Расчёт вкусов пользователя для ленты рекомендаций с применением item2vec-подхода
Ежемесячная аудитория ОК только в России превышает 36 млн человек. Причём это активные пользователи, которые хорошо взаимодействуют с нашим контентом: ставят Классы, комментируют, делают репосты. Залогом активного отклика во многом является формирование новостной ленты с учетом предпочтений каждого конкретного пользователя.
Меня зовут Дмитрий Решетников. Я тимлид команды рекомендаций в Ленте ОК. В этой статье я расскажу, как выглядит наш пайплайн рекомендации в ленте новостей, о месте item2vec в нём и результатах внедрения такого подхода.
Пайплайн подготовки рекомендаций для ленты пользователей
В ОК мы строим два основных типа новостной ленты:
Подписная — лента с контентом, на который пользователь подписался сам. В нее входят посты от групп пользователя и его друзей.
Рекомендательная — лента, которая формируется из контента, который может понравиться пользователю, но генерируется людьми и группами, на которых человек еще не подписан.
Обе ленты пользователя строятся схожим способом — используется классическая двухэтапная модель рекомендаций:
на первом этапе из множества всех постов, доступных пользователю, мы выделяем некоторое подмножество;
на втором этапе — с помощью XGBoost ранкера формируем ленту новостей, размещая на первых позициях наиболее интересный пользователю контент из собранного подмножества.
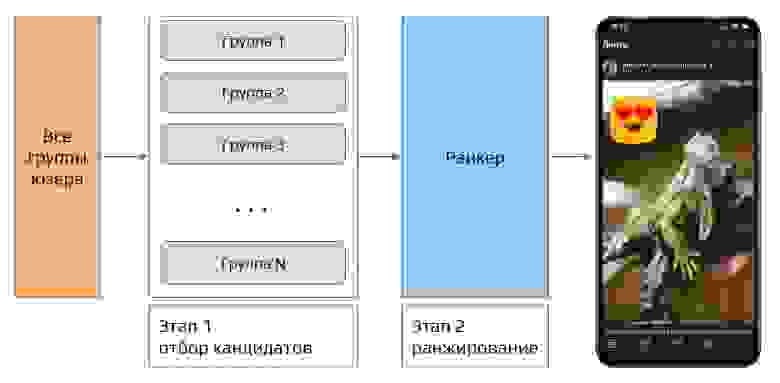
Двухэтапная модель рекомендаций подписного контента.
В случае с подписной лентой задача первого этапа сводится к поиску контента групп и друзей пользователя, который пользователь еще не видел.
В случае с неподписной или рекомендательной лентой подход к первому этапу немного меняется, поскольку в качестве первичного множества потенциальных постов приходится рассматривать весь контент в ОК за все время, а не только контент из небольшого множества групп.
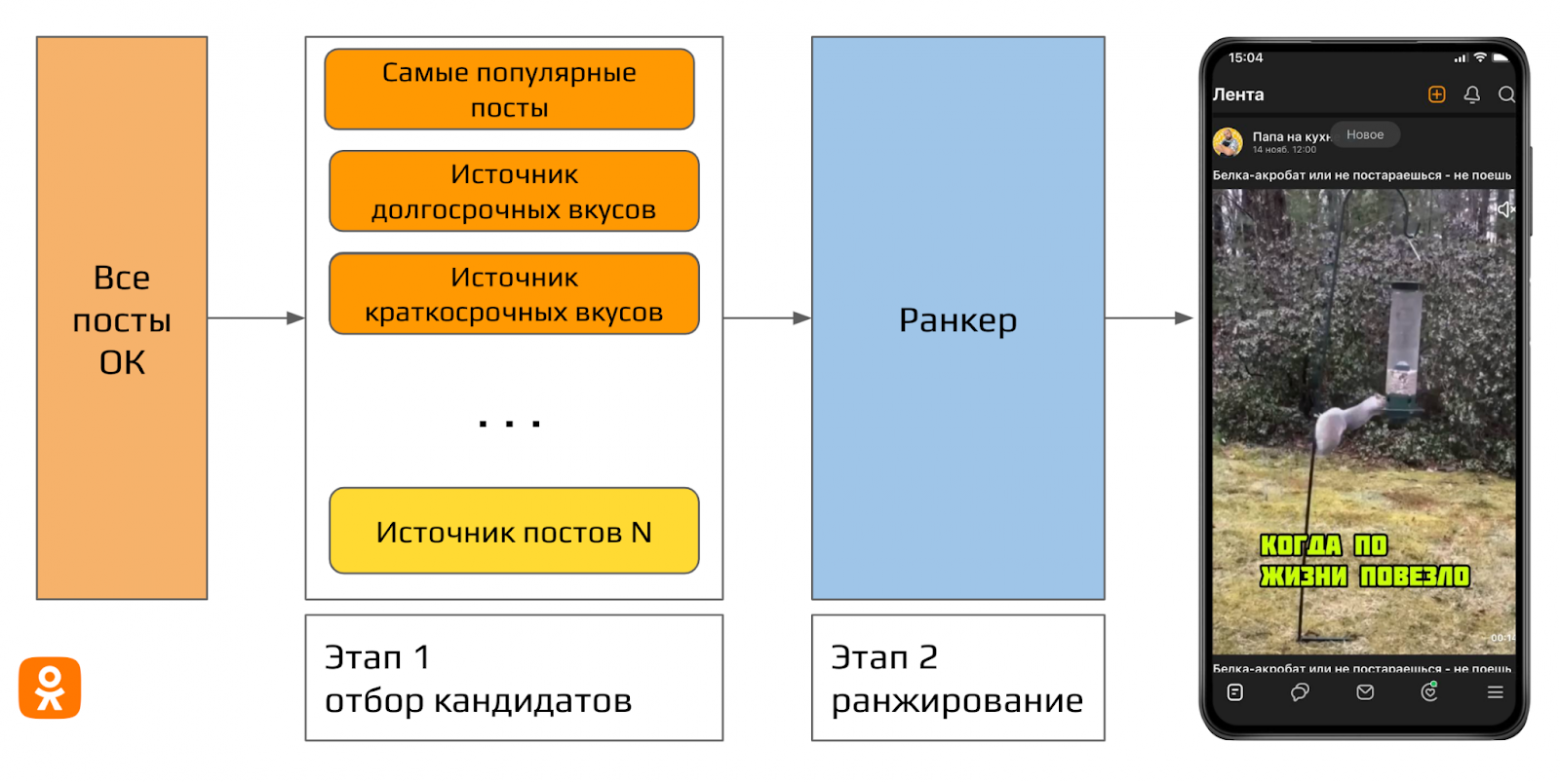
Двухэтапная модель рекомендаций для ленты рекомендаций.
Есть много способов поиска интересных пользователю постов. Давайте разберемся с некоторыми из них на примере.
Так, при регистрации на портале нового пользователя мы исходно знаем о нем только возраст и пол. Имея эту информацию, мы уже можем предложить ему наиболее популярные по CTR (click-through rate) посты для его соцдем-группы. Таким образом мы получили один из источников для отбора постов на первом этапе нашего пайплайна — источник самых популярных постов. Такой источник подходит для рекомендаций «холодным» пользователям, но он недостаточно персонализирован.
Посмотрим на нашего пользователя некоторое время спустя: он уже успел посмотреть посты из источника популярного контента, ему что-то понравилось, где-то он поставил класс, что-то прокомментировал, может остановился на каком-нибудь лонгриде. Теперь мы знаем его предпочтения и готовы построить новые источники с более персонализированными рекомендациями, чтобы пользователь возвращался к нам чаще.
Для получения таких рекомендаций мы в ОК разработали источники краткосрочных и долгосрочных вкусов.
Краткосрочные и долгосрочные вкусы
Для определения краткосрочных вкусов мы запоминаем последние несколько постов, с которыми взаимодействовал пользователь. На основании этой информации мы находим похожие посты и передаем их на ранжирование во второй этап пайплайна.
Для выявления долгосрочных вкусов мы анализируем активность пользователя за 6 месяцев. Поскольку данных о действиях пользователя в этом случае существенно больше, мы сначала кластеризуем с помощью DBSCAN посты, для которых есть фидбэк от пользователя, а после выделяем медоиды — центральные посты в каждом кластере. Такие медоиды мы считаем долгосрочными вкусами и на их основе ищем похожий контент для последующего ранжирования и формирования рекомендательной ленты.
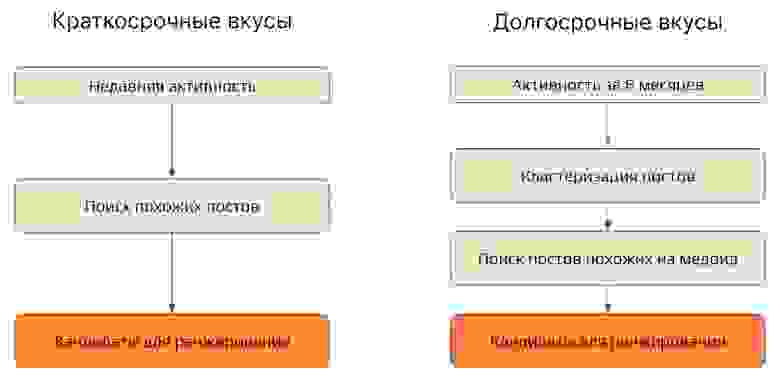
Алгоритм расчета краткосрочных и долгосрочных вкусов.
Для кластеризации постов и поиска похожего контента мы разработали item2vec-подход. Давайте разберёмся с тем, как он работает
Реализация item2vec-подхода
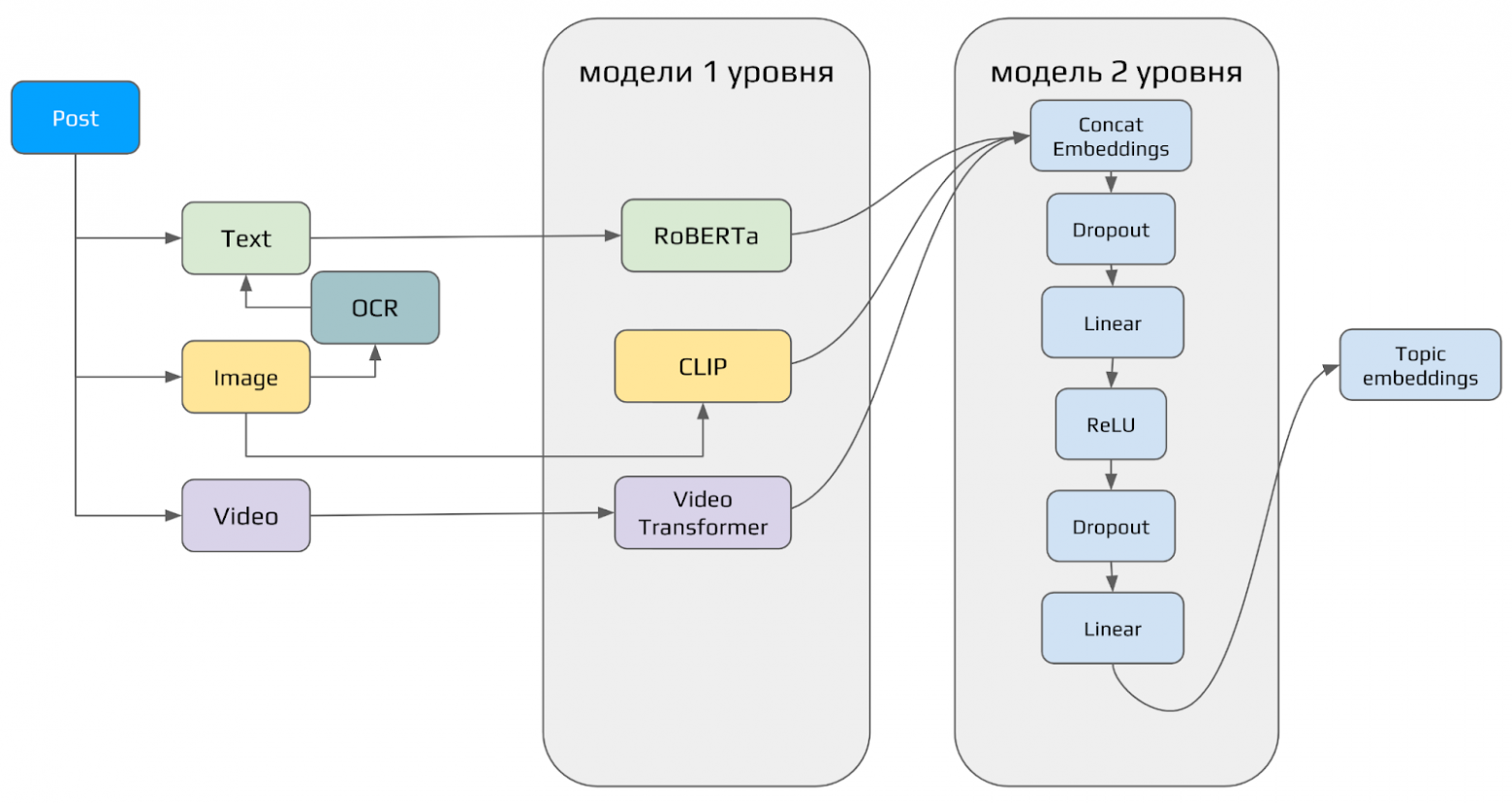
В нашей реализации Item2vec-пайплайн выполняет следующие шаги:
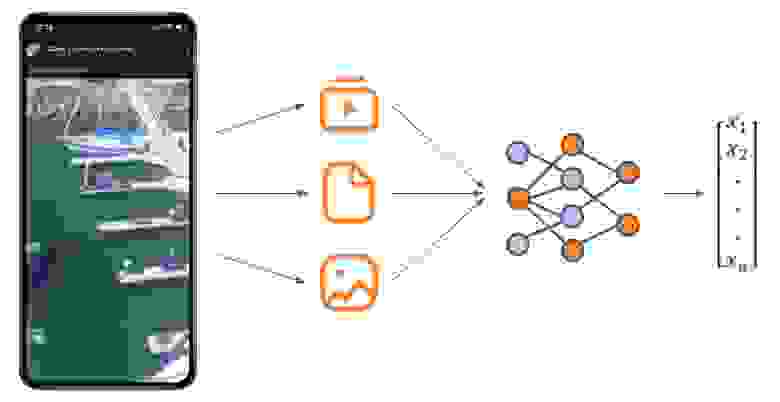
из каждого поста выделяются все доступные типы контента (видео, текст и картинка);
для каждого типа контента получается отдельный эмбеддинг;
на выходе получается вектор в n-мерном пространстве.
Реализован item2vec в виде двухэтапного пайплайна:
на первом уровне контентные модели векторизуют каждый тип контента отдельно;
на втором — полученные векторы конкатенируются и пропускаются через полносвязную нейронную сеть для получения вектора искомой размерности.
На первом этапе мы используем следующую конфигурацию моделей:
для текста — модель RoBERTa, дообученная на большом корпусе русскоязычного текста;
для картинок — модель CLIP, разработанная компанией OpenAI;
для видео — трансформер поверх efficientnet эмбеддингов 16 равномерно распределенных кадров из видео, обученный нами на раскадровках из видео.
На втором уровне item2vec представляет собой полносвязную линейную нейронную сеть.
Сбор датасета и валидация
Для обучения модели второго уровня мы собираем датасет с информацией о том, с какими постами пользователь последовательно взаимодействует в рамках одной сессии — в своей реализации мы считаем, что если оба поста нравятся пользователю, то их можно считать в некоторой степени похожими. Мы хотим, чтобы в нашем n-мерном пространстве такие посты были близко друг к другу.
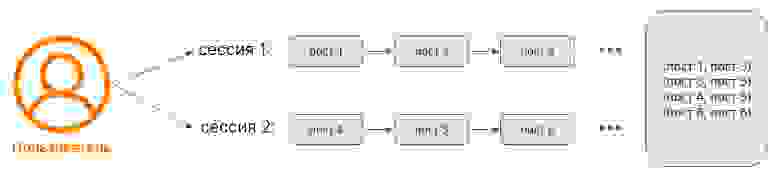
Собрав пары таких положительных взаимодействий, мы обучаем нашу модель второго этапа и получаем возможность собирать эмбеддинги.
Далее мы приступаем к проверке качества модели.
Офлайн-валидация
Сначала выполняем офлайн-валидацию — проверять сразу в онлайне на пользователях больно и дорого.
Для задач офлайн-валидации мы собрали эталонный датасет, после чего разметили его по 23 категориям и 60 саб-категориям.
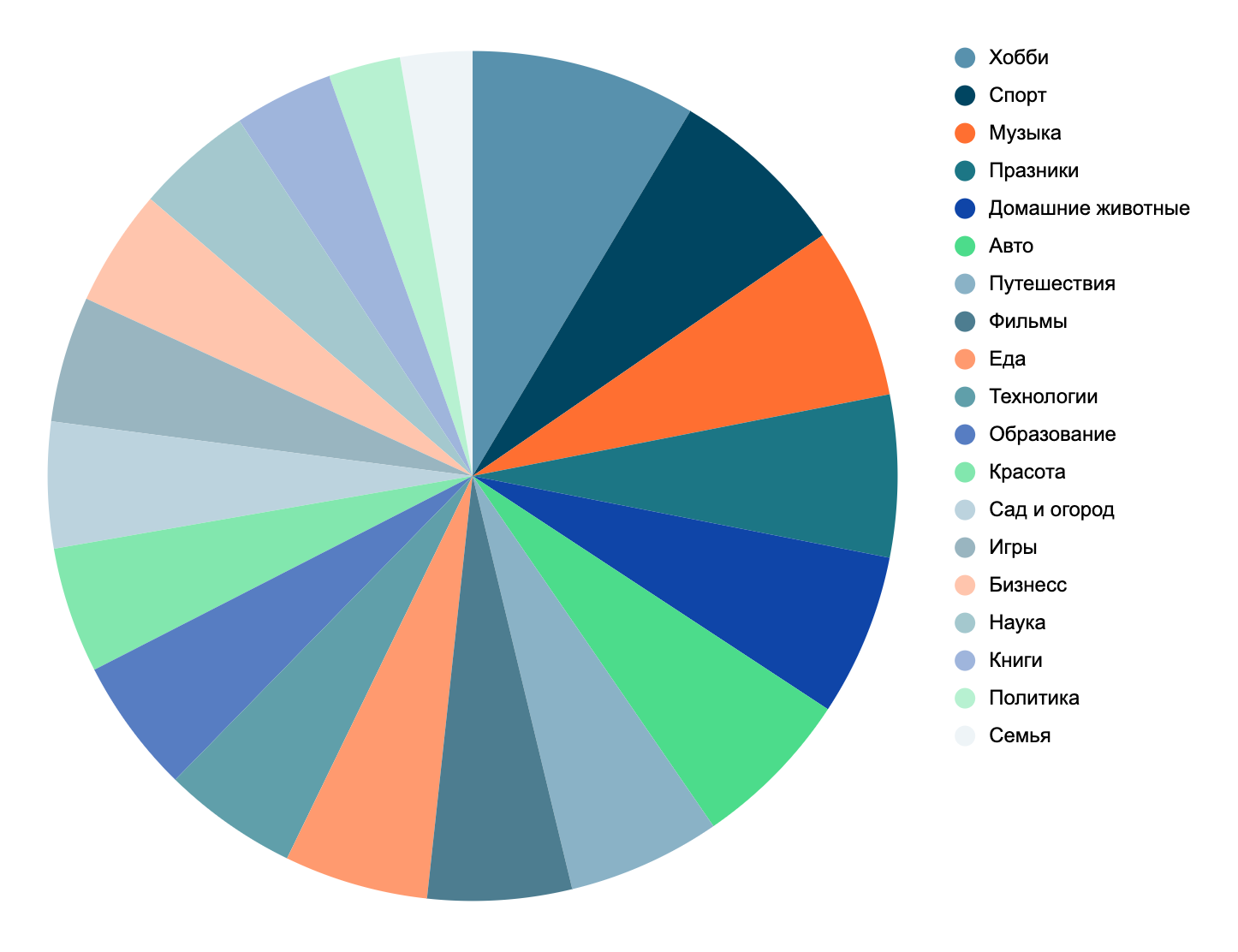
Распределение категорий в эталонном датасете.
Для каждого поста мы ищем наиболее близкие в новом полученном n-мерном пространстве посты и считаем на этих постах метрику Map@K. Если метрика улучшилась — модель качественная и ее можно передавать дальше на онлайн-валидацию через A/B-тестирование.
Онлайн-валидация
Онлайн-валидацию мы реализуем с помощью A/B-платформы ОК. Она автоматизирует большинство процессов, необходимых для построения корректного эксперимента, подбора аудитории, автоматизации расчетов. Таким образом, чтобы проверить модель в бою, дата-сайентисту остается только посмотреть на результаты эксперимента и сделать заключение, можно ли выходить с моделью в прод или нужны какие-то доработки.
Подробнее о нашей А/В-платформе можно почитать здесь и здесь.
Item2vec в проде
Для понимания функционирования item2vec-пайплайна в продакшене, давайте рассмотрим два сервиса, необходимые для его работы: Vector Index и Feature store.
Vector Index — сервис для быстрого приближенного поиска ближайших соседей в высокоразмерных векторных пространствах. Он позволяет потоково читать объекты из Kafka-топиков для хранения в FAISS индексе. В нем мы будем хранить векторы постов для поиска постов с похожим контентом.
Узнать больше деталей об этом инструменте можно, посмотрев выступление Андрея Кузнецова на codefest в прошлом году.
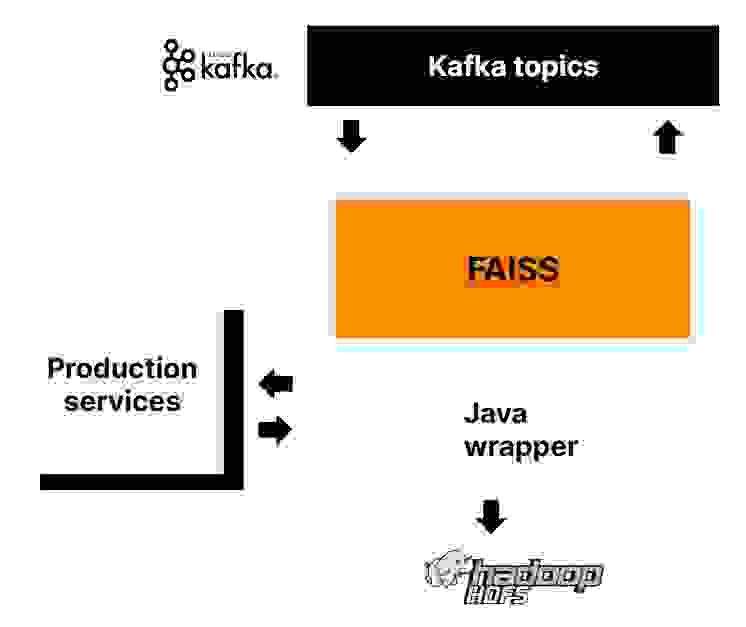
Архитектура Vector Index.
Feature store — сервис для доставки фичей батчами и стримингом, который поддерживает гибкие форматы хранения фичей и способен работать с большими объемами данных (миллиарды объектов, 25TB). В этом сервисе мы будем хранить для каждого пользователя векторы его долгосрочных и краткосрочных вкусов.
Подробнее о работе нашего feature store рассказывал мой коллега Андрей Кузнецов здесь.

Архитектура feature store.
Итоговый пайплайн
В итоге архитектура нашего сервиса в продакшене выглядит следующим образом:
Группы генерируют посты для рекомендательной ленты — как правило, более 400 тысяч постов каждый день.
Новые посты поступают в Kafka-топик и последовательно проходят через все контентные модели.
После обработки эмбеддинги контента поступают в Item2vec, который преобразовывает их в векторы меньшей размерности и складирует полученные векторы в Vector Index.
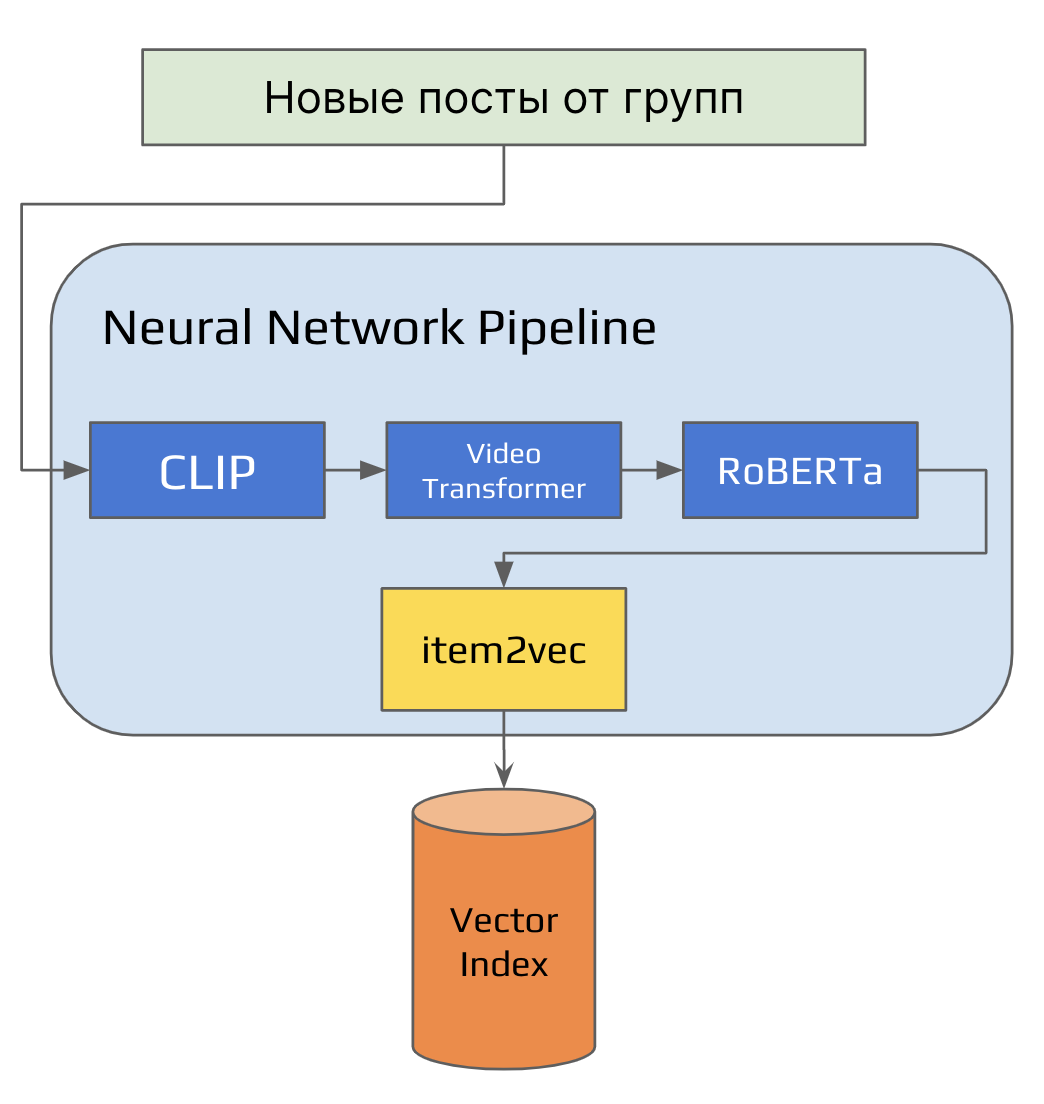
Загрузка эмбеддингов в Vector Index.
Далее, в момент загрузки пользовательского приложения, происходит следующее:
на бэкенд поступает запрос от клиента, например, от Android-приложения;
бэкенд обращается в Feature store и по ID пользователя запрашивает его краткосрочные и долгосрочные вкусы;
с данными о краткосрочных и долгосрочных вкусах бэкенд обращается в Vector Index, где получает ближайшие посты;
эти посты передаются в ранкер, где XGBoost модель ранжирует их и возвращает отсортированный список постов бэкенду;
бэкенд отправляет соответствующий контент в приложение пользователя.
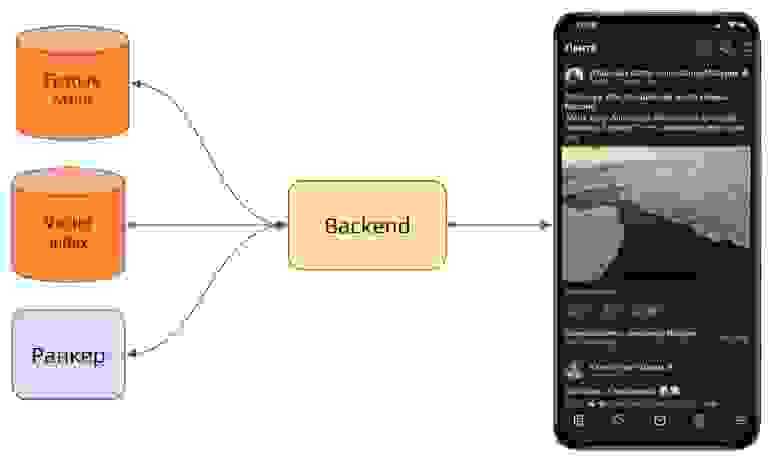
Обработка запроса от клиента.
При этом вся сложная логика реализуется за доли секунды, а пользователь сразу видит в новостной ленте посты, соответствующие его вкусам.

Пример рекомендаций.
Выводы
Векторизация постов и применение описанного пайплайна подбора рекомендаций позволили нам получить качественные источники долгосрочных и краткосрочных вкусов для ленты рекомендаций — на момент релиза они стали самыми кликабельными источниками среди всех источников неподписной ленты.
По результатам A/B-тестов новые источники позволили улучшить метрики ленты рекомендаций:
количество пользователей, читающих больше 40 постов выросло на 4%;
на 3% выросло время пользователей в ленте;
количество положительного фидбека увеличилось на 2,5%.
Вместе с тем, мы не останавливаемся на достигнутом и продолжаем развивать инструмент: пробуем новые модели для получения контентных эмбеддингов, экспериментируем со структурой модели второго уровня, ищем и находим альтернативные способы применения.
