Решаем crackme от Лаборатории Касперского
В один прекрасный день разные каналы в телеграмме начали кидать ссылку на крэкмишку от ЛК, Успешно выполнившие задание будут приглашены на собеседование! . После такого громкого заявления мне стало интересно, насколько сложным будет реверс. О том, как я решал этот таск можно почитать под катом (много картинок).
Придя домой, я еще раз внимательно перечитал задание, скачал архив и стал смотреть, что же там внутри. А внутри было это:
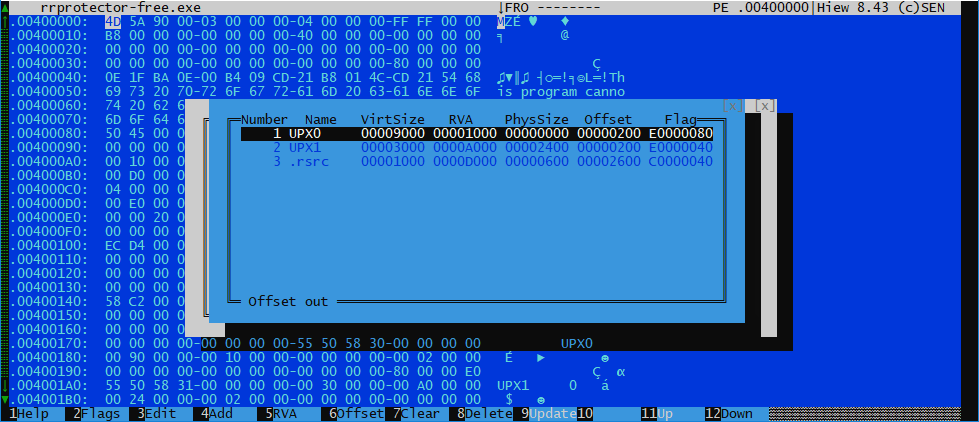
Запускаем x64dbg, дампим после распаковки, смотрим, что внутри на самом деле:
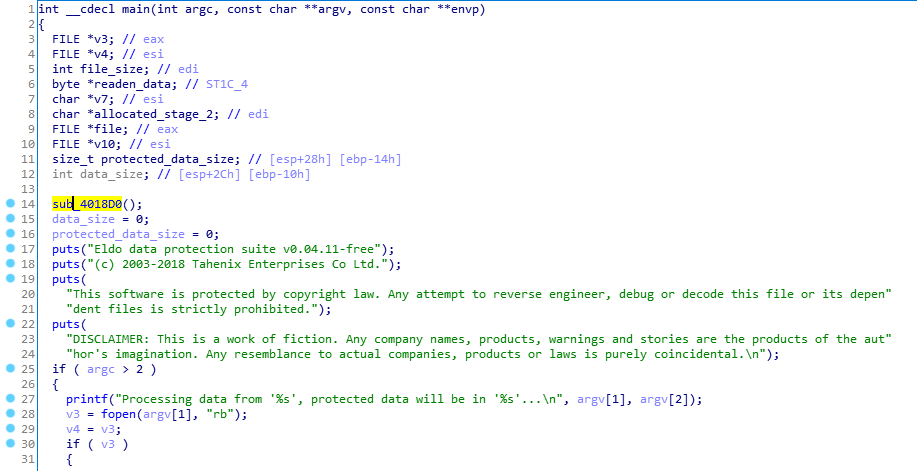

Берем имя файла из аргументов командной строки → открываем, читаем → шифруем первой ступенью → шифруем второй ступенью → записываем в новый файл.
Все просто, пора смотреть на шифрование.
Начнем со stage1
По адресу 0×4033f4 находится функция, которую я назвал crypt_64bit_up (позже вы поймете почему), она вызывается из цикла где-то внутри stage1

И немного кривоватый результат декомпиляции
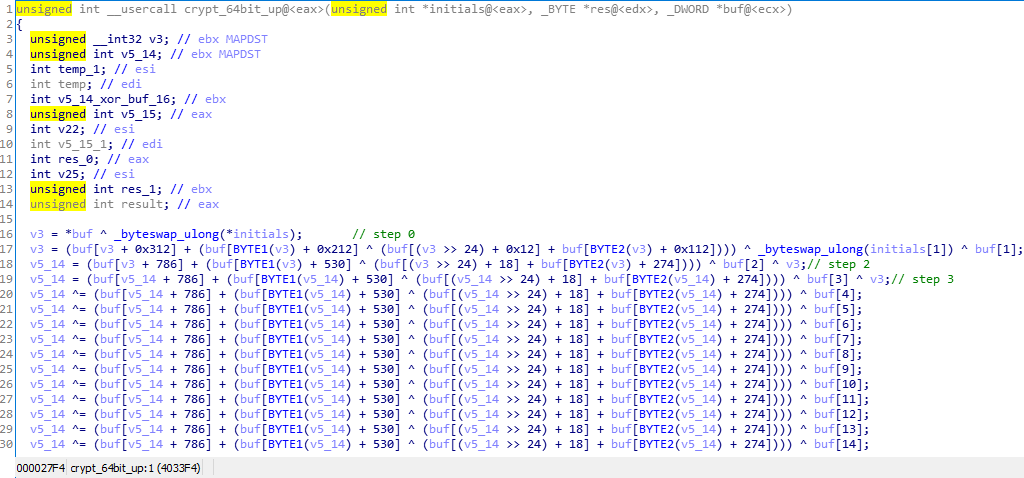
Сначала я пытался переписать этот же алгоритм на питоне, убил на это несколько часов и получилось что-то такое (что делает get_dword и byteswap должно быть понятно из названий)
def _add(x1, x2):
return (x1+x2) & 0xFFFFFFFF
def get_buf_val(t, buffer):
t_0 = t & 0xFF
t_1 = (t >> 8) & 0xFF
t_2 = (t >> 16) & 0xFF
t_3 = (t >> 24) & 0xFF
res = _add(get_dword(buffer, t_0 + 0x312), (get_dword(buffer, t_1 + 0x212) ^ _add(get_dword(buffer, t_2+0x112), get_dword(buffer, t_3+0x12))))
# print('Got buf val: 0x%X' % res)
return res
def crypt_64bit_up(initials, buffer):
steps = []
steps.append(get_dword(buffer, 0) ^ byteswap(initials[0])) # = z
steps.append(get_buf_val(steps[-1], buffer) ^ byteswap(initials[1]) ^ get_dword(buffer, 1))
for i in range(2, 17):
steps.append(get_buf_val(steps[-1], buffer) ^ get_dword(buffer, i) ^ steps[i-2])
res_0 = steps[15] ^ get_dword(buffer, 17)
res_1 = steps[16]
print('Res[0]=0x%X, res[1]=0x%X' % (res_0, res_1))
Но потом я решил обратить внимание на константы 0×12, 0×112, 0×212, 0×312 (без хекса 18, 274, 536… не очень похоже на что-то необычное). Пробуем их загуглить и находим целый репозиторий (подсказка: NTR) с реализацией функций шифрования и дешифровки, вот это удача. Пробуем зашифровать в исходной программе тестовый файл с рандомным содержимым, сдампить его и зашифровать тот же файл питонячим скриптом, все должно работать и результаты должны быть одинаковыми. После этого пробуем его расшифровать (я решил не вдаваться в детали и просто скопипастить функцию расшифровки из исходников)
def crypt_64bit_down(initials, keybuf):
x = initials[0]
y = initials[1]
for i in range(0x11, 1, -1):
z = get_dword(keybuf, i) ^ x
x = get_buf_val(z, keybuf)
x = y ^ x
y = z
res_0 = x ^ get_dword(keybuf, 0x01) # x - step[i], y - step[i-1]
res_1 = y ^ get_dword(keybuf, 0x0)
return (res_1, res_0)
def stage1_unpack(packed_data, state):
res = bytearray()
for i in range(0, len(packed_data), 8):
ciphered = struct.unpack('>II', packed_data[i:i+8])
res += struct.pack('>II', *crypt_64bit_down(ciphered, state))
return res
Важное замечание: ключ в репозитории отличается от ключа в программе (что вполне логично). Поэтому после инициализации ключа я его просто сдампил в файлик, это и есть buffer/keybuf
Переходим ко второй части
Тут все намного проще: сначала создается массив уникальных char размером 0×55 байт в диапазоне (33, 118) (printable chars), затем 32-битное значение упаковывается в 5 printable chars из массива, созданного ранее.
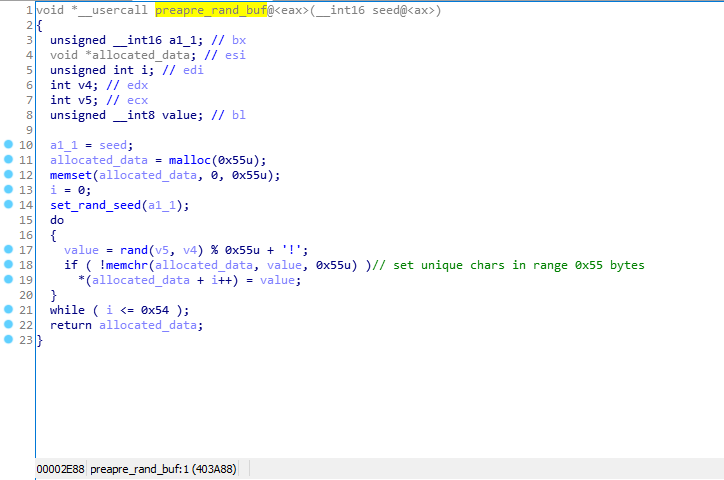
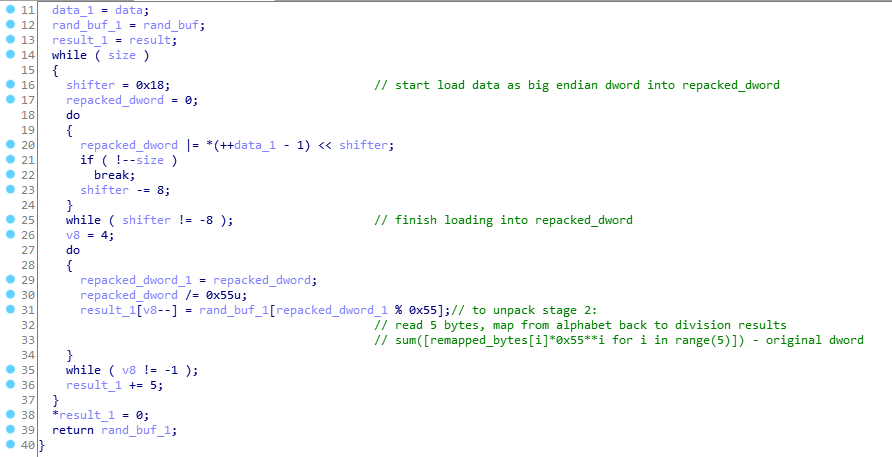
Так как никакого рандома при создании массива упомянутого выше нет, при каждом запуске программы этот массив будет одинаковым, дампим его после инициализации и простой функцией можем распаковать stage_2
def stage2_unpack(packed_data, state): # checked!
res = bytearray()
for j in range(0, len(packed_data), 5):
mapped = [state.index(packed_data[j+i]) for i in range(5)]
res += struct.pack('>I', sum([mapped[4-i]*0x55**i for i in range(5)]))
return res
Делаем что-то такое:
f = open('stage1.state.bin', 'rb')
stage1 = f.read()
f.close()
f = open('stage2.state.bin', 'rb')
stage2 = f.read()
f.close()
f = open('rprotected.dat', 'rb')
packed = f.read()
f.close()
unpacked_from_2 = stage2_unpack(packed, stage2)
f = open('unpacked_from_2', 'wb')
f.write(unpacked_from_2)
f.close()
unpacked_from_1 = stage1_unpack(unpacked_from_2, stage1)
f = open('unpacked_from_1', 'wb')
f.write(unpacked_from_1)
f.close()
И получаем результат

