Рубрика «Читаем статьи за вас». Декабрь 2017 — Январь 2018

Привет, Хабр! Продолжаем публиковать рецензии на научные статьи от членов сообщества Open Data Science из канала #article_essense. Хотите получать их раньше всех — вступайте в сообщество!
Статьи на сегодня:
- LightGBM: A Highly Efficient Gradient Boosting Decision Tree (Microsoft Research, NIPS 2017)
- Deep Watershed Transform for Instance Segmentation (University of Toronto, 2017)
- Learning Transferable Architectures for Scalable Image Recognition (Google Brain, 2017)]
- AdaBatch: Adaptive Batch Sizes for Training Deep Neural Networks (University of California & NVIDIA, 2017)
- Density estimation using Real NVP (University of Montreal, Google Brain, ICLR 2017)
- The Case for Learned Index Structures (MIT & Google, Inc., NIPS 2017)
- Automatic Knee Osteoarthritis Diagnosis from Plain Radiographs: A Deep Learning-Based Approach (Nature Scientific Reports, 2017)
- Октябрь — Ноябрь 2017
- Сентябрь 2017
- Август 2017
1. LightGBM: A Highly Efficient Gradient Boosting Decision Tree
Авторы статьи: Guolin Ke et. al., Microsoft Research, NIPS 2017
→ Оригинал статьи
Автор обзора: Федор Шабашев (@f.shabashev в слэке)
LightGBM позиционирует себя как библиотека для быстрого обучения бустинговых моделей и недавно разработчики lightGBM опубликовали на NIPS статью в которой описали две эвристики помогающие обучать бустинг на деревьях быстрее. Обе эвристики были реализованы в lightGBM примерно 6 месяцев назад.
Gradient-based One-Side Sampling (GOSS) — эвристика заключается в том чтобы на каждом шаге бустинга субсемплировать объекты с маленькими градиентами. То есть считается градиент на каждом объекте, объекты сортируются по убыванию абсолютного значения градиента, далее для построения следующего дерева берется только top N объектов с самым большим градиентом и субсемпл остальных объектов.
Как утверждают авторы эта эвристика позволяет сократить время обучения в 2 раза при незначительном ухудшении качества модели.
Включается эта эвристика выставлением параметраboostingравнымgoss. GitHub docs- Exclusive Feature Bundling (ERF) — эвристика заключается в том чтобы склеить несколько sparse признаков в один.
Таким образом, еще до построения первого дерева, берется несколько признаков вида:
(1, 1, 0, 0, 0, 0)
(0, 0, 0, 1, 1, 0)
(0, 0, 0, 0, 0, 1)
и преобразуется в один признак вида:
(1, 1, 0, 2, 2, 3)
После такой склейки вычисление оптимального сплита будет идти быстрее, так как признаков станет меньше.
Как утверждают авторы, эта эвристика тоже дает значительное ускорение на некоторых датасетах.
Насколько я понимаю ERF включена по умолчанию. GitHub config. Поэтому если sparse фичей в датасете нет, то может быть полезно ее выключить.
2. Deep Watershed Transform for Instance Segmentation
Авторы статьи: Min Bai, Raquel Urtasun, University of Toronto, 2017
→ Оригинал статьи
Автор обзора: Владимир Игловиков (тут и в слэке ternaus)
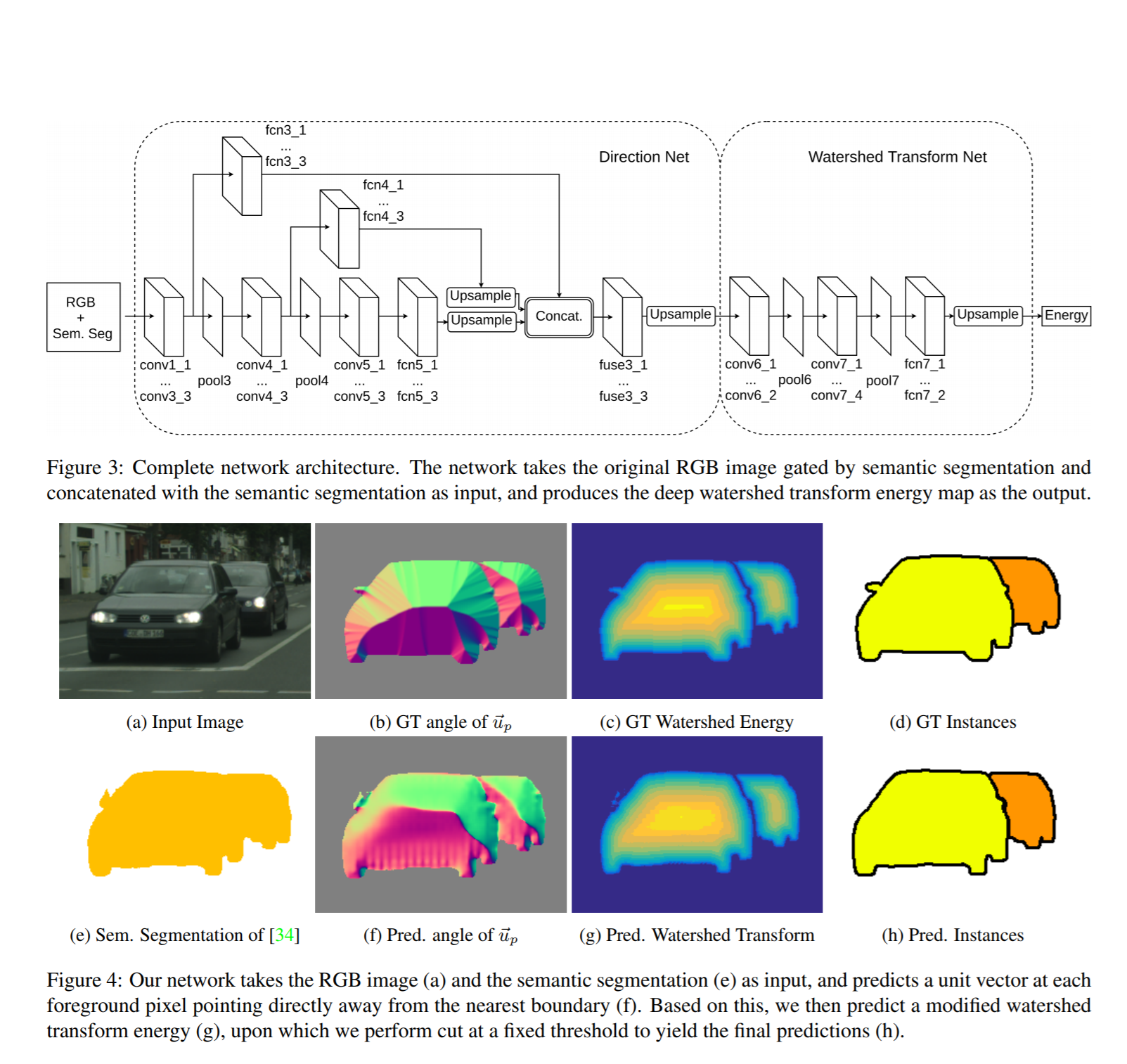
Статья пытается решить вот такую задачу: пусть у нас есть картинки причем не важно, grayscale, RGB, спутники, еще что-то. И есть бинарные маски, которые выделяют какой-то тип объекта, то есть задача Semantic Segmentation уже решена.
Теперь хочется порезать бинарную маску на отдельные объекты. То есть сделать именно то, на чем надавние победители Urban3d (albu, @selim_sef, Victor) во многом и вырвали победу и деньги у гусей. Пусть есть вот такое предсказание домиков на спутниковом снимке (зеленое — предсказанная маска)

В статье предлагается некий фреймворк, который как раз и позволяет применить watershed transform, но в более интеллектуальном end2end Deep Learning режиме.
Итак, шаги, которые они осуществляют:
- Бинарная маска, которая у нас есть, прилепляется четвертым каналом на вход (возможно без этого можно обойтись).
- По бинарной маске NxN создается векторное поле, где каждому пикселю сопоставляется unit vector, который по градиенту от distance transform направлен к ближайшей границе. Представляется как матрица (2xNxN)
- Тренируется некая сеть (думаю, что архитектуру можно 100500 раз улучшить, но это не суть), которая берет на вход 4 канала (RGB + binary mask), а на выход идет посчитанное в п.2
- Для каждой маски делается watershed transform и находится уровень отсечки (Energy level) которые позволяет исходную маску побить на инстансы.
- Тренируется вторая сеть, которая на вход берет п.2, то есть выход из п.3, а на выходе осуществляет классификацию, целью которой является предсказание бинаризированного уровня энергии из п.4.
В общем, если по простому, то ребята предложили нейросетевой способ осуществлять бинаризацию watershed transform.
- и, это они молодцы, сделали сабмит на Instance Segmentation на CityScapes — там у них шестое место на LB.
В приницпе все это действо, то есть
- сегментацию
- предсказание векторного поля
-предсказание уровня энергии
можно собрать в один пайплайн, да еще и шаринг фич агрессивный устроить (Типа как Faster RCNN встал на плечи Fast RCNN) и получить достаточно сильную и скорее всего шуструю модель
3. Learning Transferable Architectures for Scalable Image Recognition
Авторы статьи: Barret Zoph, Vijay Vasudevan, Jonathon Shlens, Quoc V. Le. Google Brain, 2017
→ Оригинал статьи
Автор обзора: Максим Лашкевич (тут BelerafonL, в слэке belerafon)
В-общем, они делают мета-учителя для поиска самой оптимальной архитектуры для распознавания изображений: типа LSTM у них генерит архитектуру, они эту архитектуру с нуля обучают распознавать картинки, а получившую точность используют как награду для RL алгоритма, который учит эту самую LSTM. И получили этим самым стейт-оф-арт на имейджнете.
В общем, они говорят — обучать такую штуку сразу на имейджнете нереально, потому как чтобы RL алгоритм что-то там выучил, нужно десятки тысяч итераций, и позволить себе такое даже гуглу не под силу. Поэтому давайте обучать на CIFAR-10, только надо вот как-то потом распространить результат на имейджнет. Но как распространить на другой датасет сгенерированную архитектуру, которая вообще непонятно как работает и почему именно такая? Чтобы можно было это сделать, они вводят для мета-учителя определенные ограничения, чтобы он искал оптимальную архитектуру, но не абы какую, а чтобы она состояла из последовательных однотипных слоев (клеток, Cell): Normal Cell, которая предполагается как усложненная замена сверточному слою и должна выучивать какие-то фичи, и Reduction Cell, которая должна выполнять понижение размерности. И типа если такие оптимальные клетки будут найдены на CIFAR, то для имейджнета можно просто их настекать побольше и всё, работать должно типа тоже хорошо. И, как ни странно, это прокатило, и так и есть — рисунок показывает как они стекают клетки эти.

Ровно половину статьи занимают бенчмарки, как это всё получившееся хорошо работает. Что везде, значит, стейт-оф-зе-арт результаты, и на имейджнете, и на сегментации, и для мобильных сетей с малыми ресурсами, и что и точность выше получилась, и вычислений у этой сгенеренной сети меньше получается и волосы кучерявее. Я результаты приводить не буду, кому надо смотрите их таблички, я лучше расскажу, как работает генератор этой сети и что там зачем.
Значит, используют в качестве генератора простую однослойную LSTM в 100 нейронов в скрытом слое. На вход она не получает ничего (как я понял), просто с места плюется конфигурацией архитектуры (а точнее конфигурацией Normal Cell и Reduction Cell, а они уже стекаются потом заданное вручную кол-во раз).
Генерируют архитектуру клетки они блоками (см. рисунок): каждый блок содержит два входа и один выход (тензоры).
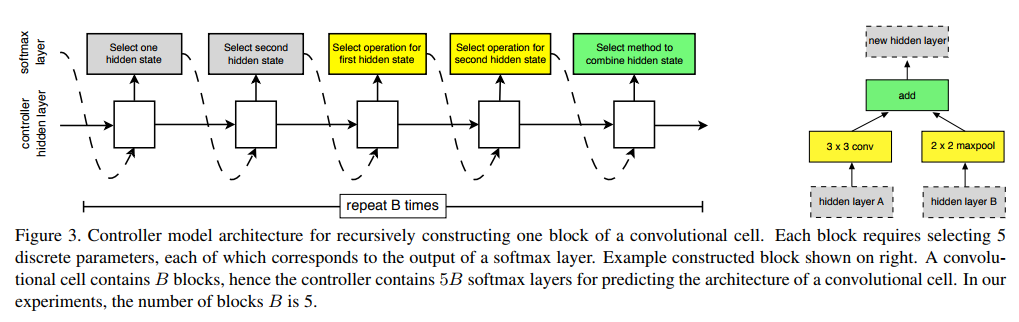
Для каждого входа генератор может выбрать по какой-то операции, которую берет из предопределенного набора, который они подобрали эмпирически из лучших традиций построения нейросетей (список рядом с первым рисунком), затем производится соединение результатов этих двух операций в один тензор, точно также выбираемой LSTM операцией.
Здесь эта операция может быть или сложение, или конкатенация. Получается у блока один выход. Этот выход добавляется в список доступных «входов» для следующего блока. И потом генерируется следующий блок. Таким образом, процесс генерации такой:
- Выбирается первый вход, с которым что-то делаем (для первого блока это может быть выход предыдущего слоя или слоя под ним, или входные данные, если это первый слой). Т.е. LSTM выдает софтмаксом номер, какой вход брать. И это и учится через RL.
- Точно также выбирается второй вход.
- Выбирается операция, что делать со входом 1 (из списка операций на картинке выше)
- Тоже самое для входа 2.
- Выбирается операция объединения результатов шагов 3 и 4, а получившийся выход добавляется к пуллу доступных входов для генерации следующего блока. Т.е. в пунктах 1 и 2 для следующего блока LSTM будет выбирать входы из списка, в который уже добавлен выход получившегося блока.
Таким образом, для генерации одного блока LSTM плюется пять раз. И таких блоков для каждого Cell они выбрали… тоже 5. Видимо, чтобы запутать с той 5, которая количество шагов генерации блока. Поэтому для генерации одной клетки LSTM плюется 25 раз. А так как надо сгенерить и Normal Cell, и Reduction Cell, то надо плюнуть еще в два раза больше. Они записывают это как формулу 2 × 5B, где B, гиперпараметр количества блоков, равен 5.
Так, результат наилучших сгенерированных Cell показан на рисунке.
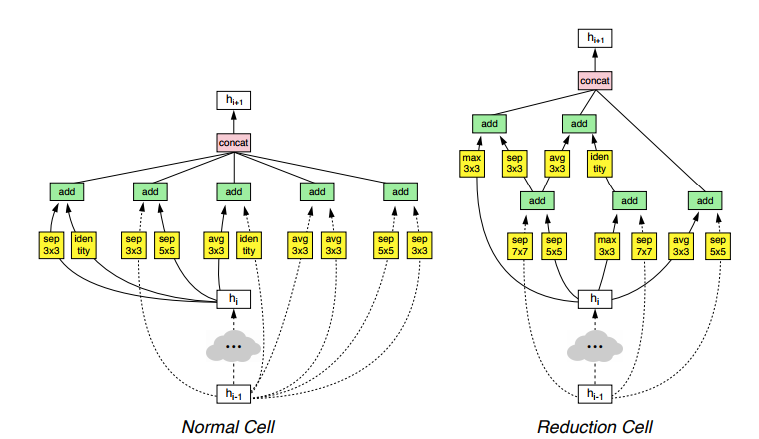
Почему так — спрашивайте у LSTM, она лучше знает. Но типа тут есть и мотивы residual соединений, и каких-то нетипичных для современных архитектур блоков и вообще ничего непонятно. Но работает хорошо для вообще разных сетей по распознаванию и сегментации изображений. Главное, настекать желаемое кол-во раз. Интересно, что это не единственные хорошие клетки, и есть другие, которые тоже работают хорошо, но визуально внутри совсем другие (есть там в приложении картинки других).
Также они сравнивают метод обучения. Типа спорно, что RL учит чему-то там лучше, чем random search, и поэтому они провели эксперименты с брутфорсом по подбору архитектуры и показали, что RL работает-таки лучше.

К слову, для RL они применяют Proximal Policy Optimization https://blog.openai.com/openai-baselines-ppo/. Учат они это добро на 500(!) GPU, где почти все они — это ведомые воркеры, которые проверяют сгенерированные LSTM архитектуры. Кол-во итераций (обученных нейросетей на CIFAR) — десятки тысяч.
Итог.
- Сам алгоритм мета-обучения оказался очень простой. По сравнению со всякими там альфа-go, тут одна худая LSTM и всё. Никакого рокет-саенс.
- Идея с тем, чтобы не генерить всю архитектуру, а генерить универсальные клетки, которые можно стекать, бесспорно, отличная и она и взлетела.
- Результаты на распознавании картинок афигенны, можно брать и юзать найденную архитектуру клеток в своих проектах распознавания картинок, должно работать.
- Повторить дома их результаты в силу необходимости 500ГПУ не представляется возможным, как и, впрочем, все остальные аналогичные гугловые работы.
4. AdaBatch: Adaptive Batch Sizes for Training Deep Neural Networks
Авторы статьи: A. Devarakonda, M. Naumov, and M. Garland, University of California & NVIDIA, 2017
→ Оригинал статьи
Автор обзора: Егор Панфилов (в слэке egor.panfilov)
Так сложилось, что при обучении DNN на маленьких батчах выше сходимость и находятся более качественные решения. Но вот только скоро лопнет пузырь Bitcoin, и на рынке появится много шального железа, которое хорошо бы уметь утилизировать для обучения в параллель (i.e., учить на больших батчах).
Авторы предлагают novel (лол) подход AdaBatch, в котором размер батча увеличивается в процессе обучения адаптивно. В некотором смысле, это эквивалентно использованию learning rate decay, однако, авторы показывают, что обе техники можно применять вместе.
Проверка идеи осуществлялась на VGG, ResNet, AlexNet на датасетах CIFAR-10, CIFAR-100, ImageNet. Сравнивали с аналогичными архитектурами, где batch size фиксирован.
На одной P100 на CIFAR-100 каждые 20 эпох применяли learning rate decay 0.75, а для адаптивного метода еще и повышали размер батча в 2 раза. В результате сеть с адаптивным batch size набрала такое же качество, как и с маленьким, но прямой и обратный проход происходили в среднем в 1.25, 1.15 и 1.46 раза быстрее (соотвественно, по архитектурам).
Следующим экспериментом смешали 4 P100-е и PyTorch.nn.DataParallel и разогнались до батчей 1024–16384 (использовали lr warmup (техника от Facebook, если помните) в начале, после — lr decay 0.5 и удвоение батча каждые 20 эпох). По результатам — опять достигли качества, аналогичного обучению с фиксированным батчем 128, но в 3.5 раза быстрее для VGG19 и 6.2 раза быстрее для ResNet-20.
Хотели еще замерять на ImageNet, но в видеокартах кончилась память на батче в 512, и авторы решили аккумулировать градиенты (прогоняя батчи один за одним, и только потом применяя backprop). Понятное дело, что ускорение обучения в таком раскладе измерить затруднительно, но по точности сравнить можно. AdaBatch с начальным батчем в 4096 и конечным 16384 показывает опять же соизмеримые результаты с обучением на фиксированном 4096.
5. Density estimation using Real NVP
Авторы статьи: Laurent Dinh, Jascha Sohl-Dickstein, Samy Bengio. University of Montreal & Google Brain, ICLR 2017
→ Оригинал статьи
Автор обзора: Артур Чахвадзе (в слэке @nopardon)
Иногда хочется моделировать сложные распределения, из которых просто получить выборку и у которых можно эффективно считать плотность в точке. Например, такая задача возникает при обучении глубоких байесовских сетей, где от гибкости вариационного распределения зависит точность оценки обоснованности.
Существует два основных подхода к этой задаче. Авторегрессионые модели, такие как MADE, NADE, PixelRNN, PixelCNN, и тд. раскладывают совместное распределение p (x1, x2, x3, …) на произведение условных p (x1)p (x2|x1)p (x3|x2, x1)… Они позволяют моделировать весьма гибкие семейства, но плохо масштабируются на данные высокой размерности, поскольку сложность семплирования пропорциональна размерности случайной величины.
Альтернативный подход основан на формуле замены переменных: если случайная величина z с плотностью p (z) преобразуется некоторой обратимой функцией f, плотность f (z) равна p (z)/|det J|, где J — якобиан f.
Нормализующие потоки используют этот факт чтобы строить сложные распределения, применяя последовательность обратимых функций к нормально распределенному шуму. Основная проблема подхода — рассчет якобиана в общим случае требует O (n^2) операций, что недопустимо для данных высокой размерности. Первые предложенные потоки, планарный и радиальный, имеют очень простую форму и позволяют посчитать определитель якобиана явно за линейное время, однако, для получения сложного распределения необходима очень длинная цепочка таких преобразований.
Inverse Autoregressive Flows используют отображения вида z → z + f (z), где f — нейронная сеть с авторегрессионной структурой, то-есть выход f (z)[i] зависит только от z[j] с j < i. Якобиан такого преобразования — нижнетреугольная матрица c единицами на диагонали и его определитель равен единице. На практике, к сожалению, оказывается что из-за авторегрессионной структуры сети, такие преобразования не так эффективны, как хотелось бы.
Авторы статьи предлагают использовать сеть, состоящую из «сдвоенных слоев». Каждый «сдвоенный слой» обратимо переводит n-мерный входной вектор X в n-мерный вектор Y. Сначала элементы вектора X разделяются на два множества — X_a и X_b. X_a без изменений отображается в себя: Y_a = X_a. На X_b слой действует аффинным преобразованием, параметры которого задаются частью X_a: Y_b = X_b * exp (scale (X_a)) + shift (X_a), где scale и shift — произвольные нейронные сети. Якобиан такого отображения имеет блочно-треугольную структуру, причем диагональные блоки являются диагональными матрицами. Предложенные слои позволяют моделировать очень сложные распределения (например, распределение лиц) и не требуют сетей вроде MADE или PixelCNN в качестве авторегрессионных функций
Стал разбираться подробнее, оказывается, авторы публиковали статью с почти той-же идеей еще в 2014 году. При этом в статье про Normalizing Flows пишут что планарный поток работает лучше. Видимо, RealNVP/NICE начинает нагибать когда размерность большая и можно эксплуатировать структуру в данных, например, сверточными сетями.
Что касается IAF, мне пришлось в свое время долго ковырять MADE палкой чтобы получилось лучше чем хотя-бы Housholder Flow, который, вообще-то, линейный.
А вот тут RealNVP используется чтобы распределения на веса параметризовать. На мнисте вроде работает.
6. The Case for Learned Index Structures
Авторы статьи: Tim Kraska, Alex Beutel, Ed H. Chi, Jeffrey Dean, Neoklis Polyzotis. MIT & Google, Inc., NIPS 2017
→ Оригинал статьи
Автор обзора: Евгений Васильев (в слэке evgenii.vasilev)
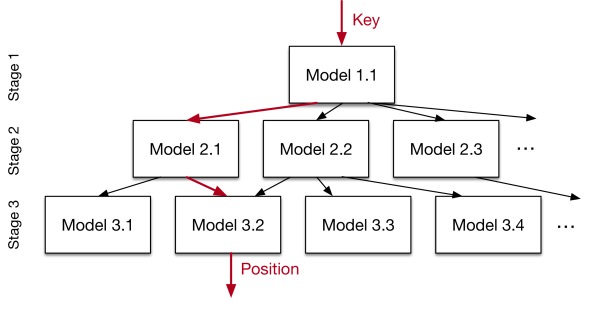
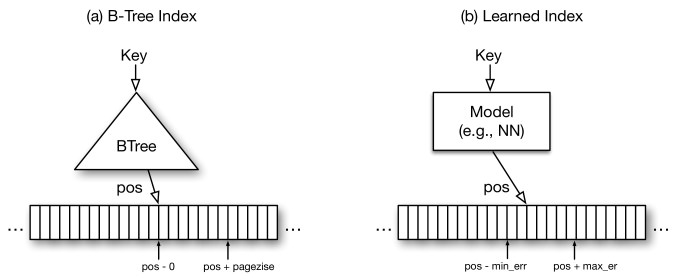
Подходы к индексации данных давно уже более менее устаканились, но ребята из гугла считают что пошатав нейросети улучшить можно всё и в данном случае у них кажется получается. Индексацию данных по сути можно свести к ML проблеме, есть вход — ключ и нужно предсказать его расположение в отсортированной таблице. Сначала они пробуют решить проблему в лоб и скормить все это одной сети, но выясняется что это затратно и не оптимальнее B-Tree, с которой они сравнивают модель. Вместо этого они предлагают «рекурсивную регрессионную модель», которая по сути представляет из себя иерархию из очень простых нейронных сетей. Верхний слой берет ключ и предсказывает которой модели из нижнего слоя отдать этот ключ дальше на предсказание, а самая нижняя модель уже предсказывает позицию в таблице. Эту систему можно так же миксовать с B-Tree, заменив самые нижние модели предложенной рекурсивной модели, которые предсказывают непосредственную позицию ключа в таблице на B-Tree что по их мнению должно дать ускорение. Они сравнили разные архитектуры B-Tree и двухуровневой рекурсивной модели. В предлагаемой ими модели архитектура нейронки подбиралась гридсерчем из 0–2 слоев по 4–32 нейрона. Бенчмарки делали на трех разных датасетах с размером от 10 до 200 м значений и система построенная на ML оказалась 3х быстрее и занимала в разы меньше места. Они так же попроовали сравнить новую систему с Хэш-таблицей и фильтром Блума (проверка наличия ключа в таблице), где она оказались примерно такой же по скорости как и классические модели, но занимала немного меньше места. Самое интересное что все бенчмарки были сделаны на CPU. Авторы считают что с GPU/TPU возможности по улучшению огромные и дают много идей для дальнейшего рисерча. В целом советую почитать статью, она очень хорошо написана.
7. Automatic Knee Osteoarthritis Diagnosis from Plain Radiographs: A Deep Learning-Based Approach
Авторы статьи: Aleksei Tiulpin, Jérôme Thevenot, Esa Rahtu, Petri Lehenkari, Simo Saarakkala. Nature Scientific Reports, 2017
→ Оригинал статьи
Автор обзора: Aleksei Tiulpin (в слэке lext)
Чего тут особенного кроме высокого импакта журнала.
- Впервые было предложено применение Siamese сетей для картинок, где есть симметрия. Например — это суставы, и очевидно что лучше шарить фичи с левой и правой части при обучении и инференсе. Эксперименты показали, что так работает лучше чем не шарить.
- Одна из первых работ, где было предложено искусственно ограничивать attention сети, так как очень важно, чтобы она смотрела в правильные участки. Был так же показан GradCAM для оригинальной топологии сети.
- Показано на примерах с клинической точки зрения, что метод с немного меньшей точности лучше для докторов — они больше доверяют тому, что интерпретируется легко.
- SOTA перформанс
- Код открыт, чего не скажешь про другие статьи, где работают с медицинскими данными.
В заключение хочу сказать, что в медицине не очень важен буст в перформансе. Важна интерпретируемость сети. Более того, как мне кажется, в медицинских задачах finetuning все-таки не очень заходит и нужен немного особый подход.
Статьи выбираются либо из личного интереса, либо из-за близости к проходящим сейчас соревнованиям. Напоминаем, что описания статей даются без изменений и именно в том виде, в котором авторы запостили их в канал #article_essence. Если вы хотите предложить свою статью или у вас есть какие-то пожелания — просто напишите в комментариях и мы постараемся всё учесть в дальнейшем.
