Разработка нового статического анализатора: PVS-Studio Java

Статический анализатор PVS-Studio известен в мире C, C++ и C# как инструмент для выявления ошибок и потенциальных уязвимостей. Однако у нас мало клиентов из финансового сектора, так как выяснилось, что сейчас там востребованы Java и IBM RPG (!). Нам же всегда хотелось стать ближе к миру Enterprise, поэтому, после некоторых раздумий, мы приняли решение заняться созданием Java анализатора.
Введение
Конечно, были и опасения. Легко занять рынок анализаторов в IBM RPG. Я вообще не уверен, что существуют достойные инструменты для статического анализа этого языка. В мире Java дела обстоят совсем иначе. Уже есть линейка инструментов для статического анализа, и чтобы вырваться вперед, нужно создать действительно мощный и крутой анализатор.
Тем не менее, в нашей компании был опыт использования нескольких инструментов для статического анализа Java, и мы уверены, что многие вещи мы сможем сделать лучше.
Кроме того, у нас была идея, как задействовать всю мощь нашего С++ анализатора в Java анализаторе. Но обо всём по порядку.
Дерево
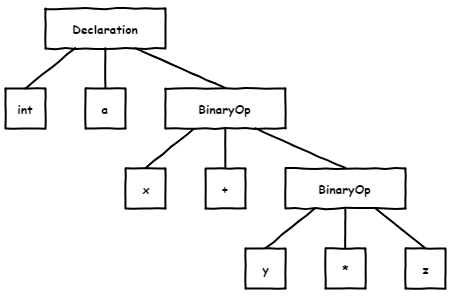
В первую очередь нужно было определиться с тем, каким образом мы будем получать синтаксическое дерево и семантическую модель.
Синтаксическое дерево является базовым элементом, вокруг которого строится анализатор. При выполнении проверок анализатор перемещается по синтаксическому дереву и исследует его отдельные узлы. Без такого дерева производить серьезный статический анализ практически невозможно. Например, поиск ошибок с помощью регулярных выражений является бесперспективным.
При этом стоит отметить, что одного лишь синтаксического дерева недостаточно. Анализатору необходима и семантическая информация. Например, нам нужно знать типы всех элементов дерева, иметь возможность перейти к объявлению переменной и т.п.
Мы рассмотрели несколько вариантов получения синтаксического дерева и семантической модели:
От идеи использования ANTLR мы отказались практически сразу, так как это неоправданно усложнило бы разработку анализатора (семантический анализ пришлось бы реализовывать своими силами). В конечном итоге решили остановиться на библиотеке Spoon:
- Является не просто парсером, а целой экосистемой — предоставляет не только дерево разбора, но и возможности для семантического анализа, например, позволяет получить информацию о типах переменных, перейти к объявлению переменной, получить информацию о родительском классе и так далее.
- Основывается на Eclipse JDT и умеет компилировать код.
- Поддерживает последнюю версию Java и постоянно обновляется.
- Неплохая документация и понятный API.
Вот пример метамодели, которую предоставляет Spoon, и с которой мы работаем при создании диагностических правил:
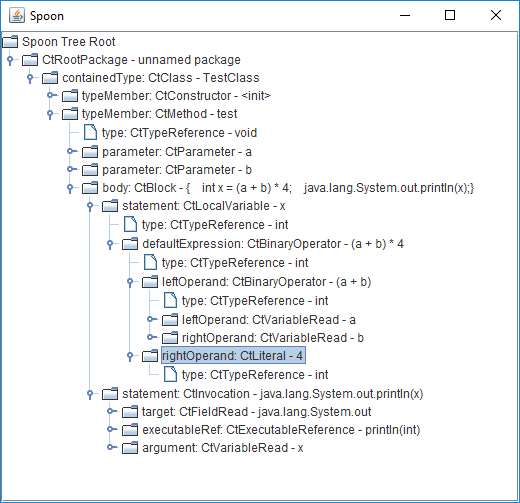
Эта метамодель соответствует следующему коду:
class TestClass
{
void test(int a, int b)
{
int x = (a + b) * 4;
System.out.println(x);
}
}
Одной из приятных особенностей Spoon является то, что он упрощает синтаксическое дерево (удаляя и добавляя узлы) для того, чтобы с ним было проще работать. При этом гарантируется семантическая эквивалентность упрощенной метамодели исходной.
Для нас это означает, например, что не нужно больше заботиться о пропуске лишних скобок при обходе дерева. Помимо этого, каждое выражение помещается в блок, раскрываются импорты, производятся еще некоторые похожие упрощения.
Например, такой код:
for (int i = ((0)); (i < 10); i++)
if (cond)
return (((42)));
будет представлен следующим образом:
for (int i = 0; i < 10; i++)
{
if (cond)
{
return 42;
}
}
На основе синтаксического дерева производится так называемый pattern-based анализ. Это поиск ошибок в исходном коде программы по известным шаблонам кода с ошибкой. В простейшем случае анализатор ищет в дереве места, похожие на ошибку, согласно правилам, описанным в соответствующей диагностике. Количество подобных шаблонов велико и их сложность может сильно варьироваться.
Простейшим примером ошибки, обнаруживаемой с помощью pattern-based анализа, может служить следующий код из проекта jMonkeyEngine:
if (p.isConnected()) {
log.log(Level.FINE, "Connection closed:{0}.", p);
}
else {
log.log(Level.FINE, "Connection closed:{0}.", p);
}
Блоки then и else оператора if полностью совпадают, скорее всего, имеется логическая ошибка.
Вот еще один подобный пример из проекта Hive:
if (obj instanceof Number) {
// widening conversion
return ((Number) obj).doubleValue();
} else if (obj instanceof HiveDecimal) { // <=
return ((HiveDecimal) obj).doubleValue();
} else if (obj instanceof String) {
return Double.valueOf(obj.toString());
} else if (obj instanceof Timestamp) {
return new TimestampWritable((Timestamp)obj).getDouble();
} else if (obj instanceof HiveDecimal) { // <=
return ((HiveDecimal) obj).doubleValue();
} else if (obj instanceof BigDecimal) {
return ((BigDecimal) obj).doubleValue();
}
В данном коде находятся два одинаковых условия в последовательности вида if (…) else if (…) else if (…). Стоит проверить этот участок кода на наличие логической ошибки, либо убрать дублирующий код.
Data-flow analysis
Помимо синтаксического дерева и семантической модели, анализатору необходим механизм анализа потока данных.
Анализ потока данных позволяет вычислять допустимые значения переменных и выражений в каждой точке программы и, благодаря этому, находить ошибки. Мы называем эти допустимые значения виртуальными значениями.
Виртуальные значения создаются для переменных, полей классов, параметров методов и прочего при первом упоминании. Если это присваивание, механизм Data Flow вычисляет виртуальное значение путем анализа выражения стоящего справа, в противном случае в качестве виртуального значения берется весь допустимый диапазон значений для данного типа переменной. Например:
void func(byte x) // x: [-128..127]
{
int y = 5; // y: [5]
...
}
При каждом изменении значения переменной механизм Data Flow пересчитывает виртуальное значение. Например:
void func()
{
int x = 5; // x: [5]
x += 7; // x: [12]
...
}
Механизм Data Flow также выполняет обработку управляющих операторов:
void func(int x) // x: [-2147483648..2147483647]
{
if (x > 3)
{
// x: [4..2147483647]
if (x < 10)
{
// x: [4..9]
}
}
else
{
// x: [-2147483648..3]
}
...
}
В данном примере при входе в функцию о диапазоне значений переменной x нет никакой информации, поэтому он устанавливается в соответствии с типом переменной (от -2147483648 до 2147483647). Затем первый условный блок накладывает ограничение x > 3, и диапазоны объединяются. В результате в then блоке диапазон значений для x: от 4 до 2147483647, а в else блоке от -2147483648 до 3. Аналогичным образом обрабатывается и второе условие x
Кроме того, необходимо иметь возможность производить и чисто символьные вычисления. Простейший пример:
void f1(int a, int b, int c)
{
a = c;
b = c;
if (a == b) // <= always true
....
}
Здесь переменной а присваивается значение c, переменной b также присваивается значение c, после чего а и b сравниваются. В этом случае, чтобы найти ошибку, достаточно просто запомнить кусок дерева, соответствующий правой части.
Вот чуть более сложный пример с символьными вычислениями:
void f2(int a, int b, int c)
{
if (a < b)
{
if (b < c)
{
if (c < a) // <= always false
....
}
}
}
В таких случаях уже приходится решать систему неравенств в символьном виде.
Механизм Data Flow помогает анализатору находить ошибки, которые с помощью pattern-based анализа найти весьма затруднительно.
К таким ошибкам относятся:
- Переполнения;
- Выход за границу массива;
- Доступ по нулевой или потенциально нулевой ссылке;
- Бессмысленные условия (always true/false);
- Утечки памяти и ресурсов;
- Деление на 0;
- И некоторые другие.
Data Flow анализ особенно важен при поиске уязвимостей. Например, в случае, если некая программа получает ввод от пользователя, есть вероятность, что ввод будет использован для того, чтобы вызвать отказ в обслуживании, или для получения контроля над системой. Примерами могут служить ошибки, приводящие к переполнениям буфера при некоторых входных данных, или, например, SQL-инъекции. В обоих случаях для того, чтобы статический анализатор мог выявлять подобные ошибки и уязвимости, необходимо отслеживать поток данных и возможные значения переменных.
Должен сказать, что механизм анализа потока данных — это сложный и обширный механизм, а в этой статье я коснулся лишь самых основ.
Рассмотрим несколько примеров ошибок, которые можно обнаружить с помощью механизма Data Flow.
Проект Hive:
public static boolean equal(byte[] arg1, final int start1,
final int len1, byte[] arg2,
final int start2, final int len2) {
if (len1 != len2) { // <=
return false;
}
if (len1 == 0) {
return true;
}
....
if (len1 == len2) { // <=
....
}
}
Условие len1 == len2 выполняется всегда, поскольку противоположная проверка уже была выполнена выше.
Еще один пример из этого же проекта:
if (instances != null) { // <=
Set oldKeys = new HashSet<>(instances.keySet());
if (oldKeys.removeAll(latestKeys)) {
....
}
this.instances.keySet().removeAll(oldKeys);
this.instances.putAll(freshInstances);
} else {
this.instances.putAll(freshInstances); // <=
}
Здесь в блоке else гарантированно происходит разыменование нулевого указателя. Примечание: здесь instances — это то же самое, что и this.instances.
Пример из проекта JMonkeyEngine:
public static int convertNewtKey(short key) {
....
if (key >= 0x10000) {
return key - 0x10000;
}
return 0;
}
Здесь переменная key сравнивается с числом 65536, однако, она имеет тип short, а максимально возможное значение для short — это 32767. Соответственно, условие никогда не выполняется.
Пример из проекта Jenkins:
public final R getSomeBuildWithWorkspace()
{
int cnt = 0;
for (R b = getLastBuild();
cnt < 5 && b ! = null;
b = b.getPreviousBuild())
{
FilePath ws = b.getWorkspace();
if (ws != null) return b;
}
return null;
}
В данном коде ввели переменную cnt, чтобы ограничить количество проходов пятью, но забыли ее инкрементировать, в результате чего проверка бесполезна.
Механизм аннотаций
Кроме того, анализатору нужен механизм аннотаций. Аннотации — это система разметки, которая предоставляет анализатору дополнительную информацию об используемых методах и классах, помимо той, что может быть получена путем анализа их сигнатуры. Разметка производится вручную, это долгий и трудоемкий процесс, так как для достижения наилучших результатов необходимо проаннотировать большое количество стандартных классов и методов языка Java. Также имеет смысл выполнить аннотирование популярных библиотек. В целом аннотации можно рассматривать как базу знаний анализатора о контрактах стандартных методов и классов.
Вот небольшой пример ошибки, которую можно обнаружить с помощью аннотаций:
int test(int a, int b) {
...
return Math.max(a, a);
}
В данном примере из-за опечатки в качестве второго аргумента метода Math.max была передана та же переменная, что и в качестве первого аргумента. Такое выражение является бессмысленным и подозрительным.
Зная о том, что аргументы метода Math.max всегда должны быть различны, статический анализатор сможет выдать предупреждение на подобный код.
Забегая вперед, приведу несколько примеров нашей разметки встроенных классов и методов (код на C++):
Class("java.lang.Math")
- Function("abs", Type::Int32)
.Pure()
.Set(FunctionClassification::NoDiscard)
.Returns(Arg1, [](const Int &v)
{ return v.Abs(); })
- Function("max", Type::Int32, Type::Int32)
.Pure()
.Set(FunctionClassification::NoDiscard)
.Requires(NotEquals(Arg1, Arg2)
.Returns(Arg1, Arg2, [](const Int &v1, const Int &v2)
{ return v1.Max(v2); })
Class("java.lang.String", TypeClassification::String)
- Function("split", Type::Pointer)
.Pure()
.Set(FunctionClassification::NoDiscard)
.Requires(NotNull(Arg1))
.Returns(Ptr(NotNullPointer))
Class("java.lang.Object")
- Function("equals", Type::Pointer)
.Pure()
.Set(FunctionClassification::NoDiscard)
.Requires(NotEquals(This, Arg1))
Class("java.lang.System")
- Function("exit", Type::Int32)
.Set(FunctionClassification::NoReturn)
Пояснения:
- Class — аннотируемый класс;
- Function — метод аннотируемого класса;
- Pure — аннотация, показывающая, что метод является чистым, т.е. детерминированным и не имеющим побочных эффектов;
- Set — установка произвольного флага для метода.
- FunctionClassification: NoDiscard — флаг, означающий, что возвращаемое значение метода обязательно должно быть использовано;
- FunctionClassification: NoReturn — флаг, означающий, что метод не возвращает управление;
- Arg1, Arg2, …, ArgN — аргументы метода;
- Returns — возвращаемое значение метода;
- Requires — контракт на метод.
Стоит отметить, что помимо ручной разметки существует еще один поход к аннотированию — автоматический вывод контрактов на основе байт-кода. Понятно, что такой подход позволяет вывести только определенные виды контрактов, но зато он дает возможность получать дополнительную информацию вообще из всех зависимостей, а не только из тех, что были проаннотированы вручную.
К слову, уже существует инструмент, который умеет выводить контракты вроде @Nullable, NotNull на основе байт-кода — FABA. Насколько я понимаю, производная от FABA используется в IntelliJ IDEA.
Сейчас мы тоже рассматриваем возможность добавления анализа байт-кода для получения контрактов для всех методов, так как эти контракты могли бы хорошо дополнить наши ручные аннотации.
Диагностические правила при работе часто обращаются к аннотациям. Помимо диагностик, аннотации использует механизм Data Flow. Например, используя аннотацию метода java.lang.Math.abs, он может точно вычислять значение для модуля числа. При этом писать какой-либо дополнительный код не приходится — только правильно разметить метод.
Рассмотрим пример ошибки из проекта Hibernate, которую можно обнаружить благодаря аннотации:
public boolean equals(Object other) {
if (other instanceof Id) {
Id that = (Id) other;
return purchaseSequence.equals(this.purchaseSequence) &&
that.purchaseNumber == this.purchaseNumber;
}
else {
return false;
}
}
В данном коде метод equals () сравнивает объект purchaseSequence с самим собой. Наверняка это опечатка и справа должно быть that.purchaseSequence, а не purchaseSequence.
Как доктор Франкенштейн собирал из частей анализатор
Поскольку сами по себе механизмы Data Flow и аннотаций не сильно привязаны к определенному языку, было принято решение переиспользовать эти механизмы из нашего C++ анализатора. Это позволило нам в короткие сроки получить всю мощь ядра C++ анализатора в нашем Java анализаторе. Кроме того, на это решение также повлияло и то, что эти механизмы были написаны на современном C++ с кучей метапрограммирования и шаблонной магии, а, соответственно, не очень хорошо подходят для переноса на другой язык.
Для того, чтобы связать Java часть с ядром на C++, мы решили использовать SWIG (Simplified Wrapper and Interface Generator) — средство для автоматической генерации врапперов и интерфейсов для связывания программ на C и C++ с программами, написанными на других языках. Для Java SWIG генерирует код на JNI (Java Native Interface).
SWIG отлично подходит для случаев, когда имеется уже большой объем C++ кода, который необходимо интегрировать в Java проект.
Приведу минимальный пример работы со SWIG. Предположим, у нас есть C++ класс, который мы хотим использовать в Java проекте:
CoolClass.h
class CoolClass
{
public:
int val;
CoolClass(int val);
void printMe();
};
CoolClass.cpp
#include
#include "CoolClass.h"
CoolClass::CoolClass(int v) : val(v) {}
void CoolClass::printMe()
{
std::cout << "val: " << val << '\n';
}
Сперва нужно создать интерфейсный файл SWIG с описанием всех экспортируемых функций и классов. Также в этом файле при необходимости производятся дополнительные настройки.
Example.i
%module MyModule
%{
#include "CoolClass.h"
%}
%include "CoolClass.h"
После этого можно запускать SWIG:
$ swig -c++ -java Example.i
Он сгенерирует следующие файлы:
- CoolClass.java — класс, с которым мы будем непосредственно работать в Java проекте;
- MyModule.java — класс модуля, в который помещаются все свободные функции и переменные;
- MyModuleJNI.java — Java врапперы;
- Example_wrap.cxx — С++ врапперы.
Теперь нужно просто добавить получившиеся .java файлы в Java проект и .cxx файл в C++ проект.
Наконец, нужно скомпилировать C++ проект в виде динамической библиотеки и подгрузить ее в Java проект с помощью System.loadLibary ():
App.java
class App {
static {
System.loadLibary("example");
}
public static void main(String[] args) {
CoolClass obj = new CoolClass(42);
obj.printMe();
}
}
Схематически это можно представить следующим образом:
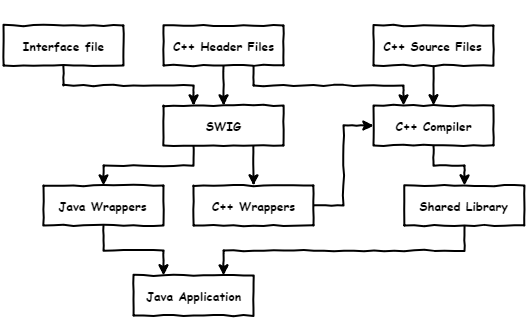
Конечно, в реальном проекте все не настолько просто и приходится приложить чуть больше усилий:
- Для того, чтобы использовать шаблонные классы и методы из C++, их нужно инстанцировать для всех принимаемых шаблонных параметров с помощью директивы %template;
- В некоторых случаях может понадобиться перехватывать исключения, которые выбрасываются из C++ части в Java части. По умолчанию SWIG не перехватывает исключения из C++ (возникает segfault), однако, имеется возможность это сделать, используя директиву %exception;
- SWIG позволяет расширять плюсовый код на стороне Java, используя директиву %extend. Мы, например, в нашем проекте добавляем к виртуальным значениям метод toString (), чтобы можно было их просмотреть в отладчике Java;
- Для того, чтобы эмулировать RAII поведение из C++, во всех интересующих классах реализуется интерфейс AutoClosable;
- Механизм директоров позволяет использовать кросс-языковый полиморфизм;
- Для типов, которые аллоцируются только внутри C++ (на своём пуле памяти), убираются конструкторы и финализаторы, чтобы повысить производительность. Сборщик мусора будет игнорировать эти типы.
Подробнее обо всех этих механизмах можно почитать в документации SWIG.
Наш анализатор собирается при помощи gradle, который зовет CMake, который, в свою очередь, зовет SWIG и собирает C++ часть. Для программистов это происходит практически незаметно, так что никаких особых неудобств при разработке мы не испытываем.
Ядро нашего C++ анализатора собирается под Windows, Linux, macOS, так что Java анализатор также работает в этих ОС.
Что из себя представляет диагностическое правило?
Сами диагностики и код для анализа мы пишем на Java. Это обусловлено тесным взаимодействием со Spoon. Каждое диагностическое правило является визитором, у которого перегружаются методы, в которых обходятся интересующие нас элементы:

Например, так выглядит каркас диагностики V6004:
class V6004 extends PvsStudioRule
{
....
@Override
public void visitCtIf(CtIf ifElement)
{
// if ifElement.thenStatement statement is equivalent to
// ifElement.elseStatement statement => add warning V6004
}
}
Плагины
Для максимально простой интеграции статического анализатора в проект мы разработали плагины для сборочных систем Maven и Gradle. Пользователю остается только добавить наш плагин к проекту.
Для Gradle:
....
apply plugin: com.pvsstudio.PvsStudioGradlePlugin
pvsstudio {
outputFile = 'path/to/output.json'
....
}
Для Maven:
....
com.pvsstudio
pvsstudio-maven-plugin
0.1
path/to/output.json
....
После этого плагин самостоятельно получит структуру проекта и запустит анализ.
Помимо этого, мы разработали прототип плагина для IntelliJ IDEA.
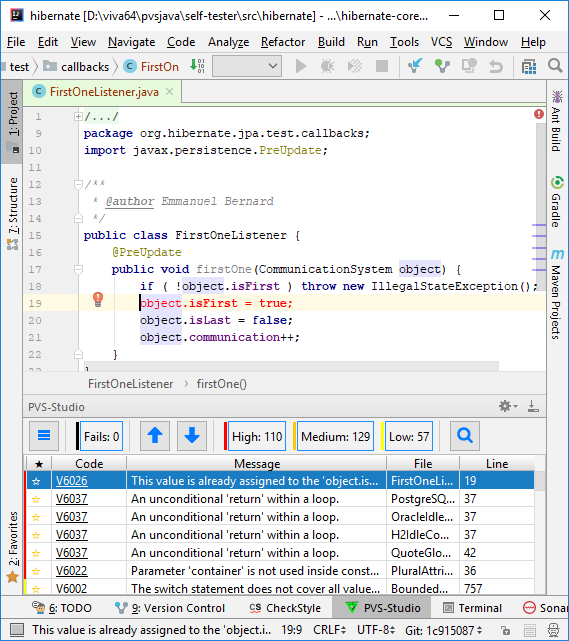
Также этот плагин работает и в Android Studio.
Плагин для Eclipse сейчас находится в стадии разработки.
Инкрементальный анализ
Мы предусмотрели режим инкрементального анализа, который позволяет проверять только измененные файлы и тем самым значительно сокращает время, необходимое для анализа кода. Благодаря этому, разработчики смогут запускать анализ так часто, как это необходимо.
Инкрементальный анализ включает в себя несколько этапов:
- Кеширование метамодели Spoon;
- Перестроение изменившейся части метамодели;
- Анализ изменившихся файлов.
Наша система тестирования
Для тестирования Java анализатора на реальных проектах мы написали специальный инструментарий, позволяющий работать с базой открытых проектов. Он был написан на коленке^W Python + Tkinter и является кроссплатформенным.
Он работает следующим образом:
- Тестируемый проект определенной версии выкачивается с репозитория на GitHub;
- Выполняется сборка проекта;
- В pom.xml или build.gradle добавляется наш плагин (при помощи git apply);
- Выполняется запуск статического анализатора при помощи плагина;
- Получившийся отчет сравнивается с эталоном для этого проекта.
Такой подход гарантирует, что хорошие срабатывания не пропадут в результате изменения кода анализатора. Ниже показан интерфейс нашей утилиты для тестирования.
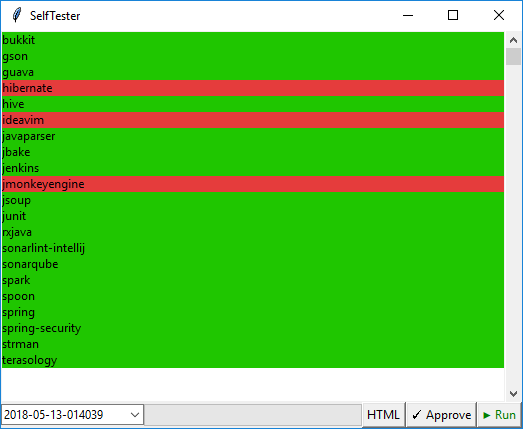
Красным отмечаются те проекты, в отчетах которых есть какие-либо различия с эталоном. Кнопка Approve позволяет сохранить текущую версию отчета в качестве эталона.
Примеры ошибок
По традиции приведу по несколько ошибок из разных открытых проектов, которые нашел наш Java анализатор. В будущем планируется написание статей с более детальным отчетом по каждому проекту.
Проект Hibernate
Предупреждение PVS-Studio: V6009 Function 'equals' receives odd arguments. Inspect arguments: this, 1. PurchaseRecord.java 57
public boolean equals(Object other) {
if (other instanceof Id) {
Id that = (Id) other;
return purchaseSequence.equals(this.purchaseSequence) &&
that.purchaseNumber == this.purchaseNumber;
}
else {
return false;
}
}
В данном коде метод equals () сравнивает объект purchaseSequence с самим собой. Скорее всего, это опечатка и справа должно быть that.purchaseSequence, а не purchaseSequence.
Предупреждение PVS-Studio: V6009 Function 'equals' receives odd arguments. Inspect arguments: this, 1. ListHashcodeChangeTest.java 232
public void removeBook(String title) {
for( Iterator it = books.iterator(); it.hasNext(); ) {
Book book = it.next();
if ( title.equals( title ) ) {
it.remove();
}
}
}
Срабатывание, аналогичное предыдущему — справа должно быть book.title, а не title.
Проект Hive
Предупреждение PVS-Studio: V6007 Expression 'colOrScalar1.equals («Column»)' is always false. GenVectorCode.java 2768
Предупреждение PVS-Studio: V6007 Expression 'colOrScalar1.equals («Scalar»)' is always false. GenVectorCode.java 2774
Предупреждение PVS-Studio: V6007 Expression 'colOrScalar1.equals («Column»)' is always false. GenVectorCode.java 2785
String colOrScalar1 = tdesc[4];
....
if (colOrScalar1.equals("Col") &&
colOrScalar1.equals("Column")) {
....
} else if (colOrScalar1.equals("Col") &&
colOrScalar1.equals("Scalar")) {
....
} else if (colOrScalar1.equals("Scalar") &&
colOrScalar1.equals("Column")) {
....
}
Здесь явно перепутали операторы и вместо '||' использовали '&&'.
Проект JavaParser
Предупреждение PVS-Studio: V6001 There are identical sub-expressions 'tokenRange.getBegin ().getRange ().isPresent ()' to the left and to the right of the '&&' operator. Node.java 213
public Node setTokenRange(TokenRange tokenRange)
{
this.tokenRange = tokenRange;
if (tokenRange == null ||
!(tokenRange.getBegin().getRange().isPresent() &&
tokenRange.getBegin().getRange().isPresent()))
{
range = null;
}
else
{
range = new Range(
tokenRange.getBegin().getRange().get().begin,
tokenRange.getEnd().getRange().get().end);
}
return this;
}
Анализатор обнаружил, что слева и справа от оператора && стоят одинаковые выражения (при этом все методы в цепочке вызовов являются чистыми). Скорее всего, во втором случае необходимо использовать tokenRange.getEnd (), а не tokenRange.getBegin ().
Предупреждение PVS-Studio: V6016 Suspicious access to element of 'typeDeclaration.getTypeParameters ()' object by a constant index inside a loop. ResolvedReferenceType.java 265
if (!isRawType()) {
for (int i=0; i(typeDeclaration.getTypeParams().get(0),
typeParametersValues().get(i)));
}
}
Анализатор обнаружил подозрительный доступ к элементу коллекции по константному индексу внутри цикла. Возможно, в данном коде присутствует ошибка.
Проект Jenkins
Предупреждение PVS-Studio: V6007 Expression 'cnt
public final R getSomeBuildWithWorkspace()
{
int cnt = 0;
for (R b = getLastBuild();
cnt < 5 && b ! = null;
b = b.getPreviousBuild())
{
FilePath ws = b.getWorkspace();
if (ws != null) return b;
}
return null;
}
В данном коде ввели переменную cnt, чтобы ограничить количество проходов пятью, но забыли ее инкрементировать, в результате чего проверка бесполезна.
Проект Spark
Предупреждение PVS-Studio: V6007 Expression 'sparkApplications!= null' is always true. SparkFilter.java 127
if (StringUtils.isNotBlank(applications))
{
final String[] sparkApplications = applications.split(",");
if (sparkApplications != null && sparkApplications.length > 0)
{
...
}
}
Проверка на null результата, возвращаемого методом split, бессмысленна, так как этот метод всегда возвращает коллекцию и никогда не возвращает null.
Проект Spoon
Предупреждение PVS-Studio: V6001 There are identical sub-expressions '! m.getSimpleName ().startsWith («set»)' to the left and to the right of the '&&' operator. SpoonTestHelpers.java 108
if (!m.getSimpleName().startsWith("set") &&
!m.getSimpleName().startsWith("set")) {
continue;
}
В данном коде слева и справа от оператора && стоят одинаковые выражения (при этом все методы в цепочке вызовов являются чистыми). Скорее всего, в коде присутствует логическая ошибка.
Предупреждение PVS-Studio: V6007 Expression 'idxOfScopeBoundTypeParam >= 0' is always true. MethodTypingContext.java 243
private boolean
isSameMethodFormalTypeParameter(....) {
....
int idxOfScopeBoundTypeParam = getIndexOfTypeParam(....);
if (idxOfScopeBoundTypeParam >= 0) { // <=
int idxOfSuperBoundTypeParam = getIndexOfTypeParam(....);
if (idxOfScopeBoundTypeParam >= 0) { // <=
return idxOfScopeBoundTypeParam == idxOfSuperBoundTypeParam;
}
}
....
}
Здесь опечатались во втором условии и вместо idxOfSuperBoundTypeParam написали idxOfScopeBoundTypeParam.
Проект Spring Security
Предупреждение PVS-Studio: V6001 There are identical sub-expressions to the left and to the right of the '||' operator. Check lines: 38, 39. AnyRequestMatcher.java 38
@Override
@SuppressWarnings("deprecation")
public boolean equals(Object obj) {
return obj instanceof AnyRequestMatcher ||
obj instanceof security.web.util.matcher.AnyRequestMatcher;
}
Срабатывание аналогично предыдущему — здесь имя одного и того же класса записано разными способами.
Предупреждение PVS-Studio: V6006 The object was created but it is not being used. The 'throw' keyword could be missing. DigestAuthenticationFilter.java 434
if (!expectedNonceSignature.equals(nonceTokens[1])) {
new BadCredentialsException(
DigestAuthenticationFilter.this.messages
.getMessage("DigestAuthenticationFilter.nonceCompromised",
new Object[] { nonceAsPlainText },
"Nonce token compromised {0}"));
}
В данном коде забыли добавить throw перед исключением. В результате объект исключения BadCredentialsException создается, но никак не используется, т.е. исключение не выбрасывается.
Предупреждение PVS-Studio: V6030 The method located to the right of the '|' operators will be called regardless of the value of the left operand. Perhaps, it is better to use '||'. RedirectUrlBuilder.java 38
public void setScheme(String scheme) {
if (!("http".equals(scheme) | "https".equals(scheme))) {
throw new IllegalArgumentException("...");
}
this.scheme = scheme;
}
В данном коде использование оператора | неоправданно, так как при его использовании правая часть будет вычислена даже в случае, если левая часть уже является истинной. В данном случае это не имеет практического смысла, поэтому оператор | стоит заменить на ||.
Проект IntelliJ IDEA
Предупреждение PVS-Studio: V6008 Potential null dereference of 'editor'. IntroduceVariableBase.java:609
final PsiElement nameSuggestionContext =
editor == null ? null : file.findElementAt(...); // <=
final RefactoringSupportProvider supportProvider =
LanguageRefactoringSupport.INSTANCE.forLanguage(...);
final boolean isInplaceAvailableOnDataContext =
supportProvider != null &&
editor.getSettings().isVariableInplaceRenameEnabled() && // <=
...
Анализатор обнаружил, что в данном коде может произойти разыменование нулевого указателя editor. Стоит добавить дополнительную проверку.
Предупреждение PVS-Studio: V6007 Expression is always false. RefResolveServiceImpl.java:814
@Override
public boolean contains(@NotNull VirtualFile file) {
....
return false & !myProjectFileIndex.isUnderSourceRootOfType(....);
}
Мне сложно сказать, что имел в виду автор, но такой код выглядит весьма подозрительно. Даже если вдруг ошибки здесь нет, думаю, стоит переписать это место так, чтобы не смущать анализатор и других программистов.
Предупреждение PVS-Studio: V6007 Expression 'result[0]' is always false. CopyClassesHandler.java:298
final boolean[] result = new boolean[] {false}; // <=
Runnable command = () -> {
PsiDirectory target;
if (targetDirectory instanceof PsiDirectory) {
target = (PsiDirectory)targetDirectory;
} else {
target = WriteAction.compute(() ->
((MoveDestination)targetDirectory).getTargetDirectory(
defaultTargetDirectory));
}
try {
Collection files =
doCopyClasses(classes, map, copyClassName, target, project);
if (files != null) {
if (openInEditor) {
for (PsiFile file : files) {
CopyHandler.updateSelectionInActiveProjectView(
file,
project,
selectInActivePanel);
}
EditorHelper.openFilesInEditor(
files.toArray(PsiFile.EMPTY_ARRAY));
}
}
}
catch (IncorrectOperationException ex) {
Messages.showMessageDialog(project,
ex.getMessage(),
RefactoringBundle.message("error.title"),
Messages.getErrorIcon());
}
};
CommandProcessor processor = CommandProcessor.getInstance();
processor.executeCommand(project, command, commandName, null);
if (result[0]) { // <=
ToolWindowManager.getInstance(project).invokeLater(() ->
ToolWindowManager.getInstance(project)
.activateEditorComponent());
}
Подозреваю, что здесь забыли как-либо изменить значение в result. Из-за этого анализатор сообщает о том, что проверка if (result[0]) является бессмысленной.
Заключение
Java направление является весьма разносторонним — это и desktop, и android, и web, и многое другое, поэтому у нас есть большой простор для деятельности. В первую очередь, конечно, будем развивать те направления, что будут наиболее востребованы.
Вот наши планы на ближайшее будущее:
- Вывод аннотаций на основе байт-кода;
- Интеграция в проекты на Ant (кто-то его еще использует в 2018?);
- Плагин для Eclipse (в процессе разработки);
- Еще больше диагностик и аннотаций;
- Совершенствование механизма Data Flow.
Также предлагаю желающим поучаствовать в тестировании альфа-версии нашего Java анализатора, когда она станет доступной. Для этого напишите нам в поддержку. Мы внесем ваш контакт в список и напишем вам, когда подготовим первую альфа-версию.

Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Egor Bredikhin. Development of a new static analyzer:
