Redis и проблема больших данных

Привет, Хабр! Мы продолжаем делиться технологической кухней Retail Rocket. В сегодняшней статье мы разберем вопрос выбора БД для хранения больших и часто обновляемых данных.
На самом начальном этапе разработки платформы перед нами возникли следующие задачи:
- Хранить у себя товарные базы магазинов (т.е. сведения о каждом товаре всех подключенных в нашу платформу магазинов с полным обновлением 25 млн. товарных позиций каждые 3 часа).
- Хранить рекомендации для каждого товара (около 100 млн. товаров содержит от 20 и более рекомендуемых товаров для каждого ключа).
- Обеспечение стабильно быстрой выдачи таких данных по запросу.
Схематично можно представить так:
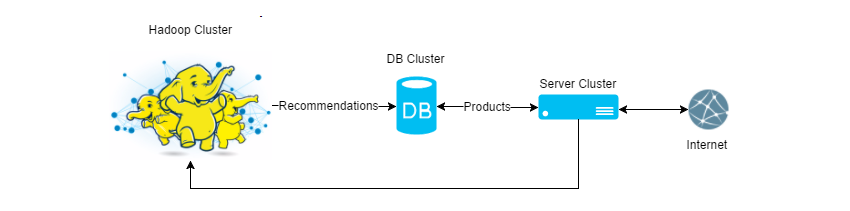
Среди популярных реляционных и документальных БД для старта мы выбрали MongoDb и сразу столкнулись со следующими трудностями:
- Оптимизация скорости обновления 100K—1M товаров за раз.
- MongoDb при записи данных упирался в диск, а призрак проблемы с вакуумом (когда запись удалена из БД, а место под нее все еще занято) заставил нас задуматься об In-memory DataBase.
Столкнувшись с первыми трудностями, мы решили продолжить поиск решения среди In-Memory Db и достаточно быстро наш выбор пал на Redis, который должен был обеспечить нас следующими преимуществами:
- Персистентность (сохраняет свое состояние на диск).
- Широкий набор типов данных(строки, массивы и т.д.) и команд работы с ними.
- Современная In-Memory Db, что оказалось немаловажным в противовес Memcached.
Но реальный мир изменил наше отношение к этим плюсам.
Чудеса персистентности

Почти сразу после запуска Redis`a в «продакшене» мы стали замечать, что временами скорость выдачи рекомендаций к товарам значительно проседает и причина была не в коде. После анализа нескольких показателей мы заметили, что в момент, когда на серверах Redis`а появляется дисковая активность, время ответа от нашего сервиса растет — очевидно, дело в Redis, а точнее в том, как он себя ведет, когда работает с диском. На некоторое время мы снизили частоту сохранения данных на диск и тем самым «подзабыли» об этой проблеме.
Следующим открытием для нас стало, что Redis недоступен все время, пока он поднимает данные с диска (это логично, конечно), т.е. если вдруг у вас упал Redis-процесс, то до тех пор, пока вновь поднятый сервис не поднимет все свое состояние с диска, сервис отвечать не будет, даже если для вас отсутствие данных гораздо меньшая проблема чем недоступная БД.
Из-за двух вышеописанных особенностей Redis`а перед нами встал вопрос: «А не отключить ли нам его персистентность?». Тем более что все данные, которые мы в нем храним, мы можем перезалить с нуля за время, сопоставимое с тем, как он сам поднимает их с диска и, при этом, Redis будет отвечать. Решено! Мы взяли за правило не хранить в Redis`е данные, без которых работа системы не возможна и, которые мы не можем быстро восстановить, а затем отключили персистентность. С тех пор прошло 1.5 года, и мы считаем, что приняли верное решение.
Выбор драйвера для Redis
Для нас с самого начала стало неприятным фактом то, что у Redis`а нет своего драйвера для .Net. Проведя тесты среди неофициальных драйверов на скорость работы, удобство использования, оказалось, что подходящий драйвер всего один. И еще хуже, что через некоторое время он стал платным и все новые функции стали выходить только в платной версии.
Нужно отметить, что с того момента прошло много времени, и, скорее всего, что-то изменилось в этой ситуации. Но быстрым анализом мы так и не увидели среди бесплатных драйверов поддержки redis-cluster, так что ситуация точно неидеальна.
Горизонтальное масштабирование
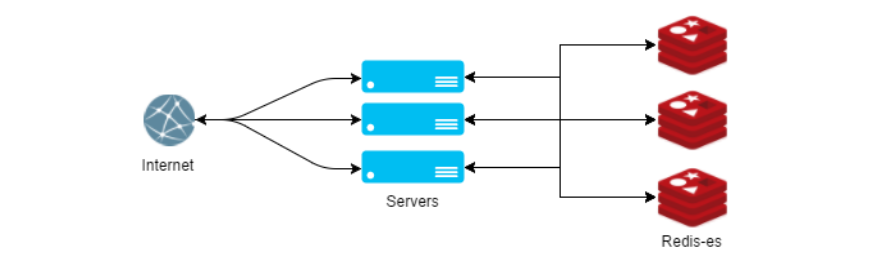
Спустя всего полгода использования Redis`а мы арендовали под него сервер с максимально допустимым количеством оперативной памяти в ДЦ, и стало понятно — шардинг не за горами. Redis-cluster, на тот момент, только собирался выходить, а ставшими платными драйвера, подсказывали, что нам придется решать эту задачу самим.
Нам до сих пор кажется, что есть только один вариант сделать шардинг в Redis`е правильно. Если описывать этот способ просто, то мы запроксировали все методы, получающие ключ записи в параметре. Внутри каждого такого метода хешируется ключ, и простым остатком от деления выбирается сервер, на который записывается/считывается ключ. Казалось бы, достаточно примитивное решение, не лишенное своих явных недостатков, позволяет нам до сих пор с успехом не думать о проблемах с горизонтальным масштабированием.
Код нашей реализации обертки для RedisClient с поддержкой sharding`а вы можете посмотреть в нашем репозитории на GitHub.
Главной задачей после внедрения шардинга стало слежение за доступностью оперативной памяти на Redis-серверах. Свободной памяти на серверах должно быть столько, чтобы при падении 1-2 Redis-машин нам хватило бы памяти для передачи всех данных на оставшиеся в бою сервера и продолжения работы до тех пор, пока вылетевшие сервера не вернутся в строй.
Первые проблемы производительности
Так как Redis может хранить только текстовые данные, то объекты перед сохранением приходиться сериализовать, а перед выдачей десериализовывать в какой-то текстовый формат. Наш драйвер по умолчанию сериализует данные в JSON-формат и мы заметили, что процесс десериализации отъедает значимое время выдачи рекомендаций. Проведя беглый анализ сериализаторов, мы приняли решение заменить стандартный серилизатор драйвера на JIL, что полностью сняло вопрос производительности сериализиторов.
В заключение
Прочитав все пункты выше, может сложиться впечатление, что Redis — это проблемная БД с кучей скрытых рисков, но на самом деле именно с Redis`ом у нас все прошло предсказуемо. Мы всегда понимали, где ждать проблем, поэтому решали их заранее. Мы используем Redis в бою уже 2 года и, хотя нас и посещают иногда мысли «А не заменить ли его «на обычную БД»?», мы все еще считаем, что сделали правильный выбор в самом начале нашего пути.
Наш чеклист «как правильно приготовить редис»:
- Хранить только те данные, которые можно быстро восстановить в случае потерь.
- Не использовать персистентность редиса.
- Свой шардинг.
- Использовать эффективный сериализатор.
