Рекомендательные системы: идеи, подходы, задачи

Многие привыкли ставить оценку фильму на КиноПоиске или imdb после просмотра, а разделы «С этим товаром также покупали» и «Популярные товары» есть в любом интернет- магазине. Но существуют и менее привычные виды рекомендаций. В этой статье я расскажу о том, какие задачи решают рекомендательные системы, куда бежать и что гуглить.
Что рекомендуем?
Что, если мы хотим рекомендовать комфортный для пользователя маршрут? Разным пользователям важны различные аспекты поездки: наличие сидячих мест, время в пути, загруженность транспорта, кондиционер, красивый вид из окна. Необычная задача, но примерно понятно, как построить такую систему.
Что, если мы рекомендуем новости? Новости быстро устаревают — нужно показывать пользователям свежие статьи, пока они ещё актуальны. При этом необходимо понимать содержание статьи. Уже сложнее.
А если мы рекомендуем рестораны на основе отзывов? Но рекомендуем не только ресторан, но и конкретные блюда, которые стоит попробовать. Можно также давать рекомендации ресторанам о том, что стоит улучшить.
Что, если мы вообще развернем задачу и попытаемся ответить на вопрос: «Какой товар будет интересен наибольшей группе людей?». Становится совсем необычно и сходу непонятно, как такое решать.
На самом деле, существует множество вариаций задачи рекомендаций и в каждой есть свои нюансы. Рекомендовать можно совершенно неожиданные вещи. Мой любимый пример — рекомендация превьюшек на Netflix.

Более узкая задача
Возьмем понятную и привычную задачу рекомендации музыки. Что именно мы хотим порекомендовать?

На этом коллаже можно найти примеры различных рекомендаций Spotify, Google и Яндекса.
- Выделение однородных интересов в Daily Mix
- Персонализированные новинки Release Radar, Recommended New Releases, Премьера
- Персональная подборка того, что вам нравится — Плейлист Дня
- Персональная подборка треков, которые пользователь еще не слышал — Discover Weekly, Дежавю
- Сочетание предыдущих двух пунктов с уклоном в новые треки — I«m Feeling Lucky
- Находится в библиотеке, но еще не прослушано — Тайник
- Your Top Songs 2018
- Треки, которые ты слушал в 14 лет, и которые сформировали твои вкусы — Your Time Capsule
- Треки, которые, возможно, понравятся, но отличаются от того, что пользователь обычно слушает — Taste breakers
- Треки артистов, которые выступают в твоем городе
- Подборки по стилям
- Подборки по активностям и настроению
И наверняка можно придумать что-нибудь ещё. Даже если мы абсолютно точно умеем предсказывать, какие треки нравятся пользователю, все равно остается вопрос, в каком виде и в какой компоновке их выдавать.
Классическая постановка

В классической постановке задачи всё, что у нас есть — это матрица оценок user-item. Она очень разрежена и наша задача — заполнить пропущенные значения. Обычно в качестве метрики используют RMSE предсказанного рейтинга, однако существует мнение, что это не совсем правильно и следует учитывать характеристики рекомендации как целого, а не точность предсказания конкретного числа.
Как оценивать качество?
Online evaluation
Наиболее предпочтительный способ оценки качества системы — прямая проверка на пользователях в контексте бизнес-метрик. Это может быть CTR, время, проведенное в системе, или количество покупок. Но эксперименты на пользователях дороги, а выкатывать плохой алгоритм даже на малую группу пользователей не хочется, поэтому до онлайн-проверки пользуются оффлайн метриками качества.
Offline evaluation
В качестве метрик качества обычно используют метрики ранжирования, например, MAP@k и nDCG@k.





Relevance в контексте MAP@k — бинарное значение, а в контексте nDCG@k — может быть и рейтинговая шкала.
Но, помимо точности предсказания, нас могут интересовать и другие вещи:
- сoverage — доля товаров, которая выдается рекомендателем,
- personalization — насколько различаются рекомендации между пользователями,
- diversity — насколько разнообразные товары находятся внутри рекомендации.
В целом есть неплохой обзор метрик How good your recommender system is? A survey on evaluations in recommendation. Пример формализации метрики новизны можно посмотреть в Rank and Relevance in Novelty and Diversity Metrics for Recommender Systems.
Данные
Explicit feedback
Матрица оценок — это пример explicit-данных. Лайк, дислайк, рейтинг — пользователь сам явно выразил степень своего интереса к айтему. Таких данных обычно мало. Например, в соревновании Rekko Challenge в тестовых данных хотя бы одна оценка есть только у 34% пользователей.
Implicit feedback
Гораздо больше имеется информации о неявных предпочтениях — просмотры, клики, добавление в закладки, настройка уведомлений. Но если пользователь посмотрел фильм — это означает лишь то, что до просмотра фильм казался ему достаточно интересным. Прямых выводов о том, понравился фильм или нет, мы сделать не можем.
Функции потерь для обучения
Чтобы использовать implicit feedback, придумали соответствующие методы обучения.
Bayesian Personalized Ranking
Оригинальная статья.
Известно, с какими айтемами взаимодействовал пользователь. Будем считать, что это положительные примеры, которые ему понравились. Остается множество айтемов, с которым пользователь не взаимодействовал. Мы не знаем, какие из них пользователю будут интересны, а какие нет, но мы наверняка знаем, что далеко не все из этих примеров окажутся положительными. Сделаем грубое обобщение и будем считать отсутствие взаимодействия отрицательным примером.



Weighted Approximate-Rank Pairwise
Добавим к предыдущей идее adaptive learning rate. Будем оценивать обученность системы, исходя из количества семплов, которые нам пришлось просмотреть, чтобы для данной пары {пользователь, положительный пример} найти отрицательный пример, который система оценила выше положительного.
Если мы нашли такой пример с первого раза, значит штраф должен быть большой. Если пришлось долго искать, значит система уже неплохо работает и штрафовать так сильно не нужно.



О чём ещё стоит подумать?
Холодный старт

Как только мы научились делать предсказания для существующих пользователей и товаров, встаёт два вопроса: — «Как рекомендовать товар, который ещё никто не видел?» и «Что рекомендовать пользователю, у которого ещё нет ни одной оценки?». Для решения этой проблемы стараются извлечь информацию из других источников. Это могут быть данные о пользователе из других сервисов, опросник при регистрации, информация об айтеме из его содержания.
При этом существуют задачи, для которых состояние холодного старта является постоянным. В Session Based Recommenders нужно успеть понять что-то о пользователе за то время, что он находится на сайте. В рекомендателях новостей или товаров моды постоянно появляются новые айтемы, а старые быстро устаревают.
Long Tail
Если для каждого айтема посчитать его популярность в виде количества юзеров, которые с ним взаимодействовали или поставили положительную оценку, то очень часто будет получаться график как на изображении:
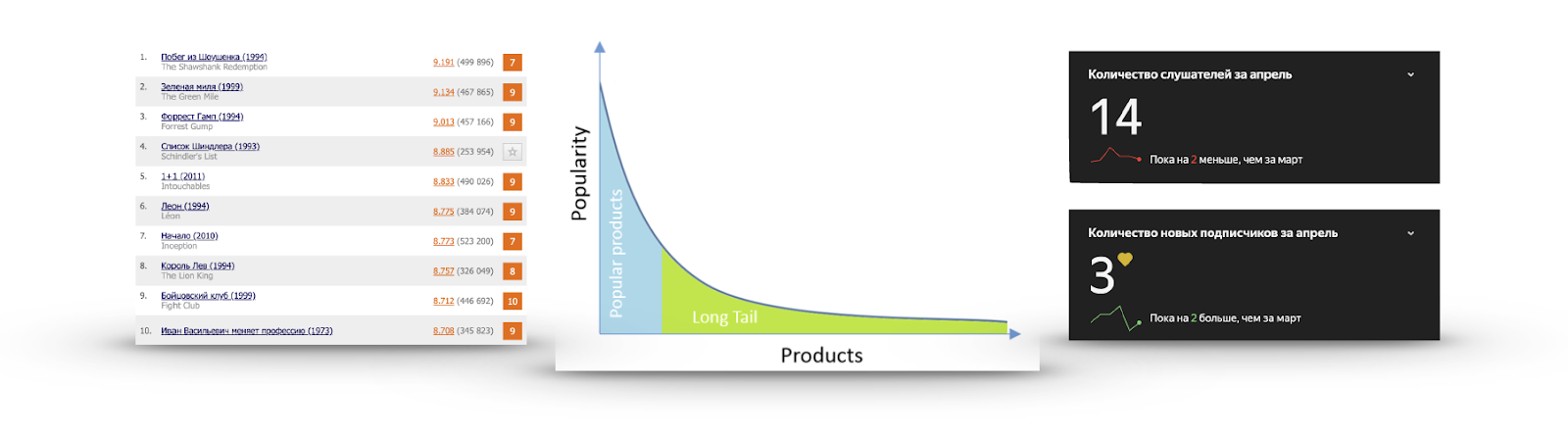
Существует очень маленькое количество айтемов, о которых знают все. Нет никакого смысла их рекомендовать, потому что пользователь, скорее всего, либо уже их видел и просто не поставил оценку, либо и так о них знает и собирается посмотреть, либо твердо решил не смотреть вовсе. Я не раз смотрел трейлер «Списка Шиндлера», но посмотреть так и не собрался.
С другой стороны, популярность очень быстро спадает, и подавляющее количество айтемов практически никто не видел. Делать рекомендации из этой части полезней: там есть интересный контент, который пользователь вряд ли сможет найти сам. Для примера — справа статистика прослушиваний одной из моих любимых групп на Яндекс.Музыке.
Exploration vs Exploitation
Допустим, мы точно знаем, что нравится пользователю. Значит ли это, что мы должны рекомендовать одно и то же? Есть ощущение, что такие рекомендации быстро наскучат и стоит иногда показывать что-то новое. Когда мы рекомендуем то, что точно должно понравиться — это exploitation. Если мы пробуем добавить в рекомендации что-то менее популярное или как-то их разнообразить — это exploration. Хочется балансировать эти вещи.
Неперсонализированные рекомендации
Самый простой вариант — рекомендовать всем одно и то же.
Сортировка по популярности

Score = (Positive ratings) − (Negative ratings)
Можно вычесть из лайков дислайки и отсортировать. Но в таком случае мы не учитываем их процентное соотношение. Есть ощущение, что 200 лайков 50 дислайков не то же самое, что 1200 лайков и 1050 дислайков.

Score = (Positive ratings) / (Total ratings)
Можно поделить количество лайков на количество дислайков, но в таком случае мы не учитываем количество оценок и товар с одной оценкой в 5 баллов будет отранжирован выше, чем очень популярный товар со средней оценкой в 4.8.
Как не сортировать по среднему рейтингу и учитывать количество оценок? Посчитать доверительный интервал: «Исходя из имеющихся оценок, с вероятностью в 95% истинная доля положительных оценок как минимум какая?». Ответ на этот вопрос дал Эдвин Уилсон в 1927 году.

 — наблюдаемая доля положительных оценок
— наблюдаемая доля положительных оценок  — 1-альфа квантиль нормального распределения
— 1-альфа квантиль нормального распределения
Совстречаемости
Выделение часто встречающихся множеств товаров включает в себя целую группу задач pattern mining: periodic pattern mining, sequential rule mining, sequential pattern mining, high- utility itemset mining, frequent itemset mining (basket analysis). Для каждой конкретной задачи будут свои методы, но если грубо обобщать, алгоритмы по поиску частых множеств выполняют сокращенный поиск в ширину, стараясь не перебирать заведомо плохие варианты.
Отсечение редких множеств происходит по задаваемой границе support — количество или частота встречаемости множества в данных.

После выделения частых itemset оценивается качество их зависимости с помощью метрики Lift или Confindence (a, b) / Confidence (! a, b). Они нацелены на то, чтобы удалить ложные зависимости.
Например, бананы могут часто встречаться в продуктовой корзине вместе с консервами. Но дело не в какой-то особой связи, а в том, что бананы популярны сами по себе, и это следует учитывать при поиске совстречаемостей.
Персонализированные рекомендации
Content-Based
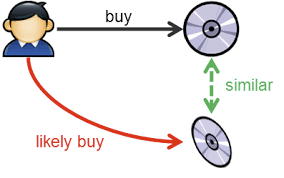
Идея content-based подхода заключается в том, чтобы по истории действий пользователя создать для него вектор его предпочтений в пространстве предметов и рекомендовать товары, близкие к этому вектору.
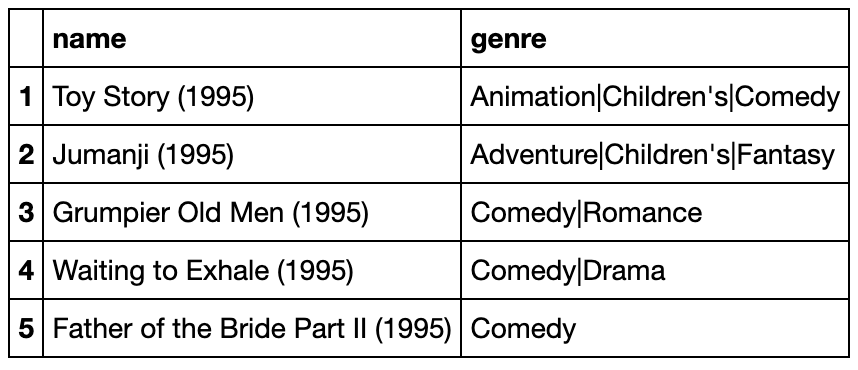
То есть у айтема должно быть какое-то признаковое описание. Например, это могут быть жанры фильмов. История лайков и дизлайков фильмов формирует вектор предпочтения,
выделяя одни жанры и избегая другие. Сравнивая вектор пользователя и вектор айтема, можно сделать ранжирование и получить рекомендации.
Collaborative Filtering

Коллаборативная фильтрация предполагает наличие матрицы оценок пользователь-айтем. Идея заключается в том, чтобы для каждого пользователя найти наиболее похожих «соседей» и заполнить пропуски конкретного пользователя, взвешенно усредняя рейтинги «соседей».


Аналогично можно смотреть на схожесть айтемов, считая, что похожие айтемы нравятся похожим людям. Технически это будет просто рассмотрение транспонированной матрицы оценок.
Пользователи по-разному используют шкалу оценок — кто-то никогда не ставит выше восьми, а кто-то использует всю шкалу. Это полезно учитывать, и поэтому можно предсказывать не сам рейтинг, а отклонение от среднего рейтинга.

Либо можно заранее нормализовать оценки.

Matrix Factorization
Из математики мы знаем, что любую матрицу можно разложить на произведение трех матриц. Но матрицы оценок очень разрежены, 99% — обычное дело. А SVD не знает, что такое пропуски. Заполнять их средним значением не очень хочется. И в целом, нас не очень интересует матрица сингулярных значений — мы просто хотим получить скрытое представление пользователей и предметов, которое при перемножении будет приближать истинный рейтинг. Можно сразу раскладывать на две матрицы.

Что же делать с пропусками? Забить на них. Оказалось, что обучать приближать рейтинги по метрике RMSE с помощью SGD или ALS можно, вообще игнорируя пропуски. Первый такой алгоритм — Funk SVD, который придумали в 2006 году в ходе решения соревнования от Netflix.
Netflix Prize

Netflix Prize — значимое событие, которое дало сильный толчок развитию рекомендательных систем. Цель соревнования — обогнать существующую систему рекомендаций Cinematch по метрике RMSE на 10%. Для этого был предоставлен большой на то время датасет, содержащий 100 миллионов оценок. Задача может показаться не такой сложной, но для достижения требуемого качества потребовалось переоткрывать соревнование два раза — решение было получено только на 3 год соревнования. Если бы было необходимо получить улучшение в 15%, возможно, этого бы и не удалось достичь на предоставленных данных.
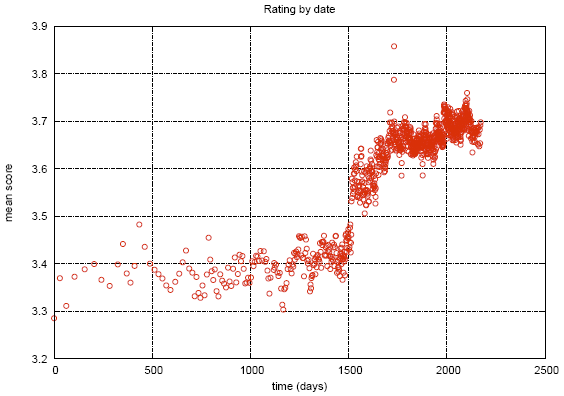
В процессе соревнования в данных были найдены некоторые интересности. На графике показана средняя оценка фильмов в зависимости от даты появления в каталоге Netflix. Видимый разрыв связывают с тем, что в это время Netflix перешел от объективной шкалы (фильм плохой, фильм хороший) к субъективной (мне не понравилось, мне очень понравилось). Люди менее критичны, когда высказывают свою оценку, а не характеристику объекта.
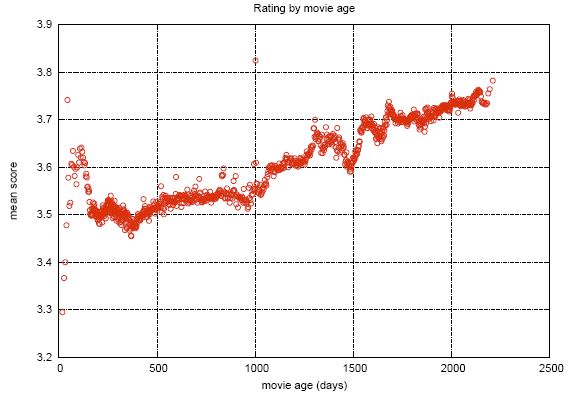
На этом графике показано, как меняется средняя оценка фильмов после релиза. Видно, что за 2000 дней оценка поднимается на 0.2. То есть, после того как фильм перестал быть новым, его начинают смотреть те, кто достаточно сильно уверен в том, что фильм ему понравится, что повышает рейтинг.
Первый промежуточный приз взяла команда специалистов из AT&T — Korbell. После 2000 часов работы и составления ансамбля из 107 алгоритмов им удалось получить улучшение в 8,43%.

Среди моделей была вариация SVD и RBM, которые сами по себе давали большую часть вклада. Остальные 105 алгоритмов улучшали только одну сотую метрики. Netflix адаптировал эти два алгоритма под свои объемы данных и использует их до сих пор как часть системы.
Во второй год соревнования произошло объединение двух команд и теперь приз взяли Bellkor in BigChaos. Они настакали суммарно 207 алгоритмов и улучшили точность ещё на одну сотую, достигнув значения 0.8616. Требуемое качество все ещё не достигнуто, но уже понятно, что на следующий год все должно получиться.
Третий год. Объединение еще с одной командой, переименование в Bellkor«s Pragmatic Chaos и достижение необходимого качества, немного уступая The Ensemble. Но это только публичная часть датасета.

На скрытой части оказалось, что точность у этих команд совпадает до четвертого знака после запятой, поэтому победителя определила разница коммитов в 20 минут.

Netflix выплатил обещанный миллион победителям, но так никогда и не использовал полученное решение. Внедрять полученный ансамбль оказалось слишком дорого, а пользы от него не так много — ведь всего два алгоритма уже дают большую часть прироста в точности. А самое главное — на время завершения соревнования в 2009, Netflix уже два года как начал заниматься своим стриминговым сервисом помимо аренды DVD. У них появилось много других задач и данных, которые они могли использовать в своей системе. Однако их сервис аренды DVD по почте до сих пор обслуживает 2,7 миллионов счастливых подписчиков.

Нейросети
В современных рекомендательных системах частый вопрос — как учитывать различные явные и неявные источники информации. Часто есть дополнительные данные о пользователе или айтеме и их хочется использовать. Нейросети — хороший способ учета такой информации.
В вопросе применения сетей для рекомендаций следует обратить внимание на обзор Deep Learning based Recommender System: A Survey and New Perspectives. В нем описаны примеры использования большого количества архитектур применительно к различным задачам.
Архитектур и подходов очень много. Одно из повторяющихся названий — DSSM. Ещё я бы хотел отметить Attentive Collaborative Filtering.

ACF предлагает ввести два уровня аттеншена:
- Даже при одинаковых рейтингах одни айтемы вносят больший вклад в ваши предпочтения, чем другие.
- Айтемы не атомарны, а состоят из компонентов. Некоторые оказывают большее влияние на оценку, чем другие. Фильм может быть интересен только за счет наличия любимого актера.

Многорукие бандиты — одна из популярных тем недавнего времени. Что такое многорукие бандиты можно почитать в статье на Хабре или на Медиуме.
В применении к рекомендациям задача Contextual-Bandit будет звучать примерно так: «Подаем на вход системы контекстные вектора пользователя и айтема, хотим максимизировать вероятность взаимодействия (клика, покупки) по всем пользователям с течением времени, совершая частые обновления политики рекомендации». Такая формулировка естественным образом решает проблему exploration vs exploitation и позволяет быстрее выкатывать оптимальные стратегии на всех пользователей.

На волне популярности архитектуры трансформер также появляются попытки использовать их в рекомендациях. Next Item Recommendation with Self-Attention пытается комбинировать долговременные и недавние предпочтения пользователя для улучшения рекомендаций.
Инструменты
Рекомендации — не такая популярная тема, как CV или NLP, поэтому чтобы использовать последние архитектуры сеток придется либо реализовывать их самому, либо надеяться, что реализация автора достаточно удобна и понятна. Однако некоторые базовые инструменты все же есть:
Заключение
Рекомендательные системы далеко ушли от стандартной постановки про заполнение матрицы оценок, и в каждой конкретной области будут свои нюансы. Это привносит трудности, но и добавляет интереса. Кроме того, отделить рекомендательную систему от продукта в целом бывает трудно. Ведь важен не только список айтемов, но и способ и контекст подачи. Что, как, кому и когда рекомендовать. Все это определяет впечатление от взаимодействия с сервисом.
