Регулярные выражения в Python от простого к сложному. Подробности, примеры, картинки, упражнения
Регулярные выражения в Python от простого к сложному
Решил я давеча моим школьникам дать задачек на регулярные выражения для изучения. А к задачкам нужна какая-нибудь теория. И стал я искать хорошие тексты на русском. Пяток сносных нашёл, но всё не то. Что-то смято, что-то упущено. У этих текстов был не только фатальный недостаток. Мало картинок, мало примеров. И почти нет разумных задач. Ну неужели поиск IP-адреса — это самая частая задача для регулярных выражений? Вот и я думаю, что нет.
Про разницу (?:…) / (…) фиг найдёшь, а без этого знания в некоторых случаях можно только страдать.
Плюс в питоне есть немало регулярных плюшек. Например, re.split может добавлять тот кусок текста, по которому был разрез, в список частей. А в re.sub можно вместо шаблона для замены передать функцию. Это — реальные вещи, которые прямо очень нужны, но никто про это не пишет.
Так и родился этот достаточно многобуквенный материал с подробностями, тонкостями, картинками и задачами.
Надеюсь, вам удастся из него извлечь что-нибудь новое и полезное, даже если вы уже в ладах с регулярками.
PS. Решения задач школьники сдают в тестирующую систему, поэтому задачи оформлены в несколько формальном виде.
Содержание
Регулярные выражения в Python от простого к сложному;
Содержание;
Примеры регулярных выражений;
Сила и ответственность;
Документация и ссылки;
Основы синтаксиса;
Шаблоны, соответствующие одному символу;
Квантификаторы (указание количества повторений);
Жадность в регулярках и границы найденного шаблона;
Пересечение подстрок;
Эксперименты в песочнице;
Регулярки в питоне;
Пример использования всех основных функций;
Тонкости экранирования в питоне ('\\\\\\\\foo');
Использование дополнительных флагов в питоне;
Написание и тестирование регулярных выражений;
Задачи — 1;
Скобочные группы (?:…) и перечисления |;
Перечисления (операция «ИЛИ»);
Скобочные группы (группировка плюс квантификаторы);
Скобки плюс перечисления;
Ещё примеры;
Задачи — 2;
Группирующие скобки (…) и match-объекты в питоне;
Match-объекты;
Группирующие скобки (…);
Тонкости со скобками и нумерацией групп.;
Группы и re.findall;
Группы и re.split;
Использование групп при заменах;
Замена с обработкой шаблона функцией в питоне;
Ссылки на группы при поиске;
Задачи — 3;
Шаблоны, соответствующие не конкретному тексту, а позиции;
Простые шаблоны, соответствующие позиции;
Сложные шаблоны, соответствующие позиции (lookaround и Co);
Ещё примеры;
Задачи — 4;
Post scriptum;
Регулярное выражение — это строка, задающая шаблон поиска подстрок в тексте. Одному шаблону может соответствовать много разных строчек. Термин »Регулярные выражения» является переводом с английского словосочетания «Regular expressions». Перевод не очень точно отражает смысл, правильнее было бы »шаблонные выражения». Регулярное выражение, или коротко «регулярка», состоит из обычных символов и специальных командных последовательностей. Например, \d задаёт любую цифру, а \d+ — задает любую последовательность из одной или более цифр.
Работа с регулярками реализована во всех современных языках программирования. Однако существует несколько «диалектов», поэтому функционал регулярных выражений может различаться от языка к языку. В некоторых языках программирования регулярками пользоваться очень удобно (например, в питоне), в некоторых — не слишком (например, в C++).
Примеры регулярных выражений
| Регулярка | Её смысл |
|---|---|
simple text |
В точности текст «simple text» |
\d{5} |
Последовательности из 5 цифр |
\d\d/\d\d/\d{4} |
Даты в формате ДД/ММ/ГГГГ (и прочие куски, на них похожие, например, 98/76/5432) |
\b\w{3}\b |
Слова в точности из трёх букв |
[-+]?\d+ |
Целое число, например, 7, +17, -42, 0013 (возможны ведущие нули) |
[-+]?(?:\d+(?:\.\d*)?|\.\d+)(?:[eE][-+]?\d+)? |
Действительное число, возможно в экспоненциальной записи Например, 0.2, +5.45, -.4, 6e23, -3.17E-14. См. ниже картинку. |

Сила и ответственность
Регулярные выражения, или коротко, регулярки — это очень мощный инструмент.
Но использовать их следует с умом и осторожностью, и только там, где они действительно приносят пользу, а не вред.
Во-первых, плохо написанные регулярные выражения работают медленно.
Во-вторых, их зачастую очень сложно читать, особенно если регулярка написана не лично тобой пять минут назад.
В-третьих, очень часто даже небольшое изменение задачи (того, что требуется найти) приводит к значительному изменению выражения.
Поэтому про регулярки часто говорят, что это write only code (код, который только пишут с нуля, но не читают и не правят).
А также шутят: Некоторые люди, когда сталкиваются с проблемой, думают «Я знаю, я решу её с помощью регулярных выражений.» Теперь у них две проблемы.
Вот пример write-only регулярки (для проверки валидности e-mail адреса (не надо так делать!!!)):
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:25[0-5]|
2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])
А вот здесь более точная регулярка для проверки корректности email адреса стандарту RFC822. Если вдруг будете проверять email, то не делайте так!
Если адрес вводит пользователь, то пусть вводит почти что угодно, лишь бы там была собака.
Надёжнее всего отправить туда письмо и убедиться, что пользователь может его получить.
Документация и ссылки
- Оригинальная документация: https://docs.python.org/3/library/re.html;
- Очень подробный и обстоятельный материал: https://www.regular-expressions.info/;
- Разные сложные трюки и тонкости с примерами: http://www.rexegg.com/;
- Он-лайн отладка регулярок https://regex101.com (не забудьте поставить галочку Python в разделе FLAVOR слева);
- Он-лайн визуализация регулярок https://www.debuggex.com/ (не забудьте выбрать Python);
- Могущественный текстовый редактор Sublime text 3, в котором очень удобный поиск по регуляркам;
Основы синтаксиса
Любая строка (в которой нет символов .^$*+?{}[]\|()) сама по себе является регулярным выражением. Так, выражению Хаха будет соответствовать строка «Хаха» и только она.
Регулярные выражения являются регистрозависимыми, поэтому строка «хаха» (с маленькой буквы) уже не будет соответствовать выражению выше.
Подобно строкам в языке Python, регулярные выражения имеют спецсимволы .^$*+?{}[]\|(), которые в регулярках являются управляющими конструкциями.
Для написания их просто как символов требуется их экранировать, для чего нужно поставить перед ними знак \.
Так же, как и в питоне, в регулярных выражения выражение \n соответствует концу строки, а \t — табуляции.
Шаблоны, соответствующие одному символу
Квантификаторы (указание количества повторений)
| Шаблон | Описание | Пример | Подходящие строки |
|---|---|---|---|
{n} |
Ровно n повторений | \d{4} |
1, 12, 123, 1234, 12345 |
{m,n} |
От m до n повторений включительно | \d{2,4} |
1, 12, 123, 1234, 12345 |
{m,} |
Не менее m повторений | \d{3,} |
1, 12, 123, 1234, 12345 |
{,n} |
Не более n повторений | \d{,2} |
1, 12, 123 |
? |
Ноль или одно вхождение, синоним {0,1} |
валы? |
вал, валы, валов |
* |
Ноль или более, синоним {0,} |
СУ\d* |
СУ, СУ1, СУ12, … |
+ |
Одно или более, синоним {1,} |
a\)+ |
a), a)), a))), ba)]) |
*?+???{m,n}?{,n}?{m,}? |
По умолчанию квантификаторы жадные — захватывают максимально возможное число символов. Добавление ? делает их анти-жадными, они захватывают минимально возможное число символов |
\(.*\)\(.*?\) |
(a + b) * (c + d) * (e + f) (a + b) * (c + d) * (e + f) |
Жадность в регулярках и границы найденного шаблона
Как указано выше, по умолчания квантификаторы жадные.
Этот подход решает очень важную проблему — проблему границы шаблона.
Скажем, шаблон \d+ захватывает максимально возможное количество цифр.
Поэтому можно быть уверенным, что перед найденным шаблоном идёт не цифра, и после идёт не цифра.
Однако если в шаблоне есть не жадные части (например, явный текст), то подстрока может быть найдена неудачно.
Например, если мы хотим найти «слова», начинающиеся на СУ, после которой идут цифры, при помощи регулярки СУ\d*,
то мы найдём и неправильные шаблоны:
ПАСУ13 СУ12, ЧТОБЫ СУ6ЕНИЕ УДАЛОСЬ.
В тех случаях, когда это важно, условие на границу шаблона нужно обязательно добавлять в регулярку.
О том, как это можно делать, будет дальше.
Пересечение подстрок
В обычной ситуации регулярки позволяют найти только непересекающиеся шаблоны.
Вместе с проблемой границы слова это делает их использование в некоторых случаях более сложным.
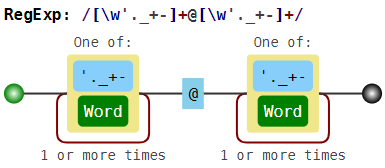
Например, если мы решим искать e-mail адреса при помощи неправильной регулярки \w+@\w+ (или даже лучше, [\w'._+-]+@[\w'._+-]+), то в неудачном случае найдём вот что:
foo@boo@goo@moo@roo@zoo
То есть это с одной стороны и не e-mail, а с другой стороны это не все подстроки вида текст-собака-текст,
так как boo@goo и moo@roo пропущены.
Эксперименты в песочнице
Если вы впервые сталкиваетесь с регулярными выражениями, то лучше всего сначала попробовать песочницу.
Посмотрите, как работают простые шаблоны и квантификаторы.
Решите следующие задачи для этого текста (возможно, к части придётся вернуться после следующей теории):
- Найдите все натуральные числа (возможно, окружённые буквами);
- Найдите все слова, написанные капсом (то есть строго заглавными);
- Найдите слова, в которых есть и буквы, и цифры;
- Найдите все слова, начинающиеся с русской или латинской большой буквы;
- Найдите слова, которые начинаются на гласную;
- Найдите все натуральные числа, не находящиеся внутри или на границе слова;
- Найдите строчки, в которых есть символ
*; - Найдите строчки, в которых есть открывающая и когда-нибудь потом закрывающая скобки;
- Выделите одним махом весь кусок оглавления (в конце примера);
- Выделите одним махом только текстовую часть оглавления, без тегов;
- Найдите пустые строчки;
Регулярки в питоне
Функции для работы с регулярками живут в модуле re.
Основные функции:
| Функция | Её смысл |
|---|---|
re.search(pattern, string) |
Найти в строке string первую строчку, подходящую под шаблон pattern; |
re.fullmatch(pattern, string) |
Проверить, подходит ли строка string под шаблон pattern; |
re.split(pattern, string, maxsplit=0) |
Аналог str.split(), только разделение происходит по подстрокам, подходящим под шаблон pattern; |
re.findall(pattern, string) |
Найти в строке string все непересекающиеся шаблоны pattern; |
re.finditer(pattern, string) |
Итератор всем непересекающимся шаблонам pattern в строке string (выдаются match-объекты); |
re.sub(pattern, repl, string, count=0) |
Заменить в строке string все непересекающиеся шаблоны pattern на repl; |
Пример использования всех основных функций
import re
match = re.search(r'\d\d\D\d\d', r'Телефон 123-12-12')
print(match[0] if match else 'Not found')
# -> 23-12
match = re.search(r'\d\d\D\d\d', r'Телефон 1231212')
print(match[0] if match else 'Not found')
# -> Not found
match = re.fullmatch(r'\d\d\D\d\d', r'12-12')
print('YES' if match else 'NO')
# -> YES
match = re.fullmatch(r'\d\d\D\d\d', r'Т. 12-12')
print('YES' if match else 'NO')
# -> NO
print(re.split(r'\W+', 'Где, скажите мне, мои очки??!'))
# -> ['Где', 'скажите', 'мне', 'мои', 'очки', '']
print(re.findall(r'\d\d\.\d\d\.\d{4}',
r'Эта строка написана 19.01.2018, а могла бы и 01.09.2017'))
# -> ['19.01.2018', '01.09.2017']
for m in re.finditer(r'\d\d\.\d\d\.\d{4}', r'Эта строка написана 19.01.2018, а могла бы и 01.09.2017'):
print('Дата', m[0], 'начинается с позиции', m.start())
# -> Дата 19.01.2018 начинается с позиции 20
# -> Дата 01.09.2017 начинается с позиции 45
print(re.sub(r'\d\d\.\d\d\.\d{4}',
r'DD.MM.YYYY',
r'Эта строка написана 19.01.2018, а могла бы и 01.09.2017'))
# -> Эта строка написана DD.MM.YYYY, а могла бы и DD.MM.YYYY
Тонкости экранирования в питоне ('\\\\\\\\foo')
Так как символ \ в питоновских строках также необходимо экранировать, то в результате в шаблонах могут возникать конструкции вида '\\\\par'.
Первый слеш означает, что следующий за ним символ нужно оставить «как есть». Третий также.
В результате с точки зрения питона '\\\\' означает просто два слеша \\.
Теперь с точки зрения движка регулярных выражений, первый слеш экранирует второй.
Тем самым как шаблон для регулярки '\\\\par' означает просто текст \par.
Для того, чтобы не было таких нагромождений слешей, перед открывающей кавычкой нужно поставить символ r, что скажет питону «не рассматривай \ как экранирующий символ (кроме случаев экранирования открывающей кавычки)».
Соответственно можно будет писать r'\\par'.
Использование дополнительных флагов в питоне
Каждой из функций, перечисленных выше, можно дать дополнительный параметр flags, что несколько изменит режим работы регулярок.
В качестве значения нужно передать сумму выбранных констант, вот они:
| Константа | Её смысл |
|---|---|
re.ASCII |
По умолчанию \w, \W, \b, \B, \d, \D, \s, \S соответствуют все юникодные символы с соответствующим качеством. Например, \d соответствуют не только арабские цифры, , но и вот такие: ٠١٢٣٤٥٦٧٨٩. re.ASCII ускоряет работу, если все соответствия лежат внутри ASCII. |
re.IGNORECASE |
Не различать заглавные и маленькие буквы. Работает медленнее, но иногда удобно |
re.MULTILINE |
Специальные символы ^ и $ соответствуют началу и концу каждой строки |
re.DOTALL |
По умолчанию символ \n конца строки не подходит под точку. С этим флагом точка — вообще любой символ |
import re
print(re.findall(r'\d+', '12 + ٦٧'))
# -> ['12', '٦٧']
print(re.findall(r'\w+', 'Hello, мир!'))
# -> ['Hello', 'мир']
print(re.findall(r'\d+', '12 + ٦٧', flags=re.ASCII))
# -> ['12']
print(re.findall(r'\w+', 'Hello, мир!', flags=re.ASCII))
# -> ['Hello']
print(re.findall(r'[уеыаоэяию]+', 'ОООО ааааа ррррр ЫЫЫЫ яяяя'))
# -> ['ааааа', 'яяяя']
print(re.findall(r'[уеыаоэяию]+', 'ОООО ааааа ррррр ЫЫЫЫ яяяя', flags=re.IGNORECASE))
# -> ['ОООО', 'ааааа', 'ЫЫЫЫ', 'яяяя']
text = r"""
Торт
с вишней1
вишней2
"""
print(re.findall(r'Торт.с', text))
# -> []
print(re.findall(r'Торт.с', text, flags=re.DOTALL))
# -> ['Торт\nс']
print(re.findall(r'виш\w+', text, flags=re.MULTILINE))
# -> ['вишней1', 'вишней2']
print(re.findall(r'^виш\w+', text, flags=re.MULTILINE))
# -> ['вишней2']
Написание и тестирование регулярных выражений
Для написания и тестирования регулярных выражений удобно использовать сервис https://regex101.com (не забудьте поставить галочку Python в разделе FLAVOR слева) или текстовый редактор Sublime text 3.
Задачи — 1
В России применяются регистрационные знаки нескольких видов.
Общего в них то, что они состоят из цифр и букв.
Причём используются только 12 букв кириллицы, имеющие графические аналоги в латинском алфавите — А, В, Е, К, М, Н, О, Р, С, Т, У и Х.
У частных легковых автомобилях номера — это буква, три цифры, две буквы, затем две или три цифры с кодом региона.
У такси — две буквы, три цифры, затем две или три цифры с кодом региона.
Есть также и другие виды, но в этой задаче они не понадобятся.
Вам потребуется определить, является ли последовательность букв корректным номером указанных двух типов, и если является, то каким.
На вход даётся число N, затем N строк с номером.
Определите тип номера.
Буквы в номерах — заглавные русские.
Маленькие и английские для простоты можно игнорировать.
| Ввод | Вывод |
|---|---|
5 С227НА777 КУ22777 Т22В7477 М227К19У9 С227НА777 |
Private Taxi Fail Fail Fail |
На вход даётся текст, посчитайте, сколько в нём слов.
PS. Задача решается в одну строчку. Никакие хитрые техники, не упомянутые выше, не требуются.
| Ввод | Вывод |
|---|---|
Он --- серо-буро-малиновая редиска!! >>>:-> А не кот. www.kot.ru |
9 |
Допустимый формат e-mail адреса регулируется стандартом RFC 5322.
Если говорить вкратце, то e-mail состоит из одного символа @ (at-символ или собака), текста до собаки (Local-part) и текста после собаки (Domain part).
Вообще в адресе может быть всякий беспредел (вкратце можно прочитать о нём в википедии).
Довольно странные штуки могут быть валидным адресом, например:
"very.(),:;<>[]\".VERY.\"very@\\ \"very\".unusual"@[IPv6:2001:db8::1]
"()<>[]:,;@\\\"!#$%&'-/=?^_`{}| ~.a"@(comment)exa-mple
Но большинство почтовых сервисов такой ад и вакханалию не допускают.
И мы тоже не будем :)
Будем рассматривать только адреса, имя которых состоит из не более, чем 64 латинских букв, цифр и символов '._+-, а домен — из не более, чем 255 латинских букв, цифр и символов .-.
Ни Local-part, ни Domain part не может начинаться или заканчиваться на .+-, а ещё в адресе не может быть более одной точки подряд.
Кстати, полезно знать, что часть имени после символа + игнорируется, поэтому можно использовать синонимы своего адреса (например, shаshkоv+spam@179.ru и shаshkоv+vk@179.ru), для того, чтобы упростить себе сортировку почты.
(Правда не все сайты позволяют использовать »+», увы)
На вход даётся текст. Необходимо вывести все e-mail адреса, которые в нём встречаются.
В общем виде задача достаточно сложная, поэтому у нас будет 3 ограничения:
две точки внутри адреса не встречаются;
две собаки внутри адреса не встречаются;
считаем, что e-mail может быть частью «слова», то есть в boo@ya_ru мы видим адрес boo@ya, а в foo№boo@ya.ru видим boo@ya.ru.
PS. Совсем не обязательно делать все проверки только регулярками. Регулярные выражения — это просто инструмент, который делает часть задач простыми. Не нужно делать их назад сложными :)
| Ввод | Вывод |
|---|---|
Иван Иванович! Нужен ответ на письмо от ivanoff@ivan-chai.ru. Не забудьте поставить в копию serge'o-lupin@mail.ru- это важно. |
ivanoff@ivan-chai.ru serge'o-lupin@mail.ru |
NO: foo.@ya.ru, foo@.ya.ru PARTLY: boo@ya_ru, -boo@ya.ru-, foo№boo@ya.ru |
boo@ya boo@ya.ru boo@ya.ru |
Скобочные группы (?:...) и перечисления |
Перечисления (операция «ИЛИ»)
Чтобы проверить, удовлетворяет ли строка хотя бы одному из шаблонов, можно воспользоваться аналогом оператора or, который записывается с помощью символа |.
Так, некоторая строка подходит к регулярному выражению A|B тогда и только тогда, когда она подходит хотя бы к одному из регулярных выражений A или B.
Например, отдельные овощи в тексте можно искать при помощи шаблона морковк|св[её]кл|картошк|редиск.
Скобочные группы (группировка плюс квантификаторы)
Зачастую шаблон состоит из нескольких повторяющихся групп. Так, MAC-адрес сетевого устройства обычно записывается как шесть групп из двух шестнадцатиричных цифр, разделённых символами - или :.
Например, 01:23:45:67:89:ab.
Каждый отдельный символ можно задать как [0-9a-fA-F], и можно весь шаблон записать так:
[0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}
Ситуация становится гораздо сложнее, когда количество групп заранее не зафиксировано.
Чтобы разрешить эту проблему в синтаксисе регулярных выражений есть группировка (?:...).
Можно писать круглые скобки из без значков ?:, однако от этого у группировки значительно меняется смысл, регулярка начинает работать гораздо медленнее.
Об этом будет написано ниже.
Итак, если REGEXP — шаблон, то (?:REGEXP) — эквивалентный ему шаблон.
Разница только в том, что теперь к (?:REGEXP) можно применять квантификаторы, указывая, сколько именно раз должна повториться группа.
Например, шаблон для поиска MAC-адреса, можно записать так:
[0-9a-fA-F]{2}(?:[:-][0-9a-fA-F]{2}){5}
Скобки плюс перечисления
Также скобки (?:...) позволяют локализовать часть шаблона, внутри которой происходит перечисление. Например, шаблон (?:он|тот) (?:шёл|плыл) соответствует каждой из строк «он шёл», «он плыл», «тот шёл», «тот плыл», и является синонимом он шёл|он плыл|тот шёл|тот плыл.
Ещё примеры
| Шаблон | Найденные подстроки |
|---|---|
(?:\w\w\d\d)+ |
Есть миг29а, ту154 б. Некоторые делают даже миг29ту154ил86. |
(?:\w+\d+)+ |
Есть миг29а, ту154б. Некоторые делают даже миг29ту154ил86. |
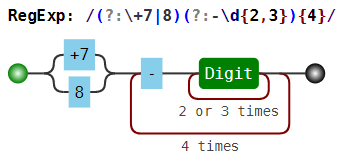
(?:\+7|8)(?:-\d{2,3}){4} |
+7–926–123–12–12, 8–926–123–12–12 |
(?:[Хх][аоеи]+)+ |
Муха — хахахехо, ну хааахооохе, да хахахехохииии! Хам трамвайный. |
\b(?:[Хх][аоеи]+)+\b |
Муха — хахахехо, ну хааахооохе, да хахахехохииии! Хам трамвайный. |
Задачи — 2
Вовочка подготовил одно очень важное письмо, но везде указал неправильное время.
Поэтому нужно заменить все вхождения времени на строку (TBD).
Время — это строка вида HH:MM:SS или HH:MM, в которой HH — число от 00 до 23, а MM и SS — число от 00 до 59.
| Ввод | Вывод |
|---|---|
Уважаемые! Если вы к 09:00 не вернёте чемодан, то уже в 09:00:01 я за себя не отвечаю. PS. С отношением 25:50 всё нормально! |
Уважаемые! Если вы к (TBD) не вернёте чемодан, то уже в (TBD) я за себя не отвечаю. PS. С отношением 25:50 всё нормально! |
Pascal requires that real constants have either a decimal point, or an exponent (starting with the letter
e or E, and officially called a scale factor), or both, in addition to the usual collection of decimal digits.
If a decimal point is included it must have at least one decimal digit on each side of it. As expected,
a sign (+ or -) may precede the entire number, or the exponent, or both. Exponents may not include
fractional digits. Blanks may precede or follow the real constant, but they may not be embedded within
it. Note that the Pascal syntax rules for real constants make no assumptions about the range of real
values, and neither does this problem.
Your task in this problem is to identify legal Pascal real constants.
| Ввод | Вывод |
|---|---|
1.2
1.
1.0e-55
e-12
6.5E
1e-12
+4.1234567890E-99999
7.6e+12.5
99
|
1.2 is legal. 1. is illegal. 1.0e-55 is legal. e-12 is illegal. 6.5E is illegal. 1e-12 is legal. +4.1234567890E-99999 is legal. 7.6e+12.5 is illegal. 99 is illegal. |
Владимир устроился на работу в одно очень важное место. И в первом же документе он ничего не понял,
там были сплошные ФГУП НИЦ ГИДГЕО, ФГОУ ЧШУ АПК и т.п.
Тогда он решил собрать все аббревиатуры, чтобы потом найти их расшифровки на http://sokr.ru/.
Помогите ему.
Будем считать аббревиатурой слова только лишь из заглавных букв (как минимум из двух). Если несколько таких слов разделены пробелами, то они
считаются одной аббревиатурой.
| Ввод | Вывод |
|---|---|
Это курс информатики соответствует ФГОС и ПООП, это подтверждено ФГУ ФНЦ НИИСИ РАН |
ФГОС ПООП ФГУ ФНЦ НИИСИ РАН |
Группирующие скобки (...) и match-объекты в питоне
Match-объекты
Если функции re.search, re.fullmatch не находят соответствие шаблону в строке, то они возвращают None, функция re.finditer не выдаёт ничего.
Однако если соответствие найдено, то возвращается match-объект.
Эта штука содержит в себе кучу полезной информации о соответствии шаблону.
Полный набор атрибутов можно посмотреть в документации, а здесь приведём самое полезное.
| Метод | Описание | Пример |
|---|---|---|
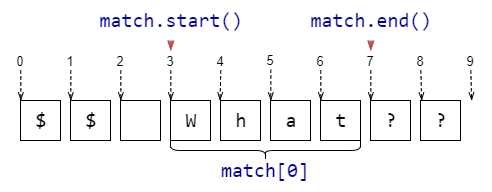
match[0], match.group() |
Подстрока, соответствующая шаблону | match = re.search(r'\w+', r'$$ What??')match[0] # -> 'What' |
match.start() |
Индекс в исходной строке, начиная с которого идёт найденная подстрока | match = re.search(r'\w+', r'$$ What??')match.start() # -> 3 |
match.end() |
Индекс в исходной строке, который следует сразу за найденной подстрока | match = re.search(r'\w+', r'$$ What??')match.end() # -> 7 |
Группирующие скобки (...)
Если в шаблоне регулярного выражения встречаются скобки (...) без ?:, то они становятся группирующими.
В match-объекте, который возвращают re.search, re.fullmatch и re.finditer, по каждой такой группе можно получить ту же информацию, что и по всему шаблону. А именно часть подстроки, которая соответствует (...), а также индексы начала и окончания в исходной строке. Достаточно часто это бывает полезно.
import re
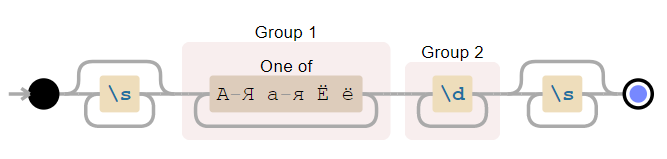
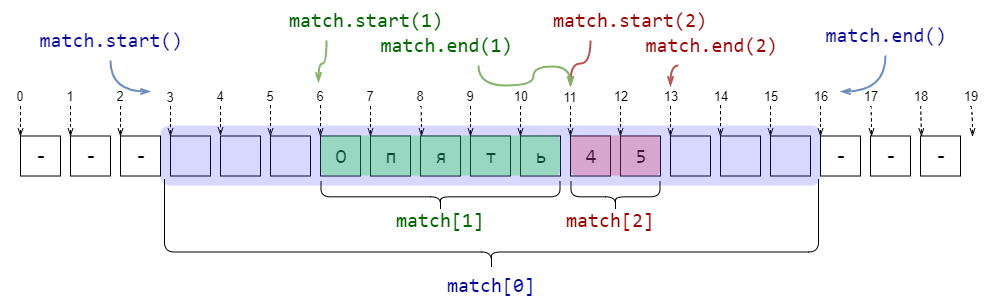
pattern = r'\s*([А-Яа-яЁё]+)(\d+)\s*'
string = r'--- Опять45 ---'
match = re.search(pattern, string)
print(f'Найдена подстрока >{match[0]}< с позиции {match.start(0)} до {match.end(0)}')
print(f'Группа букв >{match[1]}< с позиции {match.start(1)} до {match.end(1)}')
print(f'Группа цифр >{match[2]}< с позиции {match.start(2)} до {match.end(2)}')
###
# -> Найдена подстрока > Опять45 < с позиции 3 до 16
# -> Группа букв >Опять< с позиции 6 до 11
# -> Группа цифр >45< с позиции 11 до 13
Тонкости со скобками и нумерацией групп.
Если к группирующим скобкам применён квантификатор (то есть указано число повторений), то подгруппа в match-объекте будет создана только для последнего соответствия.
Например, если бы в примере выше квантификаторы были снаружи от скобок '\s*([А-Яа-яЁё])+(\d)+\s*', то вывод был бы таким:
# -> Найдена подстрока > Опять45 < с позиции 3 до 16
# -> Группа букв >ь< с позиции 10 до 11
# -> Группа цифр >5< с позиции 12 до 13
Внутри группирующих скобок могут быть и другие группирующие скобки.
В этом случае их нумерация производится в соответствии с номером появления открывающей скобки с шаблоне.
import re
pattern = r'((\d)(\d))((\d)(\d))'
string = r'123456789'
match = re.search(pattern, string)
print(f'Найдена подстрока >{match[0]}< с позиции {match.start(0)} до {match.end(0)}')
for i in range(1, 7):
print(f'Группа №{i} >{match[i]}< с позиции {match.start(i)} до {match.end(i)}')
###
# -> Найдена подстрока >1234< с позиции 0 до 4
# -> Группа №1 >12< с позиции 0 до 2
# -> Группа №2 >1< с позиции 0 до 1
# -> Группа №3 >2< с позиции 1 до 2
# -> Группа №4 >34< с позиции 2 до 4
# -> Группа №5 >3< с позиции 2 до 3
# -> Группа №6 >4< с позиции 3 до 4
Группы и re.findall
Если в шаблоне есть группирующие скобки, то вместо списка найденных подстрок будет возвращён список кортежей, в каждом из которых только соответствие каждой группе. Это не всегда происходит по плану, поэтому обычно нужно использовать негруппирующие скобки (?:...).
import re
print(re.findall(r'([a-z]+)(\d*)', r'foo3, im12, go, 24buz42'))
# -> [('foo', '3'), ('im', '12'), ('go', ''), ('buz', '42')]
Группы и re.split
Если в шаблоне нет группирующих скобок, то re.split работает очень похожим образом на str.split.
А вот если группирующие скобки в шаблоне есть, то между каждыми разрезанными строками будут все соответствия каждой из подгрупп.
import re
print(re.split(r'(\s*)([+*/-])(\s*)', r'12 + 13*15 - 6'))
# -> ['12', ' ', '+', ' ', '13', '', '*', '', '15', ' ', '-', ' ', '6']
В некоторых ситуация эта возможность бывает чрезвычайно удобна!
Например, достаточно из предыдущего примера убрать лишние группы, и польза сразу стане очевидна!
import re
print(re.split(r'\s*([+*/-])\s*', r'12 + 13*15 - 6'))
# -> ['12', '+', '13', '*', '15', '-', '6']
Использование групп при заменах
Использование групп добавляет замене (re.sub, работает не только в питоне, а почти везде) очень удобную возможность: в шаблоне для замены можно ссылаться на соответствующую группу при помощи \1, \2, \3, ....
Например, если нужно даты из неудобного формата ММ/ДД/ГГГГ перевести в удобный ДД.ММ.ГГГГ, то можно использовать такую регулярку:
import re
text = "We arrive on 03/25/2018. So you are welcome after 04/01/2018."
print(re.sub(r'(\d\d)/(\d\d)/(\d{4})', r'\2.\1.\3', text))
# -> We arrive on 25.03.2018. So you are welcome after 01.04.2018.
Если групп больше 9, то можно ссылаться на них при помощи конструкции вида \g<12>.
Замена с обработкой шаблона функцией в питоне
Ещё одна питоновская фича для регулярных выражений: в функции re.sub вместо текста для замены можно передать функцию, которая будет получать на вход match-объект и должна возвращать строку, на которую и будет произведена замена.
Это позволяет не писать ад в шаблоне для замены, а использовать удобную функцию.
Например, «зацензурим» все слова, начинающиеся на букву «Х»:
import re
def repl(m):
return '>censored(' + str(len(m[0])) + ')<'
text = "Некоторые хорошие слова подозрительны: хор, хоровод, хороводоводовед."
print(re.sub(r'\b[хХxX]\w*', repl, text))
# -> Некоторые >censored(7)< слова подозрительны: >censored(3)<, >censored(7)<, >censored(15)<.
Ссылки на группы при поиске
При помощи \1, \2, \3, ... и \g<12> можно ссылаться на найденную группу и при поиске. Необходимость в этом встречается довольно редко, но это бывает полезно при обработке простых xml и html.
Только пообещайте, что не будете парсить сложный xml и тем более html при помощи регулярок!
Регулярные выражения для этого не подходят. Используйте другие инструменты.
Каждый раз, когда неопытный программист парсит html регулярками, в мире умирает котёнок.
Если кажется «Да здесь очень простой html, напишу регулярку», то сразу вспоминайте шутку про две проблемы.
Не нужно пытаться парсить html регулярками, даже Пётр Митричев не сможет это сделать в общем случае:)
Использование регулярных выражений при парсинге html подобно залатыванию резиновой лодки шилом.
Закон Мёрфи для парсинга html и xml при помощи регулярок гласит: парсинг html и xml регулярками иногда работает, но в точности до того момента, когда правильность результата будет очень важна.
Используйте lxml и beautiful soup.
import re
text = "SPAM Here we can find something interesting SPAM"
print(re.search(r'<(\w+?)>.*?', text)[0])
# -> Here we can find something interesting
text = "SPAM Here we can find OH, NO MATCH HERE! SPAM"
print(re.search(r'<(\w+?)>.*?', text)[0])
# -> Here we can find
Задачи — 3
Владимиру потребовалось срочно запутать финансовую документацию. Но так, чтобы это было обратимо.
Он не придумал ничего лучше, чем заменить каждое целое число (последовательность цифр) на его куб. Помогите ему.
| Ввод | Вывод |
|---|---|
Было закуплено 12 единиц техники по 410.37 рублей. |
Было закуплено 1728 единиц техники по 68921000.50653 рублей. |
Акростих — осмысленный текст, сложенный из начальных букв каждой строки стихотворения.
Акроним — вид аббревиатуры, образованной начальными звуками (напр. НАТО, вуз, НАСА, ТАСС), которое можно произнести слитно (в отличие от аббревиатуры, которую произносят «по буквам», например: КГБ — «ка
