Распределенные транзакции между RabbitMQ и MS SQL
Для реализации асинхронного общения между двумя системами очень выгодно использовать очереди сообщений. Даже если одна из систем лежит, другая этого не замечает и спокойно продолжает слать ей сообщения, которые будут обработаны, когда вторую систему поднимут. В качестве очереди сообщений можно использовать таблицу MS SQL, но это не особо масштабируемое решение.Однако, как только у нас появляется отдельная система для хранения очереди сообщений (мы используем RabbitMQ), сразу возникают проблемы с транзакционностью. Например, если мы хотим сохранить в БД отметку о том, что мы отправили сообщение в Rabbit, не так уж и просто гарантировать, чтобы отметка была сохранена только в случае успешной отправки сообщения. О том, как мы справлялись с этой проблемой читайте под катом.В некоторых сценариях можно просто отправлять сообщения в RabbitMQ после завершения SQL транзакции. Например, если нам надо при регистрации отправить email с паролем и на странице, которая отображается после регистрации, есть кнопка «переотправить письмо», то мы вполне можем позволить себе обойтись без какой-либо транзакционности и в случае ошибки отправки сообщения, просто выводить уведомление пользователю.
Можно отправлять сообщение прямо перед коммитом SQL транзакции. В этом случае мы можем откатить SQL транзакцию, если упадет отправка сообщения, но есть вероятность того, что после успешной отправки сообщения упадет коммит SQL транзакции. Но если для вас приемлема ситуация, когда редкие сообщения будут доставлены системе-получателю, но система-отправитель об этом забудет, я бы рекомендовал использовать этот способ, так как он очень прост в реализации.
В сценариях, когда упавшая транзакция будет обязательно повторена, можно не бояться того, что в системе отправителе не останется записи об отправке (и более того, отправку сообщения можно выполнять в любой момент транзакции, а не только перед коммитом). Однако, при этом необходимо операцию обработки сообщения сделать идемпотентной, чтобы одно и то же с точки зрения системы-отправителя сообщение не было обработано два раза в системе-получателе.
Например, нам надо отправить потребителю email и проставить отметку об этом в БД. Данные потребителя хранятся в CRM системе. CRM система общается с email-шлюзом через очередь в RabbitMQ. Отправка сообщения выполняется задачей, у которой есть уникальный идентификатор и список потребителей, которым нужно отправить сообщение. Если обработка отправки письма потребителю падает (например по SQL таймауту), то через некоторое время задача снова попытается отправить сообщение. При таком сценарии мы можем отправлять сообщение в RabbitMQ до завершения транзакции, но при обработке сообщения в email-шлюзе мы должны сохранять уникальный идентификатор задачи и номер потребителя в списке. Если в БД email-шлюза уже есть сообщение с таким идентификатором задачи и номером потребителя, то повторно мы его не отправляем. Для того, чтобы email-шлюз абстрагировался от того, как именно CRM отправляет сообщения, CRM должен передавать не идентификатора задачи и номера потребителя в списке, а ключ идемпотентности — уникальное значение, сформированную на основании этих данных. При других способах отправки email ключ идемпотентности будет формироваться по другому. При таком подходе email-шлюз не должен ничего знать о том, как ему могут отправляться сообщения — главное, чтобы отправитель передавал ключ, уникально определяющий сообщение.
Далеко не во всех случаях можно гарантировать, что в случае падения SQL транзакции, она будет повторена через некоторое время. Также не всегда есть данные, на основании которых можно сформировать уникальный ключ идемпотентности. А операцию обработки сообщения из очереди желательно всегда делать идемпотентной, так как даже при отсутствии дублирующихся сообщений одно сообщение может быть обработано несколько раз, если упадет вызов метода Ack RabbitMQ. Для решения проблемы в общем случае, нам нужно что-то вроде распределенной транзакции между RabbitMQ и MS SQL и автоматически формируемый ключ идемпотентности. Обе эти задачи можно решить следующим образом:
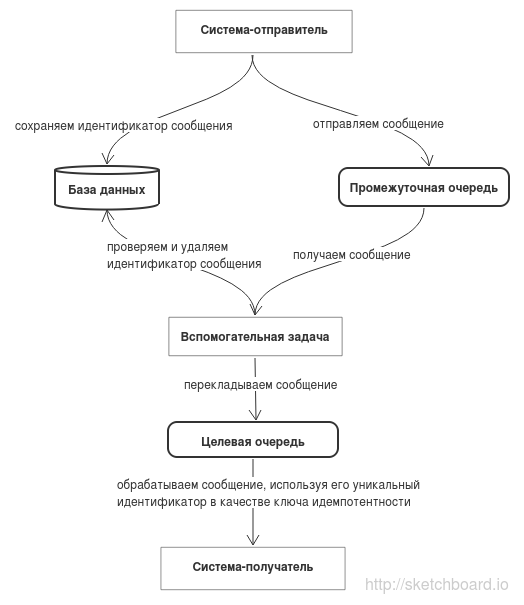
В рамках SQL транзакции в специальную таблицу в БД сохраняется уникальный идентификатор сообщения.
После выполнения INSERT запроса, но до завершения SQL транзакции, сообщение сохраняется в промежуточную очередь. В этом сообщении кроме прочего передается уникальный идентификатор, который был сохранен в БД.
Отдельная задача обрабатывает промежуточную очередь и проверяет, что уникальный идентификатор сообщения есть в БД.
Если есть, сообщение перекладывается в очередь, которую обрабатывает уже система-получатель. Для того, чтобы не хранить во вспомогательной таблице старые идентификаторы, после того как сообщение перемещено его идентификатор удаляется из БД (даже если удаление идентификатора упадет, это не повлияет на работоспособность системы — просто останется лишняя запись в БД).
Если в момент запроса записи в БД по уникальному идентификатору транзакция еще не была завершена, то запрос будет ждать завершения этой транзакции, и только после этого вернет запись. То есть никакой дополнительной логики для ожидания завершения транзакции писать не надо.
Если уникальный идентификатор отсутствует в БД, это точно значит, что транзакция была откачена и сообщение выбрасывается.
Уникальный идентификатор сообщения используется в системе-получателе в качестве ключа идемпотентности.
 При таком подходе гарантируется, что в системе-отправителе сохранится информация об отправленном сообщении. Если в транзакции отправки сообщения и так создается запись с уникальным идентификатором, то можно использовать его и обойтись без вспомогательной таблицы.Здесь может возникнуть вопрос: «А чем это лучше использования таблички в БД в качестве очереди? Все равно ведь приходится вспомогательные запросы к БД делать.» Дело в том, что если использовать таблицу в БД в качестве очереди, то для получения последнего необработанного сообщения будут выполнятся запросы вроде «SELECT TOP 1 * FROM Messages WHERE Status = 'New'». Если мы хотим обрабатывать сообщения в несколько потоков, то для того, чтобы гарантировать, что одно сообщение не будет обработано двумя разными потоками, придется использовать Serializable транзакцию для получения последнего сообщения и изменения его статуса. При использовании Serializable транзакции запрос на получение последнего необработанного сообщения будет блокировать все записи со статусом 'New' и никто не сможет добавлять новые сообщения, пока не закончится транзакция получения сообщения. Но в такой транзакции постоянно будет возникать deadlock, так как два потока смогут одновременно прочитать последнее необработанное сообщение, наложив при этом shared блокировку, а потом при попытке обновлении статуса сообщения не смогут повысить уровень этой блокировки до эксклюзивного, и одна из транзакций будет откачена. Поэтому уже при чтении сообщения надо накладывать update блокировку. В итоге очередь станет узким местом, так как доступ к ней (и на запись, и на чтение) в один момент сможет получить только один поток.
При таком подходе гарантируется, что в системе-отправителе сохранится информация об отправленном сообщении. Если в транзакции отправки сообщения и так создается запись с уникальным идентификатором, то можно использовать его и обойтись без вспомогательной таблицы.Здесь может возникнуть вопрос: «А чем это лучше использования таблички в БД в качестве очереди? Все равно ведь приходится вспомогательные запросы к БД делать.» Дело в том, что если использовать таблицу в БД в качестве очереди, то для получения последнего необработанного сообщения будут выполнятся запросы вроде «SELECT TOP 1 * FROM Messages WHERE Status = 'New'». Если мы хотим обрабатывать сообщения в несколько потоков, то для того, чтобы гарантировать, что одно сообщение не будет обработано двумя разными потоками, придется использовать Serializable транзакцию для получения последнего сообщения и изменения его статуса. При использовании Serializable транзакции запрос на получение последнего необработанного сообщения будет блокировать все записи со статусом 'New' и никто не сможет добавлять новые сообщения, пока не закончится транзакция получения сообщения. Но в такой транзакции постоянно будет возникать deadlock, так как два потока смогут одновременно прочитать последнее необработанное сообщение, наложив при этом shared блокировку, а потом при попытке обновлении статуса сообщения не смогут повысить уровень этой блокировки до эксклюзивного, и одна из транзакций будет откачена. Поэтому уже при чтении сообщения надо накладывать update блокировку. В итоге очередь станет узким местом, так как доступ к ней (и на запись, и на чтение) в один момент сможет получить только один поток.
Если же использовать описанный выше подход, то все запросы к вспомогательной таблице (вставка, поиск и удаление) выполняются по известному уникальному ключу и блокируют только одну запись в БД. Поэтому при многопоточной обработке сообщений не возникает узкого места, в котором несколько потоков будут ждать, когда освободится блокировка, чтобы добавить или получить сообщение.
