Random User-Agent — версия вторая
Прошло два года с того момента, как вышла первая версия этого расширения для Chromium-based браузеров (работает в Google Chrome, Yandex.Browser и т.д.), задача которого проста и понятна — скрывать настоящий User-Agent. На данный момент это расширение работает у +6.000 пользователей (что очень скромно), и несколько дней назад получил на почту письмо с просьбой его немного доработать. Оценив состояние кода, к которому два года никто не притрагивался, было решено — переписывать его с нуля. Четыре дня работы, и вуаля — встречаем свежую мажорную версию, значительно улучшенную и с новым функционалом.

Под катом будут некоторые мысли как по поводу чуть-более анонимного веб-серфинга, настройке браузера Google Chrome, и почему это расширение может быть полезно. Чуть-чуть опытные анонимусы не найдут в посте для себя чего-либо интересного, поэтому для них, как и для самых нетерпеливых, традиционно — исходники на GitHub и расширение в Google Webstore.
Об анонимности
Не буду говорить о том, что есть смысл пускать весь внешний сетевой трафик через VPN/OpenVPN/Tor и прочие шифрованные туннели; не буду говорить и о том, что если компетентным лицам, обладающими достаточными ресурсами понадобиться схватить тебя за задницу, скорее всего — они схватят (ты же не пользуешься только мобильным интернетом в странах третьего мира по анонимным сим-картам, постоянно перемещаясь, и глядя в сеть только с помощью telnet-а через Tor?).
Анонимность и удобство веб-серфинга, всё чаще — вещи взаимоисключающие. 3rd party cookies — это очень удобно (не надо авторизовываться на ресурсах, использующих единую авторизацию), но они же позволяют успешно отслеживать ваши перемещения по другим ресурсам. Использование proxy/socks дают дополнительные средства сокрытия реального IP адреса, но они порою успешно определяются многими ресурсами (авито, пикабу — к примеру), и из-за их использования — доступ к ресурсу для тебя закрывают. Использование агрессивных AD-блокеров определяются сайтами, и они бережно просят отключить их. Поэтому и приходится балансировать на грани — удобство, или безопасность.
Да, для меня безопасность является синонимом к слову анонимность. «Нет, мне нечего скрывать, но это совершенно не ваше дело» © хабражитель.
Я пользуюсь различными браузерами. Одновременно довольно часто запущены и FireFox, и TorBrowser, и Google Chrome (его то и использую чаще всего). В разных браузерах различные наборы плагинов/прокси, и соответственно разные настройки. Каждый из них заслуживает отдельного разговора, но сейчас я бы хотел вновь поговорить именно о Google Chrome. Ниже я перечислю настройки этого браузера по умолчанию которые, возможно, следует изменить:
- Настройки синхронизации избыточны;
- «Настройки» > «Дополнительные настройки синхронизации» > Отмечаем лишь «Сервисы», «Расширения», «Настройки» и «Закладки» (этот список можно сократить до «Расширения», «Настройки»);
- Там же включаем шифрование с помощью кодовой фразы;
- Переходим по ссылке и выключаем всё;
- Популярные поисковые системы отслеживают ваши действия;
- Ставим в качестве поисковой системы (вроде как анонимный)
https://duckduckgo.com?q=%s;
- Ставим в качестве поисковой системы (вроде как анонимный)
- Хранение файлов cookies разрешено для всех;
- «Настройки» > «Настройки контента» > «Файлы cookie» > «Не разрешать сайтам сохранять данные» + «Блокировать данные и файлы cookie сторонних сайтов»;
- При посещении ресурсов, где поддержка cookies необходима для функционирования, нажимаем на «печеньку» в строек браузера > «Показать cookies и другие данные…» > «Заблокировано» > Те, которые необходимо хранить после закрытия браузера — отмечаем как «Разрешить», иначе — «Удалять при выходе»;
- Время от времени проверять списки исключений, удаляя из разрешенных всё лишнее;
- Максимальный срок хранения файлов cookies невозможно ограничить;
- Ставим Limit Cookie Lifetime, выставляем лимит в 7 дней, к примеру. Да, раз в неделю придется перезаходить на свои ресурсы, но и треки более недели не будут актуальны (если только анализатор треков не обладает добротной логикой);
- Запуск контент-плагинов (и flash-решето входит в их число) разрешен по умолчанию;
- «Настройки» > «Настройки контента» > «Плагины» > «Заправить разрешение на запуск контента плагинов»;
- Открываем эту ссылку и выключаем «Adobe Flash Player» (при необходимости посмотреть онлайн-кино придется ручками временно включить обратно, но зато HTML5 плееры будут сразу понимать что флеша нет и корректно запускаться);
- Доступ камере, микрофону и пр. лучше запретить по умолчанию;
- Всё те же «Настройки» > «Настройки контента» — самостоятельно запрещаем доступ ко всему, что не критично прямо сейчас;
- Обязательно запрети «Доступ к плагинам вне тестовой среды» и определение местоположения;
- Отправка «Do Not Track» отключена;
- Очень, очень сомневаюсь что кто-либо следует правилу не отслеживать тех, кто отправляет данный заголовок, поэтому реши самостоятельно — ставить его в «Настройки» > «Личные данные», или же нет;
- Пароли и формы сохраняются;
- «Настройки» > «Пароли и формы» — обязательно выключаем оба чекбокса. Пояснять причину, думаю, смысла нет;
- Браузер подвержен утечке IP адреса по средствам WebRTC;
- Ставим плагин WebRTC Leak Prevent, разрешаем ему работать в режиме «Инкогнито», в настройках его указываем «Disable non-proxied UDP»;
- Проверяемся, к примеру, на этой странице;
- Referer отправляется безконтрольно, что позволяет всем ресурсам определять откуда вы к ним пришли;
- Ставим Referer Control, в настройках указываем «Referer Control status» — «Active», а «Default referer for all other sites» — «Block»;
- Некоторые сайты (например — Habrastorage) используют провекру referer-а, поэтому работа плагина может немного «доставать», но надо это пересилить, и научиться писать регулярки исключений;
- Отсутствует контроль запуска JS-скриптов, которые занимаются трекингом и аналитикой;
- Ставим всем хорошо известный Ghostery, настраиваем на блокировку всего возможного;
- Любимые плагины для блокировки рекламы детектятся посещаемыми ресурсами и закрывают доступ к контенту;
- Попробуй использовать менее популярные, но не менее эффективные. uBlock до недавнего времени входил в этот список, но крайнее время использую Adguard AdBlocker, так как он пока ещё мало кем детектится и памяти потребляет в разы меньше чем собратья.
О том, какое расширение использовать для проксирования и где брать прокси-листы — ответить тебе придется самому. Скажу лишь то, что лучше всего — использовать цепочки прокси, но от этого в 9 из 10 случаев скорость серфинга просто дохнет. Публичные прокси-листы не живучие совсем. Те, что приобретались за кровные — чуть более живучие, но не значительно. Халявы тут вообще не много, и для комфорта лучше всего приобрести собственный прокси-сервер (да, такие услуги предоставляют, и довольно много кто; при оплате не используй реальные карты, имена, ip-адреса — разумеется). О том что предварительно весь внешний трафик следует пускать через туннели — я не напоминаю, ты и так всё знаешь.
Основные методы идентификации
Заранее прошу прощения за использованную ниже терминологию. Она не совсем корректна, но, как мне кажется — более проста для понимания
Идентификация пользователя, определение что эти N запросов выполнил именно он, а не кто-то другой — является главным врагом анонимизации. Методы идентификации делятся на как минимум два больших класса — использующих стороны клиента и сервера соответственно. На стороне клиента в классическом подходе она может выглядеть следующим образом:
- Страница ресурса содержит в своем теле ссылку на JS-скрипт, например — google.analytics;
- Браузер отправляет на сервер, который хранит этот самый JS-скрипт GET запрос;
- Сервер отвечает контентом скрипта;
- Браузер исполняет полученный скрипт (загружая дополнительные «модули» при необходимости), получает от браузера информацию о его версии, ОС, установленных плагинах, установленных шрифтах, разрешению экрана, локалях, системном времени, и прочей вкусной информации;
- Скрипт проверяет наличие уникальной плюшки, или устанавливет её для отслеживания ваших дальнейших перемещений в сети;
- Скрипт отправляет собранные данные + имя плюшки себе для хранения;
«Ну и чего такого?» — спросишь ты, и будешь чертовски прав. «Пускай собирают эти данные — мне не жалко!» — да-да, дружище! А пока ты так думаешь, давай немного займемся анализом. Для посещения сайтов ты использовал Google Chrome версии 52.0.2743.116 (версия актуальная — у тебя включено автообновление) под управлением Windows 10 (минорная версия подсказывает что, возможно, у тебя не установлены крайние обновления и, как следствие, отключен Windows Update) находясь в России и, предположительно, в городе Москва (и часовой пояс соответствует), с IP провайдера «MTC», у которого данный пул привязан к Люблинскому району, скорее всего используя ноутбук (судя по разрешению экрана), и наверняка интересующийся покупкой нового автомобиля (потому как до этого на сайте drom ты искал подержанную Мазду, и именно в Москве; на сайте drom, к примеру, стоит та-же аналитика). Судя по времени посещений — ты это делал с рабочего места и, наверное, в этом или соседнем районе и работаешь. Если твоя соц. сеть использует аналогичный сервис аналитики, то… То ты понял (пример вымышленный, но не лишенный зерна здравого смысла).
Понимаешь, почему довольно важно следить за тем, какие скрипты запускает твой браузер? «Да я вообще выключаю JS по умолчанию!» — воскликнет кто-то в комментариях, и будет прав — так правильнее. Именно правильнее, а не удобнее. Тут надо тебе всё-таки выбирать, что для тебя важнее — безопасность, или комфорт. Сейчас 7 из 10 сайтов просто не заработают как надо без JS, и только тебе решать когда переходить на telnet и переезжать в страну третьего мира, попутная скупая анонимные сим-карты. Ghostery хорош, но даже если он бы давал 99% гарантию блокировки всех средств аналитики — 1% всё равно имеет место быть. Тут не может быть универсального правила, надо просто быть бдительным и чуть-чуть думать своей головой.
Как происходит идентификация на стороне сервера? Давай вспомним как выглядят access-логи http-демонов:
[meow@hosting /var/log]$ cat somesite.org.access_log | tail -3
10.12.11.254 - - [25/Jul/2016:15:51:16 +0700] "GET / HTTP/1.0" 200 5768 "-" "Mozilla/5.0 (compatible; MJ12bot/v1.4.5; http://www.majestic12.co.uk/bot.php?+)"
10.12.11.254 - - [25/Jul/2016:15:57:38 +0700] "GET / HTTP/1.0" 200 5768 "-" "Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)"
10.12.11.254 - - [25/Jul/2016:19:19:25 +0700] "GET / HTTP/1.0" 200 5768 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0"Примитивнее. По-умолчанию сервер сохраняет о тебе 4 вещи:
- IP адрес, с которого пришел запрос;
- Время, когда он пришел;
- Какую страницу ты запросил;
- Какой у тебя User-Agent.
Грепнув логи по IP мы получим всех, кто мог прийти с твоего IP (если это IP на котором NAT — мы узнает кто из твоих соседей-абонентов ещё был). Грепнув же по User-Agent — мы получим почти наверняка именно конкретного пользователя. Плюс сможем посмотреть на какие страницы он ходил, в какое время и последовательности, а если есть дебаг-лог — то возможно и какие данные вводил на формах сайта, и какие плюшки у него в браузере.
Шеф, что делать?
Избежать утечек информации на 99.8% возможно —, но это очень неудобно в плане юзабилити. Если обобщить, то к самой критичной информации можно отнести твой IP (провайдер и местонахождение) и User-Agent (используемое ПО, ОС и их версии), так как они наиболее информативны и уникальны. Как скрыть реальный IP — мы уже говорили. Как скрыть User-Agent? Есть разные способы, и описанный ниже — просто один из многих. Возможно, именно он тебе покажется чуть удобнее.
С твоего позволения основные его «фишки» будут изложены в виде простого списка:
- Открытые исходники, доступные на GitHub (принимаю Pull-реквесты и включены Issues);
- Заменяет поле User-Agent в HTTP заголовках всех запросов;
- Компактное (меньше 190 Кб, треть из которых занимают два шрифта);
- Используемый User-Agent генерируется случайным образом, подобный определенным типам браузеров и ОС (настраивается; можно было бы использовать и один какой-то определенный, но этот подход работал бы лишь если очень много кто пользовался этим расширением — так бы пользователь «терялся» в куче);
- Автоматически подменяет User-Agent на случайный через заданный промежуток времени, по нажатию на кнопку, или при старте браузера;
- Умеет использовать заданный ручками User-Agent, а не использовать генерируемый;
- Настройки синхронизируются между браузерами (настраивается);
- Включает в себя поддержку защиты от определения User-Agent средствами JavaScript (экспериментально) — то, о чем так долго просили (mock запускается асинхронно, поэтому не во всех случаях успешно скрывает; на сколько мне известно — такого больше не умеет ни одно расширение — поправьте меня, если не прав);
- Поддерживает список исключений (возможно использование масок в адресах);
- На данный момент русская и английская локализации;
- Бесплатно и без рекламы;
- Лицензия WTFPL;)
Как выглядит?
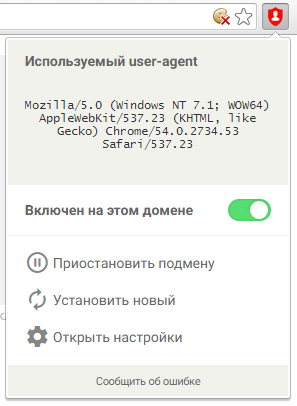
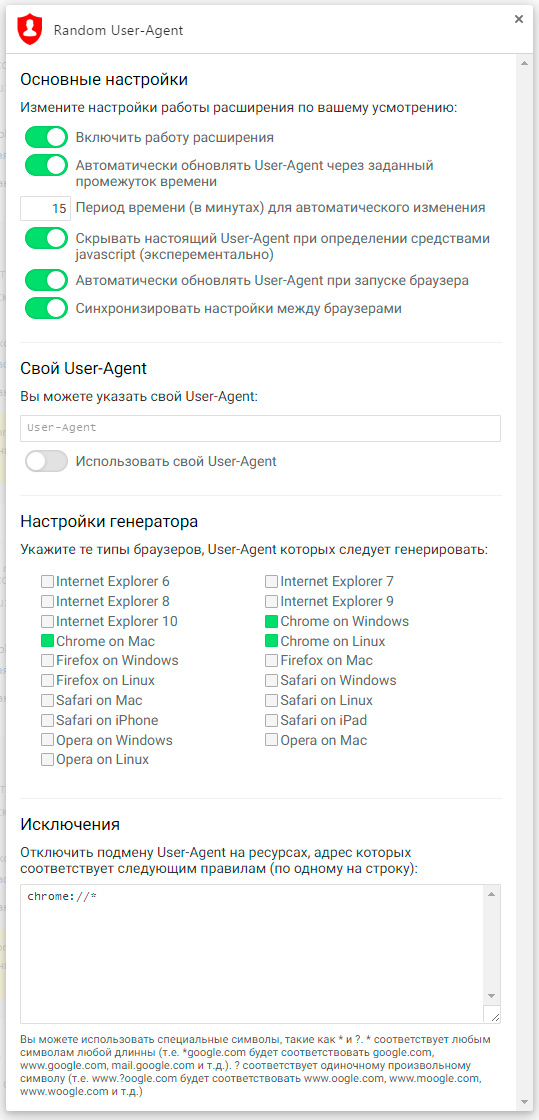
Если у вас есть вопрос, предложение или багрепорт, но вы не можете о нем написать ни в WebStore, ни в комментариях на хабре — вот вам волшебная ссылка. Хотел бы ещё написать и о том, как писал само расширение; как создал объект, который поддерживает события onGet и onSet произвольных свойств и сам хранит свои данные в хранилище; как пришел к решению реализовывать работу всех компонентов расширения с помощью своего, внутреннего API —, но это совсем другая история, и исходники, возможно, расскажут её лучше. Пользуясь случаем скажу что был бы чертовски признателен в помощи перевода расширения на языки, отличные от русского и английского. Если таковое желание имеет место быть — просто создайте Issue в репозитории с темой «Помогу с переводом на %имя_локали%».
Протестировать как работу плагина, так и свою анонимность ты можешь, например, по этим ссылкам. Но не стоит к результатам этих тестов относиться слишком серьезно.
И, с вашего позволения, продублирую ссылку на расширение Random User-Agent в WebStore.
Если встретите очепятки, грамматические или пунктуационные ошибки в тексте — пишите о них в личку, пожалуйста.
Комментарии (5)
 nazarpc
nazarpc
11 августа 2016 в 15:35
+1↑
↓
Мне вот что интересно: разве не более анонимно поставить самый популярный на сегодня User-Agent и не выделяться с толпы вместо того, чтобы постоянно менять его?
 cmepthuk
cmepthuk
11 августа 2016 в 15:45 (комментарий был изменён)
0↑
↓
Оба метода имеют право на жизнь но, мне кажется, что сопоставить разные IP и одинаковые User-Agent проще, нежели чем разные IP и разные User-Agent (если менять прокси, разумеется). Да и этот самый популярный User-Agent — он же изменяется с каждым обновлением браузера, который мы имитируем. Таким образом, скорее всего, придется его актуализировать при каждом минорном обновлении браузера, что довольно ресурсоемко.
Более того — расширение умеет использовать и заданный ручками User-Agent. Тут проблем нет.
-
nazarpc
11 августа 2016 в 15:51
0↑
↓
Как вы сопоставите разные IP с самым популярным User-Agent? Мне кажется, намного проще вычислить тех, кто во время сессии случайно меняет User-Agent, либо использует что-то вроде SeaMonkey вместо предпоследней стабильной версии Chrome или Firefox на Windows 7 или 10.
Не вижу принципиальных проблем в создании расширения, которое будет не рандомизировать, а периодически обновлять User-Agent на самый популярный в данный момент.
-
cmepthuk
11 августа 2016 в 15:54
0↑
↓
Пожалуй, это отличная идея. Я обязательно подумаю над её реализацией. А во время сессии User-Agent может и не меняться — достаточно указать ему обновляться только при запуске браузера. Или делать это строго по нажатию кнопки. Тут уже — строго как вам хочется.
-
nazarpc
11 августа 2016 в 15:59
0↑
↓
Это хорошо, но те же cookie можно сопоставить с изменяемым User-Agent при перезапуске (если они не чистятся при перезапуске, что достаточно неудобно), я бы предпочел не давать лишние биты информации в счётчик «подозрительности» пользователя. Лучше прикинуться самым обыкновенным среднестатистическим пользователем.
