Разработка системы аутентификации на Java+Tarantool
 Системы аутентификации есть везде. Пока вы скучаете в лифте по пути с седьмого этажа на первый, можно успеть проверить баланс в приложении банка, поставить пару лайков в Instagram, а потом проверить почту. Это минимум три системы аутентификации.
Системы аутентификации есть везде. Пока вы скучаете в лифте по пути с седьмого этажа на первый, можно успеть проверить баланс в приложении банка, поставить пару лайков в Instagram, а потом проверить почту. Это минимум три системы аутентификации.
Меня зовут Александр, я программист в отделе архитектуры и пресейла в Mail.ru Group. Я расскажу, как построить систему аутентификации на основе Tarantool и Java. Нам в пресейле очень часто приходится делать именно такие системы. Способов аутентификации очень много: по паролю, биометрическим данным, SMS и т.п. Для наглядности я покажу, как сделать аутентификацию по паролю.
Статья будет полезна тем, кто хочет разобраться в устройстве систем аутентификации. На доступном примере я покажу все основные части архитектуры, как они связаны между собой и как работают в целом.
Система аутентификации проверяет подлинность данных, введенных пользователем. С такими системами мы сталкиваемся везде, начиная от операционных систем и заканчивая различными сервисами. Видов аутентификации очень много: по паре логин-пароль, с помощью электронной подписи, по биометрическим данным и т.д. Я выбрал систему логин-пароль в качестве примера, потому что она встречается чаще всего и достаточно проста. А ещё она позволяет показать основные возможности Cartridge и Cartridge Java, нам достаточно будет написать относительно немного кода. Но обо всём по порядку.
Основы систем аутентификации
В любой системе аутентификации обычно можно выделить несколько элементов:
- субъект, который будет проходить процедуру;
- характеристика субъекта — отличительная черта;
- хозяин системы аутентификации, несущий ответственность и контролирующий её работу;
- механизм аутентификации, то есть принцип работы системы;
- механизм управления доступом, предоставляющий определенные права доступа субъекту.
Механизм аутентификации может предоставляться программным обеспечением, проверяющим подлинность характеристик субъекта: веб-сервисом, модулем операционной системы и т.п. Чаще всего характеристики субъекта должны где-то храниться, то есть должна быть база данных, например, MySQL или PostgreSQL.
Если нет готового программного обеспечения, позволяющего реализовать механизм аутентификации по определённым правилам, приходится писать его самостоятельно. К этим случаям можно отнести аутентификацию по нескольким характеристикам, с усложнёнными алгоритмами проверки и др.
Что такое Tarantool Cartridge и Cartridge Java?
Tarantool Cartridge — фреймворк для масштабирования и управления кластером из нескольких экземпляров Tarantool. Помимо создания кластера он также позволяет довольно эффективно этим кластером управлять, например, расширять его, автоматически решардировать и реализовывать любую бизнес-логику на основе ролей.
Для работы с кластером из какого-либо приложения необходимо использовать так называемые коннекторы — драйверы для взаимодействия с базой данных и кластером по специальному бинарному протоколу iproto. На текущий момент у нас есть коннекторы для таких языков программирования, как Go, Java, Python и др., часть из которых может работать только с одним экземпляром Tarantool, другие же могут работать с целыми кластерами. Одним из таких коннекторов является Cartridge Java, который позволяет нам взаимодействовать с кластером из приложения на Java. И здесь, собственно, возникает вопрос:, а почему именно этот язык?
Почему именно Java?
Я работаю в отделе архитектуры и пресейла, а это означает, что мы делаем пилотные проекты для заказчиков из разных областей бизнеса. Под пилотным проектом подразумевается прототип системы, который впоследствии будет доработан и передан заказчику. Поэтому в числе наших заказчиков чаще всего люди, которые используют для разработки языки, позволяющие создавать enterprise-решения. Одним из таких языков и является Java. Поэтому мы выбрали коннектор Cartridge Java.
Почему аутентификация?
Дальше возникает вопрос выбора сервиса, на примере которого мы хотим продемонстрировать технологии. Почему же мы взяли именно аутентификацию, а не какой-то другой сервис? Ответ достаточно прост: это наиболее частая задача, которую пытаются решить не только с помощью Tarantool, но и с помощью других баз данных.
Аутентификация встречается нам практически во всех более-менее приличных приложениях. Чаще всего для хранения профилей пользователей используются такие базы данных, как MySQL или PostgreSQL. Однако применение Tarantool здесь наиболее уместно, потому что он может справиться с десятками тысяч запросов в секунду за счёт того, что все данные хранятся в ОЗУ, in-memory. А при падении экземпляра он может достаточно быстро восстановиться благодаря использованию snapshot«ов и write-ahead логов.
Теперь разберём, какая же структура будет у нашего сервиса. Он будет состоять из двух частей:
- приложение на Tarantool Cartridge, выполняющее роль базы данных;
- приложение на Java, предоставляющее API для выполнения основных операций.
Рассмотрим первую часть нашего сервиса:
Приложение на Tarantool Cartridge
Это приложение будет представлять собой небольшой кластер из одного роутера, двух наборов реплик хранилищ и одного стейтборда.
Роутер — это экземпляр с ролью router, который отвечает за маршрутизацию запросов к хранилищам. Мы немного расширим его функциональность. Как это сделать, расскажу ниже.
Под набором реплик хранилищ подразумеваются группа из N экземпляров с ролью storage, один из которых является мастером, а остальные — репликами. В нашем случае это пары экземпляров, которые играют роль хранилища профилей.
Стейтборд отвечает за конфигурацию failover-механизма кластера в случае отказа отдельных экземпляров.
Создание и настройка приложения
Создадим приложение, выполнив команду:
$ cartridge create –-name authentication
Будет создана директория authentication, содержащая всё необходимое для создания кластера. Зададим список экземпляров в файле instances.yml:
---
authentication.router:
advertise_uri: localhost:3301
http_port: 8081
authentication.s1-master:
advertise_uri: localhost:3302
http_port: 8082
authentication.s1-replica:
advertise_uri: localhost:3303
http_port: 8083
authentication.s2-master:
advertise_uri: localhost:3304
http_port: 8084
authentication.s2-replica:
advertise_uri: localhost:3305
http_port: 8085
authentication-stateboard:
listen: localhost:4401
password: passwd
Теперь нам необходимо настроить роли.
Настройка ролей
Чтобы наше приложение могло работать с коннектором Cartridge Java, нам необходимо создать и настроить новые роли. Сделать это можно, продублировав файл custom.lua и переименовав полученные файлы в storage.lua и router.lua в папке app/roles, а затем поменяв в них настройки. Сперва необходимо изменить имя роли в return в поле role_name. В router.lua роль будет называться router, а в storage.lua — storage. Затем необходимо указать соответствующие имена ролей в init.lua в секции roles в cartridge.cfg.
Для работы с Cartridge Java нам нужно установить модуль ddl, добавив в файл с расширением *.rockspec в секцию dependencies строку 'ddl == 1.3.0-1'. После этого в router.lua добавим функцию get_schema:
function get_schema()
for _, instance_uri in pairs(cartridge_rpc.get_candidates('app.roles.storage', { leader_only = true })) do
local conn = cartridge_pool.connect(instance_uri)
return conn:call('ddl.get_schema', {})
end
end
И в функцию init добавим строку:
rawset(_G, 'ddl', { get_schema = get_schema })
Помимо этого, в storage.lua в функцию init добавим условие:
if opts.is_master then
rawset(_G, 'ddl', { get_schema = require('ddl').get_schema })
end
Оно означает, что на тех хранилищах, которые являются мастерами, нам необходимо выполнить функцию rawset. Перейдём к определению топологии кластера.
Создание топологии и запуск кластера
Зададим топологию кластера в файле replicasets.yml:
router:
instances:
- router
roles:
- failover-coordinator
- router
all_rw: false
s-1:
instances:
- s1-master
- s1-replica
roles:
- storage
weight: 1
all_rw: false
vshard_group: default
s-2:
instances:
- s2-master
- s2-replica
roles:
- storage
weight: 1
all_rw: false
vshard_group: default
После определения конфигурации экземпляров и топологии, выполним команды для сборки и запуска нашего кластера:
$ cartridge build
$ cartridge start -d
Будут созданы и запущены экземпляры, которые мы задали в instances.yml. Теперь мы можем перейти в браузере по адресу http://localhost:8081, где увидим графический интерфейс для управления нашим кластером, в котором будут указаны созданные экземпляры. Однако на текущий момент они не сконфигурированы и не объединены в наборы реплик так, как мы указали в replicasets.yml. Чтобы вручную не настраивать экземпляры, выполним команду:
$ cartridge replicasets setup -bootstrap-vshard
Теперь если мы посмотрим список наших экземпляров, то увидим, что топология настроена, то есть им назначены соответствующие роли и они объединены в наборы реплик:
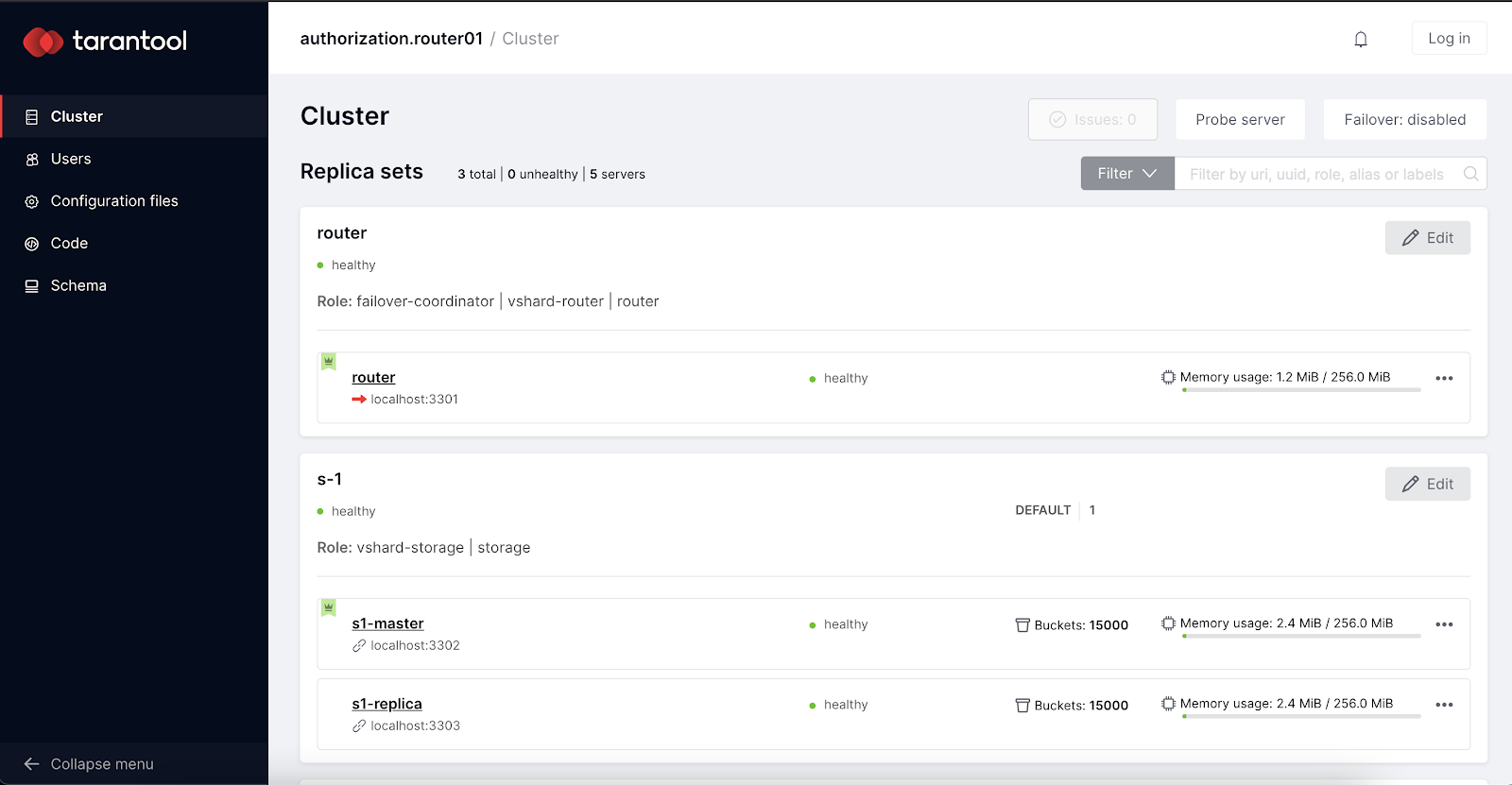
Помимо этого была выполнена первичная загрузка кластера, что дало нам работающий шардинг. Теперь мы можем пользоваться кластером!
Создание модели
На самом деле, мы пока им пользоваться не можем, потому что у нас нет модели, которая описывает пользователя. Давайте подумаем, как же лучше его описать? Какую информацию о пользователе мы хотим хранить? Так как наш пример достаточно простой, то в качестве основной информации о пользователе возьмём следующие поля:
uuid— уникальный идентификатор пользователя;login— логин пользователя;password— поле, содержащее хеш-сумму от пароля пользователя.
Это основные поля, которые будет содержать модель. Их достаточно, когда пользователей мало и нагрузка небольшая. Но что будет, когда количество пользователей станет огромным? Мы, вероятно, захотим сделать шардирование, чтобы была возможность разнести пользователей на разные хранилища, а те, в свою очередь, на разные машины или в разные ЦОДы. Тогда по какому полю шардировать пользователей? Есть два варианта: по UUID и по логину. Мы будем шардировать пользователей по логину.
Чаще всего ключ шардирования выбирается таким образом, чтобы записи из разных спейсов, имеющие одинаковый ключ шардирования, лежали на одном и том же хранилище. Но так как в нашей задаче всего один спейс, мы выбираем то поле, которое больше нравится. После этого надо подумать, какой алгоритм мы будем использовать для шардирования? К счастью, необходимость выбора отпадает, потому что в Tarantool Cartridge используется библиотека vshard, в которой применяется алгоритм виртуального шардирования, о нём можно почитать здесь. Чтобы им воспользоваться, нам необходимо добавить в модель еще одно поле — bucket_id. Значение данного поля будет высчитываться на основе значения поля login. Теперь мы можем полностью описать наш спейс:
local user_info = box.schema.create_space('user_info', {
format = {
{ name = 'bucket_id', type = 'unsigned' },
{ name = 'uuid', type = 'string' },
{ name = 'login', type = 'string' },
{ name = 'password', type = 'string' },
},
if_not_exists = true,
})
Чтобы с начать работать со спейсом необходимо создать хотя бы один индекс. Создадим первичный индекс полю login, который назовём primary:
user_info:create_index('primary', {
parts = { 'login' },
if_not_exists = true,
})
Так как мы используем vshard, нам также необходимо создать вторичный индекс по полю bucket_id:
user_info:create_index('bucket_id', {
parts = { 'bucket_id' },
if_not_exists = true,
unique = false
})
Также добавим ключ шардирования по полю login:
utils.register_sharding_key('user_info', {'login'})
Работа с миграциями
Для работы со спейсами будем использовать модуль migrations. Для этого необходимо добавить в файл с расширением *.rockspec в секцию dependencies строку:
'migrations == 0.4.0-1'
Для работы с этим модулем надо создать папку migrations в корне приложения и положить в неё файл 0001_initial.lua с таким содержимым:
local utils = require('migrator.utils')
return {
up = function()
local user_info = box.schema.create_space('user_info', {
format = {
{ name = 'bucket_id', type = 'unsigned' },
{ name = 'uuid', type = 'string' },
{ name = 'login', type = 'string' },
{ name = 'password', type = 'string' },
},
if_not_exists = true,
})
user_info:create_index('primary', {
parts = { 'login' },
if_not_exists = true,
})
user_info:create_index('bucket_id', {
parts = { 'bucket_id' },
if_not_exists = true,
unique = false
})
utils.register_sharding_key('user_info', {'login'})
return true
end
}
Чтобы наш спейс создался, надо отправить POST-запрос по адресу http://localhost:8081/migrations/up, например, так:
$ curl –X POST http://localhost:8081/migrations/up
Тем самым мы применяем миграцию. При создании новых миграций надо добавить в migrations новые файлы, имена которых начинаются с 0002-…, и выполнить приведённую выше команду.
Создание хранимых процедур
После продумывания модели и создания спейса нам необходимо создать функции, с помощью которых наше приложение на Java будет взаимодействовать с кластером. Такие функции называются хранимыми процедурами, они вызываются на роутерах и манипулируют данными посредством вызова определённых методов спейса.
Какие же операции с профилями пользователей мы хотим выполнять? Так как мы хотим использовать наш кластер в первую очередь в качестве хранилища профилей, то очевидно, что у нас должна быть функция создания профиля. Помимо этого, так как у нас пример аутентификации, мы должны иметь возможность получить информацию о пользователе по его логину. И напоследок, у нас должны быть функции обновления информации о пользователе, на тот случай, если пользователь, например, забыл пароль, и функция удаления пользователя, если пользователь захочет удалить свой аккаунт.
С основными хранимыми процедурами мы определились, теперь пришло время их реализовать. Вся реализация будет храниться в файле app/roles/router.lua. Начнём с реализации процедуры создания пользователя, но для начала создадим некоторые вспомогательные константы:
local USER_BUCKET_ID_FIELD = 1
local USER_UUID_FIELD = 2
local USER_LOGIN_FIELD = 3
local USER_PASSWORD_FIELD = 4
Как видно из названий, константы определяют номера соответствующих полей в спейсе. Они позволят нам использовать осмысленные имена при индексации полей в кортеже в наших хранимых процедурах. Теперь приступим к созданию первой процедуры. Назовём её create_user, в качестве параметров ей будут передаваться UUID, логин и хеш пароля.
function create_user(uuid, login, password_hash)
local bucket_id = vshard.router.bucket_id_mpcrc32(login)
local _, err = vshard.router.callrw(bucket_id, 'box.space.user_info:insert', {
{bucket_id, uuid, login, password_hash }
})
if err ~= nil then
log.error(err)
return nil
end
return login
end
- Первым делом мы с помощью
vshard.router.bucket_id_mpcrc32вычисляемbucket_id, по которому будут шардироваться наши записи. - Затем вызываем функцию
insert, у спейса на бакете с вычисленнымbucket_id, которому передаём кортеж, состоящий из полейbucket_id,uuid,loginиpassword_hash. Этот вызов выполняется с помощью вызоваvshard.router.callrwбиблиотеки vshard, позволяющего выполнять операции записи в спейс и возвращающего результат выполнения вызываемой функции (и ошибку в случае неудачи). - Затем мы проверяем, удачно выполнилась наша функция или нет, и в случае ошибки возвращаем
nil, а при успешной вставке возвращаем логин пользователя.
Перейдём к следующей хранимой процедуре — получению информации о пользователе по его логину. Она будет называться get_user_by_login. Для неё мы воспользуемся следующим алгоритмом:
- Вычисляем по логину
bucket_id. - Вызываем у спейса функцию
getна вычисленном бакете с помощьюvshard.router.callbro. - Если пользователь с указанным логином существует, то возвращаем кортеж с информацией о нём, иначе возвращаем
nil.
Реализация:
function get_user_by_login(login)
local bucket_id = vshard.router.bucket_id_mpcrc32(login)
local user = vshard.router.callbro(bucket_id, 'box.space.user_info:get', {login})
return user
end
Помимо аутентификации она также пригодится нам в функциях обновления информации о пользователе и его удаления.
Рассмотрим случай, когда пользователь решил обновить информацию о себе, в нашем случае это будет пароль. Напишем функцию, которую назовём update_user_by_login. На вход она принимает логин и хеш нового пароля. Какой алгоритм нам необходимо использовать? Сперва попробуем получить информацию о пользователе с помощью уже реализованной нами get_user_by_login. Если пользователь не существует, то вернём nil. Иначе вычислим bucket_id по его логину, и вызовем на бакете функцию update нашего спейса, в которую передадим логин пользователя и кортеж, содержащий информацию о поле, которое нам надо обновить — присвоить новый хеш пароля. Если при обновлении произошла ошибка, то логируем её и вернём nil, иначе вернём кортеж с информацией о пользователе. На Lua эта процедура будет выглядеть так:
function update_user_by_login(login, new_password_hash)
local user = get_user_by_login(login)
if user ~= nil then
local bucket_id = vshard.router.bucket_id_mpcrc32(user[USER_LOGIN_FIELD])
local user, err = vshard.router.callrw(bucket_id, 'box.space.user_info:update', { user[USER_LOGIN_FIELD], {
{'=', USER_PASSWORD_FIELD, new_password_hash }}
})
if err ~= nil then
log.error(err)
return nil
end
return user
end
return nil
end
И напоследок реализуем последнюю процедуру: удаление пользователя. Назовём её delete_user_by_login. Алгоритм будет чем-то похож на функцию обновления информации, с тем лишь отличием, что в случае существования пользователя у спейса будет вызвана функция delete и возвращена информация об удалённом пользователе, иначе вернём nil. Реализация этой хранимой процедуры:
function delete_user_by_login(login)
local user = get_user_by_login(login)
if user ~= nil then
local bucket_id = vshard.router.bucket_id_mpcrc32(user[USER_LOGIN_FIELD])
local _, _ = vshard.router.callrw(bucket_id, 'box.space.user_info:delete', {
{user[USER_LOGIN_FIELD]}
})
return user
end
return nil
end
Итого
- Создали приложение.
- Настроили роли.
- Сконфигурировали топологию.
- Запустили кластер.
- Описали модель и создали миграцию.
- Реализовали хранимые процедуры.
Теперь можно перезапустить кластер и начать наполнять его данными. А мы, тем временем, перейдём к разработке приложения на Java.
Приложение на Java
Приложение на Java будет выполнять роль API и предоставлять бизнес-логику для аутентификации пользователей. Так как это enterprise-приложение, создавать его будем во фреймворке Spring. Для сборки используем фреймворк Apache Maven.
Установка коннектора
Для установки коннектора добавим в pom.xml в секцию dependencies зависимость:
io.tarantool
cartridge-driver
0.4.2
После это необходимо обновить зависимости. Последнюю версию коннектора можно посмотреть здесь. Установив коннектор, необходимо импортировать из io.tarantool.driver; классы, которые будем использовать.
Подключение к кластеру
После установки коннектора нам необходимо создать класс, который будет отвечать за его конфигурацию и подключать приложение к кластеру на Tarantool Cartridge. Назовём этот класс TarantoolConfig. Укажем, что он является конфигурационным и берёт свои параметры из файла application-tarantool.properties:
@Configuration
@PropertySource(value="classpath:application-tarantool.properties", encoding = "UTF-8")
Файл application-tarantool.properties содержит в себе поля:
tarantool.nodes=localhost:3301 # список нод
tarantool.username=admin # имя пользователя
tarantool.password=authentication-cluster-cookie # пароль
Они необходимы для подключения к кластеру. Именно эти параметры принимает на вход конструктор нашего класса:
public TarantoolClient tarantoolClient(
@Value("${tarantool.nodes}") String nodes,
@Value("${tarantool.username}") String username,
@Value("${tarantool.password}") String password)
Поля username и password мы будем использовать для создания Credentials — параметров для аутентификации:
SimpleTarantoolCredentials credentials = new SimpleTarantoolCredentials(username, password);
Зададим клиентскую конфигурацию для подключения к кластеру, а именно укажем параметры для аутентификации и таймаут запроса:
TarantoolClientConfig config = new TarantoolClientConfig.Builder()
.withCredentials(credentials)
.withRequestTimeout(1000*60)
.build();
Далее необходимо передать список нод в так называемый AddressProvider, содержащий логику преобразования строки в список адресов и возвращающий этот список:
TarantoolClusterAddressProvider provider = new TarantoolClusterAddressProvider() {
@Override
public Collection getAddresses() {
ArrayList addresses = new ArrayList<>();
for (String node: nodes.split(",")) {
String[] address = node.split(":");
addresses.add(new TarantoolServerAddress(address[0], Integer.parseInt(address[1])));
}
return addresses;
}
};
И наконец, мы создаём клиент, который будет подключаться к кластеру. Оборачиваем его в специальный proxy-клиент и возвращаем результат, обёрнутый в retrying-клиент, который при неудачной попытке подключения пытается подключить ещё раз, пока не исчерпает указанное количество попыток:
ClusterTarantoolTupleClient clusterClient = new ClusterTarantoolTupleClient(config, provider);
ProxyTarantoolTupleClient proxyClient = new ProxyTarantoolTupleClient(clusterClient);
return new RetryingTarantoolTupleClient(
proxyClient,
TarantoolRequestRetryPolicies.byNumberOfAttempts(
10, e -> e.getMessage().contains("Unsuccessful attempt")
).build());
Полный код класса:
@Configuration
@PropertySource(value="classpath:application-tarantool.properties", encoding = "UTF-8")
public class TarantoolConfig {
@Bean
public TarantoolClient tarantoolClient(
@Value("${tarantool.nodes}") String nodes,
@Value("${tarantool.username}") String username,
@Value("${tarantool.password}") String password) {
SimpleTarantoolCredentials credentials = new SimpleTarantoolCredentials(username, password);
TarantoolClientConfig config = new TarantoolClientConfig.Builder()
.withCredentials(credentials)
.withRequestTimeout(1000*60)
.build();
TarantoolClusterAddressProvider provider = new TarantoolClusterAddressProvider() {
@Override
public Collection getAddresses() {
ArrayList addresses = new ArrayList<>();
for (String node: nodes.split(",")) {
String[] address = node.split(":");
addresses.add(new TarantoolServerAddress(address[0], Integer.parseInt(address[1])));
}
return addresses;
}
};
ClusterTarantoolTupleClient clusterClient = new ClusterTarantoolTupleClient(config, provider);
ProxyTarantoolTupleClient proxyClient = new ProxyTarantoolTupleClient(clusterClient);
return new RetryingTarantoolTupleClient(
proxyClient,
TarantoolRequestRetryPolicies.byNumberOfAttempts(
10, e -> e.getMessage().contains("Unsuccessful attempt")
).build());
}
}
Когда приложение после запуска впервые попытается отправить запрос в Tarantool, оно подключится к кластеру. Перейдём к созданию API и модели пользователя нашего приложения.
Создание API и модели пользователя
Будем использовать спецификацию OpenAPI версии 3.0.3. Создадим три конечные точки, каждая из которых будет принимать соответствующие виды запросов и обрабатывать их:
/register- POST — создание пользователя.
/login- POST — аутентификация пользователя.
/{login}- GET — получение информации о пользователе;
- PUT — обновление информации о пользователе;
- DELETE — удаление пользователя.
Также добавим описание методов, которые будут обрабатывать каждый из наших запросов и ответов, возвращаемые приложением:
authUserRequestauthUserResponsecreateUserRequestcreateUserResponsegetUserInfoResponseupdateUserRequest
При обработке этих методов контроллерами будут вызываться те хранимые процедуры, которые мы реализовали на Lua.
Теперь необходимо сгенерировать классы, соответствующие описанным методам и ответам. Для этого воспользуемся плагином swagger-codegen. Добавим в pom.xml в секцию build описание плагина:
io.swagger.codegen.v3
swagger-codegen-maven-plugin
3.0.21
api
generate
${project.basedir}/src/main/resources/api.yaml
java
org.tarantool.models.rest
false
false
false
false
java8
resttemplate
true
true
В нём мы указываем путь к файлу api.yaml с описанием API, и путь к папке, в которую необходимо поместить сгенерированные файлы на Java. После запуска сборки мы получим сгенерированные классы запросов/ответов, которые будем использовать при создании контроллеров.
Перейдём к созданию модели пользователя. Класс будет называться UserModel. Поместим его в папку models. В той же папке в подпапке rest лежат классы запросов/ответов. Модель будет описывать пользователя и содержать три приватных поля: uuid, login и password. Также в ней будут геттеры и сеттеры для доступа к этим полям. Окончательный вид модели:
public class UserModel {
String uuid;
String login;
String password;
public String getUuid() {
return uuid;
}
public void setUuid(String uuid) {
this.uuid = uuid;
}
public String getLogin() {
return login;
}
public void setLogin(String login) {
this.login = login;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
}
Создание сервисов и контроллеров
Для работы с Tarantool при обработке запросов мы воспользуемся сервисами, которые позволят нам скрыть всю логику за вызовом методов определённого класса. Будем пользоваться четырьмя основными методами:
getUserByLogin— получение информации о пользователе по его логину;createUser— создание пользователя;updateUser— обновление информации о пользователе;deleteUser— удаление пользователя по его логину.
Для описания базового сервиса создадим интерфейс, содержащий сигнатуры этих четырёх методов, а затем наследуем от него сервис, который будет содержать логику работы с Tarantool. Назовём его StorageService:
public interface StorageService {
UserModel getUserByLogin(String login);
String createUser(CreateUserRequest request);
boolean updateUser(String login, UpdateUserRequest request);
boolean deleteUser(String login);
}
Также создадим класс TarantoolStorageService, который будет наследоваться от этого интерфейса. Сперва мы должны создать конструктор этого класса, который на вход будет принимать TarantoolClient, чтобы была возможность выполнять запросы к Tarantool. Сохраним клиент в приватную переменную и добавим модификатор final:
private final TarantoolClient tarantoolClient;
public TarantoolStorageService(TarantoolClient tarantoolClient) {
this.tarantoolClient = tarantoolClient;
}
Теперь переопределим метод получения пользователя по логину. Сначала создадим переменную userTuple типа List, которая будет определена как null:
List
После инициализации пробуем выполнить у tarantoolClient метод call, результатом выполнения которого будет Future. Так как этот метод асинхронный, то чтобы получить результат его выполнения его выполнения вызываем метод get с аргументом 0. Если при вызове метода call возникает исключение, то мы его перехватываем и выводим в консоль.
try {
userTuple = (List
А если метод выполнился успешно, то создаём объект класса UserModel, заполняем все поля и возвращаем его; иначе возвращаем null.
if(userTuple != null) {
UserModel user = new UserModel();
user.setUuid((String)userTuple.get(1));
user.setLogin((String)userTuple.get(2));
user.setPassword((String)userTuple.get(3));
return user;
}
return null;
Полный код метода:
public UserModel getUserByLogin(String login) {
List
Аналогично переопределяем остальные методы, но с некоторыми изменениями. Так как логика похожа, то приведу просто полный код класса:
@Service
public class TarantoolStorageService implements StorageService{
private final TarantoolClient tarantoolClient;
public TarantoolStorageService(TarantoolClient tarantoolClient) {
this.tarantoolClient = tarantoolClient;
}
@Override
public UserModel getUserByLogin(String login) {
List
После реализации этого вспомогательного сервиса нужно создать сервисы, которые будут содержать логику аутентификации и модификации пользователя. Сервис модификации и получения информации о пользователе назовём UserService. Он достаточно прост в реализации, так как инициализируется объектом класса StorageService и вызывает методы, которые в нём определены. Поэтому просто приведу его полный код:
@Service
public class UserService {
private final StorageService storageService;
public UserService(StorageService storageService) {
this.storageService = storageService;
}
public String createUser(CreateUserRequest request) {
return this.storageService.createUser(request);
}
public boolean deleteUser(String login) {
return this.storageService.deleteUser(login);
}
public UserModel getUserByLogin(String login) {
return this.storageService.getUserByLogin(login);
}
public boolean updateUser(String login, UpdateUserRequest request) {
return this.storageService.updateUser(login, request);
}
}
Второй же сервис, который аутентифицирует пользователя, мы назовём AuthenticationService. Он также будет инициализироваться объектом класса StorageService и содержит один метод — authenticate, отвечающий за аутентификацию пользователя. Как происходит аутентификация? Метод по логину запрашивает в Tarantool данные пользователя. Затем вычисляет MD5-хеш пароля и сравнивает его с тем, что получил из Tarantool. Если совпадают, то метод возвращает токен, который для простоты является UUID пользователя, а иначе возвращает null. Полный код класса:
@Service
public class AuthenticationService {
private final StorageService storageService;
public AuthenticationService(StorageService storageService) {
this.storageService = storageService;
}
public AuthUserResponse authenticate(String login, String password) {
UserModel user = storageService.getUserByLogin(login);
if(user == null) {
return null;
}
String passHash = DigestUtils.md5DigestAsHex(password.getBytes());
if (user.getPassword().equals(passHash)) {
AuthUserResponse response = new AuthUserResponse();
response.setAuthToken(user.getUuid());
return response;
} else {
return null;
}
}
}
Теперь создадим два контроллера, которые отвечают за аутентификацию пользователя и работу с информацией о нём. Первый назовём AuthenticationController, а второй — UserController.
Начнём с AuthenticationController. Каждый контроллер инициализируется своим сервисом, поэтому первый мы инициализируем объектом класса AuthenticationService. Также наш контроллер будет содержать маппинг на конечную точку /login. Она будет парсить пришедший запрос, вызывать метод authenticate у сервиса, и на основе результата вызова вернёт либо UUID и код 200, либо код 403 (Forbidden). Полный код контроллера:
@RestController
public class AuthenticationController {
private final AuthenticationService authenticationService;
public AuthenticationController(AuthenticationService authenticationService) {
this.authenticationService = authenticationService;
}
@PostMapping(value = "/login", produces={"application/json"})
public ResponseEntity authenticate(@RequestBody AuthUserRequest request) {
String login = request.getLogin();
String password = request.getPassword();
AuthUserResponse response = this.authenticationService.authenticate(login, password);
if(response != null) {
return ResponseEntity.status(HttpStatus.OK)
.cacheControl(CacheControl.noCache())
.body(response);
} else {
return new ResponseEntity<>(HttpStatus.FORBIDDEN);
}
}
}
Второй контроллер, UserController, будет инициализироваться объектом класса UserService. Он будет содержать маппинги на конечные точки /register и /{login}. Его полный код:
@RestController
public class UserController {
private final UserService userService;
public UserController(UserService userService) {
this.userService = userService;
}
@PostMapping(value = "/register", produces={"application/json"})
public ResponseEntity createUser(
@RequestBody CreateUserRequest request) {
String login = this.userService.createUser(request);
if(login != null) {
CreateUserResponse response = new CreateUserResponse();
response.setLogin(login);
return ResponseEntity.status(HttpStatus.OK)
.cacheControl(CacheControl.noCache())
.body(response);
} else {
return new ResponseEntity<>(HttpStatus.BAD_REQUEST);
}
}
@GetMapping(value = "/{login}", produces={"application/json"})
public ResponseEntity getUserInfo(
@PathVariable("login") String login) {
UserModel model = this.userService.getUserByLogin(login);
if(model != null) {
GetUserInfoResponse response = new GetUserInfoResponse();
response.setUuid(model.getUuid());
response.setLogin(model.getLogin());
response.setPassword(model.getPassword());
return ResponseEntity.status(HttpStatus.OK)
.cacheControl(CacheControl.noCache())
.body(response);
} else {
return new ResponseEntity<>(HttpStatus.NOT_FOUND);
}
}
@PutMapping(value = "/{login}", produces={"application/json"})
public ResponseEntity updateUser(
@PathVariable("login") String login,
@RequestBody UpdateUserRequest request) {
boolean updated = this.userService.updateUser(login, request);
if(updated) {
return ResponseEntity.status(HttpStatus.OK)
.cacheControl(CacheControl.noCache())
.build();
} else {
return new ResponseEntity<>(HttpStatus.NOT_FOUND);
}
}
@DeleteMapping(value = "/{login}", produces={"application/json"})
public ResponseEntity deleteUser(
@PathVariable("login") String login) {
boolean deleted = this.userService.deleteUser(login);
if(deleted) {
return ResponseEntity.status(HttpStatus.OK)
.cacheControl(CacheControl.noCache())
.build();
} else {
return new ResponseEntity<>(HttpStatus.NOT_FOUND);
}
}
}
На этом мы закончили разработку нашего Java-приложения. Осталось его собрать. Делается это командой:
$ mvn clean package
После сборки его можно запустить командой:
$ java -jar ./target/authentication-example-1.0-SNAPSHOT.jar
Ура, мы закончили разработку нашего сервиса! Полный его код лежит здесь.
Итого
- Установили коннектор.
- Настроили подключение к кластеру.
- Разработали API.
- Создали контроллеры и сервисы.
- Собрали приложение.
Осталось протестировать сервис.
Проверка работоспособности сервиса
Проверим корректность обработки каждого из запросов. Для этого воспользуемся Postman. Работать будем с пользователем, у которого следующие логин
