positive Rate (когда обычное сообщение пришло с меткой «сарказм») и 2% False Negative. В случае сбалансированного обучения это норм, а вот если обучаться с кучей не-сарказма (99.75%), то вот 2% False Negative Rate — многовато.
От себя добавлю: прикинул матрицу ошибок для разметки с Reddit и ассесорской разметки, при таком дисбалансе точность (precision) разметки с Reddit получается очень низкой: всего лишь в 11% случаев ассесоры подтверждают сарказм, если с Reddit пришел сарказм. Это вызывает вопросы: чем датасет так уж лучше остальных, того же Твиттера? Авторы утверждают, что все-таки лучше: на реддите намного чаще попадается сарказм (~ 1% против 0.002% в Твиттере) и вообще сообщения на Реддите, очевидно, длиннее. Ну ок… уговорили
Далее, авторы репортят несколько бейзлайнов в задаче определения сарказма на данных Реддита. Задача формулируется так: имеется сообщение на реддите и все комментарии к нему. Надо определить, какие из комментариев несут в себе сарказм. Насобирали 8.4 млн таких сообщений (как я понял объект — это исходное сообщение + коммент к нему), сарказма — 28% (сбалансировали выборку). Далее взяли по одному сообщению из треда с сарказмом и без, причем на основе GloVe-эмбеддингов отсекали слишком похожие друг на друга саркастические фразы (лавинноподобное дрожжевое метание говн).
Строили 3 логистических регрессии, признаки очень простые: Bag of Words, Bag of bigrams и GloVe-эмбеддинги (Amazon product corpus, размерность — 1600, представление документа (сообщения) — простое усреднение представлений отдельных слов). Также посадили бедных ассесоров размечать сарказм — набралось 5 человек, разметили по 100 сообщений, скудновато будет, можно было бы и механического турка напрячь (Amazon Mechanical Turk), ведь написание научной статьи — это такое доходное дело!

Получилось, что биграммы дали лучший результат среди трех моделей (~76% accuracy в политике и 71% — в остальных сабреддитах), но человеческая разметка, конечно, лучше (83% и 82% — в среднем, 85% и 92% — ансамбль 5 ассесоров, голосование большинством). Авторы заключают, что эмбеддинги сыграли хуже, но возможно, именно с их помощью мы научимся передавать контекст, в котором применяется сарказм.
В целом, и людям, и алгоритмам сложно обнаруживать сарказм. Ожидаю прогресса в этой задаче со стороны нейросетей — надо как-то научиться правильно учитывать контекст, в котором употребляется сарказм, то есть правильно этот контекст закодировать в скрытое представление, как оно сейчас делается в conditioned рекуррентных сетках. Эксперименты в описанной статье так себе, но то что ребята выложили большой датасет по сарказму — это, безусловно, здорово! Боюсь представить, что будет, когда машины реально научатся чувствовать сарказм лучше людей.
7. Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Авторы статьи: Han Xiao, Kashif Rasul, Roland Vollgraf, 2017
→ Оригинал статьи
Автор обзора: Ivan Bendyna
У ребят из Zalando тоже пригорает от фразы «state-of-the-art на MNIST», поэтому они сделали свой Fashion-mnist, который полностью повторяет структуру оригинального MNIST. В нем тоже 10 классов (одежда и обувь: shirt, t-shirt, sneakers, …), 28×28 пикселей, 60000 train, 10000 test. В этом и есть основная идея датасета — можно просто подменить урл и проверить качество на чуть более сложном датасете. SOTA top-1 error около 3.5%, что на порядок больше ошибки на MNIST.

Есть бенчмарк основных классификаторов из sklearn, топовые результаты можно найти в Readme.md. Также там можно найти результат человека, который составляет всего 0.835, что впринципе неудивительно, если взглянуть на картинки глазами.
Датасет подготовлен по товарам с сайта zalando, процедура создания датасета хорошо описана в работе. Датасет уже есть в pytorch.
Еще узнал из статьи, что есть расширенный датасет EMNIST (62 класса рукописных символов)
Мои мысли:
- Картинки сделаны из фотографий одежды, то есть ближе по 2d-структуре к обычным фотографиям, чем рукописный текст
- Основной недостаток MNIST никуда не делся — хорошие методы могут не показать улучшения на таких маленьких картинках
- Возможно, на этом датасете не получится достигнуть accuracy 0.99, так как граница между некоторыми классами (например, shirt и t-shirt) довольно условна, а если она и есть, то может исчезнуть при уменьшении размера и перевод в ч/б изображение
- Не факт что может быть заменой, но теперь все те кто оценивал качество на MNIST могут бесплатно (с точки зрения времени разработчика) проверять и на fashion-mnist
- Также хорошая альтернатива для домашних заданий для студентов, у которых обычно нет мощностей, чтоб запускать на ImageNet
8. Dynamic Routing Between Capsules
Авторы статьи: Sara Sabour, Nicholas Frosst, Geoffrey E Hinton, 2017
→ Оригинал статьи
Автор обзора: Ruslan Grimov
В данной статье раскрывается внутреннее устройство капсул и описывается механизм роутинга — способ передавать выход от капсулы в текущем слое только на определённые капсулы в вышележащем слое. Это они называют построением Parse tree, где каждой node сопоставлена одна капсула.
Результат статьи: построение енкодера/декодера, обученного на MNIST и призыв изучать капсулы дальше. Енкодер — сеть CapsNet, состоит из обычного конволюционного слоя и двух слоёв с капсулами, один из которых конволюционный (см. далее). Декодер — просто fullconnected сеть. Код подаваемый в декодер — 10 капсул с 16 нейронами каждая. По одной на цифру.
Капсула — обособленная группа нейронов на слое. Между собой внутри капсулы они не связаны, но выход каждого нейрона зависит от выхода других в капсуле (см. формулы далее). Отдельная капсула отвечает за один объект. Каждый нейрон в капсуле учится представлять какое-то свойство объекта. В конце статьи будет картинка где они показывают как меняется форма цифр при изменении свойств (похоже на то, что действительно эти нейроны что-то знают).
Нейроны в одинаковой позиции, но в разных капсулах одного слоя отвечают за разные свойства объектов (на сколько я понял). Само наличие объекта на сцене определяется длинной выходного вектора капсулы (корень от суммы квадратов активностей нейронов в капсуле). Соответственно. если на сцене два одинаковых объекта — то свойства будут смешаны.
Размерность капсул растёт от входного слоя сети к выходному. При этом информация из «позиционной» превращается в rate-coded (As we ascend the hierarchy more and more of the positional information is «rate-coded»). Простые свёрточные слои в начале сети рассматриваются как капсулы имеющие один нейрон.
Капсулы
В статье всё отталкивается от капсул. Потому дальше все действия описываются в отношении капсул, а не отдельных нейронов. То, есть рассматривается не input/output нейрона и weights между нейронами, а input/output и weights между капсулами. Просто имеем ввиду, что капсула — это вектор из нейронов.
j — индекс капсулы в текущем слое, i — в нижележащем (тот что ближе к входу).
Вход капсулы (вектор размерности m) s[j] = сумма по всем i от c[i, j]U[i, j], где
c[i, j] — некий коэффициент связанности (скаляр) между капсулами двух слоёв — результат работы роутинга (см. далее). Для капсулы из i сумма по всем j от c[i, j] = 1. То есть одна капсула из нижележащего слоя распределяет своё «влияние» на вышележащие неравномерно. Перед циклами роутинга все c[i, j] равны.
U[i, j] — в статье называется prediction (вектор размерности m) U[i, j] = W[i, j]u[i], где W[i, j] веса связей между нейронами капсул i и j (размерность n x m), u[i] — output капсулы i (вектор размерностью n). U[i, j] также потом понадобится для роутинга.
Далее к s[j] применяется нелинейная функция активации, которая приводит вектор s[j] к вектору v[j] такой же размерности, но длинной меньше 1 (это тот момент где нейроны одной капсулы влияют друг на друга, в остальном специальными связями между собой внутри капсулы они не связаны). Элементы этого вектора после последнего цикла роутига и есть выходы нейронов капсулы j.
Роутинг
Длина выходного вектора капсулы меньше 1. А раз длина выходного вектора капсул нормализована, то можно выяснить какие из капсул вышележащего слоя более «отзывчивы» и передавать данные от нижележащей капсулы только на те капсулы, для которых скалярное произведение U[i, j] и v[j] больше. Собственно это и есть построение parsing tree (как я понял).
Parsing tree между слоем l и (l + 1) строится на лету (заново при подаче каждого изображения).
Для построения этого дерева служат специальные веса b[i, j] (скаляр) между капсулами двух слоёв (используются при вычислении того самого c[i, j] — коэффициента связанности, но постоянно не хранятся, при подаче нового входа на сеть обнуляются).
c[i, j] рассчитываются как exp (b[i, j])/(сумма по k от exp (b[i, k])), где k — кол-во групп в вышележащем слое. Т.е. это softmax.
1: procedure ROUTING(U[i,j], r, l) //prediction (зачем оно здесь?), кол-во итераций, номер слоя
2: for all capsule i in layer l and capsule j in layer (l + 1): b[i,j] = 0
3: for r iterations do
4: for all capsule i in layer l and capsule j in layer (l + 1): считаем c[i, j]
5: for all capsule j in layer (l + 1): считаем s[j]
6: for all capsule j in layer (l + 1): считаем v[j]
7: for all capsule i in layer l and capsule j in layer (l + 1): b[i,j] = b[i,j] + U[i, j]*v[j]
8: return v[j]После последней итерации значение v[j] — и есть выход нейронов капсулы j.
Функция ошибки
Максимизируем длину выходного вектора у той капсулы, которая должна активироваться на текущую картинку и минимизируем у тех, которые не должны. А именно высчитываем сумму по всем k от 0 до 9
L[k] = Tmax (0, 0.9 — ||v[k]||)^2 + 0.5(1 — T)*max (0, ||v[k]|| — 0.1) ^ 2
где T = 1 при наличии цифры k на картинке и равно 0 при отсутствии.
В качестве дополнения приплюсовываем попиксельную ошибку восстановления картинки декодером (см далее), но приплюсовывали с очень небольшим коэффициентом 0.0005.
Архитектура CapsNet

Энкодер состоит из:
- Обычного свёрточного слоя с 256 ядрами 9×9, шагом 1 и ReLU в качестве ф-ии активации.
- Слоя «primary capsule», слой с капсулами, свёрточный. 32 ядра 9×9 из капсул 8D (8 нейронов в капсуле) и шагом 2. Каждая такая капсула видит 81×256 нейронов из предыдущего слоя. Всего второй слой имеет [32, 6, 6] выходов капсул, каждый из которых состоит из 8 нейронов. Каждая капсула в решётке [6, 6] делит свои веса с другими (не совсем понятно как тут c[i, j] рассчитываются, чему равно k? 32 или 32×6x6?).
- Слой «DigitCaps» состоит из 10 капсул 16D, каждая капсула соединена со всеми капсулами предыдущего слоя.
Роутинг используется только между вторым и третьим слоем. Все b при инициализации равны 0.
Декодер состоит из трёх fullyconnected слоёв с 512, 1024 и 784 нейронами и ReLU в качестве активации. То есть декодер берёт данные из тех 10×16 нейронов последнего слоя энкодера и выдаёт картинку 28×28.
Результаты
Для определения какая цифра активна они выбирали вектор самой большой длины из последнего слоя. Без ансамблей сетей и аугментации данных (кроме смещения на 2 px) достигли 0.25% ошибку на сети с 3 слоями.
Тренировали свою сеть только на чистом MNIST пока та не достигла ошибки 99.23%. Потом применили её на affNIST, результат 79% accuracy. Проделали то же самое с традиционной CNN — она достигла 66%.
Показали что выучили нейроны в капсуле
Для этого меняли значения отдельных нейронов активной капсулы последнего слоя (все остальные капсулы занулены были, насколько я понял) в диапазоне −0.25, 0.25 и восстанавливали картину через декодер. Тут надо смотреть картинку. Нейроны в капсуле явно выделили вполне интерпретируемые свойства (наклон, размер, интенсивность штриха, всякие отдельные элементы специфичные для конкретного класса, например, закругление верхней части у шестёрки).

Сегментация. Две разные перекрывающиеся цифры из MNIST
Выбирали два самых длинных вектора. Тут тоже надо смотреть картинки. У них получилось разделить где какая цифра и обвести каждую контуром отдельно через декодер (обнуляя все остальные кроме каждой из двух по очереди). При этом цифры были нарисованы довольно плотно друг к другу.
P.S. по новой архитектуре: по сути это обычная архитектура со слоями где каждый нейрон связан со всеми нейронами предыдущего слоя. С четырьмя отличиями:
- На слое нейроны поделены на группы — капсулы
- Активация нейрона зависит от активации других нейронов в его группе
- Все веса между двумя группами двух слоёв умножаются на некоторый коэффициент c[i, j], считающейся на лету при каждой подаче входа на сеть.
- В качестве выхода сети используется не выход отдельного нейрона, а корень от суммы квадратов выходов нейронов одной группы
9. DeepXplore: Automated Whitebox Testing of Deep Learning Systems
Авторы статьи: Kexin Pei, Yinzhi Cao, Junfeng Yang, Suman Jana, 2017
→ Оригинал статьи
Автор обзора: Arseny_Info
Статья о том, как сгенерировать тест-кейсы для DL задачи, обладая хотя бы двумя обученными нейросетями и датасетом.
Т.к. тестировать сети нужно, а классическое software testing с его классическими же метриками типа code coverage выглядит малоприменимым, авторы ввели свою метрику — доля нейронов, активированных набором тест-кейсов, и придумали решение для генерации этих тестов.

Основная идея:
- берем входные данные;
- при помощи gradient ascent модифицируем их, решая задачу оптимизации с хитрым лоссом: максимизируем
(1) долю активированных нейронов,
(2) разницу предсказанной вероятности принадлежности к классу тестируемой сетью и другой (другими) сетями - при необходимости накладываем domain constraints (например, для картинок резонно ожидать, что пиксель будет лежать в интервале [0,255])
- полученный модицированный инпут в будущем используется как тест-кейс;

Задача полностью дифференцируема, тест-кейсы генерируются за разумное время на консьюмерском железе. Есть имплементация на TF + Keras.
Полученные тест-кейсы могут использоваться:
- собственно для регулярного тестирования сети к корнер кейсам;
- для обнаружения слабых мест и изменения алгоритмов аугментации;
- для обнаружения «испорченных» данных в изначальном датасете.
Алгоритм тестировался аж на пяти датасетах: три картиночных (MNIST, Imagenet, Driving) и два некартиночных (Contagio/Virustotal, Drebin). Их оригинальная метрика про активированные нейроны выглядит отлично (кто бы сомневался!), но и по остальным показателям (скорость генерации, точность сети, дообученной на проблемных семплах) вроде ок.
10. One-Shot Learning for Semantic Segmentation
Авторы статьи: Amirreza Shaban, Shray Bansal, Zhen Liu, Irfan Essa, Byron Boots, 2017
→ Оригинал статьи
Автор обзора: Vadzim Piatrou
В работе предлагается подход, который позволяет сегментировать объекты новых классов по одному или более образцу.
Предложенная нейронная сеть работает следующим образом. На нижнюю сегментирующую ветку подается изображение с новым классом объектов, которое требуется сегментировать. На выходе получается 4096 выходных каналов. На верхнюю управляющую ветвь подается изображение-образец с маской класса. Данная ветвь задает 4096 весов и 1 смещение для классификатора пикселей 4096 каналов выходного снимка, полученного в ветви сегментации. Классификатор пикселей выдает финальную маску нового класса объекта на входном изображении.
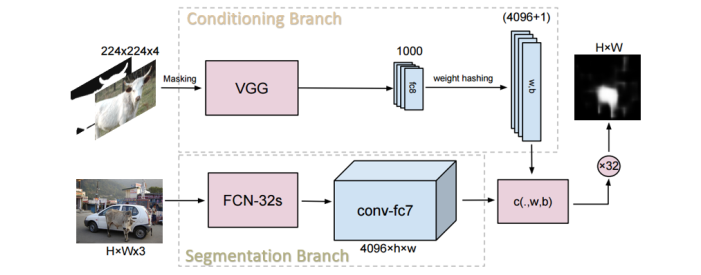
Обучение сети выполнялось на базе PASCAL VOC 2012 путем симуляции сегментации одного класса по одному примеру. На каждой итерации случайно выбиралась пара снимок-маска и формировалась маска для одного класса путем случайного выбора класса из присутствующих на снимке. В качестве образца в управляющую ветвь подавался другой случайный снимок-маска для того же класса объектов.
Точность работы (mIoU) сети на новых классах составляет около 40%, что выше предыдущих результатов для обучения по одному примеру (31–33%). Однако финальный результат ниже в 2 раза точности сегментации для полного обучения (PSPNet, 83%).
11. Field-aware Factorization Machines in a Real-world Online Advertising System
Авторы статьи: Yuchin Juan, Damien Lefortier, Olivier Chapelle, 2017
→ Оригинал статьи
Автор обзора: Fedor Shabashev
Factorization machines частенько используется в продакшене для предсказания CTR, но поведение юзеров в интернете подвержено изменениям, поэтому модель нужно периодически обучать на новых данных.
Но когда данных много, то каждый раз переобучать модель заново становится вычислительно затратно.
Поэтому, вместо того чтобы обучать модель с нуля, ее инициализируют предыдущей обученной моделью.
Как утверждают авторы, такой подход хорошо работает для логистической регрессии, но плохо для factorization machines. Они пишут что если взять обученную factorization machine и пытаться ее дообучать, то она сразу начинает переобучаться и точность ее от дообучения будет только падать (на картинке график naive).
Замечу что все эксперименты они делают на кликовых датасетах где нужно предсказывать CTR.
Однако дообучать factorization machines все-таки можно и для этого нужно брать за основу не полностью обученную модель, а недообученную. То есть такую, у которой обучение было остановлено до схождения в локальный минимум.
Если делать так, то, как как утверждается, модель при дообучении не начнет сразу переобучаться и ее точность за счет новых данных повысится (на картинке график pre-mature).
Подобный подход позволяет значительно экономить время на регулярное обучение моделей.
12. The Marginal Value of Adaptive Gradient Methods in Machine Learning
Авторы статьи: Ashia C. Wilson, Rebecca Roelofs, Mitchell Stern, Nathan Srebro, Benjamin Recht, 2017
→ Оригинал статьи
Автор обзора: BelerafonL
В статье сравнивают работу разных оптимизаторов: SGD, SGD+momentum, RMSProp, AdaGrad, Adam. Общий посыл статьи такой — адаптивные методы (RMSProp, Adam, AdaGrad) работают у авторов хуже, чем обычный SGD и он же с моментумом. Они проверяют на разных доступных в интернете сетках и задачах диплернинга, таких как распознавание картинок, рекуррентных языковых моделях и т.п. И везде у них SGD типа лучше всех ведет себя и на тесте, и на трейне — и дает лучшую точность, и даже быстрее сходится.
Адаптивные методы могут быть сравнимы с SGD на трейне, но точно проигрывают на тесте. Причем адам ведет себя хуже всех. Объясняют они это тем, что адаптивные методы сильнее оверфитятся и хуже обобщают. Даже что-то там доказывают про это в начале статьи на задаче линейной регрессии. Однако при сравнении они делают для каждого метода очень точный подбор лернингрейта и кривой для снижения лернингрейта. И говорят, что именно правильный подбор этого делает SGD таким успешным. А адаптивные методы, как я понял, работают и с более грубым подходом к заданию learning rate и его decay, сходятся быстро и почти хорошо, но все равно всегда хуже, чем правильно настроенный SGD. Статья, конечно, холиварная и доверять ей сходу стрёмно, но в каждой сказке, как говорится, есть намёк…
13. FractalNet: Ultra-Deep Neural Networks without Residuals
Авторы статьи: Gustav Larsson, Michael Maire, Gregory Shakhnarovich, 2016
→ Оригинал статьи
Автор обзора: BelerafonL
Баян, но всё же. Взахлеб прочитал статью FractalNet: Ultra-Deep Neural Networks without Residuals. На первый взгляд строят ещё одну упоротую архитектуру для обучения имейджнету, в один ряд с ремейками ResNet и DenseNet. Однако внутри оказалось всё интереснее, и меня это впечатлило сильно гораздее, чем, скажем, нашумевшие капсулы. Главная идея сети показана на картинке.
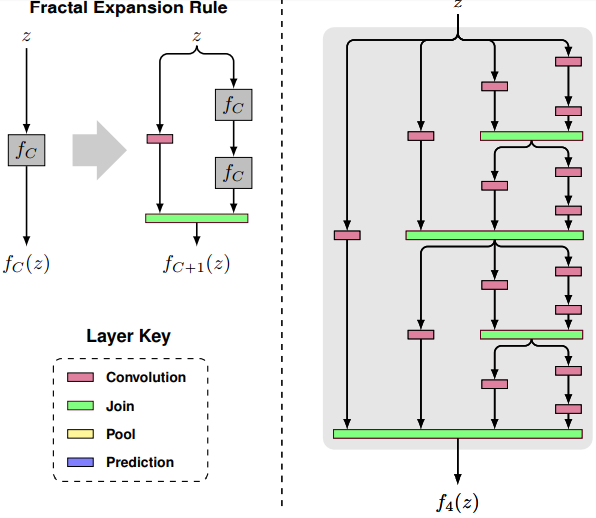
Они говорят — давайте сделаем структуру сети фрактальной. А именно: сначала поставим простую сверточную сеть от входа на выход. Параллельно ей поставим еще две такие же, соединенные последовательно. Параллельно каждой из тех поставим еще две такие же, соединенные последовательно, и так далее. Получается сеть, которая растет одновременно и в длину, и в толщину. Зачем это надо и чем лучше ResNet?
Для начала надо пояснить, как работает у них механизм объединения Join (зелененький на рисунке). Они говорят, что можно придумать много вариантов, суммирование, конкатенацию, макспуллинг или че-нить еще. Но они берут среднее арифметическое. И этот выбор завязан на то, как они делают регуляризацию своей сети при обучении. Аналогично с дропаутом или дропконнектом, они дропают ветки своей фрактальной сети. Например, одну из двух параллельных, и так для каждого уровня вложенности, как показано на рисунке

Выключенная ветка просто не участвует в расчете среднего арифметического, в результате чего параллельные ветки учатся делать одно и то же. Т.е. более простая
