Рубрика «Читаем статьи за вас». Март 2020. Часть 2

Привет, Хабр! Продолжаем публиковать рецензии на научные статьи от членов сообщества Open Data Science из канала #article_essense. Хотите получать их раньше всех — вступайте в сообщество! Первая часть мартовской сборки обзоров опубликована ранее.
Статьи на сегодня:
- NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis (UC Berkeley, Google Research, UC San Diego, 2020)
- Scene Text Recognition via Transformer (China, 2020)
- PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization (Imperial College London, Google Research, 2019)
- Lagrangian Neural Networks (Princeton, Oregon, Google, Flatiron, 2020)
- Deformable Style Transfer (Chicago, USA, 2020)
- Rethinking Few-Shot Image Classification: a Good Embedding Is All You Need? (MIT, Google, 2020)
- Attentive CutMix: An Enhanced Data Augmentation Approach for Deep Learning Based Image Classification (Carnegie Mellon University, USA, 2020)
1. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
Авторы статьи: Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, Ren Ng (UC Berkeley, Google Research, UC San Diego, 2020)
Оригинал статьи :: GitHub project: Video: Blog
Автор обзора: Александр Бельских (в слэке belskikh)
Новая СОТА в создании новый 3д видов предмета из всего лишь нескольких (порядка 25 штук) изображений с нескольких видов, чем-то похоже на интерполяцию между видами.

Суть подхода следующая:
- Генерируется датасет 3Д объектов и рендерятся соответствующие некоторым позициям камеры 2Д виды.
- Каждая точка вида моделируется как 3д координата (x, y, z) и угол камеры, подаётся на вход в обычный MLP, на выходе получаются цвета точки (r, g, b) и её объёмная плотность.
- Используем классические методы объемного рендеринга, чтобы полученные на шаге 2 значения превратить в 2д изображение.
Так как объёмный рендеринг это дифференцируемая операция, то можно обучать MLP, накидывая L2 лосс на получившееся в п3 изображение.
В простом виде это у авторов не завелось, так что придумали несколько трюков:
- ограничили сеть тем, что предсказание объемной плотности происходит только используя координаты x, y, z. Сделали это так: сначала MLP процессит координаты x, y, z через 8 полносвязных слоёв (ReLU, 256 нейронов на слой) и предсказывает объемную плотность и 256-размерный вектор признаков. Этот вектор затем конкатенируется со значениями углов камеры и подаётся дальше в 4х слойный MLP (ReLU, 128 нейронов на слой), который выдаёт уже зависимый от вида RGB цвет.
- Positional Encoding на инпут признаки. Мотивируют это темой, что глубокие сети склонны выучивать низкочастотные функции, в то время как для аутпута высокого разрешения нужны более высокие частоты. Каждую фичу (координаты отдельно и все углы камеры отдельно) кодируют через positional encoding перед подачей в MLP
- Для рендеринга каждой сцены используется не одна, а две сети, одна «грубая», а другая «точная». Далее их предсказания собираются и сэмплируются через алгоритм Hierarchical volume sampling.
Для каждой сцены оптимизируются отдельные сетки. Лоссом является сумма L2 между GT и результатами рендера выходов «грубой» и «точной» сеток. Обучение одной сетки длится 1–2 дня на 1xV100.

2. Scene Text Recognition via Transformer
Авторы статьи: Xinjie Feng, Hongxun Yao, Yuankai Qi, Jun Zhang, Shengping Zhang (China, 2020)
Оригинал статьи :: GitHub project
Автор обзора: Александр Бельских (в слэке belskikh)
Новый подход к задаче Optical Character Recognition (OCR), заключающийся в объединении ResNet и Transformer. Выдаёт СОТА результаты на распознавании букв из текста, особенно сильно аутперформит аналоги на текстах сложной формы и шрифтов (изогнутый текст на упаковках и т.п.).

Суть метода такая:
- Кропаем из изображения прямоугольник с текстом
- Ресайзим в 96×96
- Пропускаем через первые 4 слоя ResNet (уменьшение размерности 1/16, предпоследний блок)
- Полученный HxWxC фичемап (6×6x1024) решейпится в H*WxC (36×1024), затем пропускается через FC слой, чтоб уменьшить число каналов (до 36×256)
- Полученный в итоге фичемап называется в статье Word embedding и подаётся на вход модели Трансформера (можно рассматривать его как последовательность размером 256)
- На выходе получаем последовательность букв.
Здесь активно утилизируется мощный механизм внимания Трансформера, который «сам» выбирает, на какой участок изображения смотреть, чтоб найти там букву. Этим можно объяснить такие хорошие результаты на классически сложных датасетах с текстами сложной формы.
В качестве экстрактора фичей из изображения авторы использовали первые 4 слоя энкодера ResNet-101 (предобученный из torchvision). Архитектура Трансформера такая:
- энкодер состоит из 4 одинаковых слоёв, каждый из которых состоит из двух мини-слоёв;
- первый минислой это multi-head self attention механизм;
- второой минислой это position-wise полносвязный слой;
- декодер состоит из 4х одинаковых слоёв, помимо аналогичных двух мини-слоёв, в слоях декодера есть ещё один мини-слой — multi-head attention поверх аутпута энкодера;
- между всеми мини-слоями внутри основного слоя есть residual связи и layer norm;
- также используется выучиваемый эмбеддинг позиционного энкодинга (нужно для того, что правильно восстанавливать последовательность символов).
Модель обучена на датасете SynthText и RRC-ArT. Обучали всё на Tesla P40 (про время трейна и инференса инфы нет).
Модель показывает себя на уровне с аналогами в задачах распознавания «выровненного» (близкого к прямоугольно-горизонтальному) текста и значительно аутперформит аналоги в задаче распознавания изогнутого/сложного текста.
Фейлит модель чаще всего в случаях (см. примеры ниже):
- сложные шрифты, наложения, низкое разрешение;
- длинный текст.
Авторы предполагают три основные причины для этого:
- Мало длинного текста в трейн-сете.
- Ресайз длинного текста приводит к низкому разрешению.
- Из-за одной ошибки декодера в начале/середине слова следующий предикт тоже с большой вероятностью будет ошибочным.

Авторы статьи: (Imperial College London, Google Research, 2019)
Оригинал статьи
Автор обзора: Юрий Кашницкий (в слэке yorko)
В задаче суммаризации текста выделяют подходы extractive и abstractive. В первом случае пересказ — это по сути подмножество предложений из исходного текста, второй подход в целом сложнее — пересказ может быть новым текстом меньшей длины, как, например, аннотация научной статьи.
Авторы PEGASUS (первый — из Imperial College, еще три — из Google Research) подходят к задаче abstractive summarization предлагая Gap Sentences Generation objective для предобучения обычного трансформера. Это тот же Masked Language Modeling, только в BERT & Co. маскируются токены, а тут — целые предложения. Причем, получается именно abstractive self-supervised objective, то есть надо восстановить предложения, которые модель локально не видит. В случае extractive-суммаризации модель просто научилась бы некоторые предложения копировать, а остальные — игнорировать.
Вот как это работает схематически. Детали в статье не описываются, и мне лично было бы сложно провести reverse-engineering. Но идея такая: на входе 3 предложения, одно из них маскируется символом [MASK1], также некоторые токены маскируются символом [MASK2]. Стандартная схема трансформера «энкодер-декодер» — и надо восстановить замаскированное предложение и отдельные токены. Надо отметить, что это авторы попытались совместить предложенную Gap Sentences Generation objective и MLM из BERT, но эксперименты показали, что GSG уже достаточно, бертовая токен-MLM не улучшает. А картинку уже нарисовали с токен-MLM:).
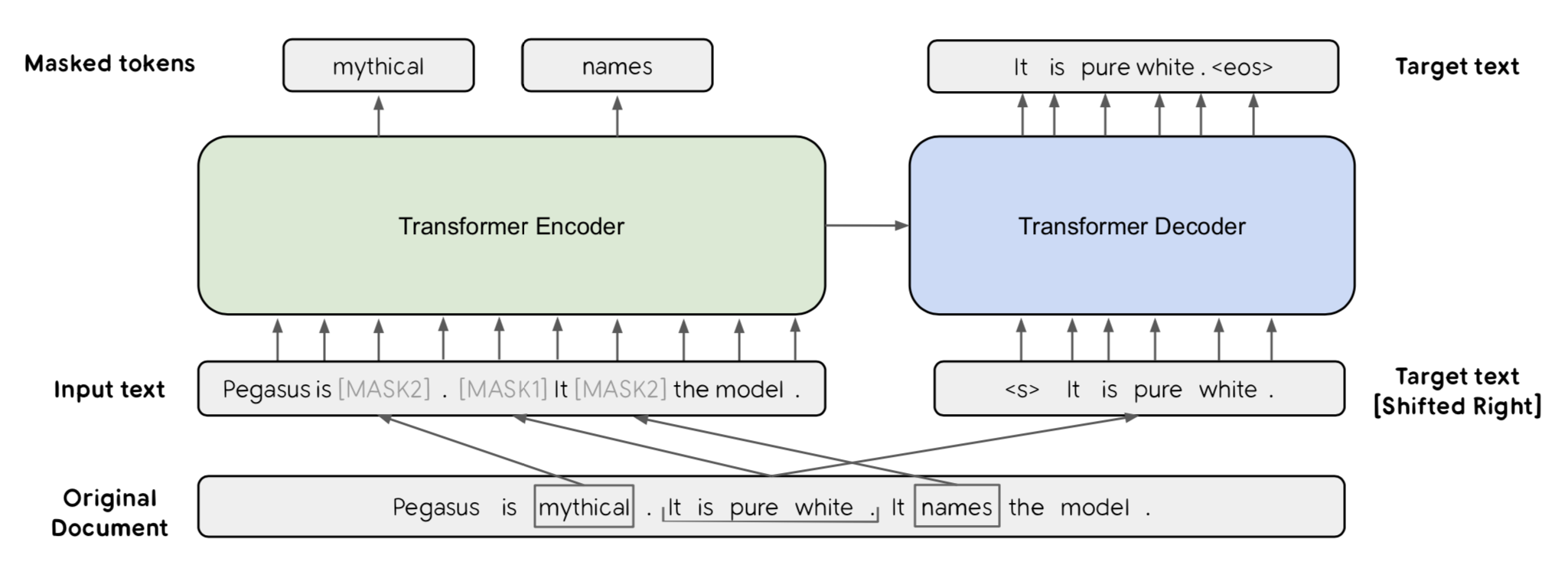
Прятать (маскировать) некоторые предложения решили не просто так, а с помощью эвристик для выбора «важных» предложений. Рассмотрели 3 подхода: маскировать случайные предложения (Random), первые несколько штук (Lead) и Principal, отобранные по ROUGE1-F1. В последнем случае считается похожесть каждого предложения на весь текст и выбирается некоторый процент (остановились на 30%) самых репрезентативных предложений, чтоб на них наложить маску и их пытаться восстановить.
Последняя стратегия Principal в итоге сработала лучше всего, хотя на новостных датасетах выстрелила Lead, т.к. в новостях есть такой bias, что все главное уже в начале сообщается.
Предобучились на двух корпусах: C4 (Colossal and Cleaned version of Common Crawl, 750 Gb), а также зарелизили HugeNews — 3.8 Tb новостей (или материалов, похожих на новости).
Дообучились на 12 задачах (пересказать новости, научные статьи, патенты, дискуссии на reddit и т.д.), почти везде SOTA (на момент публикации, дек. 2019). Также показали, что хороши, когда дообучаются на малой части датасета всего из 1000 примеров.
Вот это часть таблички в Appendix E меня впечатлила, на 10к примерах результаты в целом вровень с предыдущей SOTA (по строкам разные датасеты, 12 штук):

Авторы также посмотрели глазками на пересказы — порадовались высокому лингвистическому качеству сгенерированного текста, а также неожиданным проявлениям «понимания» текста, например, футбольный клуб Chelsea в пересказе уже возникал как «Jose Mourinho«s side» и «The Blues». Все вроде круто, только ни код ни веса не выложили. В аппендиксе как-то гиперпараметры перечислены — и на том спасибо.
От автора обзора: Ах да, в целом идея-то выглядит очень простой — берешь трансформер, маскируешь некоторые предложения. Сказывается эффект от предобучения на очень больших датасетах. Вот термин «big data» уже замылен давно и вообще моветон, но это именно оно.
И вдогонку — пока еще хороших метрик для оценки abstractive суммаризации нет. Использование ROUGE — довольно спорный выбор, лучшее из худшего. Поскольку ROUGE очень простая метрика, по сути смотрит только на пересечение слов/энграмм в пересказе-эталоне и в сгенерированном пересказе. Не проверяется ни грамматика, ни качество текста. Вкратце про это у Рудера, заодно SOTA можно заценить на разных задачах.
4. Lagrangian Neural Networks
Авторы статьи: Miles Cranmer, Sam Greydanus, Stephan Hoyer, Peter Battaglia, David Spergel, Shirley Ho (Princeton, Oregon, Google, Flatiron, 2020)
Оригинал статьи :: GitHub project: Blog
Автор обзора: Вадим Петров (в слэке graviton)
Коротко
В работе предложен способ обучения нейронных сетей, которые в последующем играют роль «лагранжиана» (функционала описывающего состояние системы) для предсказания протекания физических процессов. Данный подход позволяет задать априорные знания о законах сохранения, играющих определяющую роль в физике. В качестве основы использован «лагранжев» подход в механике, который лежит в основе законов движения, таких как, например, 2-ой закон Ньютона.

Детали
Предшествующие подходы:
Одна из проблем обычных нейронных сетей — неспособность выучить основные симметрии и законы сохранения физических явлений. Были предложены подходы, основанные на нейронных дифференциальных уравнениях (Hamiltonian Neural Networks и Deep Lagrangian Networks), решающие эти проблемы. Но у них оказались свои сложности:
- Hamiltonian Neural Networks — использует «гамильтонов» формализм, который накладывает более жесткие ограничения на координаты-импульсы, что не применимо для всех существующих задач;
- Deep Lagrangian Networks — в свою очередь ограничен только задачами с квадратичной формой кинетической энергии, т.е. подходит для обычных механических задач, но не применим для более сложных задач, вроде движения заряженной частицы в магнитном поле.
Подход
Авторы предложили использовать нейронную сеть в качестве лагранжиана (функционала описывающего состояние системы). Т.е. подав на вход сети, например, координату и скорость системы, сеть выдает лагранжиан, к которому применяются градиенты, позволяющие вычислить ускорение. Полученное ускорение используется для изменения состояния системы.
Важным в работе является следующее:
- Для предсказания поведения простых систем, которые несложно описать лагранжианом, можно использовать уравнения движения и получить нужные результаты.
- Однако следует помнить, что указанный лагранжиан для простых моделей — это лишь наше упрощенное представление о системе (мы обычно не учитываем, например, трение и сопротивление воздуха).
- Если же мы возьмем реальную систему, которую сложно описать лагранжианом и решить аналитически, мы все равно можем собрать датасет и обучить нейронную сеть (лагранжиан), с помощью которого можно будет предсказывать поведение системы на новых данных.
Имплементация
Для решения задачи авторы переписали уравнения движения (Лагранжа-Эйлера) в форме, к которому применим подход нейронных дифференциальных уравнений и реализовали это в библиотеке jax.
Архитектура
В качестве архитектуры использована 4-ех слойная полносвязная сеть с 500 нейронами в каждом слое. Для инициализации весов разработали свой подход.
Функция активации
ReLU для данной задачи не подходит, т.к. 2-ая производная нулевая. Проверили ReLU^2, ReLU^3, tanh, sigmoid и softplus. softplus оказалась лучшей.
Эксперименты
- Продемонстрирована применимость подхода даже к графовым сетям.
- Проведены эксперименты для двойного маятника. Энергия системы со временем сохраняется значительно лучше, чем с предыдущими подходами: ошибка 0.4% против 8% (см. рисунок ниже).

5. Deformable Style Transfer
Авторы статьи: Sunnie S.Y. Kim, Nicholas Kolkin, Jason Salavon, Gregory Shakhnarovich (Chicago, USA, 2020)
Оригинал статьи
Автор обзора: Евгений Кашин (в слэке digitman)
Авторы говорят, что в стайл трансфере есть два главных компонента форма и стиль. Обычно все работы в этой области меняют текстуры, без геометрии. Они сделали независимый от домена стайл трансфер, изменяющий форму объектов.

Их метод DST (deformable style transfer) берет на вход изображения «контента» и «стиля», накладывая на них ограничения: оба из одного домена, и между ними есть какая-то связь (например, и там и там машина в одном ракурсе). Основная их идея — давайте геометрически растянем контент картинку, чтобы она матчилась с картинкой стиля. Для матчинга двух картинок найдем на них подходящие кейпоинты автоматически, и применим на этом классический стайл трансфер (на деле все посложнее).
Так как они не привязываются к конкретному домену (в отличие от их бейзлайнов), то нельзя использовать какой-то готовый детектор лицевых ландмарок, нужно что-то универсальное для всех доменов. Использовали NBB (neural best-buddies): берут активации с разных слоев претрейн CNN для 2-х изображений, находят похожие активации в верхних слоях, «прослеживают» их путь до нижних слоев, спускаясь до уровня пикселей, кластеризуют попиксельные геометрические фичи на k кластеров (80), получая k соответствующих кейпоинтов на 2-х картинках, потом еще фильтруют эвристиками.
После нахождения соответствия точек между изображениями, считают вектор смещения для каждой пары точек. Из этого получают уже dense flow field из изображения 'I' в его warped версию W (I, θ). Для нахождения векторного поля используют thin-plate spline interpolation. Все дифференцируемо, дальше будет в лоссе видно, как они находят θ — вектор смещений.

На рисунке выше: е — контент, f — стиль, g — совмещенные стилевые кейпоинты с контент картинкой, h — попытка растянуть контент до геометрии стиля.
Дальше они берут два метода для сравнения, которые будут использовать для переноса стиля: Gatys (стиль как Gramm matrix по vgg активациям, контент — активации с какого либо слоя) и STROTSS (стиль состоит из 3-х компонент, контент тоже активации). Оба метода используют оптимизацию по входу, используя контент и стиль лоссы. Их метод DST не меняет контент лоссы, а только добавляет слагаемое к стиль лоссам:

Лосс состоит из стайл лосса между картиной стиля I_s и стилизованной картинкой X (первое слагаемое) и стайл лосса между I_s и геометрически деформированной версии стилизованной картинки W (X, θ). Таким образом оптимизация производится сразу для обычной и растянутой версии изображения.

Следующий лосс — deformation loss для k кейпоинтов, где p_i и p_i' — source и target кейпоинты соответственно. Здесь оптимизируется как раз по смещениям θ. Кажется, что они могли бы просто взять разность p_i' и p_i, но дальше говорят, что если слишком агрессивно минимизировать этот лосс, то будут артефакты из-за неидеального нахождения пар кейпоинтов или сильно разной геометрии source и target изображений. Поэтому они еще добавили регуляризацию на «total variation norm of the 2D warp field». Это дополнительно заставляет поле двигать соседние пиксели в одну сторону.

Итоговой лосс:

где коэффициентами α и β можно регулировать сохранение стиля, а через γ — величину искажения. Результат оптимизации (финальное изображение) — это warped stylized image W (I, θ).
Ну и наверно самый важный рисунок, который показывает, на сколько их метод лучше, чем просто применить трансформ на стайлтрансфере по отдельности. На рисунке ниже представлены: контент, стиль, просто STROTSS, заварпленный выход STROTSS, DST, отдельно преобразование контента трансформацией, выученной через DST.

Делали user study на AMT и показали, что их метод сильно лучше переносит «стиль» изображения, несущественно проседая по переносу «контента» по сравнению с бейзлайнами.
6. Rethinking Few-Shot Image Classification: a Good Embedding Is All You Need?
Авторы статьи: Yonglong Tian, Yue Wang, Dilip Krishnan, Joshua B. Tenenbaum, Phillip Isola (MIT, Google, 2020)
Оригинал статьи :: GitHub project
Автор обзора: Александр Бельских (в слэке belskikh)
Очень простой бейзлайн для few-show learning, который заключается в получении хорошего экстрактора фичей и дальнейшем обучении поверх фичей логрега на нескольких примерах данных. Несмотря на простоту, аутперформит нынешнюю соту на ряде датасетов в среднем на 3%, показывая, что хорошее представление данных работает не хуже сложных meta-learning алгоритмов.
Авторы рассматривают проблему мета-обучения, которое обычно представляет собой семейство задач, разделенных на мета-трейн и мета-тест сеты. Каждая задачка состоит из ограниченного набора данных. Алгоритм должен быть способен так обобщиться на задачках из мета-трейн сета, чтоб быть способным решать задачи из мета-тест всего по нескольким примерам из мета-тест таски. Few-shot learning это одна из задач мета-обучения.
Подход, предлагаемый авторами:
- Объединяем все задачки в одну общую задачу классификации (насколько я понял, если лейблов классификации в каких-то тасках нет, их можно получить псевдолейблингом).
- Учим обычную сеть-классификатор на всех данных.
- Во время теста на новой задаче экстрактим фичи замороженной сеткой-экстрактором и учим на них обычный логрег по нескольким (1–5) сэмплам, этот логрег и замороженный фичеэкстрактор и используются для теста.

Для дополнительного повышения качества экстрактора фичей запускается процесс self-distillation по стратегии Born-again из соответствующей статьи. Во время этого процесса учитель и студент это одинаковые архитектуры, обучающиеся на одном и том же мета-трейн сете. Студент учится минимизировать кросс-энтропию между своими предиктами и GT лейблами, а также минимизировать KL — дивергенцию между своими предиктами и софт таргетами из учителя.
Это итеративный процесс, и каждый раз студент становится учителем на следующем этапе. Авторы объясняют повышение качества тем, что при дистилляции модель лучше ловит связь между классами (например, что кошка ближе к собаке, чем к самолёту) за счёт обучения на софт-лейблах.
В экспериментах использовали ResNet-12 и SeResNet-12 архитектуры на датасетах miniImageNet, tiered- ImageNet, CIFAR-FS, и FC100.
Помимо логрега пробовали ещё kNN, но он показал себя хуже во всех сетапах, даже на отнормированных фичах.

7. Attentive CutMix: An Enhanced Data Augmentation Approach for Deep Learning Based Image Classification
Авторы статьи: Devesh Walawalkar, Zhiqiang Shen, Zechun Liu, Marios Savvides (Carnegie Mellon University, USA, 2020)
Оригинал статьи
Автор обзора: Андрей Лукьяненко (в слэке artgor)
Авторы предложили продвинутую версию cutmix. Улучшение заключается в том, что заменяют не рандомные куски картинки, а на основе attention maps, вытащенных претренированной сеткой. Это позволяет заменять самые важные части картинки, а не рандомные куски фона.Провели много экспериментов на CIFAR-10, CIFAR-100, ImageNet (!) и тренировали с нуля разные варианты ResNet, DenseNet, EfficientNet. В среднем улучшение + 1.5% качества.

По факту подход реально не сложный, но и описывают они его в довольно общих словах, да и код не выложили:
- берем претренированную сетку, чем выше качество модели, тем лучше;
- вытаскиваем feature map, находим самые важные регионы;
- эти куски вставляем на вторую картинку в тех же местах, где они были в оригинальной картинке.
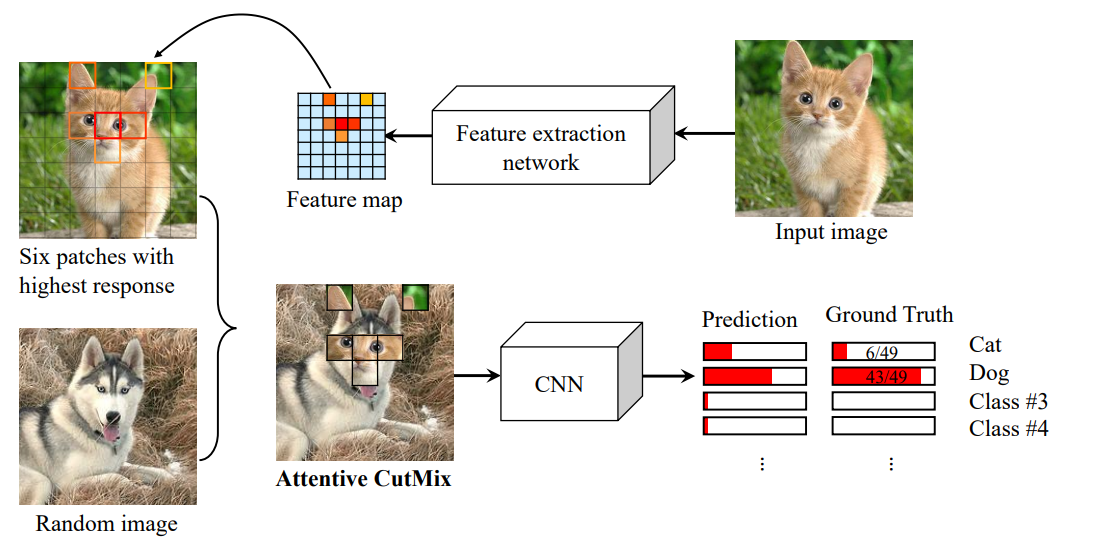
От автора обзора: Если честно, мне это напомнило CAM CutMix, который Chris описывал на конкурсе Kaggle: Bengali.AI Handwritten Grapheme Classification.
Эксперименты
Все модели тренировали с нуля и на pytorch:
- CIFAR-10 — 80 эпох, batch size 32, learning rate 1e-3, weight decay 1e-5;
- CIFAR-100 — 120 эпох, batch size 32, learning rate 1e-3, weight decay 1e-5;
- ImageNet — 100 эпох для ResNet и DenseNet, 180 для EfficientNet, batch size 64, learning rate 1e-3
Ablation study
Количество патчей, которые будут заменены — гиперпараметр, который надо подбирать. Пробовали значения от 1 до 15. Значение 6 оказалось лучше всего.
