Разработка в монорепозитории. Доклад Яндекса
Моё имя Азат Разетдинов, я в Яндексе уже 12 лет, руковожу службой разработки интерфейсов в Я.Недвижимости. Сегодня я хотел бы поговорить про монорепозиторий. Если у вас всего один репозиторий в работе — поздравляю, вы уже живете в монорепозитории. Теперь о том, зачем он нужен другим.
Как сказала руководитель службы разработки API Яндекс.Карт Марина Перескокова — посадил дед монорепу, выросла монорепа большая-пребольшая.
— Мы в Яндексе пробовали разные способы работы с несколькими сервисами и заметили — как только у тебя появляется больше одного сервиса, неизбежно начинают появляться общие части: модели, утилиты, инструменты, куски кода, шаблоны, компоненты. Встает вопрос: куда все это девать? Конечно, можно копипастить, мы это умеем, но хочется же красиво.
Мы пробовали даже такую сущность, как SVN externals, для тех, кто помнит. Мы пробовали git-сабмодули. Мы пробовали npm-пакеты, когда они появились. Но все это было как-то долго, что ли. Ты поддерживаешь какой-нибудь пакет, находишь ошибку, вносишь исправления. Затем тебе нужно выпустить новую версию, пройтись по сервисам, обновиться на эту версию, проверить, что все работает, запустить тесты, обнаружить ошибку, вернуться обратно в репозиторий с библиотекой, поправить ошибку, выпустить новую версию, пройтись по сервисам, обновиться и так по кругу. Это просто превращалось в боль.

Тогда мы подумали, не съехаться ли нам в один репозиторий. Взять все наши сервисы и библиотеки, перенести и разрабатываться в одном репозитории. Обнаружилось достаточно много плюсов. Я не говорю, что этот подход идеальный, но с точки зрения компании и даже отдела из нескольких групп появляются значимые плюсы.
Лично для меня самое важное — атомарность коммитов, то, что я как разработчик могу одним коммитом поправить библиотеку, обойти все сервисы, внести изменения, запустить тесты, проверить, что все работает, запушить в мастер, и все это одним изменением. Не нужно ничего пересобирать, публиковать, обновлять.
Но если все так хорошо, почему в монорепозиторий еще не переехали все? Конечно, в нем есть и минусы.

Как сказала руководитель службы разработки API Яндекс.Карт Марина Перескокова — посадил дед монорепу, выросла монорепа большая-пребольшая. Это факт, не шутка. Если вы собираете много сервисов в одном монорепозитории, он неизбежно разрастается. А если мы говорим про git, который вытягивает все файлы плюс всю их историю за все время существования вашего кода, это довольно большой дисковый объем.
Вторая проблема — вливание в мастер. Ты подготовил пул-реквест, прошел ревью, уже готов его сливать. И выясняется, что кто-то успел вперед тебя и тебе нужно разрешать конфликты. Ты разрешил конфликты, опять готов вливать, и ты опять не успел. Эта задача решается, есть системы merge queue, когда специальный робот автоматизирует эту работу, выстраивает пул-реквесты в очередь, пытается разрешить конфликты, если может. Если не может — призывает автора. Тем не менее, такая проблема существует. Есть решения, которые ее нивелируют, но нужно иметь ее в виду.
Это технические моменты, но есть еще и организационные. Предположим, у вас несколько команд, которые делают несколько разных сервисов. Когда они переезжают в монорепозиторий, у них начинает размываться ответственность. Потому что они сделали релиз, выкатили в продакшен — что-то сломалось. Начинаем разбор полетов. Выясняется, что это разработчик из другой команды что-то закоммитил в общий код, мы это потянули, зарелизили, не увидели, все сломалось. И непонятно, кто ответственен. Это важно понимать и использовать все возможные способы: юнит-тесты, интеграционные тесты, линтеры — все, что можно, чтобы уменьшить эту проблему влияния одного кода на все остальные сервисы.
Интересно, а кто еще кроме Яндекса и других игроков использует монорепозиторий? Довольно много кто. Это React, Jest, Babel, Ember, Meteor, Angular. Люди понимают — проще, дешевле, быстрее разрабатывать и публиковать npm-пакеты из монорепозитория, чем из нескольких маленьких репозиториев. Самое интересное, что вместе с этим процессом начали развиваться инструменты работы с монорепозиторием. Как раз о них и хочу поговорить.
Все начинается с создания монорепозитория. Самый известный во фронтенд-мире инструмент для этого называется lerna.

Достаточно открыть ваш репозиторий, запустить npx lerna init, он задаст вам несколько наводящих вопросов и добавит несколько сущностей в вашу рабочую копию. Первая сущность — это конфиг lerna.json, в котором указываются как минимум два поля: сквозная версия всех ваших пакетов и расположение ваших пакетов в файловой системе. По умолчанию все пакеты складываются в папку packages, но это вы можете настроить как угодно, можете даже в корень складывать, lerna это тоже умеет подхватывать.
Следующий шаг — как добавить свои репозитории в монорепозиторий, как их перенести?
Чего нам хочется добиться? Скорее всего, у вас уже есть какие-то репозитории, в данном случае А и В.

Это два сервиса, каждый в своем репозитории, и мы хотим их перенести в новый монорепозиторий в папку packages, желательно с сохранением истории коммитов, чтобы можно было сделать git blame, git log и так далее.

Для этого есть инструмент lerna import. Вы просто указываете расположение вашего репозитория, и lerna переносит его в вашу монорепу. При этом она, во-первых, берет список всех коммитов, модифицирует каждый коммит, меняя путь к файлам с корня на packages/название_пакета, и применяет их друг за другом, накладывает их в ваш монорепозиторий. Фактически препарирует каждый коммит, изменяя пути файлов в нем. По сути, lerna занимается git-магией за вас. Если вы почитаете исходный код, там просто команды git исполняются в определенной последовательности.
Это первый способ. У него есть недостаток: если вы работаете в компании, где есть продакшен-процессы, где люди уже пишут какой-то код, и вы собираетесь их перевести в монорепу, вряд ли вы сделаете это за один день. Вам нужно будет разобраться, настроить, проверить, что все запускается, тесты. А у людей работа не стоит, они продолжают что-то сделать.

Для более плавного перехода в монорепу есть такой инструмент как git subtree. Это более навороченная штука, но при этом нативная для git, которая позволяет не только импортировать отдельные репозитории в монорепозиторий по какому-то префиксу, но и обмениваться изменениями туда и обратно. То есть команда, которая делает сервис, может спокойно разрабатываться дальше в своем отдельном репозитории, при этом вы можете подтягивать их изменения через git subtree pull, вносить свои правки и пушить их обратно через git subtree push. И жить так в переходном периоде сколь угодно долго.
А когда вы все настроили, проверили, что все тесты запускаются, деплой работает, весь CI/CD настроен, вы можете сказать, что пора переходить. Для переходного периода отличное решение, рекомендую.
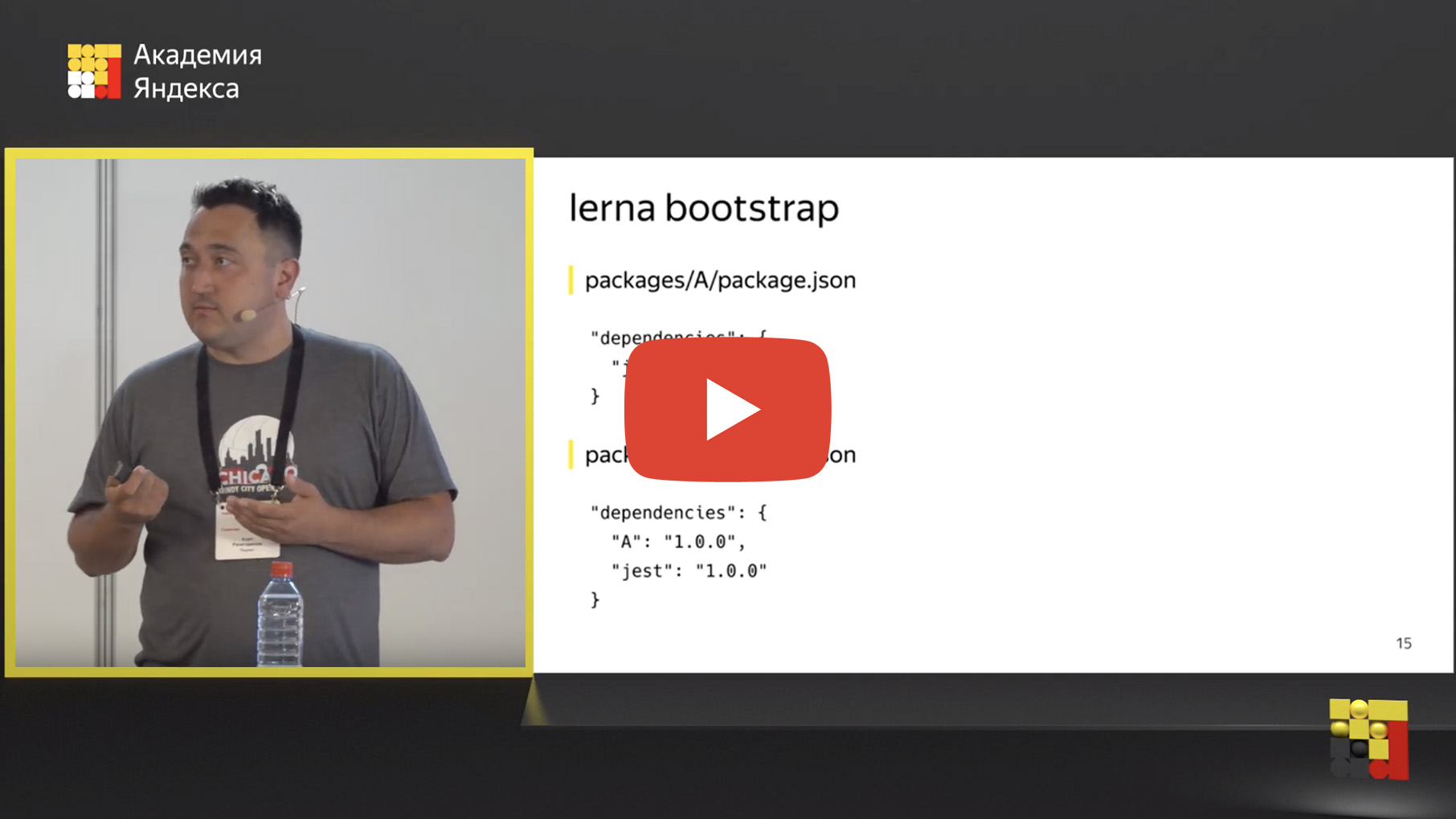
Хорошо, мы перевезли наши репозитории в один монорепозиторий, но где магия-то? Мы же хотим выделять общие части и как-то их использовать. И для этого есть механизм «связывание зависимостей». Что такое связывание зависимостей? Есть инструмент lerna bootstrap, это команда, которая похожа на npm install, просто запускает npm install во всех ваших пакетах.

Но это не всё. Кроме того она ищет внутренние зависимости. Вы можете внутри своего репозитория в одном пакете использовать другой. Например, если у вас есть пакет А, который зависит в данном случае от Jest, есть пакет В, который зависит от Jest и от пакета A. Если пакет А — это общий инструмент, общий компонент, то пакет В — это сервис, который его использует.
Lerna определяет такие внутренние зависимости и заменяет физически на файловой системе эту зависимость на символическую ссылку.


После того, как вы запускаете lerna bootstrap, прямо внутри папки node_modules вместо физической папки А появляется символическая ссылка, которая ведет на папку с пакетом А. Это очень удобно, потому что вы можете править код внутри пакета А и тут же проверять результат в пакете В, запускать тесты, интеграционные, юниты, что хотите. Сильно упрощается разработка, вам не нужно больше пересобирать пакет А, публиковать, подключать пакет В. Просто здесь поправили, там проверили.
Обратите внимание, если посмотреть на папки node_modules, и там, и там есть jest, у нас дублируется установленный модуль. И вообще это довольно долго, когда вы запускаете lerna bootstrap, ждете, пока все остановится, из-за того, что много всякой повторной работы, в каждом пакете получаются задублированные зависимости.
Чтобы ускорить установку зависимостей, используется механизм подъема зависимостей. Идея очень простая: можно взять и общие зависимости унести в корневой node_modules.

Если указать опцию --hoist (это подъем с английского), то почти все зависимости просто переедут в корневой node_modules. Причем это работает почти всегда. Нода так устроена, что если она не нашла зависимостей на своем уровне, она начинает искать на уровень выше, если там нет — еще на уровень выше и так далее. Практически ничего не меняется. А по сути, мы взяли и дедуплицировали наши зависимости, перенесли зависимости в корень.
При этом lerna достаточно умная. Если есть какой-то конфликт, например, если бы пакет А использовал Jest версии 1, а пакет В — версии 2, то один из них всплыл бы наверх, а второй остался бы на своем уровне. Это примерно то, чем на самом деле занимаются npm внутри обычной папки node_modules, он тоже пытается дедуплицировать зависимости и по максимуму нести их в корень.
К сожалению, эта магия работает не всегда, особенно с инструментами, с Babel, с Jest. Часто бывает, что он начинает, поскольку в Jest есть своя система резолвинга модулей, Нода начинает лагать, бросать ошибку. Специально для таких случаев, когда инструмент не справляется с зависимостями, которые уехали в корень, есть опция nohoist, который позволяет точечно сказать, что эти пакеты в корень не переноси, оставляй их на месте.

Если указать --nohoist=jest, то все зависимости кроме jest уедут в корень, а jest останется на уровень пакетов. Не зря я такой пример привел — именно у jest есть проблемы с таким поведением, и nohoist в этом помогает.
Еще один плюс подъема зависимостей:

Если у вас до этого были отдельные package-lock.json на каждый сервис, на каждый пакет, то при хойстинге у вас все переезжает наверх, и остается единственный package-lock.json. Это удобно с точки зрения вливания в мастер, разрешения конфликтов. Один раз все зарезолвили, и всё.
Но каким образом lerna это достигает? Она довольно агрессивно химичит с npm. Когда вы указываете hoist, она берет ваш package.json в корне, бэкапит его, вместо него подставляет другой, агрегирует в него все ваши зависимости, запускает npm install, почти все ставится в корень. Затем этот временный package.json убирает, восстанавливает ваш. Если вы после этого запустите любую команду с npm, например, npm remove, npm не поймет, что произошло, почему вдруг все зависимости оказались в корне. Lerna нарушает уровень абстракции, она залезает в инструмент, который находится ниже ее по уровню.
Первыми эту проблему заметили ребята из Yarn и сказали: чего мы мучаетесь, давайте мы вам все сделаем нативно, чтобы все из коробки работало.

Yarn уже сейчас может из коробки делать все то же самое: связывать зависимости, если видит, что пакет В зависит от пакет А, он сделает за вас симлинку, даром. Он умеет поднимать зависимости, делает это по умолчанию, все складывает в корень. Как и lerna умеет оставлять единственный yarn.lock в корне репозитория. Все остальные yarn.lock больше вам не нужны.

Настраивается он похожим образом. К сожалению, yarn предполагает, что все настройки добавляются в package.json, я знаю, есть люди, которые стараются все настройки инструментов оттуда уносить, оставить только минимум. К сожалению, yarn еще не научился указывать это в другом файле, только package.json. Там появляется две новые опции, одна новая и одна обязательная. Поскольку предполагается, что корневой репозиторий никогда не будет публиковать, yarn требует, чтобы там был указано private=true.
А вот настройки workspaces хранятся в одноименном ключе. Настройка очень похожа на настройки lerna, есть поле packages, где вы указываете расположение ваших пакетов, и есть опция nohoist, очень похожая на опцию nohoist в lerna. Просто указываете эти настройки и получаете аналогичную структуру, как и в lerna. Все общие зависимости уехали в корень, а те, которые указаны в ключе nohoist, остались на своем уровне.

Самое приятное, что lerna умеет работать с yarn и подхватывать его настройки. Достаточно указать в lerna.json два поля, lerna тут же поймет, что вы используете yarn, зайдет в package.json, достанет оттуда все настройки и будет работать с ними. Эти два инструмента уже знают друг про друга и работают в паре.

А почему в npm до сих пор не сделали поддержку, если столько больших компаний использует монорепозиторий?

Ссылка со слайда
Говорят, что все будет, но в седьмой версии. Базовая поддержка в седьмой, расширенная — в восьмой. Месяц назад вышел этот пост, но при этом до сих пор даже неизвестна дата, когда выйдет седьмой npm. Ждем, когда он наконец догонит yarn.
Когда у вас несколько сервисов в одном монорепозитории, неизбежно встает вопрос, как ими управлять, чтобы не ходить в каждую папку, не запускать команды? Для этого есть массовые операции.


У yarn есть команда yarn workspace, потом название пакета и название команды. Поскольку yarn из коробки, в отличие от npm, умеет все три вещи: запускать собственные команды, добавить зависимость от jest, запускать скрипты из package.json, как test, а также умеет запускать исполняемые файлы из папки node_modules/.bin. Приучем он сам за вас с помощью эвристики поймет, что вы хотите. Очень удобно использовать yarn workspace для точечных операций над одним пакетом.
Есть похожая команда, которая позволяет выполнить команду над всеми пакетами, что у вас есть.

Указываете просто ваши команды со всеми аргументами.

Из плюсов, очень удобно запускать разные команды. Из минусов, например, невозможно запускать shell-команды. Допустим, я хочу удалить все папки node modules, я не могу запустить yarn workspaces run rm.
Невозможно указать список пакетов, например, хочу только в двух пакетах удалить зависимость, только по очереди или по отдельности.
Ну и он падает при первой же ошибке. Если я хочу удалить зависимость из всех пакетов —, а по сути, она есть только в двух из них, но я не хочу думать, где она есть, а хочу просто удалить, — то yarn это не позволит сделать, он упадет при первой же ситуации, где этого пакета в зависимостях нет. Это не очень удобно, иногда хочется игнорировать ошибки, прогонять по всем пакетам.

У lerna куда более интересный инструментарий, там есть две отдельных команды run и exec. Run умеет исполнять скрипты из package.json, при этом в отличие от yarn она умеет фильтровать все по пакетам, можно указать --scope, можно использовать звездочки, глобы, все довольно универсально. Можно запускать эти операции параллельно, можно игнорировать ошибки через ключ --no-bail.

Exec очень похож. В отличие от yarn, он позволяет не только запускать исполняемые файлы из node_modules.bin, а исполнять любые произвольные shell-команды. Например, можно удалить node_modules или запустить какой-нибудь make, все что хотите. И поддерживается та же самая опция.

Очень удобный инструментарий, одни плюсы. Это тот случай, когда lerna рвет yarn, находится на нужном уровне абстракции. Именно за этим lerna и нужна: упрощать работу с несколькими пакетами в монорепе.
С монорепами есть еще один минус. Когда у вас налажен CI/CD, вы его никак не оптимизируете. Чем больше у вас сервисов, тем дольше это все происходит. Допустим, вы запускаете тестирование всех сервисов на каждый пул-реквест, и чем больше их становится, тем дольше идет работа. Для оптимизации этого процесса можно использовать селективные операции. Я назову три разных способа. Первые два из них можно использовать не только в монорепе, но и в ваших проектах, если вы эти способы почему-то не используете.
Первый — lint-stages, позволяющий запускать линтеры, тесты, все что хотите, только на те файлы, которые изменились или будут закоммичены в данном коммите. Запускать весь lint не на весь ваш проект, а только на те файлы, которые поменялись.


Настройка очень простая. Ставите lint-staged, husky, прекоммит-hooks и говорите, что при изменении любого js-файла нужно запустить eslint. Таким образом прекоммит-проверка сильно ускоряется. Особенно если у вас много сервисов, очень большой монорепозиторий. Тогда запускать eslint на все файлы слишком дорого, и можно таким способом оптимизировать прекоммит-hooks на lint.

Если вы пишите тесты на Jest, у него тоже есть инструменты для селективного запуска тестов.

Эта опция позволяет передать ему список исходных файлов и найти все тесты, которые так или иначе затрагивают эти файлы. Что можно использовать в связке с lint-staged? Обратите внимание, здесь я указываю не все js-файлы, а только исходники. Мы исключаем сами js-файлы с тестами внутри, смотрим только исходники. Запускаем findRelatedTests и сильно ускоряем прогон юнитов на прекоммит или на препуш, кому как удобно.
И третий способ, связанный именно с монорепозиториями. Это lerna, которая умеет определять, какие пакеты поменялись в сравнении с базовым коммитом. Тут речь скорее не про хуки, а про ваш CI/CD: Travis или другой сервис, который вы используете.


У команд run и exec есть опция since, позволяющая прогонять любую команду только в тех пакетах, которые поменялись с какого-то коммита. В простых случаях можно указать мастер, если вы все выливаете в него. Если хотите более точно, то лучше через ваш инструмент CI/CD указать базовый коммит вашего пул-реквеста, тогда это будет более честное тестирование.
Поскольку lerna знает все зависимости внутри пакетов, она умеет определять и косвенные зависимости. Если вы поменяли библиотеку А, которая используется в библиотеке В, которая используется в сервисе С, lerna это поймет. Предположим, вы меняете код в библиотеке А. Тогда она транзитивно определит, что пакет C нужно перетестировать — например, с помощью написанного вами интеграционного теста. И lerna запустит эту команду на пакет С.
Вот несколько ссылок, которые могут вам пригодиться: cайт lerna, рекомендация по yarn workspaces и теоретическое описание плюсов и минусов монорепозитория в принципе.
Есть люди, которые любят монорепозитории. Есть люди, которые любят мультирепозитории. Здесь всегда вопрос компромисса. Что проще? Я для себя определил, что работающие по отдельности команды склонны работать независимо, потому что чем больше у них независимости, тем они счастливее. Но предположим, мы поднимаемся на уровень руководителя отдела или небольшой компании, где все по отдельности независимые. Тогда компания начинает терять, потому что какие-то вещи каждая команда делает по отдельности. Допустим, нужно перейти на новую версию Babel. Каждая команда по отдельности разбирается, что там поменялось, что нужно поменять в коде. И предприниматель или руководитель отдела тратит ресурсы компании на одну и ту же деятельность в пяти разных местах. Когда мы приходим в монорепозиторий, то можем эту общую деятельность вынести за скобки и сэкономить ресурсы.
Хочу сказать спасибо своим коллегам: Мише mishanga Трошеву и Гоше Беседину. Они потратили довольно много времени на изучение инструментов, которые мы сегодня рассмотрели, и поделились опытом и знаниями. На этом всё, спасибо.
