Рубрика «Читаем статьи за вас». Январь — Февраль 2020

Привет, Хабр! Продолжаем публиковать рецензии на научные статьи от членов сообщества Open Data Science из канала #article_essense. Хотите получать их раньше всех — вступайте в сообщество!
Представлены обзоры 11 статей по Computer Vision, Natural Language Processing, Reinforcement learning и другим темам.
Статьи на сегодня:
- Side-Tuning: Network Adaptation via Additive Side Networks (University of California, Stanford University, 2019)
- Stacked DeBERT: All Attention in Incomplete Data for Text Classification (Kyungpook National University, South Korea, 2020)
- Zero-Shot Video Object Segmentation via Attentive Graph Neural Networks (UAE, USA, 2020)
- SAUNet: Shape Attentive U-Net for Interpretable Medical Image Segmentation (Toronto and Waterloo, Canada, 2020)
- FaceShifter: Towards High Fidelity And Occlusion Aware Face Swapping (Peking University, Microsoft Research, 2019)
- Towards a Human-like Open-Domain Chatbot (Google Brain, 2020)
- Positive Algorithmic Bias Cannot Stop Fragmentation in Homophilic Social Networks (Oxford, London, UK, 2020)
- BERT-of-Theseus: Compressing BERT by Progressive Module Replacing (Wuhan and Beihang Universities, Microsoft Research Asia, 2020)
- A Simple Framework for Contrastive Learning of Visual Representations (Google Research, 2020)
- BADGR: An Autonomous Self-Supervised Learning-Based Navigation System (Berkeley AI Research, USA, 2020)
- Training Large Neural Networks with Constant Memory using a New Execution Algorithm (Microsoft, 2020)
1. Side-Tuning: Network Adaptation via Additive Side Networks
Авторы статьи: Jeffrey O Zhang, Alexander Sax, Amir Zamir, Leonidas Guibas, Jitendra Malik (University of California, Stanford University, 2019)
Оригинал статьи :: GitHub project
Автор обзора: Андрей Лукьяненко (в слэке artgor)
Авторы задумались о том, как бы улучшить использование pretrained нейронок так, чтобы уменьшить оверфиттинг (бывает, если данных мало), уменьшить забывание, улучшить качество. И придумали. A давайте брать pretrained сетку, не трогать её саму по себе, но добавлять ещё одну такую же сетку и файнтюнить её, и объединять их. Улучшение качества продемонстрировали на текстах, картинках, RL и других штуках. Казалось бы, это просто увеличение количества параметров, но по факту получается интереснее.
Суть, ещё раз в том, что:
- Берем претренированную сетку. Мы фиксируем все параметры, так что она всегда даёт одни и те же предсказания. По факту feature extractor.
- Далее создаём side-tuning сетку и файнтюним её. Это либо копия оригинальной сетки, либо дистиллированная версия. Хотя по факту можно использовать любую архитектуру.
- Для расчёта предсказаний и лосса комбинируем output обоих сеток. Дефолтный подход — блендинг с весами, но есть варианты и поинтереснее.
Один из плюсов: мы свободны менять размер и архитектуру второй сетки. Поэтому если у нас мало данных и «простой» таргет, то можем делать маленькую сетку. Если данных много или таргет «сложный», можно делать более тяжелую сетку. Поскольку основная сетка не меняется, можно сказать, что вторая учит residuals от первой. Получается такой мини boosting.
Лосс-функция следующая: L (x, y) = || D (alpha B (x) + (1 — alpha) S (x)) — y||. Как уже говорилось, самый простой способ объединения — взвешенный блендинг. Стоит отметить, что при alpha=1 у нас получается просто feature extraction, при aplha=W0 — просто fine-tuning. А если менять aplha в процессе тренировки, а потом делаем равным 0, то получается что-то похожее на stage-wise тренировку в RL. Ещё вариант — hyperbolical decay. В таком случае мы типа взвешиваем приор и учим нашу оценку. Таким образом получается максимизация постериорной оценки.
Ну, а дальше можно упороться вдохновиться и сделать шаг дальше:
- Делаем side-tuning на какую-то задачу.
- Далее фиксируем веса нашей второй модели и… добавляем новую side network. Учим на другую задачу.
- Повторяем для N задач.
Благодаря тому, что мы фиксируем веса после тренировке на каждой задаче, модель не забывает это.
Дальше они сравнивают side-tuning с разными подходами на разных датасетах. Для начала берут Taskonomy и iCIFAR (делят CIFAR на 10 групп по 10 классов и учат по очереди на группах). Sidetune (A) — объединение двух сеток не весами, а адаптером — multilayer perceptron. В итоге side-tuning уступает только Progressive NN.
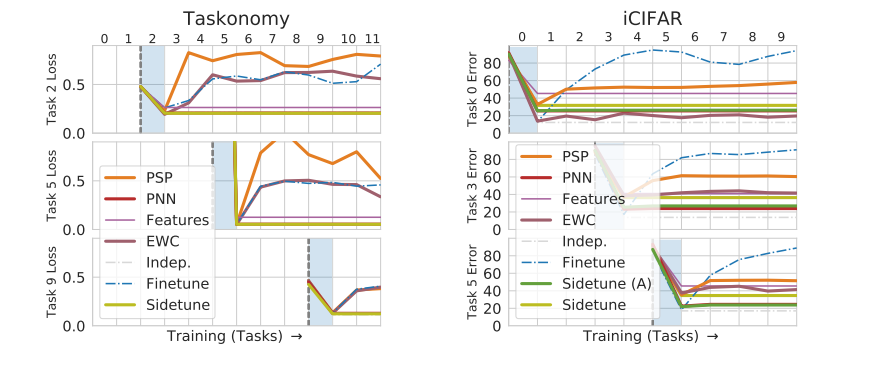
Дальше они доказывают, что подход работает и для других доменов:
- Transfer Learning для Taxonomy — задачи object classification, surface normal estimation, and curvature estimation
- Question-Answering in SQuAD v2 — с использованием BERT.
- Imitation Learning for Navigation in Habitat.
- Reinforcement Learning for Navigation in Habitat
Результаты экспериментов:
- параметр alpha надо тюнить в каждом отдельном случае, нет универсального лучшего значения;
- хорошо работает тренировка с инкрементальным увеличением объёма данных;
- вторая сетка может хорошо работать, даже если она не слишком большая;
- делать бустинг — много раз делать side-tuning на одну и ту же задачу не особо полезно. Лучше просто сделать вторую сетку потяжелее;
- вроде лучше обычного fine-tuning для RL;
- веса второй сетки лучше тренировать не с нуля, а брать из претренированной.
2. Stacked DeBERT: All Attention in Incomplete Data for Text Classification
Авторы статьи: Gwenaelle Cunha Sergio, Minho Lee (Kyungpook National University, South Korea, 2020)
Оригинал статьи :: GitHub project
Автор обзора: Андрей Лукьяненко (в слэке artgor)
Авторы задумались о том, что в реальности в текстах нередко слова пропущены или написаны с опечатками, что создаёт проблемы на стадии создания эмбеддингов, — хорошо бы что-то делать с этим.
Придумали:, а давайте возьмём input, на него наложим embedding слой, а затем трансформер, потом запихнем в denoising transformers, чтобы на выходе получить более качественное представление входных данных. В результате multilayer perceptron может реконструировать эмбеддинги пропущенных слов и создавать более абстрактные и полезные эмбеддинги, а трансформеры улучшают эти эмбеддинги.
Идею проверяли на the Chatbot Natural Language Understanding Evaluation Corpus и Kaggle’s Twitter Sentiment Corpus. Подход показал улучшение F1 и генерализации на твитах и в задаче Speech2Text улучшение предсказания сентиментов и интентов.
В итоге предлагается 2 новых идеи:
- Эта самая новая архитектура
- Предложили новые задачи на тренировку «incomplete intent and sentiment classification from incorrect sentences» и опубликовали датасеты для этого
Предложенная архитектура выглядит вот так:
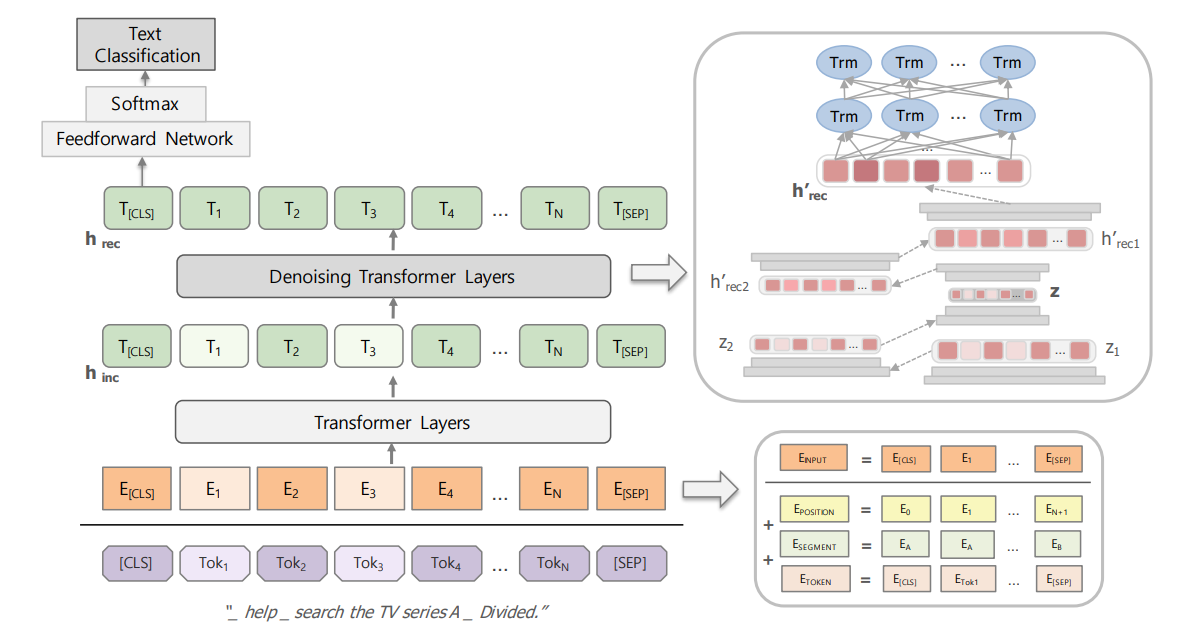
Начало архитектуры как в BERT — токенизация, эмбеддинги и прочее. Файн-тюнинг делается на «incomplete text classification corpus». Denoising transformer — это stacks of multilayer perceptron друг на друге и bidirectional transformers. На входе — эмбеддинги неполных предложений, на выходе — эмбеддинги полных предложений. (о самом датасете будет сказано ниже). Эмбеддинги получены с помощью обычного берта. Размерность (N, 768, 128) — размер батча, эмбеддинг токена и максимальный размер последовательности.
Stacks of multilayer perceptron:
- Два раза по 3 слоя.
- Вначале мы уменьшаем размерность: 768 → 128 → 32 → 12.
- А затем обратно.
Лосс для сравнения реконструированного эмбеддинга и оригинального полного эмбеддинга — MSE.
Когда эмбеддинги готовы (видимо после тренировки), они передаются в bidirectional transformers и это будет новый input. Дальше делается fine-tuning на incomplete text classification corpus.
Как уже говорилось раньше, использовалось 2 датасета.
Twitter Sentiment Classification
Взяли датасет с каггла (1.6 млн твитов). Из него взяли 200 примеров твитов (поровну позитивных и негативных) с пропущенными словами или опечатками. Вначале отдали в Amazon Turk, чтобы люди написали правильные твиты. Выглядит это как-то так:

И файн-тюнили на этих 200 примерах. Валидировались на 50 примерах, которые были без исправлений.
Intent Classification from Text with STT Error
В данном случае был датасет с корректными предложениями, и нужно было сгенерить предложения с ошибками. Они просто прогнали текст через Text-to-Speech и обратно через Speech-to-Text — вот и получились ошибки. В датасете 2 интента и он тоже маленький (файн-тюнили вообще на 100 примерах)
Они пробовали разные готовые решения для TTS, STT. Вот примеры:

Эксперименты:
- бейзлайны: Google Dialogflow, SAP Conversational AI, Rasa
- Semantic hashing with classifier. Насколько понимаю, они кодируют не слова, а символы
- BERT
- Stacked DeBERT
Все модели тренировали по 3 раза для классификации интента: на полных данных и на «ухудшенных» данных после gtts-witai и macsay-witai. Для обоих задач получили улучшенное качество.
3. Zero-Shot Video Object Segmentation via Attentive Graph Neural Networks
Авторы статьи: Wenguan Wang, Xiankai Lu, Jianbing Shen, David Crandall, Ling Shao (UAE, USA, 2020)
Оригинал статьи :: GitHub project
Автор обзора: Андрей Лукьяненко (в слэке artgor)
Авторы предлагают использовать attentive graph neural network (AGNN) для задачи zero-shot video object segmentation (ZVOS). Фреймы используются как ноды, а связи между парами фреймов — ребра, которые описываются дифференцируемым attention. Подход работает не только для ZVOS, но и для image object co-segmentation (IOCS).
Основные заявленные преимущества AGNN:
- end-to-end подход
- благодаря графому подходу эффкетивно использует взаимосвязи внутри видео
- использует attention для получения информации между парами фреймов
Архитектура такая:

Каждое видео — граф. Ноды — фреймы; все ноды связаны друг с другом (interconnected и есть self-connections для каждой ноды). Суть идеи в использовании стандартных способов GNN для обучения — message propagation внутри графа. А на выходе получаем бинарные сегментационные маски для видео.
Важные моменты модели:
- Интересно то, что используют DeepLabV3 для получения эмбеддингов нод.
- Есть специальные ребра, которые являются self-connection — нода связана сама с собой. Это типа репрезентация самого фрейма.
- Ребра между разными нодами используют inter-attention механизм. По факту показывают насколько важны эмбеддинги одной ноды для другой ноды
- Итоговые маски получаются с помощью небольшой FCN
Эксперименты:
- DAVIS16 — сегментация 50 видео (30 в трейне, 20 на валидации). Лучше других моделей.
- Youtube-Objects — 126 видео, 10 категорий. Лучше других моделей.
- DAVIS17 — 60 видео в трейне 30 на валидации, 30 в тесте. Тут не только объекты, но и маски. Тоже лучше других моделей.
- IOSC — Тоже крутые результаты
Ablation study:
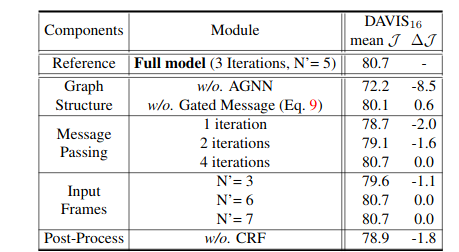
4. SAUNet: Shape Attentive U-Net for Interpretable Medical Image Segmentation
Авторы статьи: Jesse Sun, Fatemeh Darbeha, Mark Zaidi, Bo Wang (Toronto and Waterloo, Canada, 2020)
Оригинал статьи :: GitHub project
Автор обзора: Андрей Лукьяненко (в слэке artgor)
TL; DR: UNet + дополнительный поток данных + dense + dual attention decoder = SOTA + interpretability
Главная идея: разнообразные CNN хорошо работают для сегментации, в том числе медицинских картинок. Но у них не хватает робастности и интерпретируемости. Одна из причин этого — CNN обычно учат текстуру картинок, а не форму объектов. Стандартные подходы к интерптерации — gradient-based saliency методы. Но обычно это требует дополнительные вычисления и не всегда достаточно хорошо интерпретируется.
В предлагаемой архитектуре берется UNet и добавляется второй поток данных, в который подаётся информация о форме объектов. Ещё они используют dual-attention decoder, и именно он даёт интерпретируемость без дополнительных вычислений после инференса. Результат: SAUNet — SOTA на SUN09 и AC17.
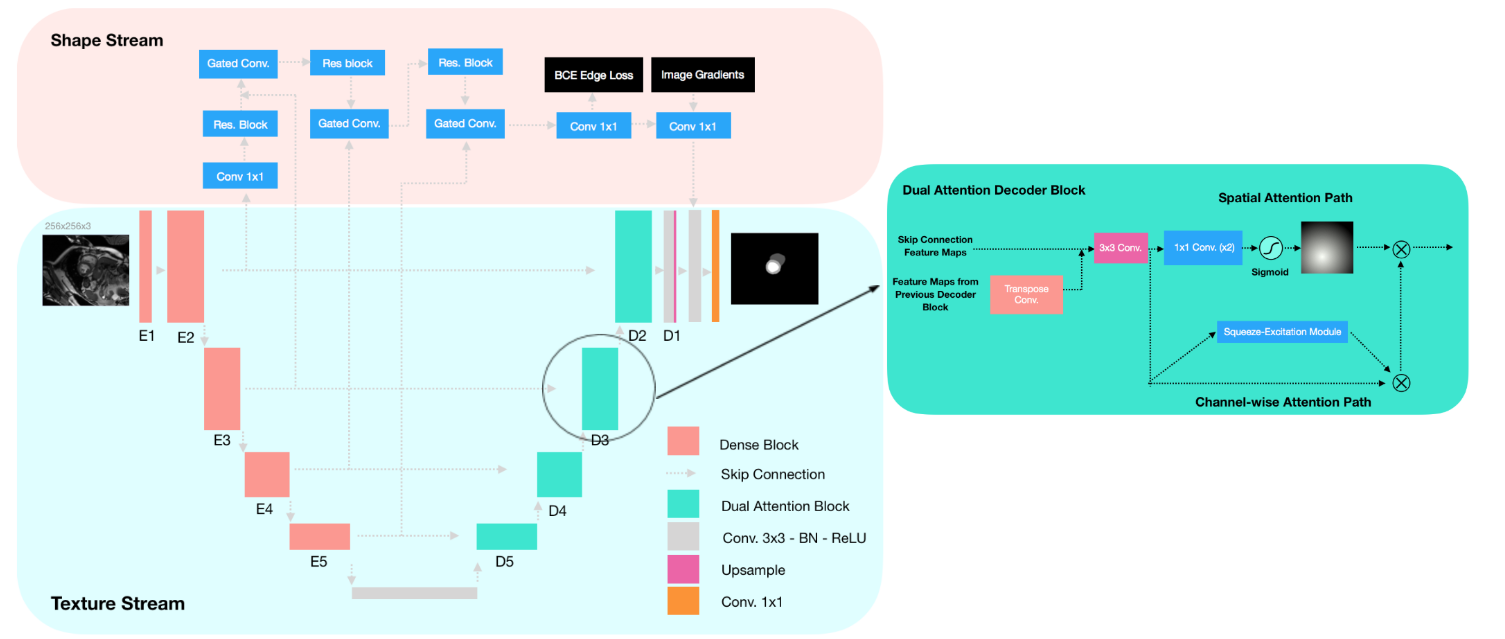
SAUNet
Как уже говорилось, в модели 2 потока данных.
Texture stream
Это UNet, но вместо энкодера используются dense блоки похожие на Tiramisu. И декодер — dual attention decoder block.
Gated shape stream
Вдохновились архитектурой Gated-SCNN.Как видно в верхней части архитектуры, данные из unet на каждом шаге downsample идут в верхний стрим. Объединие информации из стримов делается с помощью gated convolutional layer: alpha_L = sigma (C_1×1(S_L||C_1×1(T_t))), где S — feature map из shape stream, T — feature map из texture stream, C1×1 — 1×1 convolution.
Они конкатенируются по каналам, на них накладывается ещё один convolution и активация сигмоидой. Можно ещё увидеть residual blocks — это 2 нормализированных 3×3 convolution со skip-connection. А затем мы ещё раз берем S и поэлементно умножаем на alpha. И пропускаем через ещё один residual block.
К выходу из steam shape добавляется deeply supervision и можно посчитать Ledge. Это binary cross entropy loss между оригинальными и предсказанными границами картинки. Благодаря этому модель учится предсказывать форму объектов: «The output of the gated shape stream is the predicted shapefeature maps of the classes of interest concatenated channel-wise with the Canny edges from the original image. Theoutput is then concatenated with the texture stream featuremaps before the last normalized 3×3 convolution layer ofthe texture stream.»
Dual Attention Decoder Block.
Берем стандартный подход (2 нормализированных 3×3 convolution на сконкатенированных feature maps) и добавляем две новые вещи: Spatial attention path и Channel-wise attention
Spatial attention path
Это используется для интерпретируемости. По факту это два convolution 1×1 (после первого получается C/2 каналов, после второго получается один канал), затем накладываем sigmoid. И наконец стакаем С раз (как каналы, чтобы потом можно было делать поэлементное умножение).
Channel-wise attention path
Для улучшения качества. Это SE модуль.
Dual-Task Loss function
Это взвешенный лосс: L_total = lambda1 L_CE + lambda2 L_Dice + lambda3 * L_Edge
Они просто использовали значение 1 для каждой lambda.
Эксперименты
- SUN09 — 2 класса: he endocardium and the epicardium. 260+135 картинок с центральным кропом 128×128.
- AC17 — 200 сканов, с 8–20 слайсов. В итоге использовали разрешение 256×256.
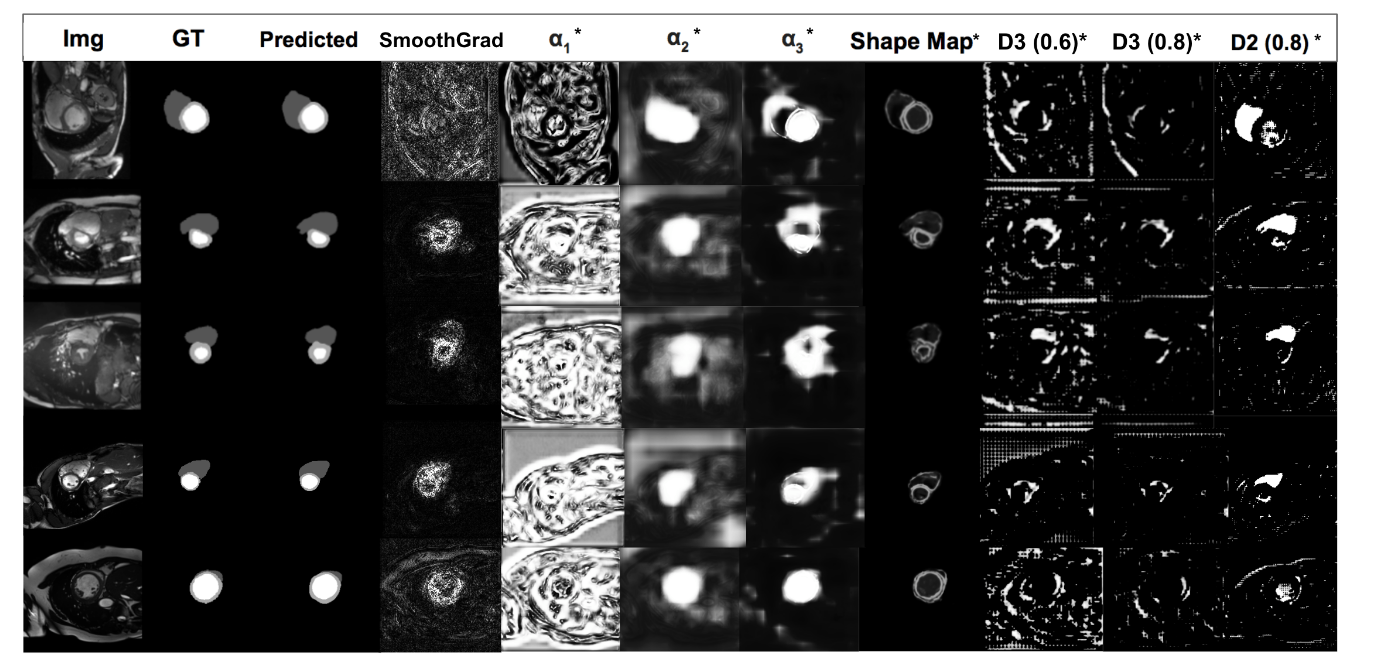
По обоим экспериментам результаты данного подхода лучше. Даже сделали Ablation study и показали, что shape stream реально приносит пользу. Пишут, что это реально полезно плюс работает быстрее, чем saliency maps.
5. FaceShifter: Towards High Fidelity And Occlusion Aware Face Swapping
Авторы статьи: Lingzhi Li, Jianmin Bao, Hao Yang, Dong Chen, Fang Wen (Peking University, Microsoft Research, 2019)
Оригинал статьи :: Non official GitHub project
Автор обзора: Алекс Широн (в слэке shiron8bit)
Еще одна попытка сделать person agnostic gan-архитектуру для face swap, не требующую для двух новых персон обучения новой модели, а осуществляющую обучение на некотором большом наборе лиц в разных визуальных условиях без аннотирования этих условий. На самом деле, это развитие идей из статьи этих же авторов, в которой объединяются эмбеддинг переносимого лица и эмбеддинг визуальных условий/атрибутов лица-реципиента и по которым генератор создает новое изображение, только в этот раз с многоуровневым unet-style энкодером атрибутов, adain-style блоком для объединения эмбеддингов разной природы и постпроцессингом в виде сетки, улучшающей изображения в сложных условиях, когда лица частично чем-то закрыты.
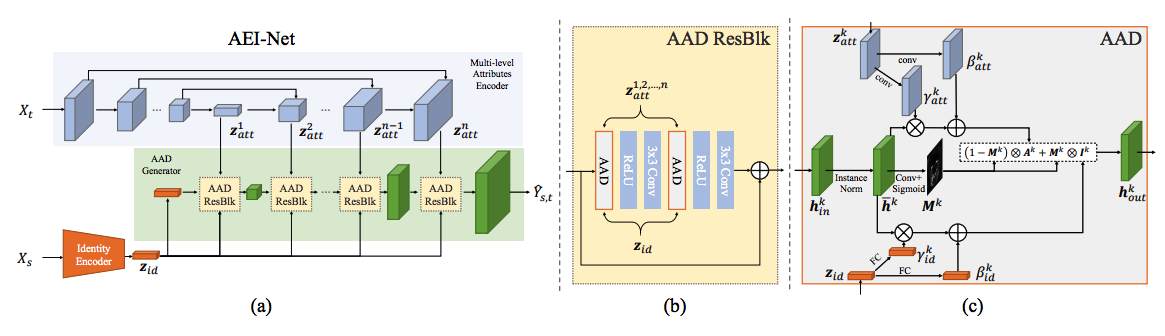
Первая (и основная) часть, осуществляющая непосредственно перенос лица X_s в визуальные условия лица X_t, представлена на рисунке выше (a) и состоит из многоуровнего энкодера атрибутов и генератора AADGenerator, в котором в AADResBlck блоках происходит объединение информации от эмбеддинга атрибутов конкретного уровня и эмбеддинга переносимой персоны z_id (у авторов это эмбеддинг от предобученной ArcFace-сетки), при этом перед подачей на вход нового AADResBlck блока текущая feature map апсэмплится с использованием билинейной интерполяции. На первый блок в качестве основного входа поступает feature map, получаемая из вектора z_id апсэмплингом с использованием transposed 2d convolution.
Каждый AADResBlck, как видно из рисунка (b), представляет из себя Residual block, в котором помимо relu и сверток присутствует несколько (2 или 3 в зависимости от того, совпадает ли число входных/выходных каналов) AAD-слоев.
При этом AAD-слой, вдохновленный AdaIN/SPADE-слоями (в соответствии с современными веяниями: статья1, статья2), берет на себя основную функцию объединения информации от эмбеддинга персоны и эмбеддинга атрибутов на текущем уровне и делает следующее:
- нормализует каждую feature map на входе (делает instance normalization)
- приводит эмбеддинг персоны через fully connected-слои к набору средних и дисперсий нужной (как у фичемапы) размерности, после чего денормализует уже нормализованные фичи поканальным перемножением и сложением, получая A_k
- приводит эмбеддинг атрибутов к набору средних и дисперсий нужной размерности, после чего денормализует уже нормализованные фичи поэлементным перемножением и сложением, получая I_k
- параллельно с этим по нормализованной фичемапе считается маска внимания (маска размерности фичемапы с весами от 0 до 1)
- выход получается поэлементным сложением A_k и I_k по маске.
Использование многоуровнего энкодера вместе с маской позволяет нам при генерации на каждом уровне определять, какая инфа в каком регионе важнее — от эмбеддинга переносимой персоны или от эмбеддинга атрибутов на заданном уровне: так, эмбеддинг персоны сильно влияет на все изображение на низких разрешениях (4×4, 8×8), на средних уровнях (16×16, 32×32) маска концентрирует влияние переносимой персоны только на отдельные регионы (контуры глаз, рта, лица), на высоких разрешениях основной вклад вносят эмбеддинги визуальных атрибутов.
Ablation study показывает, что использование маски позволяет получать куда более хорошие результаты, чем при простом суммировании/конкатенации A_k и I_k. Также показано, что уменьшение числа слоев энкодера атрибутов ведет к ухудшению результатов (по умолчанию используют 8 для картинок 256×256).

При обучении помимо стандартного для ганов adversarial loss используются 3 дополнительных лосса: L_id контролирует качественный перенос персоны (в данной работе используют косинусное расстояние между исходным эмбеддингом и эмбеддингом снегерированного изображения, а раньше использовали L2 между эмбеддингами, хотя в контексте обычно нормированных в Arcface эмбеддингов это не принципиально), L_rec — обычная попиксельная L2-ошибка восстановления изображения (которая учитывается только в случаях, когда в качестве X_s и X_t подается одна и та же картинка, при этом раньше авторы для случая с разными изображениями оставляли вес 0.1), L_att — лосс для контроля качества сохранения визуальных атрибутов при генерации нового изображения Y_s, t.
Предложенная архитектура AEI-Net дает неплохие результаты, однако у нее могут возникать проблемы в случае, если на X_t лицо будет частично чем-то закрыто. Ранее некоторые работы использовали сегментационные сетки, позволяющие выделить только незакрытые части лица, а закрытые части предлагалось брать из оригинального изображения. Авторы же для решения этой проблемы предлагают еще одну Unet-архитектуру Hear-Net, в которой на вход подается сгенерированное изображение Y_s, t, а также разность между оригинальным изображением X_t и сгенерированным Y_t, t (когда перенесли на X_t лицо из самого X_t). Основная идея такова: если подавать на оба входа AEI-Net одно и то же изображение, она будет размывать и искажать участки, где лицо чем-то перекрыто, поэтому разность может дать нам неплохую подсказку, какие области у сгенерированного лица нуждаются в улучшении.
Обучение осуществляется в semi-supervised режиме, в котором нет ground truth, но есть два лосса, контролирующих одновременно похожесть на результат первой сетки Y_s, t и на оригинал X_t (L_chg и L_rec соответственно). Поскольку зачастую в датасетах лиц не так уж и много примеров с чем-то закрытыми лицами, авторы предложили использовать синтетические данные, получаемые наложением объектов из EgoHands, GTEA Hand2K, ShapeNet на лица исходного датасета (объединение CelebaHQ, FFHQ и VGGFace).
6. Towards a Human-like Open-Domain Chatbot
Авторы статьи: Daniel Adiwardana, Minh-Thang Luong, David R. So, Jamie Hall, Noah Fiedel, Romal Thoppilan, Zi Yang, Apoorv Kulshreshtha, Gaurav Nemade, Yifeng Lu, Quoc V. Le (Google Brain, 2020)
Оригинал статьи :: Blog
Автор обзора: Артем Родичев (в слэке fuckai)
TL; DR
Команда из Google Brain получила SOTA генеративную чатбот модель под названием Meena. Тренировали огромный Evolved Transformer в 2.6B параметров на корпусе в 340GB диалогов на поде из 2048 TPU v3 в течении 30 дней. Модель разносит все сравнимые общедоступные чатбот системы по человеческим и автоматическим метрикам. Приведены примеры диалогов, судя по ним AGI близко.
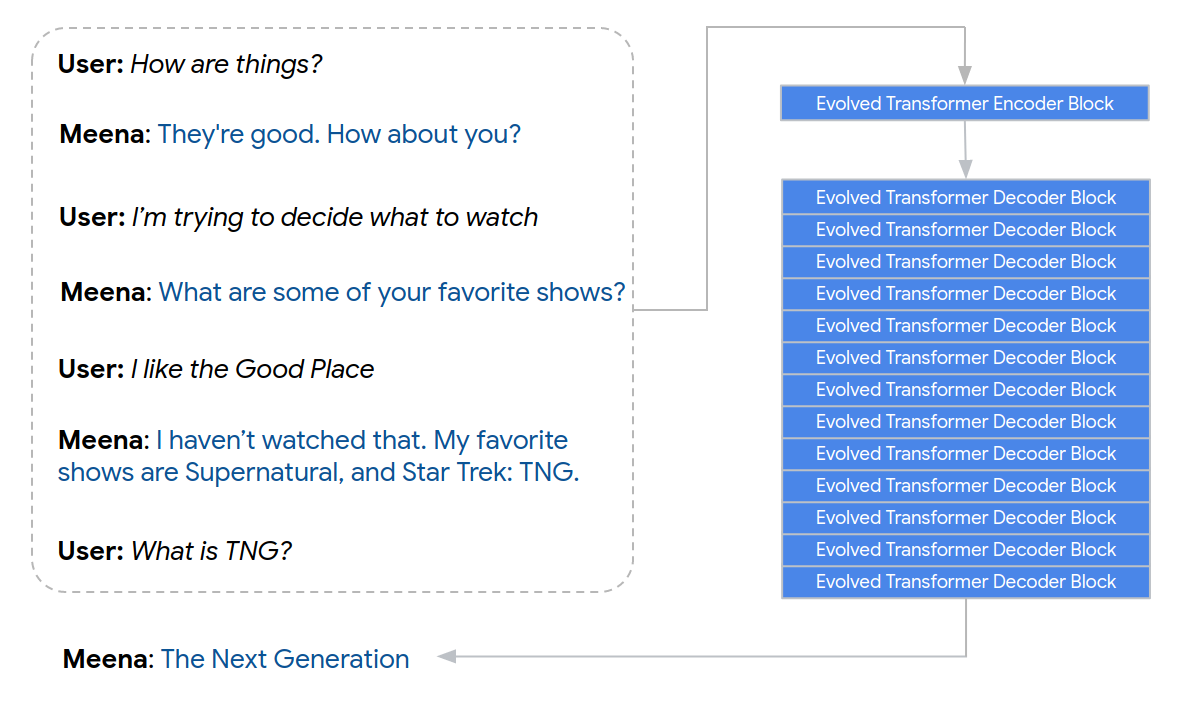
Суть
Модель представляет из себя seq2seq архитектуру, где энкодер — 1 блок Evolved Transformer«a, дэкодер — 13 таких блоков. Наглядно на первой картинке к посту. В качестве обджектива — минимизация perplexity (далее ppl). Сравнились с ванильным трансформером, у него качество по ppl получилось немного хуже, 10.2 vs 10.7 ppl.
Токенизация стандартная — BPE, но с размером словаря сделали интересное — взяли только 8K byte-pairs. Основная причина, что модель огромная и с таким размером словаря она вмещается в память их TPU на 16GB. В качестве контекста в энкодер подают до 7 диалоговых сообщений, размер энкодера и дэкодера ограничили в 128 токенов.
Трейнсет намайнили из «public domain social media». Конкретных источников не приводят, скорее всего реддит+твиттер+что-то еще. Пофильтровали корпус удаляя урлы, меншены, слишком короткие/длинные ответы, а также оскорбительные и токсичные сообщения. В итоге получилось 360GB диалогов или 876M пар (контекст, респонс).
Учили модель в течении 30 дней на TPU поде состоящем из 2048 TPU v3. За все время обучения сделали 164 эпохи по корпусу, таким образом их модель просмотрела 10 триллионов токенов. Это гугл детка.
Для генерации ответов применили несколько трюков.
- Sampling-and-rank — генерируем N респонсов каким-либо сэмплингом, например с температурой. Считаем скоры для каждого сэмпла и отвечаем респонсом с топ скором. Скор — лог вероятность респонса нормированный на кол-во токенов, чтобы корректно сравнивать респонсы с разными длинами. N взяли = 20.
- Заменили сэмплинг с температурой на top-k сэмплирование — сэмплируем не по всему словарю, а только из топ k вероятных токенов.
- Фильтрация от повторов. У генеративных моделей есть прикол, что иногда они начинают зацикливаться и повторять или самих себя или фразу собеседника. Давайте прикрутим ngram«ную фильтрацию и выбросим респонсы с слишком большим нграмным пересечением с фразами из контекста.
- На выходе навернули доп классификатор оффенса и токсичных респонсов.
Результаты
Для оценки качества ввели человеческую метрику SSA — Sensibleness and Specificity Average. Асессоров просили оценивать каждый ответ чатбота на заданный контекст по двум бинарным метрикам. Sensibleness — насколько ответ имеет смысл для данного контекста. Если ответ нерелевантный, нелогичный, противоречивый, фактологически некорректный — то он получает 0, иначе 1. Specificity — насколько ответ специфичный и распространенный. SSA = (Sensibleness + Specificity) / 2. Соответственно чем больше SSA для чатбота, тем релевантнее и интереснее он общается.
Для сравнения взяли:
- XiaoIce — самый популярный чатбот в Китае от Microsoft, ~100M пользователей, ориентирован на энгейджмент и эмпатию.
- DialoGPT, предыдущая SOTA генеративная модель от MS, по сути GPT2 на 745M параметров натренированная на огромном диалоговом корпусе из реддита.
- Mitsuku — чатбот система, 5 кратный победитель Loebner Prize — крупнейший ежегодный Тюринг, где чатботу нужно убедить судью что он — человек.
- Cleverbot — чатбот система которая появилась еще в 1986 году, жива по сей день.
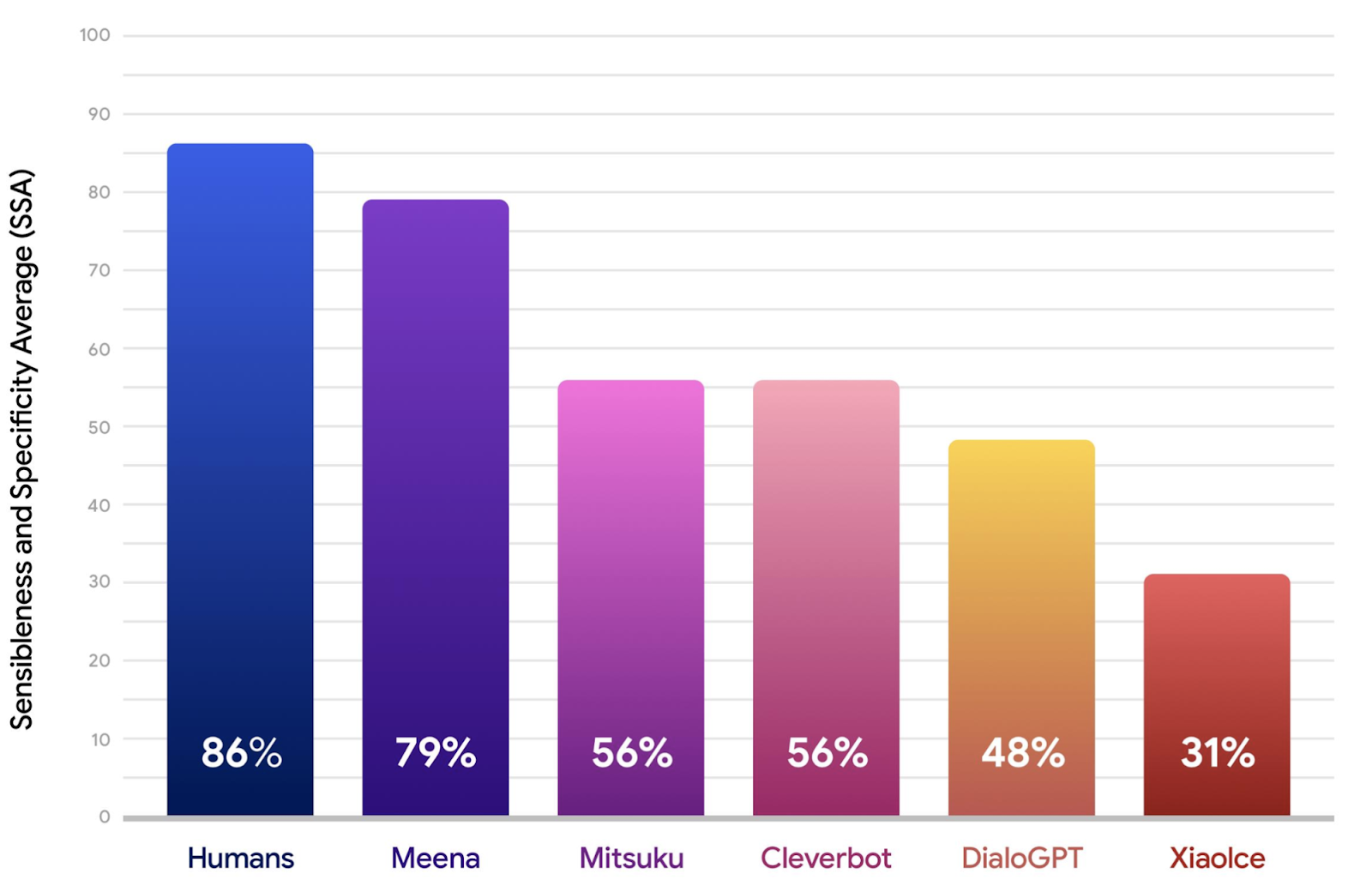
Конечно Meena разнесла все остальные чатботы по Sensibleness, Specificity, и соответственно SSA. В статье в аппендиксе есть примеры диалогов с каждым из чатботов, как утверждается не черипикнутых, по ним и правда видно что Meena хороша.
Показали что есть корреляция между автоматической ppl и человеческой SSA, хотя долгое время считалось, что генеративные диалоговые модели сложно сравнивать друг с другом на автоматических метриках по причине их слабой корреляции с человеческими.
7. Positive Algorithmic Bias Cannot Stop Fragmentation in Homophilic Social Networks
Авторы статьи: Christian Blex, Taha Yasseri (Oxford, London, UK, 2020)
Оригинал статьи
Автор обзора: Семен Синченко (в слэке sem)
TL; DR
Авторы пишут о процессе фрагментации в социальных сетях. Любая социальная сеть, в которой есть малейший preferential attchment процесс, рано или поздно скатится к полной фрагментации. Авторы приводят доказательства этого для одной из моделей. Далее авторы ставят вопрос, могут ли администраторы сети избежать процесса фрагментации. И доказывают, что сохранение равномерного разнообразия и полного отсутствия сегментации не возможно.
Авторы опираются на довольно простую модель: мы начинаем с бесконечно большой сети, где у каждой вершины есть одна случайна связь. Все вершины двух разных цветов. На каждом шаге для каждой вершины выбирается новая связь с некоторым предпочтением (в реальности предпочтение обеспечивается как склонностями людей, так и рекомендательными системами) в пользу «своего» цвета. Чем больше разнообразие имеющихся связей, тем больше предпочтение. С некоторой вероятностью «забывается» одна из старых связей, причем вероятность забыть «долгоживущую» связь меньше. Авторы доказывают, что такая система в пределе приходит к полной сегментации, даже если учитывать слабые связи (aka друзья друзей). Дальше авторы предлагают механизм, имитирующий возможности администраторов сети влиять на цвет (типа мы можем показывать модифицированные рекомендации связей), после чего доказывают, что такой механизм в пределе не способен удержать разнообразие связей на уровне 0.5.
Плюсы:
- Интригующая тема
- Интересна сама постановка вопроса
- Строгие доказательства
Минусы:
- Все в пределах бесконечного времени и бесконечного размера сети
- То, что нельзя удержать разнообразие связей на уровне 0.5 мало о чем говорит: это как в анекдоте про физика-теоретика, которого попросили оценить устойчивость стула с тремя ножками (легко оценить устойчивость стула с нулем и бесконечным числом ножек, но с произвольном числом ножек возникают трудности)
Вспомнилась статья (не помню где) о том, что люди голосовавшие за Хиллари в США писали, что не понимают, кто голосует за Трампа, так как все, кого они знают тоже голосовали за Хиллари: кажется фрагментация это наша реальность. Не ясно, в чем опасность фрагментации, может в ограниченности информации? Или быстром достижении пределов роста? В целом постановка вопроса именно про возможности влиять на процесс фрагментации довольно любопытная и кажется, эта тема довольно актуальна.
8. BERT-of-Theseus: Compressing BERT by Progressive Module Replacing
Авторы статьи: Canwen Xu, Wangchunshu Zhou, Tao Ge, Furu Wei, Ming Zhou (Wuhan and Beihang Universities, Microsoft Research Asia, 2020)
Оригинал статьи :: GitHub project
Автор обзора: Александр Бельских (в слэке belskikh)
Авторы предложили новый метод Knowledge Distillation и дистильнули с ним BERT, получив x1.98 скорость при 98% перфоманса (что лучше большинства других подходов). Более того, подход является model-agnostic и не требует изобретения каких-то особых distillation лоссов, учится почти как обычная модель end-to-end. Подход вдохновлён парадоксом Тесея (Если все составные части исходного объекта были заменены, остаётся ли объект тем же объектом?) и назван Theseus Compression.
Суть его в том, что модель делится на участки по слоям, которым ставятся в соответствие более легкие аналоги, которые «присоединяются» к тем же входам-выходам. Всё это учится параллельно, а в конце модель замещается покусочно этими легкими аналогами, в итоге остаётся только легкая модель. Исходную модель называют predecessor, а модель-заместитель — successor (в противовес teacher-student)
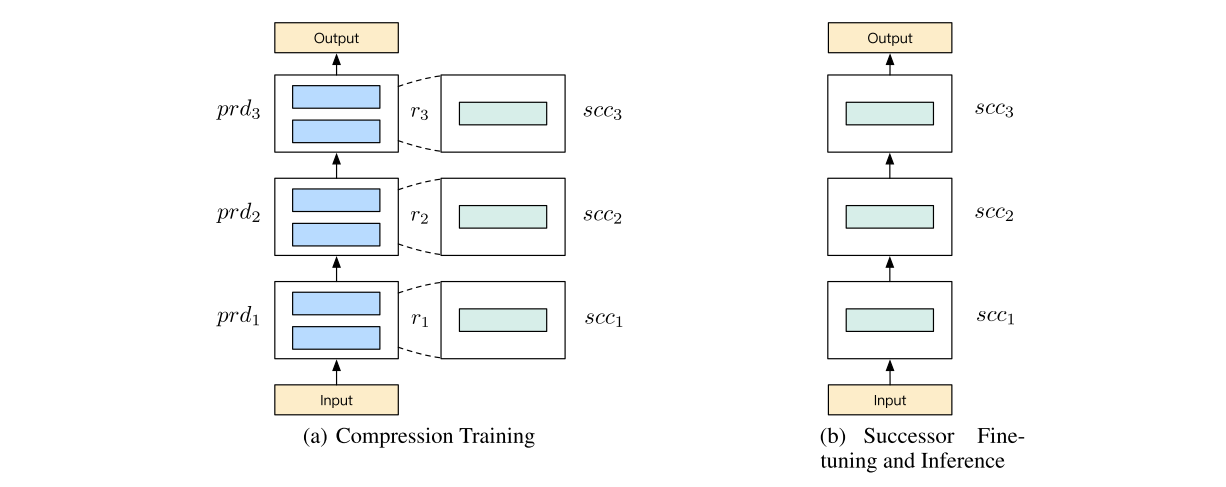
В процессе обучения forward пасс идёт через каждую группу модулей с вероятностью p, что похоже на Дропаут и обозначется авторами как некоторая регуляризация. То есть, на каждом сабблоке происходит рандомное отключение либо predecessor, либо successor.
Веса заморожены для всех модулей, кроме модулей successor, но градиенты всё равно считаются с учётом predessor (т.к. вычисления через них тоже проходят). Обучение проходит с обычным task-specific лоссом, CE, BCE, whatever, что облегчает подбор гиперпараметров.
У вероятности замены блока представлено два режима — константный и линейно увеличивающийся. В любом случае после определенного количества эпох замещенная модель ещё некоторое время файнтюнится отдельно.
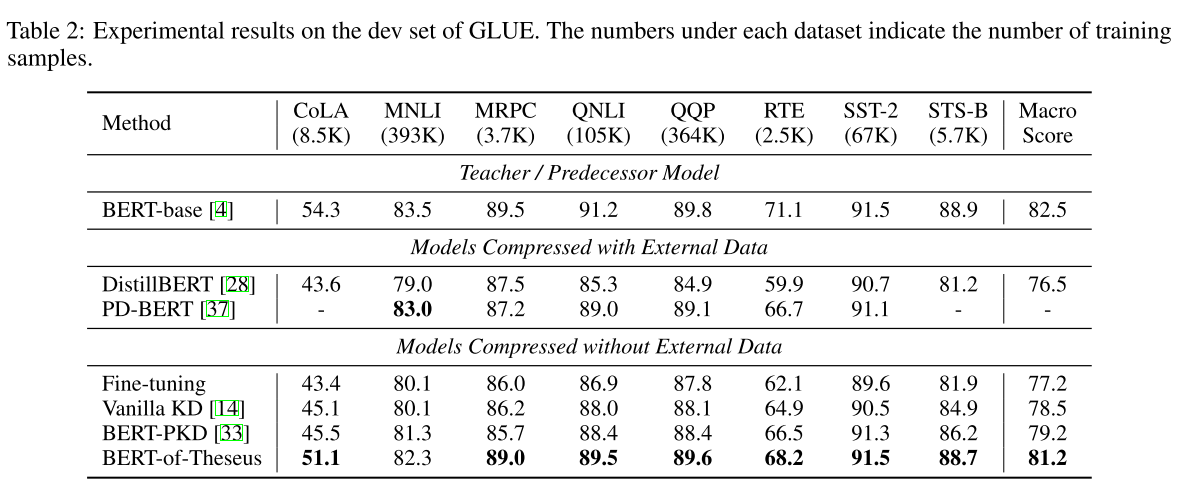
Результаты репортят как СОТА для knowledge distillation (ну, а когда репортили другие). Подход теоретически подходит для любых моделей, в тч и для Резнетов и графовых. Авторы обещают в будущем поресерчить эту тему
9. A Simple Framework for Contrastive Learning of Visual Representations
Авторы статьи: Ting Chen, Simon Kornblith, Mohammad Norouzi, Geoffrey Hinton (Google Research, 2020)
Оригинал статьи :: GitHub project
Автор обзора: Александр Бельских (в слэке belskikh)
TL; DR
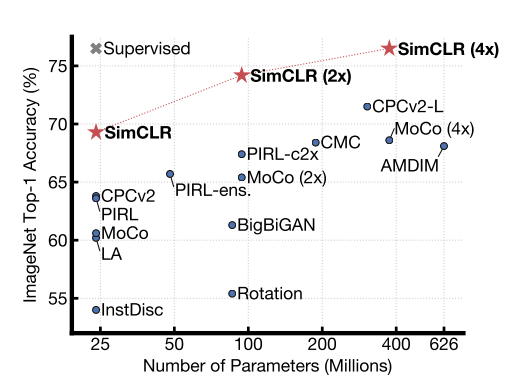
Новая СОТА в representation learning (и почти сота в semi-supervised и self-supervised) от Google Brain, которая своей простотой говорит нам, что representation learning ещё очень слабо изучен
Авторы (один из которых — Хинтон) предлагают простой фреймворк SimCLR (simple framework for contrastive learning of visual representation), благодаря которому смогли получить репрезентации, линейный классификатор поверх которых показал 76.5% топ-1 на имаджнете. Если его зафайнтюнить на 1% от всех лейблов имаджнета, то получится 85.8% топ-5 точность.
В работе показано, что:
- подбор аугментаций имеет критичское значение для этой задачи
- MLP поверх фичей сети, выучившей репрезентации, очень сильно докидывает по качеству
- contrastive learning сильно выигрывает от больших батчей, жирных моделей и долгого обучения.
Суть подхода:
- набирается батч из N изображений
- изображения аугментируются (использовалось всего ТРИ последовательных аугментации (рандомкроп+ресайз, случайные цветовые искажения, случайный гаусс блюр)
- нейронка-энкодер экстрактит фичи (использовался ResNet)
- небольшая projection head делает нелинейную проекцию (с помощью однослойного MLP) в пространство, где применяется лосс
- накидывается контрастив лосс (стремится сделать репрезентации одного и того же изображения зааугментированного максимально похожими)
Контрастив лосс применяется следующим образом. Из 2N получившихся изображениями на одну позитивную пару приходится 2(N-1) негативных. Лосс считается для всех позитивных пар по формуле ниже:
![$l_{i,j} = -log \frac{exp(sim(z_i,z_j)/\tau)}{\sum^{2N}_{k=1} \mathbb{1}_{[k\neq i]} exp(sim(z_i,z_k)/\tau)}$](https://habrastorage.org/getpro/habr/formulas/767/fd9/b76/767fd9b767dfc4599ad98055dce9e496.svg)
где sim — это cosine similarity между векторами, 1 — индикаторная функция, суть которой в том, чтоб не считать similarity между одним и тем же семплом (1=1 if k!=i), t — температура. Эта функция уже известна и носит название NT-Xent (the normalized temperature-scaled cross entropy loss).
Учили на очень больших батчах, от 256 до 8192. Так как SGD на больших батчах может быть нестабилен, использовали оптимизатор LARS. Учили на Cloud TPU, используя от 32 до 128 ядер (в зависимости от размера батча). На 128 TPUv3 ядрах занимало 1.5 часа обучить ResNet-50 на батчсайзе 4096, 100 эпох.
Изучили очень много разных аугментаций, но обнаружили, что:
- Для такой функции лосса лучше всего заходит простой набор из трёх (кроп-ресайз, цвет, гаусс блюр).
- Композиция аугов имеет критически важное значение. Использовали ассиметричную схему — в паре изображений кроп-ресайзились оба, а вот остальные ауги применялись только к одному.
- Контрастив лернинг нуждается в более сильных аугах, чем супервайзед лернинг
По архитектуре модели и projection head:
- контрастив лернинг выигрывает от более жирных моделей
- нелинейная проекция фичей перед подсчётом лосса улучшает качество этих фичей (используются именно фичи перед projection head!)
По лоссу:
- NT-Xent работает лучше других альтернатив (рассмотрены в статье)
- контрастив лернинг гораздо больше выигрывает от больших батч сайзов и дольшего обучения, чем супервайзед (объясняют тем, что больше негативных сэмплов в таком случае)
На 12 датасетах (не Imagenet) линейный классификатор поверх выученных фичей показал сравнимые с supervised результаты. Зафайнтюненная селф-супервайзед модель показывает лучшие результаты, чем супервайзед бейзлайны на 10 датасетах из 12.
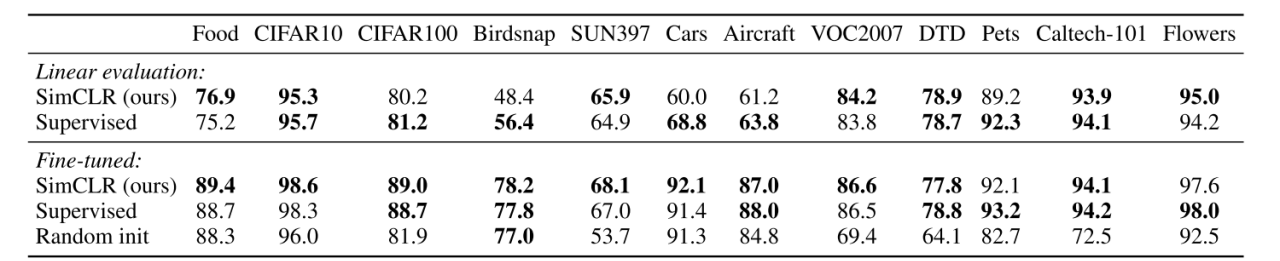
В заключении авторы делают вывод, что простота их подхода показывает избыточную сложность альтернативных методов, и что сила такого простого подхода говорит о том, что self-supervised обучение всё ещё остаётся сильно недоизученным
10. BADGR: An Autonomous Self-Supervised Learning-Based Navigation System
Авторы статьи: Gregory Kahn, Pieter Abbeel, Sergey Levine (Berkeley AI Research, USA, 2020)
Оригинал статьи :: GitHub project: Video
Автор обзора: Александр Бельских (в слэке belskikh)
Часто навигация мобильных роботов представляет собой геометрическую проблему, где строится геометрическая карта мира, по которой уже планируется действие. Такой подход фейлится, например, в траве — её вполне может проехать робот, но система навигации считает траву непреодолимым препятствием. Авторы предлагают систему, которую назвали BADGR—Berkeley Autonomous Driving Ground Robot.
Суть её в том, что на робота навешиваются сенсоры, которые позволяют определить столкновения, неровную дорогу, съезд в кювет и тп, т.е. нежелательное поведение. Затем робот отправляется в путешествие по некоторой реальной среде, собирая данные и размечая их последствии (негативные сэмплы — как раз нежелательное поведение). После разметки робот обучает CNN-LSTM модельку, которая из изображения с камеры сэмплит планируемые действия и их последствия, на основе чего и составляется план движения.
Робот использовался Cearpath Jackak, на котором стояли 6-DOF IMU sensors + GPS + wheel velocity sensors. Дополнительно поставили две камеры 170 deg FOV 640×480, лидар и компас. На роботе установлен NVIDIA jetson TX2 и 4G смартфон, который позволял вести видео стриминг и удалённое управление.
Робот насобирал 42 часа данных (34 в городе и 8 на бездорожье) в автономном режиме, но после чистки это составило всего 720 000 сэплов. Пока датка собиралась, робот периодески сваливался, его приходилось поднимать.
Моделька принимает на вход данные с сенсоров и последовательность предполагаемых действий, придиктит на каждое действие свой эвент (столкновение, кювет и тп).

На инференсе задача мод
