Разработка платформы управления данными. Доклад Яндекса
Начать рассказ проще всего с вопроса, что вообще такое DMP, потому что каждый под этим может понимать что-то свое: нет устоявшихся паттернов. Расскажу, как мы вообще пришли к текущему состоянию, покажу несколько примеров использования нашей платформы для Greenplum, для Spark, и постараюсь успеть подвести итоги.
Есть такая большая страшная картинка о том, что мы вообще делаем:
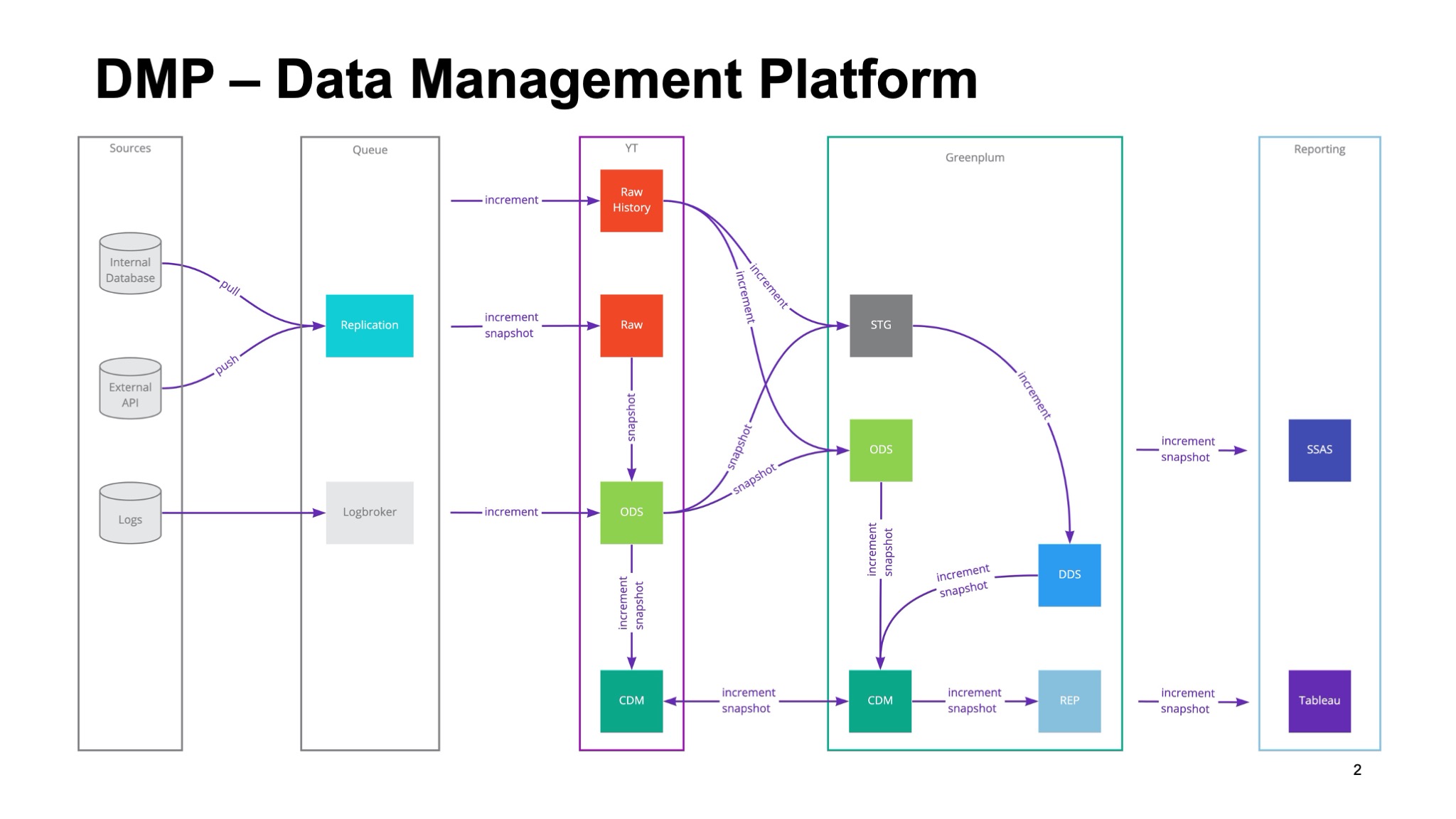
Задача платформы — донести данные от разных источников. Их у нас сотни — и порядка 50 уникальных источников. Это могут быть как базы микросервисов, которых несколько сотен, различные облачные сервисы (Zendesk, AMO CRM, Salesforce и так далее — большое разнообразие), инфраструктура, необходимая, чтобы поставлять инкременты и в дальнейшем обрабатывать данные. Все данные разложены во множество слоев. На слайде много аббревиатур из трех и более букв. Для начала я постараюсь раскрыть смысл этой картинки. Дальше перейдем непосредственно к тому, из чего состоит платформа, потому что это некий необходимый контекст.
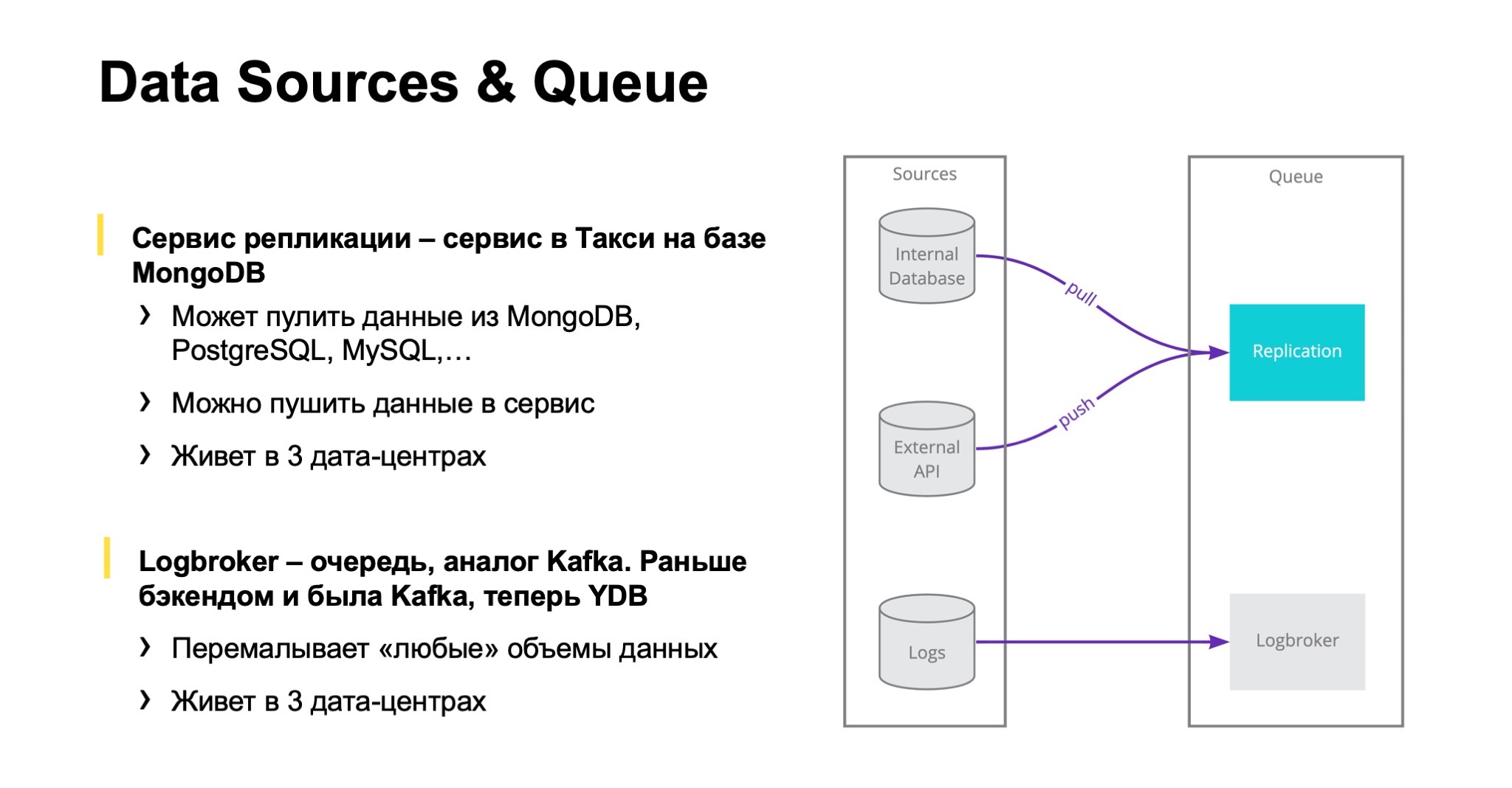
С чего у нас начинается путь данных? Путь данных от источника к DMP или к нашим хранилищам либо начинается с сервиса репликации, либо данные идут в хранилище через Logbroker.
Сервис репликации был разработан внутри Яндекс.Такси, под капотом у него MongoDB. Его основная задача — подключаться к различным базам микросервисов Такси, Еды и Лавки, пулить оттуда инкременты и поставлять их в несколько разных источников. Также в него можно пушить данные — например, чтобы не вести в сервис знания о каждом втором или третьем API, с которым нужно интегрироваться и забрать из него данные.
Сервис развернут в трех дата-центрах и, соответственно, переживает отказ в случае, если один или несколько дата-центров отключаются. В Яндексе в принципе есть практика учений, во время которых ДЦ отключают.
Другой путь данных в хранилище — Logbroker, внутрияндексовый аналог Kafka. Изначально это и была Kafka. Сейчас под капотом находится Yandex Database. Он готов к любым объемам информации, потому что через эту систему проходят, например, логи от Яндекс.Метрики — огромного сервиса, который тоже живет в трех дата-центрах. Мы можем из Logbroker читать данные и писать в несколько источников.
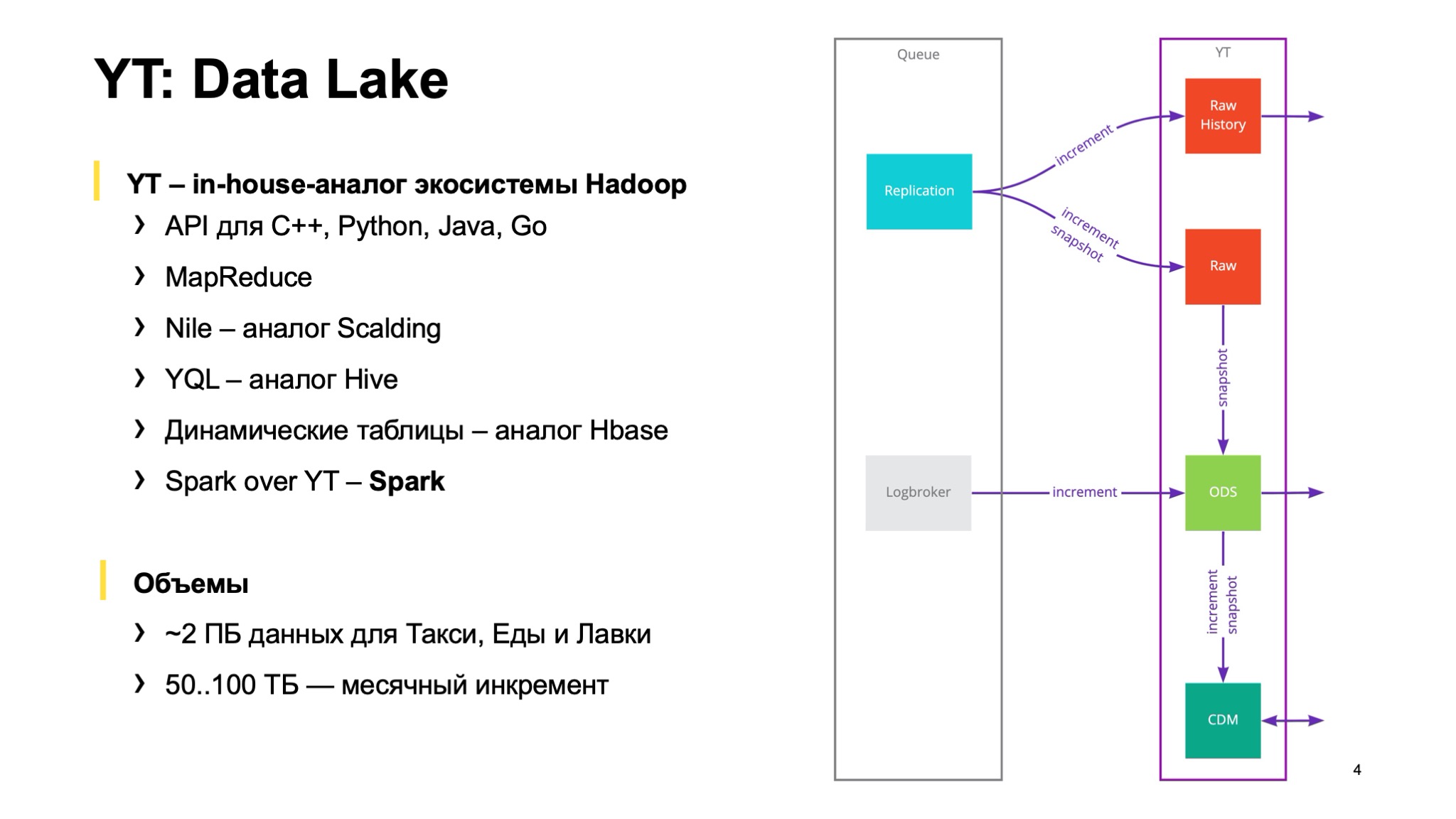
Далее у нас развернут Data Lake. Data Lake построен на in-house-аналоге экосистемы Hadoop, который в чем-то, может быть, даже круче Hadoop, а в чем-то, может быть, нет. Есть много инструментов, которые повторяют экосистему. Например, есть API для C++, Python, Java, Go, возможность писать MapReduce. Есть фреймворк Nile, про него на Хабре был доклад, он очень похож на Scalding. Есть YQL, который можно считать аналогом Hive. Есть аналог HBase. Также как раз внутри нашей команды мы смогли прикрутить Spark к YT и начать им пользоваться. Текущий объем нашего Data Lake — порядка 2 ПБ данных, ежемесячно мы прирастаем сейчас примерно по 100 ТБ — иногда больше, иногда меньше.
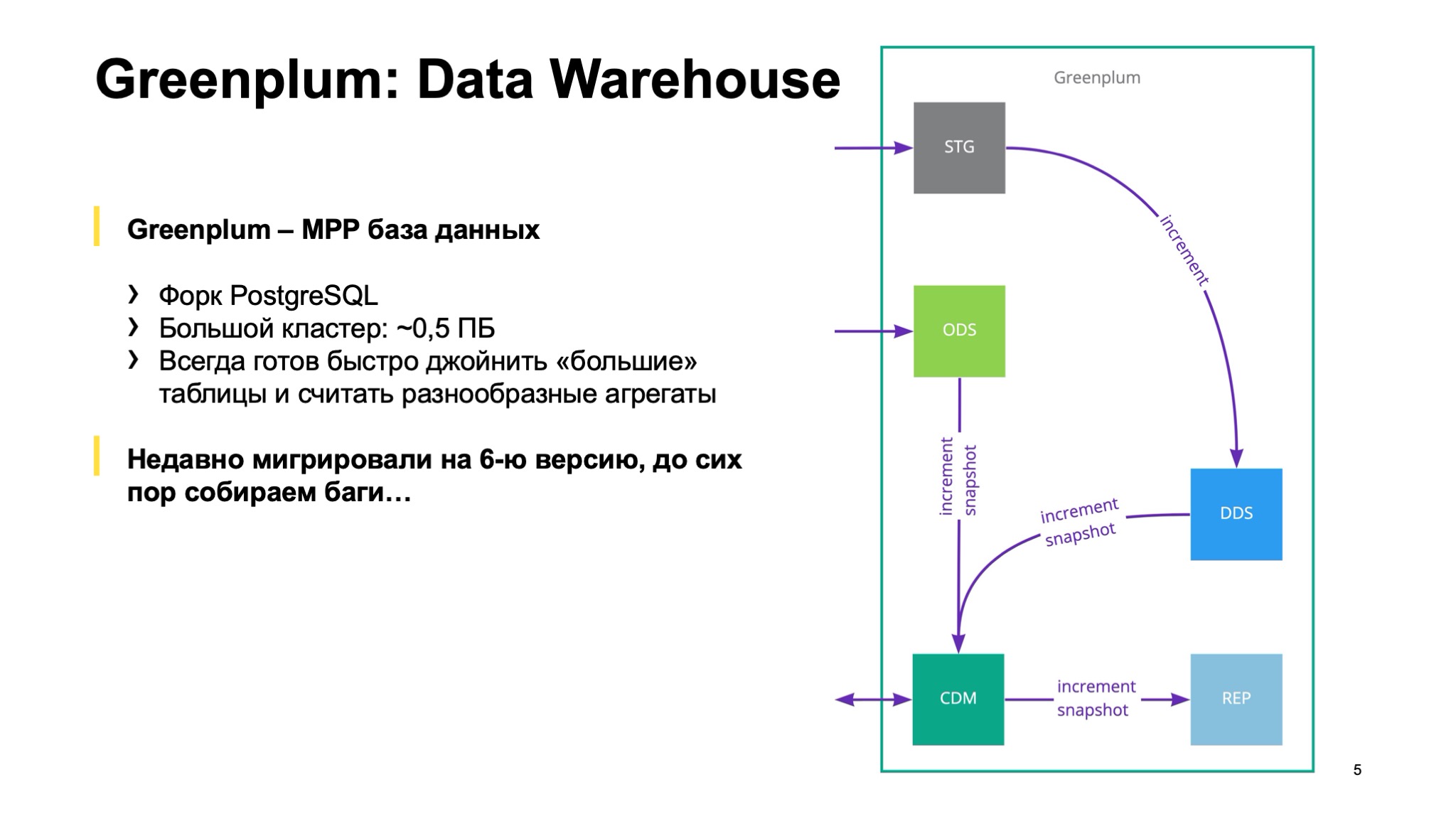
Основной процессинг, основное место для расчета витрин — это Greenplum. (…) Это MPP-база данных, форк PostgreSQL. Сейчас у нас есть кластер, в котором эффективное пространство — порядка 0,5 ПБ.
Из веселого: недавно мы мигрировали на шестую версию. Дошли уже до версии 6.12.1, но до сих пор, к сожалению, собираем ее баги. Такое тоже бывает. Переход на пятую версию был гладким. Мы перешли буквально на 5.1 или на 5.2, и практически сразу все заработало. С шестой, к сожалению, так не получилось.
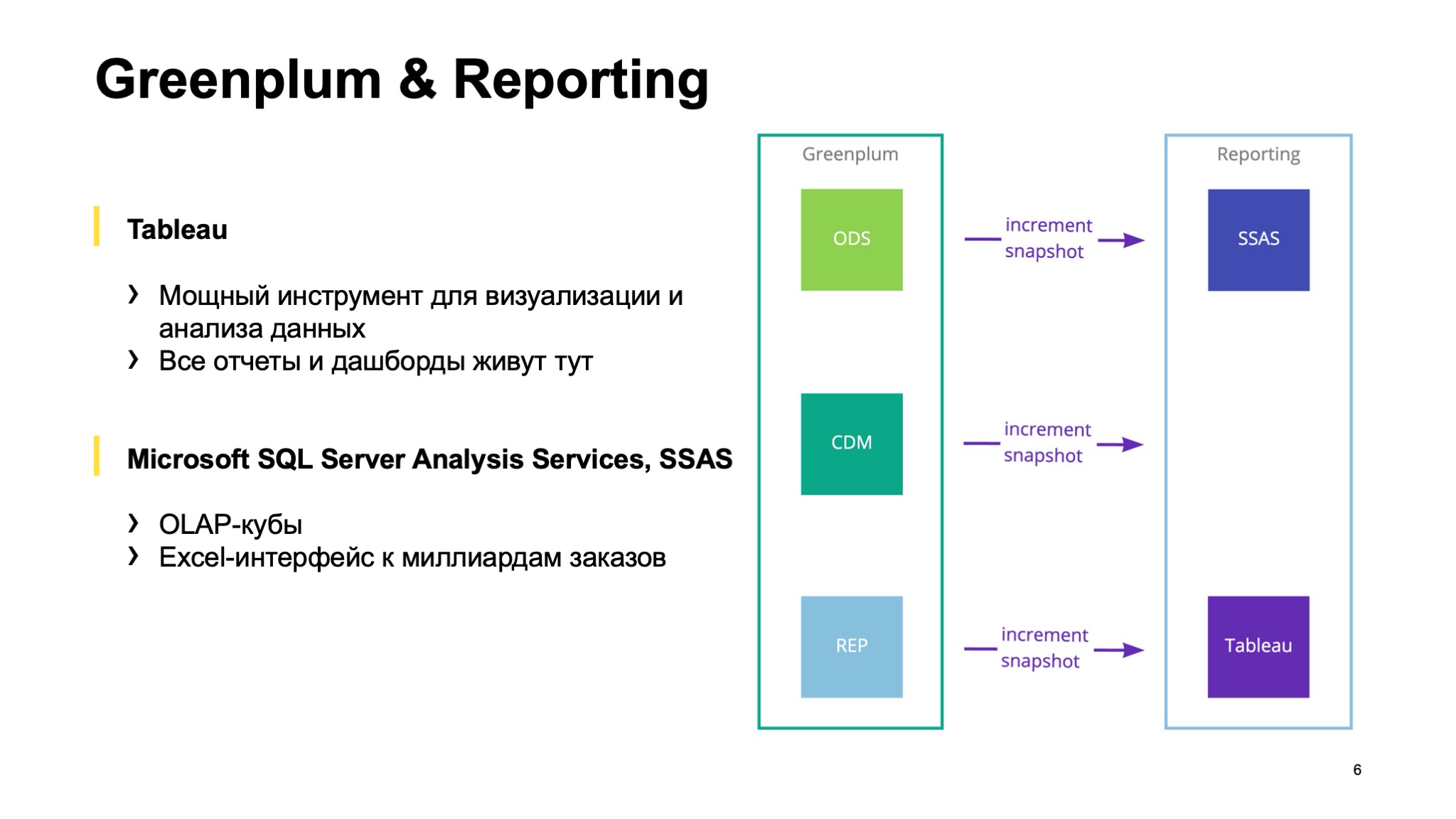
Почему у нас используется Greenplum? Потому что с ним хорошо интегрируются стандартные BI-инструменты. В нашем случае это Tableau и Microsoft Analytical Services: SSAS, OLAP-кубы. С помощью OLAP-кубов мы получаем ситуацию, когда множество менеджеров могут работать в своем привычном инструменте — Excel, но при этом под капотом подключаться, например, к огромной витрине по всем заказам Такси и работать с ней, как будто это сводная таблица, не думая о том, что под капотом.
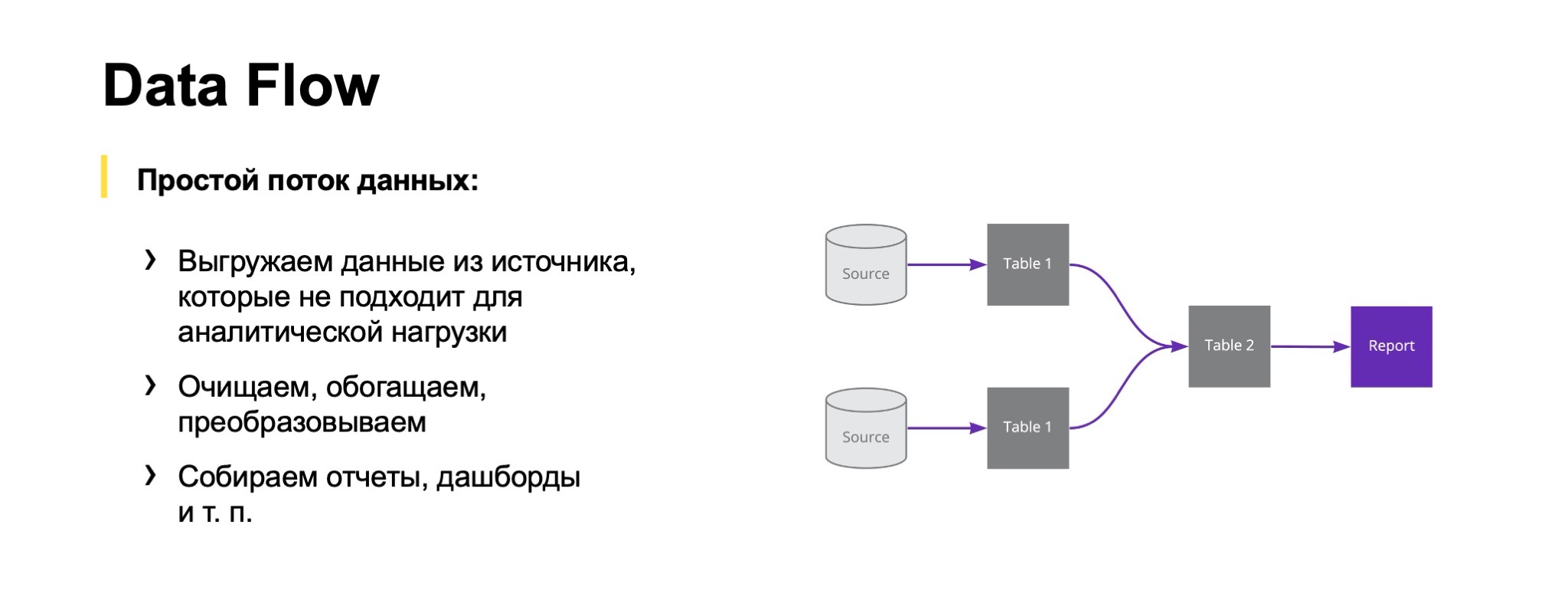
Можно сделать небольшой шаг назад и подумать:, а зачем так сложно, зачем так много систем, когда, казалось бы, нужен простой Data Flow: взяли данные из нескольких источников, получили несколько таблиц у себя в хранилище, как-то их поджойнили, поагрегировали и получили все нужные витрины и отчеты.
Так можно делать до определенного момента, пока данных и источников не становится очень много и пока ты не начинаешь понимать, что тебе хочется стандартизировать процессы. Потому что каждый дата-инженер может пытаться изобрести собственный велосипед под задачу, которую уже решил кто-то другой, сидящий рядышком в его команде.
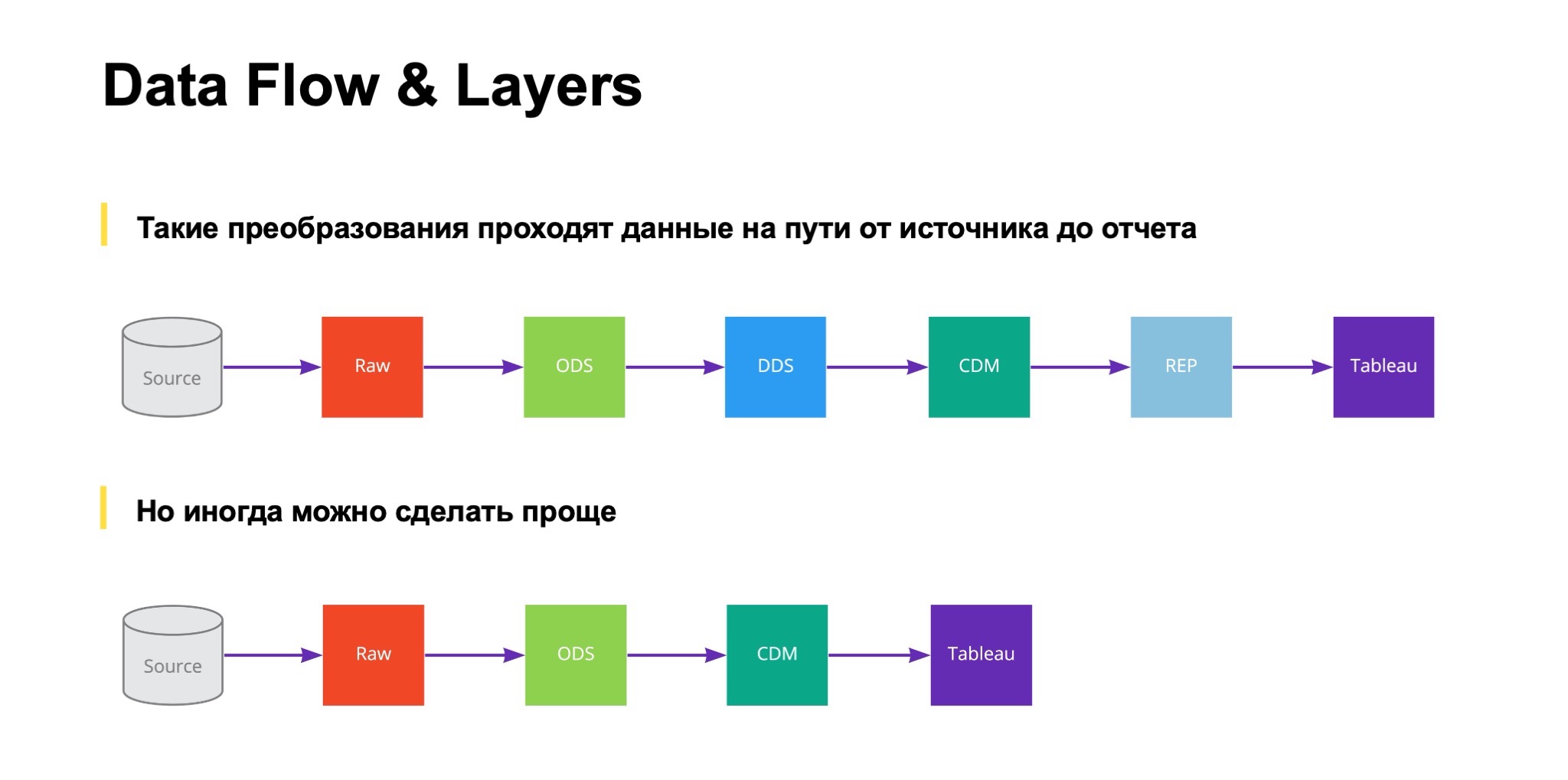
Процесс обработки данных выглядит так, он большой и страшный. Получается семь квадратиков, включая источник, на пути к BI-системам.
Но иногда мы делаем и несколько проще. Сейчас я попробую рассказать, в чем суть каждого слоя, преобразования, в чем как раз и заключается смысл слова «проще» на предыдущем слайде.

Итак, первый слой — это сырые данные. Сырые данные у нас хранятся исключительно в YT, в нашем Data Lake, и хранятся они в достаточно простом формате. То есть у нас есть идентификатор и документик Yson. И в них мы записываем данные так, как они есть на источнике, ровно в том же формате.
Raw History — по сути тот же самый сырой слой, но немножко с другим форматом. В ключ добавляется дата изменения сущности, и мы получаем change log в сыром виде, на основании которого мы можем потом делать, например, исторический пересчет, если поняли, что где-то произошел баг, проблема. И хочется взять всё как было, не трогая источник, перезагрузить к себе, в том числе не теряя изменений, которые происходили с важными сущностями. Это особенно важно, когда мы говорим о справочниках или о важных показателях.

Следующее преобразование — это ODS, Operational Data Store, наши оперативные данные, или, как мы для себя определили, наш взгляд, взгляд дата-инженерной команды на домен источника. Мы смотрим на данные источника, приводим их к стандартному именованию, делаем первичный data quality, стараемся немного нормализовывать данные. Мы не допускаем на уровне ODS сложных вложенных структур, потому что дальше всегда хотим грузить это в Greenplum, поэтому разрешаем только одноуровневые списки и словари.
Соответственно, из одного Raw, особенно когда бэкендом, источником для Raw выступает MongoDB, может получиться множество ODS-таблиц.
Staging в Greenplum — это, очевидно, промежуточный слой, который используется для загрузки данных в DDS. Почему мы его не выносим отдельно? Потому что его структура полностью повторяет ODS, и для его построения применяется то же самое преобразование.

Мои коллеги рассказывали про DDS — о том, как устроен детальный слой, и о нашем видении доменной модели бизнеса. Его внутреннее устройство достаточно сложное. В нем данные консолидируются из разных источников, нормализуются вплоть до шестой нормальной формы. Здесь строятся суррогаты, хранится история изменений по атрибутам. Методология, о которой рассказали ребята, — это некий гибрид Anchor modeling и Data Vault, который мы назвали highly Normalized hybrid Model, hNhM.

Дальше у нас есть слой витрин и слой отчетов. Витрины — это денормализованные большие и плоские таблицы, которые решают типовые задачи пользователей, скажем, по каким-нибудь доменам. Например, есть набор витрин для финансов, для саппорта, по водителям, паркам или ресторанам в Еде, по складам в Лавке, то есть это какие-то части бизнеса.
Отчеты — это уже конкретные агрегаты, которые могут быть необходимы, чтобы всё красиво и быстро отрисовывалось в Tableau на дашборде.
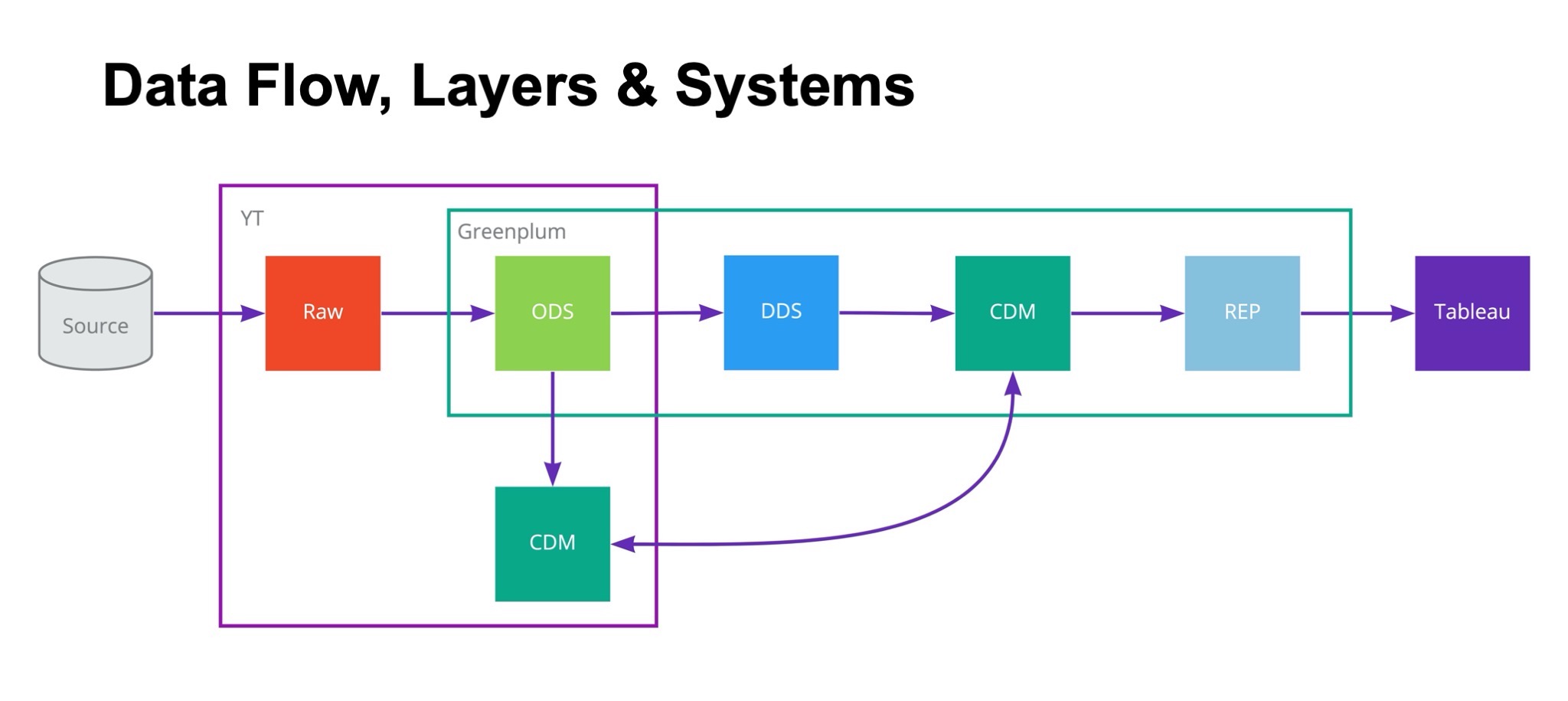
Что тут важно знать? Строительство DDS в нашем понимании требует определенных когнитивных усилий, построения доменной модели. Нужно взглянуть на мир не так, как на него смотрят, например, бэкенд или какие-нибудь системы, и пытаться это все склеить, объединить. В некоторых случаях это может быть сложно. А бизнес всегда хочет задачу не завтра, не послезавтра, а вчера. Поэтому часто приходится делать витрины поверх ODS-слоя. Мы это, наверное, не считаем большой проблемой, потому что это часто простой и быстрый способ донести или принести ценность бизнесу.
Многие вещи у нас нацелены на то, чтобы аналитику было удобно работать, делать разные adhocs. Поэтому мы дублируем много данных между YT и Greenplum, в Greenplum не льём всё. Например, условные логи от Метрики мы в Greenplum не льём. По крайней мере в сыром виде уж точно. Выжимки — да, можем лить, но сырые логи — нет. Их слишком много. Диск в Greenplum — это дорого, и его странно тратить под такие вещи.
Поэтому мы стараемся на YT в том числе поддерживать все данные, которые могут быть полезны аналитику, кроме DDS, потому что его структура совершенно не подходит для этого.
Формат Raw тоже был выбран не просто так, а потому что аналог Hive в Яндексе — YQL — умеет работать с Yson нативно. И даже когда мы просто в Raw свалили данные в виде большого документа-словаря, аналитик может сразу в YQL написать к данным запрос, и делать эдхоки, особенно с учетом того, что формат Raw не требует от разработчика практически ничего. Нужно знать только первичный ключ и дату обновления, чтобы правильно захватывать инкременты с источника. Есть Raw, и с ним уже могут работать аналитики.
Каждый следующий слой, привносит в данные какую-то ценность и упрощает их использование и жизнь аналитика.
Еще на картинке есть страшная стрелочка от CDM к CDM. Она не означает цикл, просто некоторые витрины выгоднее считать на YQL. Потому что на YT есть Spark, на котором можно написать еще UDF для тех вещей, которые либо слишком большие для Greenplum, либо просто тяжело выражаются на SQL. Такие расчеты есть.
В таком случае витрины экспортируются в Greenplum, а чаще всего наоборот: витрины строятся в Greenplum и экспортируются назад в YT, чтобы аналитики могли, например, поженить их с метриками.
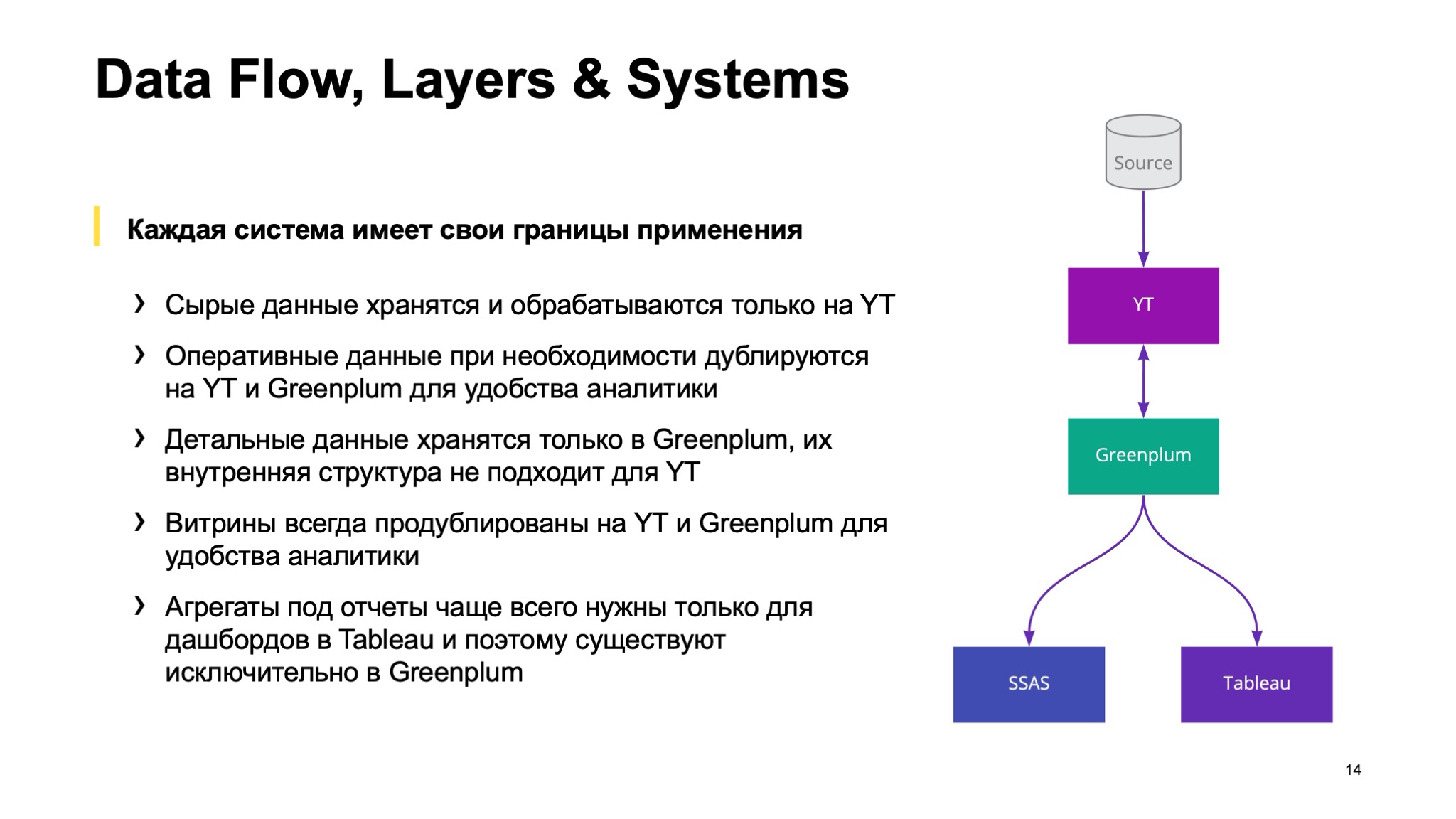
Вот и получается, что каждая система у нас имеет свои границы применимости. YT Data Lake с сырыми данными и ODS, в Greenplum — детальные данные, а витрины продублированы и там, и там. Всякие агрегаты подотчета нужны только для Tableau и SSAS, так что они находятся только в Greenplum, а в YT чаще всего от них нет никакого прока, поэтому их туда не экспортируют.
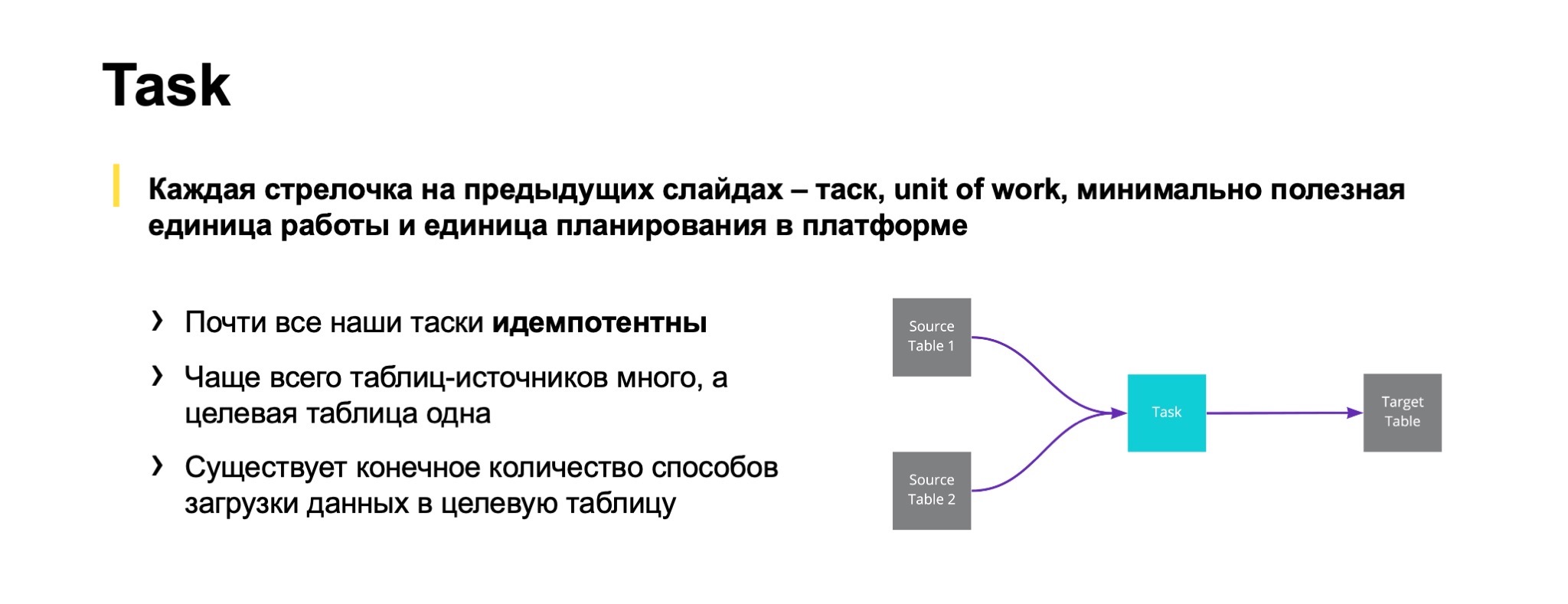
Теперь можно перейти к тому, чем занимаемся мы как разработчики, что включает в себя наша платформа. Каждая стрелочка на предыдущих слайдах — это таск. С нашей точки зрения это некий unit of work, нечто минимально полезное, что мы планируем и шедулим в своей платформе.
Какие здесь есть важные особенности? В первую очередь, почти все наши таски идемпотентны.
Далее. Чаще всего мы стараемся дизайнить свои процессы так, чтобы один таск не делал несколько выходных таблиц — за редкими исключениями, когда это требуется с точки зрения производительности.
По умолчанию мы рекомендуем так не делать. Это позволяет выделить число способов загрузки данных в целевую таблицу и прокачивать, развивать их.

Поясню про идемпотентность. Что мы под ней понимаем? Она у нас не совсем каноническая, потому что в нашем случае raw, ODS-данные, а на самом деле и DDS тоже, меняются просто постоянно. Raw-процесс работает каждую минуту, ODS тоже, DDS может прогружаться раз в 5–10–15 минут. Мы не можем обеспечить неизменность входных данных для процессов. Но при этом мы считаем таск идемпотентным, если при нескольких последовательностях вызовах — например, через retry или просто с одними и теми же аргументами — в целевой таблице будет то же самое состояние, что и после предыдущего вызова. Это позволяет нам делать retry и пересчитывать данные в исторической перспективе, чаще всего не беспокоясь о проблемах, которые могут при этом возникать. Тут, наверное, есть еще разные нюансы. И мы всем своим дата-инженерам рекомендуем делать всё, что только можно, идемпотентно, потому что жить так в разы проще.
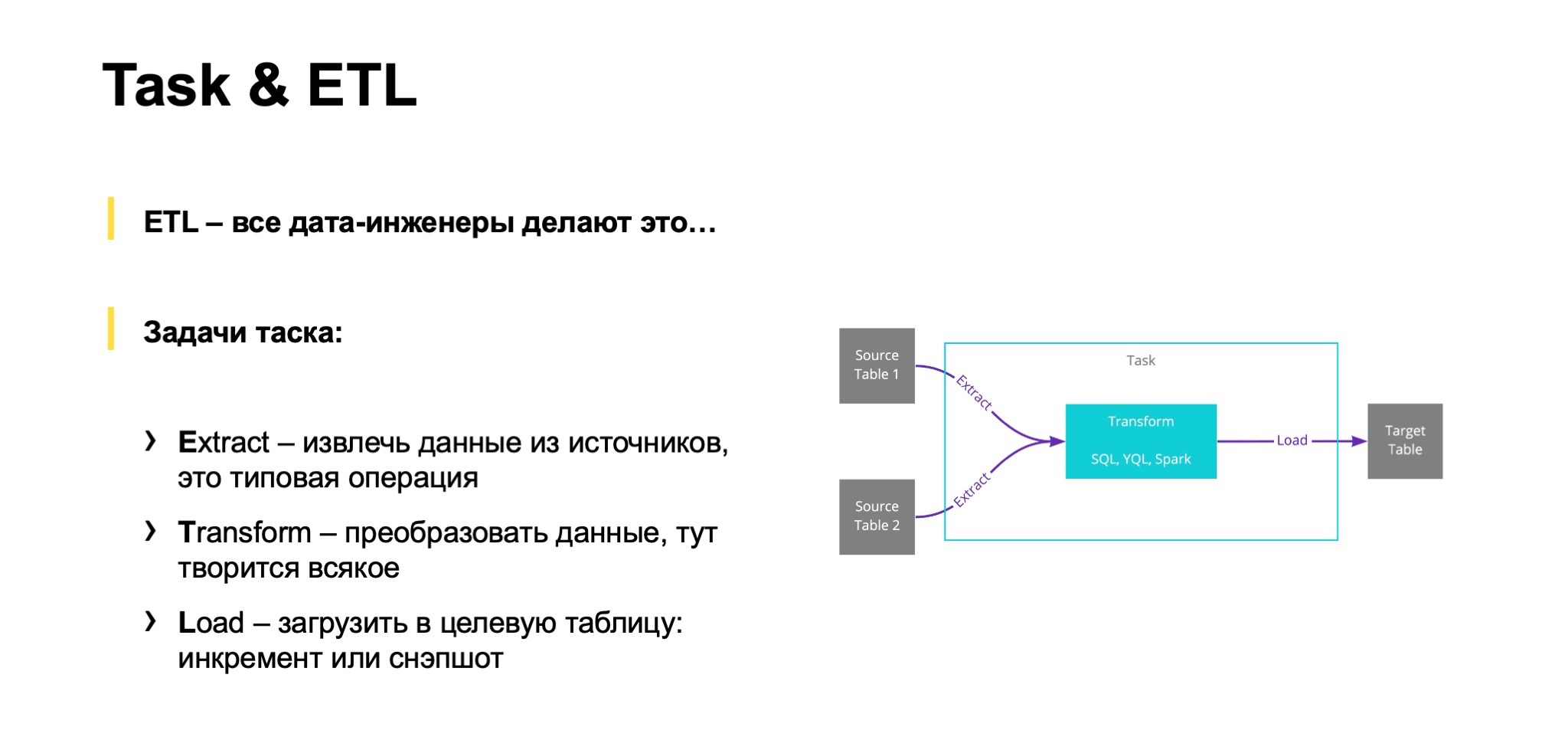
Получается, все наши таски — это ETL-процессы. Но тоже, наверное, не совсем в классическом смысле. Сейчас попробую пояснить. Таск в нашем понимании — это способ описания того, как и откуда данные нужно прочитать, заэкстрактить, преобразовать. Причем преобразовать — это не значит выкачать их куда-то к себе. Это может быть преобразование произвольными SQL, YQL, Spark, то есть движок, способный работать в базе данных или на YT. И их нужно прогрузить, но не в базу данных, а скорее применить специальную трансформацию, преобразование для записи в целевую табличку. Это могут быть различные способы загрузки инкремента, снэпшоты, разного рода истории и так далее.

Наша задача — упростить и максимально автоматизировать всё, что делает дата-инженер, автоматизировать процессы обработки данных. Причем задача экстракта или чтения данных из исходных таблиц или внешних источников чаще всего типовая. Загрузка данных в целевую таблицу — тоже. А трансформация — это как раз нечто уникальное, что приносит в данные дополнительную ценность, делает из них продукт. И именно на это дата-инженер должен тратить свое время, а не на все остальное. Мы на этом и стараемся сконцентрироваться, сделать так, чтобы дата-инженеры концентрировались.
Развитие: от cron до DMP
Расскажу, как мы до всего до этого дошли, потому что картина у нас достаточно большая, широкая и сложная.

Все начиналось, конечно, не так. Четыре года назад был бэкенд с базами, несколько MongoDB, несколько PostgreSQL, несколько аналитиков, которые ходили в дев-реплики этих самых баз. И нужно было делать Data Warehouse, просто потому что ходить в MongoDB, вытягивать оттуда данные, крутить их в Python и строить отчет — такой процесс уже перестал работать.
У нас под рукой было, наверное, то же самое, что чаще всего бывает — машинка с Linux, в нашем случае Ubuntu, cron на ней, Python — вот и все, поехали.
Что делаем? Пишем скриптики на Python, ставим их на расписание и вроде бы все работает.
from dmp_suite import arguments
# ...
def load(period):
"""
Достаем данные из источника и как-то загружаем в raw-слой
"""
pass
if __name__ == '__main__':
args = arguments.parse()
load(args.period)Как это выглядит? Вот что такое скриптик на Python? Делаем блок main, исполняемый файлик, там функция, она что-то откуда-то читает и куда-то пишет. Может писать в Raw, может не в Raw. В общем, делает какие-то произвольные вещи.
#!/bin/bash
if [[ -z "$1" ]];
then
start=$(date -d "-40 day" +'%Y-%m-%d')
end=$(date -d "-1 day" +'%Y-%m-%d')
else
start_date=$(date -d "$1" +'%Y-%m-%d')
end_date=$(date -d "$2" +'%Y-%m-%d')
fi
python -m taxi_etl.layer.yt.raw.adjust.api_kpi.loader --start_date=$start --end_date=$endПо историческим причинам — я сейчас их не назову, хотя и был в тот момент в проекте — Python-файлов нам было мало. Почему дефолтные параметры запуска мы определяли в bash-скриптах? Отчасти потому, что bash-скрипты мы еще использовали, чтобы объединить несколько питонячих скриптов в цепочки, чтобы они просто выполнялись друг за другом. Простенький процессик, да еще и с одинаковыми аргументами. Про Airflow не слышали, про Luigi не знаем, вообще ничего не знаем и пишем bash-скрипты. Очень просто.
MAILTO="taxi-dwh-cron@yandex-team.ru"
PATH=...
PYTHONPATH=...
# скрипт на python для запуска bash- и python-скриптов
LR3="python3.7 -m dmp_suite.runner sh"
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ adjust ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
30 0 * * * www-data $LR3 raw_adjust_api_kpiДальше втыкаем их в cron. Придумываем, естественно, обвязочку для cron, потому что у нас всё не просто так — у нас же продакшен живет в нескольких дата-центрах, нужен распределенный cron с блокировочками, мониторингами и так далее. И мы быстро заполняем хранилище. Просто создаем миллион загрузок в Raw и ODS и несколько витрин. Вроде бы все хорошо.

Но команда и проект растут. Когда ты просто пишешь произвольные скриптики, то, скорее всего, только автор знает, что скриптик делает и почему. Это тяжело поддерживать, развивать, практически невозможно проводить рефакторинги, выделять общие паттерны и переиспользовать наработки, потому что всё вроде про одно и то же, но по-разному. И нет понимания, как скриптики связаны между собой. Потому что, например, дата-инженер их распределил в правильном порядке в cron, и всё, работает.
Конечно, первое, что хочется сделать, — взять готовый инструмент. Мы на них смотрели — на Airflow, на Luigi. Но с нашей точки зрения, они, в первую очередь, сами по себе из коробки не приносят в код дополнительную семантику относительно того, что же происходит с данными. Да, в Airflow сделано удобно. Если ты нарисовал граф без какой-либо структуры, то у тебя будет просто репозиторий из 100–200 тысяч графов, каждый из которых написал какой-нибудь дата-инженер. Этот инженер знает, как он работает, а другие нет. Нужна структура.
И они очень плохо встраивались в наш паттерн работы, потому что у нас с самого начала проекта Raw ODS были микропатчевыми. Airflow такое не очень любил, по крайней мере когда мы все это начинали.
Еще у нас были нюансы и со специальным SOX-аудитом, который проходит компания, если она торгуется на бирже. Аудит выносит свои требования к тому, как организовывать процессы, куда можно иметь доступ, а куда нельзя.
Есть еще особенности внутренней инфраструктуры с требованиями к продакшену. Например, нужно жить как минимум в двух дата-центрах, чтобы переживать отключения. В некоторых случаях это для нас условности, потому что, например, у нас один кластер Greenplum. Но все равно есть процессы, которые могут жить 24/7.

Вернемся к задачам. Напомню, что нашим основным стимулом было сделать так, чтобы дата-инженер начал тратить время не на поиск в репозитории типового реального способа, не legacy-способа перекладывания данных из одного места в другое, а концентрировался на своей конкретной задаче — построить витрину.
С legacy — отдельная история. Проект большой, поэтому у нас было и на самом деле до сих пор есть наслоение из нескольких уровней legacy: legacy 2016-го, 2017-го, 2018-го, 2019-го и так далее годов. Мы его постепенно выпиливаем, но оно до сих пор как-то живет.
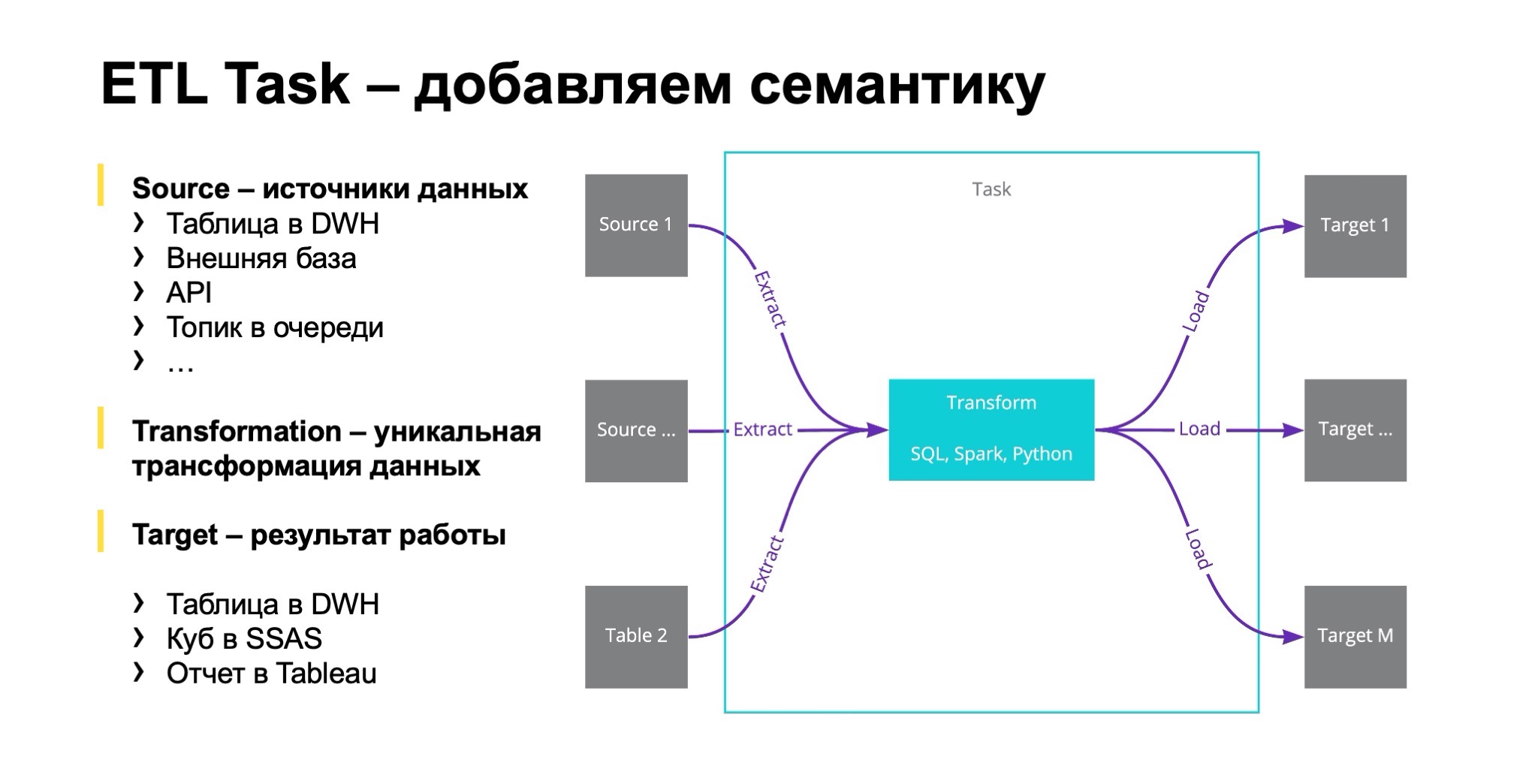
Что у нас получилось? Мы постарались в первую очередь выделить для себя очень простые и основные сущности. Выделили сущность ETL Task с определенной семантикой. У него есть входы. Это могут быть разные вещи: наша таблица, или внешняя база, API, топик в очереди и тому подобное. Далее — трансформация, на которую дата-инженер должен тратить время, и результат работы таска. Это также может быть табличка, а может быть обновление дашбордика. Или это выгрузка данных в почту, в трекер, куда-нибудь. Неважно, по-разному может быть.
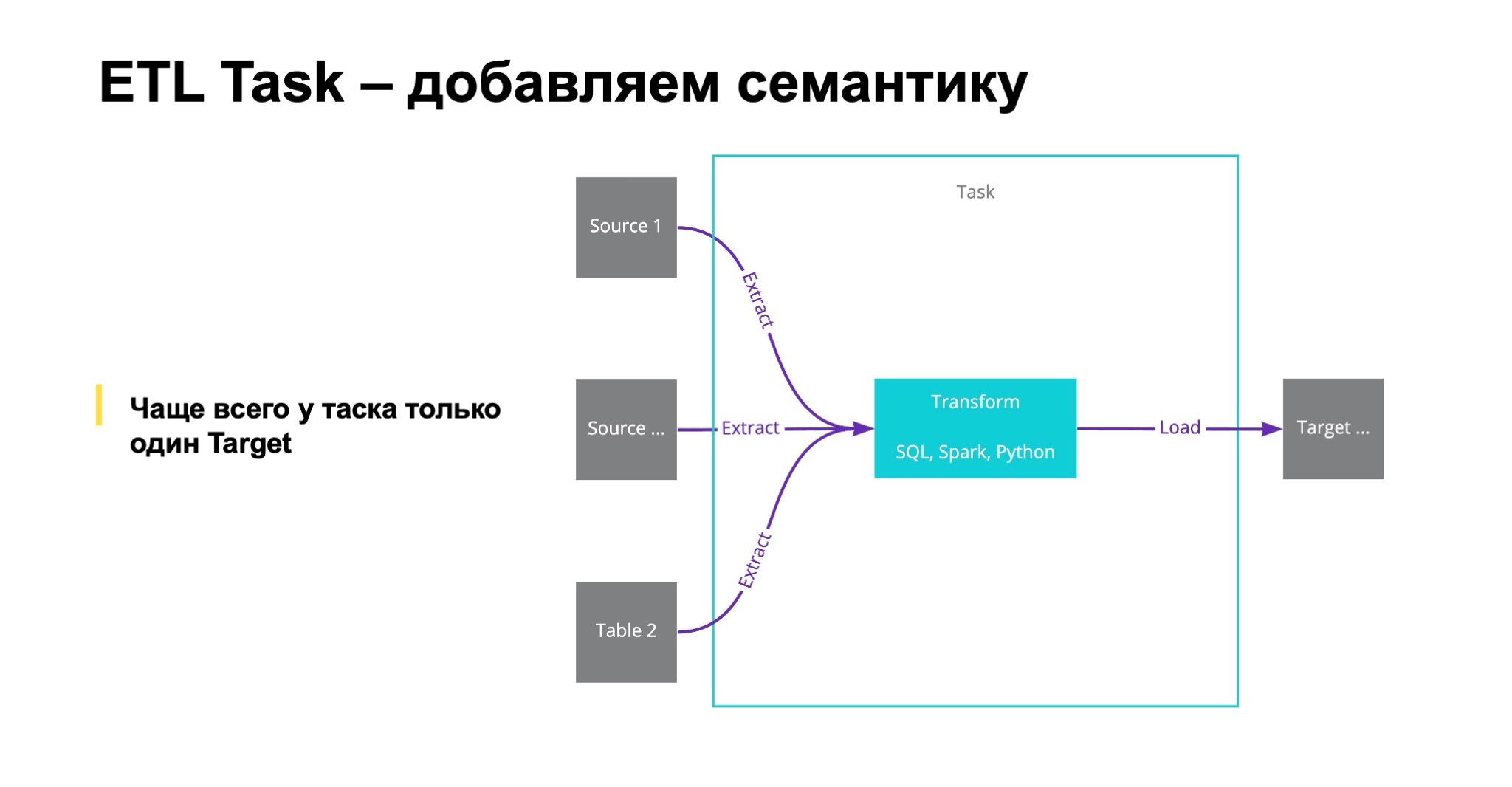
Но чаще всего мы для себя дизайнили и делали так, что таргет все-таки один. Это важно. И вот почему.

Когда таргет один, то очень легко прямо в имени таска привнести в него дополнительную семантику и сказать, что этот таск — не просто таск, а snapshot или, например, upsert. А здесь мы историю строим по SCD2 или как-нибудь еще.
Мы для себя еще сразу ставили такие критерии успешности, что нужно уметь легко запускать и тестировать таски, делать это локально и в тестовой среде, уметь указывать, когда нужно запускать таски, например, в проде, объединить их в графы. И желательно стремиться к тому, чтобы все таски были максимально автономны и случае падений, багов и даунтаймов как систем источников, так и наших целевых систем, они всегда могли перезапуститься с нужного места.

Как мы этого достигли? Начали мы с того, что договорились, в какой структуре будет организовываться репозиторий.

Допустим, мы делаем витрину. К тому, что такое сервис, я еще вернусь. У нас просто нет большого монолита со всеми процессами, а есть несколько отдельных небольших сервисов. Внутри сервиса под соглашением лежит специальный python-пакет layer со всеми тасками и таблицами. В нем есть пакет для каждой целевой системы: Greenplum, YT, ClickHouse, Tableau — в зависимости от того, что мы делаем. Информация о модуле на слой. И модуль на некий домен. Например, витрина — она же не просто витрина, а сделана для кого-то. Скажем, для финансов. Еще есть модуль на каждую табличку и таск, который ее считает.
Конечно, иногда случается нарушение — хочется что-то пообобщать или объединить вместе, но в 90% случаев весь код выглядит так. Это позволяет легко ориентироваться в структуре. Вы гуляете по коду, и он полностью повторяет то, как данные лежат, например, в БД.

Внутри модуля находится файл с самим таском, мы это называем loader, файл с определением целевой таблицы table.py. Если это SQL-запросы, то рядышком обычно лежит отдельный файл с шаблоном запроса, который мы форматируем, параметризуем. И есть несколько специфичных для нас сущностей. Первая — recipes.py, конфиг-файл. У нас все построено на разных DSL для Python, для которых можно описать, как и какие данные принести, чтобы свой таск отработал. Рядышком еще может лежать файлик — это таски с проверками качества данных.
Мы хотим прийти к тому, чтобы рядышком у каждого таска лежали еще канонические данные для тестов, чтобы можно было автоматом прогонять тесты по всем таскам — либо перед релизом, либо на пул-реквесты, либо и перед релизом, и на пул-реквесты. Но сейчас, к сожалению, это не везде так.
source = SqlSource.from_string(
'''
CREATE TEMPORARY TABLE result_table
ON COMMIT DROP AS
SELECT * FROM {table}
'''
).add_tables(
table=SourceTable,
)
task = snapshot(
'load_target_table',
source,
CdmCommission,
).set_scheduler(
Cron('* * * * *'),
)Итого как у нас выглядит таск? Обычно это сколько-то строчек на Python, вне зависимости от того, что мы делаем с данными и в какой системе.

Эти строчки на Python состоят из некой абстракции Source, она содержит в себе информацию, какие данные она использует. Например, какие входные таблички хранилища или какие внешние данные нужно предварительно загрузить в Greenplum, чтобы потом к ним применять SQL. И трансформация данных на SQL, то есть запрос с бизнес-логикой, который можно параметризировать. Если внимательно посмотреть, то мы, например, не хардкодим названия табличек, а подставляем эти таблички по нашим специальным метаданным. Сейчас покажу, как мы это описываем.
Мы это делаем, чтобы можно было относительно легко — например, в тестах, в деве — сделать так, чтобы все жило изолированно, в разных префиксах. Например, для Greenplum можно создавать разные схемы с префиксами. Файловая система в YT — как HDFS, то есть там можно делать разные папочки. И это нам кажется удобным.

Вторая часть — определение таска, первая — название таска, которое сразу доносит его семантику, объясняет, что он делает с данными. Snapshot — это понятно, мы всё удалили из целевой таблички, сгрузили все, что получилось, во временную табличку, которую возвращает SqlSource. Причем для каждой системы у нас есть контракт о том, что именно этот Source должен вернуть.
Допустим, для Greenplum он всегда возвращает табличку, временную или физическую. Это просто имя таблицы, которая принимает на вход таск и делает что-то с данными из этой таблицы.
В YT это тоже может быть таблица, но где-то в этом аналоге HDFS, или временная таблица, если такая сущность тоже есть.
В таске мы просто декларируем — вот таск, вот у него есть имя, выходная таблица, в которую он грузит данные, и source. В результате мы получаем трассировку от источника до целевой таблицы. И здесь же указываем, когда его запускать: через cron или по триггеру. Сейчас это cron. То есть запуск идет чаще всего по расписанию, а когда нужно что-то объединить, мы выстраиваем цепочки из тасков. В целом мы начали движение в сторону реактивности, но пока рано о нем говорить.

Что мы получаем благодаря такому описанию? Основной плюс — все таски выглядят одинаково, вне зависимости от системы. Куда бы вы ни зашли, у вас одинаковая структура репозитория, кода, одинаково выглядит определение таска. Мы концентрируемся на том, что именно мы делаем с данными, а не как мы это делаем. То есть говорим: «Мы прогружаем snapshot», и один раз определили, как это правильно делать. Для Greenplum мы в случае snapshot делаем не truncate, а просто delete from, потому что truncate лочит таблицу на чтение, а delete from не лочит. Подбирая правильные настройки автовакуума, мы добиваемся, с одной стороны, стопроцентной доступности данных для пользователей, а с другой — не страдаем от того, что у нас пухнут таблицы.
Еще один важный плюс — разделение команды. Есть люди, которые понимают, как работает платформа и как она устроена под капотом, и могут эту часть развивать: например, переносить. Предположим, мы решим, что внутренний инструмент круче, чем Airflo, Luigi или Kubernetes, и там надо запускать все таски. Тогда мы туда переедем. Благодаря декларативному описанию дата-инженеры это вообще могут не заметить — это в идеальном случае. Либо в жизни дата-инженера произойдут минимальные изменения.
Также мы получаем возможность строить Data Lineage. Например, мы отображаем ее в нашей документации на таблички. Для каждой таблички мы пишем, что она строится из таких-то источников, такими-то тасками и используется в расчете таких-то объектов. Нельзя сказать, что у нас крутой UI. Скорее просто внутренняя система, куда мы можем выложить документацию, и она будет проиндексирована в поиске по интранету.
Может быть, мы даже попробуем выложить это в опенсорс, но для этого еще нужно пройти большой путь.
Каковы минуса? Чтобы это все имело смысл, должен быть хороший DSL, а сделать хороший DSL правда сложно, на это уходит много времени. Дата-инженерам и аналитикам так или иначе приходится осваивать этот DSL. Это чуть бо́льший порог входа, чем когда дата-инженер просто пишет python-файлики и они у него как-то работают. Но есть ощущение, что поскольку все выглядит стандартно, то у нас получается сделать конкретный процесс не вотчиной определенного дата-инженера, а все-таки штукой, понятной всем остальным. Ты хотя бы заходишь и видишь — ага, это у меня инкремент. И хотя бы во время код-ревью понимаешь, что этот запрос возвращает не всё, а только кусочек данных, который будет прогружаться.
Поэтому мы для себя приняли такое решение, смогли это сделать, и теперь я могу об этом рассказать.
class CdmCommission(GPTable):
""" Описание таблицы в целом """
__layout__ = CdmLayout(
name='commission',
group='finance',
)
id = Int(comment='ID сущности')
int_metric_val = Int(
comment='Описание метрики ...'
)
double_metric_val = Double(
comment='Описание метрики ...'
)
# ...Вторая часть всего нашего фреймворка — DSL для описания табличек. У нас несколько систем. ClickHouse мы тоже используем, просто не очень активно. У нас есть YT, Greenplum, ClickHouse. По какому пути мы могли пойти? Понятно, что в каждой системе свой синтаксис, по которому правильно создавать таблички. Мы решили действовать по принципу, что табличка — она везде табличка, и соорудили DSL, который в целом похож на ORM-фреймворки. Например, на SQLAlchemy или на Django ORM. То есть создается класс, описываются какие-то его поля. Здесь же они комментируются. Мы на код-ревью или, например, на уровне тестов можем проверять, что данные не создаются без описания, потому что это важно. Данными без документации пользоваться нельзя. А в данном случае ты видишь этот один файлик, видишь, что туда кто-то докинул на код-ревью дополнительное поле без комментария и говоришь — ай-яй-яй, request changes. Переделывай, пожалуйста, пиши комментарий.
Не менее важен стандартный подход к именованию всех табличек. Это тоже очень холиварный момент — как правильно именовать столбцы, раскладывать таблички схемам, как их правильно называть и так далее. Мы это постарались один раз обсудить. Обсудили, например, что у нас схема содержит в себе название, указывающее, например, к какому сервису она относится, к какому слою и какому домену. А табличка — это название сущности. Но дата-инженер, создавая загрузку, об этом не думает. Он просто говорит — табличка у меня будет лежать в каком-то CDM layout, я там указываю домен, к которому она относится — допустим, finance, — и себя — допустим, commission. А под капотом оно склеивается, и получается название таблички. При необходимости можно вывести и посмотреть, что же у меня получилось. Изначально это дает некий порог входа, но потом становится скорее удобно. И получается такое декларативное описание всех данных, которые у нас есть. Понятно, что здесь есть не только такие параметры. Можно указывать партиционирование, сжатие и так далее — кучу свойств, которые присущи таблице. Причем они могут быть уникальны для каждой системы.
@ecook.recipe
def default(definition):
definition.gp.restore(
by_gp_table(SourceTable),
)
@ecook.recipe
def last_15_days(
definition,
period=period(
utcnow(),
utcnow() - timedelta(days=15),
),
):
definition.gp.restore(
by_gp_table(SourceTable, period),
)
Что это за файлик recipes, который тоже составляет важную часть фреймворка? Это такая декларация о том, что мне нужно, чтобы я мог в своей локальной дев-песочнице запустить какой-нибудь ETL-таск. Мне могут быть нужны данные из какой-нибудь таблички. Я говорю — принеси мне, пожалуйста, в эту табличку данные откуда-то. Или — табличка большая, принеси мне, пожалуйста, sample. Например, последние «N дней» из этой таблички.
Для одного таска может быть несколько рецептов, потому что мы стремимся к тому, чтобы пересчитывать данные вообще за всю историю. Соответственно, нужно иметь возможность легко протестировать таск — как он работает на 2017-м, на 2019-м. Убедиться, что он там точно работает. Такие рецепты помогают следующему дата-инженеру, который постарается пофиксить какой-нибудь баг или доработать витрину. Он просто запускает рецепт из консоли, создается среда для разработки, и он начинает работать.
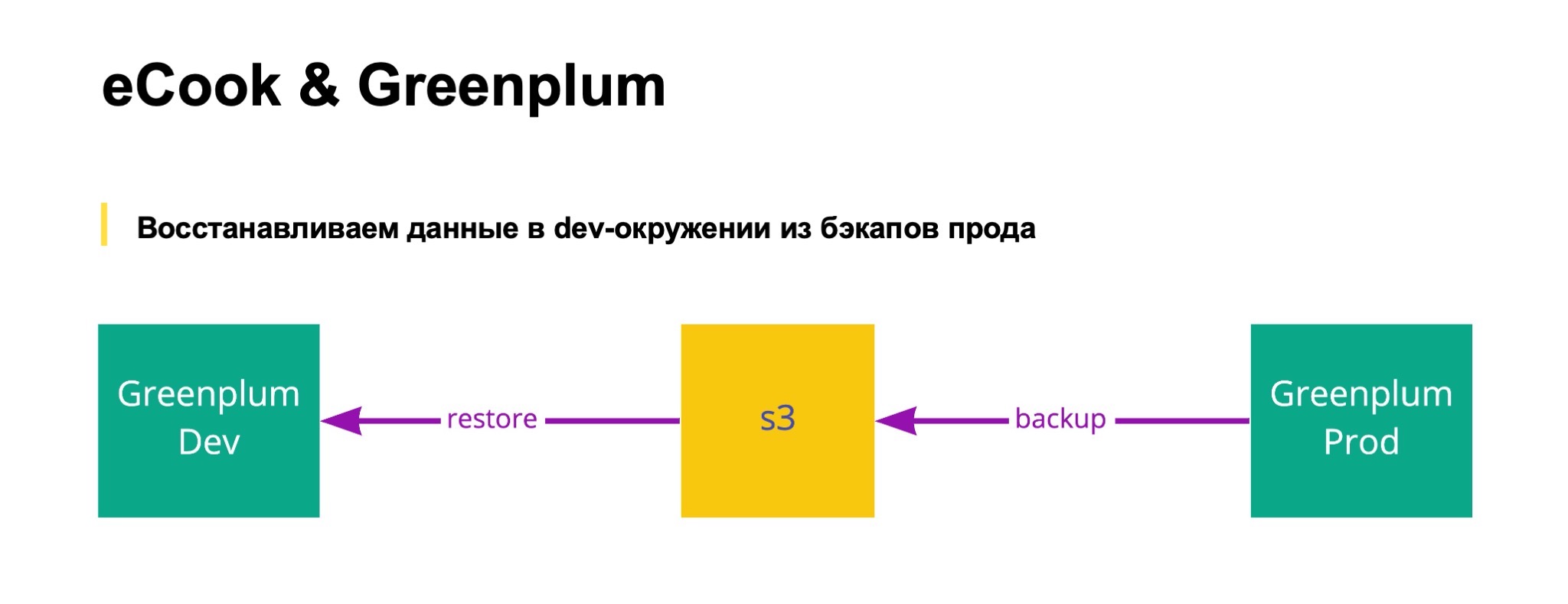
Как это устроено физически? Для Greenplum все относительно просто. Есть прод, он бэкапится в объектное хранилище. И эта команда из receipt restore представляет собой restore какой-нибудь таблички или набора партиции этой таблички из s3 в дев-кластер greenplum, есть такой отдельный сервис.
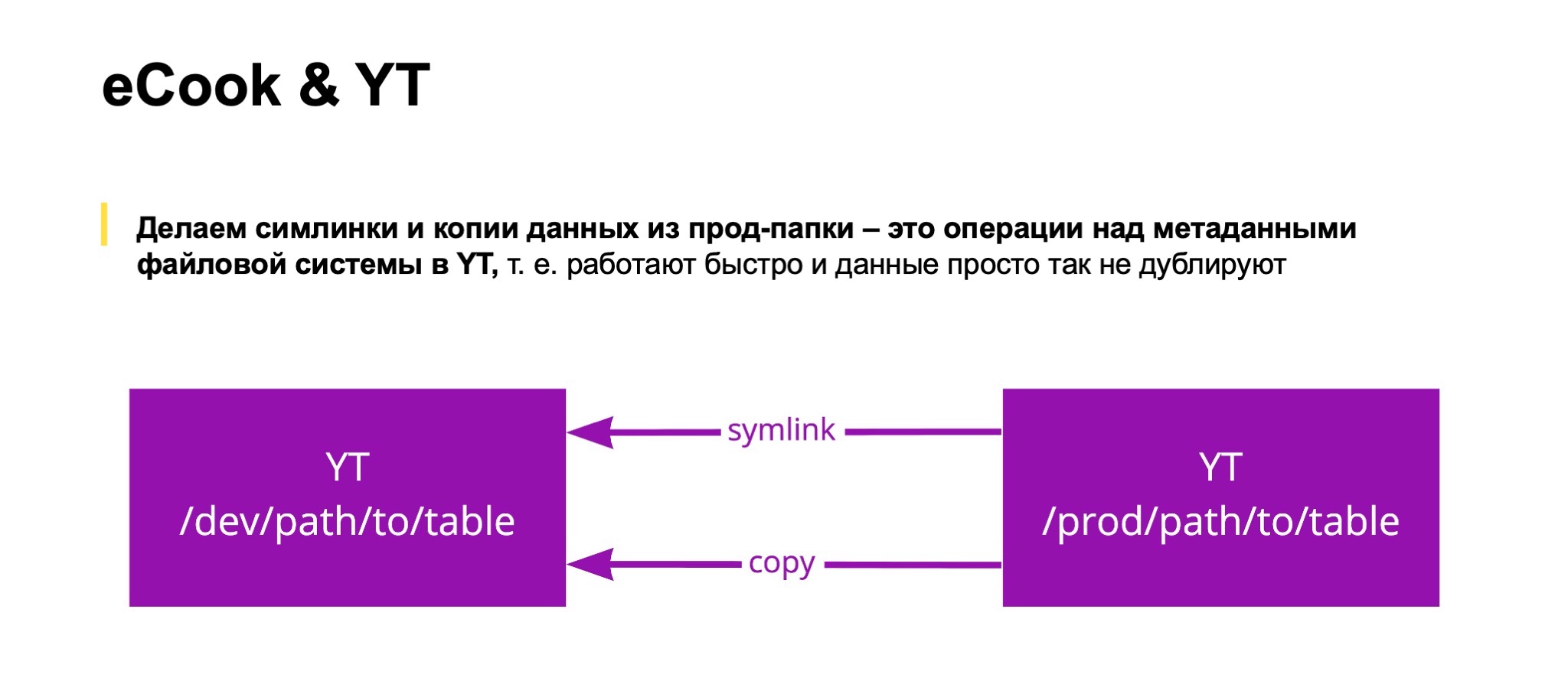
Для YT несколько проще, потому что YT — это огромный кластер, где есть и прод, и дев. Они просто разграничены разными уровнями доступа. YT умеет быстро очень делать, во-первых, симлинки, а во-вторых, копии, потому что и та, и другая операция производится над метаданными файловой системы и происходит практически мгновенно, никаких физических переносов данных нет. Получается, что можно быстро сказать — у меня есть моя домашняя папочка, я там себе воссоздал сделать песочницу под конкретный тикет для разработки, и собираюсь там жить и работать. Можно делать несколько разных тасков, каждый в отдельной песочнице.
Что здесь, что в Greenplum этот путь, префикс, задается в конфиге одной строчкой. Здесь это путь до домашней папки проекта, в Greenplum — префикс в схеме. Его можно просто поменять и работать либо с одной песочницей, либо с другой.

Теперь можно вернуться немножко назад — к сервисам и доменам. Мы стремимся к модной концепции data mash, когда каждая команда может развивать определенные домены, эти домены можно объединять в релизные единицы, в ETL-сервисы, и внутри ETL-сервисов получается множество доменов. Это позволяет сделать так, что у нас есть множество команд и все они отдельно друг от друга. В то же время все это живет в одном репозитории. Такой небольшой DMP-монолит, где живут ETL-сервисы и код фреймворка.
