Разработка хитрого ИИ в тактической игре на основе эвристик и мутаций
В тактических играх ИИ очень важен. Если ИИ видится как «искусственный идиот», то игру может спасти потрясающий мультиплеер, сюжет, атмосфера и графика (это неточно). Решение очевидное: делай хороший ИИ, в чём тут могут быть проблемы?

В деталях. Ниже описаны мои шаги по конструированию сильного ИИ с характером. Не супер сильного [1], но способного быстро отработать локально в прожорливом браузере любого средне-слабого ПК. Мною применён подход экспертных систем с использованием набора эвристик и мутаций. Описаны 15 шагов постепенного преображения ИИ, каждый из шагов можно пощупать.
Краткое описание
В подопытной браузерной игре ИИ основан на генерации множества возможных состояний — результатов выполнения текущего хода. (Из-за игровой специфики и удобства эти результирующие состояния в статье называются то сценариями хода, то стратегиями ИИ — в зависимости от контекста). Затем сценарии хода подвергаются мутациям. По полученным сценариям вычисляются оценки «успешности». Самая успешная и выполняется компьютерным игроком.
Например, генерируются три стратегии:
- Бежать оголтело всем вперед и атаковать всех, кто подвернётся под руку. Очки итогового состояния: 37000 баллов.
- Атаковать лучниками с безопасного расстояния, а остальные прячутся по углам. 45000 баллов.
- Всем отступить, сгруппироваться и попрятаться от врагов. Если можно при этом ранить какого-нибудь врага с безопасного расстояния, то атаковать. 18000 баллов.
- В этом случае будет выбрана 2-я стратегия.
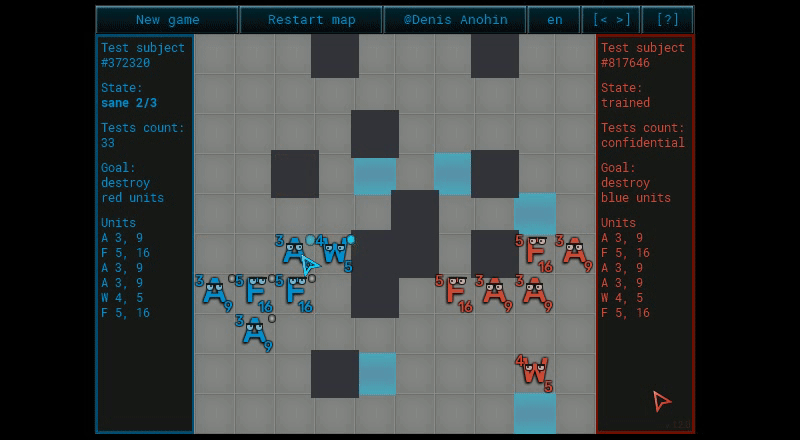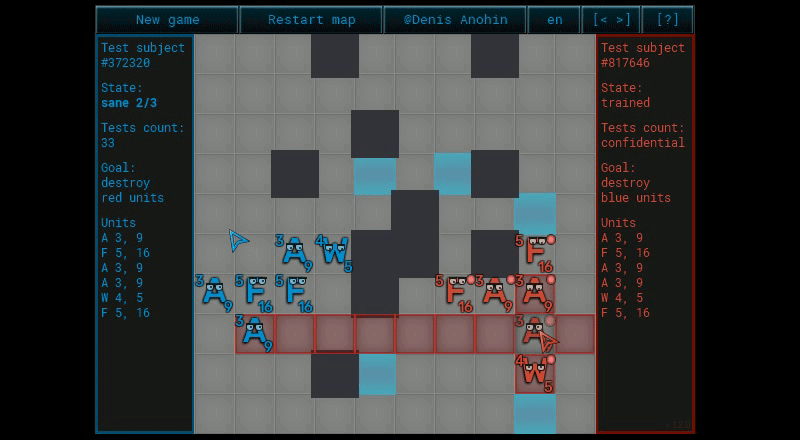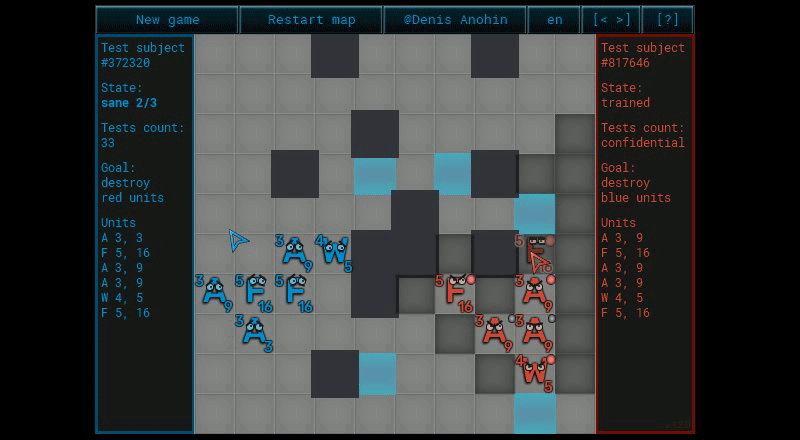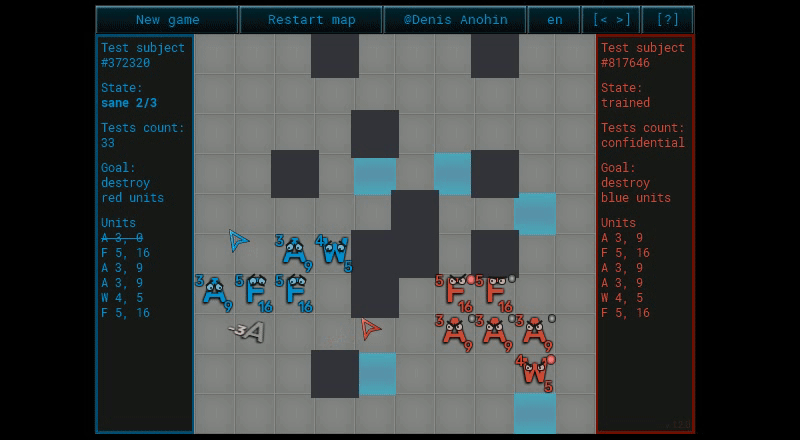
Ну вроде всё стандартно. Не совсем.
Вся мякотка в том, как генерируются сценарии и как вычисляется коэффициент ценности сценария. Налажаешь в одном из них, и результат тебя опечалит.
Правила игры
У игрока и у ИИ изначально по углам выдаются по 6 одинаковых юнитов. Каждая команда ходит по очереди всеми юнитами сразу. Варианты хода каждого юнита:
- пропустить ход;
- передвинуться и пропустить;
- передвинуться и атаковать (можно и иногда нужно атаковать своих).
Игровое поле и состав команды генерируется процедурно (то есть случайно, но с проверками на проходимость и приемлемую «тактичность»). Типы юнитов:
- Боец F, юнит ближнего боя с самой большой живучестью, уроном и мобильностью. Эдакий танк+дамагер.
- Лучник A, самый низкий урон, зато атака на расстоянии 1–7 по прямой линии.
- Колдун W, умирает с одного удара бойца, зато атака на расстоянии 1–5 по прямой линии насквозь по всем юнитам.
Игровое поле всегда размером 10×10.
Возможные поля на карте:
- Земля — не накладывает никаких ограничений.
- Стена — через неё нельзя ни прострелить, ни пройти.
- Вода — через неё нельзя пройти, но через неё может стрелять лучник (огненный маг не может).

Игра полностью детерминирована, то есть в ней нет элемента случайности (шанс попадания 100%, никаких критических уронов и т.п.). Также это игра с полной информацией, то есть соперники всё знают о состоянии войск друг друга в любой момент времени. Как в шашках.
ИИ сильнее мясного игрока, но у последнего на первом уровне есть фора в виде одного юнита. На 3-ем у игрока наоборот хандикап в одного юнита и победить гораздо сложнее (у меня около 15% побед на этом этапе). Затем идёт более рандомная версия Игра+.
Изначально был разработан другой план игры в виде «качелей» как в турнирной таблице, но в конце разработки я отказался от него, как от слабомотивирующего. Смысл был в том, что если какая-то команда проигрывает, то на следующей карте ей даётся +1 юнит, и так максимум до 10 против 6. Если и потом команда умудрялась проиграть, то её юнитам увеличивались характеристики.
Игра разработана на нативном javascript: на div-ах и css-стилях, и это было самое неудачное решение из возможных [2]. Это браузерная игра. Движок не использовался. Единственная цель проекта — создать сильного компьютерного игрока «с характером» и возможностью изменения этого характера (расчетливые киборги, агрессивные орки, коварные эльфы, глупые зомби).
Для уменьшения «компьютерного стиля» у противника были применены некоторые хитрости:
- Игрок после своего хода не ждёт, пока ИИ подумает над своим ходом. Враг «сразу» начинает делать свои передвижения (в действительности это иллюзия).
- Компьютерный игрок управляет юнитами тоже с помощью своего курсора (и это тоже иллюзия, курсор просто летает одновременно с анимациями юнитов).
- ИИ умеет использовать коварные приманки, чтобы навязать бой (тут всё по-честному).
И что тут сложного?
Сперва может показаться, что тут все просто: можно просто перебрать все варианты всех ходов и выбрать наилучший. Но очень скоро становится очевидным, что всё очень даже непросто.
Полный перебор невозможен из-за эффекта комбинаторного взрыва [3], который заключается в том, что по мере роста числа проверяемых элементов в сценариях сложность вычислений растет по экспоненте. Далее опишу, что это значит в моей конкретной игре.
Во-первых, т.к. на каждом ходу юниты команды ходят все сразу, то возможна разная их очередность. А при 6 юнитах в команде таких комбинаций становится 720 (1×2*3×4*5×6). Если юнитов будет больше, то комбинаций будет вообще огромное количество (при 7 — 5040, при 8 — 40320…). Если не учитывать максимального исхода, то игрок рискует распробовать удовольствие в ожидании очередного хода на 5–10 минут (а если он упорный, то задержка дорастёт и до миллионов лет, не каждый вытерпит). Именно из-за этой характеристики мой ИИ в начале боя менее эффективен, чем в конце. Ведь ближе к концу половина команды уже погибла.

Во-вторых, каждый юнит может передвинуться в разные точки карты. Бойцы с дальностью передвижения 4 могут походить на 1–41 разных позиций. У магов и лучников с их передвижением в 3 возможное число ходов равно 1–25. Например, состав команды может быть: 4 бойца, 1 маг и 1 лучник. Итого разных комбинаций ходов по данному пункту мы получаем: 41×41*41×41*25×25 = 1766100625. В действительности из-за взаимных пересечений и непроходимой местности комбинаций будет меньше, но в редкой ситуации «разбегания по карте» число комбинаций будет приближаться к этому числу.
В-третьих, каждый юнит после передвижения может пропустить ход или атаковать в одном из 4 направлений. То есть имеем по 5 возможных завершающих действий на юнита. Всего комбинаций: 5^6 = 15625.
 Итого комбинаций: 720×1766100625 * 15625 = 19868632031250000.
Итого комбинаций: 720×1766100625 * 15625 = 19868632031250000.
И в каждой валидной комбинации надо будет рассчитать баллы результирующего состояния. В оценочную функцию входят: эмуляция передвижений, атака, нанесение урона, гибель юнитов и подсчёт оставшихся хитпоинтов у выживших. Конечно, число комбинаций завышено, т.к. в реальных условиях вариативность будет уменьшаться за счёт границ и препятствий на карте, однако это всё равно будет неподъёмное число комбинаций. А всё это происходит ведь в обычном браузере.
Как же сделано?
Чтобы решить подобную задачу, был использован эвристический подход, обобщённый алгоритм которого можно описать так:
- Сгенерировать разные сценарии на основе заранее прописанных стратегий (~20 штук).
- Пока есть время, проводить мутации сценариев, оставляя наиболее выгодные.
- В конце выбрать сценарий с наибольшей оценкой.
- Осуществить первый ход юнита из сценария, но остальными не ходить. Начать анимацию первого хода, и пока показывается анимация, продолжить улучшать сценарии для оставшихся юнитов.
- Повторить для оставшихся юнитов с пункта 1.
Эвристический метод — это метод, который может сработать (по Макконнеллу [4]). Подробнее и строже в Википедии [5].
Ключевые моменты в этом алгоритме: генерация сценариев, мутации и правильная оценка выгодности состояния. В каждом из этих пунктов используются свои собственные локальные эвристики. Тем не менее, там где можно, использовались алгоритмы с гарантированным оптимальным результатом, например, А* для поиска пути [6].
Использованный мною эволюционный подход нельзя назвать полноценным генетическим [7], т.к. от него я использовал только мутации и выживание «сильнейшего», а коэффициенты влияния отдельных эвристик настраивал вручную. Алгоритмов формирования популяций и скрещиваний не применялось. После мутации выживает только один: либо мутант, либо родитель.

Нейронные сети [8] мною не использовались из-за особенностей задачи. Во-первых, из-за сложности их успешной реализации в условиях постоянно меняющейся среды (появление новых механик, навыков, способностей). Во-вторых, из-за сложности в их контролируемой персонализации (если захочется сделать два поведения: стремительного Суворова и осторожного Кутузова [9]).
Эволюция искусственного идиота в искусственный интеллект
0) Сначала у ИИ были введены только 3 стратегии со случайными ходами. {Сложность игры #0}. Оценка состояния была просто случайным числом. И так как ИИ не единственный элемент разработки, мне пришлось довольно долгое время мириться с таким поведением:
1) Затем в расчёты оценки стратегии были добавлены проверки оставшихся юнитов и их жизней у ИИ и у игрока. {Сложность игры #10}. За мертвого юнита команде начислялось 0 баллов. За полностью здорового Х баллов (например, 100 000 за бойца F, 70 000 за лучника A, 85 000 за колдуна W). За раненого начислялись 50% от основной ценности, а оставшиеся 50% пропорционально оставшимся жизням от максимальных. Благодаря этому ИИ было выгоднее добивать врагов, а если он мог только ранить, то он выбирал противников с меньшим числом жизней — более уязвимых.
Случайные ходы стали более осмысленными:
2) Затем была добавлена более осмысленная стартовая стратегия:
max_agro — все солдаты бежали максимально ближе к врагам и старались нанести как можно больше урона. {Сложность игры #20}. Одна стратегия использовала изначальный порядок ходов юнита, вторая ходила ими в обратном порядке.
ИИ стал вести себя так, как ведёт себя самый примитивный искусственный идиот в тактических играх. И довольно часто именно такой ИИ в тактических играх и используется. Он популярен из-за своей надежности и простоты. Такой даже может победить —, но очень редко.
Именно на это похоже поведение ИИ в провальной игре Master of Monsters — Disciples of Gaia, из-за чего в неё банально скучно играть [10].
3) Дальше были добавлены стратегии, учитывающие возможный урон от врагов при передвижениях, и выбирающие те ходы, которые приводили к наименьшей опасности — желательно нулевой. {Сложность игры #30}. И ИИ сразу же стал сверх трусливым, избегающим любой близости с противником — лучше уж сбежать, чем атаковать и ранить, ведь противник может дать большей сдачи!
Поэтому в оценке состояний стал тоже учитываться возможный урон врагу. Штрафные баллы от потенциального урона от врагов стали вычисляться с уменьшающим коэффициентом 0.20 (коэффициент постоянно перенастраивался). Это заставляло ИИ при выборе между атакой или бегством избирать агрессивный вариант, поскольку он приносил в 5 раз больше баллов, чем бегство. Но ИИ всё равно надолго остался трусливым, ведь чтобы попасть в такую ситуацию выбора, враг уже должен быть в досягаемости, а сам ИИ при таких оценках никогда не подставит себя первым под удар. То есть не пойдёт на сближение. Конечно, игрок будет чувствовать себя обманутым, ведь у ИИ бесконечный запас терпения и он может убегать от опасности вечно, вынуждая игрока к агрессии.
Следует отметить, что подобные вычисления возможного урона очень длительны без использования кэша. Один полный просчёт стратегии без оптимизаций изначально занимал 700 миллисекунд. А у меня ведь ограничение на весь ход одним юнитом ~4000 мс! После оптимизаций и отработавших кэшей это время уменьшается до 20 миллисекунд при очень похожих стратегиях (к сожалению кэш невозможно просчитать весь заранее из-за эффекта комбинаторного взрыва, поэтому 20 мс достигаются не всегда).
Поэтому когда я внедрял технологию расчета с прогнозированием на несколько ходов вперёд, то время расчетов для глубины только в 2 хода (врага и ИИ) занимало уже +700 миллисекунд. В этом случае применяют оптимизацию с отсечением «слабых» веток. Если для этого пользоваться хоты бы примитивной стратегией max_agro, то увеличение времени было +30 миллисекунд и кэширование эту разницу почти не уменьшало (т.к. позиция на карте была совершенно новой).
В итоге я делал 5 разных заходов к разработке этого подхода, но в конце концов полностью отказался от него, т.к. мутации с эвристиками давали результат лучше и быстрее.
4) Следующие стратегии были направлены на расширение изначального разнообразия стратегий:
far_attack_and_hide — юниты стараются атаковать как можно дальше от противника, а если не атакуют, то прячутся от любой атаки.
close_group_flee — юниты отступают подальше от боя и группируются как можно ближе друг к другу. Если можно при этом безопасно атаковать врага — атаковать.
{Сложность игры #40}.
Это улучшило процесс самого боя, но начало боя все равно было всегда невыгодно для ИИ: он постоянно отступал, но его можно было выманить на атаку и спугнуть так, чтобы группа ИИ разделилась на несколько мелких групп, которые можно было уничтожить по отдельности.
5) Затем настало время мутаций. {Сложность игры #50}.
Алгоритм мутаций был очень простой:
- при переборе выбранных стратегий создавалась одна копия стратегии;
- в этой копии производилась мутация хода;
- если ход становился невалидным, то он исправлялся до хоть какого-нибудь валидного по одной из стандартных стратегий;
- вычислялись баллы мутировавшей стратегии;
- если у мутанта баллы оказывались больше, то мутант заменял собой своего родителя.
При этом стратегии аутсайдеры не удалялись, а также участвовали в мутациях, т.к. всегда была заметная вероятность очень успешной серии мутаций.
Сначала был реализован самый примитивный тип мутации: от 1 до 3 движений заменялись на случайные, порядок ходов оставался прежним. За одну итерацию расчетов в среднем на каждую стратегию создавалось ~5–15 мутаций. При этом в среднем каждая пятая мутация была более выгодной и заменяла стратегию родителя.
6) Эвристика приманки. {Сложность игры #60}.
Эта эвристика повторяла ту тактику, с помощью которой я выманивал ИИ на атаку одним юнитом, чтобы перебить его по одному. Этому трюку удалось научить и ИИ.
Для этого в функции вычисления баллов за состояние стратегии проверяется, соответствует ли текущее состояние ситуации приманки:
- Только один солдат ИИ может быть атакован;
- Только один враг может атаковать вылезшего юнита;
- Юнит компьютерного игрока после этой атаки обязательно должен выжить;
- Как минимум двое юнитов компьютера смогут атаковать в ответ. Чем больше таких наказывающих юнитов, тем больше баллов за эвристику.
Эффект оказался отличным: игроку становится легче начинать бой самому. При этом чаще всего игроку всё равно выгоднее «повестись» на эту приманку, так как после ответной атаки он сможет навалиться на ИИ всем своим отрядом (это если он разумно сгруппируется предварительно). А там уже всё решат грамотные локальные тактические решения.

7) Потом мне стало бросаться в глаза, что бойцы ИИ постоянно разбегаются как тараканы. {Сложность игры #70}. Также солдаты могли забиться в угол или зайти в тесные тоннели, в которых ИИ сильно терял в своей эффективности перебора возможных атак.
Поэтому в оценочную функцию были добавлены эвристики оценки расстояний между юнитами и рельефа карты со следующими предположениями:
- Чем ближе союзники друг к другу «в среднем» — тем лучше (юниты реже стали разбегаться по разным частям карты).
- Чем ближе солдаты ИИ к в солдатам врага «в среднем» — тем лучше (мне нужен был наступательный ИИ).
- Чем больше максимальное расстояние между любой парой союзников, тем хуже. При этом расстояние в 4 не штрафуется, а всё что больше — штрафуется по экспоненте (это прекратило вытягивание солдат в уязвимые шеренги).
- Если солдат ИИ не может добежать и атаковать врага как минимум за 2 хода, то его надо штрафовать (это заставляет его наступать, но не подставляться самому под атаку).
- Если в радиусе 2 шага от солдата слишком много блокирующих позиций, то штрафовать его (реже стали забегать в тоннели).
- Если солдат находится на границе карты, то штрафовать его еще сильнее. В результате этого маневренность ИИ сильно повысилась, т.к. из открытой местности юнит может добежать в гораздо большее число позиций, чем из угла или тоннеля.
8) Затем пришло время расширения стратегий. {Сложность игры #80}. Я не мог добавить полный перебор возможного порядка ходов юнитов, но я мог сделать перебор их ходов по типам: боец, лучник, колдун. Поэтому появились стратегии последовательности ходов, вида W_A_F: сначала ходят все колдуны, потом все лучники, потом все бойцы.
Таким образом добавилось 6 новых стратегий: W_A_F, W_F_A, A_W_F, A_F_W, F_A_W, F_W_A. Они не решили всех проблем, но заметно улучшили качество игры.
9) У меня были мутации, но толку от них было мало. {Сложность игры #90}. В основном они улучшали слабые стратегии, а удачные улучшались редко. Поэтому мутации были доработаны и каждый раз срабатывал один из случайных типов мутации:
- От 1 до 3 движений заменялись на случайные, порядок ходов оставался прежним (старый способ);
- Поменять местами порядок ходов двух случайных юнитов. Действия их оставить прежними, даже если они не оптимальны. Если ход повторить невозможно, то он пересоздаётся случайно одной из обычных стратегий до валидного состояния;
- Поменять местами порядок ходов двух случайных юнитов и пересчитать их ходы заново. Все поломавшиеся ходы у последующих юнитов чинятся случайными обычными стратегиями.
Ввод этих мутаций стал серьёзно компенсировать невозможность полного перебора всех комбинаций ходов юнитов. Хотя из-за своей случайности он не даёт никаких гарантий, что удачный ход будет найден за имеющееся ограниченное время.
10) Затем были добавлены еще полуслучайные стратегии. {Сложность игры #100}. Порядок ходов генерировался случайно, а сами ходы выбирались по следующим принципам (по уменьшению их важности):
- нанести максимальный урон;
- получить как можно меньший урон в ответ;
- стать как можно ближе к врагам.
Заметного улучшения тут я не увидел, но проект уже перешел в ту стадию, когда каждое улучшение приводит к менее заметным воспроизводимым эффектам.
11) Мне надоели вопиющие ошибки ИИ, когда он при атаке своим колдуном сильно задевал моих солдат, но при этом ранил своих союзников. {Сложность игры #110}. Хотя перед этим он вообще-то мог походить ими и убрать их с линии огня. Поэтому была создана жёстко сгенерированная стратегия с ручными проверками:
- если есть колдун, то найти место, откуда он нанесет максимальный урон;
- если в этом месте или по пути удара есть союзники — запомнить их;
- сначала ходят все союзники, которых запомнили, и они не могут становиться на зарезервированные колдуном позиции (то есть освобождают дорогу);
- ходит колдун;
- ходят оставшиеся юниты.
Стратегия легко описывается на словах, но заморочно для её программирования.
12) Иногда юниты »убегали в кусты» прямо перед началом боевых действий. {Сложность игры #120}. В результате этого, когда начинался обмен атаками, то один или даже два юнита могли оказаться слишком далеко от военных действий и не помогали союзникам. Если это случалось, то я почти гарантированно выигрывал у ИИ. Если не случалось, то я чаще проигрывал. Избавлялся от этого я вводом новой эвристики по оценке результирующих баллов у стратегии. Для каждого юнита проводилась проверка:
1. Если юнит в этот ход атаковал, то он получал +1500 баллов.
2. Если не атаковал, то подсчитывались позиции, с которых враги смогут наносить урон союзникам. Продолжать подсчет, если таких позиций будет больше 0 (N > 0).
2.1. Если юнит не может достать и ударить ни по одной позиции (n = 0), то он получает штраф -1000 баллов.
2.2. Если юнит может достать до всех позиций, то он получает +1200 баллов.
2.3. Если юнит может атаковать до некоторых позиций, то он получает +(n/N)*1000 баллов.
Это позволило сильно улучшить «сплоченность» юнитов ИИ. К сожалению, начали появляться случаи «одного дезертира», когда в проигрышной ситуации один из раненых юнитов предпочитал прятаться за спинами своих товарищей вместо того, чтобы внести свою лепту, атаковав врага. Это нелепо выглядело, когда у компьютера остаётся всего 2 юнита, а у игрока 3 или даже больше. Дополнительная исправляющая эвристика представляет собой следующее правило:
IF ("у ИИ меньше юнитов, чем у противника" AND "у ИИ не больше 3 юнитов")
THEN "за каждого дезертира начислить сценарию штрафные баллы"
13) Под конец ввода стратегий их набралось уже под 25 штук. {Сложность игры #130}.
Мутировать каждую из них стало уж слишком накладно. Поэтому было принято решение удалять самые неудачные и оставлять только 8 штук. С самого начала я не хотел использовать этот подход в расчете на то, что мутация аутсайдеров может привести к неожиданному отличному результату, вместо простого хорошего. Ввод данной обработки в итоге привел к улучшению игры ИИ.
14) Примерно в начале была ещё интересная доработка. Изначально оценка ценности сценария вычислялась как разница сумм баллов:
Итоговые_баллы = Баллы_ИИ - Баллы_игрока
Но спустя несколько улучшений я вспомнил, что это не самое лучшее решение, т.к. тогда для ИИ будут одинаковыми ситуации »2 солдата против 1 одного солдата» и »4 солдата против 3 солдат». Поэтому баллы стали вычисляться как отношение:
Итоговые_баллы = Баллы_ИИ / Баллы_игрока
Изменение небольшое, а результат очень серьезный. Без доработки цена ошибки при повышенном риске всегда была одинакова. После доработки ИИ стал меньше безалаберно рисковать к концу сражения, и это заметно усилило его.
Хочу отметить, что все эти доработки вводились постепенно хоть и в указанном порядке, но многие из них улучшались, перерабатывались и исправлялись от багов в более хаотическом порядке. Реальных итераций было больше 100 штук.
Вот как играет финальный ИИ {Сложность игры #9999}:
ИИ ходит сразу, а не тратит время на раздумья
Для ускорения самих вычислений активно использовались оптимизации алгоритмов в виде разбиений вложенных циклов на последовательные циклы (уменьшение сложности) и внедрение нескольких массивов с кэшированными предварительными вычислениями (и последующей оптимизации еще этих самых кэшей). По моим прикидкам дальнейшие оптимизации смогли бы мне обеспечить еще двойной (или даже больший) прирост к скорости, но это бы привело к неоправданному росту временных затрат и дальнейшей ещё большей потери читаемости кода.
Основная технология быстрого хода — это предварительные вычисления во время простоя. Этот метод заключается в том, чтобы разбить процесс хода на 2 части: сами вычисления и показ анимаций результатов вычислений:
- вычисления хода первого юнита начинаются сразу же после хода игрока, пока еще вылетает окошко, что сейчас начнётся ход противника. А это целых 4 секунды, которые игроком не воспринимаются пустым ожиданием;
- вычисления второго и последующего ходов начинаются тогда, когда только начинается анимация хода прошлого юнита (то есть когда курсор ИИ только начинается своё движение). А время всех анимаций уже 4.5 секунды. Хотя правильнее это назвать не вычислением следующего хода, а улучшением уже выработанной прошлой стратегии и поиска новой, т.к. на каждой итерации рассчитываются ходы всей команды;
- при анимации ходов ИИ к двигающимся юнитам летает курсор ИИ, который притворяется, что он по ним кликает. Курсор летает максимально быстро, но чтобы оставалась комфортность слежения за ним. Более того, добавление курсора не только позволило увеличить запас времени вычислений с 2 секунд до 4.5, но и сделал просмотр хода компьютера более комфортным для человека;
- время хода игрока тоже не теряется впустую. Пока игрок думает, то вычислений почти никаких не производится, поэтому в это время усиленно просчитываются возможные кэши для будущего хода компьютерного оппонента.
Чтобы всё это не лагало в браузере и работало с достаточно стабильным FPS, расчёты производятся асинхронно воркером (Web workers) [11].
Этим я хотел избавиться от раздражающего окошка ожидания «Компьютер ходит». Такая неприятная плашка есть во многих хороших играх, например, в Xenonauts [12]. Я считаю, что мне удалось справиться с этой проблемой.

Таким образом, ИИ тратит на обдумывание своего хода всегда одинаковое время — независимо от его сложности. Очень любопытная особенность этого подхода в том, что чем сильнее у игрока компьютер, тем большее число мутаций ИИ успеет перебрать, а значит будет тем сильнее, чем мощнее компьютер игрока. Я сначала убрал данный эффект с помощью фиксации времени хода и предварительного подсчета скорости работы компьютера. Однако потом я убрал эту фиксацию, т.к. владельцам мощных компьютеров это позволит сразиться со «своим» компьютером, а не усреднённым.
Каков результат и в чём недостатки
Таким образом, получившийся компьютерный противник умеет достойно сражаться и хорошо пользуется любыми оплошностями игрока, а своих делает не слишком много. Тем не менее, я, зная все особенности его работы, хоть и с напряжением, но побеждаю его почти всегда (при равных условиях). А хотелось бы наоборот: чтобы даже зная о его особенностях, почти всегда ему проигрывать. ИИ далёк от идеала, поскольку используемый мною набор эвристик приводит к синергетическому наложению «ошибок моего восприятия» друг на друга. Вот эти ошибки:
- Несовершенство и неполнота моей собственной стратегии, я не знаю всех наилучших стратегий, и поэтому не могу их обозначить и внедрить в игру.
- Потеря эффективности (которая итак не идеальна) выработанных рабочих эвристик при переносе их на программный код. Например, моя человеческая эвристика «Юниты держатся рядом, но не слишком близко, чтобы избегать двойного урона от магов и не застрять в узких проходах». Эта эвристика помогает мне побеждать ИИ, но при обучении ею моего компьютерного оппонента, мне приходится качественное описание переводить в алгоритмическое с количественными оценками, и тут возможна потеря данных.
- Взаимные конфликты между эвристиками. Когда эвристик слишком много, они постепенно начинают накладываться друг на друга. В результате этого может произойти неожиданное усиление из-за скрытого двойного учёта или частичного дублирования. Либо какая-то эвристика перестанет на что-либо влиять, т.к. её вклад полностью перекрывается большими коэффициентами конкурирующей.
- Жесткие временные ограничения и пошаговые улучшения выбранных стратегий приводят к тому, что первый ход всегда будет менее продуман. Это значит, что один неудачный первый ход может заблокировать очевидные более эффективные ходы остальных юнитов команды. Это выражается в том, что первый боец F вместо отхода может криво атаковать противника и потом его союзнику волшебнику W придётся ранить своего, чтобы добить противника.
Полноценные генетические алгоритмы вместо «подбора на глазок» скорее всего позволили бы подобрать более оптимальные коэффициенты в эвристиках. Но это уже задача для будущих полноценных проектов — не хочется надолго застревать с прототипом. Текущим ИИ я вполне доволен: он расчётливый, немного коварный, достаточно агрессивный и не позволит игроку победить себя в сухую (в действительности чрезвычайно редко позволит).
Дополнительные возможности
Подобный способ реализации позволяет добиться дополнительных бонусов в игровой разработке (во многом с точки зрения разработчика и его горящих сроков):
- Появление новых механик в игре не разрушит силу компьютерного игрока, хотя и будет постепенно его ослаблять по сравнению с игроком. Это ослабление может компенсироваться вводом дополнительных эвристик. Чтобы это не приводило к прогрессирующим расходам ресурсов, применять эти новые эвристики можно только при наличии этих новых механик в текущем сражении.
- Действительно интеллектуальные уровни сложности. Сейчас в основном уровень сложности определяет то, какие бонусы компьютерный игрок получит в качестве ресурсов (больше золота на старте или бонус в добыче) или как сильно его солдаты будут бить (+50% к урону). Это работает, но можно ведь сделать ИИ чуть менее умным просто постепенным отключением некоторых эвристик по мере уменьшения сложности.
- В продолжении 2-го пункта можно создавать и разные расы/фракции компьютерных противников: у орков работают только агрессивные стратегии; у толп зомби только примитивные «бежать вперед и атаковать»;, а у киборгов использовать всю мощь ИИ. Благодаря этому игроку перед нападением придётся оценивать не только числа у противников, но и их интеллектуальность.
Всё это многообещающе звучит, но следует помнить, что все это красиво на бумаге, а в реальной игре это может просто не сработать, оказаться неинтересным или даже незаметным для игрока. Но это хороший повод для экспериментов.
Где пощупать
Вы можете протестировать силу этого ИИ в браузерке «AI tactical rumble. Test subject» бесплатно на площадках типа itch.io [13]. GET параметр ai (значения от 0 до 140 с шагом 10) позволит снизить сложность ИИ.
По моим ожиданиям победить ИИ на равных условиях Вам будет очень и очень сложно. Даже после привыкания к правилам игры. Я рекомендую рассматривать данную игру, как прототип, каковым она по сути и является (музыки, звуков и цены в ней нет).
Пожалуйста, оставляйте своё мнение в комментариях об интересности ИИ, советы и критику о возможной реализации ИИ с помощью различных методов обучения. Если Вам вдруг стали интересны другие мои изыскания, пожалуйста, рассмотрите возможность подписки здесь на мой аккаунт.
Список литературы
1. DeepMind — статьи на Хабре.
2. HTML5 games: Canvas vs. SVG vs. div на stackoverflow.
3. Комбинаторный взрыв — Википедия.
4. Совершенный код Стива Макконнелла — Хабр.
5. Эвристические методы — Википедия.
6. A* — Red Blob Games.
7. Генетический алгоритм. Просто о сложном — Хабр.
8. Восемь потрясающих игр с искусственным интеллектом от компании Google — Хабр.
9. Очень кратко о Суворове и Кутузове.
10. Master of Monsters — Disciples of Gaia — обзор на IGN.
11. A Detailed Explanation of JavaScript Game Loops and Timing.
12. Xenonauts и долгий экран ожидания ИИ.
13. AI tactical rumble. Test subject — на itch.io.
