Record-and-Replay тестирование — сочетание достоинств юнит и интеграционных тестов

Вступление
Привет, Хабр. Сегодня я расскажу вам про Record-and-Replay подход к тестированию т. к. я его понимаю. Оговорка про мое понимание не случайна. Про этот подход не так много общедоступных материалов, чтобы иметь некий common agreement относительно значения этого термина. Многое из того, что я опишу, является моими личными оригинальными находками, но, тем не менее, фраза record-and-replay, на мой взгляд, наилучшим образом описывает применяемые мной решения. Так что я буду использовать именно ее.
Чтобы было проще понять, какие проблемы решает RnR, в ходе этого разговора мы сначала обсудим некоторые другие подходы к написанию тестов (юнит-тестирование, интеграционное тестирование и т. д.). И отталкиваясь от их недостатков перейдем к варианту с RnR, я расскажу, что же это собственно такое, как это работает, и каким образом решает озвученные ранее проблемы. Поговорим про подводные камни, которые могут свести пользу от внедрения всего этого дела к нулю. Ну и, конечно, обсудим недостатки или границы применимости этого подхода.
Примеры кода в статье на Java, но язык простой, так что на чем бы вы не программировали, у вас вряд ли возникнут проблемы с их пониманием. Тем более что они несут больше иллюстративную функцию. Сама философия статьи применима ко многим стэкам.
Ключевой постулат
Итак без лишних предисловий к ключевой идее статьи. В ней будет немало оценочных суждений, и думаю необходимо сразу сказать, в свете какой идеи я делаю эти оценки. Итак… Ключевой постулат — »Ресурсы на тестирование ограничены».
Ограничено человеческое время, что значит, что у нас определенное количество людей, и они могут потратить на контроль качества определенное количество времени. Ограниченно машинное время для выполнения автотестов. Об этом не всегда вспоминают, потому-что машинное время часто дешевле человеческого, но если бы этого ограничения не было, то вы могли бы получить любой суперкомпьютер/вычислительный кластер, так что ваши тесты выполнялись бы за ничтожное время, сколько бы медлительными они не были. Наконец, есть еще одно ограничение. На какой стадии (и через какое время) производственного процесса вам становится известно о проблемах с качеством. Отчасти оно является производной первых двух, но только отчасти. Даже будь у вас миллиард тестировщиков и все процессорное время мира, пока код даже не попал в вашу систему контроля версий, не говоря уж о том, чтобы куда-то продеплоиться, эти безграничные ресурсы ничего не ускорят.
Принцип довольно простой и очевидный, поэтому я надеюсь, что все читатели со мной согласны на данном этапе. Соответственно, ключевой вопрос тестирования в этом понимании — »Как нам обеспечить как можно большую степень уверенности в качестве продукта, потратив как можно меньше ресурсов? » Тут акцент на правое или левое плечо фразы в зависимости от вашей ситуации. Например, если у вас есть условных 5 человекочасов на тестирование, то мы делаем акцент на «большую уверенность». Как с максимальной пользой для дела эти 5 человекочасов использовать. Или, напротив, если вас выделенным временем на тестирование не балуют, акцент смещается в сторону «меньше ресурсов», так чтобы получить хорошую степень уверенности за такой минимум времени, который вы все-таки сможете выкроить без специального разрешения начальства. Надеюсь вы поняли, как именно я попытался сделать эту фразу универсальной. Т. е. это некая оптимизационная задача, где ресурс мы всегда минимизируем, а уверенность максимизируем.
Пример проекта

Итак, в качестве наглядной иллюстрации представляю вам команду «Бородачи-кодеры». Это господа славятся не только своими бородами, но и умением решать непростые инженерные задачи. Совсем недавно они стали овнерами проекта FAIL (fast agile ingestion leader), который до этого разрабатывался другой командой. Ingestion leader он потому-что занимается оркестрированием сложного процесса ingestion«а — загрузки контента в систему, например .zip с новой книгой, в ходе которого координирует работу около десятка микро- и не очень сервисов. Agile, потому-что это модно, а Fast потому-что думали, что эта штука ускорит бизнес-процесс, но получилось не как хотели, а как всегда. Старая команда вроде и писала тесты, но по факту когда бородачи стали смотреть код, выяснилось, что тестами там все покрыто весьма жиденько и разнородно. Да и рефакторингом предшественники себя, похоже, не слишком утруждали. Теперь нашим бородачам нужно придумать, как по-быстрому обеспечить хоть какой-то контроль качества и двигать проект к новым горизонтам, т. е. реализовывать хотелки бизнеса, которые сыпятся как из рога изобилия. Возможно для кого-то из вас ситуация жизненная и знакомая. Итак, какие же писать тесты? Бородачи сели, чешут бороды, обдумывают.
Вариант №1. А давайте покроем все юнит-тестами?
void sendReadyForDeliveryEvent(CompositeContentContainer contentContainer,
EntityDescriptor packageDescriptor) {
LocalizedLearningProduct product = contentContainer.getProduct();
EntityDescriptor productDescriptor = new EntityDescriptor(
product.getId(), product.getType().getValue()
);
EntityDescriptor elementDescriptor =
convertContentObjectToEntityDescriptor(contentContainer);
List@Test
public void shouldSendReadyForDeliveryEvent() {
// given
EntityDescriptor productDescriptor = createEntityDescriptor(
productId, product.getType().getValue()
).get();
EntityDescriptor deliveryPackageDescriptor =
createEntityDescriptor("id", "type").get();
EntityDescriptor elementDescriptor = createVersionableEntityDescriptor(
elementId, LearningElement.TYPE, currentElementVersion
).get();
willReturn(elementDescriptor).given(sut)
.convertContentObjectToEntityDescriptor(any());
// when
sut.sendReadyForDeliveryEvent(contentContainer, deliveryPackageDescriptor);
// then
verify(contentTopicService).sendEvent(
PACKAGE_READY_FOR_DELIVERY,
List.of(productDescriptor, elementDescriptor, deliveryPackageDescriptor, job)
);
}Может вы уже видели тесты такого рода в своем проекте, а может и сами такие пишете. Вот достаточно типичный юнит-тест из живого проекта (слегка модифицированный ради соблюдения NDA), который я взял в качестве примера. Во-первых на что я сразу хочу обратить ваше внимание — это соотношение количества кода в тесте к количеству тестируемого кода. Как видите, примерно 1:1. Причем большая часть кода теста — это настройка моков Mockito. Что еще примечательного в этом тесте? Сильная связность с исходным кодом. Хотя тест и назван так, что отражает некое требование контракта, по факту если это требование не поменялось, но код в результате рефакторинга хоть как-то поменяется, тест тоже придется менять. Что еще? Глядя на тест я гораздо меньше понимаю относительно того, что должно делать приложение, чем глядя на сам тестируемый метод. Может это только у меня? Кому кажется, что этот тест лучше документирует приложение?
Конечно, это только один тест. Судить по нему о всех юнит-тестах нельзя, но этот тест, на мой взгляд, представляет собой типичный пример юнит-тестов, тестирующих glue code (склеивающий код). Склеивающий код — программный код, который служит исключительно для «склеивания» разных частей кода, и при этом не реализует сам по себе никакую иную прикладную функцию. Когда мы пытаемся протестировать склеивающий код, мы часто заканчиваем с такими юнит-тестами, где требуется много моков и сильная связность с тестируемым кодом. Я не раз читал, что тестирование glue code — это антипаттерн. За процент сказать не решусь, но это точно не единичное мнение в индустрии. Гуглить по фразе glue code unit testing.
Вы можете заметить, что для иллюстрации недостатков юнит-тестов я взял очень неудачный юнит-тест — и будете правы. Есть хорошие алгоритмически содержательные методы, которые отлично тестируются юнит-тестами. Но вот какое совпадение… Я заметил, что подавляющее количество кода, который я пишу — это именно склеивающий код. Вот не пишем мы что-то алгоритмически сложные вещи типа новых алгоритмов сортировок или компиляторов. Не знаю, как у вас в вашем Company Name. Но у меня так.
Таким образом, вот перечисление недостатков юнит-тестов с оговоркой, что степень выраженности этих недостатков может быть меньше или больше в зависимости от вашей специфики.
Много кода — дорого писать и поддерживать. В этой связи меня часто удивляет, когда юнит-тесты считаются самыми дешевыми. Может вы слышали девиз code less — do more. Если можно решить проблему без лишнего кода, это зачастую предпочтительно потому-что код помимо написания (единоразовая активность) нужно еще сопровождать. Каждая лишняя строчка кода — это бремя с которым вам придется жить.
Мало чего проверяют в общей перспективе.
Сильная связность с тестируемым кодом — удорожает рефакторинг. В идеале тестирование должно развязывать вам руки для рефакторинга, помогая улучшать кодовую базу без страха что-то сломать. Юнит-тесты иногда могут делать прямо наоборот, потому-что их нужно перелопатить при рефакторинге.
Мало говорят о работе системы. Скажем прямо юнит-тест, проверяющий, что метод C класса А должен вызвать метод D класса B не сильно то много рассказывает о вашей системе. С точки зрения парадигмы «тесты = документация» юнит-тесты часто проигрывают всем вариантам.
Хочу подчеркнуть. Я не против юнит-тестов. И снова сошлюсь на главную идею «ресурсы на тестирование ограничены». Юнит-тесты плохие, если в данной конкретной ситуации стоят дорого относительно benefit«а. И юнит-тесты хорошие, если в данной в данной конкретной ситуации стоят дешево. Очень часто люди бездумно пишут юнит-тесты из некоего чувства долга. Хотя об этом позже, в разделе, где я про коснусь религии тестирования.
Вариант №2. Интеграционные/end-to-end тесты с внешними зависимостями
Что имеется ввиду? Когда у вас есть некая корпоративная сеть и окружение, где поднят каждый компонент и вы тестируетесь, реально используя этот компонент. Обычно это некое staging-окружение специально для тестов. Набор серверов, где поднято все от и до. Более-менее похоже на то, как оно все синтегрированно на проде, но для тестирования. Например, у нас есть несколько таких: dev, qa, ppd, perf. Проблемы с этими тестами довольно общеизвестные. Они долго отрабатывают. Они flaky. Я не нашел такого же краткого и емкого русского термина, подскажите, если знаете. Flaky это тест, который то красный, то зеленый по каким-то случайным причинам. А поскольку такие тесты вовлекают целый набор компонентов и выполняются долго, то потенциал для Flaky просто огромный. Какой-нибудь минутный лаг сети из-за плохой погоды во время 3-хчасового прогона и вот часть ваших тестов красная, хотя фактически ошибок в приложении нет.
Они дороги в машинных ресурсах. Держать полноценное окружение для тестирования — это не про дешевизну. Наконец, они зачастую не очень хорошо интегрируются в пайплайн. По хорошему прохождение тестов должно быть непременным условием, чтобы кнопочка merge для нового кода стала зеленой, но с тестами выполняющимися по несколько часов такое условие соблюсти затруднительно. В итоге код мержится и бывает даже не одна, а несколько веток/задач одновременно. Потом для всего этого прогоняются тесты, что-то падает, и человеку, обеспечивающему контроль качества, приходится разбираться, какой же новый код все сломал, а программист уже за другую задачу сел, ему нужно снова переключать контекст, чтобы починить код, который уже в репозитории. Я уже не говорю о том, что один из принципов DevOps в том, что из master можно выйти на прод в любой момент, потому-что код должен тестироваться до попадания в master. С такими тестами это становится несбыточной сказкой. Это к вопросу про третий аспект цены тестирования — цикл обратной связи.
Вариант №3. Интеграционные тесты зависимостями в докере
Итак, наши бородачи-кодеры рассмотрели 2 довольно классических варианта, но оптимального решения все еще не нашли. Но они же умные ребята. Они знают Docker, Kubernetes и много других умных штук. «Почему бы не поднять все зависимости в докер-контейнерах?» — задумались они. Нам не понадобится дорогущее окружение, тесты можно будет запускать хоть на localhost. Они начинают работу в этом направлении, и перед ними встает несколько проблем. На самом деле докер здесь просто buzzword, речь в принципе о контейнерах.
Не все системы нам подконтрольны. В большой семье не без урода. Может у вас есть компонент, который не контейнеризируется нормально? Множество препятствий может стать на пути контейнеризации каждой конкретной зависимости. Лицензионные проблемы. Например, нужна полноценная версия Oracle Database. Форма поставки, которую мы не можем изменить. Например, система поставляется в виде установочного образа для установки bare-metal т. е. только на железо. Или как набор Ansible-плейбуков. Какие-нибудь внутренние политики компании, запрещающие копирование этого компонента. Или система сама представляет из себя завернутый в Docker-образ Docker Compose, где в свою очередь поднимается десяток подсистем, так что она стартует долго и жрет прорву машинных ресурсов. Многие из этих проблем преодолимы так или иначе, но сколько ресурсов вы можете потратить на их преодоление?
Это не говоря уже о том, что в Docker Compose у вас может подниматься достаточно много всего, так что тесты все равно становятся flaky. Ну и вишенкой на торте — иметь дистрибутив зависимости не всегда значит иметь все необходимое, потому-что иногда нужны тестовые данные, без которых эта зависимость бесполезна. Для которых может не быть скриптов инициализации или бэкапов, чтобы импортировать это в ваш контейнер.
Вы, наверное, обратили внимания, как часто я говорил сейчас «иногда» и «может быть». Да, иногда и может быть никаких этих препятствий не встанет. И у вас все легко, быстро и стабильно запускается командой docker compose up. Если вы из этих счастливых людей и у в ваших компонентах такой порядок, то просто забейте на эту статью. Вам незачем слушать такого неудачника как я. Вы справились со своей инфраструктурой намного лучше. Система должна подниматься в работоспособной и тестируемой конфигурации одной командой или кликом в идеальном случае. Это действительно образцовый подход. И если вы этого добились, вам ненужно мое трюкачество с RnR. Тех же, кому в жизни повезло меньше, приглашаю проследовать со мной к следующему тезису.
Вариант №4. Самописные моки для зависимостей
Итак, компания, где работали наши бородачи, оказалась не из самых прогрессивных. Они также столкнулись с проблемами при докеризации всех зависимостей для своего компонента. И стали рассматривать другие подходы. И следующий вариант, а что если взять наши зависимости и написать для них простейшие мок-сервера, покрывающие только необходимый нам функционал? Звучит, неплохо, но давайте посмотрим, какую работу мы себе при этом добавляем? Помимо, собственно, времени на написание моков, нам также придется потратить время на их актуализацию и сопровождение. Наконец, когда пишутся моки для сторонних сервисов, очень часто опускаются «несущественные» детали, которые на деле являются вполне себе существенными, но мы об этом как-то не подумали. Может быть реальный сервис делает валидацию входного параметра X, а в нашем моке, естественно, ни о какой валидации не подумали. Моя предыдущая команда наступила на эти грабли, когда разрабатывали компонент во многом полагаясь на моки собственной разработки. Их компонент на моках работал, но стадия когда понадобилось этот компонент «дружить» с реальными компонентами, в итоге очень затянулась. У нас на стэндапах фраза «на моках работает» на некоторый период времени стала крылатой.
Может быть вы скажете, а что если сделать некий гибридный подход, когда мы легко докеризуемые сервисы запускаем в докере, а для проблемных делаем мок-сервера. Это неплохая идея и вообще часто именно гибридные подходы и помогают нам хорошо так сэкономить усилия. Поэтому предлагаемая мной сегодня на рассмотрения идея тоже является гибридной, только это немного другой гибрид. RnR — это гибрид подходов с внешними зависимостями, мок-серверами и даже отчасти юнит-тестами.
Вариант №5. Record-and-replay
Основная идея крайне проста. При первом прогоне теста мы записываем ответы сторонних систем, а при последующих воспроизводим записанные ранее ответы. Давайте посмотрим, какие из вышеозвученных проблем мы тогда решим.
Во-первых эти тесты долго отрабатывают только в первый раз, когда вы пишете кассеты. Кассеты — это как раз те файлы, куда записывается трек ответов от сторонних систем. Но при последующих прогонах все выполняется со скоростью сравнимой с юнит-тестами, потому-что запросы не уходят никуда дальше локалхоста и, при этом, мы не тратим время на поднятие зависимостей. А поскольку чаще всего запись кассеты единичная операция, а вот прогон тестов в пайплайне — частая, получается, что тесты отрабатывают быстро когда это нужнее всего. Благодаря этому они легко интегрируются в пайплайн, ведь внешних зависимостей нет, а значит ваша Jenkins-джоба может работать также, как если бы это были юнит-тесты. И они не flaky поскольку никакие флуктуации сетевой связности или работы сложных внешних компонентов не оказывают на них влияния.
Но при этом для них не требуется писать много кода, как для юнит-тестов, потому-что проблема мокирования зависимостей теперь снимается с ваших плеч. Вы можете использовать ваше уже имеющееся окружение для записи кассет. Например, упомянутый ранее QA-environment.
И по объему проверяемой логики эти тесты превосходят юнит также, как и интеграционные, потому-что по сути они такие и есть. Чтобы записать кассету нужно, чтобы ваши запросы прошли все валидации в компонентах-зависимостях вашего приложения.
Вам определенно понадобится кое-что сделать с вашим приложением, чтобы запросы уходили не во внешнюю сеть, а в библиотеку, которая обеспечит эту логику: первый прогон пишем, потом воспроизводим. Но обычно для сетевого взаимодействия мы используем какую-то библиотеку, поэтому слишком сильной связности с кодом эти тесты иметь не будут. Замена одной библиотеки — это не мокирование каждого второго класса в коде.
Наконец, эти тесты говорят о работе системы даже больше, чем традиционные, потому-что в кассетах у вас будут записаны те детали взаимодействия с вашими зависимостями, которые в обычном случае вы могли бы посмотреть только под отладчиком, запустив интеграционный тест.
Решена проблема поддержания моков в актуальном состоянии, потому-что всегда можно просто стереть кассету и просто выполнить тест на запись снова. Ну, а поскольку сервисы реальные, то никаких проблем с упрощением в моках мы тоже не испытываем.
Можно было бы удивиться, почему при всей простоте идеи, это не используется повсеместно. Но я думаю, что объяснение этому все-таки есть. Чисто умозрительно сразу возникают определенные сомнения, относительно того, будет ли это так просто, как звучит на словах. Возможно как раз какое-то из этих сомнений как раз сейчас пришло вам на ум и вы сидите и думаете: «Не, ну это не будет так просто, потому-что…» Вот на эти «потому-что» я сейчас и попытаюсь ответить. По крайней мере на те, о которых мне известно. Может в комментариях вы обогатите мою копилку новыми «потому-что».
Подводные камни (опасения), как не запороть идею
Я назвал этот раздел так, потому-что все эти опасения, которые я сейчас буду перечислять, вполне возможно получить исполнившимися на практике, если применить эту идею не очень разумно. Т. е. в каком-то смысле все эти опасения справедливы. Подход RnR реально может доставить больше головной боли, чем удобства, если вы не обойдете некоторые подводные камни в ходе его имплементации. Поэтому форма подачи будет в виде набора абзацев, где подзаголовком будет некое опасение, а в тексте, как нужно делать, чтобы оно не стало реальностью.
Кассеты будут меняться на каждый чих. Действительно, в чем смысл от выполнения с воспроизведением кассеты, если в вашем приложении эти тесты будут почти всегда выполняться в режиме записи, т. е. как обычные интеграционные? Вы просто получаете интеграционные тесты с дополнительной головной болью. Поэтому нужно сделать так, чтобы у вас кассеты не требовали постоянной перезаписи. И самый простой принцип здесь — разделите тест кейсы. Если у вас все взаимодействие с внешними сервисами будет свалено в одну кучу, например, в один файл, то естественно этот файл будет меняться постоянно. И его постоянно придется снова перезаписывать. Ведь кроме рефакторингов все изменения в коде приложения функциональные, а значит что-то будет меняться и в его поведении с внешними сервисами.
Но вот в чем штука, на самом деле ситуаций когда у нас полностью с очередным коммитом меняется все поведение с внешними сервисами очень мало. Обычно в приложении добавляется/меняется маленький кусочек функциональности, который отвечает за изменения в каком-то конкретном сценарии работы. Изолируйте эти сценарии. Например, сделав по кассете на каждый тестовый метод в своем наборе тестов. Пример: в приложении бородачей был сценарий, когда происходила загрузка zip«а с книгой. И когда происходила загрузка jpeg«а с обложкой книги. И они написали 2 теста, по одному на каждый сценарий. И когда кто-то менял какие-нибудь нюансы работы с jpeg, например требования по минимальному разрешению картинки, перезаписывать надо было только кассету для одного теста. А все остальные оставались нетронутыми. И лишь один тест им надо было перезапускать в режиме записи новой кассеты. И лишь один файл с кассетой менялся в репозитории. Причем по названию файла было четко видно, для какого сценария поменялся контракт. И если вдруг один бородач обнаруживал, что после правок для изменения разрешения картинки ломался тест testIngestionZip, потому-что в кассете не было запроса к сервису Y на валидацию картинки, то было вполне очевидно, что он случайно внес нежелательные изменения, потому-что для zip ему вообще ничего трогать было не надо. Итак, первый принцип — изолированные сценарии. Меняться в репозитории должно только то, что действительно меняется.
Поведение системы уникально при каждом прогоне. Например, мы делаем запрос на создание некоей сущности и генерируем ее id — какой-нибудь uuid. При каждом запуске приложения эта случайная величина будет другой. И, естественно, ни о каком выполнении тестов на кассетах и речи быть не может, потому-что каждый раз это будет немного другая пара request/response. Естественно, такой RnR никому жизнь не облегчит, я с вами полностью согласен. Поэтому… Для тестовой конфигурации уберите из системы недетерминированность. Это на самом деле очень простое и быстрое решение, потому-что вообще-то наши программы в своей основе чаще всего детерминированны. Компьютеры вообще детерминированная штука. В них нет очень мало случайности. Даже случайные числа, которые мы используем в своих программах, на самом деле псевдослучайные, поскольку представляют из себя элементы определенной математической последовательности, генерируемой строго детерминированным алгоритмом. Который устроен так, чтобы эти числа казались случайными. Просто стартовая итерация этого алгоритма инициализируется чем-то случайным из случайного мира людей, а не компьютеров. Например текущей датой, потому-что кто знает когда пользователю взбредет нажать кнопочку Z? Эта случайная величина становится seed (семенем) генератора псевдо-случайных чисел, на основании которого он потом генерирует последовательность псевдо-случайных чисел.
Кто в теме, те понимают, что я сейчас малость упростил. Например, не упомянув аппаратный генератор случайных чисел. Кто не в теме, можете погуглить и стать в теме. Но и тех и других я подвожу к одной простой мысли. Из вашей программы, скорее всего, очень легко убрать случайность, потому-что она в принципе для компьютеров нехарактерна. Источников случайности внутри компьютера не так уж и много. Например, как в представленном примере, поменять тестовый контекст, чтобы UUID в приложении генерировались не случайно, а каждый раз одни и те же. До тех пор, пока вы задаете в тесте тот же seed. И все. Id вашей сущности в тестах теперь не случайная величина, а повторяемая. И у вас одни и те же пары request/response.
@Bean
public UuidGenerator uuidGenerator() {
return new UuidGenerator() {
@Overide
public UUID generateUuid() {
return UUID.nameUUIDFromBytes((seed + counter++).getBytes());
}
}
}Можно заменить все вызовы new Date (), если эти даты у вас где-то в запросах на вызов некоего бина-провайдера даты. А в тестовом контексте этот провайдер будет выплевывать просто одну и ту же дату. Снова убрали недетерминированность.
Если не получается справиться с недетерминированностью, вы всегда можете немножко подправить матчинг request на response в вашей библиотеке, отвечающей за запись/вопроизведение кассеты. Например, добавив в матчинг такую регулярку, чтобы разные uuid в некоем url«е матчились как одинаковые. Когда перейдем к рассмотрению библиотек, я как раз покажу пример кода. Но это плохой путь. По возможности лучше избавляться от недетерминированности. Сейчас объясню, почему.
Кассеты будут в аршин длинной, поэтому на код-ревью никто не будет проверять, что там поменялось. И это правда. Если кассеты нечитаемые или diff их изменений в pull-request огромен, то все будут просто забивать, чего там меняется. А если этот текст никто не смотрит, то велика вероятность, что там появится полная ерунда. Например, при очередном pull-request нам отправят код, который вместо правки минимально допустимого размера картинок вообще отключает эту валидацию. Но никто кассету не смотрит. Поэтому не увидит, что в сервис валидации картинок теперь отправляется полная чепуха. Если на изменения в кассетах не смотрит человек, то ваши RnR тесты нередко вместо, собственно, тестирования могут создавать иллюзию протестированности. Как бороться? Обеспечьте хороший человекочитаемый diff. Минорные изменения в коде не должны приводить к тому, что у вас поменялась вся кассета целиком. Кассеты представляют своего рода документацию на контракт приложения. Они должны помогать вам легче видеть связь изменений в коде и изменений в контракте.
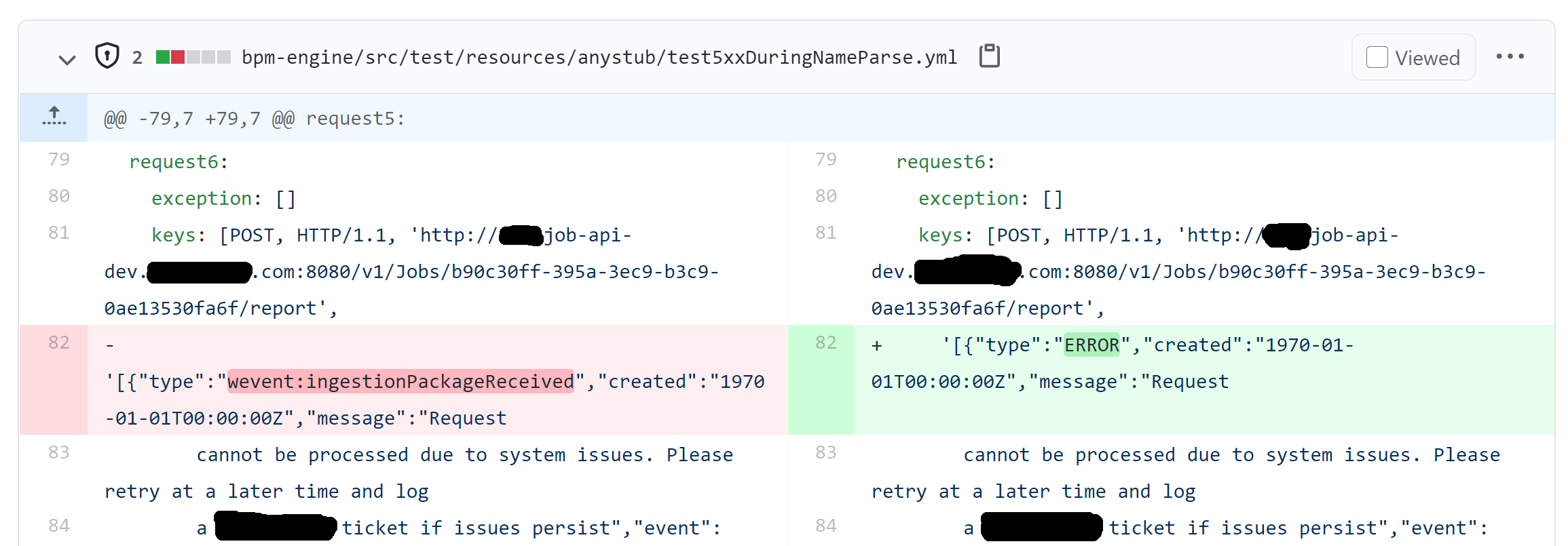
Посмотрите пример на скриншоте. Это diff изменений в кассете. Выяснилось, что изначально приложение было реализовано неправильно, и вместо уровня информативности строки отчета (ERROR/INFO и т. п.) отправляло какую-то чепуху. Были внесены изменения, чтобы отправлялся именно уровень информативности. И на diff это четко видно. Представьте себе, если бы в этой строчке поменялась еще и дата. Легко бы ваш взгляд зацепился и увидел, где же меняется контракт после этого коммита? А если бы поменялись все строчки до и после? Именно поэтому в рекомендации ранее я советовал стараться убирать недетерминированность, а не править матчинг регулярками. Это помогает еще и diff кассеты делать более читаемым. Ну, а так вообще здесь нет какого-то универсального рецепта. Смотрите глазами ваши diff«ы. И старайтесь править то, что мешает их читаемости. Может ваше приложение вообще работает по бинарным протоколам? Если нет возможности модифицировать тестовый контекст так, чтобы в кассетах сохранялось их какое-нибудь человекочитаемое представление, то, возможно, RnR вам радикально не подходит.
Например, ваше приложение отправляет в сторонний сервис крошечный .xlsx — это формат Microsoft Excel и он бинарный. Но на самом деле это .zip, в котором лежит несколько .xml-файлов. Открыв этот файл в архиваторе вы легко это увидите. Рекомендация: отправляйте на сторонний сервис .xlsx, а в бин клиента этого сервиса в тестовом контексте модифицируйте так, чтобы в кассеты попадали распакованные .xml из этого .zip. Это просто пример, тут нет универсальных решений, зависит от специфики вашего приложения. Просто принцип, нечеловекочитаемые кассеты сильно снижают ценность RnR. Поборитесь за человекочитаемость. Но только это если это не сильно дорого. Ведь наши ресурсы ограничены, помните, да?
Ну и еще несколько опасений, на которые у меня нет рекомендации, как избежать, чтобы они сбылись. RnR не серебрянная пуля и может не дать вам существенных преимуществ. Например, если проблема flaky-тестов у вас не внешние зависимости, а то, что само ваше приложение работает через раз. Или оно стартует по полгода и дело не в сетевом взаимодействии. В вашем пайплайне с RnR оно все равно будет запускаться так же полгода.
Еще один совет, хотя он, пожалуй, универсальный, а не только про RnR. Вы можете легко свести преимущество перед юнит-тестами на нет, если писать тесты не с позиции внешних контрактов вашего приложения. Когда у вас поменялся тест testCnZipHappyPath, все ли поймут, какой бизнес-кейс теперь работает по-другому? Непонятные, ничего не документирующие, непрозрачные тесты можно писать и с RnR, если называть их как попало и мешать в кучу сценарии, которые с позиции бизнеса или контрактов вашего приложения совершенно разные. Называйте тесты понятно, делите их так, чтобы они были логически изолированны. Что было бы, если бы команда бородачей в одном тестовом методе проверяла и .zip и .jpeg? Вдобавок к тесту, который непонятно что проверяет, они бы еще получили и кассету, которая непонятно какой кейс описывает. 2 проблемы по цене одной.
Ах да. И последнее. Не забудьте сделать так, чтобы в кассетах у вас не оседали всякие секретные ключи и прочие пароли. Идея в том, чтобы кассеты хранились в git вместе с приложением. А секретам в git не место. Например, отключите запись в кассеты тел запросов для своего авторизационного API. Ведь чаще всего в запросах на авторизацию есть пароль в открытом виде в request body.
Библиотеки
Итак, если мне удалось вас убедить в жизнеспособности идеи, и вы хотите попробовать, то как же это сделать? Чтобы вам не собирать все шишки, которые я собрал, я немножко поделюсь сниппетами кода и деталями реализации.
В основном про Java, но немного скажу и про другие языки. Во-первых, что у нас есть из готового? WireMock, который, уверен, многие знают или хотя бы слышали, умеет работать в режиме записи/вопроизведения. Сам не пробовал, читал в документации, что есть такая возможность. Я остановился на втором варианте — AnyStub. Про него и расскажу, поскольку это то, с чем у меня есть опыт.
WireMock — это полноценный веб-сервер, который слушает на определенном порту, но может быть запущен как часть вашего приложения и имеет JavaAPI для управления этим запущенным сервером. Это позволяет его применить в более широком диапазоне случаев, ведь все-таки это по сути стандартное HTTP-взаимодействие. В режиме записи WireMock отправляет ваш запрос на внешний API, а ответ ретранслирует и сохраняет себе на будущее для воспроизведения. Ну и, конечно, если у вас не Java, вы можете запустить WireMock в docker, а в своем приложении прописать его URL вместо реальных внешних зависимостей.
В отличии от него AnyStub имеют чуть более узкую сферу применимости. Потому-что он подменяет Apache Http Client. Многие библиотеки/фреймворки в Java под капотом используют Apache Http Client, тот же Open Feign или Spring Rest Template. Многие, но не все, что и ограничивает его применимость. Однако зато AnyStub очень легко в строить в тестовый Spring-контекст, он легко туда входит как замена этого самого Apache Http Client.
Пример с AnyStub
@Configuration
public class RnrTestConfig {
private HttpClient httpClient() {
HttpClient real = HttpClientBuilder.create().build();
StubHttpClient stubHttpClient = new StubHttpCleint(real);
return stubHttpClient;
}
@Bean
public Client feingClient() {
return new ApacheHttpClient(httpClient());
}
}Вот пример тестовой конфигурации. Как видите, здесь все тривиально. Создали StubHttpClient, которому подсунули настоящий. Когда нужно будет отправлять запрос на реальный сервер, этот клиент переправит его настоящему. А когда нужно брать ответ из кассеты, то сам поищет соответствующий этому запросу response в кассете и вернет его якобы тот пришел из стороннего сервиса. Подсовываем тому же Feign наш липовый httpClient и готово. Больше конфигурировать особо нечего.
@RunWith(SpringRunner.class)
@TestPropertySource(locations="classpath:application-test.properties")
@AnySettingsHttp(
bodyTrigger = { // include bodies in matching requests only to specific
// external APIs
"job-api-dev.somewhere.com:8080/",
"validation-service-dev.somewhere.com:8080/"
},
bodyMask = { // multipart boundaries are not repeatable, so we mask them
"/content/", "--(.*)(--)?\\r"
}
)
public class CompleteCnWorkflowRnrTest {
@Test
@AnyStubId(requestMode = requestMode.rmTrack)
public void testBookZipUploadHappyPath() {
uuidGenerator.setSeed(getMethodName() + "_cassette#3_");
startProcess(buildUrl("nonprod-exchange-dev", "Book1976_en-US.zip"),
getAuthToken());
assertEquals(getFlowOrder(getMethodName()), flowTracker.populateStages());
}
}Теперь, собственно, сам код теста. Это обычный в общем-то Spring-тест. Из специфичного тут пара аннотаций для того, чтобы AnyStub знал, как работать с этим тестом. Первая — @AnySettingsHttp позволяет несколько кастомизировать поведение AnyStub. Например, по умолчанию тела запросов не сохраняются в кассету и не используются в матчинге. Тут сделано, чтобы для нужных нам сервисов (содержащих заданную подстроку в URL) они должны сохраняться. Для остальных URL останется поведение по умолчанию. А bodyMask — это как раз пример того матчинга, о котором я ранее упоминал. У нас в контентный сервер уходили запросы с multipart POST. И из-за того, что разделители multipart генерировались где-то в недрах библиотеки, нам оказалось здесь проще сделать матчинг, а не добиться детерминированности. Тут банальная регулярка. Все, что попадает под эту регулярку выкусывается перед матчингом. Другими словами когда мы, например, сравниваем request body в кассете с request body, который прилетел в наш фальшивый клиент, мы сначала удалим из обоих все, что соответствует регулярке. Убрав этот случайно генерируемый кусок мы добиваемся того, что строчки одинаковые. Вуаля, библиотека считает, что это тот же самый request, хотя у него немного другой body. И отдает в вызываемый код соответствующий response из кассеты. Первый аргумент »/content/» значит, что э
