Развитие баз данных
Данная статься захватывает ключевые моменты (по-моему мнению) в развитии систем управления базами данных, от первых иерархических моделей до современных реляционных, NoSQL и NewSQL систем.
Содержание:
Эволюция СУБД: от иерархических к реляционным
Иерархическая модель данных
Сетевая модель данных
Появление реляционных баз данных
Появление Not Only SQL систем
Четыре типа NoSQL
Ключ-значение
Документ-ориентированное хранилище
Колоночное хранилище
Графовое хранилище
Появление NewSQL систем
Последствия появления NoSQL и NewSQL систем
Эволюция СУБД: от иерархических к реляционным
В 1960 возникла потребность в надежной модели хранения и обработки данных, особенно важной для банков и финансовых организаций. В то время отсутствовали единые стандарты работы с данными и моделями, и вся работа сводилась к ручной упорядоченной организации информации. Банкам удавалось записывать информацию о транзакциях в виде файлов в заранее подготовленную структуру, причем у каждой организации было собственное представление о том, как это должно выглядеть и функционировать. Также отсутствовали понятия консистентности и целостности данных. В таких файлах часто встречались дубликаты клиентов и их транзакций, которые приходилось уточнять и приводить в порядок вручную.
Исходя из этого можно выделить основные проблемы:
Структуры данных в каждом файле были различные.
Была необходимость согласовывать данные в разных файлах, чтобы информация была не противоречива.
Сложность разработки приложений, а также их поддержка работающих с конкретными данными, и их обновления при изменении структуры файла.
Первая попытка исправить положение была - Иерархическая модель данных
Иерархическая модель данных — модель данных, где используется представление базы данных в виде древовидной (иерархической) структуры, состоящей из объектов (данных) различных уровней.
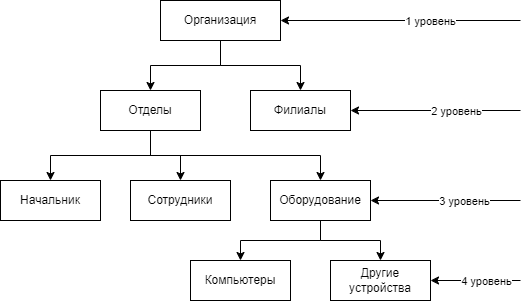
Пример иерархической модели данных
Такая модель данных представляет собой:
Запись может иметь только одного «предка».
Возможны отношения только «один к одному» или «один ко многим».
Невозможность реализации отношения «многие ко многим».
Проблема дублирования.
Сложность в поддержке.
В 60-х годах иерархическая модель баз данных была популярной, но недостаточно гибкой. В такой модели каждая запись могла иметь только одного «предка», даже если у отдельных записей было несколько «потомков». Это приводило к тому, что базы данных представляли только отношения «один к одному» или «один ко многим». Невозможность реализации отношения «многие ко многим» приводила к проблемам при работе с данными и усложняла модель. Из-за этого вопросы о консистентности данных и отсутствии дублирования информации часто не удавалось эффективно решить. Первая иерархическая система управления базами данных (СУБД) получила название IMS и была разработана компанией IBM.
Для решений проблем такого подхода появилась новая модель данных — Сетевая.
Сетевая модель данных
В ней появилась новая концепция «многие ко многим». Эта модель данных, являющаяся расширением иерархического подхода, — у потомка может быть любое число предков.

Пример сетевой модели данных
Данный подход был предложен как спецификация модели CODASYL в рамках рабочей группы DBTG (Data Base Task Group).
И даже такая модель имела недостатки на тот момент:
Высокая сложность структуры базы данных, требующая дополнительных усилий для разработки и поддержки.
«Жесткость» структуры базы данных, что затрудняло внесение изменений и модификацию данных.
Неполная независимость модели от приложения, что могло усложнять интеграцию с различными приложениями и изменения в структуре данных.
Эти недостатки сетевой модели данных могли замедлять разработку и поддержку баз данных, а также усложнять их адаптацию к изменяющимся потребностям бизнеса.
Появление реляционных баз данных
Франк Кодд существенно упростил задачу сбора и обработки данных, что привело к возникновению реляционных баз данных, которые стали неотъемлемой частью практически всех отраслей. Он также предложил язык Alpha для управления реляционными данными.
Когда Кодд опубликовал свою работу, которая послужила основой для создания реляционной модели данных. Он выделил преимущества данной модели:
Отсутствие дублирования данных
Исключение ошибок и аномалий данных
Представление всех данных как фактов, хранящихся в виде отношений (relations) со столбцами (attributes) и строками (tuples)
Коллеги Кодда из IBM, Дональд Чемберлен и Рэймонд Бойс, разработали один из языков на основе его работ. Изначально они назвали свой язык SEQUEL, однако изменили название из-за существующего товарного знака на SQL.
Реляционная модель использует таблицы и базируется на двух утверждениях:
База данных должна состоять из таблиц и только из таблиц. Только содержимое таблиц определяет операции БД.
Описание данных и манипуляции над ними должны быть независимыми от способа хранения данных на нижнем уровне.

Пример реляционной модели данных
Одной из первых реляционных СУБД была dBase-II от компании Ashton-Tate. Она была выпущена в 1979 году и разошлась тиражом около 100 000 копий, став самой популярной среди всех существовавших в то время продуктов. Это действительно стало началом, и другие компании также начали предоставлять свои продукты, включая такие известные системы как Oracle и Ingress.
Развитие баз данных усилилось после распространения локальных и глобальных сетей. Пользователи также хотели иметь возможность параллельной работы с реляционными базами данных, что способствовало развитию многопользовательских приложений для локальных сетей. В результате была создана клиент-серверная архитектура обработки данных. Реляционные базы данных, такие как Oracle, Informix, DB2, Sybase и Microsoft SQL Server, стали основными инструментами для хранения и обработки данных. Они предоставляют широкий набор функций и возможностей для эффективной работы с данными.
С 90-х годов технология баз данных стала более доступной для пользователей. В это время начали появляться различные онлайн-сервисы, такие как блоги и онлайн-магазины, которые требовали эффективной обработки и хранения данных. Большинство этих сервисов использовали комбинацию MySQL и PHP в своем стеке технологий.
Появление Not Only SQL систем
Not Only SQL (далее NoSQL) — это подход к проектированию баз данных, который предоставляет механизмы хранения и извлечения данных, отличные от традиционных реляционных баз данных. NoSQL базы данных разработаны для работы с конкретными моделями данных и обладают гибкими схемами, которые легко масштабируются для современных приложений.
Необоримость появления такого подхода произошла из-за:
Рост объемов данных: Во время больших данных компании столкнулись с необходимостью обработки огромных массивов информации, превышающих возможности традиционных реляционных СУБД.
Распределенные вычисления: С появлением интернета вещей (IoT) и мобильных приложений возросла потребность в распределенных системах обработки данных, где реляционные СУБД показали свои ограничения по масштабируемости и географической дистрибуции
Разнообразие типов данных: Современные приложения часто работают с неструктурированными или полу-структурированными данными (текст, изображения, видео, социальные медиа), для которых реляционная модель не всегда является оптимальной.
Существует четыре типа NoSQL
Ключ-значение (Key-value) — наиболее простой вариант хранилища данных, использующий ключ для доступа к значению в рамках большой хэш-таблицы.

Пример ключ-значение модель
Документ-ориентированное хранилище, в котором данные, представленные парами ключ-значение, сжимаются в виде полуструктурированного документа из тегированных элементов, подобно JSON, XML.
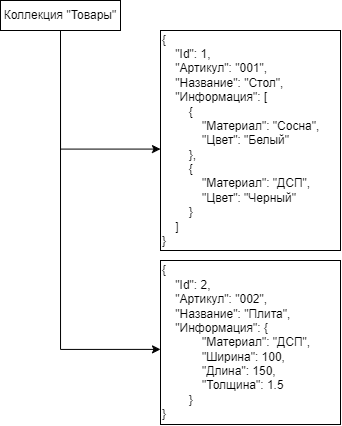
Пример документ-ориентированная модель
Колоночное хранилище, которое хранит информацию в виде разреженной матрицы, строки и столбцы которой используются как ключи.
Пример Колоночной модели | ||
Одежда | Цвет | Размер |
Футболка | Белый | 70 |
Перчатки | Красный | 40 |
Графовое хранилище представляют собой сетевую базу, которая использует узлы и рёбра для отображения и хранения данных.

Пример графовой модели
В начале 2010-х годов, на фоне стремительного роста объемов данных и популярности облачных технологий, стало очевидно, что как традиционные реляционные, так и новаторские NoSQL системы управления базами данных не могут в полной мере удовлетворить все растущие требования рынка. С одной стороны, реляционные базы данных сталкивались с проблемами масштабируемости и гибкости в обработке больших объемов данных. С другой стороны, NoSQL системы предлагали решения для этих проблем, но зачастую жертвуя согласованностью данных и совместимостью с SQL.
Появление NewSQL систем
NewSQL системы были разработаны как попытка объединить преимущества обеих подходов, предлагая масштабируемые и высокопроизводительные решения для управления данными, которые при этом поддерживают строгие транзакционные гарантии и полностью совместимы с SQL. Это позволило создать новый класс систем
Причины появления NewSQL:
Требование к ACID-транзакциям
Многие критически важные бизнес-приложения зависят от строгой консистентности данных, что обеспечивается с помощью ACID-транзакций. NoSQL системы были разработаны с упором на гибкость и масштабируемость, часто жертвуя строгими транзакционными гарантиямиСовместимость с SQL
SQL остается де-факто стандартным языком запросов для работы с данными, благодаря своей мощности, гибкости и универсальности. Многие организации и разработчики, имеющие опыт работы с реляционными базами данных, предпочли бы не отказываться от привычных SQL-инструментов. NewSQL системы предложили решение, позволяющее использовать SQL для работы с распределенными системами, обеспечивая при этом высокую производительность и масштабируемость.
Последствия появления NoSQL и NewSQL систем
С появлением систем NoSQL и NewSQL, мир управления базами данных столкнулся с значительными изменениями, которые затронули как большие организации, так и индивидуальных разработчиков. Эти изменения оказали глубокое влияние на способы хранения, обработки и анализа данных.
Следствием этого стало и ускорение процесса разработки. Благодаря возможностям, предоставляемым как NoSQL, так и NewSQL системами, разработчики смогли более эффективно адаптировать свои приложения к специфическим требованиям проектов, обеспечивая более быстрое и качественное выполнение работ.
Итог. В этой статье я рассмотрел кратко историю развития систем управления базами данных, начиная с иерархических и сетевых моделей 60-х годов и заканчивая современными реляционными, NoSQL и NewSQL системами. При написания статьи я не рассчитывал, что сможете узнать все про базы данных. Но надеюсь с помощью этого вы познакомились с ключевыми моментами, которые помогут в дальнейшем разбирать эти темы более подробно.
