Разработка парсера, кодогенератора и редактора SQL с помощью EMFText

Это 6-я статья цикла по разработке, управляемой моделями. В прошлой статье вы получили общее представление о разработке предметно-ориентированных языков с помощью EMFText. Настало время перейти от игрушечного языка к более серьёзному. Будет очень много рисунков, кода и текста. Если вы планируете использовать EMFText или подобный инструмент, то эта статья должна сэкономить вам много времени. Возможно, вы узнаете что-то новое о EMF (делегаты преобразований).
Подобно отважному хоббиту мы начнём свой путь с BNF-грамматики SQL, дойдём до жуткого дракона (метамодели) и вернёмся обратно к грамматике, но уже другой…
Введение
Сегодня мы разработаем парсер, кодогенератор и редактор SQL. Кодогенератор потребуется в следующей статье.
Вообще, SQL очень сложный язык. Гораздо сложнее, чем, например, Java. Чтобы убедиться в этом сравните грамматики Java и SQL. Это просто жесть. Поэтому в статье мы реализуем маленький фрагментик SQL — выражения для создания таблиц (CREATE TABLE), причем, не полностью.
1 Настройка
Как обычно, понадобится Eclipse Modeling Tools. Установите последнюю версию EMFText отсюда http://emftext.org/update_trunk.
2 Создание проекта
Вы можете либо взять готовый проект, либо создать новый (File → New → Other… → EMFText Project).
В новом проекте в папке model уже созданы заготовки для метамодели (sql.ecore) и грамматики (sql.cs) разрабатываемого языка, с которыми вы познакомились в прошлой статье. Два этих файла полностью описывают язык. Почти всё остальное генерируется из них.
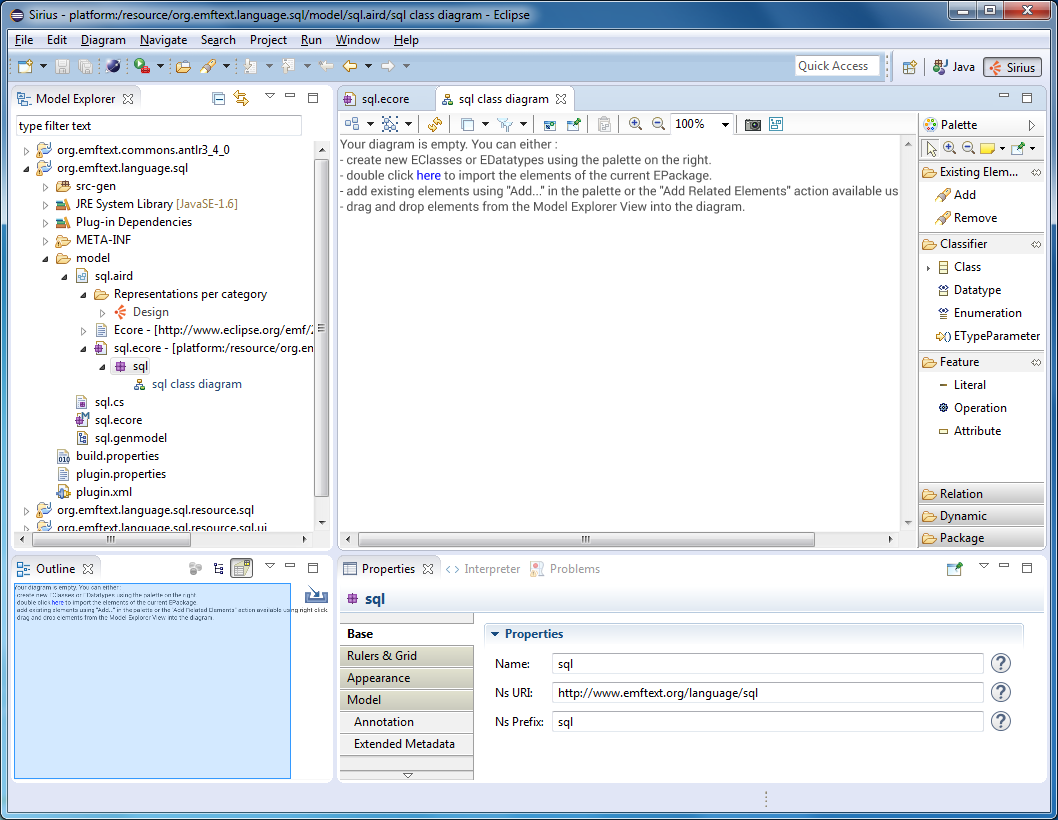
Удалите все классы и типы из метамодели, они нам не понадобятся. Редактировать метамодель можно либо в древовидном редакторе, либо в редакторе диаграмм. Чтобы создать диаграмму для метамодели выберите File → New → Other… → Sirius → Representations File. Выберите инициализацию диаграммы из существующей модели (sql.ecore). Выберите точку зрения «Design». Переключитесь на перспективу Sirius (Window → Perspective → Open Perspective → Other…). Откройте созданный aird-файл. Создайте для пакета sql диаграмму классов.
Примечание
Древовидный редактор и редактор диаграмм мы подробно рассматривали в предыдущих статьях. Если вы не любите создавать модель мышкой, а предпочитаете текстовое представление, то можете попробовать использовать Xcore. Я никогда не использовал его совместно с EMFText, но в принципе, не должно возникнуть проблем.
Также вы можете открыть Ecore-модель с помощью редактора OCLinEcore. Он текстовый, как и Xcore, только вместо Java используется OCL. Кстати, в метамодели одно вычисляемое свойство и одно правило контроля как-раз написаны с помощью OCLinEcore, но это уже тема для отдельной статьи.
Словом, для работы с метамоделью у вас есть 4 редактора на выбор :) Древовидный, диаграммный, текстовый Java-ориентированный, текстовый OCL-ориентированный.
3 Подходы к разработке метамодели языка
Есть два пути создания метамодели предметно-ориентированного языка: 1) от предметной области или 2) от синтаксиса.
В первом случае вы пытаетесь представить, что должен описывать язык. Например, язык из прошлой статьи описывает сущности, типы данных, свойства. А язык из этой статьи описывает якоря, связи, узлы, атрибуты. Для каждого вида объектов вы создаёте в метамодели соответствующий класс. А затем описываете для этих классов текстовую нотацию. Иными словами, это путь от семантики к синтаксису.
Во втором случае вы анализируете грамматику языка, смотрите как на этом языке описывается предметная область. Для каждого нетерминального символа создаёте в метамодели класс. Метамодель получается очень большая, избыточная и сложная. Вы отбрасываете из неё всё лишнее, оптимизируете её и в итоге получаете более-менее адекватную метамодель. Иными словами, это путь от синтаксиса к семантике.
Первый путь выглядит более правильным, но он опасен тем, что метамодель может получиться слишком оторванной от языка. Например, что описывает SQL? Лично я был убеждён, что это язык о таблицах, столбцах, представлениях, ограничениях, ключах, … — об объектах, которые описаны в конце спецификации SQL в разделах Information Schema и Definition Schema. Логично было бы создать в метамодели языка соответствующие классы: таблица, столбец и т.п. Но это неправильно, потому что в итоге мы получим структуру метаданных реляционной СУБД, а не структуру операторов языка SQL.
Таблицы, столбцы, ограничения как таковые в SQL отсутствуют. Вместо них есть операторы создания, удаления, изменения этих объектов. Соответственно в метамодели вместо класса «Таблица», должны быть классы «Оператор создания таблицы», «Оператор удаления таблицы», «Оператор изменения таблицы», …
Этим SQL принципиально отличается от простого декларативного языка из предыдущей статьи. Принято считать SQL декларативным языком, в отличие от, например, Java. Но, блин, на Java я могу написать:
public class User {
public int id;
public String name;
}
А на SQL я не могу описать таблицу декларативно, а могу только вызвать оператор создания таблицы:
CREATE TABLE "user" (
id INT CONSTRAINT user_pk PRIMARY KEY,
name VARCHAR(50) NOT NULL
);
Или несколько операторов:
CREATE TABLE "user" (
id INT CONSTRAINT user_pk PRIMARY KEY
);
ALTER TABLE "user" ADD COLUMN name VARCHAR(50) NOT NULL;
Из-за этого валидация SQL-скриптов усложняется. Мы сначала можем создать таблицу, потом удалить её, потом создать другую таблицу с таким же именем. Представьте, если бы в Java можно было разопределять переменные, изменять у них тип данных или добавлять/удалять свойства классов! Как вообще валидировать такой код?
Примечание
Наверное, это не делает SQL языком с динамической типизацией. Я уже чувствую, как в меня летят помидоры за «императивный и динамически типизируемый» SQL:) Но попробуйте реализовать парсер или редактор SQL-скриптов и вы придёте к тому, что это равнозначно реализации императивного и динамически типизируемого языка. Чтобы определить допустимые имена таблиц или столбцов, парсеру приходится фактически интерпретировать код, но без изменения реальной БД. В данной статье эта интерпретация реализована максимально просто (в классах, отвечающих за разрешение ссылок, описанных далее), в реальности всё сложнее. Некоторые идеи в части механизма разрешения ссылок можно почерпать из JaMoPP.
4 Разработка метамодели SQL
Итак, первый путь к метамодели хорош для декларативных языков типа EntityModel или Anchor. А придти к метамодели SQL нам проще вторым путём. Мы проанализируем небольшой фрагмент грамматики SQL и создадим для него необходимые классы.
BNF-грамматика языка состоит из правил, в левой части которых есть один нетерминальный символ, а в правой части — несколько терминальных или нетерминальных символов. Мы могли бы, не думая, для каждого нетерминального символа из левой части создавать класс, а для каждого нетерминального символа из правой части — атрибут или ссылку на соответствующий класс. Но, поверьте, метамодель получится очень сложная, с ней будет не удобно работать. Поэтому я сформулировал для себя несколько рекомендаций, которые позволяют сразу строить более-менее упрощенную метамодель.
- Если в правой части правила «сложная» последовательность символов, то для нетерминального символа из левой части правила создаём класс.
- Если в правой части правила выбор из нескольких «сложных» последовательностей символов, то для нетерминального символа из левой части правила создаём абстрактный класс, а для каждой альтернативы создаём конкретный подкласс, который наследуем от абстрактного.
- Если в правой части правила выбор из нескольких «простых» последовательностей символов, то для нетерминального символа из левой части правила создаём перечисление.
- Если правая часть правила относительно «простая», но нельзя перечислить все возможные варианты, то либо используем для нетерминального символа из левой части один из примитивных типов данных Ecore, либо (если нет подходящего) создаём новый тип данных.
- Для каждого «простого» нетерминального символа из правой части, который не является ссылкой по имени на некоторый объект предметной области, создаём атрибут в классе из левой части правила.
- Для каждого «простого» нетерминального символа из правой части, который не является ссылкой по имени на некоторый объект предметной области, создаём non-containment ссылку в классе из левой части правила на класс именуемого объекта.
- Для каждого «сложного» нетерминального символа из правой части создаём containment ссылку в классе из левой части правила на класс, соответствующий данному нетерминальному символу из правой части.
Все эти рекомендации звучат как какой-то детский сад :) Что значит «простые» и «сложные»? Также из этих правил есть некоторые исключения. Например, если символы повторно используются в разных правилах.
Я начал описывать всё это формально, с чёткими определениями. Но на второй странице понял, что это тема для отдельного научного труда, который просто не поместится в эту и так уже гигантскую статью. Поэтому предлагаю обойтись пока такими интуитивными рекомендациями.
4.1 Анализ правила для
Теперь разберём нетерминальные символы из правой части. Для каждого из них мы в соответствии с рекомендациями 5–7 должны создать атрибут или ссылку в классе TableDefinition. 4.2 Анализ правила для
Примечание У вас может сложиться впечатление, что все мои рассуждения какие-то совершенно нетривиальные — всё это выглядит безумным и сложным. Но всё проще, чем кажется, просто попробуйте сами реализовать какой-нибудь язык.
4.3 Анализ правила для
4.4 Анализ правила для
В соответствии с рекомендацией 7 создаем ссылку от класса TableDefinition к классу TableContentsSource. Для ссылки необходимо установить свойство containment в значение true. Для скобок и запятых классы, очевидно, не нужны, они реализуются на уровне лексера. 4.5 Анализ правила для
В соответствии с рекомендацией 7 создаем ссылку от класса TableElementList к классу TableElement. Для ссылки необходимо установить свойство containment в значение true. 4.6 Анализ правила для
Корневой объект модели — это SQLScript, который может содержать несколько выражений (Statement) двух видов: осмысленные выражения и разделители. Разделители также могут быть двух видов: пробельные символы и комментарии. Первые нам в метамодели не нужны. Комментарии также могут быть двух видов: однострочные и многострочные. Вообще, часто комментарии не включают в метамодель языка, потому что они никак не влияют на семантику кода. Но далее мы будем делать не только парсер, но и кодогенератор. Хотелось бы, чтобы последний мог генерить и комментарии. Обратите внимание на типы данных справа. UnsignedInteger отображается на Java-класс, который мы реализуем позже. А типы для представления даты и времени отображаются на уже существующие Java-классы. На следующем рисунке представлена основная часть метамодели. Обратите внимание на то, что в ограничениях (снизу справа) указываются не просто имена столбцов и таблиц, вовлечённых в ограничение, а ссылки на них. Парсер будет формировать из исходного кода граф, а не дерево. При определении столбцов нужно указывать их тип данных: Может потребоваться указать значение по умолчанию для столбца, для этого нужны литералы: Также в качестве значения по умолчанию можно указать текущую дату или время: Или NULL:
Теперь мы снова опишем синтаксис SQL, но уже не на BNF, а на BNF-подобном языке в файле sql.cs. Указываем а) расширение файлов, б) пространство имён метамодели и в) класс корневого объекта синтаксического дерева (начальный символ грамматики):
Обратите внимание на то, что регулярные выражения для токенов UNSIGNED_INTEGER и EXACT_NUMERIC_LITERAL пересекаются. Из-за этого далее нам придётся немного усложнить грамматику.
А, вот, APPROXIMATE_NUMERIC_LITERAL уже никак не спутаешь с другими токенами, потому что в нём всегда содержится символ «E». Если вы внимательно смотрели BNF-грамматику SQL, то, наверняка заметили, что в ней достаточно подробно описан формат даты и времени, а мы ограничились простым QUOTED_STRING. Это связано с тем, что если бы мы описали токены для даты и времени, то они пересекались бы с токеном QUOTED_STRING и нам пришлось бы очень сильно усложнять грамматику (везде, где используется токен QUOTED_STRING указывать ещё и токены для даты и времени как допустимые). Либо пришлось бы составные части литералов (вплоть до отдельных символов) описывать в метамодели, что безумно её усложнило бы. Проще реализовать разбор даты и времени в коде, а не на уровне лексера. Далее я опишу, как это сделать. 6.3 Описание синтаксиса для типов данных
Так же немного усложняют жизнь «составные» токены типа «DOUBLE» «PRECISION». Почему нельзя было вместо пробела сделать символ »_» или вообще убрать второе слово?… Текущая реализация не очень корректная, потому что допускает только одиночные пробелы в «составных» токенах, хотя реально может быть сколько угодно пробельных символов, включая переводы строк, табуляцию и т.п. Это можно было бы реализовать в EMFText, изменив соответствующим образом правила, но тогда начинаются проблемы с кодогенератором. Можно было бы переписать кодогенератор, но это слишком долго. В будущих статьях нам понадобится именно кодогенератор, а не парсер, поэтому остановимся пока на таком решении. Альтернативная реализация «составных» токенов описана в разделе 6.5. Парсер работает нормально, но кодогенератор, скорее всего, не сможет сформировать в SQL-скрипте «GLOBAL» «TEMPORARY» или «LOCAL» «TEMPORARY».
В простейших случаях EMFText сделает это автоматически. Но SQL не очень простой язык, поэтому придётся написать немного кода. 7.1 Разбор комментариев
Для них при парсинге достаточно удалить два начальных символа »-». А при кодогенерации — добавить эти символы:
Возможно, у вас возник вопрос. Почему для натуральных чисел мы сделали отдельный тип, а для идентификаторов захардкодили всё на уровне лексера? Ведь первый вариант явно универсальней, эта логика будет использоваться не только при (де)сериализации скриптов в простом текстовом виде, но и, например, в XMI. А ответ очень простой. В других (де)сериализаторах нам как-раз и не нужно заключать идентификаторы в двойные кавычки, если в них содержатся зарезервированные слова. Это нужно только при парсинге/кодогенерации SQL-скриптов в простом текстовом формате. 7.4 Разбор даты и времени
В Java есть более подходящие нам типы: java.time.LocalDate, java.time.LocalTime и java.time.ZonedDateTime. 2-ой, к сожалению, без временной зоны, но сейчас не критично. Но есть проблема, у этих типов нет метода valueOf, а toString работает не так как хотелось бы. Реализовывать разбор даты и времени на уровне лексера не хочется, потому что эта же логика могла бы повторно использоваться и при (де)сериализации в XMI-формате или других. Поэтому воспользуемся не очень документированной фичей EMF — делегатами преобразований (conversion delegates). Для этого откройте файл plugin.xml и на вкладке «Расширения» (Extensions) добавьте расширение org.eclipse.emf.ecore.conversion_delegate. Добавьте в него фабрику со следующими свойствами: Примечание Разрабатываемый парсер и кодогенератор не обязательно должны запускаться как плагин Eclipse, они могут использоваться и в отдельном приложении. В этом случае файл plugin.xml не используется, а фабрика регистрируется подобным образом:
Итак, первое правило, которое нас интересует, описывает выражения определения таблиц.
::=
CREATE [
] TABLE
[ ON COMMIT
ROWS ]
Оно выглядит достаточно «сложным»: в правой части есть область видимости создаваемой таблицы, название таблицы, источник содержимого и действие при коммите. Правило подпадает под рекомендацию 1, значит, создаём класс TableDefinition.
::=
Видно, что правые части правил достаточно «простые». Для большей простоты их можно объединить в одно правило и в соответствии с рекомендацией 3 создать в метамодели перечисление TableScope с тремя значениями:
Первый вариант перечисления не указан в грамматике явно. Но из правила для видно, что область видимости таблицы опциональна, а по умолчанию создаются как-раз постоянные таблицы.
Нетерминальный символ используется в правиле для. Поэтому в соответствии с рекомендацией 5 у класса TableDefinition создаём атрибут tableScope с типом TableScope.
Теперь пробуем проанализировать правило для имени таблицы и внезапно натыкаемся на здоровенную цепочку правил, часть из которых даже не описана в грамматике, а описана словами в спецификации SQL!
::=
Большая часть правил описывает формат идентификаторов и имён и должна реализовываться на уровне типов данных, а не в метамодели. Вопрос только в том где именно провести границу между деталями реализации типов данных и матемоделью. Возможны такие варианты представления имён таблиц:
После нескольких бессонных ночей и курения исходников JaMoPP я пришёл к тому, что лучше всего вариант 3.1. В вариантах 1 и 2 придётся создавать два пересекающихся вида токенов: идентификатор и квалифицированное имя. Проще определить один вид токена для идентификаторов. Всё что сложнее идентификаторов (включая квалифицированные имена) реализуется на уровне метамодели, а всё что проще — на уровне типов данных.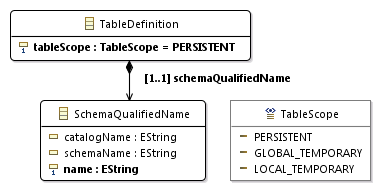
::=
| OF
]
|
::=
[ {
}... ]
Правило для источника содержимого таблицы подпадает под рекомендацию 2, поэтому создаём абстрактный класс TableContentsSource, от которого наследуем конкретный класс TableElementList. А два других варианта реализовывать пока не будем.
::=
|
В соответствии с рекомендацией 2 создаём абстрактный класс TableElement и унаследованный от него класс ColumnDefinition. Другие варианты пока реализовывать не будем.
В соответствии с рекомендацией 5 создаём у класса ColumnDefinition атрибут columnName с типом данных EString. Остальные свойства столбцов пока не будем реализовывать.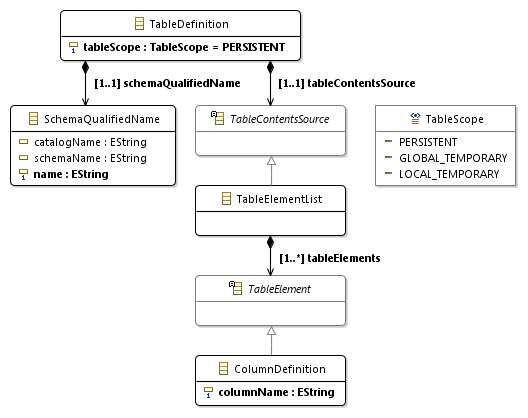
5 Более полная метамодель SQL
Если вы докурите ещё несколько правил из грамматики SQL, то получите такую метамодель.

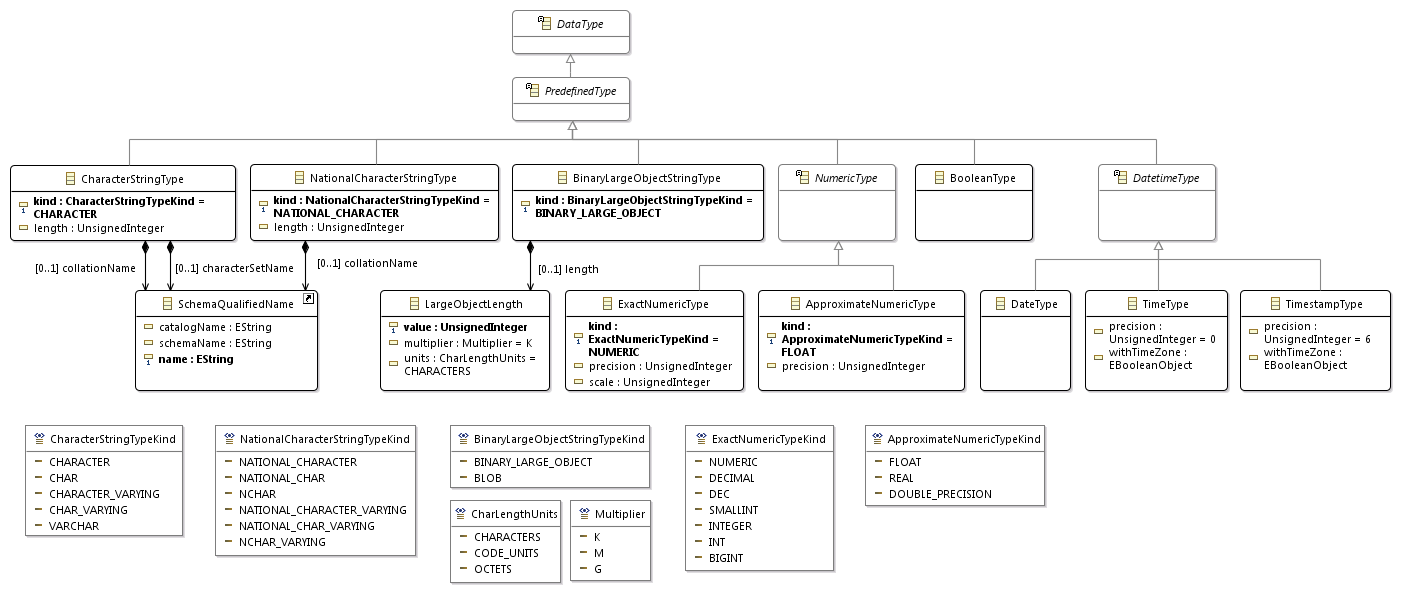


6 Описание синтаксиса SQL
Итак, мы наконец дошли до Эребора, увидели жуткого дракона Смауга (метамодель). Настало время возвращаться обратно.
SYNTAXDEF sql
FOR
Немного настроек, которые описаны в руководстве EMFText:
OPTIONS {
reloadGeneratorModel = "true";
usePredefinedTokens = "false";
caseInsensitiveKeywords = "true";
disableBuilder = "true";
disableDebugSupport = "true";
disableLaunchSupport = "true";
disableTokenSorting = "true";
overrideProposalPostProcessor = "false";
overrideManifest = "false";
overrideUIManifest = "false";
}
2 последние опции отключают перегенерацию файлов MANIFEST.MF в плагинах org.emftext.language.sql.resource.sql и org.emftext.language.sql.resource.sql.ui соответственно. В этих файлах необходимо установить минимально требуемую версию Java в JavaSE-1.8, т.к. мы будем использовать Stream API. А версию плагина изменить с »1.0.0» на »1.0.0.qualifier» иначе будут необъяснимые проблемы.
TOKENS {
// Default
DEFINE WHITESPACE $('\u0009'|'\u000A'|'\u000B'|'\u000C'|'\u000D'|'\u0020'|'\u00A0'|'\u2000'|'\u2001'$ +
$|'\u2002'|'\u2003'|'\u2004'|'\u2005'|'\u2006'|'\u2007'|'\u2008'|'\u2009'|'\u200A'$ +
$|'\u200B'|'\u200C'|'\u200D'|'\u200E'|'\u200F'|'\u2028'|'\u2029'|'\u3000'|'\uFEFF')$;
// Single characters
DEFINE FRAGMENT SIMPLE_LATIN_LETTER $($ + SIMPLE_LATIN_UPPER_CASE_LETTER + $|$ + SIMPLE_LATIN_LOWER_CASE_LETTER + $)$;
DEFINE FRAGMENT SIMPLE_LATIN_UPPER_CASE_LETTER $'A'..'Z'$;
DEFINE FRAGMENT SIMPLE_LATIN_LOWER_CASE_LETTER $'a'..'z'$;
DEFINE FRAGMENT DIGIT $('0'..'9')$;
DEFINE FRAGMENT PLUS_SIGN $'+'$;
DEFINE FRAGMENT MINUS_SIGN $'-'$;
DEFINE FRAGMENT SIGN $($ + PLUS_SIGN + $|$ + MINUS_SIGN + $)$;
DEFINE FRAGMENT COLON $':'$;
DEFINE FRAGMENT PERIOD $'.'$;
DEFINE FRAGMENT SPACE $' '$;
DEFINE FRAGMENT UNDERSCORE $'_'$;
DEFINE FRAGMENT SLASH $'/'$;
DEFINE FRAGMENT ASTERISK $'*'$;
DEFINE FRAGMENT QUOTE $'\''$;
DEFINE FRAGMENT QUOTE_SYMBOL $($ + QUOTE + QUOTE + $)$;
DEFINE FRAGMENT NONQUOTE_CHARACTER $~($ + QUOTE + $|$ + NEWLINE + $)$;
DEFINE FRAGMENT DOUBLE_QUOTE $'"'$;
DEFINE FRAGMENT DOUBLEQUOTE_SYMBOL $($ + DOUBLE_QUOTE + DOUBLE_QUOTE + $)$;
DEFINE FRAGMENT NONDOUBLEQUOTE_CHARACTER $~($ + DOUBLE_QUOTE + $|$ + NEWLINE + $)$;
DEFINE FRAGMENT NEWLINE $('\r\n'|'\r'|'\n')$;
// Comments
DEFINE SIMPLE_COMMENT SIMPLE_COMMENT_INTRODUCER + $($ + COMMENT_CHARACTER + $)*$;
DEFINE FRAGMENT SIMPLE_COMMENT_INTRODUCER MINUS_SIGN + MINUS_SIGN;
DEFINE FRAGMENT COMMENT_CHARACTER $~('\n'|'\r'|'\uffff')$;
DEFINE BRACKETED_COMMENT BRACKETED_COMMENT_INTRODUCER + BRACKETED_COMMENT_CONTENTS + BRACKETED_COMMENT_TERMINATOR;
DEFINE FRAGMENT BRACKETED_COMMENT_INTRODUCER SLASH + ASTERISK;
DEFINE FRAGMENT BRACKETED_COMMENT_TERMINATOR ASTERISK + SLASH;
DEFINE FRAGMENT BRACKETED_COMMENT_CONTENTS $.*$; // TODO: Nested comments
// Literals
DEFINE UNSIGNED_INTEGER $($ + DIGIT + $)+$;
DEFINE EXACT_NUMERIC_LITERAL $($ + UNSIGNED_INTEGER + $($ + PERIOD + $($ + UNSIGNED_INTEGER + $)?)?|$ + PERIOD + UNSIGNED_INTEGER + $)$;
DEFINE APPROXIMATE_NUMERIC_LITERAL MANTISSA + $'E'$ + EXPONENT;
DEFINE FRAGMENT MANTISSA EXACT_NUMERIC_LITERAL;
DEFINE FRAGMENT EXPONENT SIGNED_INTEGER;
DEFINE FRAGMENT SIGNED_INTEGER SIGN + $?$ + UNSIGNED_INTEGER;
DEFINE QUOTED_STRING QUOTE + CHARACTER_REPRESENTATION + $*$ + QUOTE;
DEFINE FRAGMENT CHARACTER_REPRESENTATION $($ + NONQUOTE_CHARACTER + $|$ + QUOTE_SYMBOL + $)$;
// Names and identifiers
DEFINE IDENTIFIER ACTUAL_IDENTIFIER;
DEFINE FRAGMENT ACTUAL_IDENTIFIER $($ + REGULAR_IDENTIFIER + $|$ + DELIMITED_IDENTIFIER + $)$;
DEFINE FRAGMENT REGULAR_IDENTIFIER IDENTIFIER_BODY;
DEFINE FRAGMENT IDENTIFIER_BODY IDENTIFIER_START + IDENTIFIER_PART + $*$;
DEFINE FRAGMENT IDENTIFIER_PART $($ + IDENTIFIER_START + $|$ + IDENTIFIER_EXTEND + $)$;
DEFINE FRAGMENT IDENTIFIER_START $('A'..'Z'|'a'..'z')$; // TODO: \p{L} - \p{M}
DEFINE FRAGMENT IDENTIFIER_EXTEND $($ + DIGIT + $|$ + UNDERSCORE + $)$; // TODO: Support more characters
DEFINE FRAGMENT DELIMITED_IDENTIFIER DOUBLE_QUOTE + DELIMITED_IDENTIFIER_BODY + DOUBLE_QUOTE;
DEFINE FRAGMENT DELIMITED_IDENTIFIER_BODY DELIMITED_IDENTIFIER_PART + $+$;
DEFINE FRAGMENT DELIMITED_IDENTIFIER_PART $($ + NONDOUBLEQUOTE_CHARACTER + $|$ + DOUBLEQUOTE_SYMBOL + $)$;
}
Раскрасим токены:
TOKENSTYLES {
"SIMPLE_COMMENT", "BRACKETED_COMMENT"
COLOR #999999, ITALIC;
"QUOTED_STRING"
COLOR #000099, ITALIC;
"EXACT_NUMERIC_LITERAL", "APPROXIMATE_NUMERIC_LITERAL", "UNSIGNED_INTEGER"
COLOR #009900;
}
И, наконец, в секции RULES { } опишем синтаксис для классов из метамодели.6.1 Описание синтаксиса для скрипта в целом, комментариев и имён
Если вы читали предыдущую статью, то смысл этих правил для вас должен быть очевиден:
Common.SQLScript ::= (statements !0)*;
Common.SimpleComment ::= value[SIMPLE_COMMENT];
Common.BracketedComment ::= value[BRACKETED_COMMENT];
Common.SchemaQualifiedName ::= ((catalogName[IDENTIFIER] ".")? schemaName[IDENTIFIER] ".")? name[IDENTIFIER];
6.2 Описание синтаксиса для литералов
@SuppressWarnings(explicitSyntaxChoice)
Literal.ExactNumericLiteral ::= value[EXACT_NUMERIC_LITERAL] | value[UNSIGNED_INTEGER];
Literal.ApproximateNumericLiteral ::= value[APPROXIMATE_NUMERIC_LITERAL];
Literal.CharacterStringLiteral ::= ("_" characterSetName)? values[QUOTED_STRING] (separators values[QUOTED_STRING])*;
Literal.NationalCharacterStringLiteral ::= "N" values[QUOTED_STRING] (separators values[QUOTED_STRING])*;
Literal.DateLiteral ::= "DATE" value[QUOTED_STRING];
Literal.TimeLiteral ::= "TIME" value[QUOTED_STRING];
Literal.TimestampLiteral ::= "TIMESTAMP" value[QUOTED_STRING];
Literal.BooleanLiteral ::= value[ "TRUE" : "FALSE" ]?;
Стоит подробней остановиться на первом правиле. Регулярные выражения для токенов EXACT_NUMERIC_LITERAL и UNSIGNED_INTEGER пересекаются. Например, если вы напишите в SQL-скрипте число в десятичной системе исчисления без символа ».», то оно будет интерпретировано лексером как UNSIGNED_INTEGER. Затем парсер, увидев в последовательности токенов UNSIGNED_INTEGER вместо EXACT_NUMERIC_LITERAL, выдаст ошибку, что в этом месте ожидался другой токен. Поэтому при пересечении токенов приходится усложнять грамматику подобным образом.
Тут всё относительно просто. Стоит только обратить внимание на то, что в SQL есть многозначные токены. Например, «DATE» используется как для обозначения типа данных, так и для обозначения литералов. Если вы захотите, например, раскрасить токены, относящиеся к типам данных, и токены, относящиеся к литералам, в разные цвета, то в EMFText это сделать не так просто, потому что лексер не знает в каком именно контексте используется «DATE».
Datatype.ExactNumericType ::=
kind[ NUMERIC : "NUMERIC", DECIMAL : "DECIMAL", DEC : "DEC", SMALLINT : "SMALLINT",
INTEGER : "INTEGER", INT : "INT", BIGINT : "BIGINT" ]
("(" precision[UNSIGNED_INTEGER] ("," scale[UNSIGNED_INTEGER])? ")")?;
Datatype.ApproximateNumericType ::=
kind[ FLOAT : "FLOAT", REAL : "REAL", DOUBLE_PRECISION : "DOUBLE PRECISION" ]
("(" precision[UNSIGNED_INTEGER] ")")?;
Datatype.CharacterStringType ::=
kind[ CHARACTER : "CHARACTER", CHAR : "CHAR", VARCHAR : "VARCHAR",
CHARACTER_VARYING : "CHARACTER VARYING", CHAR_VARYING : "CHAR VARYING" ]
("(" length[UNSIGNED_INTEGER] ")")?
("CHARACTER" "SET" characterSetName)?
("COLLATE" collationName)?;
Datatype.NationalCharacterStringType ::=
kind[ NATIONAL_CHARACTER : "NATIONAL CHARACTER", NATIONAL_CHAR : "NATIONAL CHAR",
NATIONAL_CHARACTER_VARYING : "NATIONAL CHARACTER VARYING",
NATIONAL_CHAR_VARYING : "NATIONAL CHAR VARYING",
NCHAR : "NCHAR", NCHAR_VARYING : "NCHAR VARYING" ]
("(" length[UNSIGNED_INTEGER] ")")?
("COLLATE" collationName)?;
Datatype.BinaryLargeObjectStringType ::=
kind[ BINARY_LARGE_OBJECT : "BINARY LARGE OBJECT", BLOB : "BLOB" ]
("(" length ")")?;
Datatype.LargeObjectLength ::= value[UNSIGNED_INTEGER]
multiplier[ K : "K", M : "M", G : "G" ]?
units[ CHARACTERS : "CHARACTERS", CODE_UNITS : "CODE_UNITS", OCTETS : "OCTETS" ]?;
Datatype.DateType ::= "DATE";
Datatype.TimeType ::= "TIME"
("(" precision[UNSIGNED_INTEGER] ")")?
(withTimeZone["WITH" : "WITHOUT"] "TIME" "ZONE")?;
Datatype.TimestampType ::= "TIMESTAMP"
("(" precision[UNSIGNED_INTEGER] ")")?
(withTimeZone["WITH" : "WITHOUT"] "TIME" "ZONE")?;
Datatype.BooleanType ::= "BOOLEAN";
6.4 Описание синтаксиса для функций и выражений
Тут всё тривиально:
Function.DatetimeValueFunction ::=
kind[ CURRENT_DATE : "CURRENT_DATE", CURRENT_TIME : "CURRENT_TIME",
LOCALTIME : "LOCALTIME", CURRENT_TIMESTAMP : "CURRENT_TIMESTAMP",
LOCALTIMESTAMP : "LOCALTIMESTAMP" ]
("(" precision[UNSIGNED_INTEGER] ")")?;
Expression.NullSpecification ::= "NULL";
6.5 Описание синтаксиса для определений таблиц
Стоит обратить внимание на то, что во многих правилах есть повторяющиеся фрагменты. Которые можно было бы устранить, но за счёт усложнения метамодели. Так как в следующих статьях мы будем работать только с метамоделью, а о существовании грамматики забудем, то простая метамодель для нас важнее, чем простая грамматика.
Schema.TableReference ::= ((catalogName[IDENTIFIER] ".")? schemaName[IDENTIFIER] ".")? target[IDENTIFIER];
@SuppressWarnings(explicitSyntaxChoice)
Schema.TableDefinition ::= "CREATE"
( scope[ PERSISTENT : "" ]
| scope[ GLOBAL_TEMPORARY : "GLOBAL", LOCAL_TEMPORARY : "LOCAL" ] "TEMPORARY" )
"TABLE" schemaQualifiedName !0
contentsSource ";" !0;
Schema.TableElementList ::= "(" !1 elements ("," !1 elements)* !0 ")";
Schema.Column ::= name[IDENTIFIER] dataType
("DEFAULT" defaultOption)?
constraintDefinition?
("COLLATE" collationName)?;
Schema.LiteralDefaultOption ::= literal;
Schema.DatetimeValueFunctionDefaultOption ::= function;
Schema.ImplicitlyTypedValueSpecificationDefaultOption ::= specification;
Schema.NotNullColumnConstraint ::=
("CONSTRAINT" schemaQualifiedName)?
"NOT" "NULL";
Schema.UniqueColumnConstraint ::=
("CONSTRAINT" schemaQualifiedName)?
kind[ UNIQUE : "UNIQUE" , PRIMARY_KEY : "PRIMARY KEY" ];
Schema.ReferentialColumnConstraint ::=
("CONSTRAINT" schemaQualifiedName)?
"REFERENCES" referencedTable
("(" referencedColumns[IDENTIFIER] ("," referencedColumns[IDENTIFIER])* ")")?;
Schema.UniqueTableConstraint ::=
("CONSTRAINT" schemaQualifiedName)?
kind[ UNIQUE : "UNIQUE" , PRIMARY_KEY : "PRIMARY KEY" ]
"(" columns[IDENTIFIER] ("," columns[IDENTIFIER])* ")";
Schema.ReferentialTableConstraint ::=
("CONSTRAINT" schemaQualifiedName)?
"FOREIGN" "KEY" "(" columns[IDENTIFIER] ("," columns[IDENTIFIER])* ")"
"REFERENCES" referencedTable
("(" referencedColumns[IDENTIFIER] ("," referencedColumns[IDENTIFIER])* ")")?;
7 Разбор токенов
Лексер разбивает исходный код на последовательность строк. Большинство этих строк нужно либо преобразовывать в значения определённых типов данных (число, дата, время), либо оставлять в строковом виде, но вносить некоторые изменения (например, в строковых литералах нужно заменять две кавычки на одну).
Начнём с самого простого токена — однострочные комментарии.
package org.emftext.language.sql.resource.sql.analysis;
import java.util.Map;
import org.eclipse.emf.ecore.EObject;
import org.eclipse.emf.ecore.EStructuralFeature;
import org.emftext.language.sql.resource.sql.ISqlTokenResolveResult;
import org.emftext.language.sql.resource.sql.ISqlTokenResolver;
public class SqlSIMPLE_COMMENTTokenResolver implements ISqlTokenResolver {
public String deResolve(Object value, EStructuralFeature feature, EObject container) {
return "--" + ((String) value);
}
public void resolve(String lexem, EStructuralFeature feature, ISqlTokenResolveResult result) {
result.setResolvedToken(lexem.substring(2));
}
public void setOptions(Map options) {
}
}
7.2 Разбор идентификаторов
С идентификаторами ситуация немного сложнее. Если идентификатор не содержит спецсимволы и не является зарезервированным словом, то его можно указывать без кавычек. Иначе он должен указываться в двойных кавычках.
package org.emftext.language.sql.resource.sql.analysis;
import java.util.Map;
import org.eclipse.emf.ecore.EObject;
import org.eclipse.emf.ecore.EStructuralFeature;
import org.emftext.language.sql.resource.sql.ISqlTokenResolveResult;
import org.emftext.language.sql.resource.sql.ISqlTokenResolver;
public class SqlIDENTIFIERTokenResolver implements ISqlTokenResolver {
public String deResolve(Object value, EStructuralFeature feature, EObject container) {
return Helper.formatIdentifier((String) value);
}
public void resolve(String lexem, EStructuralFeature feature, ISqlTokenResolveResult result) {
try {
result.setResolvedToken(Helper.parseIdentifier(lexem));
}
catch (Exception e) {
result.setErrorMessage(e.getMessage());
}
}
public void setOptions(Map options) {
}
}
Мы реализовали очень маленькую часть SQL, поэтому приходится явно перечислять все зарезервированные слова (недопустимые в идентификаторах):
package org.emftext.language.sql.resource.sql.analysis;
import java.util.Arrays;
import java.util.HashSet;
import java.util.Set;
public class Helper {
private static final String DOUBLE_QUOTE = "\"";
private static final String DOUBLE_QUOTE_SYMBOL = "\"\"";
private static final Set
7.3 Разбор натуральных чисел
Для натуральных чисел (UNSIGNED_INTEGER) мы могли бы в метамодели использовать тип данных EInt, который отображается в примитивный Java-тип данных int. Но мы не ищем лёгких путей, поэтому создали собственный тип:
package org.emftext.language.sql;
public class UnsignedInteger {
private int value;
private UnsignedInteger(int value) {
this.value = value;
}
public static UnsignedInteger valueOf(String str) {
return new UnsignedInteger(Integer.parseUnsignedInt(str));
}
@Override
public String toString() {
return String.format("%d", value);
}
}
Дополнительно настраивать лексер не требуется, он сам догадается, что необходимо использовать методы valueOf и toString. Причём, это фича даже не EMFText, а EMF вообще. Например, при (де)сериализации в XMI-формате абстрактного синтаксического дерева для некоторого SQL-скрипта будут использоваться эти же самые методы.
Наконец, самое сложное в нашем примере — это разбор даты и времени. Проблема заключается в том, что в Ecore есть только один тип для представления даты и времени — EDate, который отображается в java.util.Date. Но в SQL может указываться временная зона, которая этим типом не поддерживается. Также в SQL может указываться время суток без даты, для чего EDate тоже не очень хорош.
EDataType.Internal.C
