Репликация ClickHouse без костылей: ожидание и реальность
Про ClickHouse есть много разной информации, но мало про то, как готовить инфраструктуру с ним. Мы потратили примерно полгода вялого набивания шишек, чтобы это заработало именно так, как нас наконец-то устраивает. Нужно было найти конфигурацию эффективную и в плане денег, и в плане работы базы как таковой.
На момент написания статьи хранилищем и результатами его работы пользуются 16+ команд (11+ аналитиков и 2 data scientist, 70+ разработчиков, руководители и менеджерский состав).
Ежесуточно в хранилище поступает ~1,2 ТБ данных, пользователи и автоматика для построения отчётности генерируют ~35 000 запросов в сутки на выборки различной сложности. Подробнее про наше хранилище и то, какие задачи для бизнеса им решаем, можно почитать по ссылке.
Мы прошли путь от СlickНouse as a service у облачного провайдера к своей инсталляции, и до недавнего времени у нас уже более года существовал кластер ClickHouse из пяти нод без репликации и был развёрнут на гиперконвергентной инфраструктуре с гибридными дисками (SSD в качестве кеша + HDD), у инсталляции был ряд проблем:
- Был риск потери данных в случае выхода из строя одной из нод.
- Отсутствовала удобная схема репликации данных.
- Непредсказуемое поведение по производительности дисков и влияние на другие виртуальные машины, развёрнутые на кластере, нужна была большая изоляция аналитической нагрузки от других сервисов компании.
Большинство данных, которые хранились в ClickHouse, мы в случае потерь могли восстановить из других источников (OLTP-баз данных или S3), но это потребовало бы значительного времени, по нашим оценкам, около 1 недели, потому как при потере одного сервера из кластера нужно было бы восстанавливать весь объём данных, что конечно же ни нас, ни бизнес не устроило.
К этому моменту у нас был механизм бекапов данных из ClickHouse, который работал не всегда стабильно, но даже если бы работал — мог гарантировать восстановление кластера в течение 1–2 суток, но при этом нам пришлось бы перезапускать все ETL и ELT-процессы, чтобы записать данные повторно с момента создания бекапа и до выхода из строя кластера, что заняло бы тоже значительное время.
Поэтому было решено использовать механизмы репликации в ClickHouse, которые имеют существенные сложности в использовании, с точки зрения разработчика, если вы привыкли к зрелым RDBMS, таким как PostgreSQL и MySQL.
Аналитическая нагрузка от ClickHouse мешала работе сервисов, которые чувствительны к latency, поэтому было принято решение, сразу выносить в отдельный контур на отдельные сервера. Изоляции, которая предлагалась на основе гиперконвергентной инфраструктуры, нам было недостаточно. Не хватало производительности гибридных дисков (SSD + HDD), хотели перейти на SSD only.
К текущему моменту мы понимали, что новая инсталляция хранилища будет существовать минимум пару лет. У нас есть выстроенная команда, поддерживающая парк серверов, в связи с этим разворачивание ClickHouse на наших железных серверах было экономически выгодным. Мы не рассматривали разворачивание в облаках основной инсталляции, но хотели бы иметь возможность расширить нашу инсталляцию, если такая потребность возникнет. Также по нашему опыту на обслуживание собственных серверов приходится тратить меньше времени, чем на решение проблем и разных спецэффектов в облаках.
Для защиты от рисков и ухода от проблем мы рассматривали разные варианты конфигурации ClickHouse и то, где всё это будет жить. Мы хотели подобрать решение, чтобы не пришлось переделывать через полгода и снова возвращаться к этому вопросу, потому как хранилище достаточно консервативное решение из-за многих связей с ним, которые появляются в процессе использования.
Как было описано выше, мы остановились на своих железных серверах, так как для нас это было экономически выгодным решением и исключало проблемы производительности, с которыми мы столкнулись ранее.
Мы заранее понимали, что у нас экспертов по ClickHouse будет один-два, а пользователей будет 40–50. Мы хотели изолировать знания об инфраструктуре, кластере и его топологии от обычных пользователей. Если нужно просто создать табличку — вот вам простая команда, вы её делаете через SQL и не знаете, как кластер в динамике меняется. Классические базы данных изолируют этот уровень и дают удобный инструментарий, чтобы отделить роль человека, который поддерживает инфраструктуру и пользуется инфраструктурой. Вся нужная информация есть в документации, но из неё сложно вытаскивать точечно куски — потому что документации очень много, а не потому что она плохая. И документация предполагает, что ты — эксперт, через пару неделек ковыряния можно выйти со знанием. Но наши пользователи не должны так делать. Для них у нас есть инструкция, которую можно впитать за 1 час, и работать спокойно.
И тут у ClickHouse есть две фишки, которые решают эти потребности.
- Использование крутого механизма ON CLUSTER, который развивается и во многом абстрагирует пользователя от понимания топологии кластера. Например, при создании таблиц не нужно самому выполнять запрос на всех нодах кластера.
- Использование distributed-таблиц, когда пользователь может обращаться к одной таблице на любой из нод кластера и получать все необходимые данные по этой таблице со всего кластера, так как под капотом ClickHouse сам всё сделает.
Смотрим хорошие практики
На момент создания кластера мы нашли только опыт компаний, которые предлагали использовать круговую репликацию. И такой подход предполагал, что коду, который пишут разработчики и аналитики вне команды, которая поддерживает хранилище, нужно было знать топологию кластера, распределение нод по физическим серверам. Что нас в корне не устраивало, потому как мы стремимся снижать порог входа для пользователей хранилища.
Вкратце репликация выглядит так: данные с первой ноды должны реплицироваться на вторую, со второй на третью и так далее.
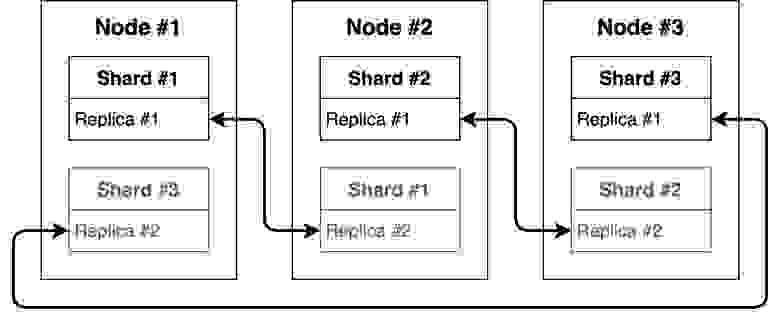
У нас уже был опыт использования такого подхода и с ним были неудобства.
- Для хранения реплик на одном сервере нужно использовать разные базы (такая конфигурация хорошо описана в упомянутой статье выше). Мы не можем создать реплицируемые таблицы в одной базе, так как основная таблица на одном шарде будет находиться по одному пути с репликой соседнего шарда. Для решения такой проблемы нужно разместить таблицы в разных базах, создать на каждой ноде по две базы, в одной из которых будут храниться данные конкретного шарда, а в другой — реплика соседнего шарда.
Выглядеть будет примерно так:
- Shard #1
- db_shard_1
- db_shard_2
- Shard #2
- db_shard_2
- db_shard_3
- Shard #3
- db_shard_3
- db_shard_1
Создавать такие таблицы придётся на каждом шарде в отдельности.Пример запросов создания таблиц для Shard #1:
CREATE TABLE db_shard_1.test_table_shard ( id UInt32, name String, cdate DateTime ) ENGINE ReplicatedMergeTree('/clickhouse/tables/db_shard_1/test_table_shard', 'replica_1') ORDER BY (id) PARTITION BY (cdate); CREATE TABLE db_shard_2.test_table_shard ( id UInt32, name String, cdate DateTime ) ENGINE ReplicatedMergeTree('/clickhouse/tables/db_shard_2/test_table_shard', 'replica_2') ORDER BY (id) PARTITION BY (cdate);
Минус такого подхода ещё в том, что все созданные реплицируемые таблицы в кластере будут находиться только в определённых БД. Нет возможности ограничить права доступа к определённым базам. - Shard #1
- Для создания distributed-таблицы поверх реплицируемых таблиц в качестве параметра конфигурации нужно указать название базы и таблицы, которые должны быть одинаковыми на всех нодах. Чтобы это заработало, нужно определить дефолтную базу данных для каждой ноды в шарде, сделать это можно добавив в конфигурацию каждой ноды параметр
... После определения default_database, при создании distributed-таблицы можно не указывать название базы, так как значение подставится из конфига.
CREATE TABLE default.test_table ( id UInt32, name String, cdate DateTime ) ENGINE = Distributed('test_cluster', '', 'test_table_shard', rand()); - При создании таблиц можно использовать макросы с определёнными значениями для каждой ноды.
- Макросы, добавленные разработчиками:
- {database} — раскрывается в имя базы данных.
- {table} — имя таблицы.
- Макросы, добавленные нами (администраторами хранилища) в конфиг:
- {shard} — идентификатор шарда.
- {replica} — имя реплики.
Такие макросы удобно использовать для создания таблиц с использованием ON CLUSTER, можно выполнить один запрос, и на всех нодах будут созданы необходимые таблицы. Но при круговой репликации есть проблема, так как таблицы лежат в разных базах, предположительно, такой запрос должен создать все необходимые таблицы:CREATE TABLE test_table_shard ( id UInt32, name String, cdate DateTime ) ENGINE ReplicatedMergeTree('/clickhouse/tables/{database}/{shard}/{table}', '{replica}') ORDER BY (id) PARTITION BY (cdate);
Но мы получим предупреждение, что нужно явно указать базу, в которой создаётся таблица, в связи с этим нет возможности одним запросом создать все необходимые таблицы.Code: 371, e.displayText() = DB::Exception: For a distributed DDL on circular replicated cluster its table name must be qualified by database name. (version 21.4.3.21 (official build))Можно, конечно, выполнить запрос на каждой паре реплицируемых нод, но для этого нужно знать топологию кластера.
- Макросы, добавленные разработчиками:
- Для восстановления ноды требуется много ручных действий. Основное неудобство заключается в том, что нет возможности вытащить актуальные метаданные таблиц из
/var/lib/clickhouse/metadata/с соседней ноды, так как нет ещё одной ноды, на которой были бы созданы точно такие же таблицы. Приходится смотреть конфигурацию и в соответствии с ней править метаданные для новой ноды. - При добавлении новой ноды нужно будет вручную перенести реплики, чтобы не было ситуации, что две реплики находятся на одном сервере. Получится, что реплика для Shard #3 переедет с Node #1 на Node #4.
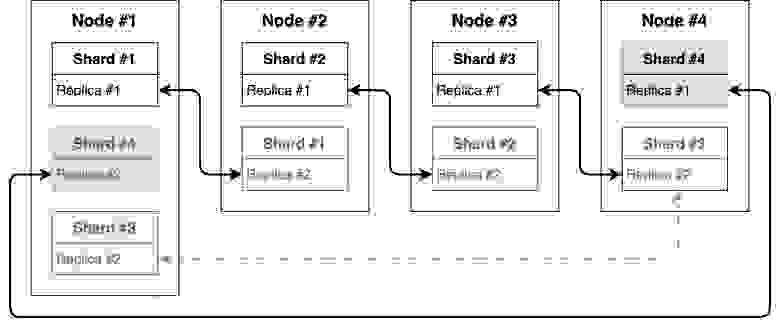 Есть сложность ещё и с решардингом партиций, так как ClickHouse не предоставляет это в автоматическом режиме. Для этих целей можно воспользоваться утилитой СlickНouse-copier (её уже немного упоминали на Habr: один, два). Есть ещё один подход, немного о нём ниже.
Есть сложность ещё и с решардингом партиций, так как ClickHouse не предоставляет это в автоматическом режиме. Для этих целей можно воспользоваться утилитой СlickНouse-copier (её уже немного упоминали на Habr: один, два). Есть ещё один подход, немного о нём ниже.
Наша конфигурация
Напомню, мы остановились на своих железных серверах, так как для нас это было экономически выгодным решением. И с учётом выше описанных ограничений было принято решение использовать виртуализацию. Поселить на каждый из серверов по две виртуальные машины с ClickHouse. Разместив так, чтобы реплики жили на разных физических хостах. Мы понимали, что таким решением мы теряем часть мощностей, но мы сделали упор на простоту для пользователей и эксплуатацию, а не оптимизировали потребление ресурсов.
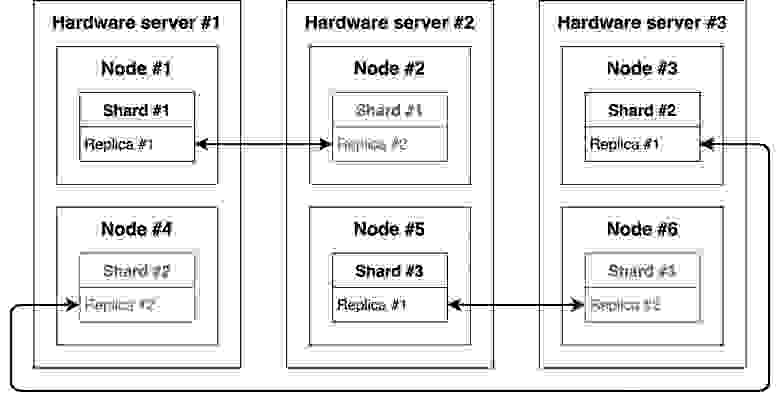
Это решение очень похоже на пример с круговой репликацией, , но для нас есть свои плюсы.
- Для каждой таблицы или нескольких таблиц можно создавать свои базы. Помимо того, что становится удобнее с ними работать, появляется возможность ограничивать права доступа доступа к определённым базам.
- При использовании ON CLUSTER таблицы будут созданы сразу на всех нодах кластера.
Запрос создания реплицируемой таблицы выглядит так:
CREATE TABLE test_database.test_table_shard ON CLUSTER test_cluster ( id UInt32, name String, cdate DateTime ) ENGINE ReplicatedMergeTree('/clickhouse/tables/{database}/{shard}/{table}', '{replica}') ORDER BY (id) PARTITION BY (cdate);
Макросы, используемые в запросе выше, на одной из нод:- {shard} = 1.
- {replica} = node-1.
С distributed-таблицей аналогичная ситуация:
CREATE TABLE test_database.test_table ON CLUSTER test_cluster ( id UInt32, name String, cdate DateTime ) ENGINE = Distributed('test_cluster', 'test_database', 'test_table_shard', rand()); - Для восстановления ноды нам нужно сконфигурировать сервер и перенести на него метаданные (
/var/lib/clickhouse/metadata/) с оставшейся живой реплики. Запустить ClickHouse, дальше он сам создаст все необходимые базы, таблицы и зальёт данные. - При добавлении новой ноды нам не нужно будет переносить отдельно реплики таблиц, мы можем просто погасить одну виртуальную машину и перенести её на новый сервер. Получится, что виртуальная машина Node #4 переедет с Hardware server #1 на #4.
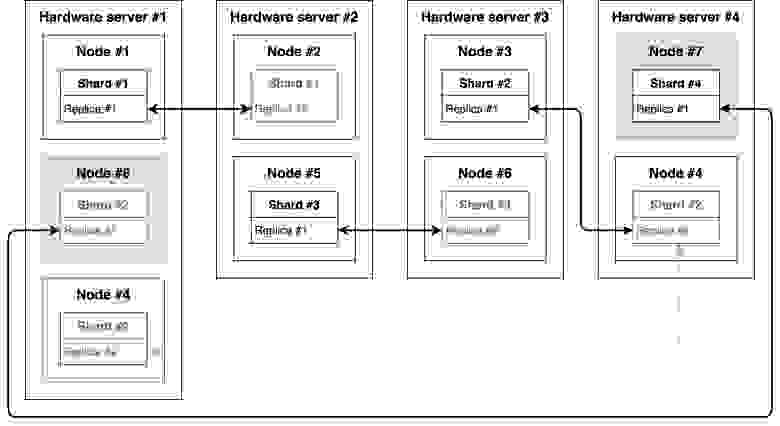
В дополнение получили увеличение скорости работы за счёт SSD only, обновились с версии 20.9.3.45 на 21.4.3.21 и получили новые фичи.
После переезда на SSD бекап также стал работать стабильнее.
- Стабилизировать бекап.
- Добавить аутентификацию через AD.
- Обновиться на самую свежую версию и наладить регулярные обновления.
