Разработчики остались неизвестны. Лекция Яндекса
Этот доклад руководителя группы разработки ClickHouse Алексея Миловидова представляет собой обзор мало кому известных СУБД. Некоторые из них устарели, некоторые прекратили свое развитие и заброшены. Алексей обращает внимание на интересные архитектурные решения в перечисленных примерах, разбирается в их судьбе и объясняет, каким требованиям должен отвечать ваш опенсорс-проект.
— Мой доклад будет про базы данных. Позвольте сразу спросить, схема метрополитена какого города изображена на этом слайде? Все линии идут в одну сторону.
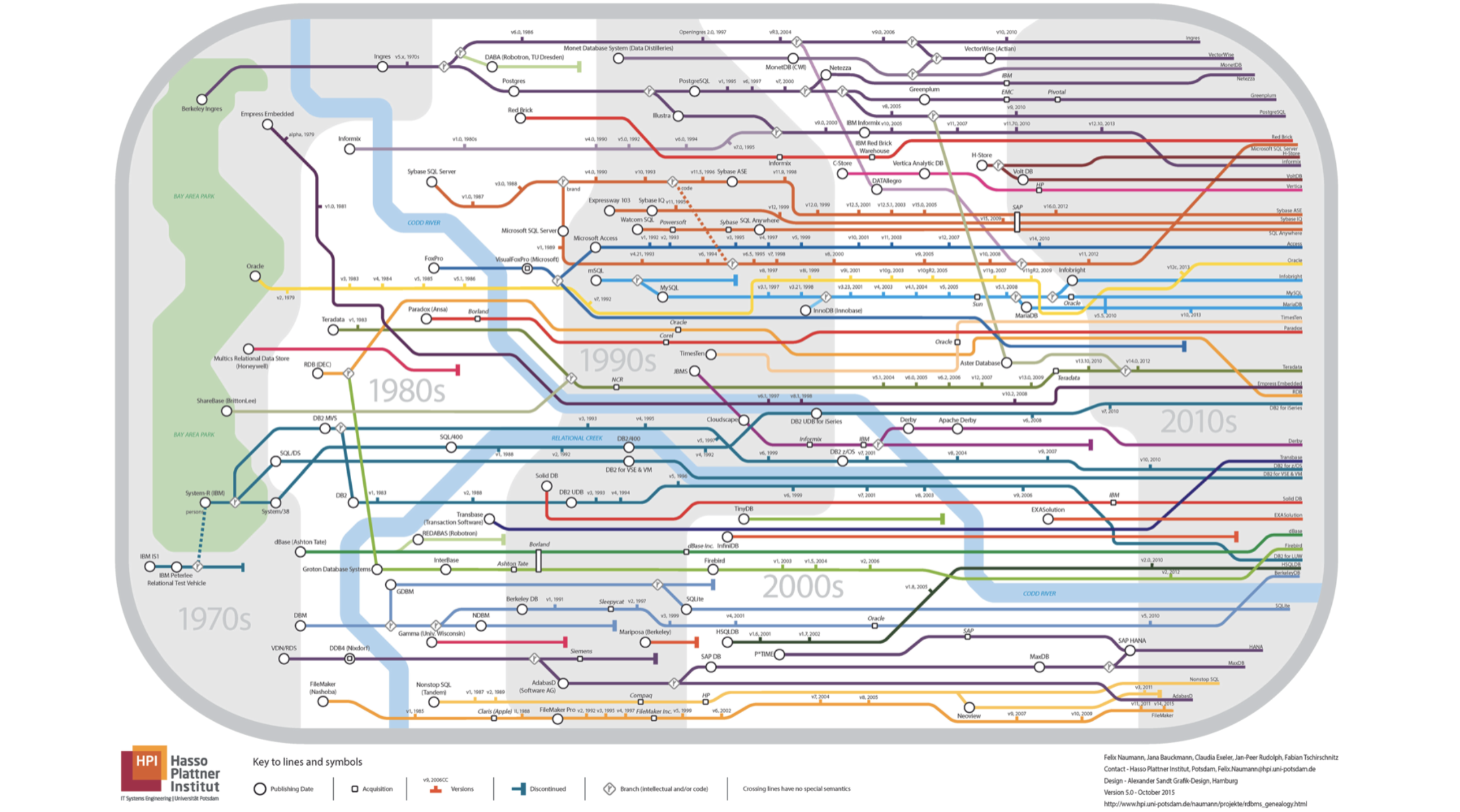
Все неверно, это вообще не метрополитен, это родословная реляционных баз данных. Если приглядеться, будет видно, что река — это река Кодда.
Про них я рассказывать не буду. Что может быть скучнее, чем рассказывать о MySQL, PostgreSQL или о чём-то в этом роде? Вместо этого я буду рассказывать про крафтовые базы данных.

Ручная сборка. Системы, которые почти никому не известны. Они либо разработаны одним человеком, либо давно заброшены.

Ссылка со слайда
Первый пример — EventQL. Пожалуйста, поднимите руку, если вы когда-нибудь слышали про эту систему. Ни одного человека, кроме тех, кто работает в Яндексе и уже слушал мой доклад. Значит, не зря я эту систему включил в свой обзор.

Это распределенная столбцовая СУБД, разработанная для обработки событий и аналитики. Выполняет очень быстрые SQL-запросы, опенсорс с 26 июля 2016 года, написана на С++, для координации используется ZooKeeper, кроме него зависимостей нет. Что-то мне это напоминает. Нашу замечательную систему, все и так знают название. EventQL — это примерно как ClickHouse, но лучше. Распределенная, массивно-параллельная, column-oriented, масштабируется до петабайт, быстрые range-запросы — все понятно, это все у нас есть. Почти полная поддержка SQL 2009, реалтайм-инсерты и апдейты, автоматическое распределение данных по кластеру, да еще и язык ChartSQL для описания графиков. Как круто! Это же то, что мы всем обещаем и чего у нас нет.
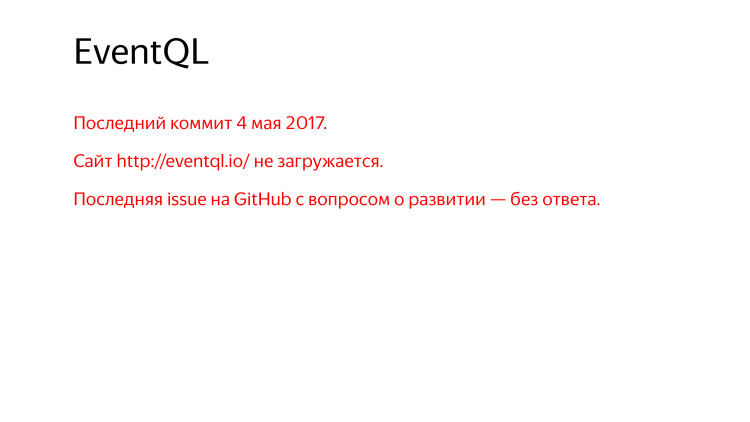
Тем не менее, последний коммит почти год назад, есть сайт, который не загружается, смотреть приходится через web.archive.org.
Спрашивают на GitHub — какие планы по разработке, что будет дальше? Никто не ответил.
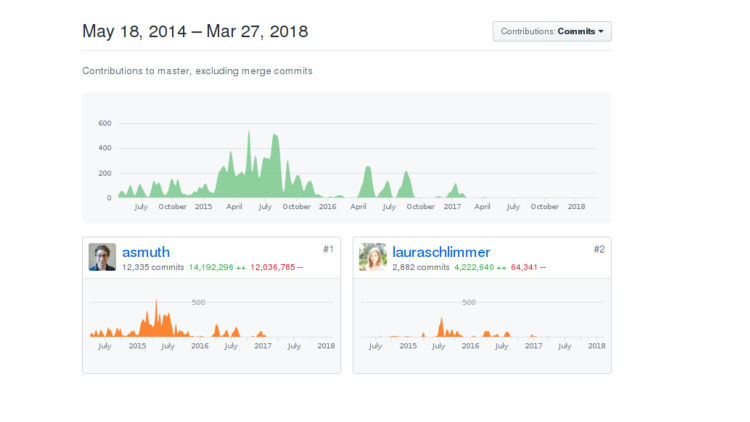
У системы два разработчика. Один — разработчик бэкенда, второй — фронтенда. Не буду показывать, кто из них кто, может, догадаетесь сами. Сделана в компании DeepCortex. Название кажется знакомым, но есть много компаний со словом Deep и со словом Cortex. DeepCortex — это какая-то неизвестная компания из Берлина. Разрабатывается система с 2014 года, довольно долго разрабатывалась внутри, потом ее выпустили в опенсорс и через год забросили.

Это выглядит примерно так: ее подбросили в воздух и подумали, вдруг кто-то ее заметит или она куда-то улетит. К сожалению, нет.
Еще из недостатков — лицензия AGPL, сравнительно неудобная. Даже если она не представляет серьезных ограничений для использования вашей компанией, все равно ее часто боятся, юридический отдел может иметь некоторые пункты против.
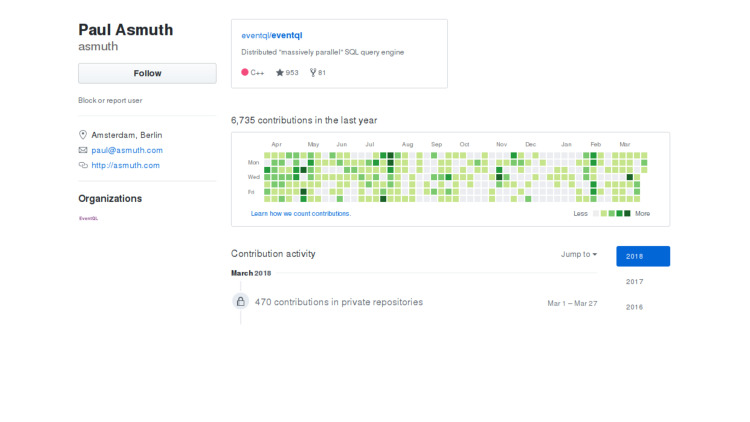
Стал искать, что же произошло, почему не разрабатывается. Посмотрел на аккаунт разработчика, в принципе все нормально, человек живет, продолжает коммитить, правда, все коммиты в приватный репозиторий. Непонятно, что произошло.

То ли человек перешел в другую компанию и потерял интерес к поддержке, то ли изменились приоритеты у компании, то ли какие-то жизненные обстоятельства. Возможно, сама компания чувствовала себя не очень плохо, и опенсорс был сделан на всякий случай. Или просто надоело. Точный ответ я не знаю. Если кто-то знает, пожалуйста, скажите.

Но это все делалось не зря. В первую очередь, ChartSQL для декларативного описания графиков. Теперь нечто похожее используется в системе визуализации данных Tabix для ClickHouse. Есть у EventQL блог, правда, он сейчас недоступен, приходится смотреть через web.archive.org, там файлики .txt. Система реализована очень грамотно, и если вас интересует, вполне можно почитать код, посмотреть интересные архитектурные решения.
Про нее пока все. А следующая система выигрывает у всех, что я буду рассматривать, потому что у нее самое лучшее, самое вкусное название. Система Alenka.
Хотел добавить фотографию упаковки шоколада, но боюсь, будут проблемы с авторскими правами. Что такое Alenka?

Ссылка со слайда
Это аналитическая СУБД, которая выполняет запросы на графических ускорителях. Опенсорс, лицензия Apache 2, 1103 звезды, написана на CUDA, немножко С++, один разработчик из Минска. Есть даже JDBC драйвер. Опенсорс с 2012 года. Правда, с 2016-го система почему-то больше не развивается.

Ссылка со слайда
Это личный проект, не собственность компании, а реально проект одного человека. Это такой исследовательский прототип для исследования возможностей, как можно быстро обрабатывать данные на GPU. Есть интересные тесты от Марка Литвинчика, если интересно, можете посмотреть в блоге. Наверное, многие уже видели там его тесты, что ClickHouse быстрее всех.

У меня нет ответа, почему система заброшена, только догадки. Сейчас человек работает в компании nVidia, наверное, это просто совпадение.

Это отличный пример, потому что повышает интерес, кругозор, вы можете посмотреть и понять, как можно делать, как система может работать на GPU.
Но если вас интересует эта тема, есть еще куча других вариантов. Например, система MapD.
Кто слышал про MapD? Обижаете. Это дерзкий стартап, тоже разрабатывает GPU базу данных. Недавно выпущен в опенсорс под лицензией Apache 2. Не знаю, к чему это, к добру или наоборот. Этот стартап такой успешный, что выложен в опенсорс или наоборот, скоро закроется.
Есть PGStorm. Если вы тут все разбираетесь в PostgreSQL, то про PGStorm должны слышать. Тоже опенсорс, разрабатывается одним человеком. Из закрытых систем есть BrytlytDB, Kinetica и российская компания Полиматика, которая делает систему Business Intelligence. Аналитика, визуализация и всякое такое. И для обработки данных тоже может использовать графические ускорители, возможно, будет интересно посмотреть.

Ссылка со слайда
Можно ли сделать что-то круче, чем GPU? Например, была система, которая обрабатывала данные на FPGA. Это компания Kickfire. Она поставляла свое решение в виде железа вместе с софтом сразу. Правда, компания давно закрылась, это решение было достаточно дорогим и не могло конкурировать с другими такими шкафами, когда вам какой-то вендор приносит этот шкаф, и у вас все магическим образом круто работает.
Далее есть процессоры, в которых есть инструкции для ускорения SQL — SQL in Silicon в новых моделях процессоров SPARC. Но не нужно думать, что вы на Ассемблере напишите join, там такого нет. Там простые инструкции, которые либо делают разжатие по каким-то простым алгоритмам и немножко фильтрации. В принципе, оно не только SQL может ускорять. Для примера, в процессорах Intel есть набор инструкций SSE 4.2 для обработки строк. Когда он появился где-то в 2008 году, то на сайте Intel была статья «Использование новых инструкций процессоров Intel для ускорения обработки XML». Здесь примерно то же самое. Инструкции, полезные для ускорения БД, тоже можно использовать.
Еще один очень интересный вариант — перенос задачи по фильтрации данных частично на SSD. Сейчас SSD стали довольно мощными, это маленький такой компьютер, где есть контроллер, и в него в принципе можно загрузить свой код, если очень постараться. У вас данные будут читаться с SSD, но сразу же фильтроваться и передавать в вашу программу только нужные данные. Очень круто, но все это пока на стадии исследований. Вот статья на VLDB, читайте.
Дальше, некая ViyaDB.

Ссылка со слайда
Она была открыта всего месяц назад. «Аналитическая база данных для несортированных данных». Почему «несортированных» вынесено в название, непонятно, зачем делать такой акцент. Что, в других БД только с сортированными можно работать?
Все нормально, исходники на GitHub, Apache 2.0 лицензия, написана на самом современном С++, все замечательно. Разработчик один, но ничего.

Ссылки со слайда: на сайт и на Хабр
Что мне больше всего понравилось, с чего можно брать пример, так это отличная подготовка запуска. Поэтому я удивлен, что никто не слышал. Есть замечательный сайт, есть документация, есть статья на Хабре, есть статья на Medium, LinkedIn, Hacker News. И что? Все это зря? Вы ничего из этого не посмотрели. Тут говорят, Хабр не торт. Ну, может быть, но отличная вещь.
Что из себя эта система представляет?

Данные в оперативке, в системе идет работа с агрегированными данными. Выполняется постоянно предагрегация. Система для аналитических запросов. Есть некоторая начальная поддержка SQL, но она только начинает разрабатываться, изначально запросы надо было писать в каком-то JSON. Из интересных особенностей то, что вы даете ей запрос, и она на ваш запрос пишет код на С++ сама, этот код генерируется, компилируется, динамически подгружается и обрабатывает ваши данные. Как бы ваш запрос будет обработан настолько оптимально, насколько это возможно. Идеально специализированный код на С++, написанный для вашего запроса. Есть масштабирование, и для координации используется Consul. Это тоже плюс, как вы знаете, это круче чем ZooKeeper. Или нет. Я не уверен, но кажется, что да.
Некоторые предпосылки, из которых эта система исходит, несколько противоречивые. Я большой энтузиаст самых разных технологий, и я не хочу никого ругать. Это просто мое мнение, может, я не прав.
Предпосылка такая, что для того, чтобы постоянно записывать в систему новые данные, причем в том числе задним числом, за час назад, за день назад, за неделю событие. И при этом сразу же гонять по этим данным аналитические запросы.

Ссылка со слайда
Автор утверждает, что для этого система обязательно должна быть in-memory. Это не так. Если интересует, почему, можете почитать статью «Эволюция структур данных в Яндекс.Метрике». Один человек в зале читал.
Вовсе необязательно хранить данные в оперативке. Не буду говорить, что нужно делать и какую систему устанавливать, если вас интересует решение этой проблемы.

Ссылка со слайда
Что хорошего можно изучить? Интересное архитектурное решение — кодогенерация на С++. Если вас интересует эта тема, можно обратить внимание на такой исследовательский проект DBToaster. Исследовательская разработка института EPFL, доступен на GitHub, Apache 2.0. Код на Scala, вы туда даете SQL запрос, этот код генерирует вам исходники на С++, которые будут данные откуда-то читать и обрабатывать самым оптимальным образом. Наверное, но не уверен.

Ссылка со слайда
Это только один подход для кодогенерации, для обработки запросов. Есть даже более популярный подход — генерация кода на LLVM. Суть в том, что ваша программа как бы динамически пишет код на Ассемблере. Ну, не совсем, на LLVM. В качестве примера есть MemSQL. Это изначально OLTP база данных, но для аналитики тоже неплохо подходит. Закрытая, проприетарная, изначально там использовался С++ для кодогенерации. Потом перешли на LLVM. Почему? Вы написали код на С++, должны его скомпилировать, и на это уходят драгоценные пять секунд. И хорошо, если у вас запросы более-менее одинаковые, можно один раз код сгенерировать. Но когда речь идет об аналитике, там у вас ad hoc запросы, и вполне возможно, что каждый раз они не только разные, но даже имеют разную структуру. Если кодогенерация на LLVM, там уходят миллисекунды или десятки миллисекунд, по-разному, иногда больше.
Другой пример — Impala. Тоже использует LLVM. Но если говорить про ClickHouse, там тоже есть кодогенерация, но в основном ClickHouse полагается на векторную обработку запроса. Интерпретатор, но который работает над массивами, поэтому работает очень быстро, как такие системы, как kdb+.
Еще один интересный пример. Самый лучший логотип в моем обзоре.

Ссылка со слайда
Первая и единственная реляционная опенсорсная СУБД, разработанная специально для хранилищ данных и бизнес-аналитики. Доступна на GitHub, лицензия Apache 2. Раньше была GPL, но ее сменили, и правильно сделали. Написана на Java. Последний коммит шесть лет назад. Изначально система разработана некоммерческой организацией Eigenbase, целью организации было разработать основу, максимально расширяемую кодовую базу для БД, которые не только OLTP, но например, одна для аналитики, сама LucidDB, другая StreamBase для обработки потоковых данных.

Что же было шесть лет назад? Хорошая архитектура, хорошо расширяемая кодовая база, больше одного разработчика. Отличная документация. Сейчас ничего не загружается, но через WebArchive посмотреть можно. Отличная поддержка SQL.

Но что-то не так. Задумка хорошая, но это делала некоммерческая организация на какие-то пожертвования, и парочка стартапов была рядом. Почему-то все загнулось. Не смогли найти финансирование, не было энтузиастов, и все эти стартапы давным-давно закрылись.
Но не все так просто. Все это было не зря.

Ссылка со слайда
Есть такой фреймворк — Apache Calcite. Это как бы фронтенд для SQL БД, Он умеет парсить запросы, анализировать, выполнять всякие преобразования оптимизации, составлять план выполнения запросов, предоставляет готовый JDBC-драйвер.
Представьте, что вы вдруг проснулись, у вас было хорошее настроение, и вы решили разработать свою реляционную СУБД. Мало ли, бывает. Теперь вы можете взять Apache Calcite, вам остается дописать только хранение данных, чтение данных, обработку запросов, репликацию, отказоустойчивость, шардирование, все просто. Apache Calcite основан на кодовой базе LucidDB, которая была настолько продвинутой системой, что оттуда взяли весь фронтенд, который теперь в несколько адаптированном виде используется почти во всех продуктах Apache, Hive, Drill, Samza, Storm и даже в MapD, несмотря на то, что он на С++ написан, каким-то образом подключили этот код на Java.

Все эти интересные системы используют Apache Calcite.
Следующая система — InfiniDB. От этих названий кружится голова.

Ссылка со слайда
Была компания Calpont, изначально InfiniDB проприетарная система, и было такое, что с нашей компанией связались менеджеры по продажам, продавали нам эту систему. Было интересно в этом участвовать. Они говорят, что аналитическая СУБД, замечательная, быстрее чем Hadoop, column-oriented, естественно, все запросы будут работать быстро. Но у них тогда не было кластера, система не масштабировалась. Я говорю, что нет кластера — мы покупать не сможем. Смотрю, через полгода вышла версия InfiniDB 4.0, добавили интеграцию с Hadoop, масштабирование, все замечательно.
Еще прошло полгода, и исходники доступны в опенсорсе. Я тогда подумал, чего я сижу, разрабатываю что-то, надо же брать, есть готовое.
Стали смотреть, как можно адаптировать, воспользоваться. Еще через год компания обанкротилась. Но исходники доступны.
Это называется посмертный опенсорс. И это хорошо. Если какая-то компания начинает не очень хорошо себя чувствовать, надо, чтобы хоть какое-то наследие осталось, чтобы другие могли пользоваться.

Ссылка со слайда
Это все было не зря. На основе исходников InfiniDB в системе MariaDB теперь присутствует движок таблиц под названием ColumnStore. По сути, это и есть InfiniDB. Компании больше нет, люди теперь в других местах работают, но наследие осталось, и это замечательно. Про MariaDB знают все. Если вы ее используете, и вам нужно прикрутить по быстренькому аналитический движок column-oriented, можете брать ColumnStore. По секрету скажу, это не самое лучшее решение. Если вам нужно самое лучшее решение, то вы знаете, к кому идти и что использовать.
Еще одна система со словом Infini в названии. У них странный логотип, эта линия как будто вниз загибается. И еще непонятный шрифт, почему-то нет антиалиасинга, как будто рисовали в Paint. А все буквы большие, наверное, для устрашения конкурентов.

Ссылки со слайда: на сайт, на GitHib
Я энтузиаст всяких технологий, очень уважительно отношусь ко всяким интересным решениям. Я не издеваюсь, не надо думать.
Что же из себя представляла эта система? Это уже не аналитическая система, это OLTP. Система для обработки транзакций на экстремальных масштабах. Есть сайт, достоинства этой системы в том, что сайт загружается. Потому что я когда смотрю на все другие, привык, что там будет паркинг доменов или что-то еще. Исходники доступны. Сейчас лицензия GPL. Раньше была AGPL, но к счастью, автор быстро изменил ее. Написано на С++, больше одного разработчика, выложено в опенсорс в ноябре 2013, а в январе 2014 уже заброшена. Полтора месяца. Почему? Какой смысл? Зачем так делать?

OLTP-база с изначальной поддержкой SQL, личный проект, за ним не стоит никакая компания. Автор сам на Hackers News говорит, что выложено в опенсорс в надежде привлечь энтузиастов, которые будут работать над этим продуктом.

Эта надежда всегда обречена на провал. У вас есть идея, вы молодец, вы энтузиаст. Значит, вам же эту идею и делать. Вряд ли кто-то другой сможет вдохновиться этим. Или вам придется очень постараться, чтобы вдохновить кого-то. Так-то трудно надеяться, чтобы откуда ни возьмись на другом конце света появился человек, который начнет дописывать чужой код на GitHub.
Во-вторых, возможно, просто недооценка сложности. Разработка СУБД — это не приключение на 20 минут. Это сложно, долго, дорого.
Это очень интересный кейс, многие слышали, RethinkDB. Этот пример — не аналитическая база, не OLTP, а документоориентированная.

У этой системы многократно менялась концепция. Перепродумывалась. Скажем, в 2011 году было написано, что это движок для MySQL, который в сто раз быстрее на SSD, так было написано на официальном сайте. Потом было сказано, что это система с протоколом memcached, тоже оптимизирована для SSD. А через некоторое время, что это БД для реалтайм приложений. То есть для того, чтобы подписываться на данные и принимать обновления прямо в реальном времени. Скажем, всякие интерактивные чаты, онлайн-игры. Попытка поиска ниши. Система документо-ориентированная, модель данных JSON. В связи с этим эту систему часто сравнивают с MongoDB. Хотя это несправедливо. Что думают про MongoDB разработчики, которые хорошо себя вели? MongoDB должна умереть. Это не мои слова, я не желаю никому зла, так говорил Олег из компании «PostgreSQL профессиональный».
И вообще что думают такие разработчики? Монго — они же все неправильно делают. Они не смогли нормально реализовать протокол консенсуса и даже с задачей сохранения данных система справляется не очень. Вроде бы в новых версиях с этим получше, раньше было не особенно.
Что такое RethinkDB? Репликация сделана правильно, люди реализовали протокол консенсуса RAFT. Язык запросов замечательный, потому что он встраивается в клиентские библиотеки, и разработчики пишут запросы так, что прямо радостно писать запросы. Не тупые JSON, а что-то типа LINQ или еще более удобно. Язык запросов ReQL, написано на С++, что неудивительно, та же Монго на С++.

Ссылки со слайда: на сайт, на GitHib
Но это не все. Реально классный сайт. Система давно разрабатывается, гораздо больше одного разработчика, просто супер документация по этой системе, и самое главное, поддержка сообщества. Настолько хорошая, что это лучший пример, с которого надо брать пример. 20938 звезд на GitHub. Это уже что-то заоблачное.

Система разрабатывается до сих пор, но если посмотреть на график коммитов, то видно, что был период, когда разрабатывалась активно, а сейчас постепенно заглохла. Почему? Что не так?

Это стартап, в 2009 году получили инвестиции, дальше поиск ниши, поиск того, как лучше позиционировать этот продукт. К сожалению, стартап не стал расти, в 2016 году компания закрылась. Разработчики ушли работать в другую компанию, и казалось бы, на этом все, но нет. И это очень хорошо, потому что разработчики смогли создать замечательное сообщество вокруг своей системы, и благодаря пожертвованиям удалось выкупить права на продукт RethinkDB, на название, логотип и все остальное, и передать их в компанию The Linux Foundation. Заодно изменили лицензию с AGPL на Apache 2, существенно менее ограничительную. Теперь продукт полностью свободен, коммить — не хочу.

Ссылка со слайда
Разработка продолжается, выходят новые релизы, и в принципе, я рекомендую, если вас интересует, имеет смысл посмотреть, что это такое. Система чудесная, я действительно так думаю.
Если вас интересует, почему стартап развалился и почему оно перестало активно развиваться, то есть рассказ об ошибках от основателя компании. Это очень ценно, потому что не я вам буду говорить по каким-то обрывочным сведениям, а там реально написано, какие, по мнению основателя компании, были сделаны ошибки.
Переходим дальше. Иногда бывает, что перестают быть актуальными не отдельные системы управления БД, а целые направления. Скажем, направление XML баз данных было популярно лет 15 назад.
Если открыть какой-то новостной сайт за это время, середину 2000-х, можно увидеть забавные цитаты. Например, в будущем технология XML будет занимать все большую роль в задачах обработки и хранения данных. Говорит топ-менеджер какой-то компании, которая начала разрабатывать эти замечательные БД. Это будущее уже наступило, а потом прошло мимо.

Ссылки со слайда: на сайт, на GitHub
Рассмотрим один пример, это система управления БД Sedna. Прирожденная XML БД, разработана в Институте системного программирования РАН. Не думайте, что там по темным коридорам ходят профессоры с перфокартами. Например, один из основных разработчиков этой системы сейчас работает в компании Яндекс. Конечно, он уже не разрабатывает эту Sedna, все давно забыто, сейчас он делает одну супер СУБД, которая просто чудо, там все сделано правильно и даже лучше. Надеюсь, потом этот человек сам об этом расскажет.
Последний коммит в 2013, и особо не разрабатывается, потому что уже неактуально. Были популярны XML БД, сейчас непопулярны, никому не нужны.
Не мог не добавить в свой доклад отдельный раздел — СУБД от Константина Книжника.
Ссылка со слайда
Константин Книжник — это человек, которого следовало бы занести в Книгу рекордов Гиннеса как человека, который единолично разработал самое большое количество СУБД. Есть личный сайт garret.ru, судите сами, какие интересные СУБД. Полностью уверен, что все эти системы работают надежно. Я зашел на личный сайт этого человека, все прекрасно описано, документация, архитектура. И там расположен его личный адрес и телефон.

Ссылка со слайда
Он продолжает регулярно писать новые СУБД и движки. 2014 год — IMCS, расширение для PostgreSQL, предназначено для хранения и обработки временных рядов. Подключаете к PostgreSQL, система там не так чтобы хорошо интегрирована в SQL, доступна в виде некоторых табличных функций, и внутри частично свой язык. Но вы можете писать типа select, создать временной ряд и тому подобное. Судя по юз-кейсу, это для аналитики биржевых данных. Уверен, это не просто так разработано, а для реальных задач, реальных заказчиков. И это очень круто, когда один человек может сделать специализированную систему. Написал, готово, и работает лучше, чем что-то другое. Специально сделано то, что заказывали.
Почему так бывает, что какие-то опенсорсные продукты оказываются заброшенными? Причины можно классифицировать.

В первую очередь, кому это все принадлежит, кто делал? Первый пример самый простой, если наш опенсорс — личный проект. Тут все просто: надоело, изменились какие-то обстоятельства, потерян интерес. И в конце концов, сколько можно времени тратить лично на свой проект. Или просто недооценка трудозатрат.
Если стартап — тоже все просто. Получили финансирование, стартап не растет, компания закрывается. Не смогли выбрать нишу, на которую позиционировать свой продукт, не смогли получить следующий раунд инвестиций.
Самый частый пример — сторонний продукт компании. Компания не занимается исключительно тем, что делает этот опенсорс-продукт. Она делает что-то другое, но в качестве бонуса — вот вам, пожалуйста, мы выложили, делайте с этим что-нибудь.
Тут, возможно, было несколько разработчиков или даже один внутри компании, но он ушел.
Другой пример — компания просто думает, зачем тратить ресурсы? Наши разработчики сидят и пилят этот код, лучше пусть они займутся чем-то другим.
Или, например, выкладка в опенсорс в связи с банкротством компании. Этот пример положительный. Если компании больше нет, а код есть, можно воспользоваться, полезно.
Еще пример — когда что-то выкладывают в опенсорс по какому-то недоразумению. Мне не очень удобно об этом говорить в Санкт-Петербурге, но тут примером является KPHP.
Дальше пример — разработка института. Делали исследование, защитили диссертацию, дальше разрабатывать не нужно, исследование завершено.

Что же нужно, чтобы делать настоящий живой опенсорс, чтобы все радовались: и разработчики, и компания, и люди, которые пользуются? В первую очередь — масштабирование разработки. Нужно, чтобы разрабатывал не один человек. Я очень стараюсь, чтобы код писал не только я. Как масштабировать? Как и БД: шардирование, репликация.
Понятное позиционирование. Надо, чтобы система решала задачу, которая действительно всем нужна. А лучше, чтобы эту задачу никто больше не умел решать или никто больше не умел решать так хорошо.
Фокусировка на конкретной нише. Скажем, если вы заходите на сайт какого-нибудь стартапа, и там написано, что у нас multimodel DB, она графовая, аналитическая, OLTP, строго консистентная, документоориентированная и, до кучи, навигационная и постреляционная. Может, этот сайт лучше закрыть? Может быть, эта система не справляется с тем, чтобы решать хоть какую-то из этих задач достаточно хорошо. Если у вас есть какой-то юз-кейс, то, скорее всего, это конкретная задача, которую надо уметь хорошо решать. Для этого нужна система, которая эту задачу хорошо решает.
Надежная поддержка родительской компании. Тут без комментариев. Не ограничительная лицензия, чтобы в других компаниях не пугать юридический отдел, эти люди всего боятся. Преимущества вашей системы должны исходить из фундаментальных причин. Скажем, если у вас БД для обработки XML — это как-то не очень. Может, никому и не надо больше хранить в XML данные. А если у вас документоориентированная БД, это уже другое. Всем нужно хранить документы, и неважно, в чем именно. Кроме того, для хорошего опенсорса очень важна поддержка развития сообщества. Это значит вовсе не только то, что вам нужно мержить pull-реквесты. Это значит — вам нужно, чтобы люди чувствовали, что вы есть, вы существуете, отвечаете на вопросы, продукт развивается. Именно это позволит сделать хороший и живой опенсорс. На этом все, спасибо.
