Разработка: прототип игры Wordle в ProtoPie
Привет! На связи арт-директор IceRock Женя Гребенщиков. Не так давно прочитал новость, что Times купила права на игру Wordle. Посмотрел, что за игра, и решил попробовать сделать ее прототип в ProtoPie. Рассказываю, что получилось.
Wordle — браузерная игра в слова, в которой игроки должны угадать загаданное слово методом подбора букв. Каждый день программа загадывает слово из пяти букв, и игроки подбирают верный вариант. После каждого предположения буквы выделяются зеленым, желтым или серым цветом: зеленый означает, что буква находится на верной позиции, желтый — что буква есть в слове, но на другом месте, и серый — что буквы в слове нет. Так, методом подбора, разгадывается полное слово.
Когда начал создавать прототип, понял, что раньше никто не использовал в ProtoPie что-то похожее на базы данных. Самое важное, когда пришла какая-то идея, — подумать о концепции и возможностях. Точно ли получится сделать такую игру в ProtoPie? Обычно я мысленно перебираю весь функционал и абстрактно придумываю те или иные решения, которые буду использовать.
Итак, программа загадывает слово, значит, должна быть база данных этих слов. Как сделать базу данных слов в ProtoPie? Я уже делал много таких штук, и обычно довольно сложно объяснить на пальцах, как оно работает. Постараюсь как можно подробнее все описать.
В начале придумал, что будет под капотом игры
За основу взял простую базу данных со списком слов. Но чтобы выбрать случайное слово, надо каждому слову присвоить айдишник. Поэтому формат базы сделал idWord и выглядеть она будет примерно так:

Начинаем тестировать: берем рандомное число, например 12. Ищем через indexof(text,"12«), на какой позиции оно находится. Например, это 67-й символ. Смотрим в базу и видим там »12БАРЖА». Переносим слово из базы в переменную.
Для начала функцией right стираем все, что было до нужного слова. Наша «база данных» — это, по сути, очень длинная строка, которая начинается с символа »1» и заканчивается последней буквой последнего слова. Поэтому мы можем использовать функции работы со строками. С помощью функции right мы сможем «обрезать» строку до нужного слова, а функцией left — после этого слова. Тем самым мы достанем из базы нужное нам слово.
Теперь нам надо понять, сколько символов надо оставить «справа» функцией right. Предыдущая функция indexOf дала нам информацию, что номер нужного слова находится с 67-го символа. Чтобы достать слово, надо убрать эти 67 символов и еще 2 символа номера 12 (»12БАРЖА»). Так как номер у нас может быть и однозначный, и двух-трех-четырехзначный, то используем функцию length для определения количества символов в этом числе. В текущем виде нам надо убрать 69 символов. Следовательно, чтобы понять, сколько оставить, надо от значения длины всей базы данных отнять 69.
Для решения задачи можно использовать код:
right(riddle_bd.text,(length(riddle_bd.text) - (length(rnd_num)) - (indexOf(riddle_bd.text,rnd_num))))
Затем от всего этого нужно отрезать функцией left пять символов, так как слова у нас состоят из пяти букв. Таким образом мы получили рандомное слово из базы.
Кстати, выбранное слово из базы надо будет потом удалить, чтобы оно не повторялось в следующих играх. Делаем это функцией replace. Плюс делаем проверку: если рандом выдаст число, которого в базе нет, повторяем рандом.
Придумал концепцию игрового процесса
С базой разобрались — теперь у нас есть первое рандомное слово для игры. Например, «ВИРУС». В игре пользователь вводит свое слово, и нужно показать, какие буквы совпали и какие — не на том месте. Также нужно добавить проверку, есть ли слово в базе.
Пользователь вводит слово «РЕБУС». Буква «Р» есть, но в другом месте. Буква «У» и буква «С» на своих местах.
Как сделать такую проверку? Нужно провести пять проверок для каждой буквы введенного слова. Самый простой способ — помещать каждую букву в отдельное поле ввода, чтобы было проще производить с ней какие-либо манипуляции. Однако надо это сделать так, чтобы игрок не заметил, что это пять полей ввода, и ему казалось, что поле ввода одно. Делитесь идеями, как это можно реализовать, в комментариях.
Алгоритм поиска совпадений должен работать так:
Берем первую букву — «Р», производим поиск в слове «ВИРУС». Буква найдена, ее позиция — 3, а в введенном слове «РЕБУС» она первая, значит, красим букву «Р» в желтый цвет.
Берем вторую букву — «Е», ищем в слове «ВИРУС». Буква не найдена — красим в серый.
То же самое с третьей буквой — «Б».
Берем четвертую букву — «У». Буква найдена, и ее позиция — 4. Красим в зеленый цвет, потому что позиции буквы совпадают в обоих словах.
Последняя буква — «С» — тоже совпадает по позициям — красим зеленым.
Теперь просим игрока ввести второе слово. Он вводит «ПАРУС» — показываем, что буквы «РУС» на своих местах.
Игрок вводит слово «ВИРУС» — все буквы на своих местах. Ура!
Перешел к созданию игры
Концептуально проблем не обнаружилось — переходим к созданию игры. Процесс я разбил на шаги для наглядности.
Шаг 1. Создал базу данных. Для того чтобы подготовить базу данных, я взял гугл-табличку. Это довольно простой и удобный инструмент для работы с небольшими базами данных. Надеюсь, когда-нибудь ProtoPie добавит нативную синхронизацию с такими таблицами.
Во второй столбик перенес список слов из интернета. Первый оставил пустым, чтобы позже написать там айдишники слов. Получилось 6266 слов — для тестов слов оказалось слишком много. Поэтому сделал копию страницы и оставил примерно по 20 слов на каждую букву. Получилось 279 слов — теперь сойдет.
Потом, используя функционал гугл-таблиц, сначала все слова сделал большими буквами =UPPER() (потому что поиск букв регистрозависимый). Далее я перемешал слова в рандомном порядке таким образом: добавил в третью колонку случайное число =RAND() и отсортировал табличку по возрастанию этих случайных чисел.
Затем в первую колонку записал номера по порядку от 1 до 279. Чтобы перенести базу в ProtoPie, я скопировал первые два столбика в «Блокнот» и функцией «Заменить» заменил табуляцию между числом и словом на пустоту. В итоге получил нужный мне формат базы данных — idWord:
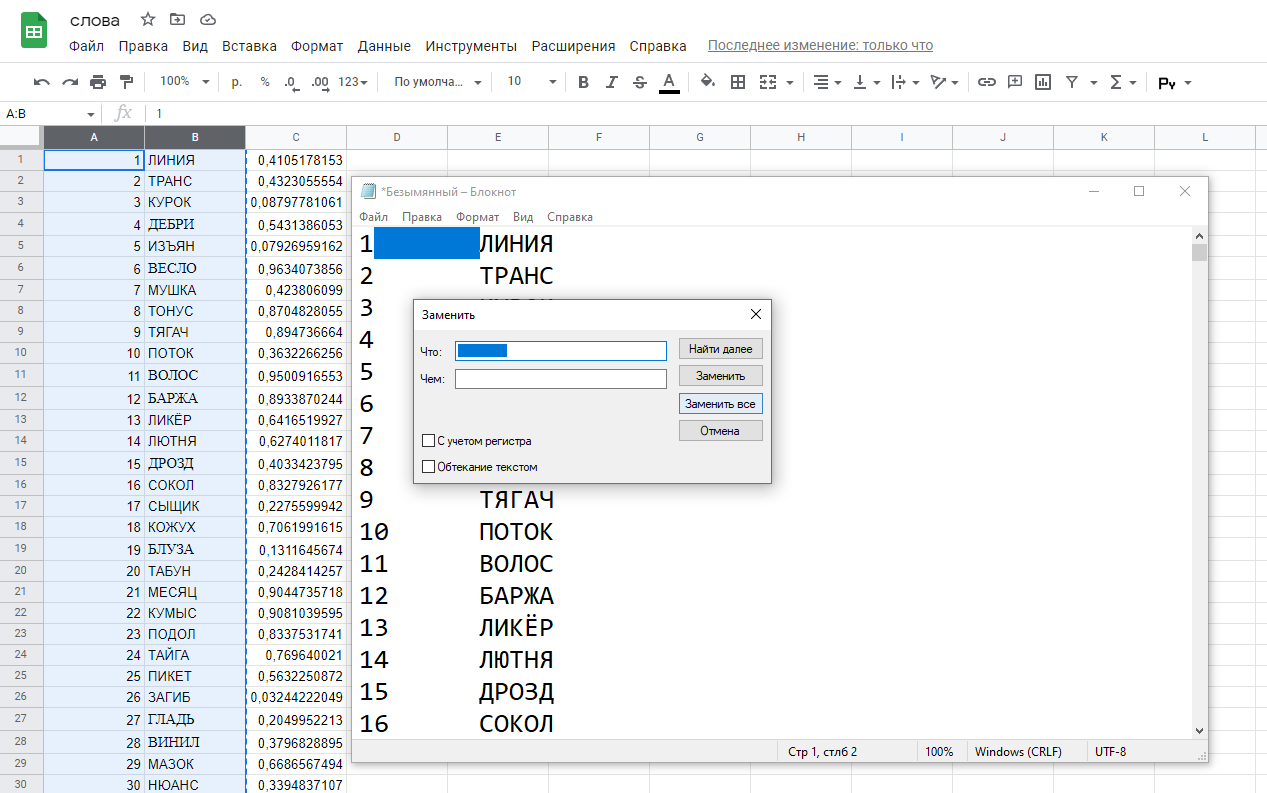
Шаг 2. В ProtoPie создал текстовый слой bd, куда вставил нашу базу данных. Также создал числовую переменную для случайного числа rnd_num, текстовую переменную для случайного слова rnd_word и переменную lang, чтобы в будущем сделать игру на разных языках.
Шаг 3. Создал промежуточную версию прототипа. Для начала решил сделать простой прототип, который по нажатию кнопки выдает случайное слово из базы данных. Процесс занимает пять шагов:
Добавляем на слой текст-кнопку, вешаем триггер
Tapи присваиваем переменнойrnd_numслучайное целое число от 1 до 279, так как моя тестовая база данных содержит 279 слов:Assign rnd_num randomInt(1,279).Детектим изменение переменной
rnd_numи сразу вешаем проверку на будущее: если число не найдено:Condition indexOf(`bd`.text,rnd_num) =-1, тогда повторяем предыдущее действие:Assign rnd_num randomInt(1,279).Функция
indexOf(`bd`.text,rnd_num)показывает номер символа, после которого идет искомое число.Если же число найдено в базе данных:
Condition indexOf(`bd`.text,rnd_num) ≥ 0, то записываем в переменнуюrnd_wordслучайное слово тем способом, концепцию которого я описывал в начале статьи:Берем все символы базы данных, кроме тех, которые находятся до искомого числа. То есть, используя функцию
right, обрезаем начало базы данных:right(`bd`.text,(length(`bd`.text)-(indexOf(`bd`.text,rnd_num))).Однако надо не забыть вычесть еще длину самого рандомного числа, чтобы у нас было слово «РЕБУС», а не »123РЕБУС», поэтому добавляем в формулу еще
(length(rnd_num)). Получается:right(`bd`.text,(length(`bd`.text)-(length(rnd_num))-(indexOf(`bd`.text,rnd_num)))).Эта функция отрезает только левую часть базы данных. Остается от нее отрезать пять символов нашего слова, и оно будет у нас:
left((right(`bd`.text,(length(`bd`.text)-(length(rnd_num))-(indexOf(`bd`.text,rnd_num))))),5).Все эти формулы выглядят довольно сложно, поэтому постарался все подробно изложить. Однако если у вас остались вопросы — с радостью отвечу на них в комментариях.
Присваиваем переменной
rnd_wordконструкцию, выведенную выше. Вот что получилось:
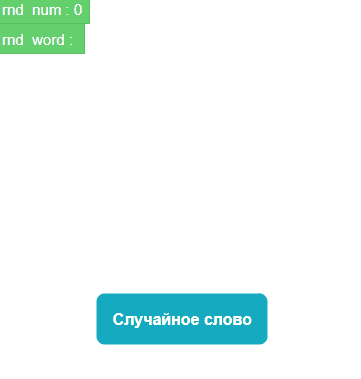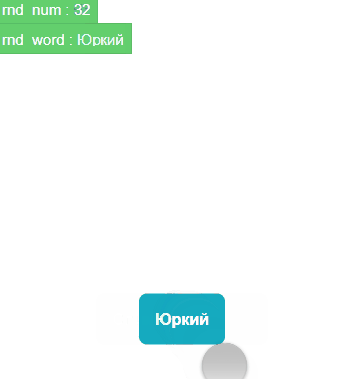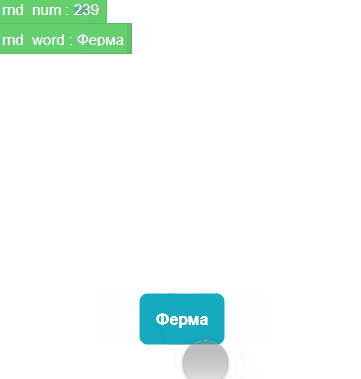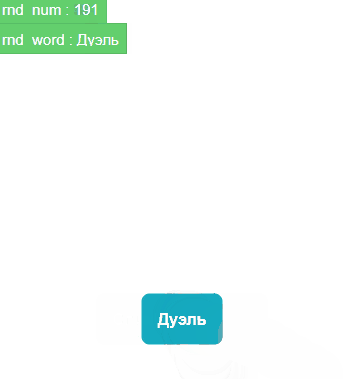
Промежуточная версия прототипа
Шаг 4. Сделал игровое поле. Слово загадывать мы умеем, теперь надо сделать игровое поле:
Клавиатура будет всегда открыта, поэтому сразу отделяю часть экрана под нее — это 294 px для iPhone X.
По правилам оригинальной игры у игрока есть шесть попыток угадать слово, поэтому нужно сделать шесть текстовых полей для предыдущих попыток и одно активное для текущей попытки. Эти поля должны выглядеть одинаково, примерно вот так:

Следующая проблема — разбить слово на буквы. Это нужно, чтобы потом подсветить правильные буквы зеленым и те, которые на других местах, — желтым.
Сначала я решил разбить слово по буквам, используя функции
leftиright:Для первой буквы — просто
left(word,1).Для второй буквы берем ту же одну букву слева, но уже от четырех букв:
left((right(word,4)),1).Для третьей, четвертой буквы можно сделать соответственно
left((right(word,3)),1)иleft((right(word,2)),1).Для пятой буквы достаточно
right(word,1).
Но тут сталкиваемся с проблемой, что введенное слово не всегда состоит из пяти букв. Вот что я имею в виду: пользователь вводит слово «ВИРУС» по буквам. Ввел «ВИ» — получилось слово из двух букв, следовательно, используя функции выше, первая буква («В») найдется верно, вторая («И») тоже, но так как в слове нет третьей, четвертой и пятой букв, то все функции будут выводить вторую букву вместо третьей, четвертой и пятой. Вот как эта проблема выглядит в прототипе.

Существует множество способов решить эту проблему. Да и в целом эту задачу можно сделать по-другому… Я решил сделать из пяти полей компонент, в который буду слать вводимое слово. В компоненте получаю вводимый текст и разбиваю его на буквы, проверяя длину текста. Получается шесть проверок: когда нет символов и когда один, два, три, четыре или пять символов.
Добавляю красивые анимации для ввода букв и подсветку текущей буквы. Пока проверку на совпадения делать не буду: для начала надо проверить, как работает ввод слов.
На главной сцене дублирую пять раз компонент и строю «игровое поле»:
Нужно добавить переменную
try, которая будет отслеживать количество попыток пользователя. В начале игры она равна 1. Когда игрок ввел первое слово, равна 2 и так далее.Добавляем триггер
Return(нажатие Enter на клавиатуре, подтверждение ввода) и проверяем введенное слово на наличие в БД с помощью функцииindexOf(bd.text,Input 1.text). Если значение формулы =-1, значит такого слова нет в словаре — выводим сообщение об ошибке.Если
indexOf(bd.text,Input 1.text)больше 0, значит слово есть в словаре и всё в порядке. Заодно проверим, что слово состоит из пяти символов. Изменяем значение переменнойtryна следующую попытку.Добавим переменную
successи будем ее проверять. Как только пользователь угадает слово, она станет =1. Но это уже другая история :)При
try=7делаемjumpна страницу Game Over.Для каждого значения переменной
tryвыбираем свой компонент для попытки.

На этом шаге прототип выглядит так:
Ссылка на прототип
В прототипе можно вводить слова, которые есть в базе данных, попробовать поиграть и потратить все попытки :)
Шаг 5. Добавил две проверки, которые улучшат UX. В первой проверке убрал букву «Ё». В моей базе данных нет слов на букву «Ё», и там, где она должна быть, используется буква «Е». Поэтому просто функцией replace заменим в поле ввода «Ё» на «Е».

Вторая проверка — для пробела: это большая кнопка, которую случайно можно нажать. Мы просто ее отключим: используем ту же функцию replace и меняем пробел (» ») на ничего (»). Можно еще сделать аналогично с цифрами, но пока влом :)

Шаг 6. Теперь надо сделать так называемый вин кондишен.
Для начала сделал примитивную проверку: если введенное слово равно загаданному слову — победа! Для этого просто сравниваем две переменные.
Теперь можно добавить проверку букв:
Сначала происходит проверка на правильность расположения букв, чтобы отметить их зеленым цветом.
Затем проверка на наличие буквы в слове, чтобы отметить желтым. Для этого берем первую букву загаданного слова с помощью формулы, которой разбивали слово на буквы выше:
left(word,1). Если буква совпадает, красим в зеленый, если нет — переходим к следующей.Так делаем с каждой буквой по пять раз: первую букву загаданного слова сверяем с каждой буквой введенного слова.
Если же обе проверки не принесли результата, оставляем букву серой.
Заметки во время тестирования игры
Заметка 1. Тестируя приложение, я подумал, что базу данных лучше сделать «вверх ногами», чтобы проще было добавлять новые слова, открывая текстовый блок и дописывая значение. Например,»2130ЗЕБРА». Тогда не нужно будет скролить в самый низ. Вот почему:
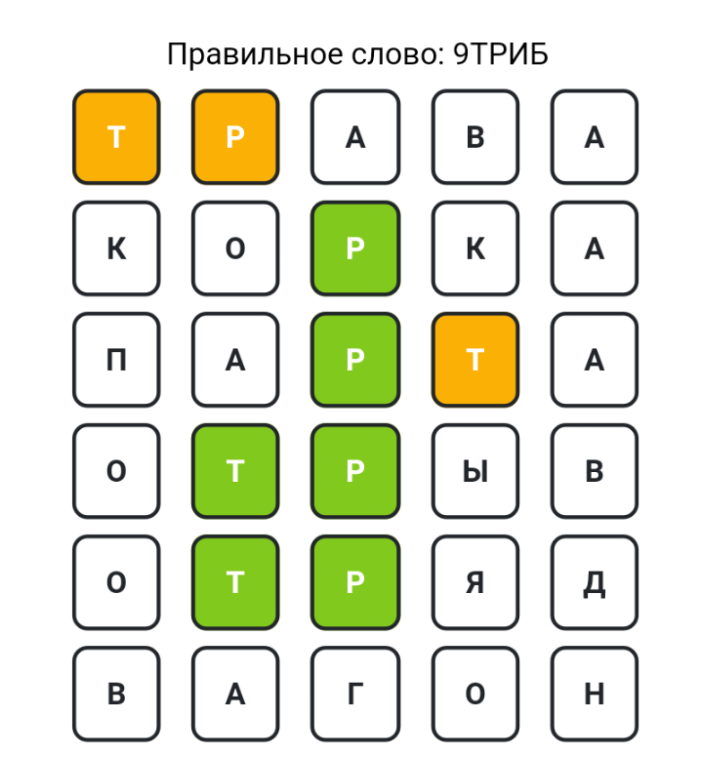
У меня рандомится айдишник, и потом берется слово под этим айдишником. База у меня записана «вверх ногами»: последний айдишник в самом верху, так мне было удобнее добавлять слова. Ну и сгенерился айдишник 211, пошел поиск слова, и он нашел после айдишника 2120 айдишник 2119, и взял 211 и дальше слово из пяти букв.
По факту это слово »2119ТРИБА» (это что-то из биологии), но из-за бага программа загадала слово »9ТРИБ».
Я вернул базу в прежний вид, и баг исчез.
Заметка 2. Узнал много новых слов. Пришла в голову идея добавить функцию «Посмотреть значение слова».
Для этого добавил триггер
Longtap, в который добавил действиеLink.В параметр действия написал ссылку на викисловрь с переменной-словом.
Теперь можно лонгтапнуть на любом слове, и откроется браузер с значением слова.
Заметка 3. Во время тестов словил вот такой баг:

Баг в третьем и пятом слове. Суть в том, что вначале слова проверяется буква «А» и подсвечивается желтым, потому что она не на верном месте. Следом проверяется последняя «А». Она на своем месте, и поэтому она зеленая. Пользователь думает что в слове две буквы «А», но это всего лишь баг.
Исправил я его таким образом: после закрашивания буквы зеленым заменял проверенную букву на цифру 0. Таким образом, при второй проверке, когда происходит закрашивание желтых клеток, система ее уже не проверяет.
Заметка 4. «Причесал» UI, добавил анимацию при неправильном вводе слова в компоненте:

Заметка 5. «Поиграл» с цветами и формами, придав игре более приятный вид.
Сейчас игра выглядит так:
Итоги и планы на будущее
Игра получилась интересная и с большим потенциалом для развития. Кстати, я уже реализовал большую часть задуманных фич. Вот их список:
Расширил базу слов для игры. Уже нашел базу из 6000 русских слов и базу из 13000 английских слов.
Добавил свитч языка, чтобы можно было выбрать, какие слова будут загаданы. Кстати, это неплохая тренировка языка.
Сделал две базы данных для каждого языка. Первая — для слов, которые будет загадывать система, вторая — для слов, которые будет вводить пользователь. В первой базе будут более популярные слова. Нужно это для того, чтобы программа не загадывала редкие, малоиспользуемые, слова. Однако если такие слова введет пользователь, они пройдут проверку. Например, программа загадает слово «МИНАИ» — это слово никто не отгадает (это, кстати, тип художественной керамики). Используя несколько баз данных, можно менять и сложность игры. Чем сложнее игра, тем более редкие слова будет загадывать программа.
Добавил локальную статистику игр. Показывает, с какого раза игрок угадывает слово.
Поэтому в следующей статье я расскажу, как изменил базу слов и разбил ее на разные языки и как сделал статистику игр. Сейчас я планирую улучшить игру, добавив в нее темную тему и общий рейтинг. Об этом также напишу в следующей статье. Подписывайте на наш блог, чтобы не пропустить продолжение.
Пишите о ваших идеях, как можно улучшить или дополнить игру! И делитесь своими успехами в игре: будем рады посмотреть скриншоты вашей статистики :)
