Распределенные Workflow на PHP. Часть 1
Мы занимаемся разработкой огромного количества сложного ПО для автоматизации и энтерпрайза и Workflow для нас — это большая и больная проблема. Если для вас тоже — я расскажу, как писать и оркестрировать очень сложные процессы на масштабах, и как убедиться, что они не падают. А также как делать таймеры на 30 дней внутри процессов. И самое главное, как всё это пилить на PHP.
Меня зовут Антон Титов. Я более 17 лет занимаюсь коммерческой разработкой. Являюсь соавтором Spiral Framework, RoadRunner и Cycle ORM. Основной стек: PHP и Golang. Разговор пойдет про нашу разработку Temporal PHP SDK, которая и помогает решать все вышеперечисленные сложные задачи.

Статья получилась большая. Поэтому я разделил ее на теоретическую и практическую часть. Сначала, естественно, теория. И, чтобы ввести вас в курс дела — начну с истории.
Предположим, вас наняли в стартап и предложили сделать систему по доставке пиццы, которая должна масштабироваться на небольшой городок. Пиццу нужно приготовить, потом оформить заказ доставки и отправить его клиенту. И вы, как опытные разработчики, берёте для координации действий очередь, чтобы она красиво масштабировалась, БД, где будете хранить состояние, и начинаете писать.
Первая интеграция
Первую интеграцию вы делаете с сервисом Яндекс.Еда:

Получается, что заказчик приготовил пиццу, нажал кнопку, кто-то заказал ее в Яндекс.Еде и получил трек доставки, а пиццу отправили пользователю — все счастливы и довольны.
Чуть позже вам приходит требование —, а давайте делать не только доставку, а еще показывать пользователю состояние текущего процесса поэтапно: готовим пиццу, приготовили, передали в доставку или она уже едет:
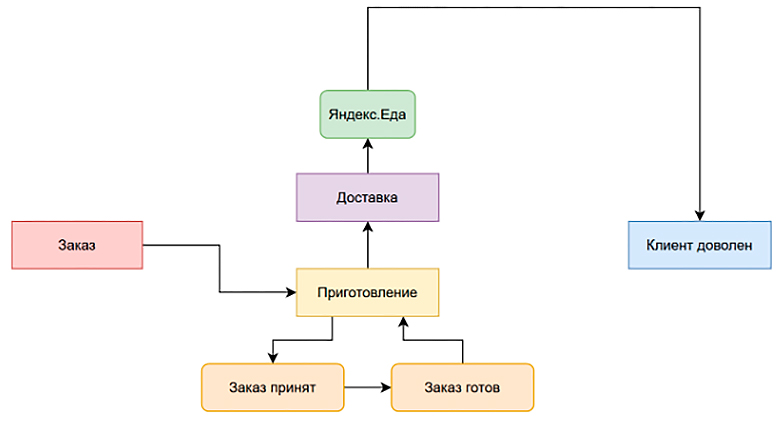
Вы делаете интеграцию с терминалом на их кухне и с менеджерами. Они тоже будут нажимать на кнопки и обновлять статусы. Это не очень сложная задача.
Вторая интеграция
Чуть позже к вам прибегает директор пиццерии и говорит, что Яндекс.Еда для них дорогая и выгоднее взять местный сервис, у которого тоже есть API. Правда, API не отдает трек-код, а пинает вас обратно по webhook и callback, но это тоже не беда. Вы просто добавляете пару if-чиков, делаете отдельную очередь и http-точку:

Третья интеграция
Местный сервис в итоге тоже оказывается недешевым, поэтому в соседнем отделе пиццерии два неизвестных программиста начинают разрабатывать свой собственный сервис, а вам его предлагают прикрутить. Впрочем, это тоже пара if-чиков и поначалу все работает.
Правда, потом оказывается, что сервис разработали на коленке на Perl, поэтому он любит падать и отваливаться. Но вы добавляете пару крон-табов, чтобы проверять таймауты, и retry — и вроде бы система продолжает работать:
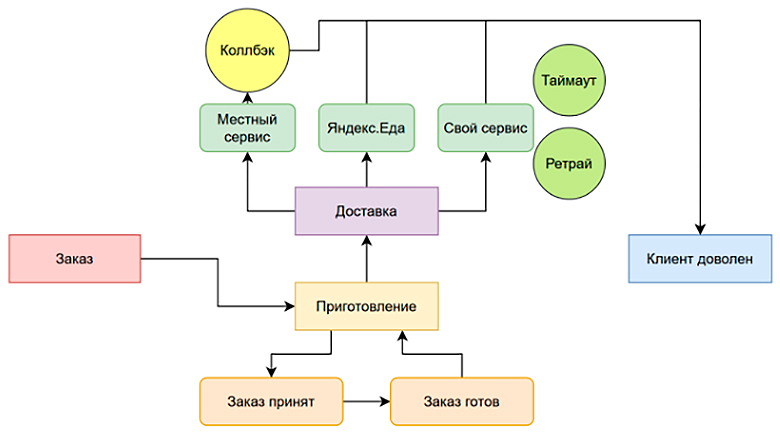
Правда, возникает новая проблема: повара забывают принимать заказы — в результате клиенты недовольны, а менеджеры ругаются. Что ж, вы добавляете еще одну CronJob, которая проверяет, что заказ висит и приготовление очень долгое — и уведомляет об этом поваров. Похожим образом решается ситуация, когда повар забыл достать пиццу из духовки.
В один момент к вам менеджер предлагает вам сделать еще и возможность отмены заказа. Однако заказ доставки отменить нельзя, но можно каким-то безопасным образом от trace-condition добавить возможность отмены еще до приготовления. Например, в момент принятия заказа:
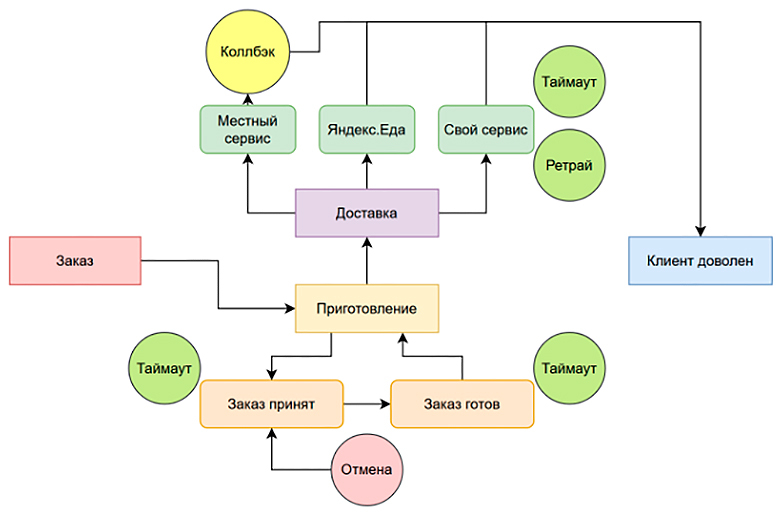
Кажется, закончили!
В результате получилась система, которая описывает бизнес-процесс или Workflow по приготовлению и доставке пиццы. На схеме видно, что она сильно смешана не только с бизнес-задачей, но также со структурной логикой — коллбеками, таймаутами, ретраями и прочим.
Такую систему можно написать в лоб — взять немного «редиски», немного RabbitMQ, добавить пару крон-задач и как-то склеить, но в итоге получится монстр с кучей проблем:
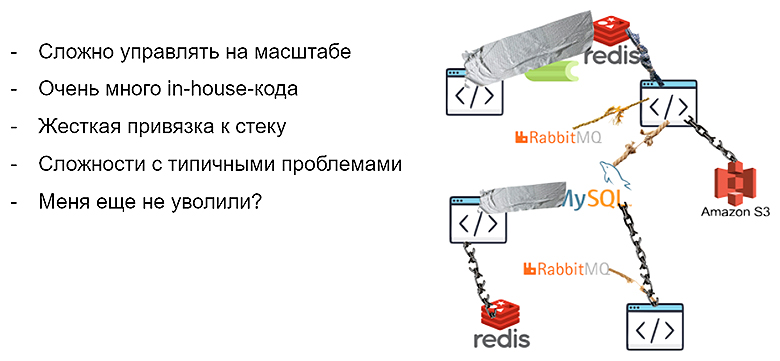
Масштабировать его будет очень непросто. Поэтому, если ту компанию купит большой холдинг и скажет: «Давайте вы будете доставлять не 100 пицц в день, а 10 тысяч в час», то вам все придется переписывать с нуля.
Всё это Workflow, а система, которая передает данные между шагами, называется оркестрацией.
Поговорим о Workflow и оркестрации
Чтобы пояснить, что здесь можно сделать, сначала чуть разберем, что же такое Workflow — более простым языком. Очень часто его представляют в виде схемы со стрелками и набором шагов. Тогда наглядно видно, как происходит координация действий между внешними и внутренними задачами. Они могут быть с API или ответами пользователей, но это в любом случае программа по координации данных шагов синхронно или асинхронно:
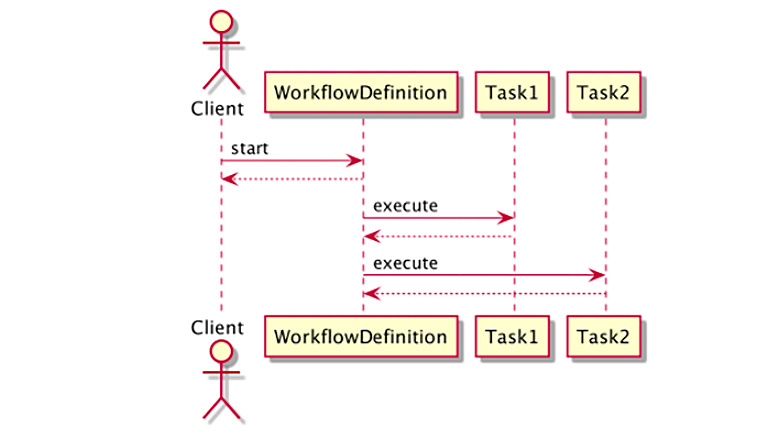
Будет неудобно, если мы напишем систему по доставке пиццы, а потом, чтобы добавить новый шаг, придется всю её переписывать. Поэтому очень хочется иметь инструмент, который позволит делать это легко и просто, не ломая при этом существующую бизнес-логику. Концептуально это и есть основная задача Workflow.
Очень важное свойство любого Workflow в реальном мире — это, во-первых, получать влияние от внешних событий, а во-вторых, быть растянутым во времени. В любой задаче, будь то логистика, система доставки пиццы или поднятие серверов, у вас не будет ситуации, когда все задачи выполняются мгновенно. Какие-то из них будут выполняться секунду, какие-то — минуту, другие — пару дней, а некоторые даже несколько месяцев. Поэтому ограничений тут быть не должно.
Также нужно учитывать, что бизнес-процессы не живут в вакууме. Как только мы что-то запустили — всегда найдется человек, который предложит что-то усовершенствовать. Например, возможность добавлять перчик в пиццу уже после того, как сделан заказ. Поэтому нужна система, которая позволит влиять на состояние бизнес-процесса.
Пожалуй, два самых важных пункта, которые нужно понимать именно на масштабах — это наблюдаемое состояние и устойчивое состояние.
Наблюдаемое состояние
Это возможность понимать, где мы сейчас находимся в нашем бизнес-процессе. Ведь не очень удобно, если при заказе пиццы нужно угадывать — приедет она к нам или нет, а если приедет, то когда. Поэтому хотелось бы иметь возможность поиска по Workflow: по состоянию, то есть этапу выполнения.
И наконец, если вы работали с большим энтерпрайзом, то знаете, что есть очень важное требование — это аудит-лог. Нам надо понимать, какой шаг занял какое время, как и когда он мог отвалиться и как его оптимизировать в будущем.
Устойчивое состояние
Даже если наш сервер сгорел, база легла, а сетевая карта отключилась, то мы все равно хотим быть уверены, что после перезапуска система продолжит работать с нужной точки. Иначе в Workflow нет никакого смысла.
Чтобы достигнуть устойчивого состояния или отказоустойчивости, нам нужно решить несколько проблем. И сначала — убедиться в том, что ошибки в коде и бизнес-процессе не теряются. Очень неприятно, когда что-то упало, а мы не знаем что именно. Логов нет, системы нет, а у нас отвалился сервис доставки или повар чудит? В идеале хочется понимать всю историю ошибки. Например, доставка не пришла потому, что пицца некорректная. А пицца некорректная потому, что отвалился сервис чек-аута, который добавил некорректный ингредиент, и повар не смог приготовить пиццу.
Если мы делаем большие, сложные — особенно если распределенные — системы с кучей микросервисов, то важно понимать, как они между собой связаны. Как происходит error propagation или распределенный стек-трейс ошибки.
Естественно, раз мы пишем процессы для реального мира, то все равно будут проблемы, когда отваливается внешний API, микросервис или просто что-то зависает. Поэтому важно иметь подсистему для таймаутов. Если мы отправили задачу на кухню, но за полчаса ничего не произошло — то давайте узнаем, что же там случилось.
Также обязательно иметь систему ретраев — в идеале с back off, чтобы если API отвалилось, можно было потихонечку пытаться до него достучаться.
Workflow — где применяется?
распределенные вычисления;
финансовые операции;
логистика, инвентаризация;
синхронизация внешних систем;
накопительная рассылка уведомлений;
чекауты и корзины пользователя;
документооборот;
управление инфраструктурой;
обработка файлов;
мониторинг, CI/CD;
просто чтобы не падало.
Все это управляется системами, подобными Workflow. Они немного разные, но имеют основное общее требование — мы хотим, чтобы наш процесс не падал. И если вы начнете видеть Workflow и понимать, что это паттерн, то потом убрать его у себя из головы будет очень сложно.
Варианты реализации
Мы рассмотрели пример, у нас есть даже какая-то теоретическая база. Давайте подумаем, как это можно реализовать.
Напишем на очередях и базах!
Первый вариант я уже рассказал — мы пишем в лоб, поднимая какую-то систему очередей для балансировки задач. Для масштабирования поднимаем базу данных, чтобы понимать, где мы сейчас находимся в процессе. Проблема в том, что для реализации отказоустойчивости данной системы нужно очень сильно постараться:
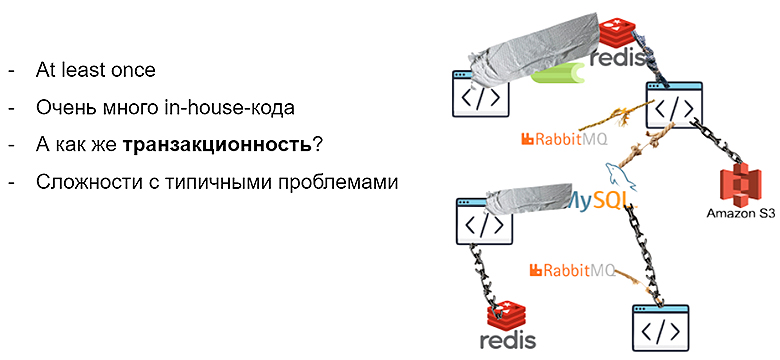
Транзакционность будет вашей самой большой проблемой на масштабе, потому что всегда наступит ситуация, когда добавили значение в БД, но очередь его не приняла, либо наоборот. У вас получается сломанный state, полностью зависающая система, и что с этим делать — непонятно.
Может, на Kafka?
Если вы более смелый, то можете попробовать на Kafka:
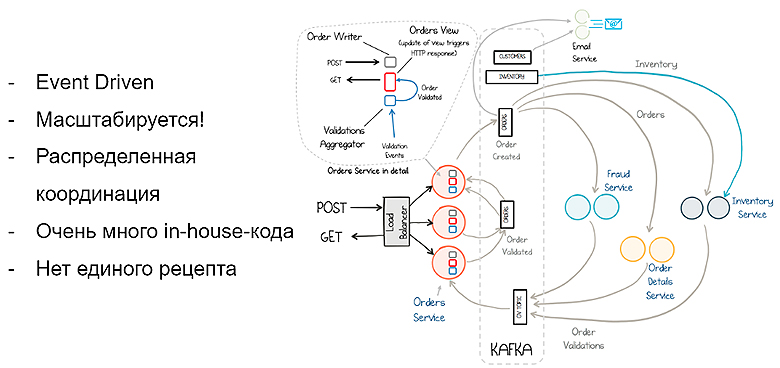
Kafka — Event Driven система, она гарантирует определенную транзакционность записи в лог и хорошо масштабируется. Но скорее всего, вам придется писать очень много кода, потому что координация различных partitions и пайплайнов — нетривиальное дело, которое занимает много времени. Тем не менее большое количество крупных стартапов используют Kafka для координации своих задач, и это тоже валидный вариант.
Workflow — ну тогда декларативно!
Наверное, мы все ленивые разработчики, поэтому давайте просто найдем готовый инструмент. Скорее всего, это будет реализация Workflow декларативно:

Это будет какой-то JSON, описывающий набор шагов и transition между ними. В лучшем случае BPMN. Например, Apache Airflow или Camunda, где мы сможем рисовать диаграммы, перекидывать данные между ними и таким образом координировать нашу систему.
Вариаций декларативных Workflow очень много, есть даже отдельный репозиторий assem_workflow. Но у всех них есть много ограничений.
Workflow — ограничения DAG
Ограничения в основном связаны с тем, что это декларативная система:
запеченный граф (сложно делать динамичные ветки);
конечный автомат, полно ограничений;
каждый тянет в свою сторону;
накладно применять для чего-то мелкого;
трудно встраивать в существующий код;
максимальный размер графа ограничен;
возможности маппинга ограничены;
сложно управлять глобальными данными процесса.
То есть желаемое поведение Workflow вы описываете в виде графа. Соответственно, нет динамики. Добиться её для мелких задач очень тяжело. Ну зачем затягивать визуально BPMN для того, чтобы заказать пиццу? Это проще на коленке написать.
Из-за того, что всё декларативно, передача данных между шагами будет делаться только по тем примитивам маппинга и вариациям, которые доступны в этом движке. Если нужен более кастомный маппинг, то пишите авторам и надейтесь, что они это добавят.
Есть еще много проблем. Например, нет общего стандарта, поэтому если вы выучили Netflix Conductor, а потом перешли на Apache Airflow — то будьте добры, изучайте заново. У вас будут новые примитивы, новые маппинги, и переехать будет очень тяжело. И всё очень грустно: нужно самому писать, — очень долго, дорого, сложно — и это миллион эдж-кейсов. У готовых движков много ограничений, а половина из них вообще платная. И почти везде требуется DSL.
У нас много энтерпрайз-софта, и Workflow для нас — старая боль. Поэтому мы подошли к проблеме серьезно, долго искали и все-таки нашли интересный продукт. Uber Cadence — это Workflow-движок, причем очень интересный:
описание Workflow кодом;
можно делать свои DSL;
изоляция данных;
бесконечный скейл;
Golang-ядро.
В первую очередь, он интересен тем, что не имеет DSL. Оркестрация или поведение Workflow описывается прямо внутри вашего кода, то есть движок вообще ничего не знает про ваш бизнес-процесс и позволяет вам самостоятельно координировать дальнейшие шаги. Но, кроме этого, он также гарантирует, что система не будет падать.
Поскольку движок императивный, то есть написан вашим кодом, то можно взять свой готовый DSL, переписать на Temporal и положить его прямо сверху. Так делают многие пользователи этого движка, это реальный use case.
Uber Cadence очень хорошо масштабируется линейно, потому что Uber — это очень большая система, которая обслуживает много городов в различных странах. Он используется у них под капотом, как основной движок для координации всех финансовых операций.
Для нас большим бонусом стала возможность использования Golang-ядра и Golang-SDK. Так как у нас много продуктов написан на Golang, в частности, RoadRunner.
Но всё оказалось еще интереснее. Авторы Uber Cadence открыли отдельный стартап, получили инвестиции, назвали его Temporal, и все это залицензировали под MIT лицензией. Кроме того, это были бывшие русские, поэтому нам с ними было легче общаться по интеграции и разработке API. Для нас это был полный win-win — MIT-система, которая скейлится, которую можно поднимать у себя, описывает Workflow кодом без каких-то DSL, и еще можно общаться на русском языке.
И на что способен Temporal PHP SDK, мы разберем в следующей, более практической, части.
Конференция PHP Russia 2022 — отличное место, где можно рассказать о своём опыте сообществу. Она пройдет 12 и 13 сентября в Москве, в Radisson SAS Славянская. В центре внимания: развитие экосистемы (сам PHP, стандарты, фреймворки, библиотеки, OpenSource); опыт крупных компаний для построения на PHP сложных проектов и лучшие практики. И, конечно, темы повседневной разработки.
До 25 мая идет прием заявок на выступления. Оплачиваются расходы на дорогу и проживание спикеров. Все подробности на сайте.
