Распределенное логирование и трассировка для микросервисов
Логирование — важная часть любого приложения. Любая система логирования проходит три основных шага эволюции. Первый — вывод на консоль, второй — запись логов в файл и появление фреймворка для структурированного логирования, и третий — распределенное логирование или сбор логов различных сервисов в единый центр.
Если логирование хорошо организовано, то позволяет понимать, что, когда и как идет не так, как задумано, и передавать нужную информацию людям, которым предстоит эти ошибки исправлять. Для системы, в которой каждую секунду отправляется 100 тысяч сообщений в 10 дата-центрах на 190 стран, а 350 инженеров каждый день что-то деплоят, система логирования особенно важна.

Иван Летенко — тимлид и разработчик в Infobip. Чтобы решить проблему централизованной обработки и трассировки логов в микросервисной архитектуре при таких огромных нагрузках, в компании пробовали различные комбинации стека ELK, Graylog, Neo4j и MongoDB. В итоге, спустя много грабель, написали свой лог-сервис на Elasticsearch, а как БД для дополнительной информации взяли PostgreSQL.
Под катом подробно, с примерами и графиками: архитектура и эволюция системы, грабли, логирование и трассировка, метрики и мониторинг, практика работы с кластерами Elasticsearch и их администрирования в условиях ограниченных ресурсов.
Чтобы ввести вас в контекст, расскажу немного о компании. Мы помогаем клиентам-организациям доставлять сообщения их клиентам: сообщения от службы такси, СМС от банка о списании или одноразовый пароль при входе в ВК. В день через нас проходит 350 млн сообщений для клиентов в 190 странах. Каждое из них мы принимаем, обрабатываем, биллим, роутим, адаптируем, отсылаем операторам, а в обратном направлении обрабатываем отчеты о доставке и формируем аналитику.
Чтобы всё это работало в таких объемах, у нас есть:
- 36 дата-центров по всему миру;
- 5000+ виртуальных машин;
- 350+ инженеров;
- 730+ различных микросервисов.
Это сложнейшая система, и ни один гуру не сможет в одиночку понять весь масштаб. Одна из основных целей нашей компании — это высокая скорость доставки новых фич и релизов для бизнеса. При этом всё должно работать и не падать. Мы над этим работаем: 40 000 деплоев в 2017 году, 80 000 в 2018, 300 деплоев в день.
У нас 350 инженеров — получается, что каждый инженер ежедневно что-то деплоит. Еще несколько лет назад такая производительность была только у одного человека в компании — у Крешимира, нашего principal-инженера. Но мы добились того, что каждый инженер чувствует себя так же уверенно, как Крешимир, когда нажимает кнопку «Deploy» или запускает скрипт.
Что для этого нужно? Прежде всего уверенность в том, что мы понимаем, что происходит в системе и в каком состоянии она находится. Уверенности придает возможность задать системе вопрос и выяснить причину проблемы во время инцидента и при разработке кода.
Чтобы добиться этой уверенности, мы инвестируем в наблюдаемость (observability). Традиционно этот термин объединяет три компоненты:
- логирование;
- метрики;
- трассировка.
Об этом и поговорим. Прежде всего, посмотрим на наше решение для логирования, но метрик и трассировки также обязательно коснемся.
Эволюция
Практически любое приложение или система логирования, в том числе и у нас, проходит несколько этапов эволюции.
Первый шаг — это вывод на консоль.
Второй — мы начинаем писать логи в файл, появляется фреймворк для структурированного вывода в файл. Обычно мы используем Logback, потому что живем в JVM. На этом этапе появляется структурированное логирование в файл, понимание, что разные логи должны иметь разный уровень, warnings, errors.
Как только экземпляров нашего сервиса или разных сервисов становится уже несколько, появляется задача централизованного доступа к логам для разработчиков и поддержки. Мы переходим к распределенному логированию — объединяем различные сервисы в единый сервис логирования.
Распределенное логирование
Самый известный вариант — стек ELK: Elasticsearch, Logstash и Kibana, но мы выбрали Graylog. У него классный интерфейс, который заточен на логирование. Из коробки идут алерты уже в бесплатной версии, чего нет в Kibana, например. Для нас это отличный выбор с точки зрения логов, а под капотом тот же Elasticsearch.

В Graylog можно строить алерты, графики аналогично Kibana и даже метрики по логам.
Проблемы
Наша компания росла, и в определенный момент стало понятно, что с Graylog что-то не так.
Чрезмерная нагрузка. Появились проблемы с производительностью. Многие разработчики стали использовать классные возможности Graylog: строили метрики и дашборды, которые выполняют агрегацию по данным. Не лучший выбор строить сложную аналитику на кластере Elasticsearch, на который идет мощная нагрузка на запись.
Коллизии. Команд много, единой схемы нет. Традиционно, когда один ID первый раз попал в Graylog в качестве long, автоматически произошел маппинг. Если другая команда решит, что туда надо записать UUID в виде строки — это сломает систему.
Первое решение
Разделили логи приложений и коммуникационные логи. У разных логов разные сценарии и способы применения. Есть, например, логи приложений, к которым у разных команд разные требования по разным параметрам: по времени хранения в системе, по скорости поиска.
Поэтому первое, что мы сделали, — разделили логи приложений и коммуникационные логи. Второй тип — важные логи, которые хранят информацию о взаимодействии нашей платформы с внешним миром и о взаимодействии внутри платформы. Мы еще поговорим об этом.
Заменили существенную часть логов на метрики. В нашей компании стандартный выбор — это Prometheus и Grafana. Какие-то команды используют и другие решения. Но важно, что мы избавились от большого количества дашбордов с агрегациями внутри Graylog, перевели все на Prometheus и Grafana. Это значительно облегчило нагрузку на серверы.
Посмотрим на сценарии применения логов, метрик и трейсов.
Логи
Высокая размерность, отладка и исследование. Чем хороши логи?
Логи — это события, которые мы логируем.
У них может быть большая размерность: можно логировать Request ID, User ID, атрибуты запроса и другие данные, размерность которых не ограничена. Они также хороши для отладки и исследования, чтобы задавать вопросы системе о том, что происходило, и искать причины и следствия.
Метрики
Низкая размерность, агрегация, мониторинг и алерты. Под капотом всех систем сбора метрик находятся time series базы данных. Эти БД отлично справляются с агрегацией, поэтому метрики подходят для агрегации, мониторинга и построения алертов.
Метрики очень чувствительны к размерности данных.
Для метрик размерность данных не должна превышать тысячи. Если мы будем добавлять какие-то Request ID, у которых размер значений не ограничен, то быстро столкнемся с серьезными проблемами. Мы уже наступали на эти грабли.
Корреляция и трассировка
Логи должны быть коррелированы.
Структурированных логов недостаточно, чтобы мы могли удобно искать по данным. Должны быть поля с определенными значениями: Request ID, User ID, другие данные с сервисов, с которых логи пришли.
Традиционное решение — присваивать транзакции (логу) на входе в систему уникальный ID. Затем этот ID (контекст) пробрасывается через всю систему по цепочке вызовов внутри сервиса или между сервисами.

Корреляция и трассировка.
Есть устоявшиеся термины. Трассировка разбивается на spans и демонстрирует стек вызовов одного сервиса относительно другого, одного метода относительно другого относительно временной шкалы. Наглядно прослеживается путь сообщения, все тайминги.
Сначала мы использовали Zipkin. Уже в 2015 году у нас был Proof of Concept (пилотный проект) этих решений.
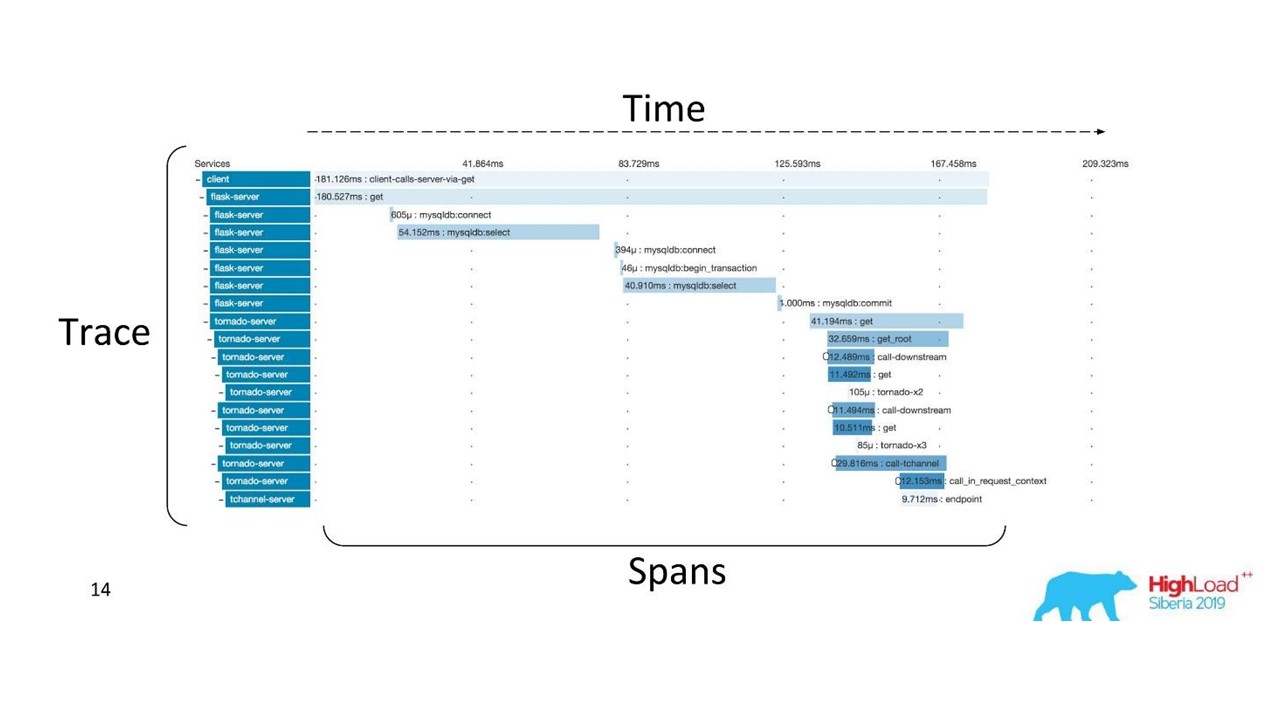
Распределенная трассировка.
Чтобы получить такую картину, код нужно инструментировать. Если вы уже работаете с кодовой базой, которая существует, нужно по ней пройтись — она требует изменений.
Для полной картины и чтобы получать выгоду от трейсов, необходимо инструментировать все сервисы в цепочке, а не один сервис, на котором вы сейчас работаете.
Это мощный инструмент, но он требует значительных затрат на администрирование и железо, поэтому мы перешли от Zipkin на другое решение, которое предоставляется «as a service».
Отчеты о доставке
Логи должны быть коррелированы. Трейсы тоже должны быть коррелированы. Нам нужен единый ID — общий контекст, который можно пробрасывать по всей цепочке вызовов. Но зачастую это невозможно — корреляция происходит внутри системы в результате ее работы. Когда мы начинаем одну или несколько транзакций, мы еще не знаем, что они часть единого большого целого.
Рассмотрим первый пример.
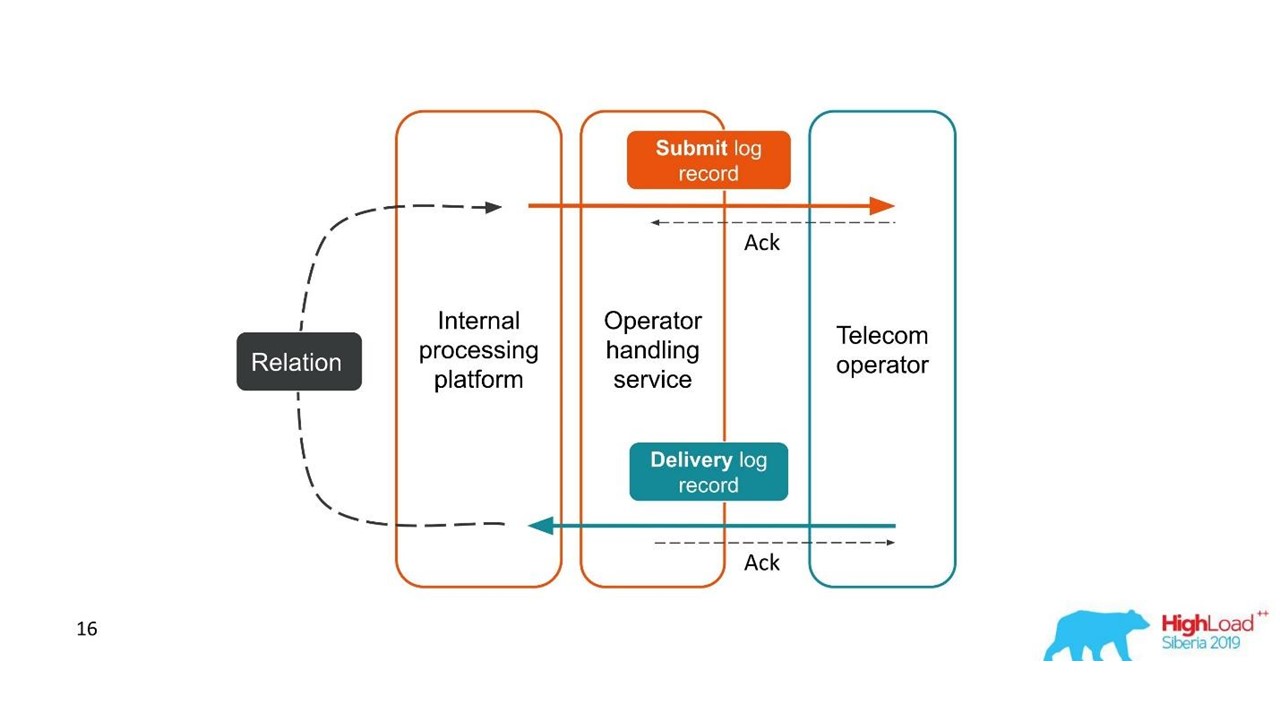
Отчеты о доставке.
- Клиент отправил запрос на сообщение, и наша внутренняя платформа его обработала.
- Сервис, который занимается взаимодействием с оператором, отправил это сообщение оператору — появилась запись в системе логов.
- Позже оператор присылает нам отчет о доставке.
- Сервис, который занимается процессингом, не знает, к какому конкретно сообщению относится этот отчет о доставке. Эта взаимосвязь создается внутри нашей платформы позже.
Две связанные транзакции — части единой целой транзакции. Эта информация очень важна для инженеров поддержки и разработчиков интеграций. Но это совершенно невозможно видеть, исходя из единой трассировки или единого ID.
Второй случай похож — клиент присылает нам сообщение в большой пачке, потом мы их разбираем, они возвращаются тоже пачками. Количество пачек даже может меняться, но все они потом объединяются.
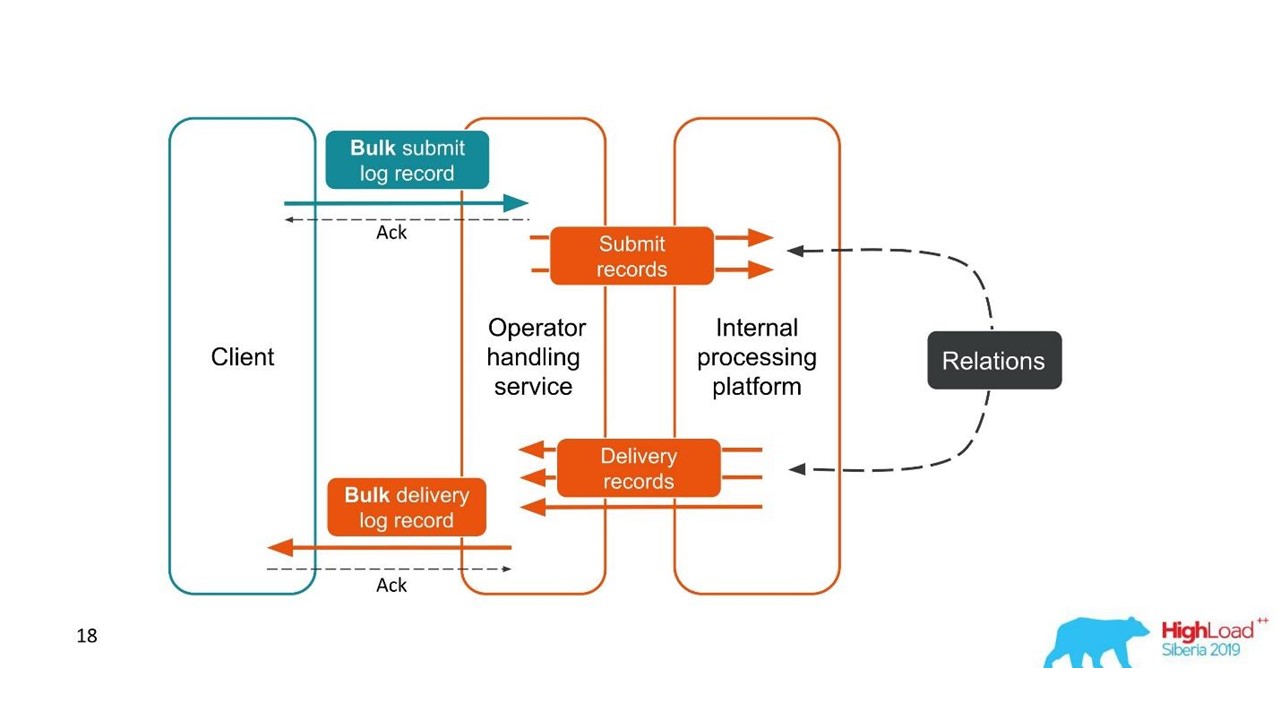
С точки зрения клиента, он отправил сообщение и получил ответ. Но мы получили несколько независимых транзакций, которые необходимо объединять. Получается связь один ко многим, а с отчетом о доставке — один к одному. По сути, это граф.
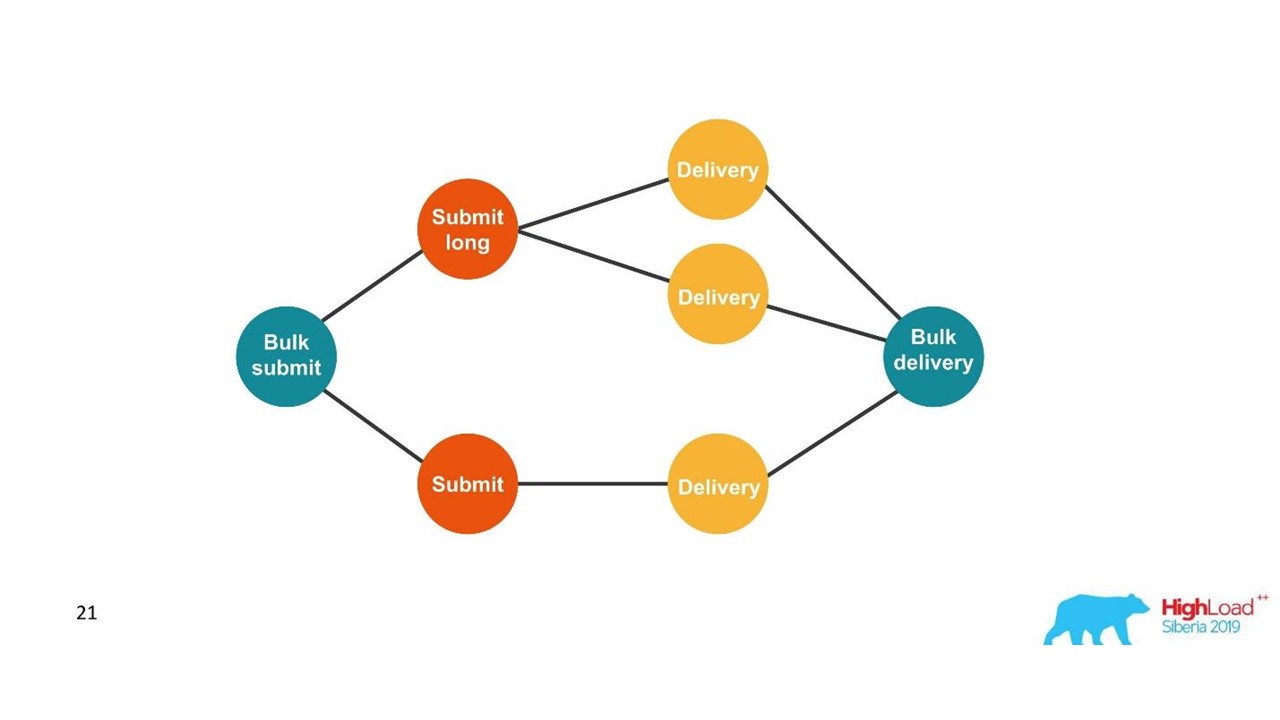
Строим граф.
Раз мы видим граф, то адекватный выбор — графовые БД, например, Neo4j. Выбор был очевиден, потому что Neo4j дарит на конференциях классные футболки и бесплатные книжки.
Neo4j
Мы реализовали Proof of Concept: хост на 16 ядер, который мог обрабатывать граф 100 млн нод и 150 млн связей. Граф занимал всего 15 ГБ диска — тогда нам это подходило.
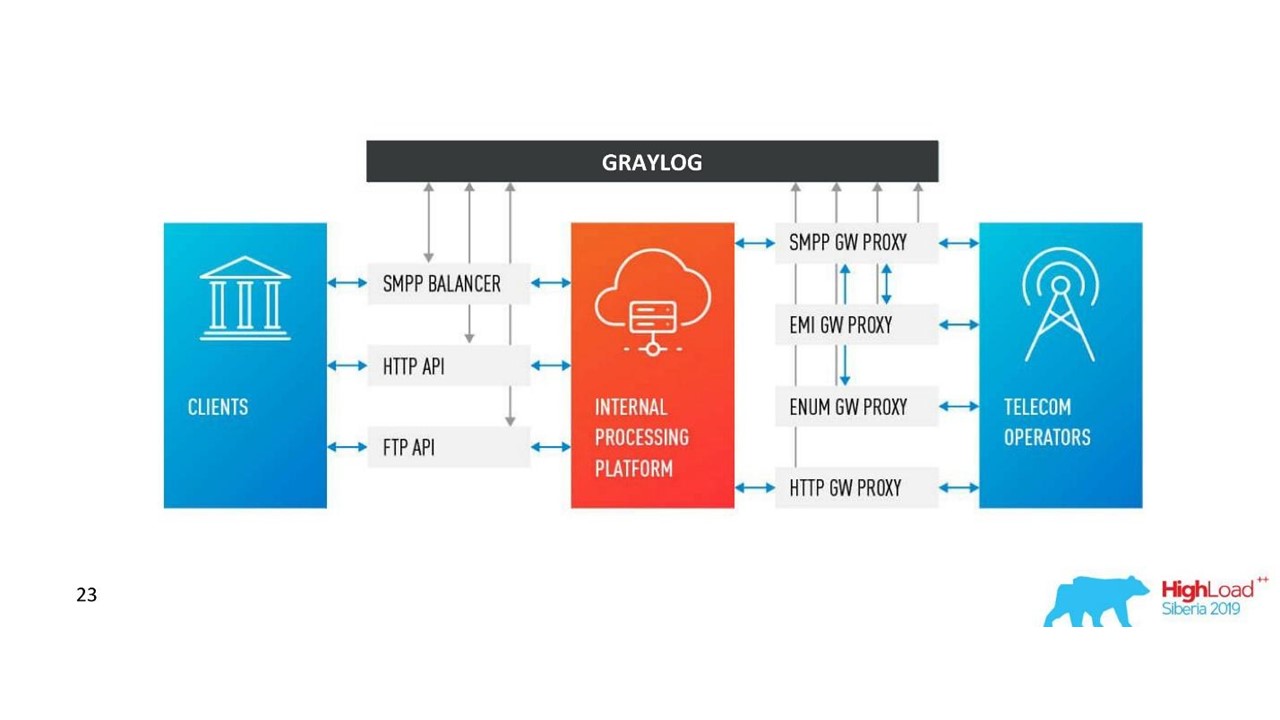
Наше решение. Архитектура логов.
Кроме Neo4j у нас появился несложный интерфейс для просмотра связанных логов. С ним инженеры видят картину целиком.
Но довольно быстро мы разочаровались в этой БД.
Проблемы с Neo4j
Ротация данных. У нас мощные объемы и данные необходимо ротировать. Но при удалении ноды из Neo4j данные на диске не очищаются. Пришлось строить сложное решение и полностью перестраивать графы.
Производительность. Все графовые БД заточены на чтение. На запись производительность заметно меньше. Наш случай абсолютно противоположный: мы много пишем и относительно редко читаем — это единицы запросов в секунду или даже в минуту.
High availability и кластерный анализ платно. В наших масштабах это выливается в приличные затраты.
Поэтому мы пошли другим путем.
Решение с PostgreSQL
Мы решили, что раз читаем редко, то граф можно строить на лету при чтении. Так мы в реляционной базе PostgreSQL храним список смежности наших ID в виде простой таблички с двумя столбцами и индекс по обоим. Когда приходит запрос, мы обходим граф связанности по знакомому алгоритму DFS (обход в глубину), и получаем все связанные ID. Но это по необходимости.
Ротация данных тоже решается легко. На каждый день заводим новую табличку и через несколько дней, когда приходит время — удаляем её и освобождаем данные. Простое решение.
Сейчас в PostgreSQL у нас 850 млн связей, они занимают 100 ГБ диска. Мы пишем туда со скоростью 30 тыс в секунду, и для этого в БД всего две VM по 2 CPU и 6 GB RAM. Что и требовалось доказать — PostgreSQL умеет быстро писать longs.
Еще есть небольшие машины для самого сервиса, которые ротируют и управляют.
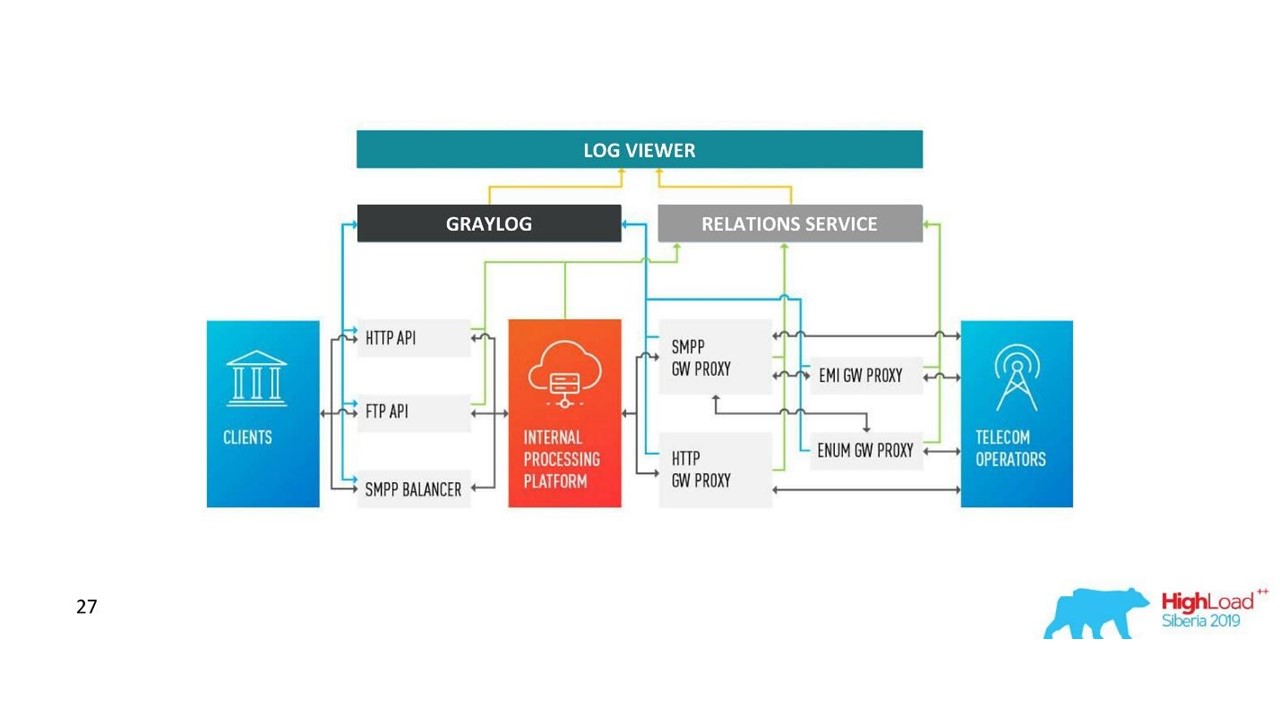
Как изменилась наша архитектура.
Сложности с Graylog
Компания росла, появлялись новые дата-центры, нагрузка заметно увеличивалась, даже с решением с коммуникационными логами. Мы задумались о том, что Graylog подходит уже не идеально.
Единая схема и централизация. Хочется иметь единый инструмент управления кластерами в 10 дата-центрах. Также встал вопрос единой схемы маппинга данных, чтобы не было коллизий.
API. Мы используем собственный интерфейс для отображения связей между логами и стандартное API Graylog не всегда было удобно использовать, например когда нужно отобразить данные с разных дата-центров, правильно их рассортировать и пометить. Поэтому нам хотелось иметь возможность менять API как нам нравится.
Производительность, трудно оценить потери. Наш трафик — 3 ТБ логов в день, что прилично. Поэтому Graylog не всегда стабильно работал, нужно было залезать в его внутренности, чтобы понять причины сбоев. Получалось, что мы используем его уже не как инструмент — с этим надо было что-то делать.
Задержки обработки (очереди). Нам не нравилась стандартная реализация очереди в Graylog.
Необходимость поддерживать MongoDB. Graylog тащит за собой MongoDB, приходилось администрировать еще и эту систему.
Мы поняли, что на данном этапе хотим собственное решение. Возможно, там меньше классных функций по алертингу, которые уже не использовались, по дашбордам, но свое лучше.
Наше решение
Мы разработали собственный Logs service.
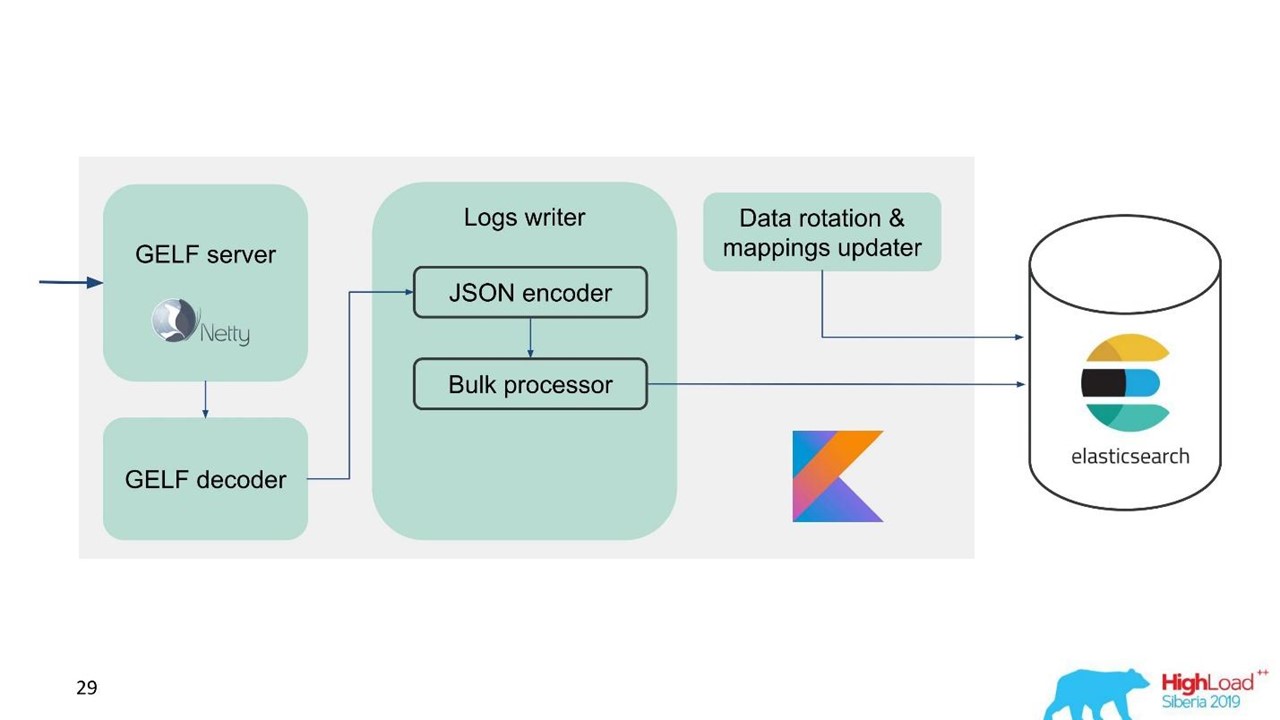
Сервис логов.
В тот момент у нас уже была экспертиза по обслуживанию и поддержанию крупных кластеров Elasticsearch, поэтому за основу взяли Elasticsearch. Стандартный стек в компании — это JVM, но для бэкенда мы классно используем и Kotlin, поэтому для сервиса взяли этот язык.
Первый вопрос — как ротировать данные и что делать с маппингом. Мы используем фиксированный маппинг. В Elasticsearch лучше иметь индексы одинакового размера. Но с такими индексами нам нужно как-то маппить данные, особенно для нескольких дата-центров, распределенной системы и распределенного состояния. Были идеи прикрутить ZooKeeper, но это опять усложнение обслуживания и кода.
Поэтому мы решили просто — пишем по времени.
Один индекс на один час, в других дата-центрах 2 индекса на час, в третьих один индекс на 3 часа, но все по времени. Индексы получаются разного размера, поскольку ночью трафик меньше, чем днем, но в целом работает. Опыт показал, что усложнения не нужны.
Для простоты миграции и учитывая большой объем данных мы выбрали протокол GELF — простой протокол Graylog на основе TCP. Так у нас появился GELF-сервер на Netty и GELF-декодер.
Потом JSON кодируется для записи в Elasticsearch. Мы используем официальное Java API от Elasticsearch и пишем Bulk«ами.
Для высокой скорости записи нужно писать Bulk«ами.
Это важная оптимизация. API предоставляет Bulk-процессор, который автоматически накапливает запросы и потом отправляет на запись их пачкой или по времени.
Проблема с Bulk-процессор
Вроде бы все хорошо. Но мы запустили и поняли, что упираемся в Bulk-процессор — это было неожиданно. Мы не можем добиться тех значений, на которые рассчитывали — проблема пришла из ниоткуда.
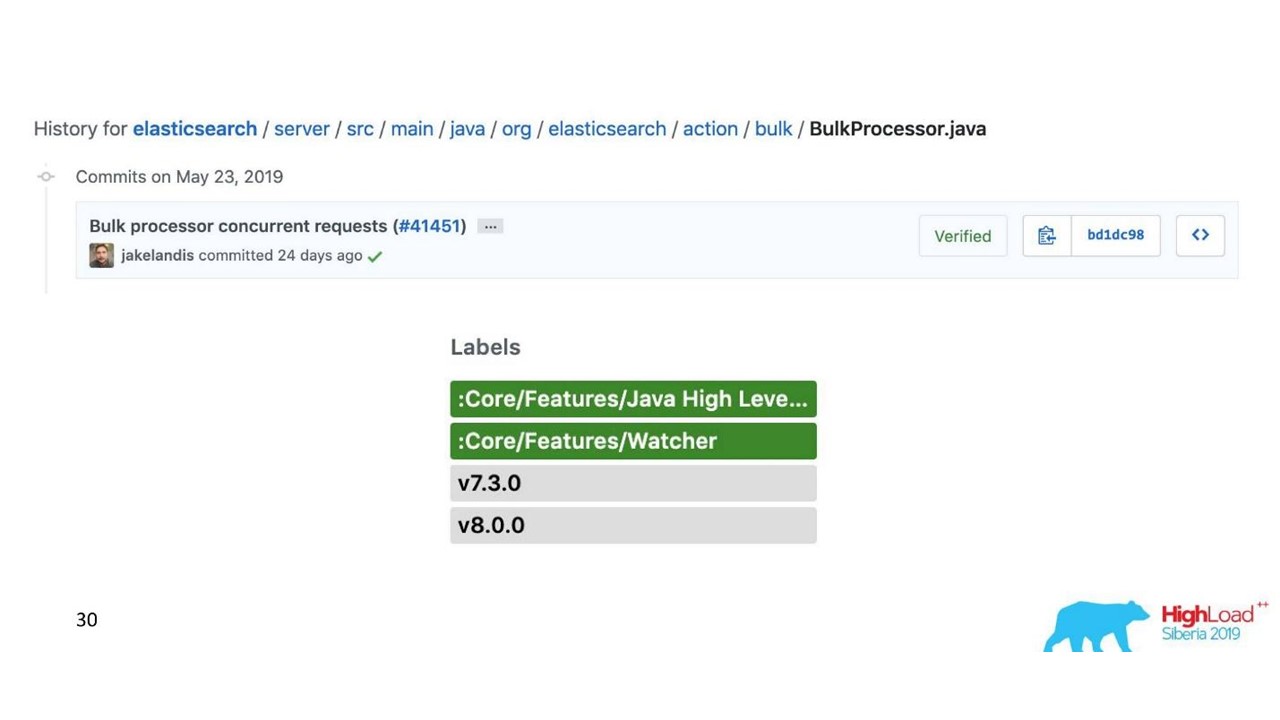
В стандартной реализации Bulk-процессор однопоточный, синхронный, несмотря на то, что там есть настройка параллелизма. В этом и была проблема.
Покопались и оказалось, что это известная, но не решенная бага. Мы немного изменили Bulk-процессор — сделали явную блокировку через ReentrantLock. Только в мае похожие изменения были внесены в официальный репозиторий Elasticsearch и будут доступны только с версии 7.3. Текущая — 7.1, а мы пользуемся версией 6.3.
Если вы также работаете с Bulk-процессором и хотите разогнать запись в Elasticsearch — посмотрите эти изменения на GitHub и обратно портируйте под вашу версию. Изменения затрагивают только Bulk-процессор. Сложностей не возникнет, если нужно портировать на версию ниже.
Все отлично, Bulk-процессор пошел, скорость разогналась.
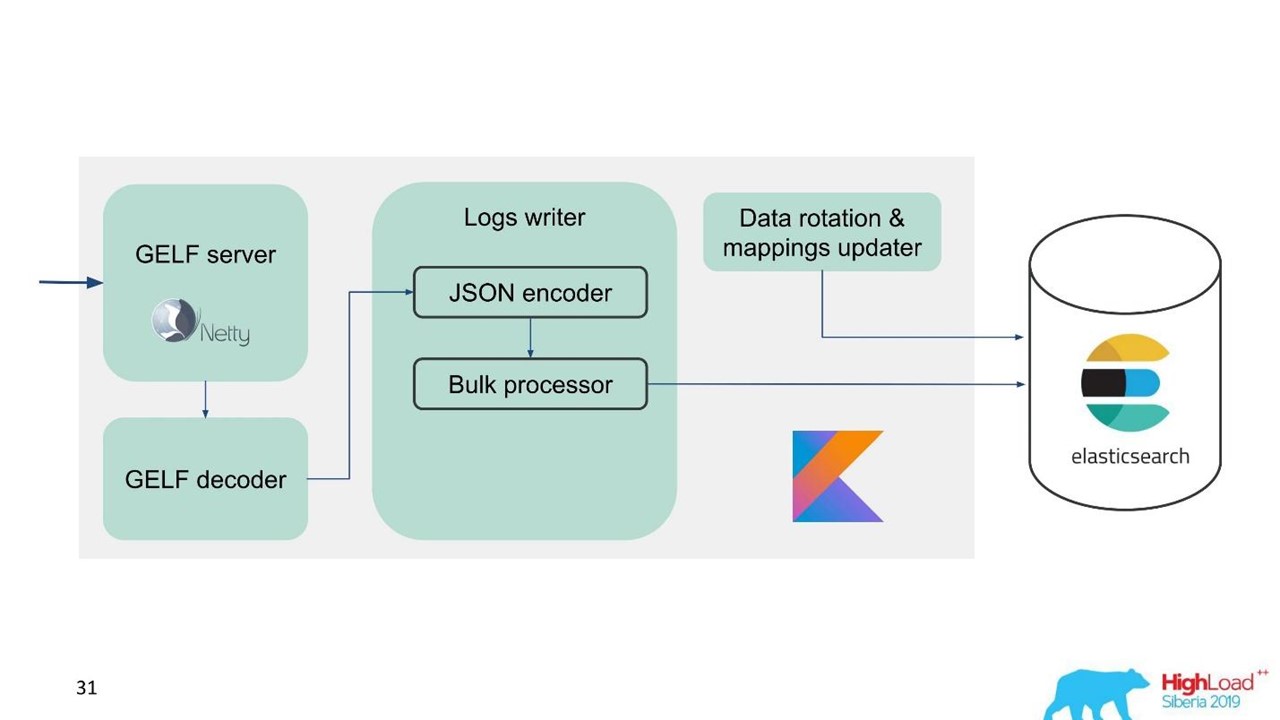
Производительность Elasticsearch на запись нестабильна во времени, поскольку там происходят различные операции: мёрджинг индексов, flush. Также производительность на некоторое время замедляется во время обслуживания, когда выбывает часть нод из кластера, например.
В связи с этим мы поняли, что нам нужна реализация не только буфера в памяти, но и очереди. Мы решили, что будем отправлять в очередь только отклоненные сообщения — только те, что Bulk-процессор не смог записать в Elasticsearch.
Retry fallback
Это простая реализация.
- Сохраняем в файл отклоненные сообщения —
RejectedExecutionHandler. - Повторно отправляем с заданным интервалом в отдельном executor.
- При этом мы не задерживаем новый трафик.
Для инженеров поддержки и разработчиков новый трафик в системе заметно важнее, чем тот, который почему-то задержался во время спайка или замедления Elasticsearch. Он задержался, но прибудет потом — ничего страшного. Новый трафик приоритетнее.
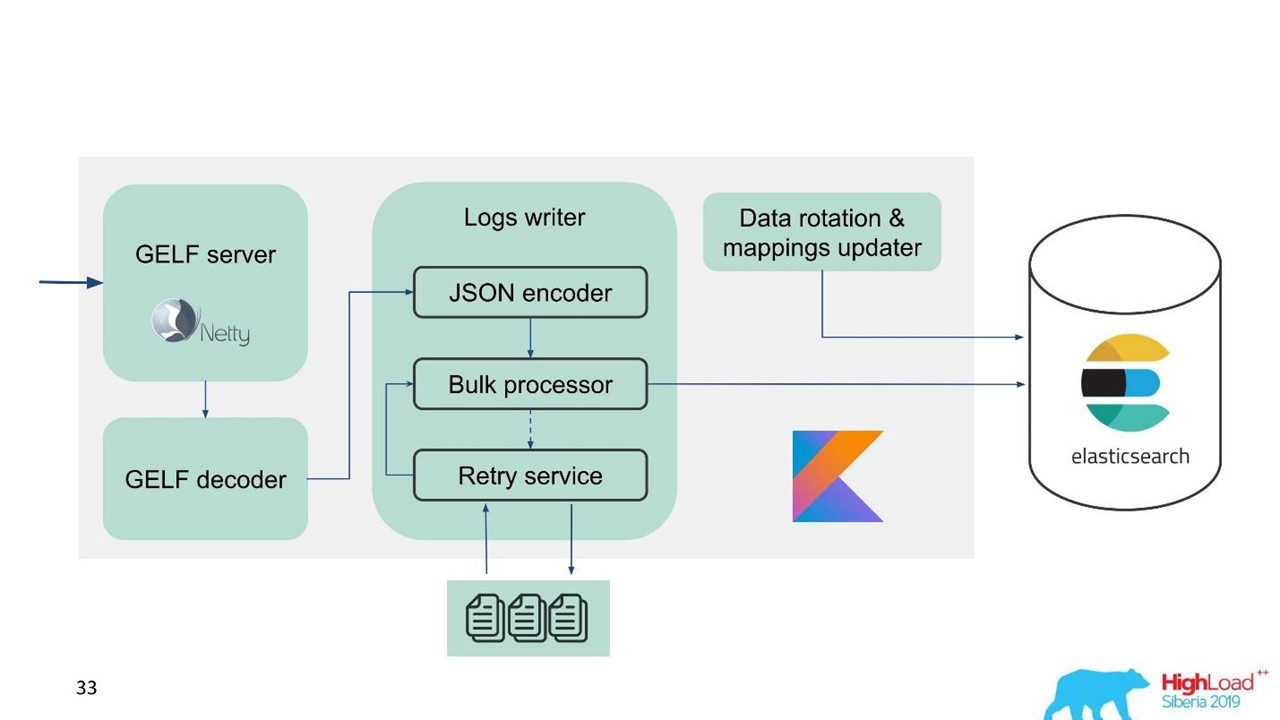
Наша схема стала выглядеть так.
Теперь поговорим как мы готовим Elasticsearch, какие параметры использовали и как настраивали.
Конфигурация Elasticsearch
Проблема, с которой мы столкнулись — необходимость разгонять Elasticsearch, оптимизировать его на запись, поскольку количество чтений заметно меньше.
Мы использовали несколько параметров.
"ignore_malformed": true — отбрасываем поля с неверным типом, а не весь документ. Нам все-таки хочется хранить данные, даже если почему-то туда просочились поля с неправильным маппингом. Этот параметр не совсем связан с производительностью.
Для железа у Elasticsearch есть нюанс. Когда мы начали просить большие кластеры, то нам сказали, что RAID-массивы из SSD-дисков под ваши объемы это жутко дорого. Но массивы не нужны, потому что отказоустойчивость и партиционирование уже встроено в Elasticsearch. Даже на официальном сайте есть рекомендация брать больше дешевого железа, чем меньше дорогого и хорошего. Это касается и дисков, и количества ядер процессоров, потому что весь Elasticsearch очень хорошо параллелится.
"index.merge.scheduler.max_thread_count": 1 — рекомендовано для HDD.
Если вам достались не SSD, а обычные диски HDD, то в этот параметр выставляйте единицу. Индексы пишутся кусочками, потом эти кусочки мёржатся. Это чуть-чуть экономит диск, но, прежде всего, ускоряет поиск. Также, когда вы перестали записывать в индекс, можно сделать force merge. Когда нагрузка на кластер поменьше, оно автоматически мёржится.
"index.unassigned.node_left.delayed_timeout": "5m" — задержка реаллокации при пропадании ноды. Это время через которое Elasticsearch начнет реаллоцировать индексы и данные, если какая-то нода перезагрузилась, деплоится или выведена для обслуживания. Но если у вас мощная нагрузка на диск и сеть, то реаллокация это тяжелая операция. Чтобы их не перегрузить, этот таймаут лучше контролировать и понимать, какие задержки необходимы.
"index.refresh_interval": -1 — не обновлять индексы, если нет поисковых запросов. Тогда индекс будет обновляться при появлении поискового запроса. Этот индекс может быть выставлен в секундах и минутах.
"index.translogDurability": "async" — как часто выполнять fsync: при каждом запросе или по времени. Дает прирост производительности для медленных дисков.
Еще у нас появился интересный способ применения. Поддержка и разработчики хотят иметь возможность полнотекстового поиска и применения regexp«ов по всему телу сообщения. Но в Elasticsearch это невозможно — он может искать только по токенам, которые уже есть в его системе. RegExp и wildcard можно использовать, но токен не может начинаться с какого-то RegExp. Поэтому мы добавили word_delimiter в фильтр:
"tokenizer": "standard"
"filter" : [ "word_delimiter" ]
Он автоматически разбивает слова на токены:
- «Wi-Fi» → «Wi», «Fi»;
- «PowerShot» → «Power», «Shot»;
- «SD500» → «SD»,»500».
Подобным образом пишется название класса, разная отладочная информация. С ним мы закрыли часть проблем с полнотекстовым поиском. Советую добавлять такие настройки, когда работаете с логином.
О кластере
Количество шард должно равняться количеству дата-нод для распределения нагрузки. Минимальное количество реплик — 1, тогда каждая нода будет иметь один основной шард и одну реплику. Но если у вас ценные данные, например, финансовые транзакции, — лучше 2 и более.
Размер шарда от нескольких ГБ до нескольких десятков ГБ. Количество шардов на ноде не больше 20 на 1 ГБ хипа Elasticsearch, естественно. Дальше Elasticsearch замедляется — мы на это тоже наступали. В тех дата-центрах где трафика немного, данные не ротировались по объему, появлялись тысячи индексов и система падала.
Используйте allocation awareness, например, по имени гипервизора на случай обслуживания. Помогает разбрасывать индексы и шарды по разным гипервизорам, чтобы они не пересекались, когда выбывает какой-то гипервизор.
Создавайте индексы предварительно. Хорошая практика, особенно когда пишем по времени. Индекс сразу горячий, готовый и нет задержек.
Ограничьте число шард одного индекса на ноде. "index.routing.allocation.total_shards_per_node": 4 — это максимальное количество шард одного индекса на ноде. В идеальном случае их 2, мы ставим 4 на всякий случай, если всё-таки у нас окажется меньше машин.
В чем здесь проблема? Мы используем allocation awareness — Elasticsearch знает, как правильно разбросать индексы по гипервизорам. Но мы выяснили, что после того, как нода была долго выключена, а потом обратно приходит в кластер, Elasticsearch видит, что на ней формально меньше индексов и они восстанавливаются. Пока данные не синхронизируются, формально на ноде мало индексов. При необходимости аллоцировать новый индекс Elasticsearch старается как можно плотнее забить эту машину свежими индексами. Так нода получает нагрузку не только от того, что на нее реплицируются данные, но еще и свежим трафиком, индексами и новыми данными, которые попадают на эту ноду. Контролируйте и ограничивайте это.
Рекомендации по обслуживанию Elasticsearch
Тем, кто работает с Elasticsearch, эти рекомендации уже знакомы.
Во время планового обслуживания применяйте рекомендации для rolling upgrade: disable shard allocation, synced flush.
Disable shard allocation. Отключите аллокацию реплик шард, оставьте возможность аллоцировать только primary. Это заметно помогает Elasticsearch — он не будет переаллоцировать данные, которые вам не нужны. Например, вы знаете, что через полчаса нода поднимется — зачем перебрасывать все шарды с одной ноды на другую? Ничего страшного не случится, если полчаса пожить с желтым кластером, когда доступны только primary-шарды.
Synced flush. В этом случае нода при возвращении в кластер синхронизируется намного быстрее.
При сильной нагрузке на запись в индекс или восстановлении можно уменьшить количество реплик.
Если вы загружаете большой объем данных, например, пик нагрузки, можно отключить шарды и позже дать команду, чтобы Elasticsearch их создал, когда нагрузка будет уже меньше.
Приведу несколько команд, которыми я люблю пользоваться:
GET _cat/thread_pool?v— позволяет посмотретьthread_poolна каждой ноде: что сейчас горячо, какие очереди на запись и чтение.GET _cat/recovery/?active_only=true— какие индексы куда реаллоцируются, где происходит восстановление.GET _cluster/allocation/explain— в удобном человеческом виде почему и какие индексы или реплики не аллоцировались.
Для мониторинга мы используем Grafana.
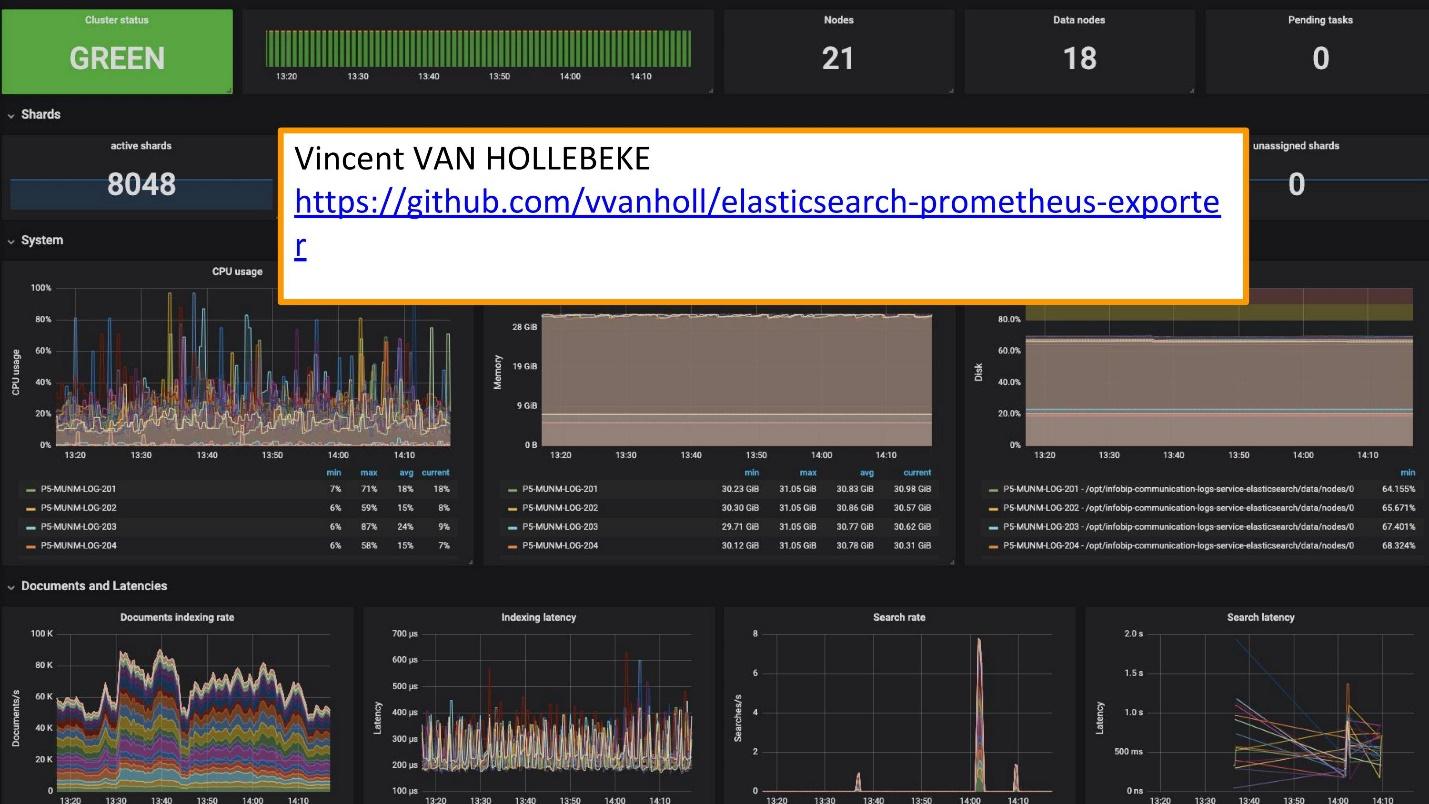
Есть прекрасный экспортер и Grafana teamplay от Vincent van Hollebeke, который позволяет наглядно смотреть состояние кластера и все его основные параметры. Мы добавили его в наш Docker-образ и все метрики при деплое у нас из коробки.
Выводы по логированию
Логи должны быть:
- централизованы — единая точка входа для разработчиков;
- доступны — возможность быстрого поиска;
- структурированы — для быстрого и удобного извлечения ценной информации;
- коррелированы — не только между собой, но и с другими метриками и системами, которые вы используете.
Недавно проходил шведский конкурс Melodifestivalen. Это отбор представителей от Швеции на Евровидение. Перед конкурсом к нам обратилась наша служба поддержки: «Сейчас в Швеции будет большая нагрузка. Трафик достаточно чувствительный и мы хотим коррелировать некоторые данные. У вас в логах есть данные, которых не хватает на дашборде Grafana. У нас есть метрики, которые можно взять из Prometheus, но нам нужны данные по конкретным ID-запросам».
Они добавили Elasticsearch как источник Grafana и смогли коррелировать эти данные, закрыть проблему и получить достаточно быстро хороший результат.
Эксплуатация собственных решений заметно проще.
Сейчас вместо 10 кластеров Graylog, которые работали для этого решения, у нас несколько сервисов. Это 10 дата-центров, но у нас нет даже специально выделенной команды и людей, которые их обслуживают. Есть несколько человек, которые работали над ними и что-то меняют по необходимости. Эта маленькая команда прекрасно вписана в нашу инфраструктуру — деплоить и обслуживать легче и дешевле.
Разделяйте кейсы и используйте соответствующие инструменты.
Это отдельные инструменты для логирования, трассировки и мониторинга. Нет «золотого инструмента», который закроет все ваши потребности.
Чтобы понять, какой именно инструмент нужен, что именно мониторить, какие где использовать логи, какие требования логам, нужно обязательно обратиться к SLI/SLO — Service Level Indicator/Service Level Objective. Нужно знать, что важно для ваших клиентов и вашего бизнеса, на какие индикаторы они смотрят.
Уже через неделю в СКОЛКОВО состоится HighLoad++ 2019. Вечером 7 ноября Иван Летенко расскажет, как живется с Redis на проде, а всего в программе 150 докладов на самые разные темы.Если у вас не получается посетить HighLoad++ 2019 вживую, у нас хорошие новости. В этом году конференция пройдет сразу в трех городах — в Москве, Новосибирске и Санкт-Петербурге. Одновременно. Как это будет и как попасть — узнайте на отдельной промостранице события.
