Разработка на CUBA — большой шаг в сторону от Spring?
Когда вы читаете требования к очередному корпоративному веб-приложению для внутреннего использования, то обычно (сужу по своему опыту) это один и тот же набор: реляционная база для хранения данных, зачастую доставшаяся от предыдущей версии приложения, большое количество форм разного уровня сложности (но одновременно типовых) для ввода данных, множество форм отчетности, сложная бизнес-логика, интеграции с другими приложениями — от бухгалтерии до управления поставками, несколько тысяч одновременно работающих пользователей. Что обычно приходит в голову?
«Так, возьму СУБД, которую я знаю и которая подойдет под их объемы данных, прикручу Hibernate/JPA, приложение напишу на Spring Boot, выставлю REST API и напишу клиент на JS фреймворке, скорее всего Angular/React».
«Ага, надо еще Spring Security прикрутить. И написать ограничение по доступу к данным для разных отделов и ролей — на уровне строк БД или объектов данных. Как бы это сделать? Представления или VPD, надо будет посмотреть».
«Уф, надо будет написать кучу DAO — они делаются быстро, но их много».
«И конверсия из Entity в DTO — запользую ModelMapper ».
«Главное — не забыть напомнить практиканту про lazy атрибуты и joins, чтобы не было, как в прошлый раз».
«Елки-палки, пока к бизнес-логике приступишь, столько служебного кода написать надо…»
Эта статья для тех, кто написал хотя бы пару корпоративных приложений с нуля на Spring/Spring Boot и теперь думает о том, что было бы неплохо как-то ускорить разработку таких вот разных, но в то же время однотипных приложений. Далее мы посмотрим, как можно избавиться от «типовых» задач при помощи CUBA Platform.
Еще один фреймворк?

Мысль номер один, когда разработчику предлагают новый фреймворк (и, в частности, CUBA), это: «Зачем мне с этим возиться? Я возьму привычный и знакомый Spring Boot и на нем все запилю». И это резонно. Новый фреймворк — это изучение новых подходов к разработке, новые подводные камни и ограничения, которые вы научились ловко избегать при разработке в знакомом фреймворке.
Но, когда я начал разрабатывать на CUBA, мне не пришлось сильно менять свои навыки работы со Spring. Естественно, пришлось потратить немного времени на понимание устройства платформы, но это была не коренная ломка всех привычек, а, скорее, небольшой сдвиг в навыках разработки.
В результате исчез код для DTO, постраничного вывода данных, фильтрации данных (анализ передаваемых в форму параметров и составление запросов). Заодно почти не пришлось ковыряться с настройками Spring Security и писать код админки, формы логина и логику переключения языка пользовательского интерфейса.
Начнем с самого начала и посмотрим, как разработка на CUBA соотносится с привычным способом разработки на Spring и как, используя свой опыт и изучив несколько новых вещей, можно, в конечном итоге, быстрее создавать приложения.
Основное внимание в статье уделяется разработке серверной части, чтобы не терять фокус и сохранить объем текста на приемлемом уровне.
Архитектура приложений на Spring
В 90% случаев, набрав в гугле «Spring Application Architecture» или «архитектура приложений Spring», вы увидите подобную картинку. Классическое трехслойное приложение с модулями, общими для некоторых слоев.
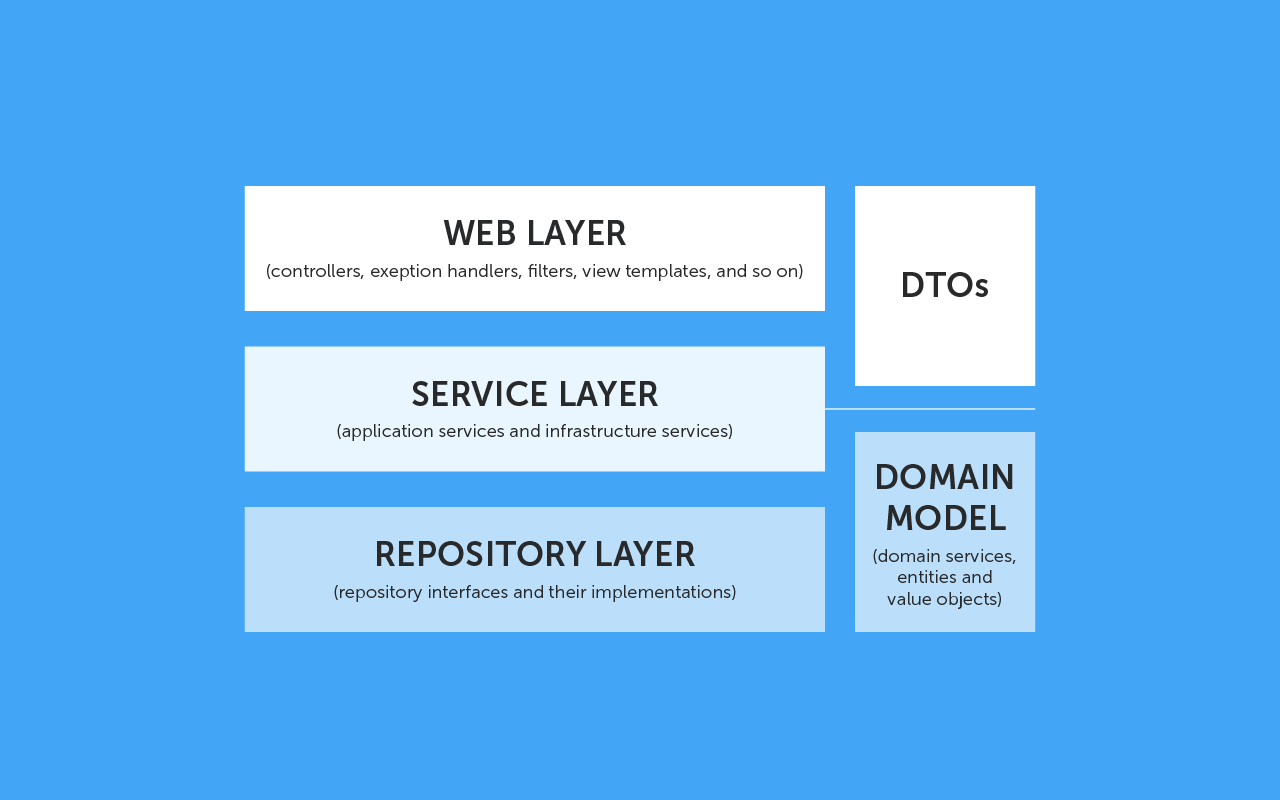
Domain Model (Доменная модель) — классы-сущности предметной области (Entities), хранящиеся, как правило, в базе данных. Классы создаются обычно вручную, но можно построить структуру автоматически, на основе схемы БД.
Repository Layer (Слой репозиториев) — набор классов, которые обеспечивают работу с хранилищем данных. Как правило, этот слой использует различные ORM фреймворки и содержит логику для выполнения CRUD операций. Если говорить о Spring, то репозитории получаются достаточно компактными, в основном за счет JPA Query methods, но зачастую приходится писать логику выборки из базы и отображение на доменную модель вручную.
Service Layer (Слой сервисов) — слой приложения, который содержит реализацию бизнес-логики, алгоритмы обработки информации, специфичные для предметной области. Это полезно в случае сложных алгоритмов обработки, а также для работы с данными из разных источников (БД, внешние приложения, сервисы из Интернета и т.д.).
Web/Controllers Layer (Слой контроллеров) — классы, отвечающие за REST API. На этом слое также могут находиться файлы шаблонов страниц, если мы используем фреймворк типа Thymeleaf, Velocity, а также классы, отвечающие за отрисовку и обработку событий пользовательского интерфейса, если используется что-то типа GWT, Vaadin, Wicket, и т.д.  Обычно контроллеры работают с DTO, а не с классами из доменного слоя, поэтому в приложение добавляется функциональность по конвертации DTO в Entity и обратно.
Обычно контроллеры работают с DTO, а не с классами из доменного слоя, поэтому в приложение добавляется функциональность по конвертации DTO в Entity и обратно.
Если все вышенаписанное для вас очевидно или даже «очередное капитанство» — это отлично. Значит, сможете начать работать с CUBA без проблем.
Эталонное приложение — Pet Clinic
Давайте рассмотрим конкретный пример и напишем немного кода. Для Spring есть «эталонное» приложение — Pet Clinic на GitHub. Это приложение создано в разных вариантах с использованием разных инструментов — от классического Spring до Kotlin и Angular. Дальше мы посмотрим, как можно сделать это приложение на CUBA. Для тех, кто не знаком со Spring-версией, есть хороший текст тут; в этой статье будут использоваться выдержки из него.
Модель данных

ER-диаграмма приведена на рисунке выше. Доменная модель повторяет эту структуру, в нее добавлены несколько классов с общими полями и от них уже унаследованы классы-сущности. UML можно найти в презентации, о которой я упоминал ранее.
Слой репозиториев
В приложении четыре репозитория, которые отвечают за работу с сущностями Owner (Владелец), Pet (Питомец), Visit (Посещение) и Vet (Ветеринар). Репозитории написаны с использованием Spring JPA и практически не содержат кода, только объявления методов. Однако в репозитории, который работает с сущностью Owner, добавлен запрос, который позволяет извлечь из БД владельцев и их питомцев в одной выборке.
Пользовательский интерфейс
В Pet Clinic девять страничек, которые позволяют просматривать список владельцев, их питомцев, а также список ветеринаров. Приложение предоставляет простую CRUD-функциональность: возможно редактирование некоторых данных — владельцев, питомцев, а также можно добавлять посещения клиники. Но, как уже было сказано, мы не будем глубоко обсуждать пользовательский интерфейс в этой статье.
Дополнительно
Кроме кода для простых манипуляций с сущностями, в приложении есть интересная функциональность, которая призвана показать возможности Spring:
- Кэширование — список ветеринаров выбирается из БД только один раз, затем сохраняется в кэше до перезапуска сервера приложений.
- Проверка заполненности обязательных полей при вводе информации о новом питомце.
- Форматирование типа животного перед выводом на экран.
- i18n — приложение поддерживает английский и немецкий языки.
- Управление транзакциями — некоторые транзакции помечены как «только чтение».
Заметки на полях
 Мне очень нравится эта картинка. Она на 100% отражает мои ощущения во время работы с фреймворками. Чтобы эффективно пользоваться фреймворком, надо обязательно понимать, как он там внутри устроен (кто бы что ни говорил). Например, многие ли из вас задумывались, сколько классов надо, чтобы заставить работать JPA интерфейс?
Мне очень нравится эта картинка. Она на 100% отражает мои ощущения во время работы с фреймворками. Чтобы эффективно пользоваться фреймворком, надо обязательно понимать, как он там внутри устроен (кто бы что ни говорил). Например, многие ли из вас задумывались, сколько классов надо, чтобы заставить работать JPA интерфейс?
Даже в таком небольшом приложении, как Pet Clinic, есть немного магии Spring Boot:
- Никакой конфигурации для кэша нет (кроме аннотации
@Caсheable), однако Spring Boot «знает», как запустить нужный кэш (EhCache в этом случае). - CRUD Репозитории не помечены аннотацией
@Transactional(и их родительский классorg.springframework.data.repository.Repositoryтоже), но все методыsave()отрабатывают, как надо.
Но, несмотря на все «неявности», Spring Boot очень популярен. Почему? Он прозрачный и предсказуемый. Хорошая документация и открытый исходный код позволяют понять принципы и, при необходимости, углубиться в детали реализации. Мне кажется, все любят такие фреймворки, прозрачность и предсказуемость — залог стабильности и поддерживаемости приложения.
Pet Clinic на платформе CUBA
Что ж, давайте посмотрим на Pet Clinic, которое было сделано с использованием CUBA, с точки зрения Spring разработчика и попробуем понять, где можно сэкономить.
Исходный код приложения можно найти на GitHub. Кроме того, у CUBA Platform очень приличная документация на русском и английском языках, где подробно объясняется, как правильно разрабатывать на этой платформе. Много примеров на GitHub, включая несколько учебников. В статье я буду часто ссылаться на документацию, чтобы не писать два раза одно и тоже.
Архитектура CUBA-приложения
CUBA-приложение состоит из модулей, показанных на диаграмме.
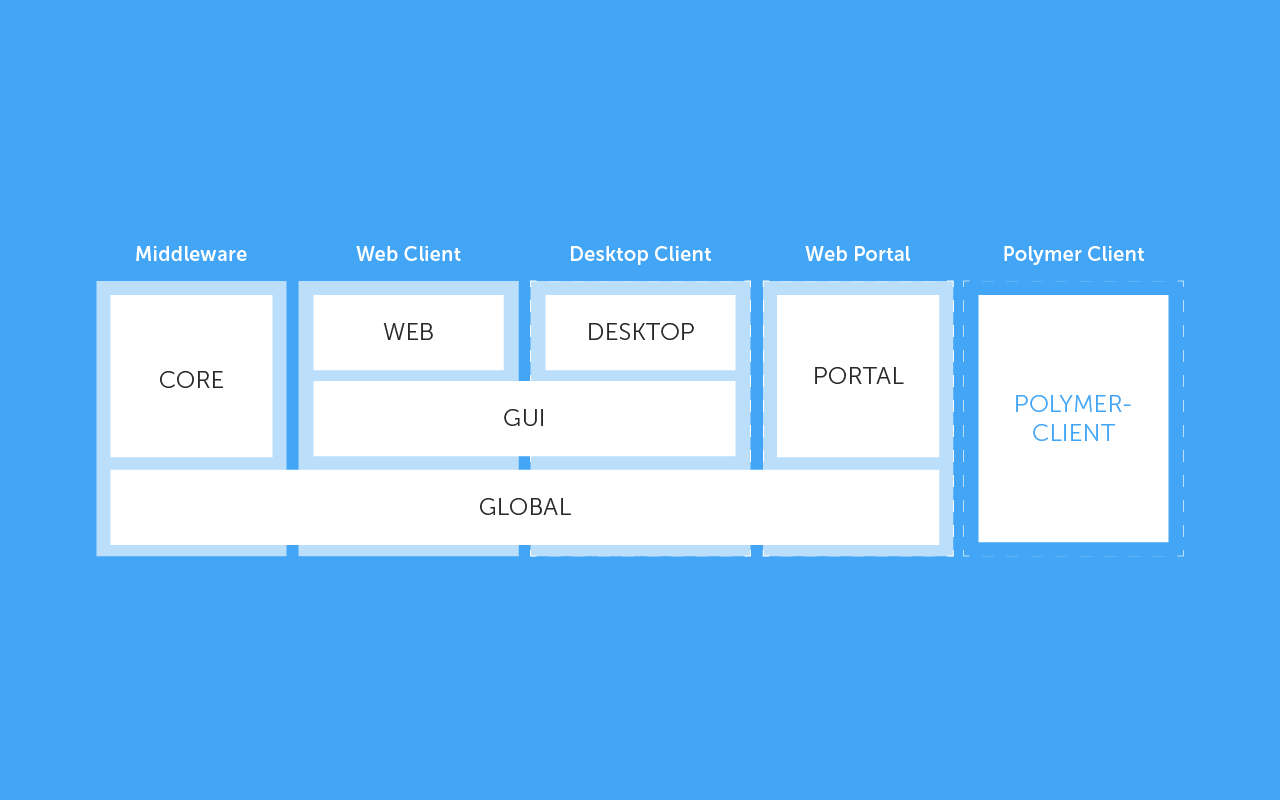
Global (глобальный модуль) — содержит классы-сущности, CUBA-представления и интерфейсы сервисов, которые используются в разных модулях.
Core (модуль сервисов) — сюда помещаются код сервисов, которые реализуют бизнес-логику, а также код работы с хранилищем данных. Нужно отметить, что эти классы недоступны из других модулей приложения, это сделано для того, чтобы обеспечивать раздельное развертывание для лучшей масштабируемости. Для того, чтобы использовать сервисы в других модулях приложения, нужно использовать интерфейсы, объявленные в глобальном модуле.
GUI, Web, Desktop, Portal — в этих модулях размещается код классов, относящихся к обработке событий пользовательского интерфейса, а также дополнительные REST контроллеры, если встроенного REST API CUBA недостаточно.
Для экономии времени разработчика в CUBA есть студия — небольшая графическая среда разработки, которая помогает делать рутинную работу, такую как генерация сущностей, прописывание сервисов в конфигурационные файлы и т.д. при помощи графического интерфейса. Для генерации интерфейса разрабатываемого приложения есть (почти) WYSIWYG редактор.
Таким образом, приложение, основанное на CUBA Platform, состоит из двух основных модулей — Core и GUI, которые можно разворачивать отдельно, а также общего модуль — Global. Давайте рассмотрим устройство этих модулей детальнее.
Модуль Global
Модель сущностей
Моделирование сущностей в CUBA приложении не отличается от того, к чему привыкли Spring разработчики. Создаются классы предметной области и на них ставятся аннотации @Table, @Entity и.т.д. Затем эти классы регистрируются в файле persistence.xml.
При написании Pet Clinic я просто скопировал классы из оригинального Spring приложения и немного их поменял. Вот пара мелких дополнений, про которые надо знать, если пишешь на платформе CUBA:
- В CUBA вводится понятие «пространство имен» для каждого компонента приложения для того, чтобы исключить дублирование имен таблиц в БД. Как раз поэтому в каждую сущность был добавлен префикс «petclinic$».
- Рекомендуется использовать аннотацию
@NamePattern— аналог методаtoString()для читабельного отображения сущностей в пользовательском интерфейсе.
Закономерный вопрос: «Что еще добавляет CUBA кроме префиксов и декларативного toString()?» Вот неполный список дополнительных возможностей:
- Базовые классы с автогенерацией ID от Integer до UUIDs.
- Полезные маркер-интерфейсы, которые дают дополнительные возможности:
Versioned— для поддержки версионирования экземпляров сущностей.SoftDelete— для поддержки «логического» удаления записей в БД.Updatable— добавляются поля для регистрации факта обновления записи, имя пользователя и время.Creatable— добавляются поля для регистрации создания записи.
Более подробно про моделирование сущностей можно почитать в документации. - Скрипты для создания и обновления БД генерируются автоматически при помощи CUBA Studio.
Таким образом, создание модели данных для Pet Clinic свелось к копированию классов сущностей и добавлению в них CUBA-специфичных вещей, которые я упомянул выше.
Представления
Концепция «представлений» в CUBA может показаться несколько непривычной, но она достаточно легко объясняется. Представление — это декларативный способ объявления атрибутов, значения которых необходимо извлечь из хранилища данных.
Например, нужно извлечь владельцев и их питомцев из БД (или ветеринаров и их профессии) — очень частая задача при создании интерфейса, когда нужно показать зависимые данные на той же форме, что и основные. В Spring это можно сделать через JPA join…
@Query("SELECT owner FROM Owner owner left join fetch owner.pets WHERE owner.id =:id")
public Owner findById(@Param("id") int id);
… или задать EAGER/LAZY атрибуты для извлечения коллекции основной сущности в контексте одной транзакции.
@ManyToMany(fetch = FetchType.EAGER)
@JoinTable(name = "vet_specialties", joinColumns = @JoinColumn(name = "vet_id"),
inverseJoinColumns = @JoinColumn(name = "specialty_id"))
private Set specialties;
В CUBA можно сделать это через EntityManager и JPQL (все так умеют) или через представление и DataManager:
- Сформировать представление (можно сделать в CUBA Studio или вручную в конфигурации)
- И использовать DataManager для выборки:
public CollectionfindAll() { return dataManager.load(Vet.class) .query("select v from cubapetclinic$Vet v") .view("vet-specialities-view") .list(); }
Можно создавать разные представления для разных задач с нужным набором атрибутов и уровней вложенности сущностей. Есть отличная статья про представления в блоге Марио Дэвида.
Для приложения Pet Clinic было сделано шесть разных представлений. Большинство из них были сгенерированы «полуавтоматически» при создании пользовательского интерфейса, а представление, описанное выше, было реализовано для сервиса экспорта данных.
Интерфейсы сервисов
Поскольку глобальный модуль используется всеми остальными модулями приложения, то интерфейсы сервисов объявляются именно в нем, чтобы потом можно было использовать их в других модулях через механизм внедрения зависимостей (dependency injection, DI).
Дополнительно нужно зарегистрировать сервисы в файле web-spring.xml в модуле Web. При инициализации контекста CUBA создаст прокси-классы для сериализации и десериализации классов при взаимодействии с сервисами в модулем Core. Это как раз обеспечивает раздельное развертывание модулей Core и Web, при этом разработчику не нужно прилагать дополнительных усилий, все делается прозрачно.
Итак: при создании классов-сущностей в CUBA тратится такое же количество времени, как и в чистом Spring (если не использовать CUBA Studio), но не нужно делать базовые классы для генерации первичных ключей. Также не нужно писать код для поддержки поля версии сущности, логического удаления и аудита. Также, на мой взгляд, представления могут сэкономить немного времени на отладке JPA join и манипуляций с EAGER/LAZY выборками.
Модуль Core
В этом модуле располагаются реализации интерфейсов, объявленных в глобальном модуле. Каждый сервис в приложении CUBA аннотируется @Service, можно использовать и другие Spring-аннотации, но нужно учитывать следующее:
- Если вы хотите, чтобы сервис был доступен в других модулях, то нужно обязательно ставить аннотацию
@Service. - Рекомендуется назначать имя сервису, чтобы избежать дублирования, если в приложении появится компонент, который реализует такой же интерфейс.
- Выборка данных сделана немного по-другому, чем в Spring, об этом в следующем разделе.
В остальном Core модуль — это обычный Spring код. Можно выбирать данные из базы, можно вызывать внешние веб-сервисы, в общем, писать код так, как вы привыкли.
Entity Manager и DataManager
В платформе CUBA используется собственный EntityManager, который делегирует часть вызовов привычному javax.persistence.EntityManager, но не реализует этот интерфейс. EntityManager обеспечивает, в основном, низкоуровневые операции и не поддерживает модель безопасности CUBA в полном объеме. Основной класс для работы с данными — DataManager который предоставляет следующую функциональность:
- Управление доступом на уровне строк и атрибутов.
- Использование представлений при выборке данных.
- Динамические атрибуты.
Больше про DataManager и EntityManager написано в документации. Для выборки данных в компоненты пользовательского интерфейса (таблицы и т.д.) явно работать с этими классами нет нужды, в GUI используются источники данных (Datasources).
Если говорить о PetClinic — в модуле Core почти нет кода, какой-то сложной бизнес-логики в этом приложении нет.
Дополнительная функциональность из Pet Clinic в CUBA
В предыдущей секции были рассмотрена дополнительная функциональность в эталонном приложении. Поскольку CUBA использует Spring, то такая же функциональность доступна и при разработке на базе этой платформы, но придется обойтись без части магии Spring Boot. В дополнение к этому, CUBA предоставляет аналогичную функциональность «из коробки».
Кэширование
В платформе CUBA есть кэш запросов и кэш cущностей. Они подробно описаны в документации и могут быть рассмотрены как приоритетные решения, если хочется использовать кэширование в приложении. Встроенные решения поддерживают распределенное развертывание приложения и кластеризацию. Ну и, конечно же, можно использовать аннотацию @Cacheable, как описано в документации по Spring, если встроенное кэширование чем-то не устраивает.
Проверка ввода
CUBA использует BeanValidation для проверки правильности введенных данных. Если встроенные классы не предоставляют нужной функциональности, можно написать собственную логику проверок. И, в дополнение к этому, CUBA предоставляет классы Validator, работа с которыми описана здесь.
Форматирование вывода
Платформа CUBA предоставляет несколько форматтеров для компонентов пользовательского интерфейса, также можно сделать свой собственный помимо стандартных. Для представления экземпляров сущностей в виде строки можно использовать аннотацию @NamePattern
i18n
CUBA поддерживает вывод на разных языках с использованием файлов message.properties, здесь ничего нового. CUBA Studio позволяет создавать и редактировать такие файлы быстро и просто.
Управление транзакциями
Поддерживаются следующие виды управления транзакциями:
- Всем знакомая по Spring аннотация
@Transactional, - Интерфейс (и класс)
Persistent, если нужно управление транзакциями на низком уровне.
Когда я писал Pet Clinic, мне управление транзакциями потребовалось только в одном месте: когда я разрабатывал форму ввода, которая позволяла редактировать несколько связанных сущностей на одном экране. Требовалось редактировать владельцев и их питомцев, а также добавлять визиты в клинику. Нужно было аккуратно сохранять данные и обновлять их на других экранах.
Pet Clinic за несколько часов. Реально
Я сделал копию Pet Clinic со стандартным CUBA-интерфейсом часов за шесть. Не сказать, что я эксперт в CUBA (прошла пара недель, как я начал работать в Haulmont), но у меня есть опыт со Spring, и он мне здорово помог.
Давайте глянем на CUBA приложение с точки зрения классической архитектуры:
Модель данных — классы-сущности в модуле Global. Создание модели — известная и знакомая процедура. Спасибо классу BaseIntegerIdEntity за экономию времени, которое обычно тратится на возню с генерацией ID.
Слой репозиториев — не нужен. Я создал несколько представлений, и на этом все. Конечно, CUBA Studio сэкономила мне немного времени, не пришлось вручную писать XML файлы.
Слой сервисов — в приложении всего два сервиса для экспорта данных в JSON и XML. В текущей версии приложения на Spring Boot эту возможность убрали, кстати. Хотя она и не работала для JSON. В CUBA-версии я объявил интерфейсы в глобальном модуле и поместил реализацию в Core. Ничего нового, кроме DataManager, но на его освоение времени потребовалось очень мало.
Слой контроллеров — в CUBA Pet Clinic только один REST контроллер, для экспорта в JSON и XML. Этот контроллер я поместил в модуль Web. Опять же, ничего особенного, аннотации те же, обычный Spring контроллер.
Пользовательский интерфейс — сделать стандартные CRUD формы, да еще и с CUBA Studio, не вызвало никаких сложностей. Не надо писать код для передачи данных в компоненты, никакого разбора данных от формы фильтрации данных, никакой возни с постраничным выводом. Есть компоненты для всего этого. Время потратилось на то, чтобы сделать интерфейс похожим на тот, который сделан в Spring Boot версии. Vaadin — это все-таки не чистый HTML, и стилизовать его было сложнее.
Персональный опыт свел в таблицу:
Конечно, Pet Clinic не использует все возможности CUBA, полный список возможностей платформы можно найти на сайте, там же можно найти примеры кода для решения типичных задач, которые возникают при разработке корпоративных приложений.
Мое личное мнение — CUBA упрощает разработку серверной части приложения и помогает еще больше сэкономить время на разработке пользовательского интерфейса, если вы будете использовать стандартные пользовательские компоненты и возможности стилизации. Но, даже если нужен какой-то особенный пользовательский интерфейс, то все равно будет выигрыш по времени за счет стандартной серверной части.
Одни плюсы! А минусы есть?
Конечно есть, не бывает совершенных фреймворков. Они не критичны, но на первых порах, когда я только начинал работать с CUBA, был некоторый дискомфорт. Но величина WTF/m была не запредельной.
- Для платформы CUBA есть IDE, которая упрощает начальное создание проекта. Переключение между студией и IDEA немного раздражает на первых порах. Хорошие новости — есть бета-версия CLI, не нужно запускать студию для генерации структуры проекта, а еще — следующая версия CUBA Studio будет плагином Intellij IDEA. Больше никаких переключений.
- В CUBA больше XML файлов, чем в среднестатистическом Spring Boot приложении, это сделано потому, что инициализация контекста в CUBA сделана по-своему. Сейчас ведется борьба за уменьшение количества XML, переходим на аннотации там, где возможно.
- Для форм пользовательского интерфейса нет «читаемых» URL. Есть возможность доступа к формам через ссылки на экраны, но они не очень дружественны пользователю.
- Для работы с данными нужно использовать DataManager, представления и EntityManager, а не Spring JPA или JDBC (но эти API также доступны, если нужно).
- Лучше всего CUBA работает с реляционными БД в качестве хранилища данных. Что касается NoSQL, придется использовать библиотеки доступа к этим хранилищам и писать свой собственный слой репозиториев. Но это такой же объем работы, как при разработке приложения без CUBA, по-моему.
Если есть задача разработки приложения, которое использует реляционную БД в качестве хранилища данных и ориентировано на работу с данными в табличном формате, то CUBA может быть неплохим выбором, потому что:
- CUBA прозрачна. Исходный код доступен, можно отлаживать любой метод.
- CUBA расширяема (до известных пределов, естественно). Можно унаследовать практически любой служебный класс и подсунуть его платформе, делать собственный REST API, использовать свой любимый фреймворк для пользовательского интерфейса. CUBA создавалась так, чтобы можно было легко адаптировать решения для любого заказчика. Здесь есть хорошая статья про расширяемость платформы.
- CUBA — это Spring. 80% вашего серверного кода будет просто Spring приложением.
- Быстрый старт. У вас будет полноценное приложение с админкой уже после создания первой сущности и экрана для работы с ней.
- Множество рутинных задач уже решено в платформе.
Итак, с CUBA можно сэкономить время на написании однообразного «служебного» кода и сфокусироваться на написании кода для решения задач бизнеса. И да, мы в Haulmont сами используем CUBA при разработке как коробочных продуктов, так и заказных.
