Рубрика «Читаем статьи за вас». Июнь 2020 года

Привет, Хабр! Продолжаем публиковать рецензии на научные статьи от членов сообщества Open Data Science из канала #article_essense. Хотите получать их раньше всех — вступайте в сообщество!
Статьи на сегодня:
- PointRend: Image Segmentation as Rendering (Facebook AI Research, 2020)
- Natural- To Formal-Language Generation Using Tensor Product Representations (USA, 2019)
- Linformer: Self-Attention with Linear Complexity (Facebook AI, 2020)
- DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution (Johns Hopkins University, Google, 2020)
- Training Generative Adversarial Networks with Limited Data (NVIDIA, 2020)
- Multi-Modal Dense Video Captioning (Tampere University, Finland, 2020
- Are we done with ImageNet? (DeepMind, 2020)
- 2020 год: Январь — Февраль, Март ч1, ч2, Апрель ч1, ч2, Май ч1, ч2
- 2019 год: Январь — Июнь, Июль — Сентябрь, Октябрь — Декабрь
- Декабрь 2017 — Январь 2018, Февраль — Март 2018
- 2017 год: Август, Сентябрь, Октябрь — Ноябрь
1. PointRend: Image Segmentation as Rendering
Авторы статьи: Alexander Kirillov, Yuxin Wu, Kaiming He, Ross Girshick (Facebook AI Research, 2019)
Оригинал статьи :: GitHub project
Автор обзора: Евгений Желтоножский (в слэке evgeniyzh, на habr Randl)
Авторы предлагают элегантное решение проблемы низкого разрешения масок в сегментации с помощью адаптивного алгоритма, который уточняет маску в тех местах, где она недостаточно точная. Метод может быть применен поверх других алгоритмов, увеличивая как визуальное качество, так и AP (average precision).
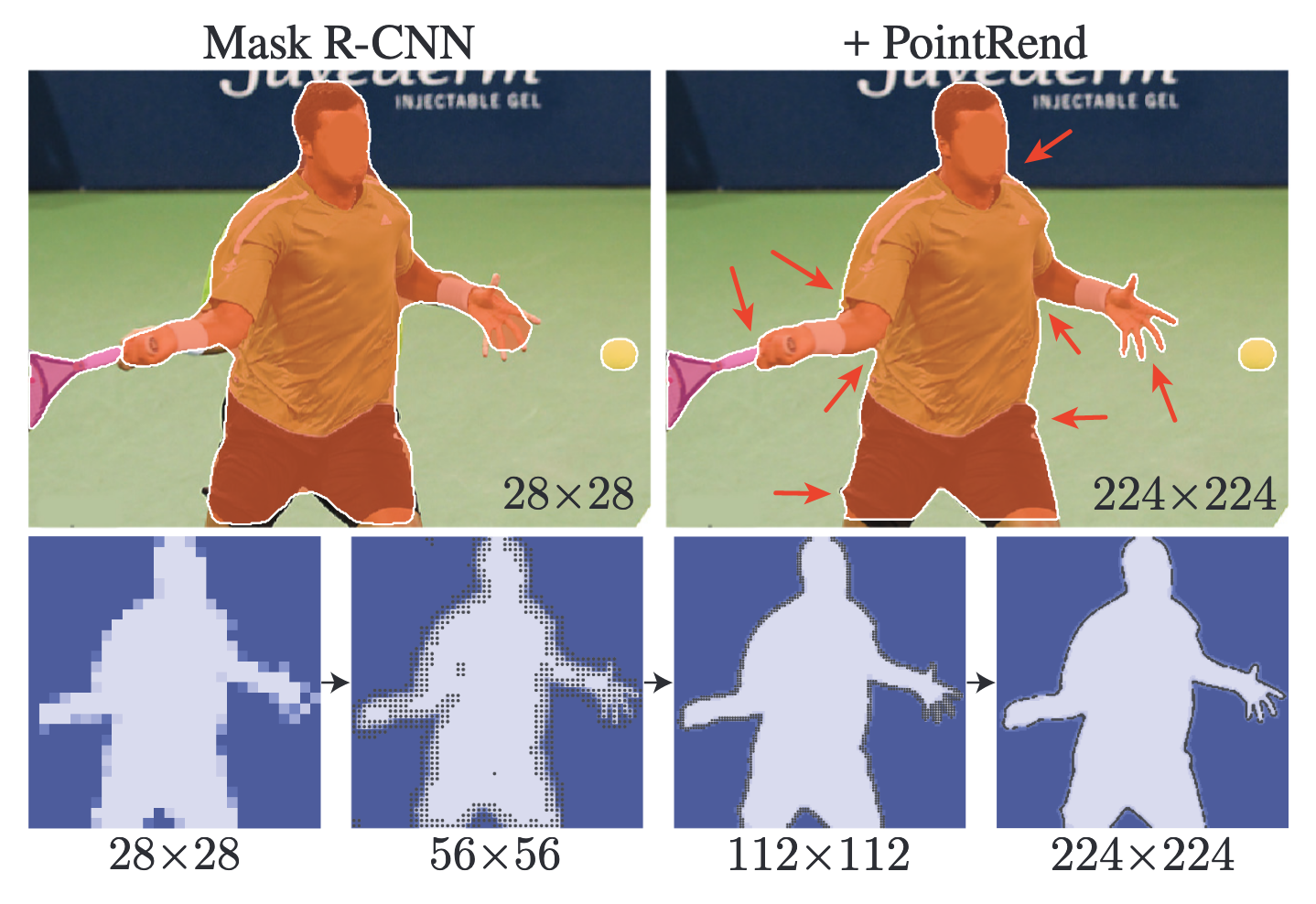
Мотивация авторов приходит из рендеринга, где подобные проблемы решаются с помощью нерегулярного семплирования. На проблему сегментации предлагается посмотреть как на проблему рендеринга: мы пытаемся получить из (непрерывного) occupancy map предмета или класса «рендерить» регулярную сетку (пикселей) маски сегментации. PointRend берет маску низкого разрешения, апсемплит и уточняет ее в определенных точках. Так как большая часть маски не требует уточнения, эти точки расположены в основном на границе маски. Таким образом, для увеличения разрешения маски в два раза мы не классифицируем в четыре раза больше пикселей.
Во время инференса используется техника, которая называется adaptive subdivision. Для начала feature map апсемплится стандартным билинеарным апсемплингом. Далее, N точек с самой близкой к 0.5 вероятностью принадлежности к маске прогоняются через MLP (с общими весами для всех точек и регионов) и для них генерируются новые фичи. Процесс повторяется пока не достигается необходимое разрешение, и требует N * log (M/M_0) предсказаний вместо M^2 (M — входной размер, M0 — размер первого шага, N — количество обрабатываемых граничных точек).
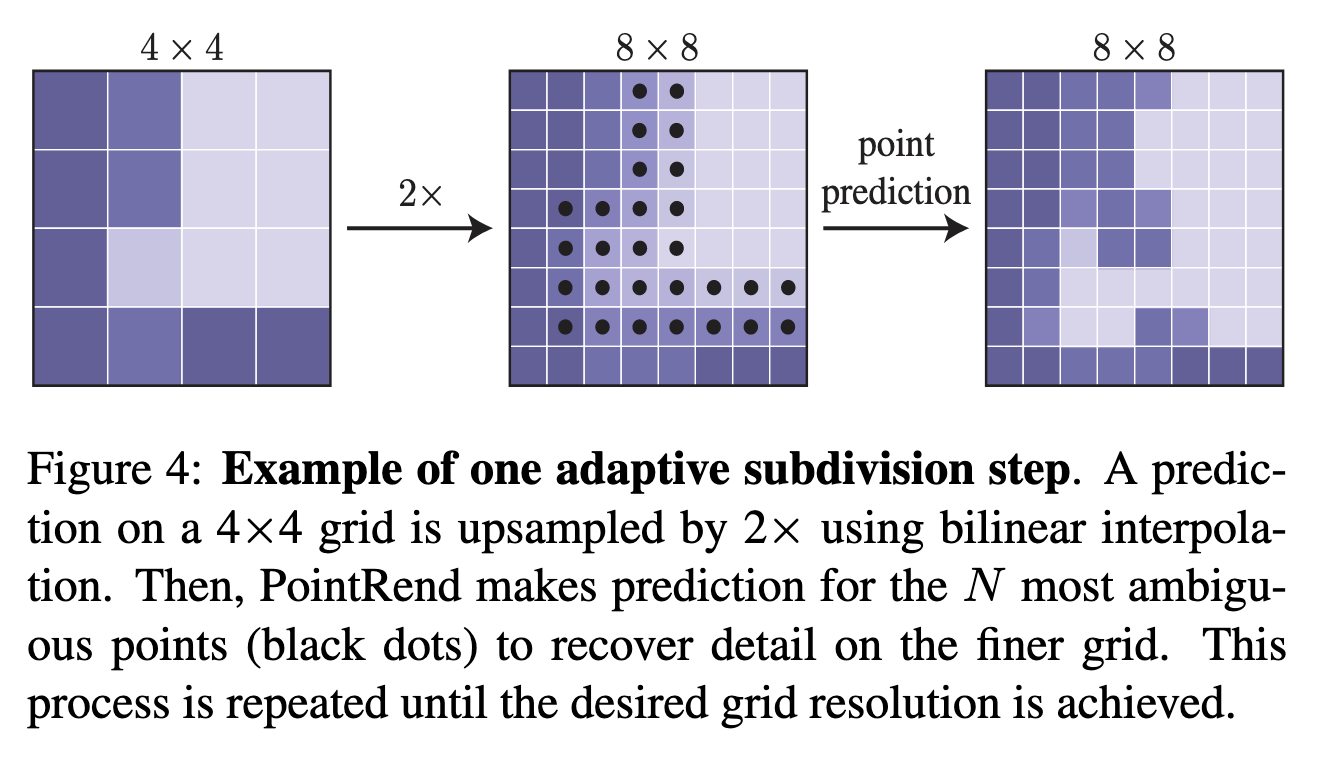
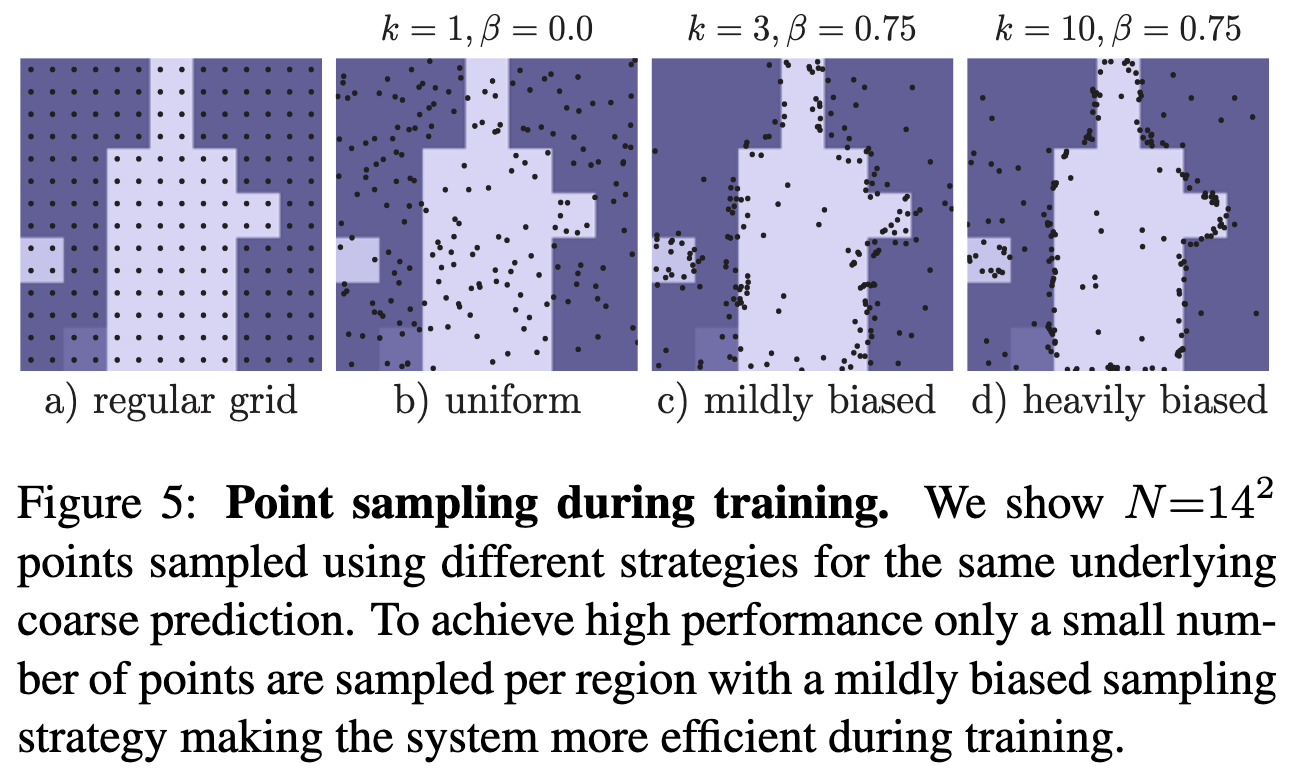
Из-за итеративности процесса, бекпропогейшн через него работает не очень хорошо. Вместо этого, авторы сэмплируют точки из распределения, которое смещено в сторону точек с низким confidence.
В качестве фич для точек используется конкатенация высокоуровневых фич (предсказание сети о классе этой точки) и низкоуровневых (фичи из одного или нескольких фичермапов CNN).
Для экспериментов авторы использовали Mask R-CNN с ResNet-50 + FPN. Голову для предсказания масок заменили на более эффективную которая предсказывает маску 7×7. Кроме того, на вход масочной головы во время трейнинга подавали выход головы для bounding box, что не улучшило Mask R-CNN, но улучшило PointRend за счет более качественного семплирования точек. В итоге оверхед по флопсам по сравнению с Mask R-CNN с масками 28×28 почти в 2 раза (0.5 vs. 0.9 GFLOPS), но конечно не сравним с масками 224×224 (34 GFLOPS).
Так как PointRend улучшает качество масок на границах, значительного улучшения по AP не наблюдается. Но на датасете с более точными масками (LVIS) профит выше. Авторы провели неплохой ablation study: количество точек на каждом этапе (N), итоговое разрешение маски, тип семплирования во время тренинга, а также разные архитектуры и увеличение времени тренировки.
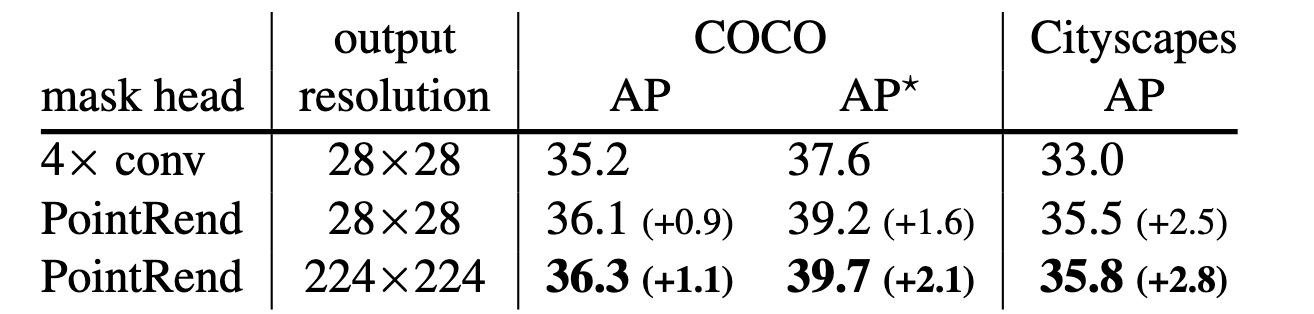
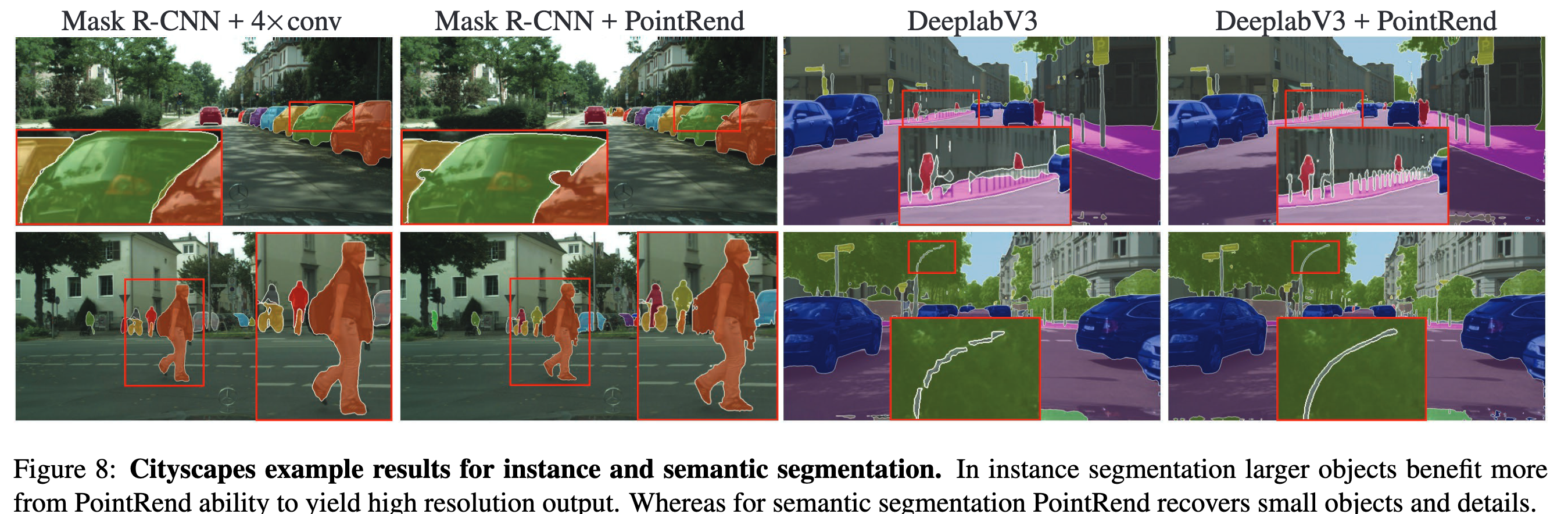
Алгоритм также протестировали на семантической сегментации, поверх DeeplabV3 и SemanticFPN. Опять таки, по mIoU профит небольшой, но сетка восстанавливает мелкие детали и визуально разница заметна.
2. Natural- To Formal-Language Generation Using Tensor Product Representations
Авторы статьи: Kezhen Chen, Qiuyuan Huang, Hamid Palangi, Paul Smolensky, Kenneth D. Forbus, Jianfeng Gao (USA, 2019)
Оригинал статьи :: GitHub project: Реализация автора обзора
Автор обзора: Максим Плевако (в слэке Max Plevako)
Исследователи из компании Майкрософт предлагают модель кодера-декодера на основе представлений в виде тензорных произведений для перевода естественного языка в формальный.
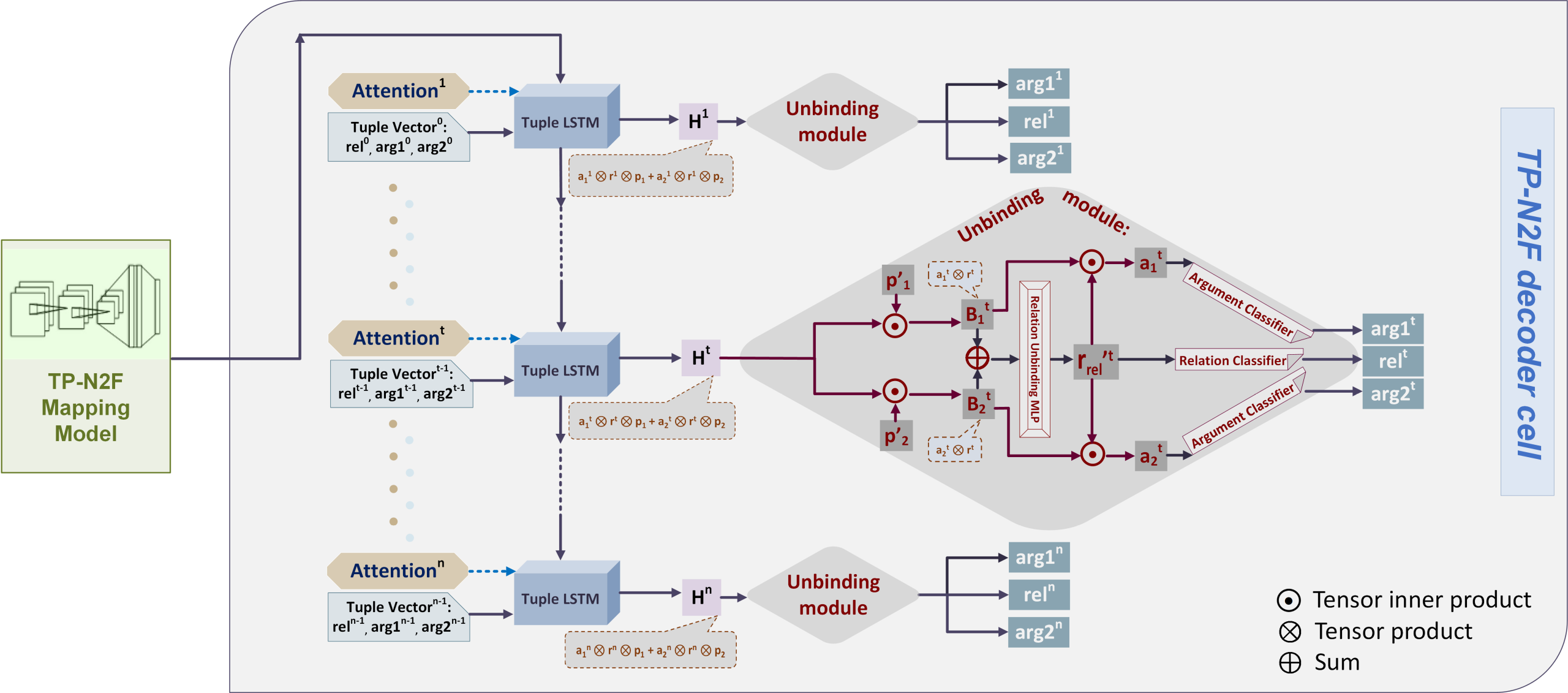
Кодер использует представления в виде тензорных произведений для погружения символических структур некоторой формальной задачи, сформулированной на естественном языке, в линейное векторное пространство. На основе этих векторных представлений декодер, по сути, генерирует символическую формулу/программу, решающую поставленную задачу. Авторам удалось существенно превзойти результаты ранее существовавших моделей на основе долгой краткосрочной памяти (LSTM) и показать передовые результаты в решении математических задач на основе набора данных MathQA и синтезе программ на основе набора данных AlgoLisp.
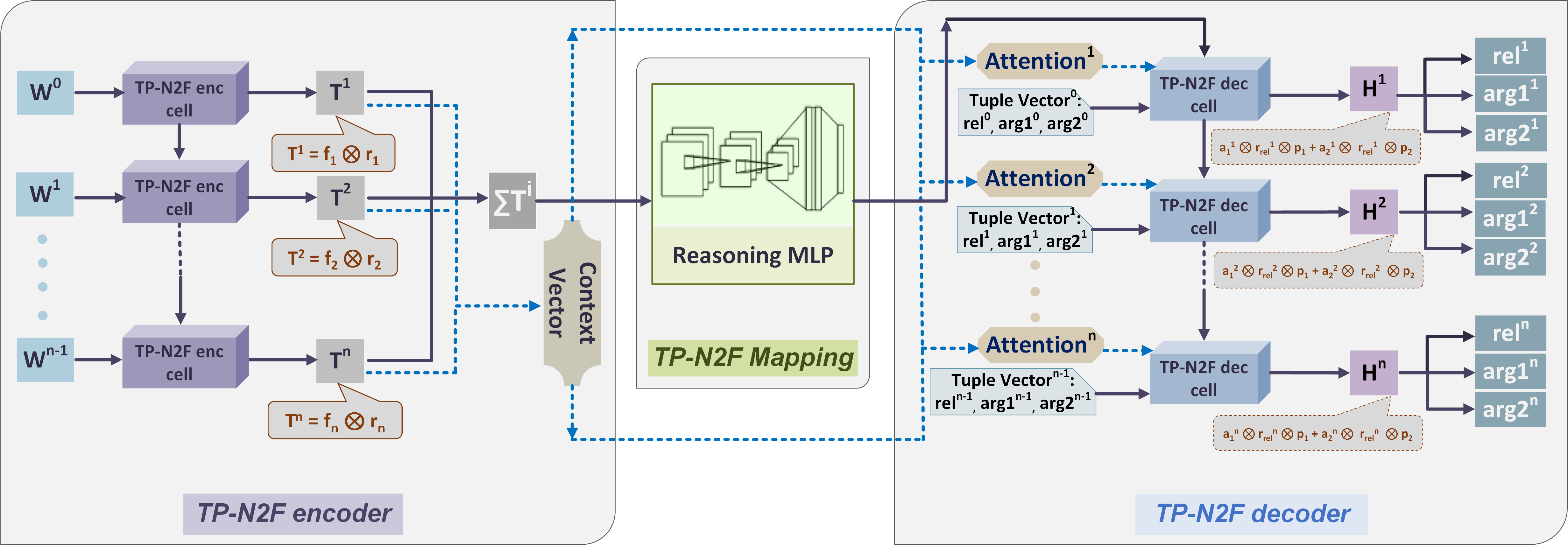
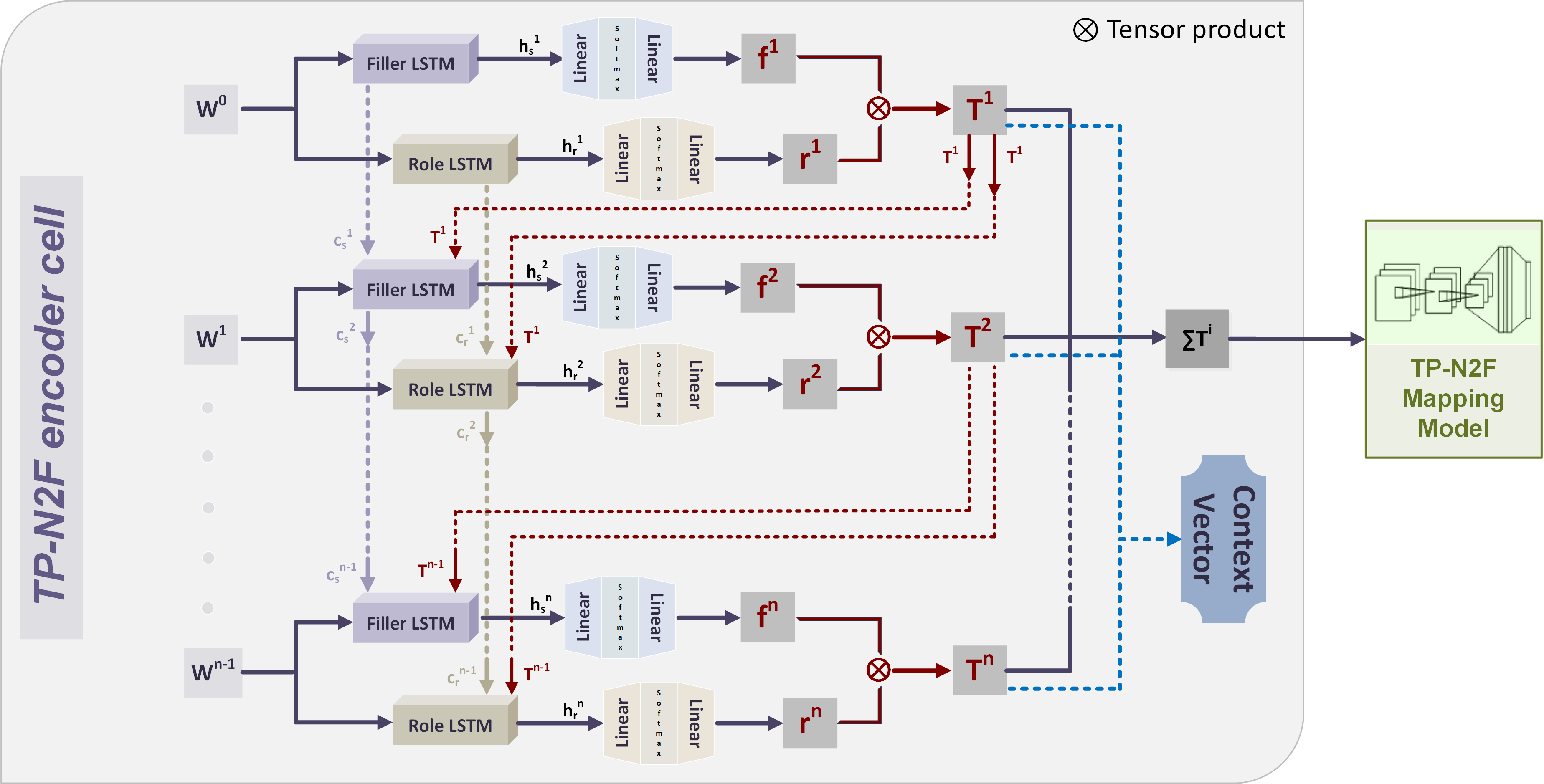
Каждому входному токену в кодере назначается вектор «роли» и вектор «исполнителя роли», выбираемые из соответствующих обучаемых словарей. Назначение основывается на гипотезе о том, что векторы «роли» и «исполнителя» аппроксимируют грамматическую роль и лексическую семантику слова соответственно.
Выбор этих векторов осуществляется парой модулей, каждый из которых состоит из ячейки долгой краткосрочной памяти и двух последующих линейных слоёв, соединённых функцией мягкого максимума и отображающих скрытое состояние ячейки в соответствующий вектор. Каждый токен представляется в виде тензорного произведения двух таких векторов.
При этом, помимо самого набора таких произведений, который в дальнейшем выполняет роль контекста для механизма внимания, всё предложение в целом представляется также в виде их суммы, которая с помощью многослойного персептрона кодируется в начальное скрытое состояние ячейки долгой краткосрочной памяти декодера.
На каждом шаге новое скрытое состояние ячейки долгой краткосрочной памяти декодера подаётся на вход механизма внимания со скалярным произведением в роли оценивающей функции и набором тензорных произведений векторов «ролей» и «исполнителей» в роли контекста. Выходной вектор передаётся на вход специального модуля, который расценивает его (вектор) так, как если бы он являлся представлением в виде тензорного произведения некоторого отношения с фиксированным набором аргументов.
Используя обучаемые структуры для вычленения позиций, отношения и аргументов из такого гипотетического представления, этот модуль выбирает наиболее вероятные символы для отношения и его аргументов, и выдаёт их на выход.
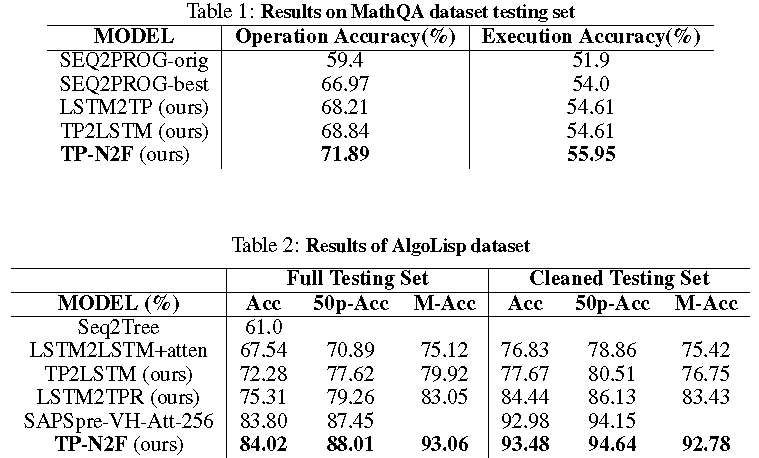
Такая модель, обученная с использованием метода адаптивной оценки моментов с педагогическим принуждением и перекрёстной энтропией в качестве функции потерь, показала на наборе данных MathQA точность операций/численных результатов, равную 71.89% и 55.95% соответственно. В задаче синтеза программ на наборе данных AlgoLisp также обученная модель показала точность 84.02% и 93.48% на полном и очищенном наборах тестов соответственно.
Примеры выводов:

3. Linformer: Self-Attention with Linear Complexity
Авторы статьи: Sinong Wang, Belinda Z. Li, Madian Khabsa, Han Fang, Hao Ma (Facebook AI, 2020)
Оригинал статьи
Автор обзора: Андрей Лукьяненко (в слэке artgor, на habr artgor)
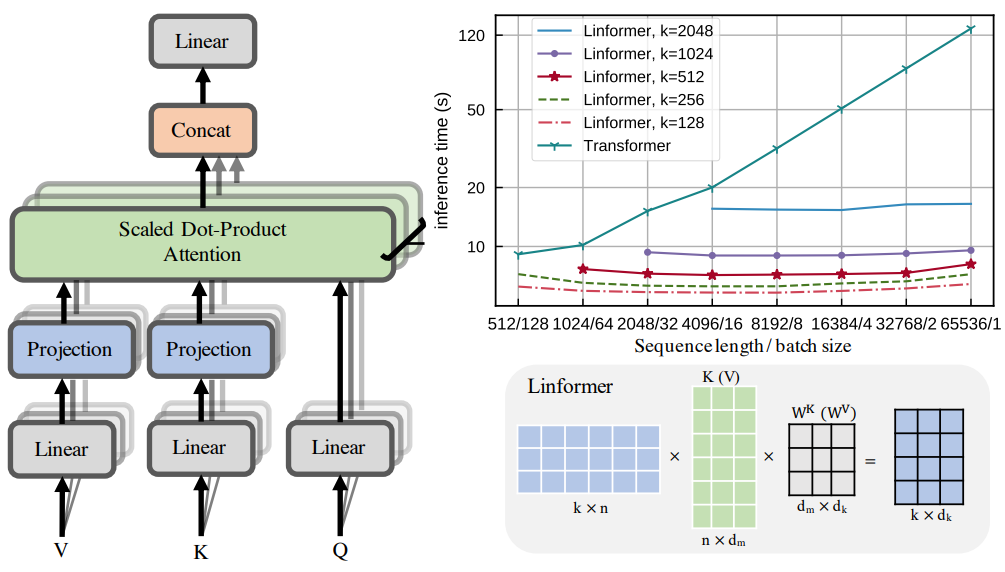
Авторы осознали, что механизм self-attention можно аппроксимировать матрицей низкого ранга. Они предлагают новую архитектуру self-attention, которая уменьшает сложность алгоритма с O (N^2) до O (N) во времени и пространстве.
Прям супер эффективно. Но все равно использовали 64 V100 для тренировки модели.
Если по сути: scaled dot-product attention декомпозируется во много мелких attention с помощью линейных проекций, комбинация которых по факту дает low-rank factorization от оригинального attention.
Self-Attention is Low Rank
P — the context mapping matrix. Авторы берут RoBERTa-base и RoBERTa-large, которые были претренированы на задачах классификации и masked-language-modeling tasks. Применяют SVD на головы и слои модели и строят графики нормализованных кумулятивных сингулярных значений, усредненных по 10к предложений. Как видно, большую часть информации можно получить, взяв несколько первых больших сингулярных значений.
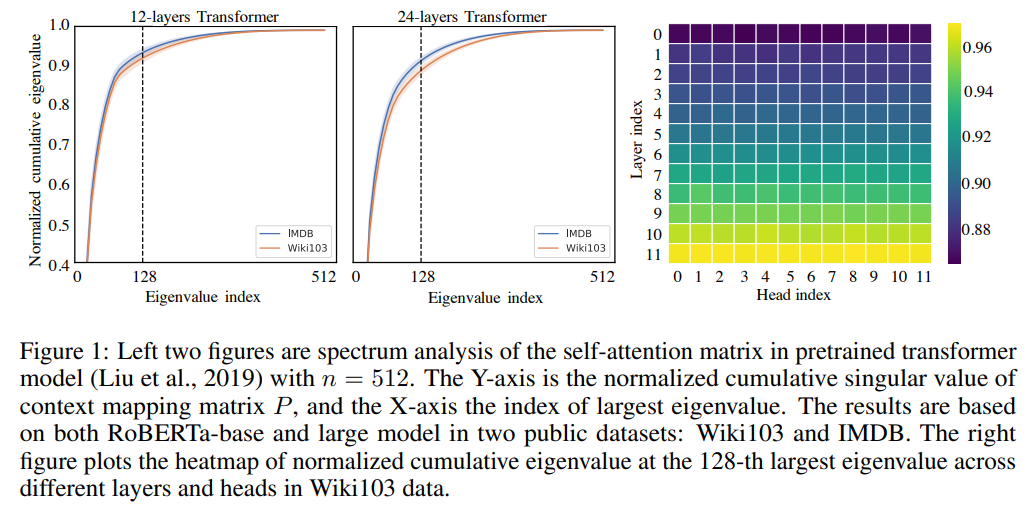
P можно аппроксимировать матрицей низкого ранга, но для этого придется делать SVD в каждой матрице self-attention, поэтому авторы предлагают другую идею.
Model
Основная идея: при расчете ключей и значений мы добавляем две матрицы линейных проекций. Они берут матрицы KW и VW (размерность n x d) и проецируют в размерность k x d, а затем считают n x k матрицу P с помощью scaled attention.
Дополнительные способы увеличения эффективности:
- Шеринг параметров между проекциями: Headwise, layerwise or key-value.
- Различная размерность проекций для разных слоёв. Для верхних слоёв можно уменьшать размерность без особых потерей качества.
- Другие варианты проекций — например pooling или convolution с кернелом n и stride k.
Эксперименты
RoBERTa. 64 Tesla V100 GPUs и 250k итераций. Во-первых, мы видим, что перплексия на валидации лишь чуть-чуть ниже, чем у трансформера. Дальше мы видим, что с увеличением длины последовательности модель сходится примерно к такой же перплексити.
Fine-tuning даёт примерно такое же качество, иногда и выше.
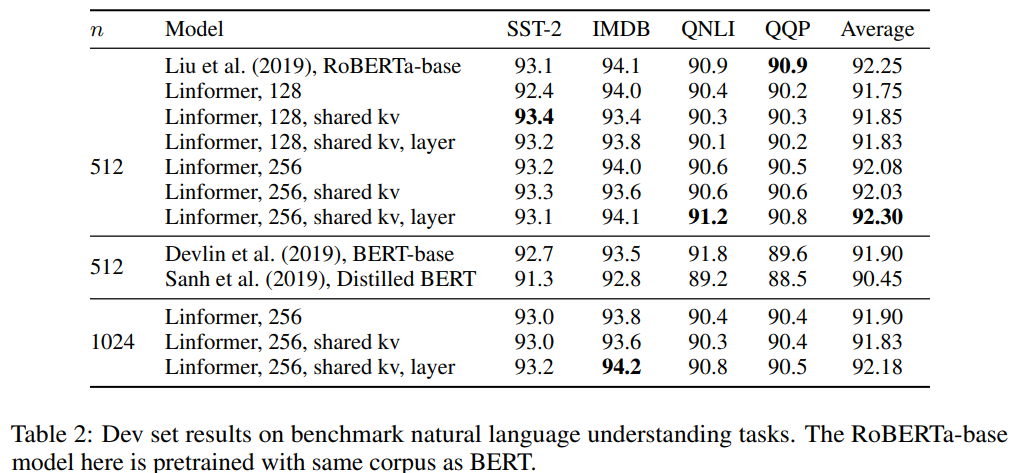
Ну и самое главное — инференс быстрее и требует меньше памяти
Для любителей математики в статье есть теоремы и их доказательства.
4. DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution
Авторы статьи: Siyuan Qiao, Liang-Chieh Chen, Alan Yuille (Johns Hopkins University, Google, 2020)
Оригинал статьи :: GitHub project: sotabench
Автор обзора: Евгений Желтоножский (в слэке evgeniyzh, на habr Randl)
Новая сота в object detection (54.7% AP на COCO test-dev), instance (47.1% AP на COCO test-dev) и panoptic segmentation (49.6% PQ на COCO test-dev). Основные идеи — добавление рекуррентности в Feature Pyramid, добавление аналога SE для глобального контекста и смешивания конволюций с разным dilation (который авторы называют atrous), но (частично) пошаренными весами.
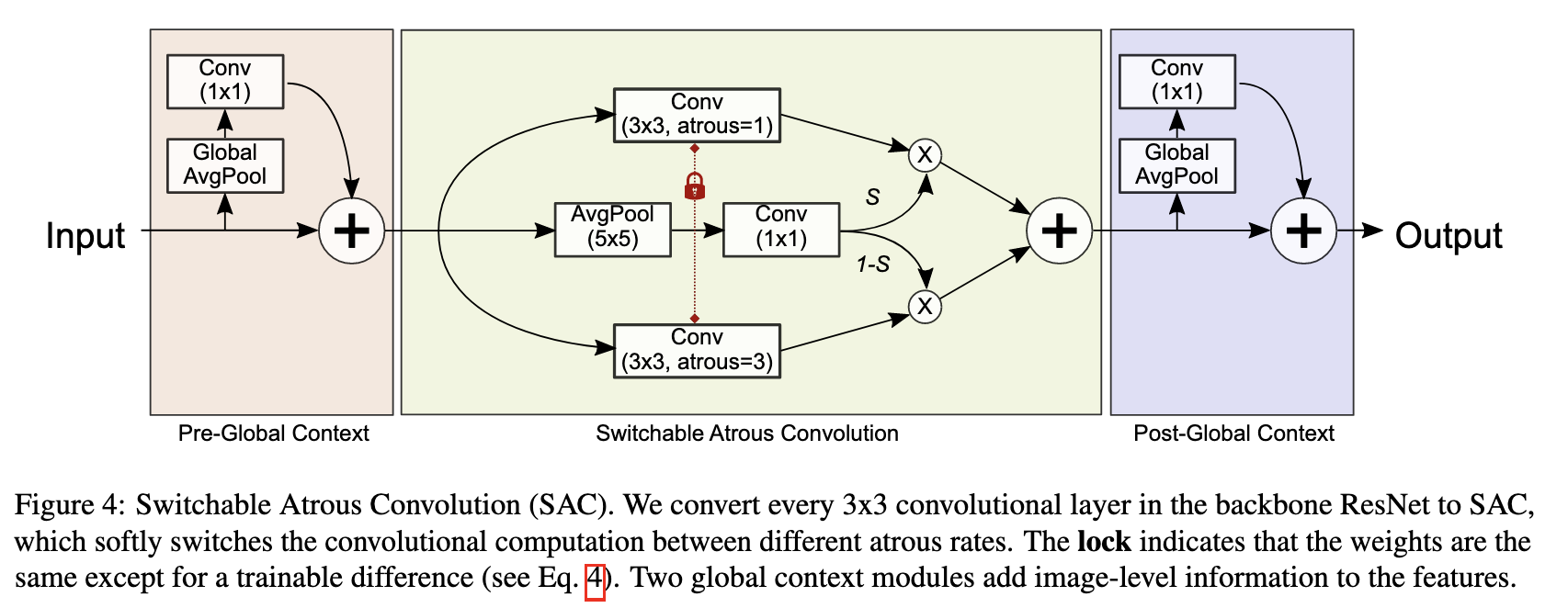
Recursive Feature Pyramid (RFP)Switchable Atrous Convolution предлагает прогонять изображение по пирамиде несколько раз (в статье авторы ограничиваются двумя), каждый следующий раз подмешивая результаты предыдущего.
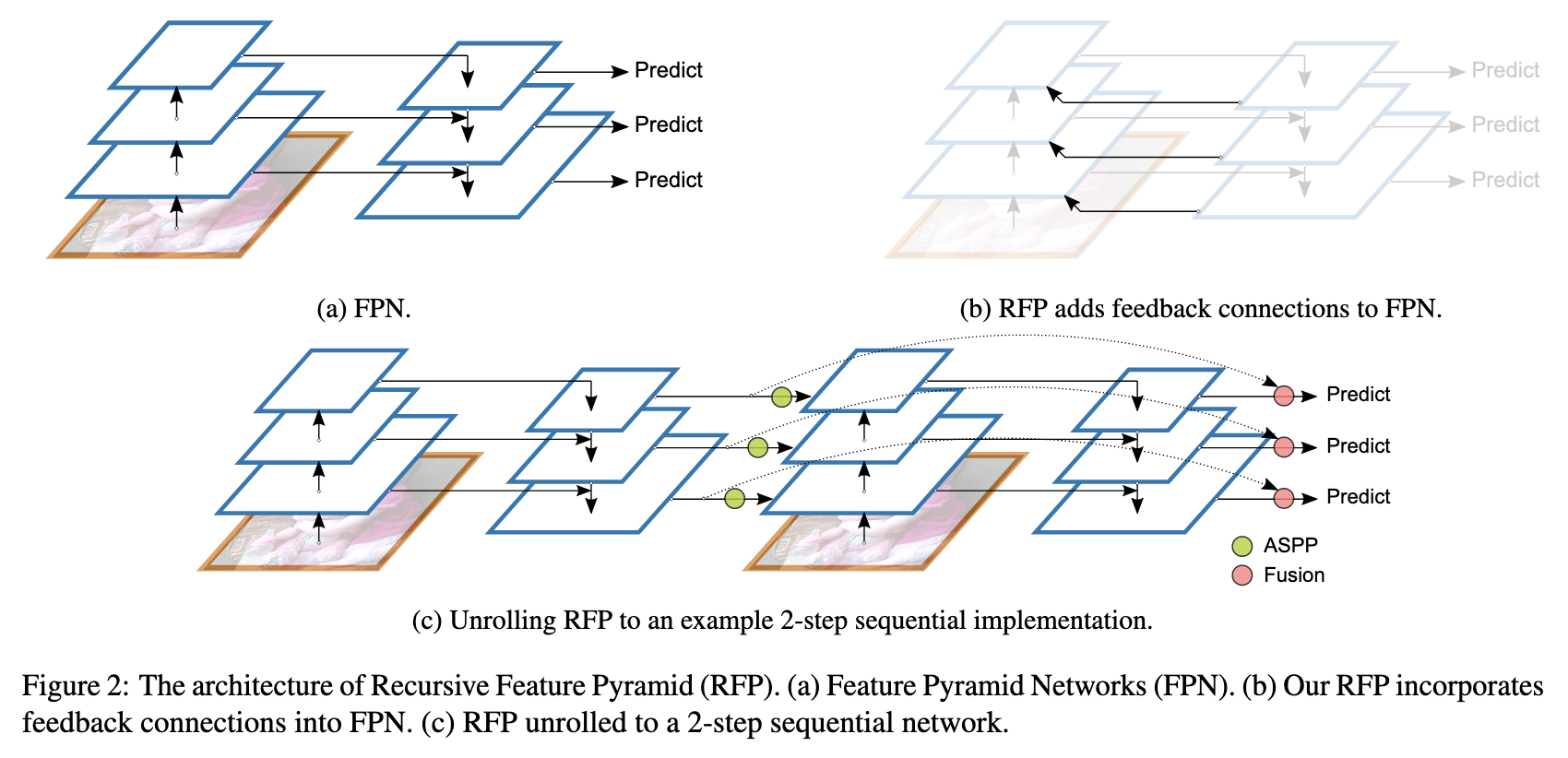
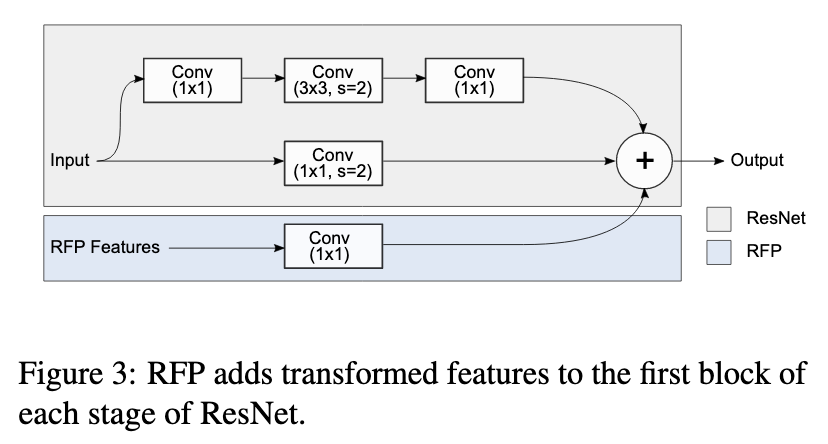
В частности, для каждой из 4 частей ResNet, в первый блок подмешиваются фичи, полученные по следующей схеме (Atrous Spatial Pyramid Pooling): фичи подаются на вход 4 блокам с выходом того же разрешения и ¼ каналов каждый, три из которых это конволюция (1 1, 3 3 c dilation 3, 3 3 c dilation 6) + ReLU, а последний это global average pooling + конволюция (1 1) + ReLU. Выходы конкатенируются и складываются с выходом первого блока.
Кроме того, на выходе фичи t+1-ой пирамиды смешиваются с фичами t-ой пирамиды с весами полученными через attention (σ).
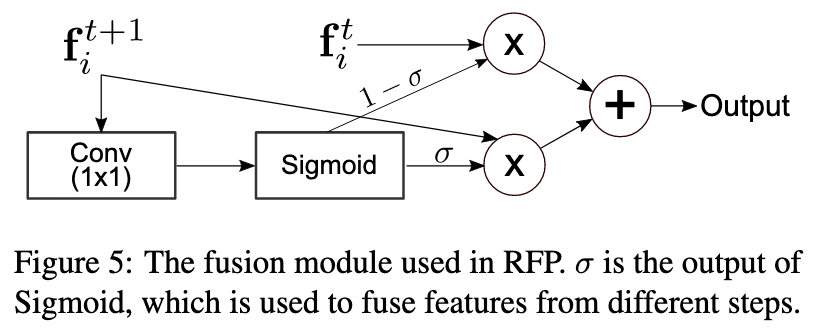
Switchable Atrous Convolution (SAC)
На уровне отдельных операций авторы предлагают заменить стандартные конволюцию блоком из двух конволюций с общими весами и разным dilation (на практике авторы выучивают разницу ∆w между весами, которая добавляет 0.1% к перформансу, но использование независимых весов все ломало). Эти конволюции складываются с весами, посчитанными еще одной 1×1 конволюцией. До и после конволюции авторы добавляют некий упрощенный аналог SE блока, но без нелинейности.
Как уже упоминалось, предложенный метод получает соту в detection, instance и panoptic segmentation. Авторы постарались повторить как можно точнее экспериментальный сетап HTC.
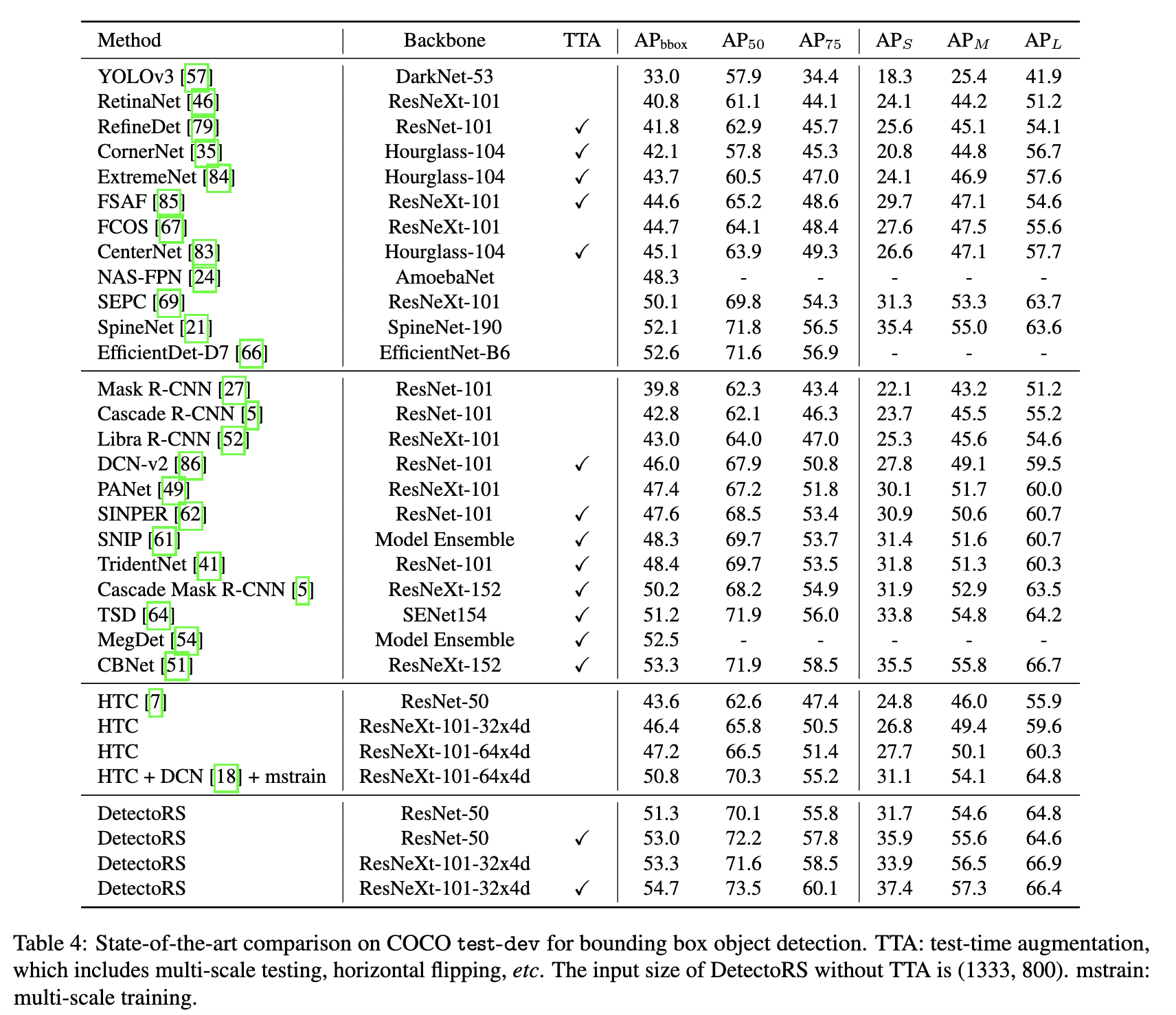
Также проведен подробный ablation study. RFP и SAC добавляют 4.2 и 4.3 к AP детекшна на ResNet-50 соответственно, вместе добавляя 7%. Так же проверены индивидуальные элементы RFP и SAC.
Авторы визуализируют веса конволюции c dilation 3 в блоке SAC. Они замечают что эта конволюция получает вес на больших объектах, в то время когда на малых больший вес у конволюции c dilation 1 (впрочем, судя по сотабенчу, AP на мелких объектах у DetectoRS несколько ниже чем у того же EfficientNet).

5. Training Generative Adversarial Networks with Limited Data
Авторы статьи: Tero Karras, Miika Aittala, Janne Hellsten, Samuli Laine, Jaakko Lehtinen, Timo Aila (NVIDIA, 2020)
Оригинал статьи
Автор обзора: Евгений Кашин (в слэке digitman, на habr digitman)
Работа от авторов stylegan, позволяющая использовать ганы, когда картинок мало. Основная идея — хитрое использование дифференцируемых аугментаций, без изменения лоссов или архитектуры. Добавив улучшения к StyleGAN2 показали сопоставимые результаты с на порядок меньшим количество данных (несколько тысяч).
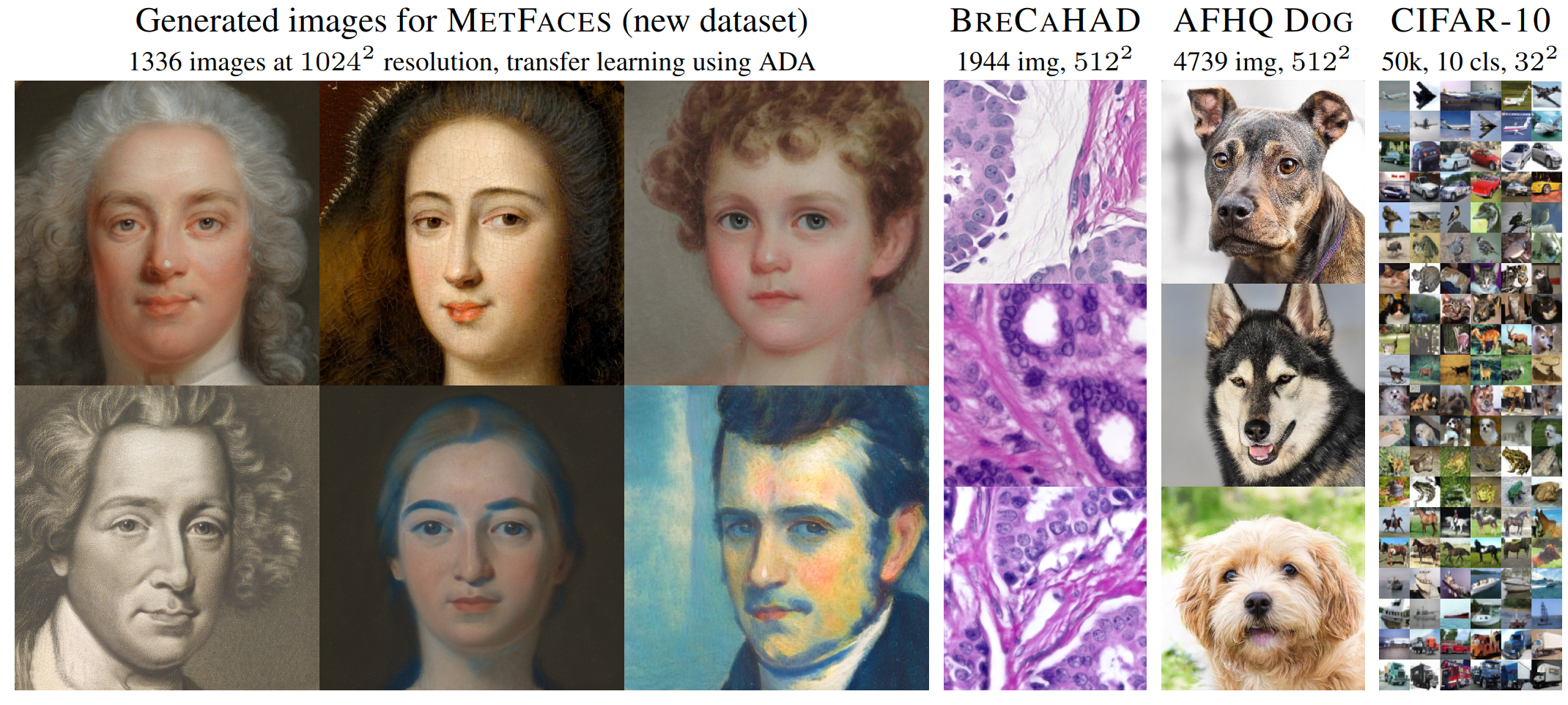
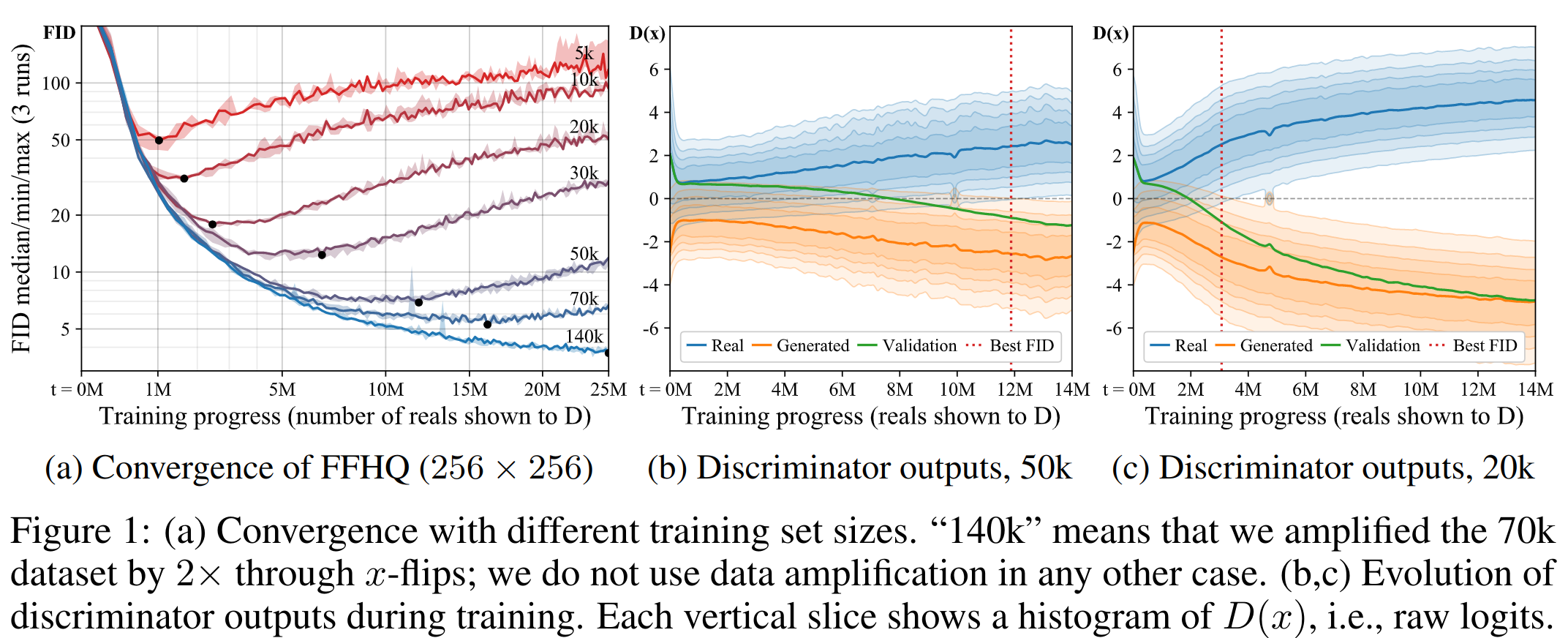
Проблема с маленькими датасетами — дискриминатор быстро переобучается. На больших датасетах это не является проблемой (как говорят в BigGAN — роль D прокидывать сигнал, а не обобщать). На графике ниже видно, как влияет объем данных на обучение, чем меньше — тем хуже Fréchet inception distance (FID). Сравнивая (b) и © видно, что на меньшем объеме, распределение выходов дискриминатора D очень быстро перестает пересекаться для real и fake, а распределение на валидационных данных становится близко к fake — оверфиттинг.
Простое применение на исходном датасете аугментаций не подходит для генерации изображений, т.к. тогда эти аугментации «утекают» и генератор начинает генерировать с этими аугментациями. Предложенная ранее Consistency regularization, суть которой в сближении выходов D для аугментированных и неаугментированных картинок, тоже приводит к утеканию аугментаций. Дискриминатор становится «слеп» к аугментациям и генератор этим пользуется.
Авторы предлагают использовать аугментации перед дискриминатором всегда. Для реальных и сгенерированных изображений. Получается D никогда не увидит реальных изображений. А генератор G должен генерировать такие семплы, которые после аугментаций будут выглядеть как настоящие картинки после аугментаций. Хорошо видно на 2(b).
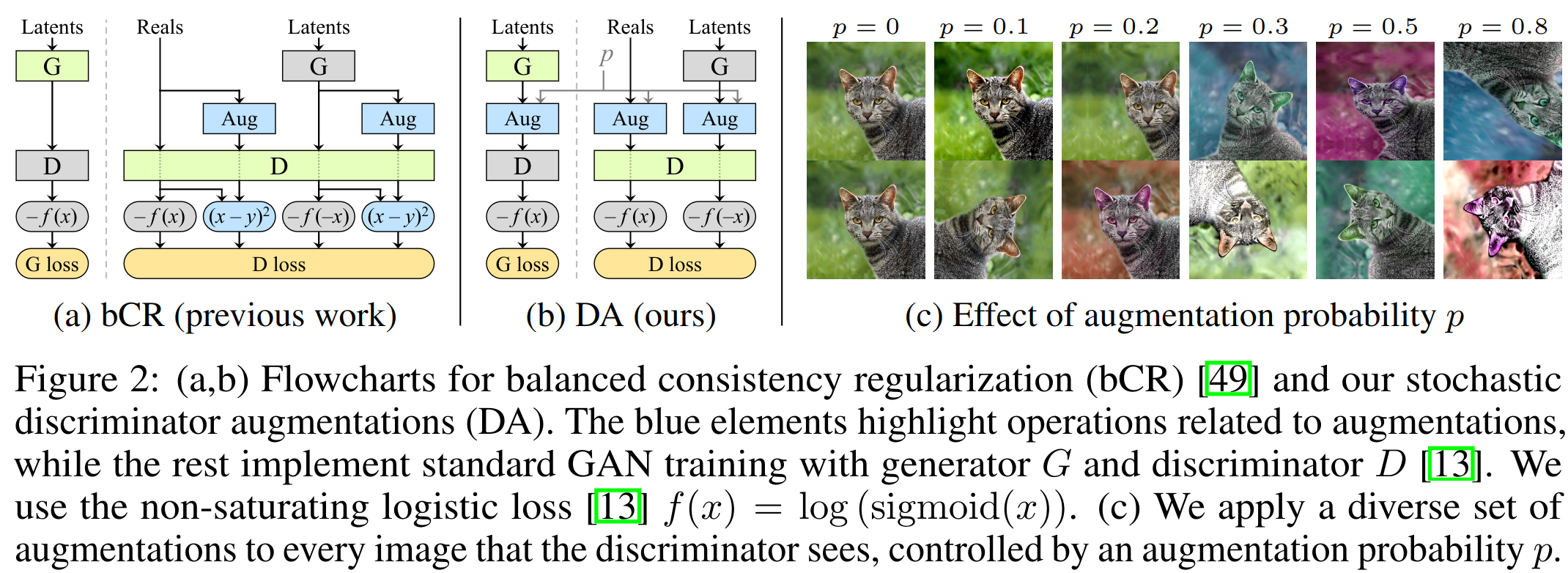
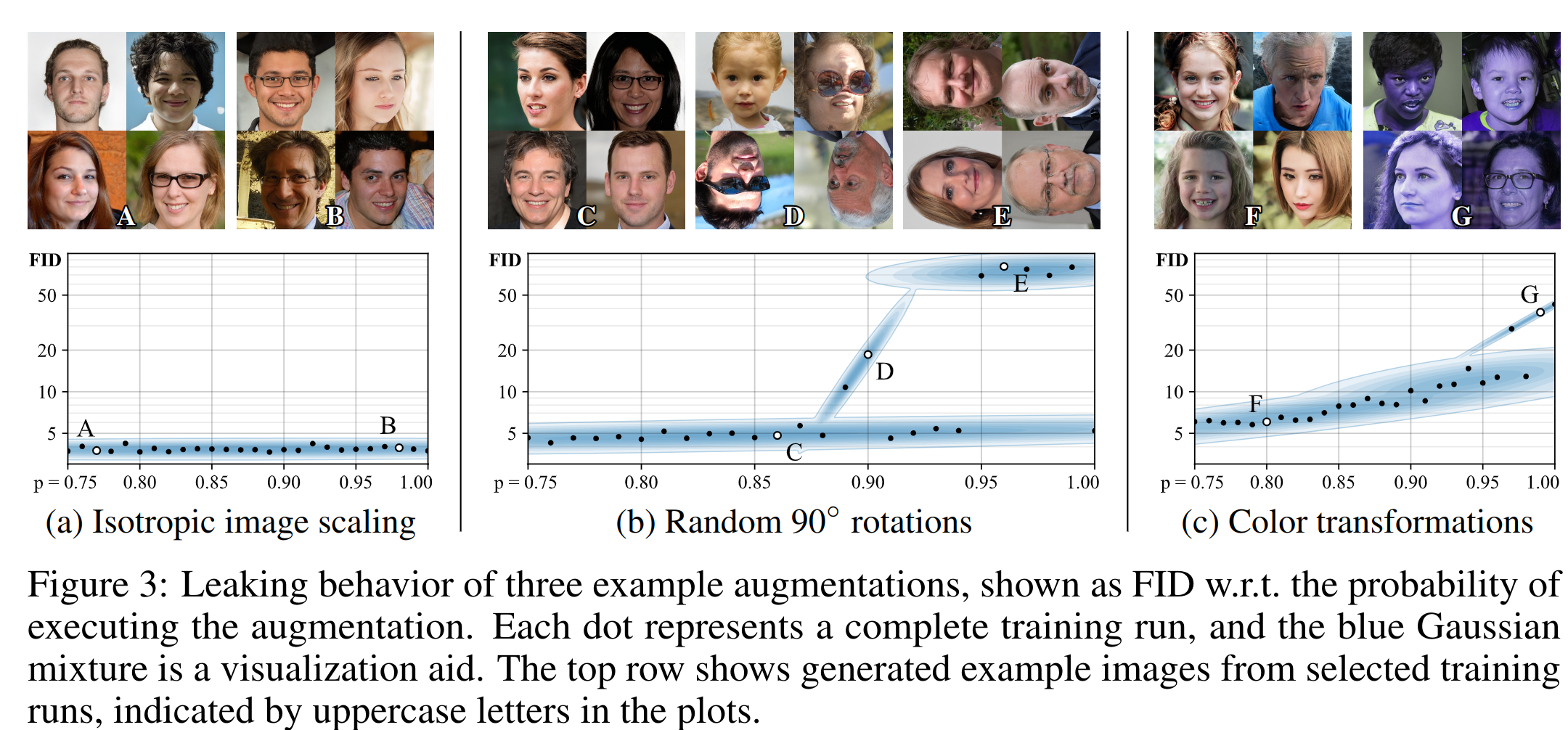
Самое интересное — не все аугментации подходят, а только те, которые генератор может неявно «отменить». Они называют их non-leaking. Но это не значит, что каждая отдельная аугментация должна быть отменяемой, а это больше про вероятностный смысл. Поэтому зануление 90% изображения отменяемая (применив его много раз случайно, можно догадаться, какое было исходное изображение), а случайный поворот на [0, 90, 180, 270] неотменяемый (после аугментации не угадать начальное положение картинки). Но многие аугментации становится возможно использовать, если применять их с вероятностью p < 1. Например, тот же случайный поворот, применяемый с p=0.5, будет чаще выдавать картинку в 0 градусов. Поэтому можно будет догадаться, какая картинка была до аугментаций(опять же, в вероятностном смысле, а не по одной картинке).
Они пробовали геометрические (повороты, смещения) и цветовые трансформации, добавление шума, cutout, частотные фильтрации. Важно, что т.к. аугментации используют после G и перед D в обучении, они должны быть дифференцируемые. Чаще всего композиция non-leaking аугментаций тоже non-leaking. Они применяют аугментации последовательно в одном порядке, каждую с равной для всех вероятностью p. Даже с небольшим значением p финальная картинка почти всегда будет аугментированной 2©. Поэтому в любом случае, генератору нужно стараться делать картинки максимально дефолтными, без аугментаций. Течет или нет аугментация также зависит от вероятности p. Примеры для отдельных аугментаций (зависимость от p).
Остается проблема, что для каждого датасета и объема данных надо было бы подбирать p. Поэтому они предложили это делать адаптивно, по эвристике, меряющей величину оверфиттинга. Два варианта эвристики (0 — не оверфиттинг, 1 — оверфиттинг):
- первая использует валидационный сет (неудобно): r_v = (E[Dtrain]-E[Dval])/(E[Dtrain]-E[Dgen]);
- вторая — только выход D (доля положительных выходов D): r_t = E[sign (Dtrain)].
Каждые 4 батча обновляют значение величины аугментаций p по выбранной эвристики. Если эвристика показывает, что сильное переобучение, то прибавляют p, и наоборот. Назвали adaptive discriminator augmentation (ADA).
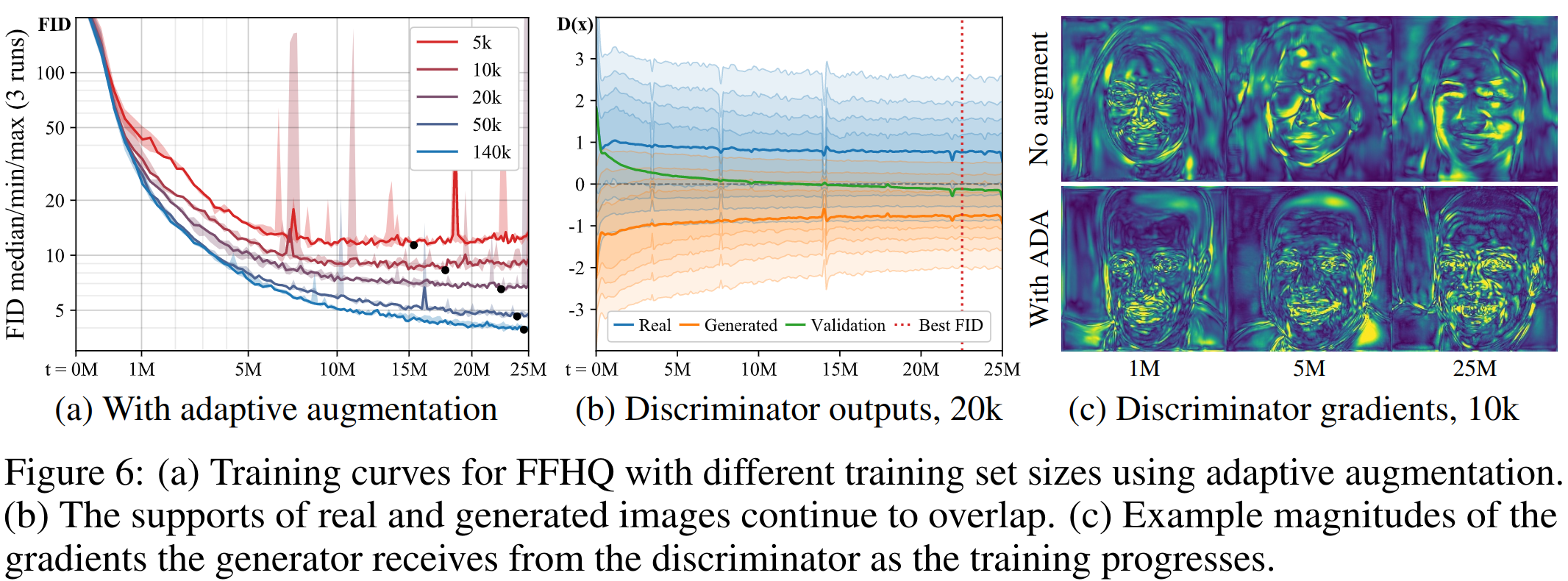
Видно, что по сравнению с первым изображением, использование ADA уменьшает оверфиттинг со временем, а градиенты в G становятся четче.По метрикам и визуально результаты лучше, чем у бейзлайнов на разных по объему датасетах. Их sample-efficiency позволяет применять StyleGAN2 на новых доменах с всего лишь 1к картинок.
Также показали, что можно использовать их метод для transfer learning. Он значительно ускоряет процесс обучения и вероятность что-то вообще выучить.
Предобученные веса на FFHQ. Кода нет, но есть псевдокод для используемых аугментаций.
6. Multi-Modal Dense Video Captioning
Авторы статьи: Vladimir Iashin, Esa Rahtu (Tampere University, Finland, 2020)
Оригинал статьи :: GitHub project
Автор обзора и статьи: Владимир Яшин (в слэке vdyashin)
Что такое (Dense) Video Captioning?
Начнем с того, что такое Video Captioning. У нас есть видео и наша задача описать текстом, что происходит на видео. Проблема с таким подходом в том, что сложно описать одним предложением 120 минутный фильм. Поэтому подход сейчас состоит в том, чтобы находить «интересные» моменты на видео, а потом описывать только их. Отсюда и название Dense Video Captioning.

Что нового мы предлагаем?
Давайте подумаем как человек воспринимает информацию с видео. Мы ведь не только смотрим на картинку, но еще и слушаем аудио. А если плохо знаем иностранный язык, то еще включаем субтитры. Несмотря на это, бОльшая часть предыдущих работ использует только визуальную информацию. А те, кто использует аудио или субтитры, показывают слабые результаты или используют датасеты, где субтитры довольно точно описывают, что происходит на видео (типа «How to do …»). В нашей работе мы показываем важность дополнительных модальностей (аудио и речь) на датасете с открытым domain в решении задачи Dense Video Captioning.
Метод
Как обычно подходят к решению задачи Dense Video Captioning? Сначала тренируют event localization модуль, а потом используют seq-to-seq модель для генерации описания для каждого из предсказанных временных интервалов.
Event Localization
Event localization можно представить как детектор на картинках только по времени. В качестве event localization модуля мы взяли ранее представленную двунаправленную LSTM, которая за первый проход (forward) для каждой фичи в последовательности накидывает anchors и выдает уверенность в том, что event там есть. Так как LSTM аккумулирует только предыдущую информацию, используется еще и обратный проход по фичам (backward). Опуская детали, получаем много возможных временных интервалов (proposals), из которых выбираем наиболее уверенные и используем их дальше для генерации описания.
Caption Generation
Этот модуль принимает на вход фичи, соответствующие временному интервалу. В нашем случае фичи из I3D, VGGish и тренируем текст эмбеддинг для речи. В качестве seq-to-seq модели, взяли ванильный трансформер.
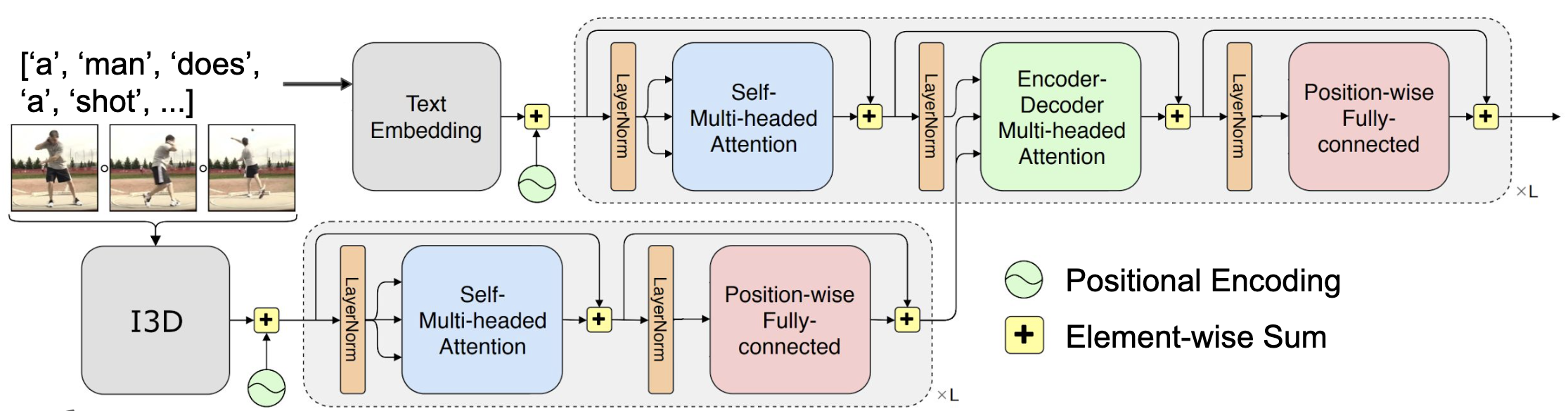
Каждый трансформер выводит внутреннее представление декодера, которое используется для моделирования распределения для следующего слова.
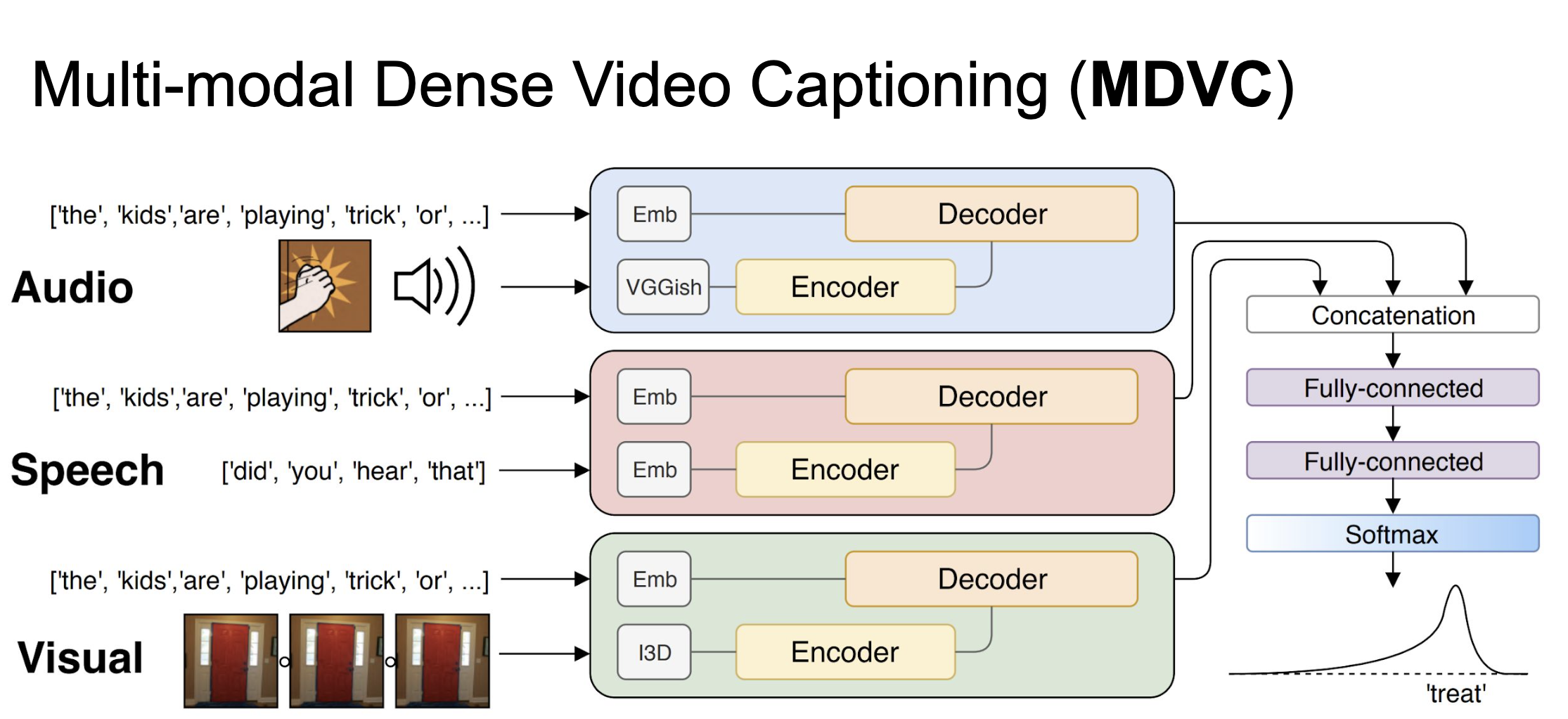
Эксперименты и что получилось
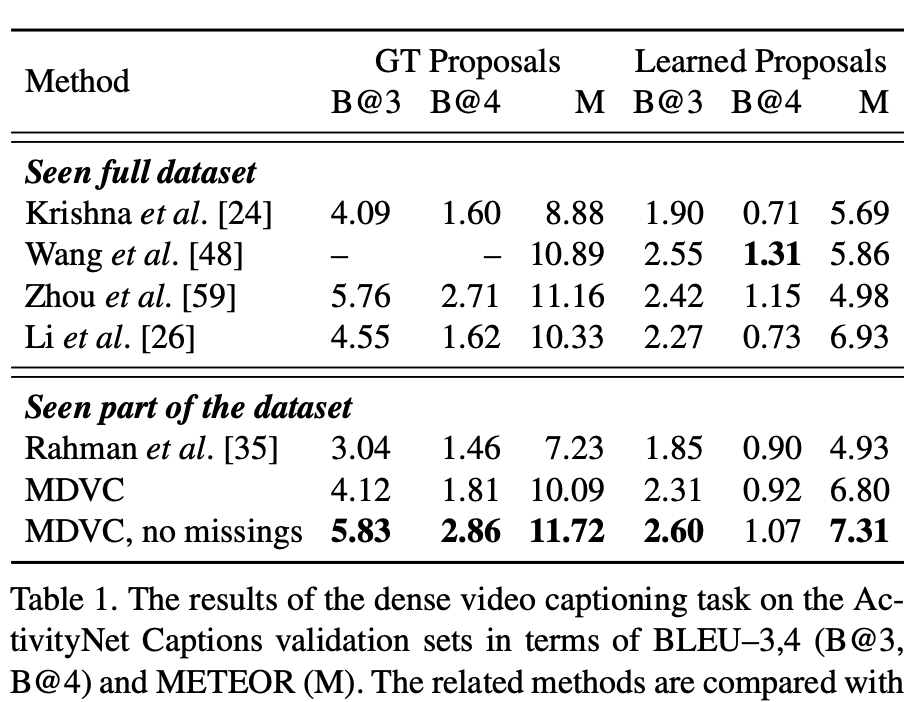
В качестве датасета использовали ActivityNet Captions. Сравнивали с другими ребятами и получили, что наш метод, как минимум, так же хорош как и СОТА при этом мы тренировались только на 90% от датасета, потому что 10% уже удалились с ютюба (см. таблицу). Можно еще посмотреть на черрипикнутый примерчик в статье.
Что забрать с собой домой
- Используйте дополнительные модальности, когда работаете с видео и хотите результат получше.
- Несмотря на хорошие результаты, вообще, конечно, пока такие методы довольно плохо работают на практике и остаются в рисерче, впрочем, как и большинство рисерча в анализе видео пока что.
От автора обзора про библиотеку: мне показалось мало и я решил начать делать небольшую либку для рассчета фичей для видео. Что классного в либке? То что можно взять список видео в формате .mp4 и запараллелить на всех GPU что у вас есть, и пойти слак дальше читать. Пока поддерживается только I3D (с PWC-Net для optical flow) и VGGish модельки.
7. Are we done with ImageNet?
Авторы статьи: Lucas Beyer, Olivier J. Hénaff, Alexander Kolesnikov, Xiaohua Zhai, Aäron van den Oord (DeepMind, 2020)
Оригинал статьи :: GitHub project
Автор обзора: Евгений Желтоножский (в слэке evgeniyzh, на habr Randl)
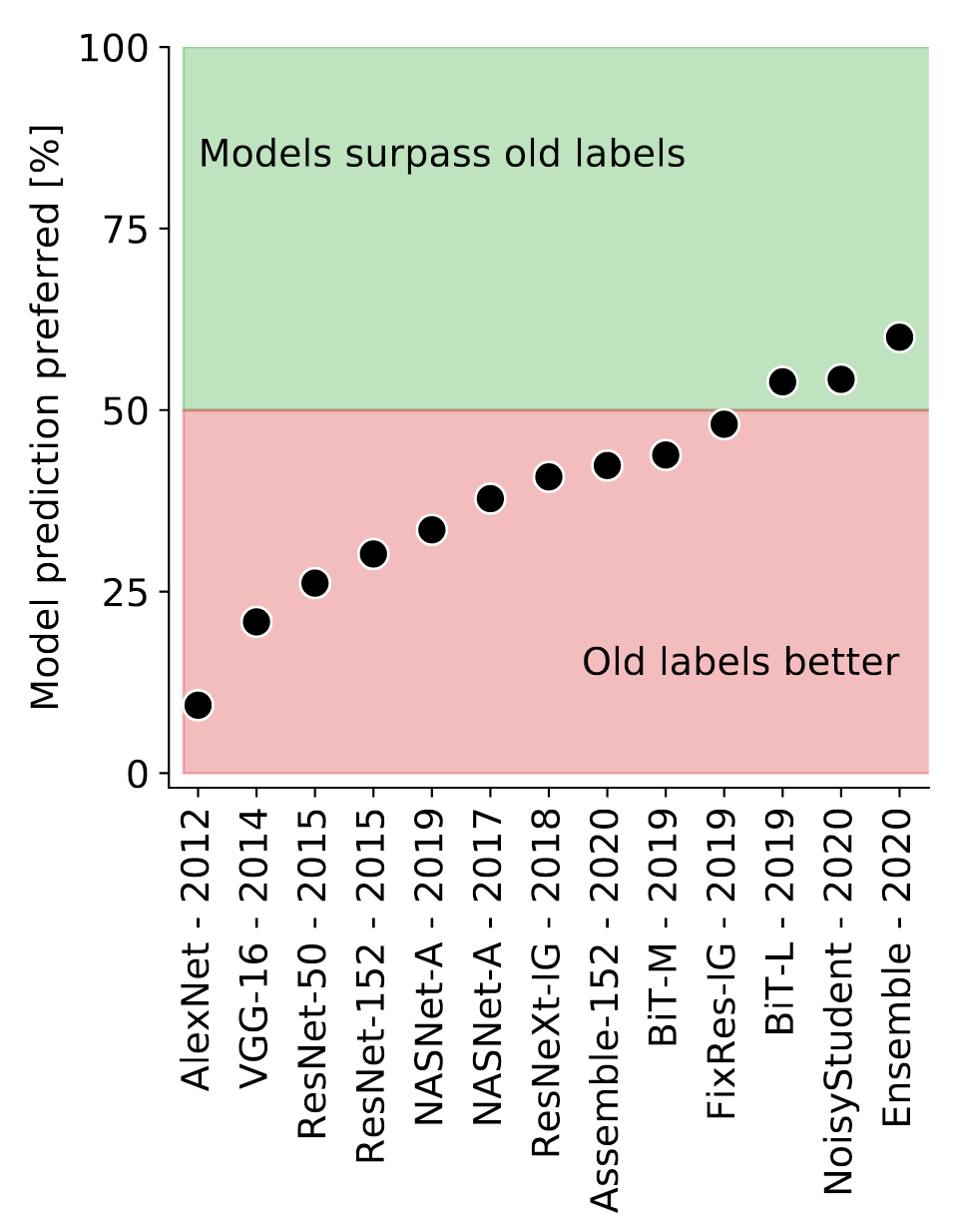
Авторы задают вопросы: «есть ли смысл выжимать 0.1% на имеджнете за 10 миллионов GPU-часов», «насколько хорошо обобщаются новые модели на ImageNet и насколько мы просто оверфиттимся на лейблы»? В частности предлагается новая разметка валидации ImageNet, показывается что люди предпочитают предсказания сетей оригинальным лейблам.
Какие вообще проблемы есть у лейблов ImageNet?
- Один лейбл на изображение, где иногда больше чем один объект.
- Процесс предложения лейблов сильно ограничивает разметчиков: их спрашивают есть ли объект на картинке, хотя иногда есть более подходящий лейбл.
- Есть практически дублирующие классы: «sunglasses» и «sunglass», «laptop» и «notebook», или «projectile, missile» и «missile».

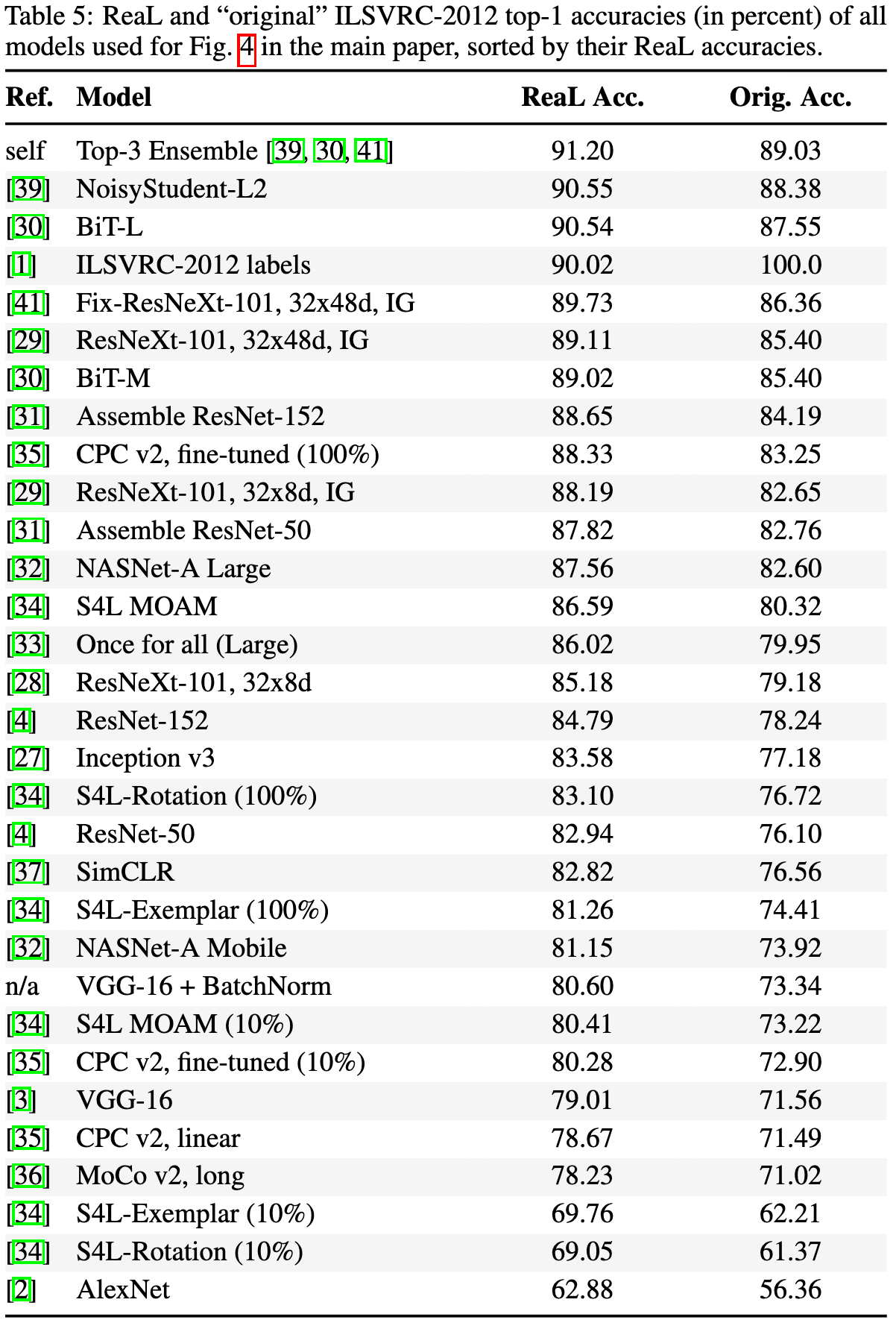
Авторы начинают со сбора вероятных лейблов для каждого из валидационных изображений. Для этого они взяли 19 моделей (VGG-16; Inception v3; ResNet-50; ResNet-152; ResNeXt-101, 32×8d; ResNeXt-101, 32×8d, IG; ResNeXt-101, 32×48d, IG; BiT-M; BiT-L; Assemble ResNet-50; Assemble ResNet-152; NASNet-A Large; NASNet-A Mobile; Once for all (Large); S4L MOAM; CPC v2, fine-tuned; CPC v2, linear; MoCo v2, long; SimCLR). Для каждой модели и каждой пары картинка-лейбл посчитали логит и вероятность. Взяли 150000 самых больших логитов и самых больших вероятностей. После этого выкинули пары, которые предложила только одна модель. Добавили топ-1 предикт каждой модели и оригинальный лейбл из ImageNet. Чтобы уменьшить количество пропозалов, 256 картинок разметили 5 экспертов, и оставили только модели которые дали Recall выше 97% (VGG-16; Inception v3; BiT-M; BiT-L; CPC v2, fine-tuned), уменьшив среднее количество лейблов на картинку с 13 до 7.4.
Далее, лейблы по которым не все модели были согласны (а таких было 24 889) переразметили люди. Картинки для которых было слишком много пропозалов (больше 8), разбили на несколько заданий, получив в итоге 37 998 задач. Каждую задачу решило 5 независимых экспертов.
Для объединения предсказаний использовался метод, который оценивает качество разметчика с помощью maximum-likelihood. Для животных, где часто нужна экспертиза, оригинальный лейбл добавили как еще одного виртуального разметчика. В итоге, получили 57 553 лейблов для 46 837 картинок, оставшиеся картинки выкинули. Эти лейблы назвали «ReaL labels» и использовали для оценки моделей.
Для начала сравнили точность на оригинальных и на ReaL лейблах. Довольно явно выявилось 2 тренда: до ~81% коэффициент корреляции равен 0.86, а после — 0.51. Z-test на то, что коэффициенты разные дал p<0.001. Видимо, топовые модели начинают оверфититься на разметку ImageNet. Кроме того, топовые модели получили точность на ReaL лейблах выше чем оригинальные лейблы.
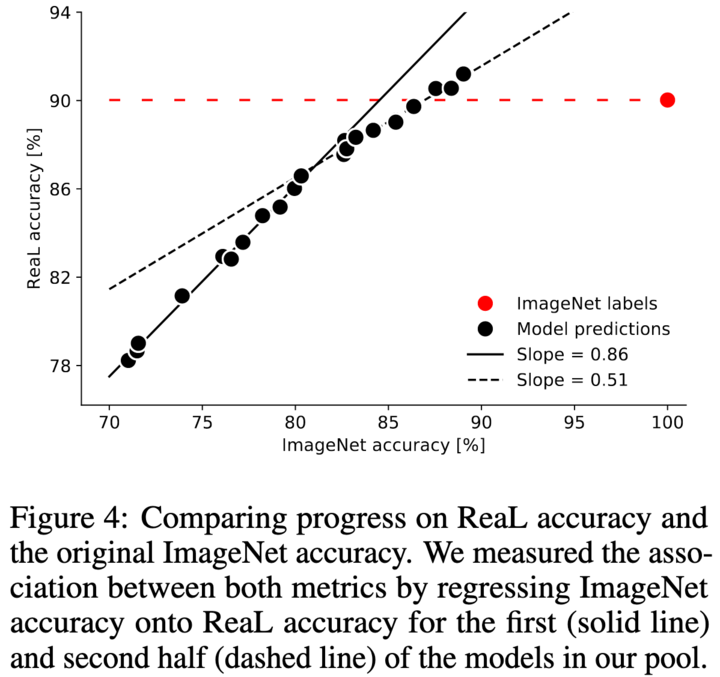
Чтобы подтвердить это утверждение, авторы взяли лейблы на которых модели не согласны с разметкой и спросили людей, какой лейбл больше подходит картинке. Топовые модели — BiT-L и NoisyStudent-L2 люди посчитали лучше оригинальной разметки. Также авторы взяли ансамбль трех топовых моделей: NoisyStudent-L2; BiT-L; Fix-ResNeXt-101, 32×48d, IG. Получили 89.03% на оригинальных лейблах и 91.20% на ReaL.
Заодно проверили, попадают ли топ-2 и топ-3 предикты в список допустимых лейблов. Точность второго и третьего предикта значительно ниже, но все равно довольно высока и коррелирует с точностью на ReaL.
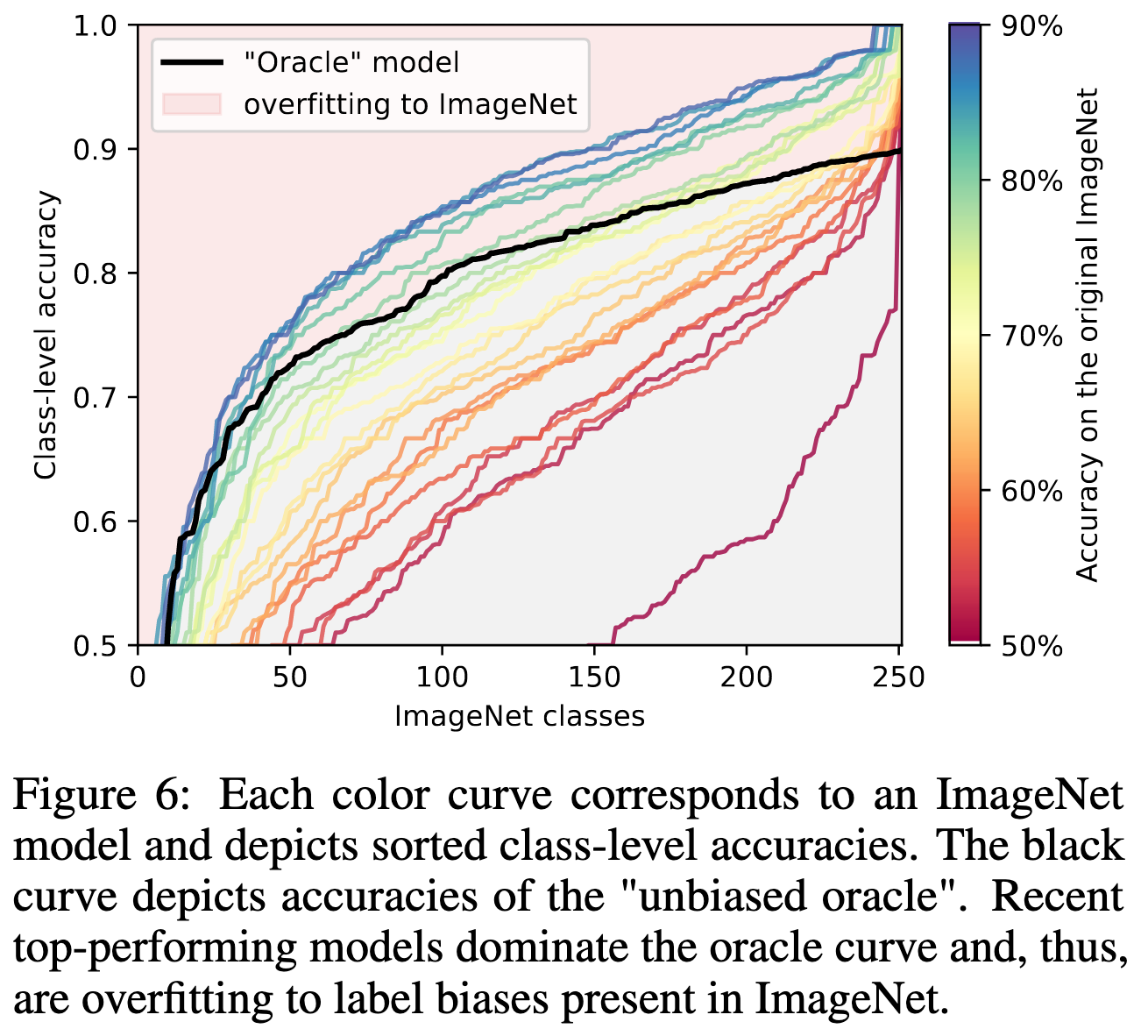
Следующий вопрос: как ведут себя модели на картинках с множественными объектами или одним из дублирующих лейблов? Предсказывается ли рандомно один из лейблов или модель выучивает bias разметчиков? Авторы выбрали неоднозначные классы как те, на которых оракул который предсказывает рандомный лейбл из ReaL получает меньше 90%. Таких классов получилось довольно много (253): часть неоднозначные: (sunglass, sunglasses), (bathtub, tub), (promontory, cliff), (laptop, notebook); часть часто находящиеся на одном изображении: (keyboard, desk), (cucumber, zucchini), (hammer, nail).
Топовые модели неслабо обгоняют оракула, что значит что они оверфитнулись на разметку.
Наконец, авторы анализируют ошибки топовых моделей. Для этого они опять опросили людей «является ли эта ошибка ошибкой?» В то время как количество настоящих ошибок падает с качеством модели, относительно обеих разметок. Тем не менее количество «не-ошибок» не особо зависит от модели и значительно ниже для ReaL.
По пути авторы попробовали улучшить трейнинг. Во первых, они заменили softmax на sigmoid. Во вторых на 10-fold с помощью BiT-L почистили трейнинг сет (дропнув ~10% лейблов). Получили улучшение на 0.5–2% относительно baseline.
Результаты разных моделей на оригинальной и ReaL валидациях в таблице ниже.