RBKmoney Payments под капотом — инфраструктура платежной платформы

Привет, Хабр! Описание работы внутренностей большой платежной платформы логично будет продолжить описанием того, как именно все эти компоненты работают в реальном мире на физическом железе. В этом посте рассказываю о том, как и где размещены приложения платформы, каким образом до них доходит трафик из внешнего мира, а также опишу схему стандартной для нас стойки с оборудованием, размещенной в любом из наших дата-центров.
Подходы и ограничения

Одно из первых требований, которые мы сформулировали перед разработкой платформы звучит как «возможность близкого к линейному масштабирования вычислительных ресурсов для обеспечения обработки любого количества транзакций».
Классические подходы платженых систем, используемые участниками рынка, подразумевают под собой наличие потолка, хоть и довольно высокого по заявлениям. Обычно это звучит так: «наш процессинг может принимать 1000 транзакций в секунду».
В наши бизнес-задачи и архитектуру такой подход не вписывается. Мы не хотим иметь какой-то предел. В самом деле, было бы странно услышать от Яндекса или Гугла заявление «мы можем обработать 1 миллион поисковых запросов в секунду». Платформа должна обработать столько запросов, сколько нужно в текущий момент бизнесу за счет архитектуры, которая позволяет, упрощенно говоря, отправить в ДЦ ИТшника с тележкой серверов, которые он установит в стойки, подключит к коммутатору и уедет. А оркестратор платформы раскатит на новые мощности копии экземпляров бизнес-приложений, в результате чего мы получим нужное нам увеличение RPS.
Второе важное требование заключается в обеспечении высокой доступности предоставляемых сервисов. Было бы забавно, но не слишком полезно, создать платежную платформу, которая может принимать бесконечное количество платежей в /dev/null.
Пожалуй, самый эффективный способ достичь высокой доступности — это многократно дублировать сущности, которые обслуживают сервис, с тем чтобы отказ любого разумного количества приложений, оборудования или дата-центров не повлиял на общую доступность платформы.
Многократное дублирование приложений требует большого количества физических серверов и сопутствующего сетевого оборудования. Это железо стоит денег, количество которых у нас конечно, мы не можем позволить себе покупать много дорогого железа. Так что платформа спроектирована таким образом, чтобы легко размещаться и чувствовать себя хорошо на большом количестве недорогого и не слишком мощного железа, либо вообще в публичном облаке.
Использование не самых сильных в плане вычислительной мощности серверов имеет свои преимущества — их отказ не оказывает критичного влияния на общее состояние системы в целом. Представьте, что лучше — если сгорит дорогой, большой и супернадежный брендовый сервер, на котором работает СУБД по схеме master-slave (а по закону Мерфи он обязательно сгорит, причем вечером 31 декабря) или парочка серверов в кластере из 30 нод, работающем по masterless-схеме?
Исходя из этой логики, мы решили не создавать себе еще одну массивную точку отказа в виде централизованного дискового массива. Общие блочные устройства нам обеспечивает кластер Ceph, развернутый гиперконвергентно на тех же серверах, но с отдельной сетевой инфраструктурой.
Таким образом, мы логически пришли к общей схеме универсальной стойки с вычислительными ресурсами в виде недорогих и не особо мощных серверов в дата-центре. Если нам нужно еще ресурсов, мы или добиваем любую свободную стойку серверами, либо ставим еще одну, желательно поближе.

Ну и, в конце концов, это просто красиво. Когда в стойки устанавливается понятное количество одинакового железа, это позволяет решить проблемы с качественной укладкой проводного хозяйства, позволяет избавиться от ласточкиных гнезд и опасности запутаться в проводах, уронив процессинг. А хорошая с инженерной точки зрения система должна быть красивой везде — и изнутри в виде кода, и снаружи в виде серверов и сетевого железа. Красивая система работает лучше и надежнее, у меня хватало предостаточно примеров убедиться в этом на личном опыте.
Пожалуйста, не подумайте, что мы крохоборы или бизнес нам зажимает финансирование. Разработка и поддержка распределенной платформы на самом деле очень дорогое удовольствие. По факту это выходит даже дороже, чем владение классической системой, построенной, условно, на мощном брендовом железе с Oracle/MSSQL, серверами приложений и прочей обвязкой.
Окупается наш подход высокой надежностью, очень гибкими возможностями горизонтального масштабирования, отсутствием потолка по количеству платежей в секунду, и как бы странно это не звучало — большим количеством фана для ИТ-команды. Для меня уровень удовольствия разработчиков и девопсов от системы, которую они создают, не менее важен, чем предсказуемые сроки разработки, количество и качество выкатываемых фич.
Серверная инфраструктура

Логически, наши серверные мощности можно разделить на два основных класса: сервера для гипервизоров, для которых важна плотность ядер CPU и RAM на юнит, и сервера хранения данных, где основной акцент сделан на объем дискового пространства на юнит, а CPU и RAM уже подбираются под число дисков.
В текущий момент наш классический сервер для вычислительных мощностей выглядит так:
- 2xXeon E5–2630 CPU;
- 128G RAM;
- 3xSATA SSD (Ceph SSD pool);
- 1xNVMe SSD (dm-cache).
Сервер для хранения состояний:
- 1xXeon E5–2630 CPU;
- 12–16 HDD;
- 2 SSD для block.db;
- 32G RAM.
Сетевая инфраструктура
В выборе сетевого железа наш подход несколько отличается. Для коммутации и маршрутизации между vlan-ами мы-таки используем брендовые коммутаторы, сейчас это Cisco SG500X-48 и Cisco Nexus C5020 в SAN.
Физически каждый сервер включается в сеть 4 физическими портами:
- 2×1GbE — сеть управления и RPC между приложениями;
- 2×10GbE — сеть для СХД.
Интерфейсы внутри машин объединяются bonding-ом, дальше тегированный трафик расходится по нужным vlan-ам.
Пожалуй, это единственное место в нашей инфраструктуре, где можно заметить лейбл известного вендора. Потому что для маршрутизации, сетевой фильтрации и инспекции трафика мы используем линуксовые хосты. Специализированных маршрутизаторов не покупаем. Все, что нам нужно мы настраиваем на серверах под управлением Gentoo (iptables для фильтрации, BIRD для динамической маршрутизации, Suricata в качестве IDS/IPS, Wallarm в качестве WAF).
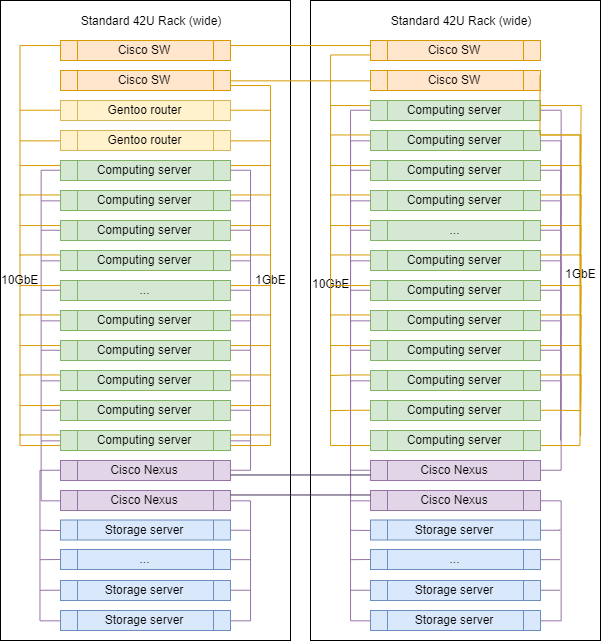
Типичная стойка в ДЦ
Схематически при масштабировании стойки в ДЦ и практически не отличаются друг от друга за исключением маршрутизаторов к аплинкам, которые устанавливаются в одной из них.
Точные пропорции серверов разных классов могут варьироваться, но в целом логика сохраняется — серверов для вычислений больше, чем серверов для хранения данных.
Блочные устройства и разделение ресурсов
Попробуем собрать все вместе. Представим, что нам нужно разместить несколько наших микросервисов в инфраструктуре, для большей наглядности это будут микросервисы, которым надо между собой общаться по RPC и один из них — Machinegun, который хранит состояние в кластере Riak-а, а также немного вспомогательных сервисов, таких, как ноды ES и Consul.
Типичная схема размещения будет выглядеть так:
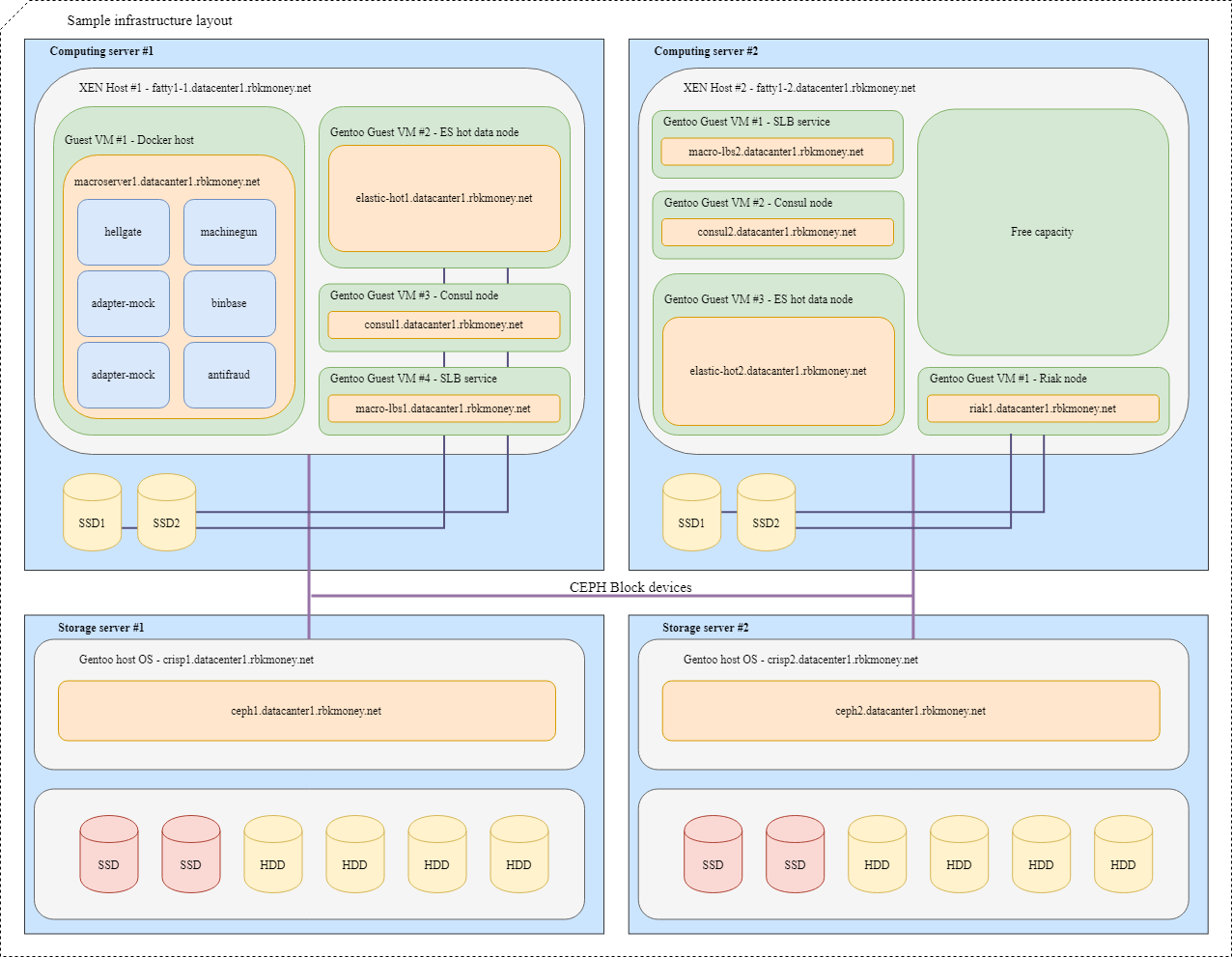
Для VM с приложениями, которым требуется максимальная скорость блочного устройства, вроде Riak и горячих нод Elasticsearch, используются разделы на локальных NVMe дисках. Такие VM жестко привязаны к своему гипервизору, и приложения сами отвечают за доступность и целостность своих данных.
Для общих блочных устройств мы используем Ceph RBD, обычно с write-through dm-cache на локальном NVMe диске. OSD для устройства могут быть как full-flash, так и HDD c SSD журналом, в зависимости от желаемого времени отклика.
Доставка трафика до приложений
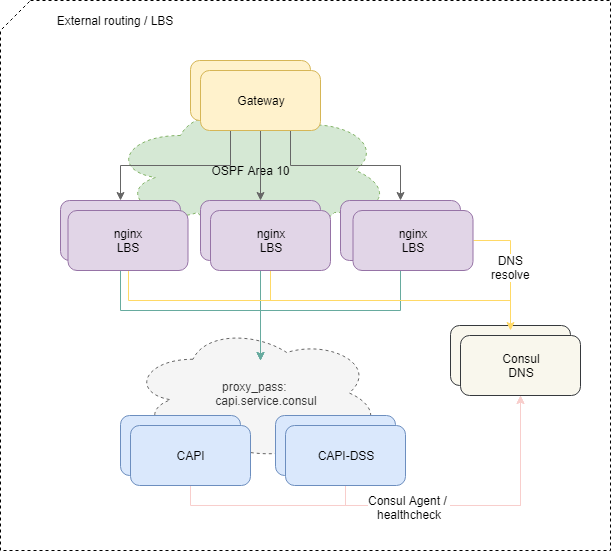
Для балансировки запросов, приходящих снаружи, мы используем стандартную схему OSPFv3 ECMP. Небольшие виртуальные машины с nginx, bird, consul анонсируют в OSPF облако общие anycast адреса с интерфейса lo. На маршрутизаторах для этих адресов bird создает multi-hop routes, обеспечивающие per-flow балансировку, где flow это «src-ip src-port dst-ip dst-port». Для быстрого отключения пропавшего балансера используется протокол BFD.
При добавлении или выходе из строя любого из балансировщиков у верхнестоящих маршрутизаторов появляется или удаляется соответствующий маршрут, а сетевой трафик до них доставляется согласно подходов Equal-cost multi-path. И если мы специально не вмешиваемся, то весь сетевой трафик равномерно распределяется на все доступные балансировщики по IP-потоку каждому.
Кстати, у подхода с ECMP-балансировкой есть неочевидные подводные камни, которые могут привести к совершенно неочевидным потерям части трафика, особенно если на маршруте между системами находятся другие маршрутизаторы или странным образом сконфигурированные фаерволы.
Для решения проблемы мы используем демона PMTUD в этой части инфраструктуры.
Дальше трафик идет вовнутрь платформы к конкретным микросервисам согласно конфигурации nginx-ов на балансировщиках.
И если балансировкой наружного трафика все более-менее просто и понятно, то распространить подобную схему дальше вовнутрь было бы затруднительно — нам нужно нечто большее, чем просто проверка доступности контейнера с микросервисом на сетевом уровне.
Для того чтобы микросервис начал получать и обрабатывать запросы, он должен зарегистрироваться в Service Discovery (мы используем Consul), проходить ежесекундные health check-и и иметь разумный RTT.
Если микросервис чувствует и ведет себя хорошо, Consul начинает резолвить адрес его контейнера при обращении к своему DNS по имени сервиса. Мы используем внутреннюю зону service.consul, и, например, микросервис Common API 2 версии будет иметь имя capi-v2.service.consul.
Конфиг nginx-а касательно балансировки в итоге у нас выглядит так:
location = /v2/ {
set $service_hostname "${staging_pass}capi-v2.service.consul";
proxy_pass http://$service_hostname:8022;
}Таким образом, если мы опять же не вмешиваемся специально, трафик с балансировщиков равномерно распределяется между всеми зарегистрированными в Service Discovery микросервисами, добавление или удаление новых экземпляров нужных микросервисов полностью автоматизировано.
Если запрос от балансировщика ушел в апстрим, а тот по дороге умер, мы возвращаем наружу 502 — балансировщик на своем уровне не может определить идемпотентный ли был запрос или нет, поэтому обработку таких ошибок мы отдаем на более высокий уровень логики.
Идемпотентность и дедлайны
Вообще, мы не боимся и не стесняемся отдавать с API ошибки 5хх, это нормальная часть работы системы, если сделать правильную обработку таких ошибок на уровне бизнес-логики RPC. Принципы этой обработки у нас описаны в виде небольшого мануала под названием Errors Retry Policy, мы его раздаем нашим клиентам-мерчантам и реализовываем внутри наших сервисов.
Для упрощения этой обработки мы реализовали несколько подходов.
Во-первых, для любых изменяющих состояние запросов к нашему API можно указать уникальный в рамках учетной записи ключ идемпотентности, который живет вечно и позволяет быть уверенным в том, что повторный вызов с одинаковым набором данных вернет одинаковый ответ.
Во-вторых, мы реализовали дополнительный механизм в виде уникального идентификатора платежной сессии, который гарантирует идемпотентность запросов на списание средств, обеспечивая защиту от ошибочных повторных списаний, даже если не генерировать и не передавать отдельный ключ идемпотентности.
В-третьих, мы решили дать возможность предсказуемого и контролируемого снаружи времени ответа на любой внешний вызов нашего API в виде параметра отсечки по времени, определяющего максимальное время ожидания завершения операции по запросу. Достаточно передать, к примеру, HTTP-заголовок X-Request-Deadline: 10s, чтобы быть уверенным в том, что ваш запрос выполнится течение 10 секунд или будет убит платформой где-то внутри, после чего к нам можно будет обратиться снова, руководствуясь политикой переотправки запросов.
Управление и владение платформой
Мы используем SaltStack как в качестве инструмента управления как конфигурациями, так и инфраструктурой в целом. Отдельные инструменты для автоматизированного управления вычислительной мощностью платформы пока что не взлетели, хотя уже сейчас понимаем, что будем идти в эту сторону. При нашей любви к продуктам Hashicorp это скорее всего будет Nomad.
Основные инструменты мониторинга инфраструктуры — это проверки в Nagios, а вот для бизнес-сущностей в основном настраиваем алерты в Grafana. В ней очень удобный инструмент задания условий, а event-based модель платформы позволяет все записать в Elasticsearch и настроить условия выборки.
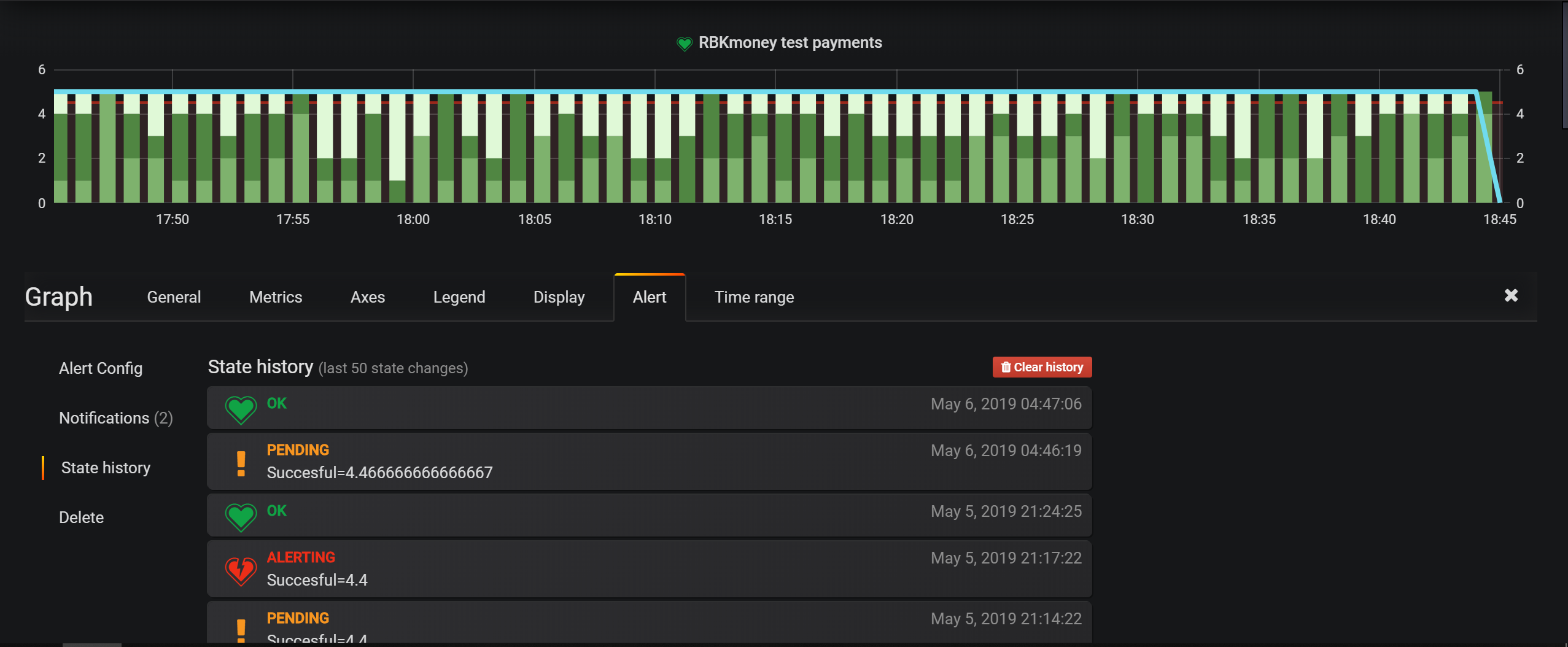
Дата-центры находятся в Москве, в них мы арендуем стойко-места, самостоятельно устанавливаем и управляем всем оборудованием. Темную оптику нигде не используем, наружу у нас только интернет от местных провайдеров.
В остальном же наши подходы к мониторингу, управлению и сопутствующим сервисам скорее стандартны для отрасли, не уверен, что очередное описание интеграции этих сервисов стоит упоминания в посте.
На этой статье я, пожалуй, закончу цикл обзорных постов про то, как устроена наша платежная платформа.
Считаю, что цикл получился достаточно откровенным, я встречал мало статей, которые настолько подробно раскрывали бы внутреннюю кухню крупных платежных систем.
Вообще, по моему мнению, высокий уровень открытости и откровенности — очень важная вещь для платежной системы. Такой подход не только повышает уровень доверия партнеров и плательщиков, но и дисциплинирует команду, создателей и операторов сервиса.
Так, руководствуясь этим принципом, мы недавно сделали общедоступным статус платформы и историю аптайма наших сервисов. Вся последующая история нашего аптайма, обновлений и падений отныне публична и доступна по адресу https://status.rbk.money/.
Надеюсь, вам было интересно, а возможно, кому-то наши подходы и описанные ошибки окажутся полезными. Если вас заинтересовали какие-либо направления, описанные в постах, и вы хотели бы, чтобы я раскрыл их более подробно, пожалуйста, не стесняйтесь писать в комментариях или в личку.
Спасибо, что вы с нами!

P.S. Для вашего удобства указатель по предыдущим статьям цикла:
