Рейтинг русскоязычных энкодеров предложений
Энкодер предложений (sentence encoder) — это модель, которая сопоставляет коротким текстам векторы в многомерном пространстве, причём так, что у текстов, похожих по смыслу, и векторы тоже похожи. Обычно для этой цели используются нейросети, а полученные векторы называются эмбеддингами. Они полезны для кучи задач, например, few-shot классификации текстов, семантического поиска, или оценки качества перефразирования.
Но некоторые из таких полезных моделей занимают очень много памяти или работают медленно, особенно на обычных CPU. Можно ли выбрать наилучший энкодер предложений с учётом качества, быстродействия, и памяти? Я сравнил 25 энкодеров на 8 задачах, и составил их рейтинг. Самой качественной моделью оказался mUSE, самой быстрой из предобученных — FastText, а по балансу скорости и качества победил rubert-tiny2. Код бенчмарка выложен в репозитории encodechka, а подробности — под катом.
Родственные проекты
Первой известной попыткой системно сравнить английские эмбеддинги предложений был SentEval, сочетающий чисто лингвистические задачи со вполне прикладными. Для русского языка тоже было создано немало разного рода бенчмарков NLU моделей:
RussianSuperGLUE: бенчмарк «сложных» NLP задач; фокус на дообучаемых моделях.
MOROCCO: RussianSuperGLUE + оценка производительности, довольно трудновоспроизводимый бенчмарк.
RuSentEval: бенчмарк BERT-подобных энкодеров предложений на лингвистических задачах.
Статья от Вышки Popov et al, 2019: первая научная статья по русским энкодерам предложений; увы, содержит маловато моделей и задач.
SentEvalRu и deepPavlovEval: два хороших, но давно не обновлявшихся прикладных бенчмарка.
Мой бенчмарк вырос из поста Маленький и быстрый BERT для русского языка, где я, обучив модель rubert-tiny, сравнивал её с другими русскоязычными бертами. С тех пор появилось много новых русскоязычных моделей, включая rubert-tiny2, поэтому и бенчмарк пришло время обновить.
Модели
В основу бенчмарка легли BERT-подобные модели: sbert_large_nlu_ru, sbert_large_mt_nlu_ru, и ruRoberta-large от Сбера; rubert-base-cased-sentence, rubert-base-cased-conversational, distilrubert-tiny-cased-conversational, и distilrubert-base-cased-conversational от DeepPavlov; мои rubert-tiny и rubert-tiny2; мультиязычные LaBSE (плюс урезанная версия LaBSE-en-ru) и старый добрый bert-base-multilingual-cased. Для каждой такой модели я использовал два вида эмбеддингов: или эмбеддинг первого (CLS) токена, или средний эмбеддинг всех токенов. Кроме этого, я добавил в бенчмарк разные T5 модели, т.к. они тоже должны хорошо понимать тексты: мои rut5-small, rut5-base, rut5-base-multitask, и rut5-base-paraphraser, и Сберовские ruT5-base и ruT5-large. Для них я использовал только средний эмбеддинг всех токенов.
Помимо BERTов и T5, я включил в бенчмарк большие мультиязычные модели Laser от FAIR и USE-multilingual-large от Google. В качестве быстрого бейзлайна, я добавил FastText, а именно, geowac_tokens_none_fasttextskipgram_300_5_2020 с RusVectores, а также его сжатую версию. Наконец, я добавил парочку «моделей», которые вообще не выучивают никаких параметров, а просто используют HashingVectorizer для превращения текста в вектор признаков.
Ни одну из моделей я не дообучал на задачи из бенчмарка. Вместо этого я извлекал из них эмбеддинги текстов «как есть» и обучал простенькие модели, используя эти эмбеддинги как признаки. Таким образом, мой бенчмарк (в отличие, скажем, от RussianSuperGLUE) ранжирует модели не по способности к дообучению, а по качеству уже выученных представлений текстов.
Про rubert-tiny2
Про rubert-tiny2 я расскажу подробнее, потому что эту модель я ранее нигде не описывал. Это доработанная версия rubert-tiny: я расширил словарь модели c 30К до 80К токенов, увеличил максимальную длину текста с 512 до 2048 токенов, и дообучил модель на комбинации задач masked language modelling, natural language inference, и аппроксимации эмбеддингов LaBSE. Код дообучения есть в блокноте.
В результате увеличения словаря я улучшил модель по нескольким показателям. Во-первых, за счёт выделенных эмбеддингов она начала лучше понимать смысл слов: например, у неё появился отдельный эмбеддинг для слова «коронавирус» и возможность запомнить его смысл. Это, в свою очередь, позволило «высвободить» слои self-attention, чтобы модель могла уделять больше внимания смыслу текста в целом. Во-вторых, за счёт увеличения словаря сократилось число среднее токенов на один текст, а значит, модель стала быстрее работать на CPU (где нет возможности обрабатывать токены параллельно). В-третьих, увеличение словаря вкупе с увеличением числа positional embeddings позволило запихивать в модель более длинные тексты, чем раньше. Я надеялся, что все эти улучшения сильно повысят качество модели, и в принципе мои надежды оправдались. Вторая версия rubert-tiny стала занимать больше памяти, чем первая (за счёт увеличенной матрицы эмбеддингов), но чуть быстрее работать (из-за увеличения покрытия словаря), а главное, давать более качественные эмбеддинги текстов.
Задачи и оценка качества
В новой версии бенчмарка я оставил всё те же 10 задач, что и в прежней, но слегка изменил формат некоторых из них:
Semantic text similarity (STS) на основе переведённого датасета STS-B;
Paraphrase identification (PI) на основе датасета paraphraser.ru;
Natural language inference (NLI) на датасете XNLI;
Sentiment analysis (SA) на данных SentiRuEval2016. В прошлой версии бенчмарка я собрал кривые тестовые выборки, поэтому этот датасет я переделал;
Toxicity identification (TI) на датасете токсичных комментариев из OKMLCup;
Inappropriateness identification (II) на датасете Сколтеха;
Intent classification (IC) и её кросс-язычная версия ICX на датасете NLU-evaluation-data, который я автоматически перевёл на русский. В IC классификатор обучается на русских данных, а в ICX — на английских, а тестируется в обоих случаях на русских.
Распознавание именованных сущностей () на датасетах factRuEval-2016E1) и RuDReC (NE2). Эти две задачи требуют получать эмбеддинги отдельных токенов, а не целых предложений; поэтому модели USE и Laser, не выдающие эмбеддинги токенов «из коробки», в оценке этих задач не участвовали.
В задачах STS, PI и NLI оценивается степень связи двух текстов. Хороший энкодер предложений должен отражать эту степень в их косинусной близости, поэтому для STS и PI мы измеряем качество как Спирмановскую корреляцию косинусной близости и человеческих оценок сходства. Для NLI я обучил трёхклассовую (entail/contradict/neutral) логистическую регрессию поверх косинусной близости, и измеряю её точность (accuracy). Для задач бинарной классификации TI и II я измеряю ROC AUC, а в задачах многоклассовой классификации SA, IC и ICX — точность (accuracy). Для всех задач классификации я обучаю логистическую регрессию либо KNN поверх эмбеддингов предложений, и выбираю лучшую модель из двух.
Для задач NER я классифицировал токены логистической регрессией поверх их эмбеддингов, и измерял macro F1 по всем классам токенов, кроме О. Поскольку разные модели токенизируют тексты по-разному, я токенизировал все тексты razdel’ом, и вычислял эмбеддинг слова как средний эмбеддинг его токенов.
Поскольку все метрики качества лежат между 0 и 1, агрегированное качество по всем задачам можно репортить просто как среднее арифметическое. Я вычисляю два таких средних: по первым 8 задачам (где используются только эмбеддинги предложений), и по всем 10 (включая NER, где участвуют также эмбеддинги токенов).
Кроме качества моделей на конечных задачах, я замерял их производительность (среднее число миллисекунд на предложение при запуске на CPU либо GPU) и размер (в мегабайтах, которые модель занимает на диске).
Результаты
Первая таблица показывает перформанс моделей в каждой из задач. Единого победителя нет, но MUSE, sbert_large_mt_nlu_ru и rubert-base-cased-sentence взяли по многу призовых мест. Удивительно, но модели T5 очень хорошо показали себя на задачах NER.
Таблица 1: качество по задачам
model | STS | PI | NLI | SA | TI | IA | IC | ICX | NE1 | NE2 |
|---|---|---|---|---|---|---|---|---|---|---|
MUSE-3 | 0.81 | 0.61 | 0.42 | 0.77 | 0.96 | 0.79 | 0.77 | 0.75 | ||
sentence-transformers/LaBSE | 0.77 | 0.64 | 0.43 | 0.76 | 0.94 | 0.77 | 0.75 | 0.74 | 0.35 | 0.41 |
cointegrated/LaBSE-en-ru | 0.77 | 0.64 | 0.43 | 0.76 | 0.94 | 0.77 | 0.75 | 0.74 | 0.34 | 0.41 |
laser | 0.75 | 0.6 | 0.41 | 0.73 | 0.96 | 0.72 | 0.72 | 0.7 | ||
cointegrated/rubert-tiny2 | 0.75 | 0.65 | 0.42 | 0.73 | 0.93 | 0.75 | 0.69 | 0.59 | 0.4 | 0.4 |
sberbank-ai/sbert_large_mt_nlu_ru | 0.77 | 0.64 | 0.4 | 0.79 | 0.98 | 0.8 | 0.7 | 0.42 | 0.3 | 0.34 |
DeepPavlov/rubert-base-cased-sentence | 0.73 | 0.66 | 0.49 | 0.75 | 0.89 | 0.75 | 0.61 | 0.36 | 0.36 | 0.34 |
sberbank-ai/sbert_large_nlu_ru | 0.65 | 0.61 | 0.38 | 0.78 | 0.97 | 0.79 | 0.68 | 0.37 | 0.36 | 0.4 |
DeepPavlov/distilrubert-base-cased-conversational | 0.57 | 0.52 | 0.36 | 0.73 | 0.98 | 0.78 | 0.67 | 0.42 | 0.4 | 0.43 |
DeepPavlov/distilrubert-tiny-cased-conversational | 0.59 | 0.52 | 0.37 | 0.71 | 0.98 | 0.78 | 0.66 | 0.36 | 0.35 | 0.44 |
ft_geowac_full | 0.69 | 0.53 | 0.37 | 0.72 | 0.97 | 0.76 | 0.66 | 0.26 | 0.22 | 0.34 |
cointegrated/rut5-base-paraphraser | 0.64 | 0.53 | 0.36 | 0.69 | 0.91 | 0.69 | 0.61 | 0.5 | 0.45 | 0.41 |
cointegrated/rubert-tiny | 0.65 | 0.51 | 0.4 | 0.68 | 0.86 | 0.68 | 0.58 | 0.54 | 0.23 | 0.34 |
ft_geowac_21mb | 0.68 | 0.52 | 0.36 | 0.72 | 0.96 | 0.74 | 0.65 | 0.15 | 0.21 | 0.32 |
DeepPavlov/rubert-base-cased-conversational | 0.54 | 0.53 | 0.34 | 0.72 | 0.97 | 0.76 | 0.62 | 0.26 | 0.4 | 0.43 |
cointegrated/rut5-base-multitask | 0.62 | 0.5 | 0.36 | 0.66 | 0.88 | 0.69 | 0.57 | 0.32 | 0.47 | 0.41 |
sberbank-ai/ruRoberta-large | 0.38 | 0.58 | 0.33 | 0.7 | 0.98 | 0.77 | 0.56 | 0.24 | 0.29 | 0.45 |
bert-base-multilingual-cased | 0.62 | 0.51 | 0.36 | 0.66 | 0.85 | 0.69 | 0.56 | 0.23 | 0.35 | 0.37 |
hashing_1000_char | 0.7 | 0.53 | 0.4 | 0.7 | 0.84 | 0.59 | 0.63 | 0.05 | 0.05 | 0.14 |
cointegrated/rut5-small | 0.59 | 0.52 | 0.34 | 0.65 | 0.86 | 0.67 | 0.53 | 0.15 | 0.44 | 0.38 |
hashing_300_char | 0.69 | 0.51 | 0.39 | 0.67 | 0.75 | 0.57 | 0.61 | 0.04 | 0.03 | 0.08 |
hashing_1000 | 0.63 | 0.49 | 0.39 | 0.66 | 0.77 | 0.55 | 0.57 | 0.05 | 0.02 | 0.04 |
sberbank-ai/ruT5-large | 0.4 | 0.34 | 0.35 | 0.67 | 0.94 | 0.73 | 0.47 | 0.16 | 0.46 | 0.44 |
hashing_300 | 0.61 | 0.48 | 0.4 | 0.64 | 0.71 | 0.54 | 0.5 | 0.05 | 0.02 | 0.02 |
sberbank-ai/ruT5-base | 0.28 | 0.23 | 0.35 | 0.62 | 0.88 | 0.66 | 0.37 | 0.14 | 0.45 | 0.41 |
cointegrated/rut5-base | 0.37 | 0.21 | 0.34 | 0.61 | 0.83 | 0.68 | 0.35 | 0.13 | 0.48 | 0.39 |
Вторая таблица показывает среднее качество каждой из моделей, а также их скорость и размер. Самыми качественными энкодерами предложений оказались мультиязычные MUSE, LaBSE и Laser. Кажется, это означает, что параллельные мультиязычные корпусы — это очень хороший источник семантики для обучения моделей, понимающих смысл текста. За мультиязычными моделями следует rubert-tiny2.
Таблица 2: среднее качество и производительность
model | CPU | GPU | size | Mean S | Mean S+W |
|---|---|---|---|---|---|
MUSE-3 | 66.2 | 18.5 | 303 | 0.736 | |
sentence-transformers/LaBSE | 105.9 | 7.5 | 1750 | 0.726 | 0.657 |
cointegrated/LaBSE-en-ru | 106 | 7.5 | 492 | 0.725 | 0.656 |
laser | 118.8 | 8.8 | 200 | 0.699 | |
cointegrated/rubert-tiny2 | 4.9 | 2.7 | 112 | 0.689 | 0.631 |
sberbank-ai/sbert_large_mt_nlu_ru | 356 | 14.4 | 1590 | 0.687 | 0.613 |
DeepPavlov/rubert-base-cased-sentence | 100.6 | 7.6 | 678 | 0.656 | 0.594 |
sberbank-ai/sbert_large_nlu_ru | 348.6 | 14.2 | 1590 | 0.654 | 0.599 |
DeepPavlov/distilrubert-base-cased-conversational | 49.7 | 4.5 | 517 | 0.629 | 0.587 |
DeepPavlov/distilrubert-tiny-cased-conversational | 16.8 | 2.1 | 409 | 0.62 | 0.575 |
ft_geowac_full | 0.6 | 1910 | 0.617 | 0.55 | |
cointegrated/rut5-base-paraphraser | 118.8 | 9.1 | 932 | 0.617 | 0.579 |
cointegrated/rubert-tiny | 6.1 | 2.8 | 45 | 0.614 | 0.549 |
ft_geowac_21mb | 1.4 | 21 | 0.597 | 0.531 | |
DeepPavlov/rubert-base-cased-conversational | 98.8 | 7.6 | 681 | 0.591 | 0.557 |
cointegrated/rut5-base-multitask | 117.8 | 9.4 | 932 | 0.575 | 0.548 |
sberbank-ai/ruRoberta-large | 354.9 | 14.1 | 1320 | 0.568 | 0.528 |
bert-base-multilingual-cased | 124.6 | 7.8 | 681 | 0.561 | 0.521 |
hashing_1000_char | 0.5 | 1 | 0.557 | 0.464 | |
cointegrated/rut5-small | 31.8 | 7.1 | 247 | 0.54 | 0.514 |
hashing_300_char | 0.5 | 1 | 0.528 | 0.433 | |
hashing_1000 | 0.2 | 1 | 0.513 | 0.416 | |
sberbank-ai/ruT5-large | 339.9 | 14.4 | 2750 | 0.508 | 0.497 |
hashing_300 | 0.2 | 1 | 0.491 | 0.397 | |
sberbank-ai/ruT5-base | 94.3 | 8.1 | 850 | 0.442 | 0.44 |
cointegrated/rut5-base | 119.6 | 9.6 | 932 | 0.439 | 0.439 |
Модель с наилучшим средним качеством — только одна (mUSE), но это не значит, что всегда надо выбирить именно её; скорость и память тоже важны. Но выбирать стоит из Парето-оптимальныхмоделей: таких, что ни одна другая модель не превосходит их по всем критериям. Из 25 моделей только 12 Парето-оптимальны:
MUSE, rubert-tiny2, FT_geowac, Hashing_1000_char и Hashing_1000 обладают самым лучшим качеством для своей скорости на CPU;
MUSE, LaBSE, rubert-tiny2, и distilbert-tiny обладают наилучшим качеством для своей скорости на GPU;
MUSE, LaBSE, rubert-tiny2, rubert-tiny, FT_geowac_21mb, и Hashing_1000_char обладают наилучшим качеством для своего размера.
Картинка ниже показывает, в каком смысле каждая из этих моделей оптимальна.
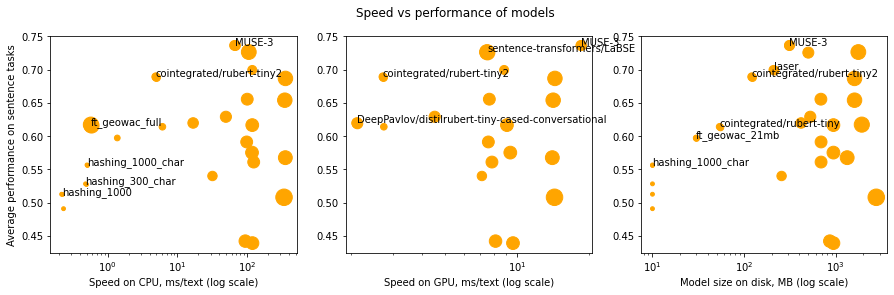 Баланс производительности и качества разных моделей
Баланс производительности и качества разных моделей
В большинстве приложений лимитирующим фактором является скорость на CPU; поэтому для них в качестве энкодеров предложений можно рекомендовать использовать MUSE (если главное качество), FastText (если очень важна скорость), либо rubert-tiny2 (если хочется компромисса).
И что теперь
Если вы хотите использовать готовый энкодер предложений, и не знаете, какой выбрать, в readme репозитория — лидерборд. Наверное, я буду его время от времени обновлять. Выбирайте тот баланс качества и производительности, какой нравится. А если не хочется думать, используйте rubert-tiny2 (:
Если в лидерборде нет задачи, похожей на ту, которую вы хотите решить — пишите в issue, и я включу эту задачу туда. Для бенчмарка это окей — быть динамическим.
Если вы нашли новый энкодер для русских предложений или даже обучили свой собственный, и хотите его протестировать на моём бенчмарке — вот пример кода. Либо опять таки пишите issue, и я перезапущу бенчмарк с вашей моделью.
Ну напоследок стандартное: подписывайтесь на мой канал, вступайте в чат по NLP, создавайте полезные ресурсы, и не нападайте на соседние страны. И вообще ни на кого не нападайте!
