Релиз без ошибок. Невозможное возможно?

Привет! Меня зовут Сергей, я технический эксперт в компании Bercut. Когда-то увлекался Delphi и J2ME, издал несколько книг на эти темы, а сейчас создаю высоконагруженные приложения для баз данных.
Первой СУБД, с которой я познакомился — случилось это в далеком 2002 году, — была PostgreSQL. Тогда я, студент 4-го курса ТИУ, должен был разработать систему электронного документооборота для университета. Система представляла собой WEB-приложение, написанное на языке C, работающее на сервере под ОС UNIX и хранящее информацию в PostgreSQL. С тех пор мое основное поле деятельности — базы данных. А PostgreSQL стала одной из самых популярных СУБД в мире.
В Bercut мы занимаемся разработкой и развитием IT-продуктов, решений для операторов цифровых услуг и мобильных сервисов. Наши системы работают на различном железе, разных СУБД и обслуживают 24×7x365 в режиме онлайн сотни миллионов абонентов по всему миру.
Сегодня мы обсудим, как создавать максимально качественное ПО, содержащее в себе минимальное количество ошибок. Такое ПО, что ошибки никак не проявляются и потому можно считать, что их нет совсем.
«Любая, даже самая простая программа содержит как минимум одну ошибку».
Закон Мерфи
Ошибки бывают разные. Одни приводят к полной остановке всей системы и того, что с ней связано. Другие — к проблемам конкретных пользователей (количество которых может измеряться десятками или тысячами). Третьи вообще никак не проявляются, либо ни на что не влияют. Если ошибки не найдены, это не значит, что их нет совсем. Это может означать одно из двух: либо их не искали, либо абсолютно все, что есть важное в системе, работает как надо.
Так вот, мы выпустили релиз, у которого на приемке и при дальнейшей эксплуатации заказчиком не было найдено ни одной ошибки. Чтобы вы понимали, система содержит десятки тысяч процедур, работает с тысячами таблиц в нескольких базах данных. Обслуживает миллионы абонентов. Ни одной ошибки. В очередной раз. Заказчик месяц тестирует наш новый релиз, затем эксплуатирует его на проде, и ни одной ошибки. Но как?
Немного из личной истории
Много лет назад я работал в одном крупном банке, где в качестве банковской информационной системы (БИС) применялась система, разработанная сторонней компанией. Подрядчик выпускал 2 релиза в год, и их ПО использовалось в нескольких банках. Мы, айтишники, тестировали, выполняли небольшие доработки (кастомизацию), настройки, прикручивали новую функциональность. Сбои и ошибки в работе БИС — это плохо для репутации банка. Чтобы снизить вероятность проникновения с новым релизом ошибок в прод, у нас имелся целый комплекс действий:
Мы всегда ставили на продуктив не последний, а предпоследний релиз, со всеми патчами к нему. Пусть у компании-разработчика будет дополнительные полгода времени, чтобы найти и исправить как можно больше проблем.
Релиз ставился на тестовые БД, и мы выполняли полное тестирование системы в течение месяца. Несмотря на то, что разработчик его уже протестировал. Буквально на первых же тестах ловили стоповые ошибки — не работает то прием платежа, то гашение кредита, то еще что. Эксплуатация системы в таком случае невозможна. А как же другие банки на этом полгода работали?! Оказывается, у них слегка другие настройки, и потому баги не проявлялись.
После месяца тестирования и десятков заведенных заявок, мы ожидали очередных исправлений, после чего повторяли тестирование с самого начала. Находили еще несколько новых ошибок. Заводили заявки, ждали исправления. Убедившись, что все работает, устанавливали релиз на продуктив и опять ловили ошибки… Конечно, они уже не были стоповыми, с ними можно было работать. Но все равно неприятно.
То есть как бы мы не тестировали, ошибки все равно появлялись. Почему так происходит?
Посмотрим на ситуацию с разных сторон.
Взгляд разработчика
Допустим, разработчик написал процедуру p1. Ее нужно протестировать; на это он потратил время t1. Затем разработчик написал процедуру p2 (вызывающую процедуру p1), затраты на ее тестирование составили t2. И таких процедур 9 штук. Суммарные затраты времени на тестирование составили t1+t2+t3+t4+t5+t6+t7+t8+t9.
Затем при разработке процедуры p10 разработчик обнаружил, что процедура p1 в таком виде, как она есть, слегка не подходит. Нужно ее чуть-чуть доработать. Как вариант, там нашлась незначительная ошибка. Доработал. Теперь ему нужно перетестировать все процедуры с 1-й по 9-ю. Тогда трудозатраты на тестирование составили t1+t2+t3+t4+t5+t6+t7+t8+t9 + t1+t2+t3+t4+t5+t6+t7+t8+t9+t10. Они удвоились, хотя была написана всего одна небольшая процедура и внесена незначительная правка в существующую процедуру. Так сказать, красоту навели. Есть ли у разработчика столько времени на тестирование? Конечно, нет. А может, процедуру p10 писал разработчик, который вообще не знает о существовании процедур p2…p9. Потому протестируем заново процедуры p1 и p10, а остальные, будем надеяться, работают. Или? А вот и нет, все они находятся в зоне риска, хотя большинство из них работает корректно. Но, вероятно, не все. Ведь бывает, что разработчик, устранив одну ошибку, внес при этом две-три новых.
Действуя таким образом, получим ли мы систему с нулем ошибок? Нет. Но как все это протестировать, уложиться во время и ничего не сломать? На помощь приходят модульные тесты. Для каждой процедуры пишется набор модульных тестов. Тест вызывает процедуру с различными наборами входных данных и проверяет результат ее работы на соответствие ожиданиям.
Предположим, имеются модульные тесты для всех процедур p1…p9. Тогда, доработав p1 и создав p10, разработчик пишет новый тест для p10 и правит тест для p1. Тесты для остальных процедур просто запускает и проверяет результат.
Если все тесты успешно проходят, то он, может быть, ничего не сломал. Стоп, почему не «не сломал», а «может быть, ничего не сломал»? Сколько раз мы употребили слово «может» и сколько это «может» будем нам стоить?…
Взгляд пользователя
Кто знает, что поменял в коде разработчик? А ведь, как выяснили ранее, от этого может вообще все посыпаться. Нужно ли теперь перетестировать систему целиком? А она же не одна в вакууме, она взаимодействует с другими системами, нужно ли перетестировать еще и их?
Система содержит много процедур, но пользователи об этом ничего не знают и знать не хотят. Есть конкретные бизнес-процессы и они должны работать в соответствии с ожиданиями пользователя. Значит и тестировать нужно бизнес-процессы, а не процедуры.
Получается, модульные тесты не нужны? Нужны, но не стоит их переоценивать. Польза от них есть, модульные тесты должны быть, но не на все подряд процедуры, а только на наиболее критичные. Польза от функциональных тестов гораздо больше, к тому же при доработке ПО править существующие функциональные тесты приходится крайне редко. Если же была изменена процедура, то ее модульные тесты потребуют доработки. По аналогии со строительством — если мы проверим, что абсолютно все кирпичи, из которых нужно построить дом, имеют идеальную форму и размер, это не означает, что мы точно построим из них «правильный» дом. Придется проверить, что стены ровные, есть крыша, есть дверь, она открывается, через нее можно войти, есть окна и еще много всего. При этом даже если некоторые кирпичи не идеальной формы или размера, вполне возможно построить хороший дом.

Приведем пример бизнес-процесса.
Если абонент пополнил баланс, то ему приходит уведомление с указанием правильной суммы. Если пришло время, списывается абонентская плата. Происходит разблокировка сервисов, если был блок из-за неоплаты и т.д. Зайдя в личный кабинет, абонент должен увидеть сумму на балансе и операцию пополнения. Вот бизнес-процесс, и он проверяется функциональным тестированием. Функциональное тестирование может быть как ручным, так и автоматическим. Ручной тест один раз пройти проще, чем написать автотест (АТ). Но проверенное вручную очень просто испортить очередной правкой, и всё придется тестировать заново, если о правке стало известно. А если нет? Тогда ошибку, вполне вероятно, найдет уже заказчик. Если же есть АТ, который регулярно запускается, то как только функциональность будет сломана разработчиками, тест начнет падать. А значит проблема обнаружится моментально и будет устранена до отгрузки заказчику.
Рассмотрим, как происходит разработка ПО. Итак, все начинается с того, что заказчику потребовалась новая функциональность.
Проектирование
В игру вступает команда аналитиков.
Уже на этапе написания технического проекта аналитики закладывают в систему отказоустойчивость. Проектируются некие «рубильники», которые позволяют даже после установки ПО на среду заказчика отключать доработанные изменения логики. Тем самым в случае критичных ошибок с помощью настроек можно «откатиться» к старой версии без физического отката патча. Также в техническом проекте встречаются фразы типа «если подключена услуга X (такого быть не может), то: залогировать ошибку, заказать отключение услуги X». Теперь, если есть незначительные баги, были небольшие сбои или кто-то вручную слегка проапдейтит данные в БД, система все равно будет работать корректно. Речь именно про несанкционированные изменения, которые выполнил кто-то из специалистов заказчика, используя сторонние средства. Пользовательский интерфейс проектируется так, чтобы сделать с его помощью недопустимые вещи было нельзя. Конечно, это не спасет, если баги большие или кто-то сильно попортил данные.
Для качественного проектирования новой функциональности, аналитики должны хорошо знать, что уже есть в системе. Что и как работает. Для этого необходима качественная документация, включающая в том числе историю проектирования. Чтобы можно было ответить на вопрос — кто когда и почему поменял структуру такого-то объекта.
У аналитиков имеется библиотека элементов разработки, которую они переиспользуют для повышения скорости и качества проектирования.
Проект структурируется по уровням:
требования;
use case;
через что use case реализуется;
дельта изменений элементов разработки;
элемент разработки (таблица, алгоритм, UI форма, отчет, сервис и пр.).
В результате этой работы:
экономим время на этапе проектирования за счет описанной модели системы;
снижаем сроки выполнения проектирования;
структурируем результат аналитической работы;
снижаем неопределенность в системе и задаче.
После написания технического проекта мы проводим встречу, на которой аналитик рассказывает, что требуется заказчику и как решено это сделать.
Разработка
Теперь на поле выходит группа разработки.
Разработчики должны хорошо знать, что уже есть в системе и в инструментах, используемых в работе. Чтобы постоянно не изобретать велосипед, а переиспользовать уже имеющиеся возможности. Так будет быстрее, качественнее и надежнее. Ведь уже имеющийся код когда-то был написан, затем протестирован и функционально и нагрузочно. А то, что будет написано новое, должно пройти все стадии с самого начала.
Самоконтроль и самодокументирование
Разработчики пишут код, учитывают ТП, логируют так, чтобы по логу можно было моментально найти строку кода и понять весь стек вызовов, а также значения всех важных переменных. Для этого есть система логирования и трассировки.
Каждая процедура, вызывая другие процедуры, контролирует результаты их работы: отработали успешно либо вернули ошибку. В код закладываются элементы самодиагностики. Например, в процедуру не передали обязательный параметр, либо передали что-то не то. Либо, исходя из логики, мы должны были пойти по одной из двух веток, а не попали ни в одну из них.
Увы, в отличие от аналитиков разработчики зачастую не видят бизнес-процесс целиком. Только часть, но зато в этой части они имеют бОльшую детализацию. В процессе работы, разработчики постоянно взаимодействуют друг с другом, а также с аналитиками и тестировщиками.
Разработчики должны писать грамотный, надежный и понятный код. Для этого у них есть стандарт разработки. Плюс все постоянно повышают свою квалификацию, как через обмен опытом между собой, так и через различные курсы и митапы, взаимодействие с другими командами.
Стандарты
Хороший код — код, понятный без комментариев. Но комментарии должны быть. Они поясняют даже не то, что мы делаем (ведь код несложный), а почему мы это делаем. Никаких процедур длиной в 10 000 строк — в такой процедуре никто никогда не разберется. Никаких 10-ти уровней вложенности условных операторов, по 5 экранов каждый. Скажем «нет» переменным с названием v_flag или v_number! Название должно говорить, что за переменная перед нами и для чего она нужна. Вот нормальное имя переменной: v_is_no_money. Хорошее форматирование. В качественном, простом коде и ошибиться сложнее, и ошибку найти проще.
#define _ -F<00||--F-OO--;
int F=00,OO=00;main(){F_OO();printf("%1.3f\n",4.*-F/OO/OO)'}F_OO()
{
_-_-_-_
_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_
_-_-_-_
}Выше — «круглая программа» расчета числа пи на языке C; иллюстрация того, как нельзя программировать. Выглядит красиво, но непонятно, что и как она делает. Доработка крайне проблематична (взято с просторов Интернета, ссылку уже не найти).
Проверки
Код написали, сделали новые модульные тесты, запускаем их все — если они прошли, процедура работает как надо. А еще есть тесты на соответствие кода стандарту разработки. Например, разработчик в своем коде не должен вызывать commit или rollback, а если вызвал — один из тестов на соответствие стандарту разработки будет провален.
Странное требование, правда? Это только на первый взгляд. Разработчик должен вызывать не напрямую commit или rollback, а разработанные нами процедуры commit_work или rollback_work, каждая из которых уже и вызывает commit или rollback. Если это допустимо. А почему может быть не так? Потому что если это не настоящая работа системы, а отладка кода разработчиком, то выполнив commit, он испортит тестовые данные. Какова вероятность, что с первого прохода отладки разработчик поймет, в чем проблема, и устранит ее, не создав новых ошибок? Близка к нулю. А на подготовку тестовых данных заново нужно время. Если данные готовятся АТ, то нужно где-то полминуты на запуск теста. А если данные готовились вручную? Может полчаса, а может полдня. Это на один раз, а по моему опыту, до полного понимания проблемы и ее успешного устранения в среднем выполняется около пяти сеансов отладки. Обычно сразу примерно понятно, в какой процедуре ошибка — там ставится точка останова и в ней проверяется, ошибка возникла или еще нет. Затем прерываем этот сеанс отладки, запускаем новый. Значит, закоммитив при отладке, мы можем потерять от нескольких минут до 2.5 рабочих дней. А в итоге может не хватить времени на тестирование. Поэтому в режиме отладки все commit в коде отключаются, а по ее завершении выполняется rollback. Также крайне важно корректное управление транзакциями с точки зрения бизнес-процесса.
К моменту завершения разработки уже имеется несколько smoke-автотестов на наиболее критичные для новой функциональности кейсы. Разработчик запускает их, убеждается, что система работает как задумывалось. Причем сначала просто запускает, чтобы проверить, упадут тесты или нет, а затем второй раз уже в режиме отладки проходит через весь бизнес-процесс. Так разработчик улучшает свое понимание кода, технического проекта и бизнес-процесса. Может увидеть и исправить проблемные места.
При работе с кодом разработчик обращает внимание на предупреждения компилятора.
В коде выполняется неявное приведение типов? А разработчик точно хотел приведение типов сделать? Если да, нужно использовать соответствующую функцию, чтобы не было проблем с форматами даты/числа, с невозможностью использования индекса в SQL-запросе и т.д.
Присваиваемая, но не используемая переменная? А что разработчик забыл сделать — удалить ее объявление и присвоение или применить ее в логике процедуры?
К объявленной, но не используемой переменной — те же самые вопросы.
Неиспользуемый параметр процедуры? Аналогично.
После компилятора при помощи специальных инструментов выполняется сканирование кода на уязвимости и потенциальные ошибки/неоптимальные конструкции.
Выполняя фиксацию разработанного кода в репозитории, разработчик обязательно просматривает все изменения. Убеждается, что закоммичено будет именно то, что он хотел написать, и ничего больше. Просто коммитить, не ознакомившись с изменениями, нельзя. Потому как в репозиторий может попасть тестовый код, который разработчик изначально добавлял, чтобы было легче проверить корректность какой-то процедуры, но потом забыл удалить. Или часть разработанного кода может не попасть. Не забываем также, что разработчиков много, и бывает, что они одновременно редактируют один и тот же файл, а иногда даже одну и ту же процедуру в нем. Все это может быть автоматически либо вручную слито в репозиторий, но в любом случае нужно внимательно просмотреть, что в итоге идет в GIT, и убедиться, что результаты не ломают логику. Но изначально при распределении работ между различными разработчиками нужно стремиться к тому, чтобы число таких пересечений стремилось к нулю.
Ревью
Сделал сам — помоги покажи другому. Разработчику мало написать код, который ему нравится, нужно, чтобы он понравился и другим разработчикам. А еще аналитикам и тестировщикам. Для этого, после написания кода, делается его ревью: обсуждаются особенности реализации проекта, спорные моменты, правятся замечания. Обычно код показывают другим специалистам, работающим над этим же техническим проектом. Так каждый расширяет кругозор, начинает понимать не только свою часть кода, но бизнес-процесс целиком. А значит, меньше шансов сделать что-то не так. Без ревью в том числе возрастает риск, что ошибка закрадется где-то на стыке кода нескольких разработчиков.
Когда все работы завершены, можно формировать предварительный патч, который уйдет на тестирование.
Функциональное тестирование
Пришла очередь функционального тестирования.
Стоп, а кто сказал, что группа тестирования работает после разработчиков? Мы же хотим работать не только качественно, но и быстро, потому все работают параллельно и одновременно. Во время разработки происходит подготовка к тестированию, составляется методика, пишется продукт для АТ и smoke-тесты, а по готовности сборки команда приступает к непосредственному прохождению тест-кейсов.
Прежде всего у нас имеется требование — при разработке любой новой функциональности мы не должны сломать ничего старого. А чтобы мы точно не сломали, в нашем распоряжении десятки тысяч функциональных АТ. Они покрывают все бизнес-процессы каждой из наших систем, все хоть сколько-нибудь значимые кейсы. Имитируют при помощи настоящих процедур системы, которые работают в реальности, все возможные ситуации. Проверяют, что результат именно такой, какой должен быть. Также проверяют, что после прохождения тестов лог ошибок пустой.
Для каждой доработанной процедуры проводится анализ. Уточняется, в каких бизнес-процессах она используется, и достаточное ли у нас покрытие АТ данной функциональности.
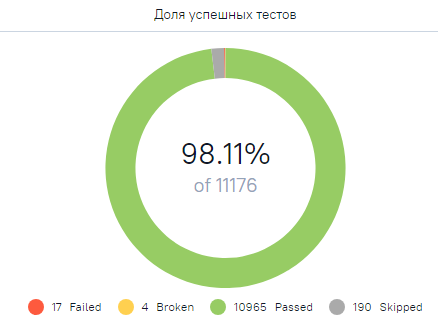
Так выглядит краткий отчет о прохождении АТ одной из наших систем.
Все имеющиеся АТ проходят успешно? Если да, то группа функционального тестирования может заниматься проверкой новой функциональности.
Но сначала мы организуем встречу, на которой разработчики расскажут, что и как они реализовали, на что нужно обратить внимание при тестировании и ответят на все вопросы аналитиков и тестировщиков.
Составляется методика тестирования, определяются тест-кейсы, им присваиваются приоритеты. При этом пишутся новые АТ на все кейсы, которые считаются важными. Таким образом количество АТ растет с каждым релизом. Из минусов — времени на их прохождение тратится все больше и больше. Но тесты у нас идут параллельно в несколько потоков, так что буквально час-два и все тесты пройдены. Конечно, если тестов будет миллионы штук, понадобится больше времени и более мощное оборудование.
Если тестирование нашло ошибку, вновь созданный АТ падает. Разработчик ее исправляет. Запускаем только что созданные 100–200 АТ на новую функциональность (а новых функциональностей в каждом релизе несколько), ждем 2 минуты — все тесты проходят успешно. Но все ли в порядке, точно узнаем завтра, после того, как ночью на последней сборке патча выполнится полный регресс АТ. Или, если срочно, можем запустить их прямо сейчас и получим результат через 1 час. Днем АТ работают еще немного быстрее, чем ночью, т.к. не проверяется красота кода (тот же коммит из примера выше), а только функциональность.
Нагрузочное тестирование

Грузите апельсины бочками.
Функционально система работает, а как дела с нагрузкой?
Для каждого бизнес-процесса проводится ряд нагрузочных тестов. Это позволяет выявить узкие места, требования к оборудованию, способность системы обработать определенный объем данных за некоторое время, определить что и как можно улучшить в быстродействии системы — снизить нагрузку на CPU, диски, память, сеть, повысить скорость обработки и т.д. Найденные проблемы производительности устраняются.
У нас имеется специальный стенд, максимально приближенный к по своим техническим характеристикам к продуктиву. Помимо ручного нагрузочного тестирования, имеется также нагрузочный регресс — набор АТ, в которых измеряется время прохождения тестов и прочие параметры на больших объемах данных.
Так, нашу систему мы проверили, но она не одна. С ней взаимодействуют другие системы, как нашего, так и стороннего производства. В других наших системах также много АТ. Они тоже постоянно запускаются.
Интеграционное тестирование
На поле выходит команда интеграционного тестирования.
На самом деле она тоже работала с самого начала, не дожидаясь окончания функционального тестирования и даже окончания разработки. Пока не было даже черновой сборки дорабатываемой системы, команда ИТ верифицировала тест-кейсы, определялась, какие системы и как будут участвовать в проверках. Настраивала тестовые контуры. Интеграционное тестирование является востребованным сервисом, позволяющим ускорять реализацию идей бизнеса для конечного пользователя (time to market). В том числе в рамках ИТ, верифицируются бизнес-настройки на тестовых средах.
Опять АТ, но АТ взаимодействия систем. Бизнес-процесс от и до, не ограничиваясь рамками одной только системы. И ручные тесты тоже. Если на этапе ФТ другие системы могли имитироваться, то здесь уже все по-настоящему. Если говорить о примере выше, то на ФТ пополняли баланс, проверяли, что он действительно пополнился, система создала заявку на уведомление, что метод, который вызывает личный кабинет возвращает корректные данные. На ИТ же осуществляется фактический вход в личный кабинет на тестовом контуре и там выполняется проверка корректности отображения. Фактически получается уведомление о пополнении баланса и т.д.
Документирование
«Предъявите документы!»
Тем временем группа технических писателей пишет пользовательскую документацию, в которой подробно рассказывается, что и как нужно настроить, как будет вести себя система, какие есть фичи и т.д.
Также как и все прочие группы, никто из технических писателей не ждет окончания работ на всех предыдущих этапах. Документация начинает готовиться еще на этапе проектирования системы. Причем процессом занимается несколько писателей и действуют они также параллельно. Сначала документ содержит только структуру заголовков, но постепенно обрастает деталями и к моменту окончания интеграционного тестирования в него вносят последние правки. У писателей есть множество источников для работы — это и технический проект и описание разработчиком созданного кода и тест-кейсы функционального и интеграционного тестирования. Материалы всех проведенных по проекту встреч. Результаты нагрузочного тестирования.
Разработанная документация читается аналитиками, разработчиками, тестировщиками. Найденные неточности и замечания устраняются. Более того, читая документацию, в теории разработчик может понять, что упустил из виду какую-то незначительную доработку, а тестировщик — что не проверил какой-то низкоприоритетный кейс. Не помню, чтобы мы на этом этапе находили какие-то ошибки, но вот предложения о том, как можно что-то улучшить, оптимизировать возникали не раз.
При качественной документации, заказчику проще настраивать и работать с ПО, количество проблем у пользователей снижается.
Убедившись, что нет сложностей на всех этапах от начала и до конца, мы отгружаем патч заказчику.
По окончании работы над релизом мы проводим ретроспективу, обсуждаем, что было сделано хорошо, что не очень, как можно улучшить процессы.
Матч завершен победой нашей команды.
Выводы
Из нашего опыта, чтобы ПО не содержало ошибок, в пристальном фокусе внимания должны быть пункты из списка:
качественное проектирование;
качественная разработка;
модульные тесты;
плотное взаимодействие команд, участвующих в проектировании/разработке/тестировании/документировании;
высокое покрытие всех бизнес-процессов функциональными АТ;
качественное тестирование всех видов: функциональное, интеграционное, нагрузочное;
постоянное увеличение количества АТ;
подробная документация, включая историю разработки той или иной функциональности;
постоянное совершенствование всех этапов процесса разработки ПО.
Все вышеописанное, контроль качества, переиспользование элементов при проектировании, разработки, тестировании, огромное количество АТ всех видов и параллельная работа всех команд позволяет нам в сжатые сроки создавать качественное ПО.
А что вы думаете по этому поводу? Пишите комментарии, будем рады узнать вашу точку зрения.
