Разбор финальных задач Яндекс.Алгоритма 2014
1 августа в офисе Яндекса, открывшемся недавно в Берлине, состоялся финал нашего чемпионата по программирования. И его победителем снова стал известный всем, интересующимся спортивным программированием, Геннадий Короткевич.Задания для Алгоритма готовила международная команда. В нее вошли программисты из России, Беларуси, Польши и США. Это специалисты МГУ имени М.В. Ломоносова, Университета Карнеги-Меллон, сотрудники Яндекса и Google. В Яндексе задачи составляли разработчики минского и киевского офиса, а потом проверяли их на своих коллегах. Один из составителей в прошлом году сам был финалистом Алгоритма. Специально для Хабрахабра мы разобрали с авторами все задачи.

На победу претендовали многие финалисты. Среди них были победители и призеры АСМ ICPC и TopCoder Open, разработчики Google и Facebook. В финальном раунде сражались призёры Алгоритма-2013 Евгений Капун и Ши Бисюнь, чемпион АСМ ICPC Михаил Кевер, а также один из самых титулованных спортивных программистов мира Пётр Митричев. В этом году побороться за приз решил также Макото Соэдзимо — составитель заданий для Алгоритма-2013 и администратор TopCoder Open.
Борьба за первое место разгорелась между ним и Хосакой Кадзухиро из Токийского университета. Лучший результат — четыре задачи при 66 минутах штрафного времени — показал Короткевич, подтвердив титул чемпиона. Кадзухиро решил столько же задач, но набрал больше штрафного времени (90 минут) и занял второе место. Третье место завоевал Ван Циньши из университета Цинхуа: он решил четыре задачи при 125 минутах штрафа.
Задача A. 1024 Stack EditionИмя входного файла: Standard inputИмя выходного файла: Standard outputОграничение по времени: 1 secondОграничение по памяти: 512 mebibytesНедавно девочка Ксюша купила в онлайн магазине приложение »1024 Stack Edition» — пошаговую аркаду. Как можно догадаться из названия, игра разворачивается вокруг некоторого стека, наполненного степенями двойки. По правилам игры, на каждом ходу игрок может выполнить одно из трех действий над стеком:
Добавить случайное число в конец стека. Убрать последее число из стека. Если два последних числа равны, то заменить их на их сумму. Если игрок выбирает добавить случайное число в стек, то с шансом p в стек добавится число 1 и с шансом 1-p добавится число 2. Если игрок выбирает убрать последнее число из стека, он платит штраф в 1 монету. Обратите внимание, что все остальные операции, кроме удаления последнего элемента из стека, не приводят к уплате штрафа. Для того чтобы выиграть, игроку необходимо привести стек в такое состояние, что в нем находится лишь один элемент — 1024. При этом, чем меньше штрафа он заплатит — тем лучше.Как-то раз, Ксюша оставила свой телефон без присмотра, а по возвращению обнаружила, что кто-то играл в »1024 Stack Edition». Ксюше не интересно узнать, кто это был и каковы были его мотивы. Ей интересно узнать, каково математическое ожидание штрафа, который лично ей придется заплатить при оптимальной игре, если она доиграет партию. Ваша задача, как вы могли уже догадаться, посчитать это число.
Разбор задачи A
Для начала рассмотрим случай, когда N = 0. Пусть f (i) — это ожидаемое наименьшее количество монет, которое потребуется потратить, чтобы собрать число 2i. Приведем формулы для подсчета f (i) в случае, если p < 100. Если же p = 100, то эти же формулы адаптируются тривиальным образом.
f (0) = 1.0/p — 1; f (1) = min (f (0) • 2; 1/(1 — p) — 1, 1 — p); f (i) = 2 • f (i — 1), i > 1. В случае с N = 0 ответом на задачу будет f (10).Теперь предположим, что N > 0. Обозначим через g (i, j) ожидаемое наименьшее количество монет, которые нам нужно будет потратить, чтобы из последних (верхних) i элементов стека получить только одно число 2j. Подсчет g (i, *) для фиксированного i будет происходить в 2 этапа (через S (i)обозначим двоичный логарифм i-го сверху элемента стека):1. Посчитаем g (i, S (i)) = 1+min (g (i — 1; *)), i > 1. Этот случай соответствует тому, что из всего, что выше элемента i, мы получаем некоторое число, после чего удаляем его.
Также посчитаем g (i, S (i) + 1) = g (i − 1, S (i)). Этот случай соответствует тому, что мы из всех элементов, расположенных выше i, собираем число 2S (i), после чего объединяем его с текущим элементом, который также равен 2S (i). Для всех j, отличных от S (i) и S (i) + 1, положим g (i, j) = +inf.
2. На первом этапе мы «разобрались» с числом S (i). Прежде чем переходить к g (i + 1, *) и числу S (i + 1), мы можем произвести некоторые действия с i-м элементом стека, превратив его в любой другой элемент. Чтобы это учесть в динамике, пересчитаем g (i, *) следующим образом:
• g (i, 0) = min (g (i, 0), min (g (i, *)) + 1.0/p) — мы либо используем уже найденное значение g (i, 0), либо берем любое число, удаляем его и ставим туда 1 = 20.• g (i, j) = min (g (i, j), min (g (i,*)) + 1 + f (j), g (i, j − 1) + f (j − 1)), j > 0. Здесь мы либо удаляем стоявшее на месте i число и затем за f (j) монет ставим туда число 2j, либо ставим за g (i, j − 1) шагов число 2j−1, собираем за f (j − 1) шагов еще 2j−1 и объединяем их.
Ответом на задачу будет g (N,10). Следует обратить внимание, что в промежуточных вычислениях следует также считать g (*,11). Сложность решения O (NR), где R — максимальная степень двойки, которая присутствует во входных данные (в данном случае R ≤ 10).

Задача B. Строчная задача Имя входного файла: Standard inputИмя выходного файла: Standard outputОграничение по времени: 4 secondsОграничение по памяти: 512 mebibytesПоисковые запросы — что может быть лучше? Поле для ввода вопроса, кнопка «найти» — и весь интернет выстраивается в упорядоченный список ответов. Миллионы поисковых запросов сохраняются каждый день, чтобы в будущем отвечать на них быстрее и лучше, но этого мало!
Важно помочь пользователю быстрее вводить сам поисковый запрос. Например, можно подсказывать популярные или интересные пользователю варианты запросов, упорядочивая их в соответствии с предпочтениями. Но что делать, если мы ничего не знаем о том, кто задаёт вопрос? Вам поручено разработать алгоритм, который будет предлагать две подсказки в лексикографическом порядке. Ну, почти в лексикографическом.
Известно, что пользователи могут допустить опечатки при вводе запроса. Скажем, что строка A почти меньше строки B, если в строке A можно заменить не более одной буквы на произвольную маленькую букву латинского алфавита так, чтобы строка A стала лексикографически меньше строки B.
Вам даны N слов-подсказок. Посчитайте количество пар слов, первое из которых почти меньше второго. Количество пар нужно вычислять с учётом порядка: если два слова являются взаимно почти меньшими, то учитывайте обе пары.
Разбор задачи B
Рассмотрим пару строк s и w. Строка s почти меньше строки w тогда и только тогда, когда минимальная лексикографически строка smin, которую можно получить из s заменой одной буквы, строго меньше w.
Однако, как легко видеть, smin получается из строки s заменой первого символа не равного «a» на символ «a». Если строка s состоит только из символов «a», то s = smin. Рассмотрим строку si, и найдем Ci — количество строк sj (возможно i = j)таких, что smini < sj. Тогда к ответу нужно прибавить Ci — 1, если smini ≠ si, и Ci в противном случае.
Для нахождения величин Ci можно воспользоваться двумя способами:
отсортировать строки si и находить Ci двоичным поиском; добавить все строки в trie, и находить Ci спуском по нему. Задача C. Кубик Имя входного файла: Standard inputИмя выходного файла: Standard outputОграничение по времени: 2 secondsОграничение по памяти: 512 mebibytesДан куб, грани которого пронумерованы различными целыми числами от 1 до 6. Также дано гексамино, все клетки которого пронумерованы различными целыми числами от 1 до 6.
Определите, можно ли из заданного гексамино сделать куб, который можно повернуть так, чтобы нумерация граней совпала с нумерацией граней заданного куба, если разрешается только сгибать гексамино по границам клеток, но не разрезать его.
Разбор задачи C
Основное, что надо заметить в этой задаче — гексамино можно сгибать в разные стороны. При этом получаются два кубика, отличающихся друг от друга только взаимной перестановкой одной пары противоположных цифр (так как поворот на 180 градусов переставляет две пары противоположных цифр, то перестановка всех трёх пар эквивалентна перестановке одной пары).
Далее существует несколько методов решения. Один из них состоит из следующих шагов:
Устанавливаем кубик нижней стороной на соответствующую клетку гексамино.
Для каждого из четырёх поворотов кубика вокруг своей оси начинаем перекатывать его по гексамино до тех пор, пока возможно перекатить кубик так, чтобы нижняя грань попала на клетку с соответствующим номером.
Если для какого-то из поворотов все 6 клеток посещены, то ответ «Yes».
Если нет, то меняем местами цифры на правой и левой гранях и повторяем процедуру с шага 2.
Если и в этом случае ни при одном из поворотов не посещены все 6 клеток, то ответ — «No».
Также существует возможность предпросчитать все 11 развёрток и затем проверять совпадение гексамино (поворачивая его в стандартное положение), а в случае совпадения — соответствие пар чисел, использованных для нумерации противоположных сторон кубика, с теми же парами в развёртке.
Задача D. НЛО Имя входного файла: Standard inputИмя выходного файла: Standard outputОграничение по времени: 1 secondОграничение по памяти: 256 mebibytesНочью в озеро, расположенное неподалеку от Васиного дома, упал НЛО.НЛО представлял собой каркас N-мерного прямоугольного параллелепипеда, собранный из титановых рёбер, причём все рёбра имели целые длины. В момент крушения соединения между рёбрами разрушились, в отличие от самих рёбер, которые оказались на дне и на берегу озера.
С утра Вася пришёл на берег озера и нашёл K титановых стержней. Предполагая, что эти стержни являются рёбрами каркаса НЛО и что, возможно, часть рёбер ещё находится под водой, определите наименьшую возможную размерность пространства, из которого прибыл НЛО.
Решение задачи D
Это самая простая задача набора. Очевидно, что размерность параллелепипеда не меньше количества различных длин рёбер. Также заметим, что в K-мерном параллелепипеде 2K-1 рёбер одного типа, то есть в в случае наличия X одинаковых рёбер для них будет использовано [(X − 1)/2k−1] + 1 измерение.
Поэтому в порядке возрастания перебираем все размерности, пока вычисленное по указанной выше формуле суммарное количество использованных измерений не будет меньше или равно текущей размерности. Так как при K = 21 рёбер одного типа будет 220 > 106, то перебор будет небольшим.
Задача E. Недополняемое паросочетание Имя входного файла: Standard inputИмя выходного файла: Standard outputОграничение по времени: 1 secondОграничение по памяти: 512 mebibytesАртёмка очень любит паросочетания. Паросочетание в неориентрированном графе — это набор попарно несмежных ребер.Паросочетание называется недополняемым, если невозможно добавить в паросочетание ещё одно ребро, не удаляя при этом ни одно из уже включённых рёбер.
Неориентрированный граф называется двудольным, если его вершины можно разбить на два множества так, чтобы любое ребро графа соединяло вершины из разных множеств.
Артёмке дан двудольный граф. Его задача — найти количество недополняемых паросочетаний в нем по модулю 1 000 000 007 (109 + 7). Ваша задача — помочь ему.
Решение задачи E
Для решения задачи заметим, что число вершин в левой доле невелико.
Будем считать следующую динамику, добавляя по одной вершине из правой доли: f (i, j) — количество способов расставить рёбра в случае, когда мы рассмотрели первые i вершин правой доли, а вершины левой доли заданы троичной маской j следующим образом: 0 — вершина не могла быть соединена ребром ни с одной вершиной из правой доли, 1 — вершина могла быть соединена ребром ни с одной вершиной из правой доли, однако мы не поставили это ребро, 2 — вершина соединена ребром с одной из вершин правой доли.
Таким образом, рассматривая очередную вершину из правой доли, мы можем пересчитать маску для вершин левой доли. Очевидно, что при подсчете ответа нужно рассматривать маски без 1.
Таким образом, ответом будет сумма f (n2, ValidMask), для всех троичные масок ValidMask, не содержащих единиц в троичной записи.

Задача F. Музыкальный мир Имя входного файла: Standard inputИмя выходного файла: Standard outputОграничение по времени: 1 secondОграничение по памяти: 512 mebibytesВ обновленной Яндекс.Музыке музыкальные рекомендации стали ещё лучше, чем раньше! Они учитывают каждый прослушанный пользователем трек с самого начала использования сервиса, и в зависимости от уже прослушанных — увеличивают пул рекомендаций. Плеер включает пользователю случайный из рекомендованных треков, и так целый день.
Но сервера Яндекса такие быстрые, что могут строить рекомендации не только для того трека, которую сейчас слушает пользователь, но для всех вариантов случайно выбранных следующих треков.
Пользователь выбирает первый трек, а дальше алгоритм автоматически строит рекомендации на N песен вперёд. Из каждой песни i-го поколения может получиться не более Ki (1 ≤ Ki ≤ 5) новых песен в (i + 1)-м поколении, причём для i-го поколения известна вероятность pi, j того, что на основании песни i-го поколения будет предсказано j новых песен для каждого j от 0 до Ki.
Так как экспериментальное исследование производилось на жанре инди, все рекомендованные треки различны. Для того чтобы измерить разнообразие сбора статистики о похожести песен, похожесть измеряется для каждой пары треков. Чтобы помочь разработчикам Яндекса оценить затраты по памяти для этого измерения, вычислите математическое ожидание количества пар треков в пуле рекомендаций в (N + 1)-м поколении.
Решение задачи F
Обозначим за Yi случайную величину, равную количеству песен в i-ом поколении. Предлагаемое решение задачи основано на понятии производящей функции. Если вы не знакомы с ним, ознакомиться можно, к примеру, в статье Википедии ru.wikipedia.org/wiki/Производящая_функция_последовательности.
Рассмотрим производящие функции заданных во входе случайных величин 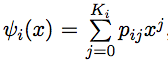 , атакже производящие функции случайных величин
, атакже производящие функции случайных величин 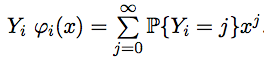 .
.
У нас есть явный вид всех ψi, а также явный вид φ1(x) = x. Научимся выражать φi+1 через ψi и φi.
В случае, если бы мы точно знали, что Yi = k, то можно было бы утверждать, что φi+1(x) = ψi (x)k. Но так как Yi — случайная величина, то искомая производящая функция есть сумма производящих функций, соответствующих разным значениям, с весами, равными вероятностям этих значений, то есть 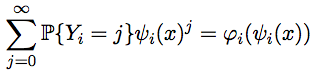 .
.
Так как максимальное значение искомой величины очень большое, вычислить явный вид производящей функции для Yn+1 не представляется возможным. Однако он нам и не нужен. Несложно заметить, что величина, которую необходимо посчитать
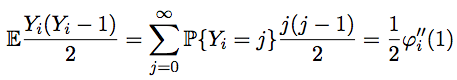 Научимся пересчитывать значение, первую и вторую производную функции φi+1(x) в (1) через предыдущие функции. Напомню, что φi (1) = ψi (1) = 1. Как мы знаем, φi+1(x) = φi (ψi (x)). Тогда
Научимся пересчитывать значение, первую и вторую производную функции φi+1(x) в (1) через предыдущие функции. Напомню, что φi (1) = ψi (1) = 1. Как мы знаем, φi+1(x) = φi (ψi (x)). Тогда
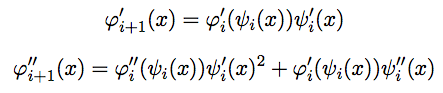 При подстановке x = 1 эти формулы упрощаются и принимают вид
При подстановке x = 1 эти формулы упрощаются и принимают вид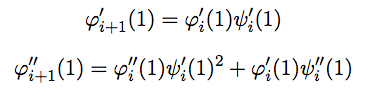 Также несложно понять, что вычисления можно проводить сразу по модулю 109 + 7, заменив исходные вероятности на соответствующие значения по модулю.
Также несложно понять, что вычисления можно проводить сразу по модулю 109 + 7, заменив исходные вероятности на соответствующие значения по модулю.
