Различия Postgres Pro Enterprise и PostgreSQL
1. Кластер multimaster
Расширение multimaster и его поддержка в ядре, которые есть только в версии Postgres Pro Enterprise, дают возможность строить кластеры серверов высокой доступности (High Availability). После каждой транзакции гарантируется глобальная целостность (целостность данных в масштабах кластера), т.е. на каждом его узле данные будут идентичны. При этом легко можно добиться, чтобы производительность по чтению масштабировалась линейно с ростом количества узлов.
В ванильном PostgreSQL есть возможность строить высокодоступные кластеры с помощью потоковой репликации, но для определения вышедших из строя узлов и восстановления узла после сбоя требуются сторонние утилиты, и хитроумные скрипты. multimaster справляется с этим сам, работает из коробки без использования внешних утилит или сервисов.
Масштабирование по чтению в ванильном PostgreSQL возможно при репликации в режиме горячего резерва (Hot-standby), но с существенной оговоркой: приложение должно уметь разделять read-only и read-write запросы. То есть для работы на ванильном кластере приложение, возможно, придется переписать: по возможности использовать отдельные соединения с базой для read-only транзакций, и распределять эти соединения по всем узлам. Для кластера с multimaster писать можно на любой узел, поэтому проблемы с разделением соединений с БД на пишущие и только читающие нет. В большинстве случаев переписывать приложение не надо.
Для обеспечения отказоустойчивости приложение должно уметь делать reconnect — т.е. совершать попытку восстановления соединения с базой при его нарушении. Это касается как ванильного кластера, так и multimaster.
С помощью логической репликации в ванильном PostgreSQL можно реализовать асинхронную двунаправленную репликацию (например BDR от 2ndQuadrant), но при этом не обеспечивается глобальная целостность и возникает необходимость разрешения конфликтов, а это можно сделать только на уровне приложения, исходя из его внутренней логики. То есть эти проблемы перекладываются на прикладных программистов. Наш multimaster сам обеспечивает изоляцию транзакций (сейчас реализованы уровни изоляции транзакций «повторяемое чтение» (Repeatable Read) и «чтение фиксированных данных» (Read Committed). В процессе фиксации транзакции все реплики будут согласованы, и пользовательское приложение будет видеть одно и то же состояние базы; ему не надо знать, на какой машине выполняется запрос. Чтобы этого добиться и получить предсказуемое время отклика в случае отказа узла, инициировавшего транзакцию, мы реализовали механизм 3-фазной фиксации транзакций (3-phase commit protocol). Этот механизм сложнее, чем более известный 2-фазный, поэтому поясним его схемой. Для простоты изобразим два узла, имея в виду, что на самом деле аналогично узлу 2 обычно работает четное число узлов.

Рис. 1. Схема работы multimaster
Запрос на фиксацию транзакции приходит на узел 1 и записывается в WAL узла. Остальные узлы кластера (узел 2 на схеме) получают по протоколу логической репликации информацию об изменениях данных и, получив запрос подготовить фиксацию транзакции (prepare transaction) применяют изменения (без фиксации). После этого они сообщают узлу, инициировавшему транзакцию, о своей готовности зафиксировать транзакцию (transaction prepared). В случае, когда хотя хотя бы один узел не отвечает, транзакция откатывается. При положительном ответе всех узлов, узел 1 посылает на узлы сообщение, что транзакцию можно зафиксировать (precommit transaction).
Здесь проявляется отличие от 2-фазной транзакции. Это действие на первый взгляд может показаться лишним, но на самом деле это важная фаза. В случае 2-фазной транзакции узлы зафиксировали бы транзакцию и сообщили об этом 1-му, инициировавшему транзакцию узлу. Если бы в этот момент оборвалась связь, то узел 1, не зная ничего об успехе/неуспехе транзакции на узле 2, вынужден был бы ждать ответа, пока не станет понятно, что он должен сделать для сохранения целостности: откатить или зафиксировать транзакцию (или фиксировать, рискуя целостностью). Итак, в 3-фазной схеме во время 2-ой фазы все узлы голосуют: фиксировать ли транзакцию. Если большинство узлов готово зафиксировать ее, то арбитр объявляет всем узлам, что транзакция зафиксирована. Узел 1 фиксирует транзакцию, отправляет commit по логической репликации и сообщает метку времени фиксации транзакции (она необходима всем узлам для соблюдения изоляции транзакций для читающих запросов. В будущем метка времени будет заменена на CSN — идентификатор фиксации транзакции, Commit Sequence Number). Если узлы оказались в меньшинстве, то они не смогут ни записывать, ни читать. Нарушения целостности не произойдет даже в случае обрыва соединения.
Архитектура multimaster выбрана нами с расчетом на будущее: мы заняты разработкой эффективного шардинга. Когда таблицы станут распределенными (то есть данные на узлах уже будут разными), станет возможно масштабирование не только по чтению, но и по записи, так как не надо будет параллельно записывать все данные по всем узлам кластера. Кроме того мы разрабатываем средства общения между узлами по протоколу RDMA (в коммутаторах InfiniBand или в устройствах Ethernet, где RDMA поддерживается), когда узел напрямую общается к памяти других узлов. За счет этого на упаковку и распаковку сетевых пакетов тратится меньше времени, и задержки при передаче данных получаются небольшие. Поскольку узлы интенсивно общаются при синхронизации изменений, это даст выигрыш в производительности всего кластера.
2. 64-разрядные счетчики транзакций
Эта принципиальная переделка ядра СУБД нужна только для сильно нагруженных систем, но для них она не просто желательна. Она необходима. В ядре PostgreSQL счетчик транзакций 32-разрядный, это значит, более чем до 4 миллиардов им досчитать невозможно. Это приводит к проблемам, которые решаются «заморозкой» — специальной процедурой регламентного обслуживания VACUUM FREEZE. Однако если счетчик переполняется слишком часто, то затраты на эту процедуру оказываются очень высокими, и могут привести даже к невозможности записывать что-либо в базу. В России сейчас не так уж мало корпоративных систем, у которых переполнение происходит за 1 день, ну, а базы, переполняющиеся с недельной периодичностью, теперь не экзотика. На конференции разработчиков PGCon 2017 в Оттаве рассказывали, что у некоторых заказчиков переполнения счетчика происходило за 2–3 часа. В наше время люди стремятся складывать в базы те данные, которые раньше выбрасывали, относясь с пониманием к ограниченным возможностям тогдашней техники. В современном бизнесе часто заранее не известно, какие данные могут понадобиться для аналитики.
Проблема переполнения счетчика носит название (transaction ID wraparound), поскольку пространство номеров транзакций закольцовано (это наглядно объясняется в статье Дмитрия Васильева). При переполнении счетчик обнуляется и идет на следующий круг.
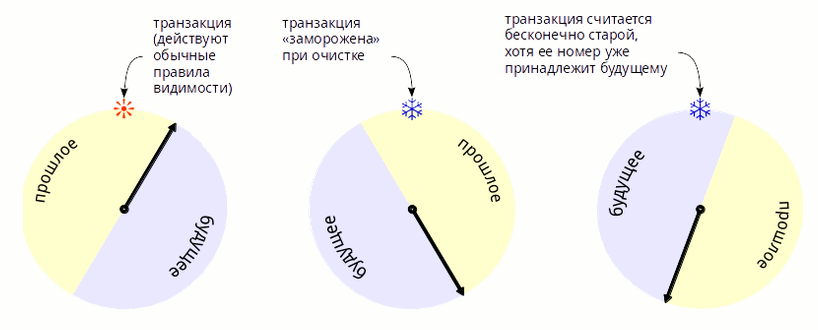
Рисунок 2. Как действует заморозка транзакций, отставших больше, чем на полкруга.
В ванильном PostgreSQL (то есть с заведомо 32-разрядным счетчиком транзакций) тоже что-то делается для облегчения проблемы transaction wraparound. Для этого в версии 9.6 в формат карты видимости (visibility map) был добавлен бит all-frozen, которым целые страницы помечаются как замороженные, поэтому плановая (когда накапливается много старых транзакций) и аварийная (при приближении к переполнению) заморозки происходят намного быстрее. С остальными страницами СУБД работает в обычном режиме. Благодаря этому общая производительность системы при обработке переполнения страдает меньше, но проблема в принципе не решена. Описанная ситуация с остановкой системы по-прежнему не исключена, хоть вероятность ее и снизилась. По-прежнему надо тщательно следить за настройками VACUUM FREEZE, чтобы не было неожиданных проседаний производительности из-за ее работы.
Замена 32-разрядных счетчиков на 64-разрядные отодвигает переполнение практически в бесконечность. Необходимость в VACUUM FREEZE практически отпадает (в текущей версии заморозка все еще используется для обработки pg_clog и pg_multixact и в экстренном случае, о котором ниже). Но в лоб задача не решается. Если у таблицы мало полей, и особенно если эти поля целочисленные, ее объем может существенно увеличиться (ведь в каждой записи хранятся номера транзакции, породивших запись и той, что эту версию записи удалила, а каждый номер теперь состоит из 8 байтов вместо 4). Наши разработчики не просто добавили 32 разряда. В Postgres Pro Enterprise верхние 4 байта не входят в запись, они представляют собой «эпоху» — смещение (offset) на уровне страницы данных. Эпоха добавляется к обычному 32-разрядному номеру транзакции в записях таблицы. И таблицы не распухают.
Теперь, если система попытается записать XID, который не помещается в диапазон, определенный эпохой для страницы, то мы должны либо увеличить сдвиг, либо заморозить целую страницу. Но это безболезненно выполняется в памяти. Остается ограничение в случае, когда самый минимальный XID, который еще может быть востребован снимками данных (snapshots), отстанет от того, который мы хотим записать в эту страницу, больше, чем на 232. Но это маловероятно. К тому же в ближайшее время мы скорее всего преодолеем и это ограничение.
Другая проблема 32-разрядных счетчиков в том, что обработка переполнений очень сложный процесс. Вплоть до версии 9.5 в соответствующем коде находили и исправляли весьма критичные баги, и нет гарантий, что баги не проявятся в следующих версиях. В нашей реализации 64-разрядного счетчика транзакций заложена простая и ясная логика, поэтому работать с нею и дальше ее развивать будет проще, чем бороться с переполнением.
Файлы данных систем с 64-разрядными счетчиками бинарно несовместимы с 32-разрядными, но у нас есть удобные утилиты для конвертации данных.
3. Постраничное сжатие
В PostgreSQL, в отличие от большинства других СУБД, отсутствует сжатие (компрессия) на уровне страниц (page level compression). Сжимаются только TOAST-данные. Если в БД много записей с относительно небольшими текстовыми полями, то сжатием можно было бы в несколько раз уменьшить размер БД, что помогло бы не только сэкономить на дисках, но и повысить производительность работы СУБД. Особенно эффективно могут ускоряться за счет сокращения операций ввода-вывода аналитические запросы, читающие много данных с диска и не слишком часто изменяющие их.
В Postgres-сообществе предлагают использовать для сжатия файловые системы с поддержкой компрессии. Но это не всегда удобно и возможно. Поэтому в Postgres Pro Enterprise мы добавили собственную реализацию постраничного сжатия. По результатам тестирования у различных пользователей Postgres Pro размер БД удалось уменьшить от 2 до 5 раз.
В нашей реализации страницы хранятся сжатыми на диске, но при чтении в буфер распаковываются, поэтому работа с ними в оперативной памяти происходит точно так же, как обычно. Разворачивание сжатых данных и их сжатие происходит быстро и практически не увеличивает загрузку процессора.
Поскольку объем измененных данных при сжатии страницы может увеличиться, мы не всегда можем вернуть ее на исходное место. Мы записываем сжатую страницу в конец файла. При последовательной записи сбрасываемых на диск страниц может значительно возрасти общая производительность системы. Это требует файла отображения логических адресов в физические, но этот файл невелик и издержки незаметны.
Размер самого файла при последовательной записи увеличится. Запуская по регламенту или вручную сборку мусора, мы можем периодически делать файл компактнее (дефрагментировать его), перемещая все непустые страницы в начало файла. Собирать мусор можно в фоновом режиме (блокируется страница, но не вся таблица), причем мы можем задать число фоновых процессов, собирающих мусор.
| Сжатие (алгоритм) | Размер (Гб) | Время (сек) |
|---|---|---|
| без сжатия | 15.31 | 92 |
| snappy | 5.18 | 99 |
| lz4 | 4.12 | 91 |
| postgres internal lz | 3.89 | 214 |
| lzfse | 2.80 | 1099 |
| zlib (best speed) | 2.43 | 191 |
| zlib (default level) | 2.37 | 284 |
| zstd | 1.69 | 125 |
Сравнение механизмов компрессии. Параметры теста: pgbench -i -s 1000
Для сжатия мы выбрали современный алгоритм zstd (его разработали в Facebook). Мы опробовали различные алгоритмы сжатия, и остановились на zstd: это лучший компромисс между качеством и скоростью сжатия, как видно из таблицы.
4. Автономные транзакции
Технически суть автономной транзакции в том, что эта транзакция, выполненная из основной, родительской транзакции, может фиксироваться или откатываться независимо от фиксирования/отката родительской. Автономная транзакция выполняется в собственном контексте. Если определить не автономную, а обычную транзакцию внутри другой (вложенная транзакция) то внутренняя всегда откатится, если откатится родительская. Такое поведение не всегда устраивает разработчиков приложений.
Автономные транзакции часто используются там, где нужны логирование действий или аудит. Например, необходима запись о попытке некоторого действия в журнал в ситуации, когда транзакция откатывается. Автономная транзакция позволяет сделать так, чтобы «чувствительные» действия сотрудников (просмотр или внесение изменений в счета клиентов) всегда оставляли следы, по которым можно будет в экстренной ситуации восстановить картину (пример на эту тему будет ниже).
В таких СУБД как Oracle и DB2 (но не MS SQL) автономные транзакции формально задаются не как транзакции, а как автономные блоки внутри процедур, функций, триггеров и неименованных блоков. В SAP HANA тоже есть автономные транзакции, но их как раз можно определять и как транзакции, а не только блоки функций.
В Oracle, например, автономные транзакции определяются в начале блока как PRAGMA AUTONOMOUS_TRANSACTION. Поведение процедуры, функции или неименованного блока определяется на этапе их компиляции и во время исполнения меняться не может.
В PostgreSQL автономных транзакций вообще нет. Их можно имитировать, запуская новое соединение при помощи dblink, но это выливается в накладные расходы, сказывается на быстродействии и попросту неудобно. Недавно, после появления модуля pg_background, было предложено имитировать автономные транзакции, запуская фоновые процессы. Но и это оказалось неэффективно (к причинам мы вернемся ниже, при анализе результатов тестов).
В Postgres Pro Enterprise мы реализовали автономные транзакции в ядре СУБД. Теперь ими можно пользоваться и как вложенными автономными транзакциями, и в функциях.
Во вложенных автономных транзакциях можно определять все доступные PostgreSQL уровни изоляции — Read Committed, Repeatable Read и Serializable — независимо от уровня родительской транзакции. Например:
BEGIN TRANSACTION
<..>
BEGIN AUTONOMOUS TRANSACTION ISOLATION LEVEL REPEATABLE READ
<..>
END;
END;
Все возможные комбинации работают и дают разработчику необходимую гибкость. Автономная транзакция никогда не видит результатов действий родительской, ведь та еще не зафиксирована. Обратное зависит от уровня изоляции основной. Но в отношениях их с транзакцией, стартовавшей независимо, будут действовать обычные правила изоляции.
В функциях синтаксис немного отличается: ключевое слово TRANSACTION выдаст ошибку. Автономный блок в функции определяется всего лишь вот так:
CREATE FUNCTION <..> AS
BEGIN;
<..>
BEGIN AUTONOMOUS
<..>
END;
END;
Соответственно уровень изоляции задать нельзя, он определяется уровнем родительской транзакции, а если он явно не задан, то уровнем по умолчанию.
Приведем пример, который считается одним из классических в мире коммерческих СУБД. В некотором банке в таблице customer_info хранятся данные клиентов, их долги
CREATE TABLE customer_info(acc_id int, acc_debt int);
INSERT INTO customer_info VALUES(1, 1000),(2, 2000);
Пусть эта таблица будет недоступна напрямую сотруднику банка. Однако они имеют возможность проверить долги клиентов с помощью доступной им функции:
CREATE OR REPLACE FUNCTION get_debt(cust_acc_id int) RETURNS int AS
$$
DECLARE
debt int;
BEGIN
PERFORM log_query(CURRENT_USER::text, cust_acc_id, now());
SELECT acc_debt FROM customer_info WHERE acc_id = cust_acc_id INTO debt;
RETURN debt;
END;
$$ LANGUAGE plpgsql;
Перед тем, как подсмотреть данные клиента, функция записывает имя пользователя СУБД, номер эккаунта клиента и время операции в в таблицу лог:
CREATE TABLE log_sensitive_reads(bank_emp_name text, cust_acc_id int, query_time timestamptz);
CREATE OR REPLACE FUNCTION log_query(bank_usr text, cust_acc_id int, query_time timestamptz) RETURNS void AS
$$
BEGIN
INSERT INTO log_sensitive_reads VALUES(bank_usr, cust_acc_id, query_time);
END;
$$ LANGUAGE plpgsql;
Мы хотим, чтобы сотрудник имел возможность осведомиться о долгах клиента, но, дабы не поощрять праздное или злонамеренное любопытство, хотим всегда видеть в логе следы его деятельности.
Любопытный сотрудник выполнит команды:
BEGIN;
SELECT get_debt(1);
ROLLBACK;
В этом случае сведения о его деятельности откатятся вместе с откатом всей транзакции. Поскольку нас это не устраивает, мы модифицируем функцию логирования:
CREATE OR REPLACE FUNCTION
log_query(bank_usr text, cust_acc_id int, query_time timestamptz) RETURNS void AS
$$
BEGIN
BEGIN AUTONOMOUS
INSERT INTO log_sensitive_reads VALUES(bank_usr, cust_acc_id, query_time);
END;
END;
$$ LANGUAGE plpgsql;
Теперь, как бы не старался сотрудник замести следы, все его просмотры данных клиентов будут протоколироваться.
Автономные транзакции удобнейшее средство отладки. Сомнительный участок кода успеет записать отладочное сообщение перед тем, как неудачная транзакция откатится:
BEGIN AUTONOMOUS
INSERT INTO test(msg) VALUES('STILL in DO cycle. after pg_background call: '||clock_timestamp()::text);
END;
В заключение о производительности. Мы тестировали нашу реализацию автономных транзакций в сравнении с теми же SQL без автономных транзакций, с решением с «голым» dblink, комбинацию dblink с pgbouncer и с контролем соединения.
Расширение pg_background создает три функции: pg_background_launch(query) запускает фоновый процесс background worker, который будет исполнять переденный функции SQL; pg_background_result(pid) получает результат от процесса, созданного pg_background_launch(query) и pg_background_detach(pid) отсоединяет фоновый процесс от его создателя. Код, исполняющий транзакцию не слишком интуитивный:
PERFORM * FROM pg_background_result(pg_background_launch(query))
AS (result text);
Но более существенно, что, как и ожидалось, создание процесса на каждый SQL работает медленно. Из истории создания pg_background известно, что предполагалась четвертая функция pg_background_run(pid, query), которое передает новое задание уже запущенному процессу. В этом случае время на создание процесса не будет тратиться на каждый SQL, но это функция недоступна в текущей реализации.
Роберт Хаас, создавший первую версию pg_background, говорит:
«Я скептически отношусь к такому подходу [к имитации автономных транзакций при помощи pg_background]. Как и Грег Старк, Серж Рило и Константин Пан, я полагаю, что автономные транзакции следует выполнять внутри одного и того же серверного процесса [backend], не полагаясь на фоновые процессы [background_workers]. При таком подходе мы вряд ли выйдем за лимит числа фоновых процессов [max_worker_processes], и работать он, скорее всего, будет эффективнее, особенно когда автономная транзакция выполняет небольшую работу, внося, скажем, небольшую запись в дневник».
Именно так и реализован наш вариант автономных транзакций: материнский процесс запоминает свой контекст, переключается на новый и, после исполнения автономной транзакции, возвращается к материнскому. Результаты тестов подтверждают соображения Хааса, механизм, использующий pg_background работает в 6–7 раз медленнее, чем автономные транзакции в Postgres Pro Enterprise.
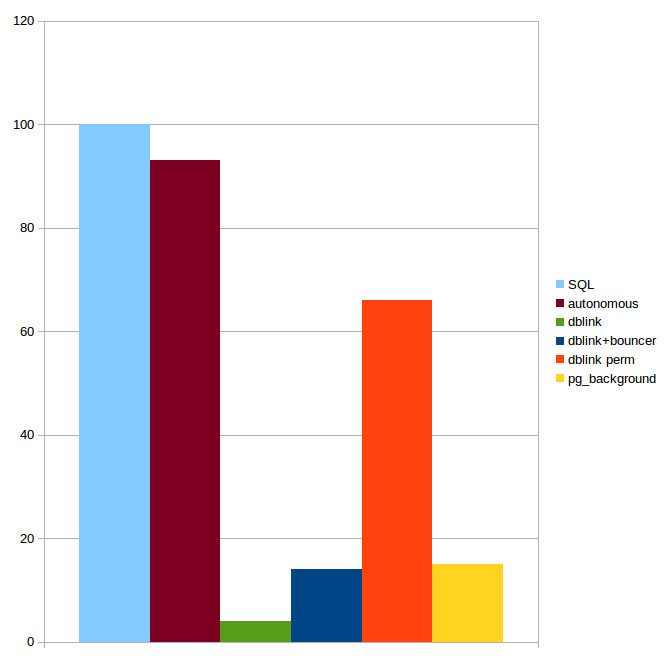
Рис. 3. Производительность различных реализаций автономных транзакций. Тесты проводились нами на базе pgbech с INSERT в таблицу pgbench_history. Коэффициент масштабирования при инициализации БД был равен 10. TPS на «чистом» SQL принят за 100.
PS. Мы будем рады узнать ваше мнение об актуальности и возможных применениях этих новшеств!
