Резервное копирование, часть 4: Обзор и тестирование zbackup, restic, borgbackup
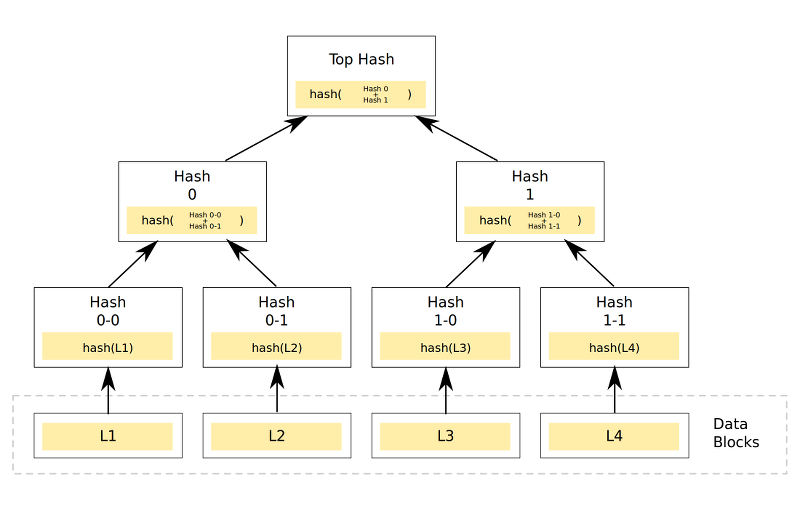
В данной статье будут рассматриваться программные средства для резервного копирования, которые путем разбиения потока данных на отдельные компоненты (chunks), формируют репозиторий.
Компоненты репозитория могут дополнительно сжиматься и шифроваться, а самое главное — при повторных процессах резервного копирования — переиспользоваться повторно.
Резервная копия в подобном репозитории — именованная цепочка связанных друг с другом компонентов, например, на основе различных hash-функций.
Есть несколько подобных решений, я остановлюсь на 3: zbackup, borgbackup и restic.
Ожидаемые результаты
Поскольку все претенденты так или иначе требуют создания репозитория, одним из важнейших факторов будет оценка размера репозитория. В идеальном случае его размер должен быть не более 13 гб согласно принятой методике, а то и меньше — при условии хорошей оптимизации.
Также крайне желательно иметь возможность создавать резервные копии файлов напрямую, без применения архиваторов типа tar, а также работу с ssh/sftp без дополнительных средств вроде rsync и sshfs.
Поведение при создании резервных копий:
- Размер репозитория будет равен размеру изменений, или меньше.
- Ожидается большая нагрузка на процессор при использовании сжатия и/или шифрования, а также вероятна достаточно большая нагрузка на сеть и дисковую подсистему, если процесс архивации и/или шифрования будет работать на сервере хранения резервных копий.
- Если повредить репозиторий — вероятна отложенная ошибка как при создании новых резервных копий, так и при попытке восстановления. Надо планировать дополнительные меры по обеспечению целостности репозитория или использовать встроенные средства проверки его целостности.
В качестве эталонного значения принята работа с tar, как это было показано в одной из прошлых статей.
Тестирование zbackup
Общий механизм работы zbackup заключается в том, что программа находит в потоке данных, подаваемом на входе, области, содержащие одинаковые данные, затем опционально их сжимает, шифрует, сохраняя каждую область только 1 раз.
Для дедупликации используется 64-битная кольцевая hash-функция со скользящим окном для побайтной проверки на совпадение с уже существующими блоками данных (подобному тому, как это реализовано в rsync).
Для сжатия применяется lzma и lzo в многопоточном исполнении, а для шифрования — aes. В последних версиях присутствует возможность в будущем удалять старые данные из репозитория.
Программа написана на C++ с минимальными зависимостями. Автор по всей видимости вдохновлялся unix-way, поэтому программа принимает данные на stdin при создании резервных копий, выдавая аналогичный поток данных в stdout при восстановлении. Таким образом, zbackup можно использовать как весьма неплохой «кирпичик» при написании собственных решений резервного копирования. Например, у автора статьи эта программа является основным средством резервного копирования для домашних машин примерно с 2014 года.
В качестве потока данных будет применяться обычный tar, если не сказано иначе.
Проверка работы выполнялась в 2 вариантах:
- создается репозиторий и запускается zbackup на сервере с исходными данными, потом содержимое репозитория передается на сервер хранения резервных копий.
- создается репозиторий на сервере хранения резервных копий, запускается zbackup через ssh на сервере хранения резервных копий, ему через pipe выдаются данные.
Результаты первого варианта были такие: 43m11s — при использовании нешифрованного репозитория и компрессора lzma, 19m13s — при замене компрессора на lzo.
Нагрузка на сервере с исходными данными была следующей (показан пример с lzma, с lzo была примерно такая же картинка, но доля rsync была примерно четверть от времени):
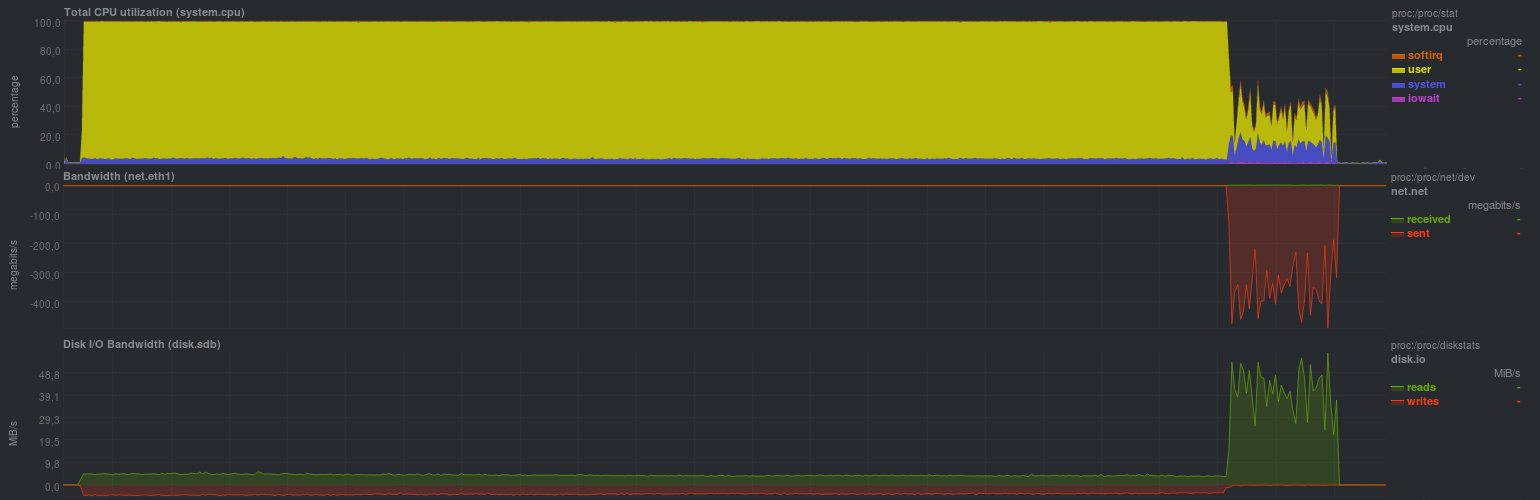
Ясно видно, что подобный процесс резервного копирования годится лишь при относительно редких и небольших изменениях. Также крайне желательно ограничивать работу zbackup в 1 поток, иначе будет весьма высокая загрузка по процессору, т.к. программа весьма хорошо умеет работать в несколько потоков. Нагрузка на диск была небольшой, что в целом при современной дисковой подсистеме на основе ssd будет незаметно. Также четко видно запуск процесса синхронизации данных репозитория на удаленный сервер, скорость работы сравнима с обычным rsync и упирается в производительность дисковой подсистемы сервера хранения резервных копий. Минусом подхода является хранение локального репозитория и, как следствие, — дублирование данных.
Более интересным и применимым на практике является второй вариант с запуском zbackup сразу на сервере хранения резервных копий.
Для начала будет проверена работа без использования шифрования c компрессором lzma:
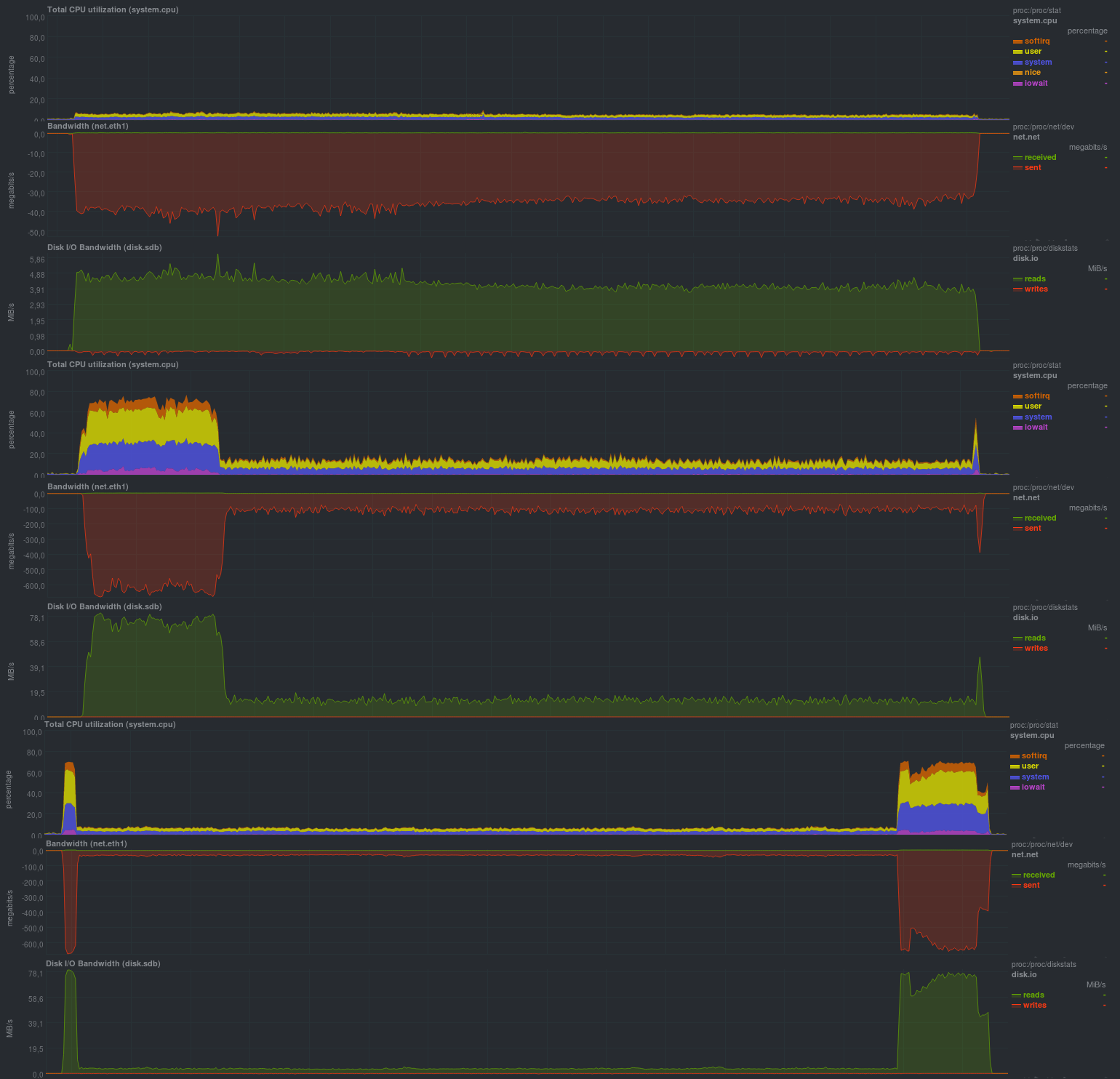
Время работы каждого тестового запуска:
Если активировать шифрование с применением aes, результаты достаточно близки:
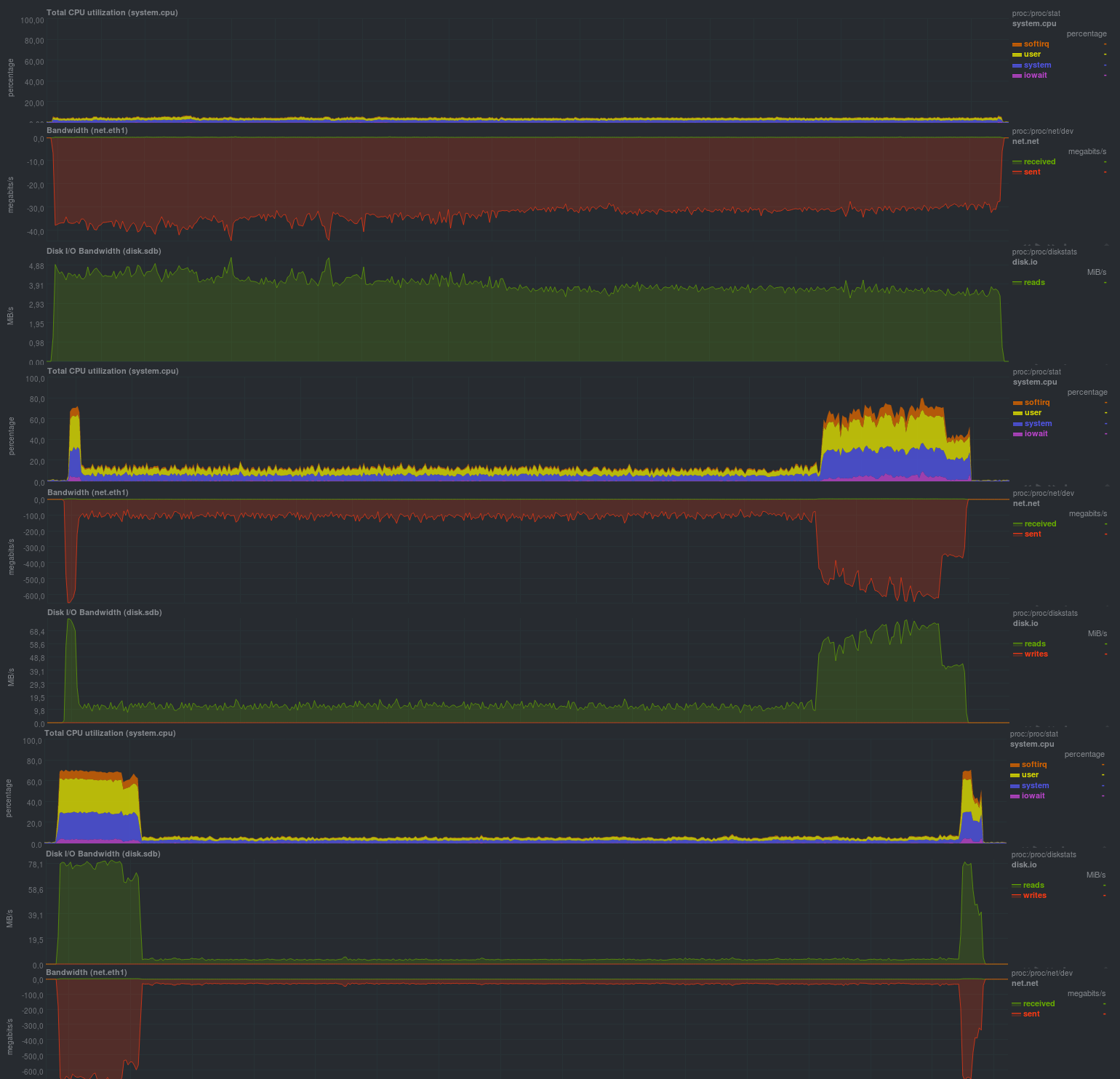
Время работы на тех же данных, с шифрованием:
Если шифрование совместить с сжатием на lzo, выходит так:
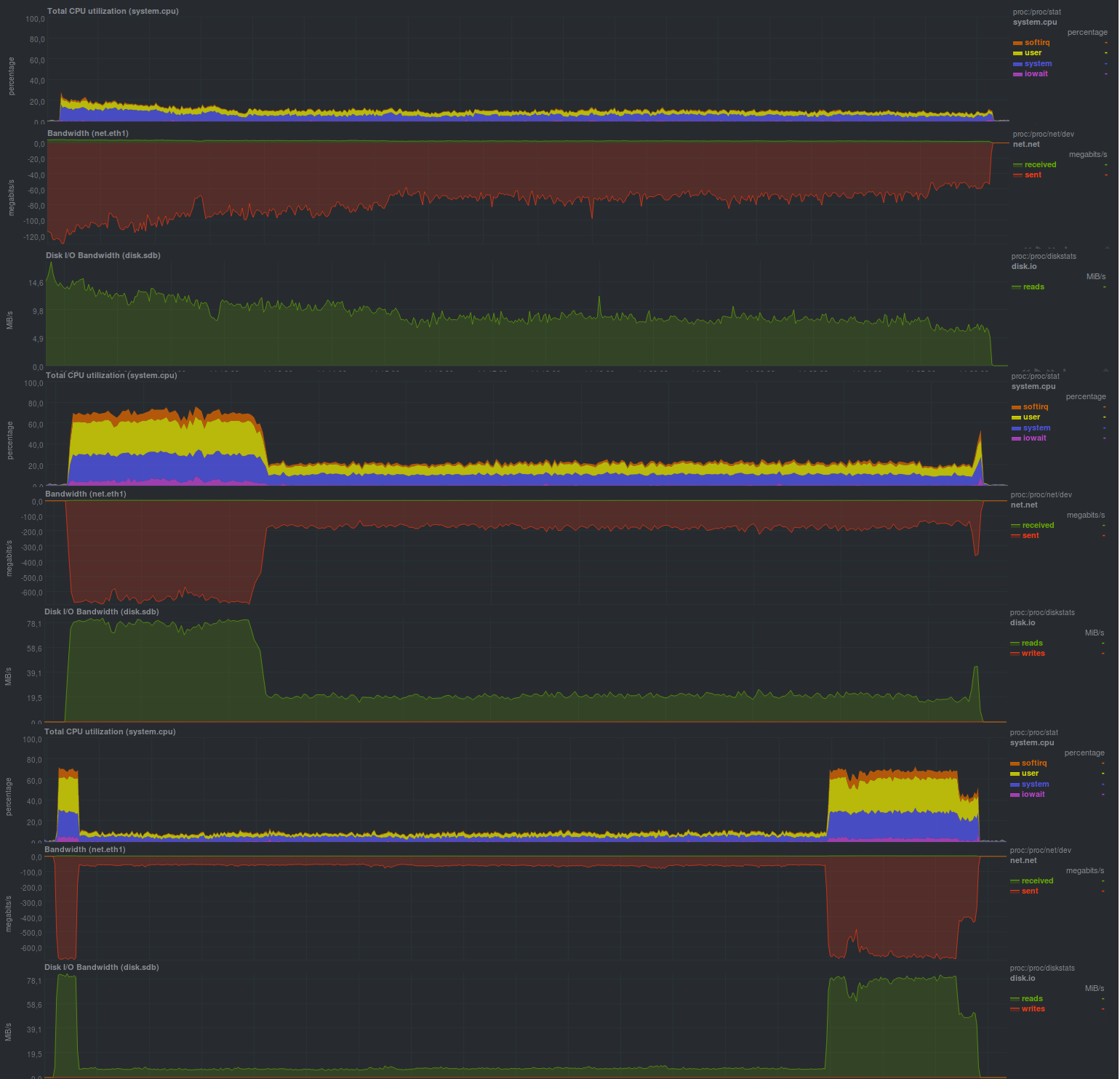
Время работы:
Размер результирующего репозитория был относительно одинаков и составлял 13 гб. Это значит, что дедупликация работает корректно. Также на уже сжатых данных применение lzo дает ощутимый эффект, по общему времени работы zbackup вплотную приближается к duplicity/duplicati, однако отставая от основанных на librsync в 2–5 раз.
Преимущества очевидны — экономия дискового пространства на сервере хранения резервных копий. Что касается инструментов проверки репозитория — автором zbackup они не предусмотрены, рекомендуется применять отказоустойчивый дисковый массив или облачный провайдер.
В целом весьма неплохое впечатление, несмотря на то, что проект примерно 3 года стоит на месте (последний feature request был около года назад, но без ответа).
Тестирование borgbackup
Borgbackup является форком attic, еще одной, схожей с zbackup системы. Написан на python, имеет схожий с zbackup список возможностей, но дополнительно умеет:
- Монтировать резервные копии через fuse
- Проверять содержимое репозитория
- Работать в режиме клиент-сервер
- Использовать различные компрессоры для данных, а также эвристическое определение типа файла при его компрессии.
- 2 варианта шифрования, aes и blake
- Встроенное средство для
При тестировании будет использоваться эвристика при компрессии с определением типа файла (compression auto), а результаты будут такие:
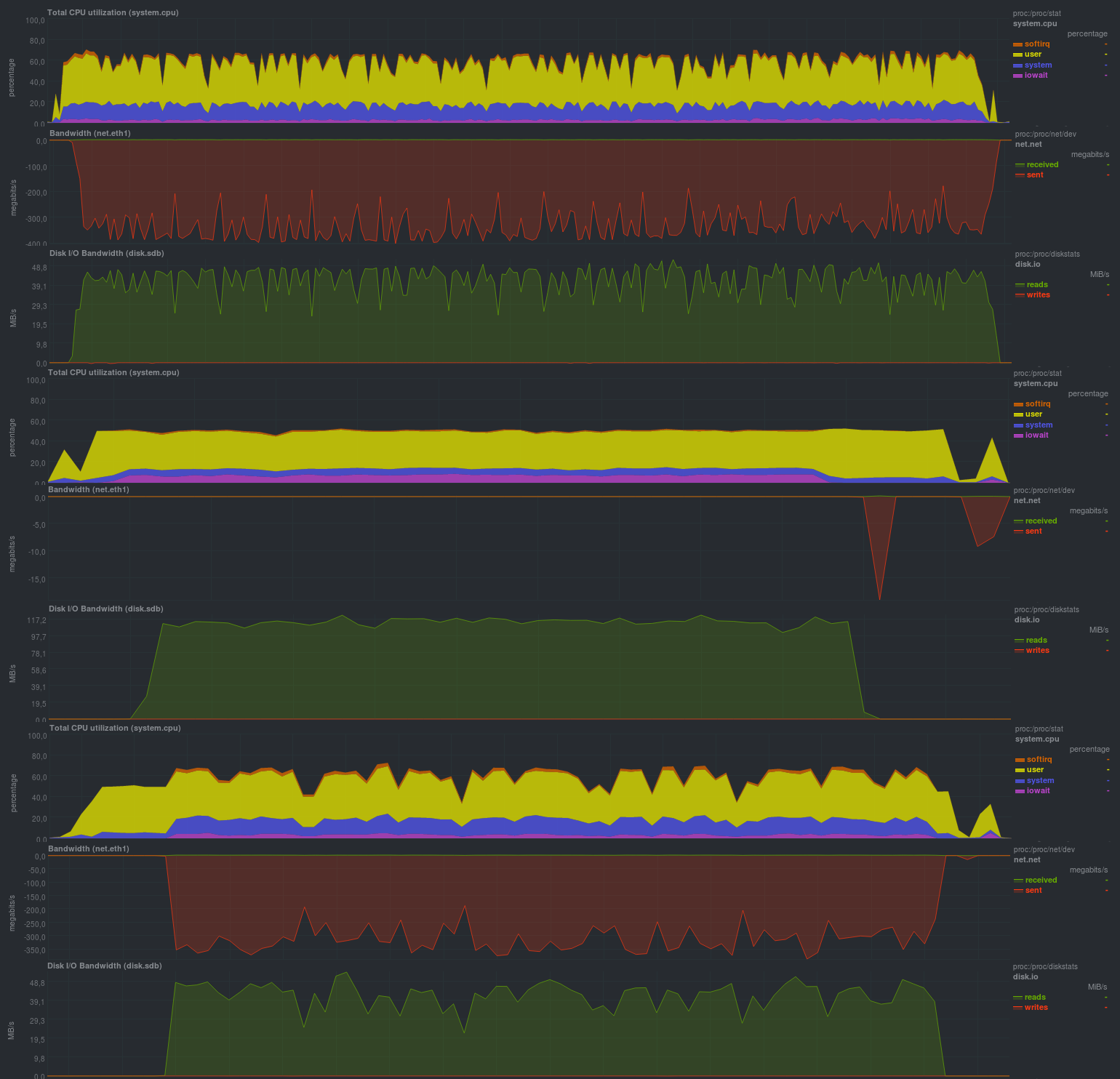
Время работы:
Если включить авторизацию репозитория (режим authenticated), результаты получатся близкими:
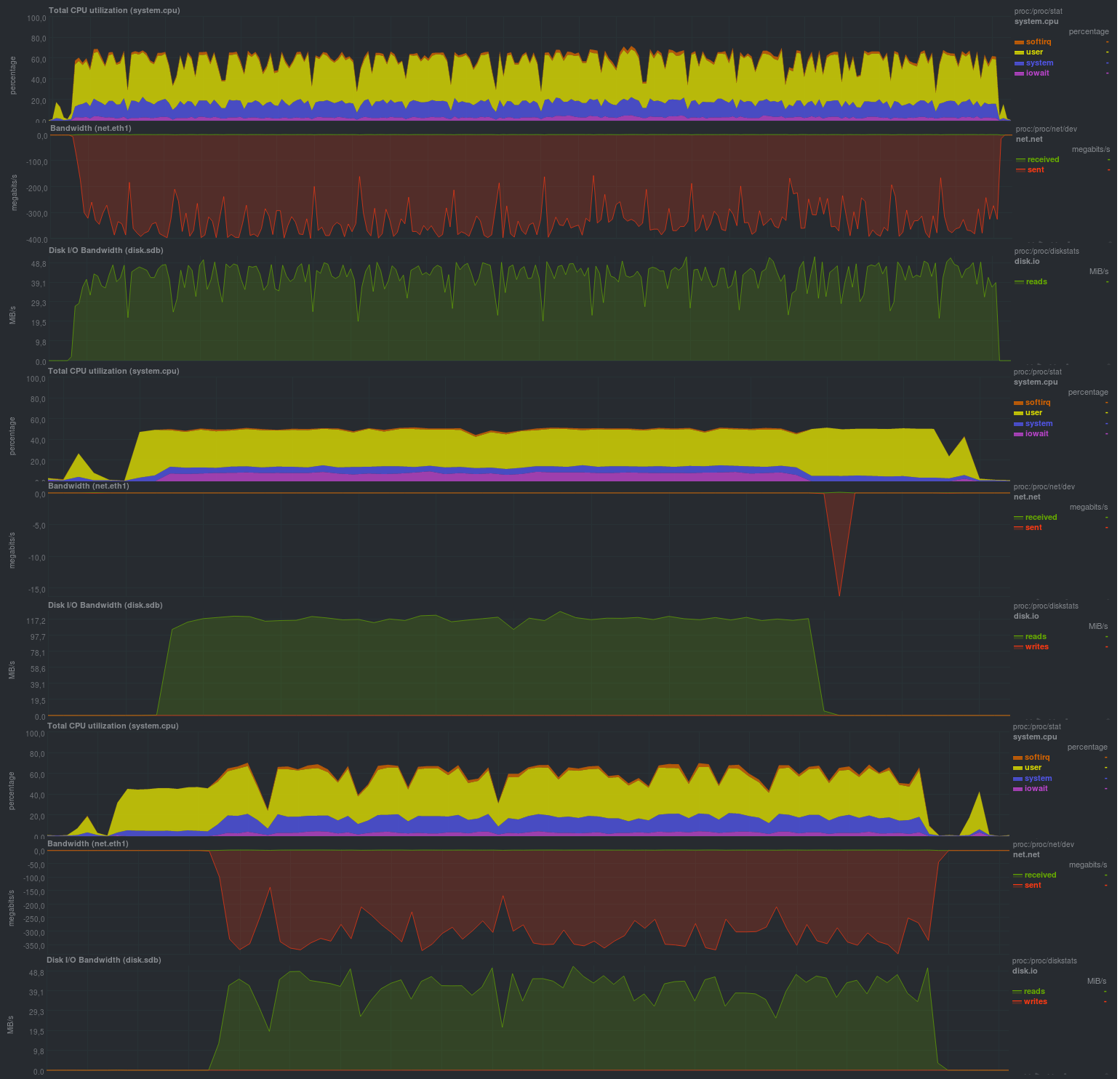
Время работы:
При активации шифрования aes результаты не сильно ухудшились:

А если поменять aes на blake, ситуация вовсе улучшится:
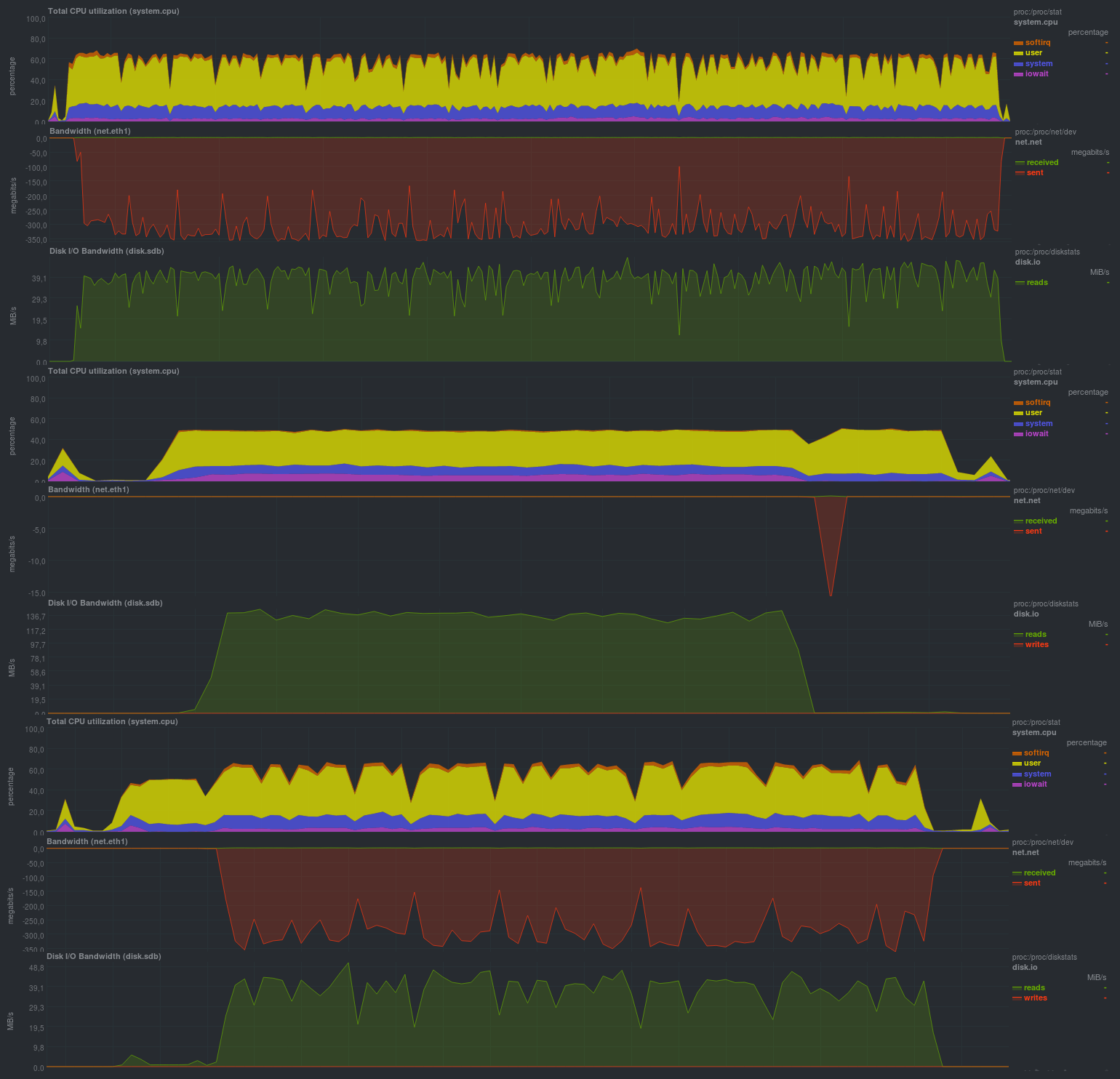
Время работы:
Как и в случае с zbackup, размер репозитория составил 13 гб и даже чуть меньше, что, в целом, ожидаемо. Весьма порадовало время работы, оно сравнимо с решениями на основе librsync, обеспечивая гораздо более широкие возможности. Также порадовала возможность задания различных параметров через переменные окружения, что дает весьма серьезное преимущество при использовании borgbackup в автоматическом режиме. Также порадовала нагрузка при резервном копировании: судя по загрузке процессора — borgbackup работает в 1 поток.
Особых минусов при использовании не обнаружилось.
Тестирование restic
Несмотря на то, что restic достаточно новое решение (первые 2 кандидата были известны еще с 2013 года и старше), он обладает достаточно неплохими характеристиками. Написан на Go.
Если сравнивать с zbackup, дополнительно дает:
- Проверку целостности репозитория (включая проверку по частям).
- Огромный список поддерживаемых протоколов и провайдеров для хранения резервных копий, а также поддержку rclone — rsync для «облачных» решений.
- Сравнение 2 резервных копий между собой.
- Монтирование репозитория через fuse.
В целом список возможностей достаточно близок к borgbackup, местами больше, местами меньше. Из особенностей — отсутствие возможности отключения шифрования, а следовательно, резервные копии будут зашифрованными всегда. Давайте посмотрим на практике, что можно выжать из этого ПО:
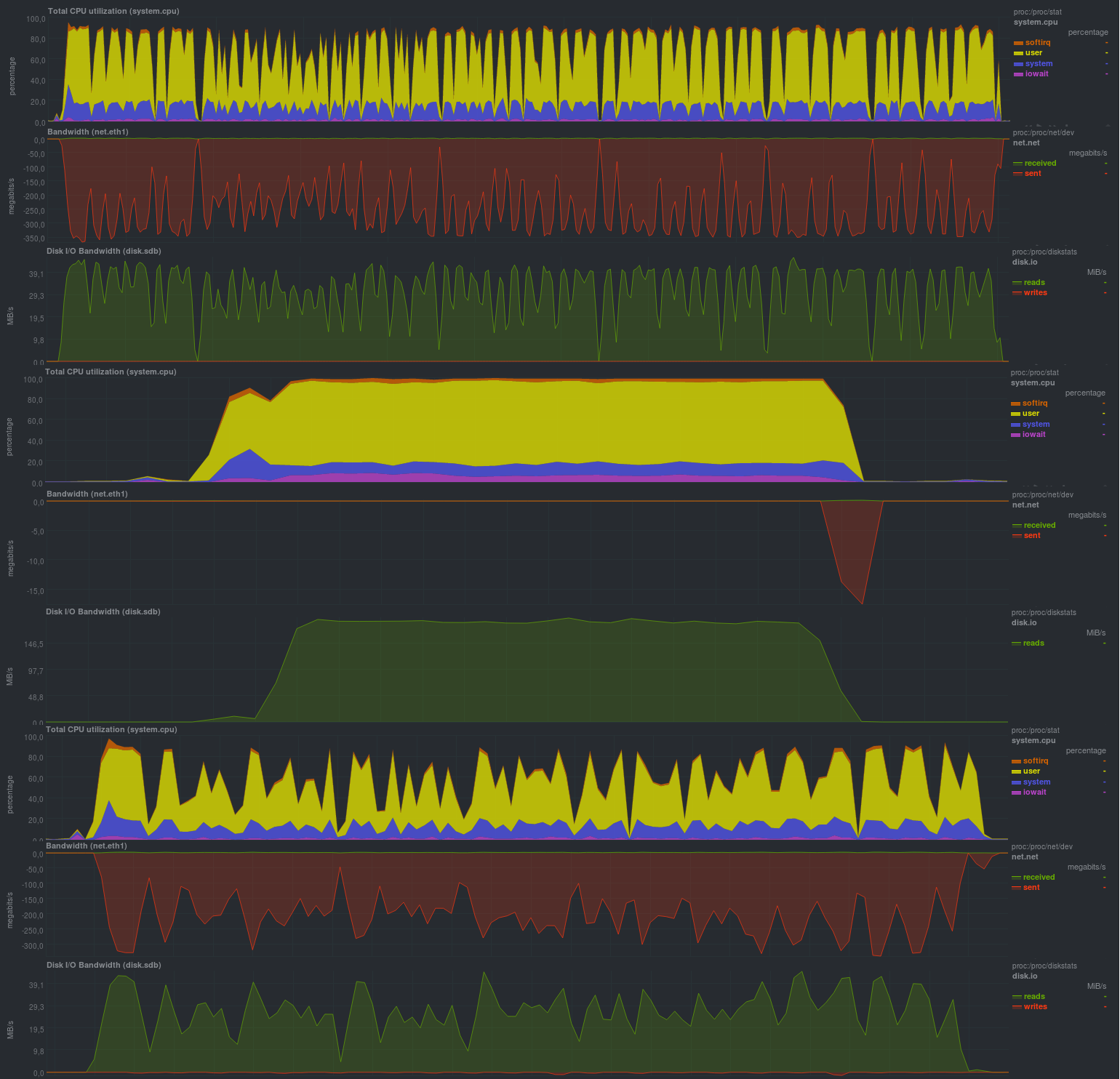
Время работы:
Результаты работы также сравнимы с решениями на основе rsync и, в целом, весьма близки к borgbackup, но нагрузка на процессор более высокая (работает несколько потоков) и пилообразная.
Вероятнее всего, программа упирается в производительность дисковой подсистемы на сервере хранения данных, как это уже было с rsync. Размер репозитория составил 13 гб, как и у zbackup или borgbackup, явных минусов при использовании этого решения не обнаружилось.
Результаты
По факту у всех кандидатов получились близкие показатели, однако разной ценой. Лучше всех показал себя borgbackup, чуть медленнее — restic, zbackup, вероятно, не стоит начинать применять,
а если он уже используется — пробовать менять на borgbackup или restic.
Выводы
Наиболее перспективным решением выглядит restic, т.к. именно он обладает наилучшим соотношением возможностей к скорости работы, но пока не будем торопиться с общими выводами.
Borgbackup в принципе ничем не хуже, а вот zbackup вероятно лучше заменить. Правда, для обеспечения работы правила 3–2–1 zbackup все еще можно задействовать. Например, в дополнение к средствам резервного копирования на основе (lib)rsync.
Анонс
Резервное копирование, часть 1: Зачем нужно резервное копирование, обзор методов, технологий
Резервное копирование, часть 2: Обзор и тестирование rsync-based средств резервного копирования
Резервное копирование, часть 3: Обзор и тестирование duplicity, duplicati
Резервное копирование, часть 4: Обзор и тестирование zbackup, restic, borgbackup
Резервное копирование, часть 5: Тестирование bacula и veeam backup for linux
Резервное копирование, часть 6: Сравнение средств резервного копирования
Резервное копирование, часть 7: Выводы
Автор публикации: Павел Демкович
