Распознавание текста в ABBYY FineReader
Систему распознавания текста в FineReader можно описать очень просто.У нас есть страница с текстом, мы разбираем ее на текстовые блоки, затем блоки разбираем на отдельные строчки, строчки на слова, слова на буквы, буквы распознаем, дальше по цепочке собираем все обратно в текст страницы.

Выглядит очень просто, но дьявол, как обычно, кроется в деталях.
Про уровень от документа до строки текста поговорим как-нибудь в следующий раз. Это большая система, в которой есть много своих сложностей. В качестве некоторого введения, пожалуй, можно оставить здесь вот такую иллюстрацию к алгоритму выделения строк.

В этой статье мы начнём рассказ про распознавание текста от уровня строки и ниже.
Небольшое предупреждение: система распознавания FineReader — очень большая и постоянно дорабатывается в течение многих лет. Описывать эту систему целиком со всеми ее нюансами, во-первых, лучше кодом, а во-вторых, — займет очень-очень много места. Поэтому к тому, что здесь описано, рекомендуем относиться как к некой очень обобщенной теории, стоящей за практической системой. То есть общие идеи и направления в технологии примерно похожи на правду, но чтобы понять до мелочей, что же там на практике происходит, лучше не читать эту статью, а работать у нас над разработкой этой системы.
Граф линейного деленияИтак, у нас есть черно-белое изображение строки текста. На самом деле изображение, конечно, серое или цветное, а черно-белым становится после бинаризации (про бинаризацию тоже нужно писать отдельную статью, а пока отчасти может помочь вот это.Так вот, пусть у нас есть черно-белое изображение строки текста. Нам нужно его поделить на слова, а слова на символы для распознавания. Базовая идея, как обычно, очевидна — ищем на изображении строки вертикальные белые просветы, а дальше кластеризуем их по ширине: широкие просветы — это пробелы между словами, узкие — между символами.

Идея замечательная, но в реальной жизни ширина пробелов может быть очень неоднозначным показателем, к примеру, для текста с наклоном или неудачного сочетания символов или слипшегося текста.

Решений у проблемы, в общем, два. Решение первое — считать некую «видимую» ширину просветов. Человек может практически любой текст, даже на незнакомом языке, точно поделить на слова, а слова на символы. Это происходит потому, что мозг фиксирует не вертикальное расстояние между символами, а некий видимый объем пустого пространства между ними. Решение хорошее и мы его, конечно, используем, только работает оно не всегда. К примеру, текст может быть повреждён при сканировании и некоторые нужные просветы могут уменьшиться или, наоборот, сильно увеличиться.
Это приводит нас ко второму решению — графу линейного деления. Идея в следующем — если у нас есть несколько вариантов, где поделить строку на слова, а слова на буквы, то давайте отметим все возможные точки деления, которые мы смогли придумать. Кусок изображения между двумя отмеченными точками будем считать кандидатом буквы (или слова). Вариант графа линейного может быть простым, если текст хороший и нет проблем с определением точек деления или сложным, если изображение было плохое.


Теперь задача. У нас есть множества вершин графа, нужно найти путь от первой вершины до последней, проходящий через какое-то количество промежуточных вершин (не обязательно все) с наилучшим качеством. Начинаем думать, что нам это напоминает. Вспоминаем курс оптимального управления из института, понимаем, что это подозрительно похоже на задачи динамического программирования.
Давайте подумаем, что нам нужно, чтобы алгоритм перебора всех вариантов не взорвался.
Для каждой дуги в графе нам нужно определить ее качество. Если мы работаем с графом линейного деления слова на символы, то каждая дуга у нас — это символ. Как качество этой дуги мы использовать уверенность распознавания этого символа, как его посчитать мы поговрим позднее. А если мы работаем с ГЛД на уровне строки, та каждая дуга этого ГЛД — это вариант распознавания слова, который в свою очередь был получен из символьного графа. То есть нам нужно уметь оценивать общее качество полного пути в графе линейного деления.
Качество полного пути в графе мы будем определять как сумму качества всех дуг МИНУС штраф за весь вариант. Почему именно минус? Это дает нам возможность быстро оценить максимально возможное качество варианта пути по сумме качества дуг этого пути, а это значит, что большинство вариантов мы будем отсекать еще до подсчета общего качества варианта.
Таким образом для ГЛД мы приходим к стандартному алгоритму динамического программирования — находим точки линейного деления, строим путь от начала до конца по дугам с наибольшим качеством, высчитываем итоговую стоимость построенного варианта. А дальше перебираем пути в ГЛД в порядке уменьшения суммарного качества элементов с постоянным обновлением найденного лучшего варианта, пока не поймем, что все необработанные варианты заведомо хуже, чем текущий лучший вариант.
Гипотезы изображения Прежде, чем мы спустимся на уровень распознавания отдельных слов, у нас есть еще одна тема которая не обсуждалась, — гипотезы изображения фрагмента.Идея в следующем — у нас есть изображение текста, с которым мы собираемся работать. Очень хочется все изображения обрабатывать одинаковым образом, но правда в том, что в реальном мире изображения все разные — они могут быть получены из разных источников, они могут быть разного качества, они могут быть по-разному отсканированы.
С одной стороны, кажется, что разнообразие возможных искажений должно быть очень велико, но если начать разбираться, обнаруживается только ограниченный набор возможных искажений. Поэтому мы используем систему гипотез текста.
У нас есть предопределенный набор возможных гипотез проблемного текста. Для каждой гипотезы нужно определить:
Быстрый способ выяснить, применима ли данная гипотеза к текущему изображению, причем сделать это только на основе характеристик изображения, до распознавания.
Метод для исправления на изображении проблем конкретной гипотезы.
Критерий качества правильности выбора гипотезы по итогам распознавания изображения, плюс, возможно, рекомендации для следующих гипотез.

 На изображении выше можно увидеть гипотезы для различной бинаризации и контрастности исходного изображения.
На изображении выше можно увидеть гипотезы для различной бинаризации и контрастности исходного изображения.
В результате обработка гипотез выглядит так:
По изображению сгенерировать наиболее подходящую гипотезу.
Исправить искажения от выбранной гипотезы.
Распознать полученное изображение.
Оценить качество распознавания.
Если качество распознавания улучшилось, то оценить, нужно ли применять новые гипотезы к измененному изображению.
Если качество ухудшилось, то вернуться к исходному изображению и попробовать применить к нему какую-либо другую гипотезу.
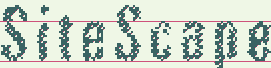
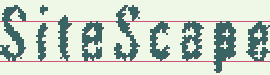
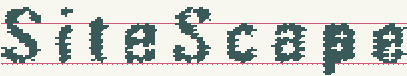
На изображениях показано последовательное применение гипотез белого шума и сжатого текста.
Оценка качества слова У нас остались нераскрытыми две важных темы: оценка общего качества распознавания слова и распознавание символов. Распознавание символа — тема на несколько разделов, поэтому сначала обсудим оценку качества распознанного слова.Итак у нас есть некий вариант распознавания слова. Первое, что приходит на ум, — проверить его по словарю и дать ему штраф, если оно в словаре не нашлось. Идея хорошая, но не все языки есть словари, не все слова в тексте могут быть словарными (имена собственные, к примеру), и, если уж мы углубляемся в сложности, — не всё в тексте вообще может быть словами в стандартном понимании этого термина.
Чуть раньше мы говорили, что любые оценки за слово целиком должны быть отрицательными, чтобы у нас нормально работал перебор по ГЛД. Сейчас нам это начнет активно мешать, поэтому давайте зафиксируем, что у нас есть некая заранее определенная максимальная положительная оценка слова, слову мы даем положительные бонусы, а финальный отрицательный штраф определяем как разность набранных бонусов и максимальной оценки.
Ок, пусть мы распознаём фразу «Вася прилетает рейсом SU106 в 23.55 20/07/2015». Мы, конечно, можем оценивать здесь качество каждого слова по общим правилам, но это будет достаточно странно. Скажем, и SU106 и Вася вполне понятные в данной строке слова, но очевидно, что правила образования у них разные и, по идее, верификация тоже должна быть разной
Отсюда появляется идея моделей. Модель слова — это некое обобщенное описание конкретного типа слов в языке. У нас, конечно, будет модель стандартного слова в языке, но также будут модели чисел, аббревиатур, дат, сокращений, имен собственных, URL и т.д.
Что нам дают модели и как их нормально использовать? Фактически мы обращаем в обратную сторону нашу систему проверки слова — вместо того чтобы для варианта слова долго узнавать, что же это такое, мы даем каждой модели решать, подходит ли ей данный вариант слова и насколько хорошо она его оценивает.

Из самой постановки задачи формируются наши требования к архитектуре модели. Модель должна уметь:
Быстро сказать, подходит или нет для нее вариант слова. Стандартная проверка включает все проверки разрешенных наборов символов для каждой буквы в слове. Скажем, в словарном слове пунктуация должна быть только в начале или в конце, а в середине слова набор пунктуации сильно ограничен, и сочетание пунктуации сильно ограничено (супер-способность?!), а в модели числа в основном должны быть цифры, кроме разрешенного в данном языке символьного суффикса (10-ое, 10th). Уметь по своей внутренней логике оценить качество распознаваемого слова. К примеру, слово из словаря должно явно оцениваться выше, чем просто набор символов. При оценке качества модели не стоит забывать, что наша задача в итоге — сравнивать модели между собой, поэтому их оценки должны быть согласованы. Более-менее нормальный способ этого добиться — это относиться к оценке модели как к оценке вероятности построить слово по данной модели. Скажем, словарных слов в обычном языке достаточно много, и получить словарное слово при неправильном распознавании несложно. А вот собрать нормальный, подходящий под все правила телефонный номер уже гораздо сложнее.
В итоге при распознавании некоторого фрагмента строки у нас получается примерно такая схема:
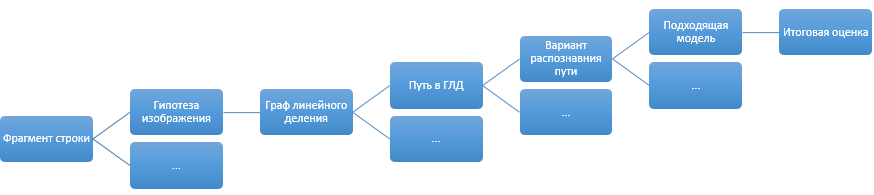
Отдельным пунктом при оценке вариантов распознавания идут дополнительные эмпирические штрафы, не вписывающиеся ни в концепцию моделей, ни в оценку распознавания. Скажем, «ООО Рога и копыта» и »000 Рога и копыта» выглядят как два одинаково нормальных варианта (особенно если в шрифте 0 (ноль) и О (буква О) слабо отличаются пропорциями). Но при этом достаточно очевидно, какой вариант распознавания должен быть правильным. Для таких небольших конкретных знаний о мире сделана отдельная система правил, которая может дополнительно штрафовать не понравившиеся ей варианты после оценок моделей.
Про само распознавание поговорим уже в следующей части этого поста. Подписывайтесь на блог компании, чтобы не пропустить :)
