RBKmoney Payments под капотом — логика работы платежной платформы

Привет, Хабр! Продолжаю публикацию цикла про внутренности платежной платформы RBK.money, начатую в этом посте. Сегодня речь пойдет про логическую схему процессинга, конкретные микросервисы и их взаимосвязь друг с другом, как логически разделены сервисы, обрабатывающие каждый свой кусок бизнес-логики, почему ядро процессинга ничего не знает про номера ваших платежных карт и как внутри платформы бегают платежи. Также, чуть более подробно раскрою тему о том, как мы обеспечиваем высокую доступность и масштабирование для обработки высокой нагрузки.
Обзорная логическая схема и общие подходы
В общем случае схема основных элементов той части процессинга, что отвечает за платежи выглядит так.
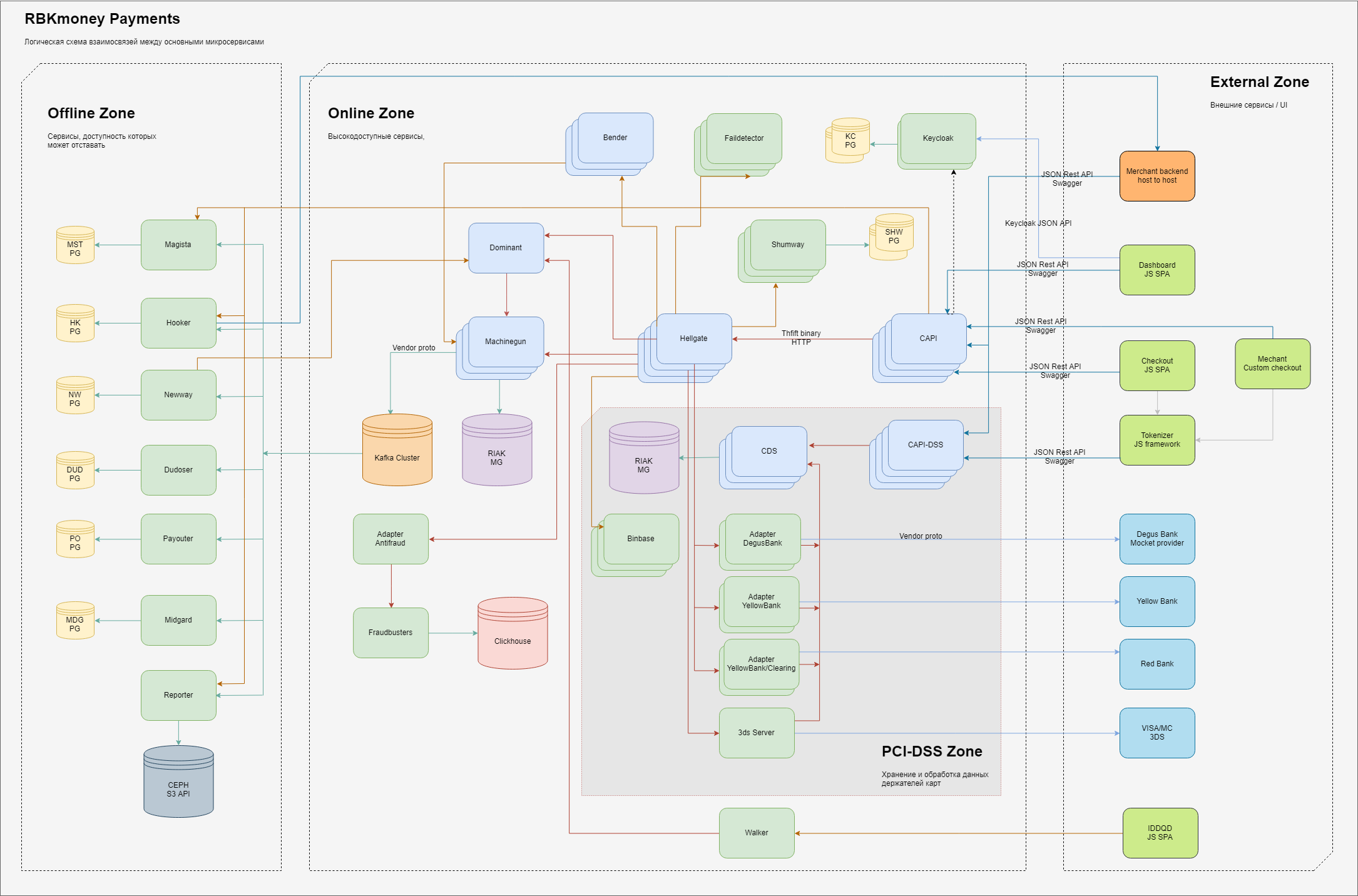
Логически внутри себя мы разделяем области ответственности на 3 домена:
- внешняя зона, сущности, которые находятся в интернете, такие как JS-приложения нашей платежной формы (это туда вы вводите свои карточные данные), бекенды наших клиентов-мерчантов, а также процессинговые шлюзы наших банков-партнеров и провайдеров других платежных методов;
- внутренняя высокодоступная зона, там живут микросервисы, которые обеспечивают работу непосредственно платежного шлюза и заведуют списанием денег, учетом их внутри нашей системы и прочими онлайн-сервисами, которые характеризуются требованием «должен быть доступен всегда, несмотря на любые отказы внутри наших ДЦ»;
- здесь отдельно выделяется зона сервисов, работающих непосредственно с полными данными держателей карт, эти сервисы имеют отдельные требования, выдвигаемые МПС и подлежащие обязательной сертификации в рамках стандартов PCI-DSS. Подробнее, почему именно такое разделение расскажем ниже;
- внутренняя зона, где выдвигаются меньшие требования к доступности предоставляемых сервисов либо времени их ответа, в классическом понимании — это бек-офис. Хотя, разумеется, здесь мы тоже стараемся обеспечить принцип «доступен всегда», просто тратим на это меньше усилий;
Внутри каждой из зон расположены микросервисы, выполняющие свои части обработки бизнес-логики. На вход они принимают RPC-вызовы, на выходе генерируют обработанные по заложенным алгоритмам данные, также оформленные в виде вызовов других микросервисов по цепочке.
Для обеспечения масштабируемости мы стараемся хранить состояния в как можно меньшем количестве мест. Stateless-сервисы на схеме не имеют связей с персистентными хранилищами, stateful, соответственно, подключены к ним. В целом используем несколько ограниченных сервисов для персистентного хранения состояний — для основной части процессинга это кластеры Riak KV, для сопутствующих сервисов — PostgreSQL, для асинхронной обработки очередей используем Кафку.
Для обеспечения высокой доступности сервисы разворачиваем в нескольких экземплярах, обычно от 3 до 5.
Stateless-сервисы масштабировать получается легко, просто поднимаем нужное нам количество экземпляров на разных виртуалках, они регистрируются в Consul-е, становятся доступны для резолвинга по консульному DNS и начинают получать вызовы от других сервисов, обрабатывая полученные данные и отправляя их дальше.
Stateful-сервисы, а точнее он у нас основной один и на схеме показан как Machinegun, реализуют высокодоступный интерфейс (распределенная архитектура основана на Erlang Distribution), а для обеспечения гарантий очередности и распределенной блокировки — синхронизацию через Consul KV. Это вкратце, подробное описание будет в отдельном посте.
Riak из коробки обеспечивает высокодоступное персистентное masterless-хранилище, мы его особо никак не готовим, конфиг практически дефолтный. При текущем профиле нагрузки нам хватает 5 нод в кластере, развернутых на отдельных хостах. Важное замечание — мы практически не используем индексы и большие выборки данных, работаем с конкретными ключами.
Там, где реализовать KV-схему слишком затратно, используем базы PostgeSQL с репликацией, либо вообще однонодовые решения, так как налить нужные события в случае отказа мы всегда можем из онлайновой части через Machinegun.
Цветовое разделение микросервисов на схеме указывает на языки, на которых они написаны — светло-зеленые — это Java-приложения, светло-синие — Erlang.
Все сервисы работают в Docker-контейнерах, которые являются артефактами сборки на CI и располагаются в локальном Docker Registry. Разворачивает сервисы на продакшене SaltStack, конфигурация которого находится в приватном Github-репозитории.
Разработчики самостоятельно делают запросы на изменение в этот репозиторий, где описывают требования к сервису — указывают нужную версию и параметры вроде размера выделяемой под контейнер памяти, передаваемый переменных окружения и прочего. Дальше, после ручного подтверждения запроса на изменение авторизованными сотрудниками (у нас это девопс, поддержка и информационная безопасность), CD автоматом раскатывает экземпляры контейнеров с новыми версиями на хосты продуктовой среды.
Также, каждый сервис пишет логи в понятном для Elasticsearch формате. Файлы логов подхватываются Filebeat-ом, который записывает их в кластер Elasticsearch. Таким образом, несмотря на то, что доступа на продуктовую среду у разработчиков нет, у них всегда есть возможность провести дебаг и посмотреть, что происходит с их сервисами.
Взаимодействие с внешним миром

Любое изменение состояния платформы у нас происходит исключительно через вызовы соответствующих методов публичных API. Мы не используем классических веб-приложений и генерацию контента на серверной стороне, фактически все, что вы видите в качестве UI — это вьюхи написанные на JS над нашими публичными API. В принципе, любое действие в платформе можно совершить цепочкой curl-вызовов из консоли, чем мы и пользуемся. В частности, для написания интеграционных тестов (они у нас написаны на JS в виде библиотеки), которые на CI при каждой сборке проверяют все публичные методы.
Также подобный подход решает все проблемы внешних интеграций с нашей платформой, позволяя получить единый протокол как для конечного пользователя в виде красивой формы ввода платежных данных, так и host-to-host для прямой интеграции со сторонними процессингами, использующими исключительно межсерверное взаимодействие.
Помимо полного покрытия интеграционными тестами, используем подходы staging update, в распределённой архитектуре это сделать довольно легко, например, выкатывая только по одному сервису из каждой группы за один проход с последующей паузой и анализом логов и графиков.
Это позволяет нам деплоиться практически круглосуточно, включая пятничные вечера, без особого страха выкатить что-то неработоспособное либо быстро откатиться, сделав простой revert коммита с изменением, пока никто не заметил.
Регистрация в платформе и публичные API

Перед любым вызовом публичного метода нам нужно авторизовать и аутентифицировать клиента. Для того, чтобы в платформе появился клиент, нужен сервис, который возьмет на себя все взаимодействие с конечным пользователем, предоставит интерфейсы регистрации, ввода и сброса паролей, контроля безопасности и прочей обвязки.
Здесь мы не стали изобретать велосипед, а просто интегрировали опенсорсное решение от Redhat — Keycloak. Перед началом любого взаимодействия с нами вам потребуется зарегистрироваться в платформе, что, собственно, через Keycloak и происходит.
После успешной аутентификации в сервисе клиент получает JWT. Его мы используем в дальнейшем для авторизации — на стороне Keycloak-а можно задать произвольные поля, описывающие роли, которые будут встроены в виде простой json-структуры в JWT и подписаны приватным ключом сервиса.
Одна из особенностей JWT состоит в том, что эта структура подписана приватным ключом сервера, соответственно для авторизации списка ролей и других ее объектов нам не нужно обращаться к сервису авторизации, процесс полностью развязан. Сервисы CAPI при запуске читают публичный ключ Keycloak и используют его для авторизации вызовов публичных методов API.
Как мы придумывали схему отзыва ключей — история отдельная и достойна своего собственного поста.
Итак, JWT у нас получен, мы можем использовать его для аутентификации. Здесь вступает в действие группа микросервисов Common API, на схеме указанных как CAPI и CAPI-DSS, реализующих следующие функции:
- авторизацию полученных сообщений. Каждый вызов публичного API предваряется HTTP-заголовком Authorizaion: Bearer {JWT}. Сервисы группы Common API используют его для проверки подписанных данных имеющимся публичным ключом сервиса авторизации;
- валидацию принятых данных. Поскольку схема описана в виде спецификации OpenAPI, также известной как Swagger, валидировать данные можно очень легко и с малой долей вероятности получить управляющие команды в потоке данных. Это положительным образом сказывается на безопасности сервиса в целом;
- трансляцию форматов данных из публичного REST JSON во внутренний бинарный Thrift;
- обрамление транспортной обвязки данными типа уникального trace_id и передачу события дальше вовнутрь платформы сервису, который управляет бизнес-логикой и знает, что такое, например, платеж.
Таких сервисов у нас много, они достаточно простые и дубовые, не хранят никаких состояний, соответственно для линейного масштабирования производительности мы их просто разворачиваем на свободных мощностях в нужных нам количествах.
PCI-DSS и открытые карточные данные

Как видно на схеме, таких групп сервисов у нас две — основная, Common API, отвечает за обработку всех потоков данных, не имеющих в себе открытых данных держателей карт, и вторая, Common API PCI-DSS, которая непосредственно с этими картами работает. Внутри они абсолютно одинаковы, однако мы их физически разделили и расположили на разных железках.
Это сделано для того, чтобы минимизировать количество мест хранения и обработки карточных данных, уменьшить риски утечки этих данных и область сертификации PCI-DSS. А это, поверьте, достаточно трудоемкий и затратный процесс — как платежная компания, мы обязаны каждый год проходить платную сертификацию на соответствие стандартам МПС, и чем меньше серверов и сервисов в ней участвует, тем быстрее и легче проходить этот процесс. Ну и на безопасности это отражается самым позитивным образом.
Обработка платежных данных и токенизация
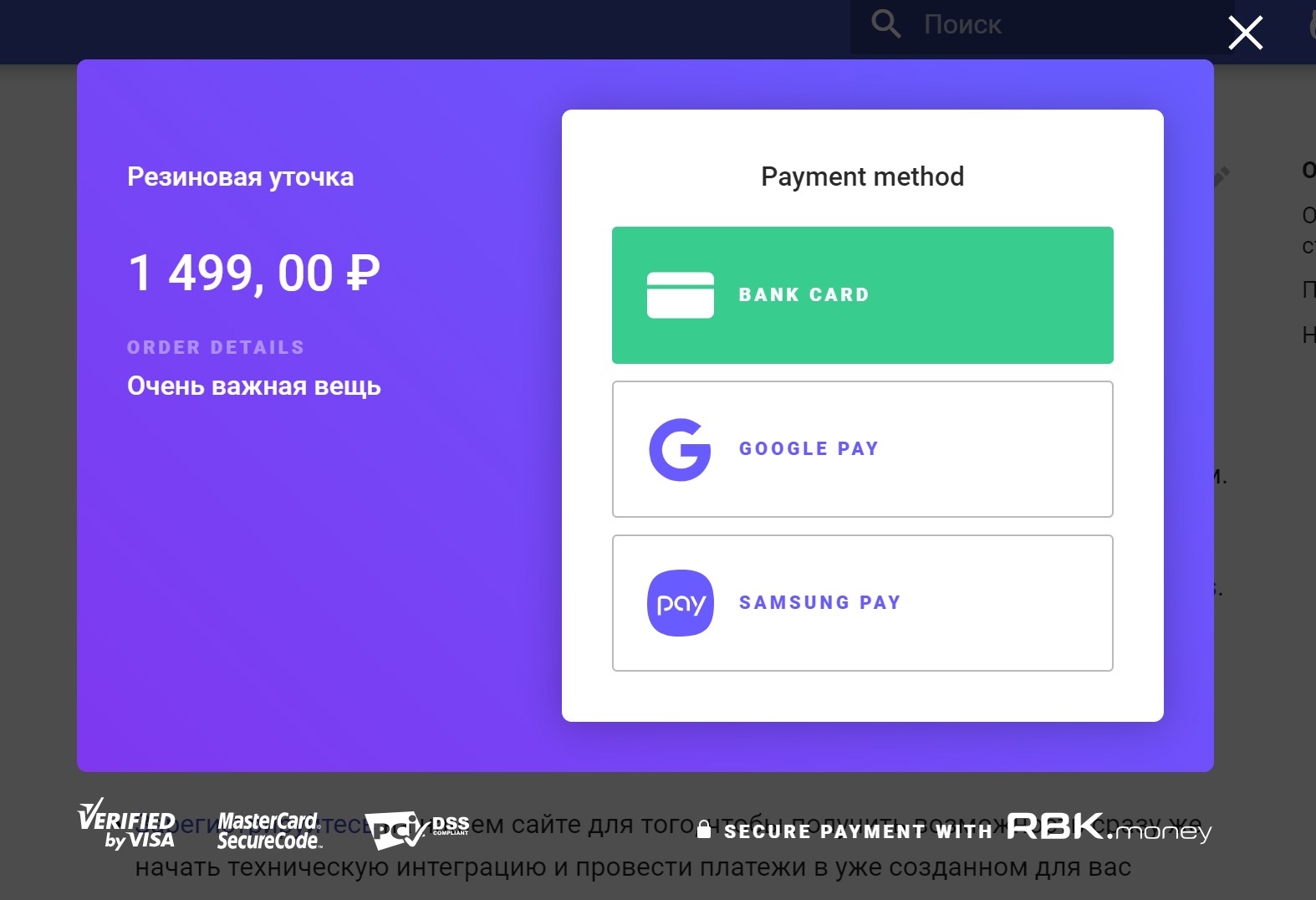
Итак, мы хотим запустить платеж и списать деньги с карты плательщика.
Представим, что запрос на это пришел в виде цепочки вызовов методов нашего публичного API, который был инициирован вами, как плательщиком после того, как вы зашли в интернет-магазин, собрали корзину товаров, нажали «Купить», ввели свои карточные данные в нашу платежную форму и нажали кнопку «Оплатить».
Мы предоставляем разные бизнес-процессы списания денег, но наиболее интересным мне кажется процесс с использованием счетов к оплате. У нас в платформе можно создать счет к оплате, или инвойс, который будет являться контейнером для платежей.
Внутри одного инвойса можно поочередно делать попытки его оплаты, т. е. создавать платежи до того момента, пока очередной платеж не окажется успешным. Например, можно пробовать оплатить инвойс с разных карт, кошельков и любых других платежных методов. Если на одной из карт не будет денег, можно попробовать другую и так далее.
Это положительно сказывается на конверсии и пользовательском опыте.
Конечный автомат инвойса

Внутри платформы эта цепочка превращается во взаимодействия по следующему маршруту:
- перед выдачей контента в ваш браузер наш клиент-мерчант интегрировался с нашей платформой, зарегистрировался у нас и получил JWT для авторизации;
- со своего бекенда мерчант вызвал метод createInvoice (), то есть создал счет к оплате в нашей платформе. Фактически, бекенд мерчанта отправил HTTP POST-запрос следующего содержания на наш эндпоинт:
curl -X POST \
https://api.rbk.money/v2/processing/invoices \
-H 'Authorization: Bearer {JWT}' \
-H 'Content-Type: application/json; charset=utf-8' \
-H 'X-Request-ID: 1554417367' \
-H 'cache-control: no-cache' \
-d '{
"shopID": "TEST",
"dueDate": "2019-03-28T17:41:32.569Z",
"amount": 6000,
"currency": "RUB",
"product": "Order num 12345",
"description": "Delicious meals",
"cart": [
{
"price": 5000,
"product": "Sandwich",
"quantity": 1,
"taxMode": {
"rate": "10%",
"type": "InvoiceLineTaxVAT"
}
},
{
"price": 1000,
"product": "Cola",
"quantity": 1,
"taxMode": {
"rate": "18%",
"type": "InvoiceLineTaxVAT"
}
}
],
"metadata":
{
"order_id": "Internal order num 13123298761"
}
}'
Запрос отбалансировался на одно из эрланговых приложений группы Common API, которое проверило его валидность, сходило в сервис Bender, где получило ключ идемпотентности, перевело в трифт и отправило запрос на группу сервисов Hellgate. Экземпляр Hellgate выполнил бизнес-проверки, например убедился, что владелец данного JWT в принципе не заблокирован, может создавать инвойсы и вообще взаимодействовать с платформой и начал создание инвойса.
Можно сказать, что Hellgate является ядром нашего процессинга, так как именно он оперирует бизнес-сущностями, знает, как запустить платеж, кого нужно пнуть, чтобы этот платеж превратился в реальное списание денег, как вычислить маршрут этого платежа, кому сказать, чтобы это списание отразилось на балансах, вычислить комиссии и прочую обвязку.
Что характерно, также не хранит никаких состояний и также легко масштабируется. Но нам не хотелось бы потерять инвойс, или получить двойное списание денег с карты в случае network split-а или отказа Hellgate-а по любой причине. Нужно эти данные персистентно сохранить.
Здесь в действие вступает третий микросервис, а именно Machinegun. Hellgate отправляет в Machinegun вызов «создать автомат» с полезной нагрузкой в виде параметров запроса. Machinegun упорядочивает параллельные запросы и с помощью Hellgate из параметров создает первое событие — InvoiceCreated. Которое потом сам и записывает в Riak и очереди. После этого, на изначальный запрос по цепочке в обратном порядке возвращается успешный ответ.
Вкратце Machinegun — это такая СУБД с таймерами над любой другой СУБД, в текущей версии платформы — над Riak-ом. Она предоставляет интерфейс, позволяющий управлять независимыми автоматами, и предоставляет гарантии идемпотентности и очередности записи. Именно MG не даст записать событие в автомат вне очереди, если к нему вдруг придут с таким запросом несколько HG.
Автомат — уникальная в рамках платформы сущность, состоящая из идентификатора, набора данных в виде списка событий и таймера. Конечное состояние автомата рассчитывается из обработки всех его событий, которые инициируют его переход в соответствующее состояние. Мы используем этот подход для работы с бизнес-сущностями, описывая их, как конечные автоматы. Фактически, все созданные нашими мерчантами инвойсы, как и платежи в них — это конечные автоматы со своей логикой перехода между состояниями.
Интерфейс работы с таймерами в Machinegun позволяет от другого сервиса вместе с событиями для записи получить просьбу вида «я хочу продолжить обработку этого автомата через 15 лет». Такие отложенных задачи реализуются на встроенных таймерах. На практике они используются очень часто — периодические обращения в банк, автоматические действия с платежами из-за долгой неактивности и т. д.
Кстати, исходные коды Machinegun открыты под лицензией Apache 2.0 в нашем публичном репозитории. Мы надеемся, что этот сервис может быть полезен сообществу.
Подробное описание работы Machinegun-а и вообще того, как мы готовим распределенку, тянет на отдельный большой пост, поэтому более подробно здесь останавливаться не буду.
Нюансы авторизации внешних клиентов

После успешного сохранения Hellgate возвращает данные в CAPI, тот преобразовывает бинарную трифтовую структуру в красиво оформленный JSON, готовый к отправке в бекенд мерчанта:
{
"invoice": {
"amount": 6000,
"cart": [
{
"cost": 5000,
"price": 5000,
"product": "Sandwich",
"quantity": 1,
"taxMode": {
"rate": "10%",
"type": "InvoiceLineTaxVAT"
}
},
{
"cost": 1000,
"price": 1000,
"product": "Cola",
"quantity": 1,
"taxMode": {
"rate": "18%",
"type": "InvoiceLineTaxVAT"
}
}
],
"createdAt": "2019-04-04T23:00:31.565518Z",
"currency": "RUB",
"description": "Delicious meals",
"dueDate": "2019-04-05T00:00:30.889000Z",
"id": "18xtygvzFaa",
"metadata": {
"order_id": "Internal order num 13123298761"
},
"product": "Order num 12345",
"shopID": "TEST",
"status": "unpaid"
},
"invoiceAccessToken": {
"payload": "{JWT}"
}
}
Казалось бы, можно отдавать контент в браузер плательщику и начинать процесс оплаты, но тут мы подумали, что не все мерчанты будут готовы самостоятельно реализовывать авторизацию на клиентской стороне, поэтому ее реализовали сами. Подход заключается в том, CAPI генерирует еще один JWT, позволяющий запускать процессы токенизации карт и управлять конкретным инвойсом и добавляет его в возвращаемую структуру инвойса.
Пример ролей, описанных внутри подобного JWT:
"resource_access": {
"common-api": {
"roles": [
"invoices.18xtygvzFaa.payments:read",
"invoices.18xtygvzFaa.payments:write",
"invoices.18xtygvzFaa:read",
"payment_resources:write"
]
}
}
Данный JWT имеет ограниченное количество попыток использования и настраиваемый нами срок жизни, что позволяет публиковать его в браузере плательщика. Даже если он будет перехвачен, максимум что сможет сделать злоумышленник — это заплатить за чужой инвойс или прочитать его данные. Причем, поскольку платежный автомат не оперирует открытыми карточными данными, максимум, что злоумышленник сможет увидеть — это маскированный номер карты вида 4242 42** **** 4242, сумму платежа и, опционально, корзину товаров.
Созданный инвойс и ключ доступа к нему позволяют начинать платежный бизнес-процесс. Отдаем идентификатор инвойса и его JWT в браузер плательщику и передаем управление нашим JS-приложениям.
Наше JS-приложение Checkout реализовывает интерфейс взаимодействия с вами, как плательщиком — рисует форму ввода платежных данных, запускает платеж, получает его финальный статус, показывает веселую или грустную Точку.
Токенизация и карточные данные

Но Checkout не работает с карточными данными. Как было указано выше, нам хочется хранить чувствительные данные в виде данных держателей карт в как можно меньшем количестве мест. Для этого мы реализовываем токенизацию.
Здесь вступает в действие JS-библиотека Tokenizer. Когда вы вводите свою карту в поля ввода и нажимаете «Оплатить», она перехватывает эти данные и асинхронно отправляет их к нам в процессинг, вызывая метод createPaymentResource ().
Этот запрос балансируется на отдельные приложения CAPI-DSS, которые также авторизуют запрос, только уже проверяя инвойсовый JWT, валидируют данные и отправляют трифтом в сервис хранения карточных данных. На схеме он указан как CDS — Card Data Storage.
Основные задачи этого сервиса:
- получить на вход чувствительные данные, в нашем случае — данные вашей карты;
- зашифровать эти данные ключом шифрования данных;
- сгенерировать некое случайное значение, используемое в виде ключа;
- сохранить по этому ключу зашифрованные данные в своем кластере Riak;
- вернуть ключ в виде токена платежных данных сервису CAPI-DSS.
Попутно сервис решает еще кучу важных задач, таких как генерация ключей для шифровки ключей, безопасный ввод этих ключей, перешифровка данных, контроль затирания CVV после проведения платежа и прочее, но это выходит за рамки данного поста.
Здесь не обошлось без защиты от возможности выстрелить себе в ногу. Существует ненулевая вероятность того, что приватный JWT, призванный авторизовывать запросы с бекенда, будет опубликован в вебе в браузер клиента. Для того, чтобы этого не случилось, мы встроили защиту — вызвать метод createPaymentResource () можно только с ключом авторизации инвойса. При попытке использовать приватный JWT платформа вернет ошибку HTTP/401.
После выполнения запроса токенизации Tokenizer возвращает полученный токен в Checkout и на этом свою работу заканчивает.
Бизнес-процесс платежного автомата

Checkout запускает процесс платежа, а именно — вызывает метод createPayment (), передав в качестве аргумента полученный раньше токен карточных данных и запускает процесс поллинга событий, фактически, раз в секунду вызывая метод API getInvoiceEvents ().
Эти запросы через CAPI попадают в Hellgate, который начинает реализовывать платежный бизнес-процесс, при этом не оперируя карточными данными:
- в первую очередь Hellgate идет в сервис управления конфигурациями — Dominant и получает текущую ревизию конфигурации домена. В ней записаны все правила, по которым будет выполняться данный платеж, то, в какой банк он попадет на авторизацию, какие проводки комиссий будут записаны и прочее;
- у сервиса управления участниками, сейчас это часть HG, узнает данные о внутренних номерах счетов мерчанта в пользу которого осуществляется платеж, применяет суммы комиссий, готовит план проводок и запихивает его в сервис Shumway. Этот сервис отвечает за управление информацией о движении денег по счетам участников сделки при проведении платежа. В плане проводок находится инструкция «заморозить возможное движение средств по указанным в плане счетам участников сделки»;
- обогащает данные платежа, обращаясь к дополнительным сервисам, например в Binbase для того, чтобы узнать страну банка-эмитента, выпустившего карту и ее тип, например «золотая, кредитная»;
- обращается в сервис инспектора, как правило — это Аntifraud для того, чтобы получить скоринг платежа и принять решение о выборе терминала, покрывающего выданный скорингом уровень риска. Например, для низкорисковых платежей может использоваться терминал без 3D-Secure, а платеж, получивший фатальный уровень риска на этом свою жизнь и закончит;
- обращается в сервис определения ошибок, Faultdetector и на основе полученных от него данных выбирает маршрут проведения платежа — адаптер банковского протокола, имеющий в текущий момент наименьшее количество ошибок и наиболее высокую вероятность успешного проведения платежа;
- отправляет запрос в выбранный адаптер банковского протокола, пусть в данном случае это будет YellowBank Adapter, «авторизовать указанную сумму с этого токена».
Адаптер протокола по полученному токену обращается в CDS, получает расшифрованные карточные данные, переводит их в специфичный для банка протокол, и в общем случае, получает авторизацию — подтверждение от банка-эквайера о том, что указанная сумма заморожена на счете плательщика.
Именно в этот момент вы получаете СМС с сообщением о списании денежных средств с вашей карты от вашего банка, хотя на самом деле средства по факту пока только заморожены на вашем счете.
Адаптер уведомляет HG об успешной авторизации, из сервиса CDS удаляется ваш CVV-код и на этом этап взаимодействия заканчивается. Управление возвращается в HG.

В зависимости от указанного при вызове createPayment () мерчантом бизнес-процесса платежа HG ожидает со внешнего API вызовы метода захвата авторизации, т. е. подтверждения списания денег с вашей карты, либо делает это сразу же самостоятельно, в том случае, если мерчант выбрал схему одностадийного платежа.
Как правило, большинство мерчантов использует одностадийный платеж, однако есть категории бизнеса, которые в момент получения авторизации еще не знают итоговой суммы списания. Такое часто случается в туристической индустрии, когда вы бронируете тур на одну сумму, а уже после подтверждения брони, сумма уточняется и может отличаться от той, что была авторизована вначале.
Несмотря на то, что сумма подтверждения может быть исключительно равной или меньшей суммы авторизации, здесь есть подводные камни. Представьте, что вы оплачиваете с карты товар или услугу в валюте, отличной от валюты вашего банковского счета, к которому привязана карта.
На момент авторизации на вашем счете блокируется сумма исходя из курса обмена валют на день авторизации. Поскольку платеж может находиться в статусе «авторизован» (несмотря на то, что у МПС есть рекомендации по максимальному сроку и сейчас составляет 3 суток) несколько дней, захват авторизации будет проводиться по курсу того дня, в который она была произведена.
Таким образом, вы несете валютные риски, которые могут быть как в вашу пользу, так и против вас, особенно в ситуации высокой волатильности на рынке валют.
Для захвата авторизации происходит тот же процесс общения с адаптером протокола, что и для ее получения, и в случае успеха, HG применяет план проводок по счетам внутри Shumway, и переводит платеж в статус «Оплачен». Именно в этот момент у нас, как у платежной системы возникают финансовые обязательства перед участниками сделки.
Стоит также заметить, что любые изменения состояния автомата инвойса, к которым относится процесс платежа, записываются Hellgate-ом в Machinegun, обеспечивая персистентность данных и обогащая инвойс новыми событиями.
Синхронизация состояний автомата платежа и UI
В то время, пока внутри платформы происходит фоновый процесс проведения платежа, Checkout поллит процессинг, запрашивая события. При получении определенных событий он отрисовывает текущее состояние платежа в виде, понятном человеку — рисует прелоадер, показывает экран «Ваш платеж успешно обработан» или «Платеж провести не удалось» либо переадресовывает браузер на страницу вашего банка-эмитента для ввода пароля 3D-Secure;
В случае неуспеха Checkout предложит выбрать другой метод оплаты либо попробовать еще раз, таким образом запустив новый платеж в рамках инвойса.
Такая схема с поллингом событий позволяет обеспечить восстановление состояния даже после закрытия вкладки браузера — в случае повторного запуска Checkout получит текущий список событий и отрисует актуальный сценарий взаимодействия с пользователем, например предложит ввести код 3D-Secure или покажет, что платеж уже был успешно проведен.
Репликация событий в Offline Zone
Одновременно с интерфейсами управления автоматами Machinegun реализует сервис, отвечающий за переливку потока событий к сервисам, отвечающим за другие, менее онлайновые задачи платформы.
В качестве брокера очередей в финале мы остановились на Kafka, хотя ранее реализовывали эту функциональность силами самого Machinegun. В общем случае этот сервис представляет собой сохранение гарантированно упорядоченного потока событий, либо выдачу определенного списка событий по запросу другим потребителям.
Также изначально мы реализовывали схему дедупликации событий, предоставляя гарантии того, что одно и то же событие не будет реплицировано дважды, однако нагрузка на Riak, которую генерировал подобных подход заставила от нее отказаться — все-таки поиск по индексам — это не лучшее, что умеет KV-хранилище. Теперь за дедупликацию событий отвечает каждый сервис-потребитель самостоятельно.
В общем случае репликация событий со стороны Machinegun заканчивается на подтверждении сохранения данных в Kafka, а потребители уже подключаются к топикам Kafka и выкачивают те списки событий, которые им интересны.
Шаблон типичного приложения Offline-зоны
Например, сервис Dudoser отвечает за то, чтобы отправить вам на электронную почту уведомление об успешно проведенном платеже. Он при запуске выкачивает список событий успешно проведенных платежей, берет оттуда информацию об адресе и сумме, сохраняет в локальный экземпляр PostgreSQL и использует его для дальнейшей обработки бизнес-логики.
Все остальные подобные сервисы работают по такой же логике, как например сервис Magista, отвечающий за поиск инвойсов и платежей в личном кабинете мерчанта или сервис Hooker, который отправляет асинхронные коллбеки на бекенд мерчантам, которые по той или иной причине не могут организовать поллинг событий, обращаясь напрямую к API процессинга.
Такой подход позволяет нам развязать нагрузку на процессинг, выделяя максимальные ресурсы и обеспечивая высокую скорость и доступность обработки платежей, предоставляя высокую конверсию. Тяжелые запросы вроде «бизнес-заказчики хотят смотреть статистику по платежам за последний год» обрабатываются сервисами, никак не влияющими на текущую нагрузку онлайн-части процессинга, и соответственно, не затрагивают вас, как плательщиков и мерчантов, как наших клиентов.
Пожалуй, на этом остановимся, чтобы не превращать пост в уж слишком большой лонгрид. В будущих статьях обязательно расскажу про нюансы обеспечения атомарности изменений, гарантий и очередности в нагруженной распределенной системе на примере Machinegun, Bender, CAPI и Hellgate.
Ну, а про Salt Stack уже в следующий раз ¯\_(ツ)_/¯
