Рекомендации на потоке
Всем привет!
Сегодня мы расскажем о том, как с помощью потоковой обработки данных можно увеличить качество рекомендаций и снизить время отклика всей рекомендательной системы в 5 раз. Речь пойдет об одном из наших клиентов — сервисе потокового видео Rutube.

Для начала несколько слов о самом Rutube и зачем ему нужны рекомендации. Во-первых, на момент написания статьи в нашей рекомендательной системе хранятся данные по 51,76 млн юзеров и 1,26 млн айтемов, то есть видео. Очевидно, что ни один юзер не сможет просмотреть все видео в обозримом будущем. Ему на помощь приходит рекомендательная система. Во-вторых, Rutube зарабатывает на показе рекламы. Один из ключевых бизнес-показателей компании — время, проведенное пользователем на сайте. Rutube максимизирует этот показатель. Рекомендательная система помогает это сделать. И, в-третьих, уже особенность самого Rutube. Часть контента представляет собой коммерческие видео правообладателей. Например, свой канал есть у ТНТ, на котором они регулярно выкладывают выпуски своих передач. Когда выходит новый выпуск «Дома-2» или «Танцев», народ бросается смотреть их. Видео имеет «вирусный» характер. Отслеживать и показывать такие видео другим пользователям помогает рекомендательная система.
Первую версию рекомендательной системы для Rutube мы в E-Contenta сделали в мае 2015. Представляла она из себя следующее: item-based collaborative filtration с перерасчетом рекомендаций каждые n раз, где n — число из ряда Фибоначчи. То есть просмотр каждого видео был событием и, если порядковый номер этого события входил в ряд Фибоначчи, мы пересчитывали меры близости этого видео с другими видео. Реализовано это было с помощью следующего стека: Tornado + Celery (где брокер — RabbitMQ) + MongoDB. То есть данные шли в Tornado, оттуда через Celery publisher в RabbitMQ, а оттуда через Celery consumer — обрабатывались и отправлялись в MongoDB. На запрос рекомендаций для пользователя мы должны отвечать в течение 1 сек (SLA).
Поначалу система работала неплохо: мы принимали поток событий, обрабатывали их, и рассчитывали рекомендации. Однако довольно скоро вскрылись следующие проблемы.
Во-первых, техническая проблема. Перерасчет рекомендаций для популярных видео «клал» всю систему. Огромное число событий из Mongo забивали всю оперативную память, а обработка всех этих событий «забивала» все ядра. В такие моменты мы не могли ни отдать уже рассчитанные рекомендации, ни пересчитать новые, нарушая SLA.
Во-вторых, бизнесовая проблема. Пересчитывая рекомендации только каждый i-й раз, где i принадлежит ряду Фибоначчи, мы могли не сразу отследить вирусное видео. Когда же наконец мы до него добирались, то каждый раз нам приходилось делать полный пересчет, что занимало слишком много времени и ресурсов, при том что количество событий продолжало расти.
В-третьих, алгоритмическая проблема под названием implicit feedback problem. Любая рекомендательная система строится на оценках, или рейтингах. Мы же собирали только просмотры видео, то есть по сути система оценок у нас была бинарная: 1 — смотрел видео, 0 — не смотрел.
В качестве решения напрашивался переход на полный real-time, однако для этого нужен был недорогой с точки зрения ресурсов и в то же время эффективный алгоритм. Основным вдохновением послужила статья, опубликованная компанией Tencent. Описанный ими алгоритм мы и взяли за основу нашего нового рекомендательного движка.
Новый алгоритм представлял из себя классический item based CF, где в качестве меры близости использовался косинус угла:
Если внимательно посмотреть на формулу, то можно заметить, что она состоит из трех сумм: суммы совместных рейтингов в числителе и двух сумм квадратов рейтингов в знаменателе. Заменив их на более простые понятия, получаем следующее:
А теперь давайте подумаем, что происходит при перерасчете рекомендаций при получении нового события (новой оценки)? Правильно! Мы всего лишь увеличиваем наши суммы на полученное значение. Таким образом, новую меру близости можно представить в следующем виде:
Отсюда следует очень важный вывод. Нам необязательно каждый раз пересчитывать все суммы. Достаточно хранить их и увеличивать на каждое новое значение. Такой принцип называется incremental update. Благодаря ему, существенно снижается нагрузка при перерасчете рекомендаций, и становится возможным использовать такой алгоритм в real-time processing.
В той же статье было предложено решение для implicit feedback problem: давать оценку каждому конкретному действию пользователя при просмотре видео. Например, отдельно оценивать начало просмотра, просмотр до середины или до конца, паузу, перемотку и т.д. Вот как мы расставили веса сейчас:
ACTION_WEIGHTS = {
"thirdQuartile": 0.75,
"complete": 1.0,
"firstQuartile": 0.25,
"exitFullscreen": 0.1,
"fullscreen": 0.1,
"midpoint": 0.5,
"resume": 0.2,
"rewind": 0.2,
"pause": 0.05,
"start": 0.2
}
При нескольких действиях пользователя с одним видео берется максимальная оценка.
Также теперь мы учитываем популярные (trending) видео. У каждого видео есть счетчик, который увеличивается на 1, при поступлении события, связанного с ним. Самые популярные видео попадают в топ-20. При поступлении каждого нового события мы проверяем, если видео есть в топ-20, его счетчик увеличивается, если нет, у всех видео в топ-20 счетчик уменьшается на 1. Таким образом, получается довольно динамичный список, с помощью которого легко отследить вирусное видео. Такой список мы ведем для каждого региона. То есть пользователям из разных регионов мы рекомендуем разные популярные видео.
При запросе рекомендаций для пользователя выдача состоит на 85% из персональных рекомендаций и на 15% — из популярных видео.
С алгоритмом определились, теперь нужно выбрать технологии, с помощью которых его можно реализовать. Если обобщить все кейсы, которые мы нашли по stream processing, то стек используемых технологий выглядит примерно следующим образом:
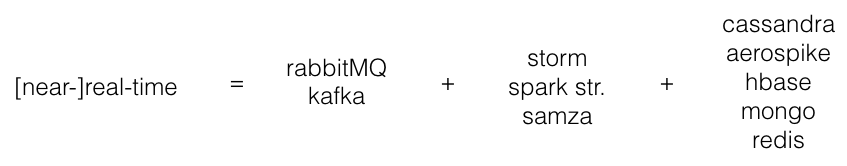
То есть мы загоняем все события в message broker, затем параллельно обрабатываем их в stream processing engine и складываем результаты в key-value database, откуда затем их считываем при получении запроса. Осталось выбрать конкретный вариант для каждого элемента.
RabbitMQ у нас уже был, и мы вполне были им довольны. Однако большинство streaming движков поддерживают из коробки именно Kafka. Мы были совсем не против перехода, тем более за последнее время Kafka набрала серьезные обороты, хорошо себя зарекомендовала и вообще считается довольно универсальным и надежным инструментом, освоив который, можно еще много где его применить.
В качестве streaming движка рассматривали все 3 варианта. Однако сразу ввели одно ограничение — весь код должен писаться только на Python. Все члены нашей команды хорошо его знают, плюс на Python есть все необходимые нам библиотеки, а те, которых не было, мы написали сами. Поэтому Samza отпала сразу, так как поддерживает только Java. Сначала хотели попробовать Storm, но покопавшись в документации выяснили, что часть кода (topology) будет писаться на Java, и лишь код для узлов обработки (bolts) можно написать на Python. Уже позже мы обнаружили прекрасную Python обертку для Storm под названием streamparse. Кому нужен Storm полностью на Python, рекомендуем! В результате выбор остановился на Spark. Во-первых, мы были уже с ним знакомы. А во-вторых, он полностью поддерживал Python. И в-третьих, действительно впечатляет, как бурно они сейчас развиваются.
Выбор БД был сделан сразу. Несмотря на то, что мы имеем опыт работы с каждой из них, у нас есть любимчик. Это Aerospike. Весь свой потенциал Aerospike раскрывает на серверах с SSD дисками. Он обходит файловую систему Linux и пишет напрямую в SSD отдельными блоками. Благодаря этому достигается производительность в 1 млн TPS на одной ноде, а время ответа 99% запросов составляет < 1 ms. Мы не раз его использовали и довольно неплохо умеем его готовить (хотя там и готовить особо ничего не надо :).
В результате наш стек выглядит так:

Еще пару слов про выбор между Storm и Spark, вдруг кому-то пригодится.
Spark streaming — это не совсем real-time движок, это скорее near real-time, так как в нем используется mini-batching. То есть поток данных разбивается на мини-батчи, размером в указанное количество секунд и параллельно обрабатывается. Для тех, кто знаком с понятиями в Spark, мини-батч не что иное, как RDD. Storm — это настоящий real-time. Поступившие событие сразу обрабатывается (хотя Storm тоже можно настроить на mini-batching с помощью Trident). Резюмируя всё вышесказанное, Storm — это lower latency, а Spark — higher throughput. Если у вас есть жесткое ограничение по latency, то следует выбирать Storm. Например, для security приложений. В противном случае Spark будет более чем достаточно. Мы используем его уже больше месяца в продакшене, при должном тюнинге кластера работает как часы. Существует еще мнение, что Spark более отказоустойчив. Однако на наш взгляд его следует дополнить, Spark более отказоустойчив из коробки. При должном желании и умении и Storm можно вывести на такой уровень.
И самое главное. Имело ли это всё смысл? Имело. Начнем с качества рекомендаций. Мы используем онлайн метрику качества, которой измеряем, входило ли фактически просмотренное пользователем видео в список, рекомендованный нами, и на каком месте оно там находилось. Распределение выглядит следующим образом.
Для только персональных рекомендаций (item-item CF):

Для только популярных айтемов (trending):
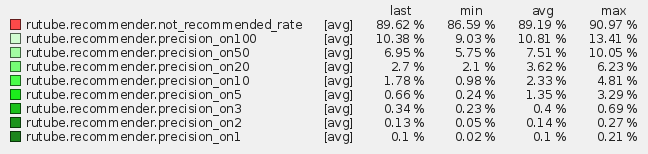
Для гибридных рекомендаций (85% item-item CF и 15% trending):
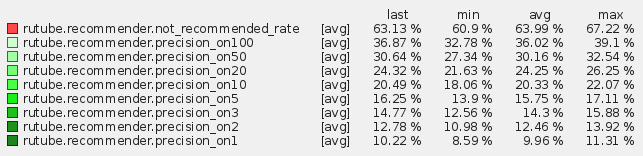
Именно последний вариант мы используем в продакшене, так как метрики на нем максимальны. То есть около 10% просмотренных пользователями видео мы рекомендуем ему на первом месте! Около 36% входят в топ 100. Если вам эти цифры ни о чем не говорят, то можно посмотреть на распределение популярных видео. Если мы будем рекомендовать пользователю только популярные видео, то будем угадывать лишь 0,1% от всех просмотренных им видео. Что в свою очередь тоже неплохо, если сравнивать со случайным распределением, где вероятность угадывания любого видео будет равна 1/(1,26 млн).
Для большей наглядности ниже приведен график нашей метрики:
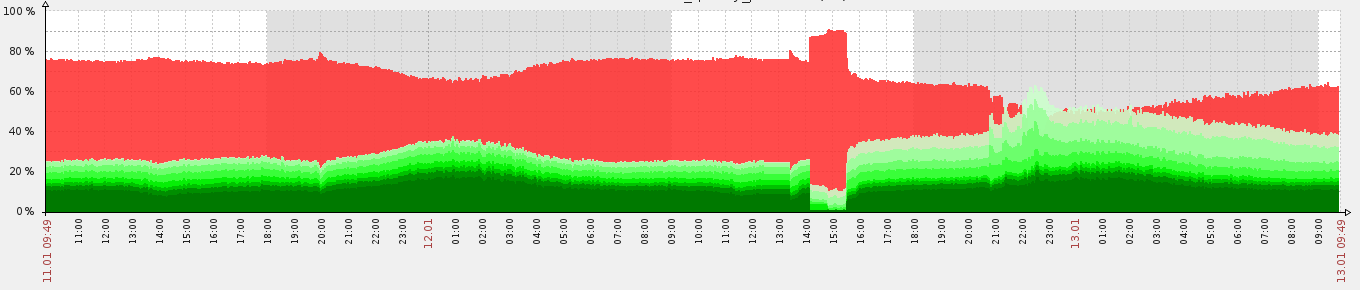
Кусочек 12.02 с 14:00 до 15:30, где больше всего неугаданного (красного) — это как раз тестирование рекомендаций только с trending items. До этого — item-item CF, а после — гибридная модель. Как видно, благодаря «риэлтаймовости», наша рекомендательная система быстро адаптируется под новую конфигурацию. К слову при запуске системы с нуля она выходит на указанные выше показатели за полчаса.
Благодаря переходу с MongoDB на Aerospike упало среднее время отклика на запрос рекомендаций. Ниже момент переключения со старого движка на новый:
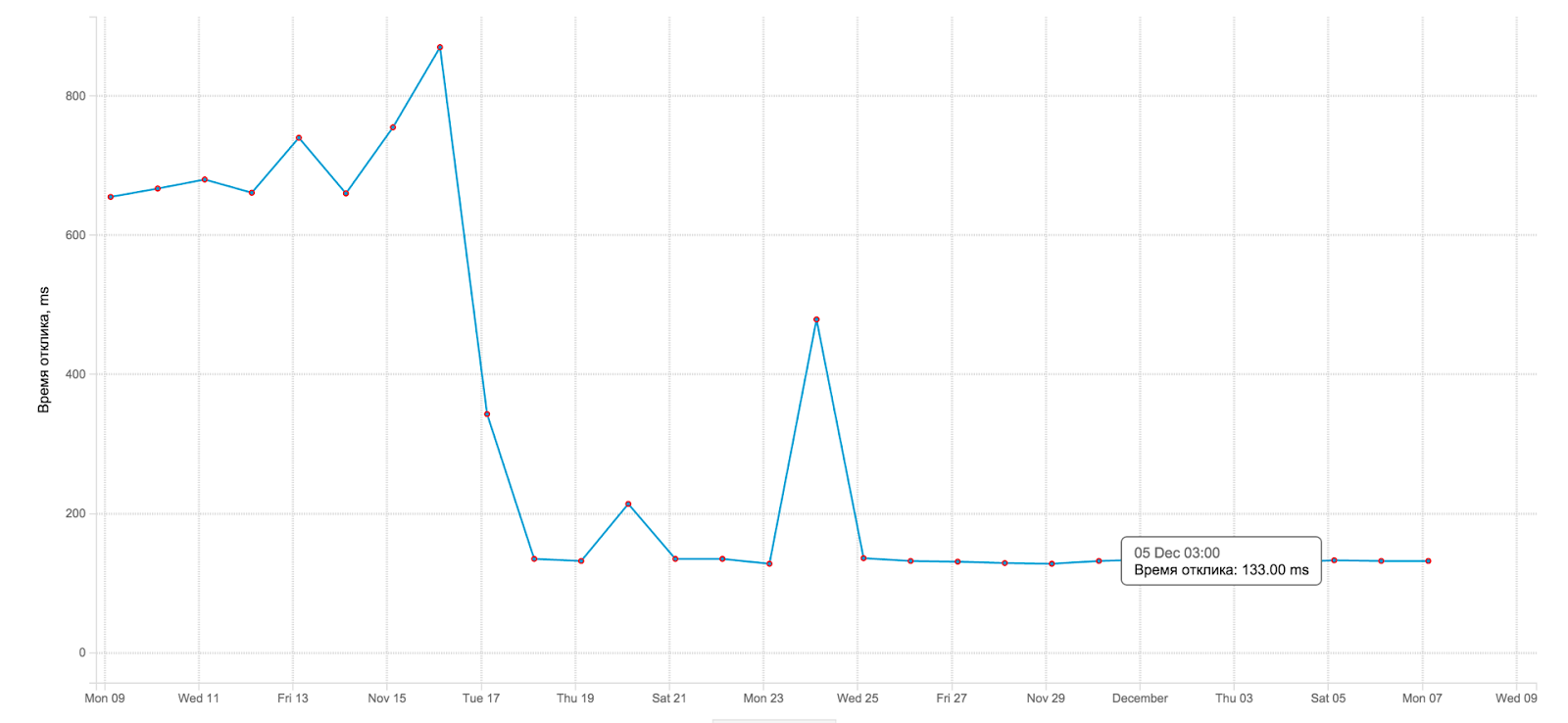
Как видно, время отклика упало примерно в 5 раз. Что также приятно, как для нас, так и для самого Rutube, потому что за SLA мы больше не беспокоимся :)
Что касается железа, то мы развернули новый кластер (Cloudera) на 3-х машинах. Пока нам этого хватает. Вся система отказоустойчива, поэтому uptime 99.9%. Вдобавок к этому идет масштабируемость: мы в любой момент можем «воткнуть» новые машины при значительном увеличении нагрузки на кластер.
Сейчас нас интересуют 2 момента: веса событий (начало просмотра, просмотр до середины, пауза и т.д.) и доля популярных видео в выдаче рекомендаций. И те, и другие показатели были выставлены экспертным методом, то есть «на глаз» :) Хотелось бы все-таки определить максимально эффективные показатели и в том, и в другом случае. Скорее всего, мы воспользуемся Metric Optimization Engine (MOE). Это фреймворк для определения параметров системы на основе A/B тестирования. Как только получим какие-то интересные результаты, обязательно напишем.
Если у вас есть какие-то вопросы по кейсу и по потоковой обработке в целом, задавайте в комментариях, постараемся всем ответить.
