Работа над ошибками. Правдивая история переезда на Sentry в масштабах большой продуктовой компании. Григорий Кошелев
Ошибки — это интересная штука, потому что даже в названии самого доклада есть двойное дно. Это работа над ошибками, которые мы допускаем в своем софте, в программах, сервисах. А также работа над ошибками — это создание pipeline, чтобы все это обработать, чтобы все в конце было хорошо.
Sentry — инструмент мониторинга исключений (exception), ошибок в ваших приложениях.

Работа над ошибками — это длинная история про то, как мы большой компанией переходили на Sentry. Этот переход у нас занял порядка двух лет. И маленький спойлер: этот переход еще не во всех местах завершен, но мы делаем работу над ошибками и вроде у нас все хорошо получается.

Давайте посмотрим ретроспективно на эти истории 2019–2020-года.
Начнем с того, как устроен у нас pipeline доставки логов и как он менялся во времени.

Если в прошлом году у нас было порядка 60 000 логов записей в секунду и суммарно 3 ТБ данных в сутки, то в этом году мы пробили потолок в 150 000 логов записей в секунду, а объем данных превышает порядка 6 ТБ за сутки.
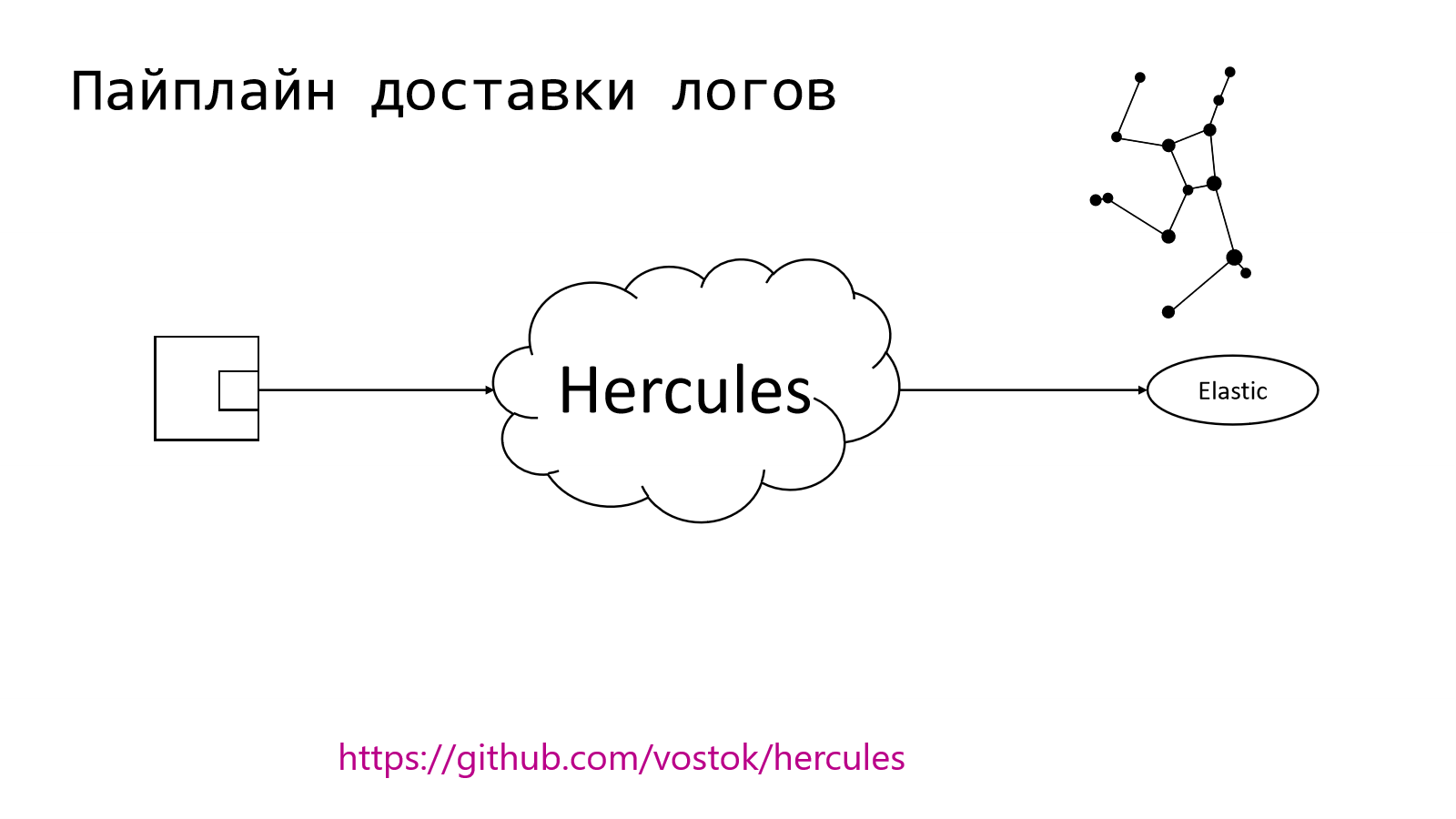
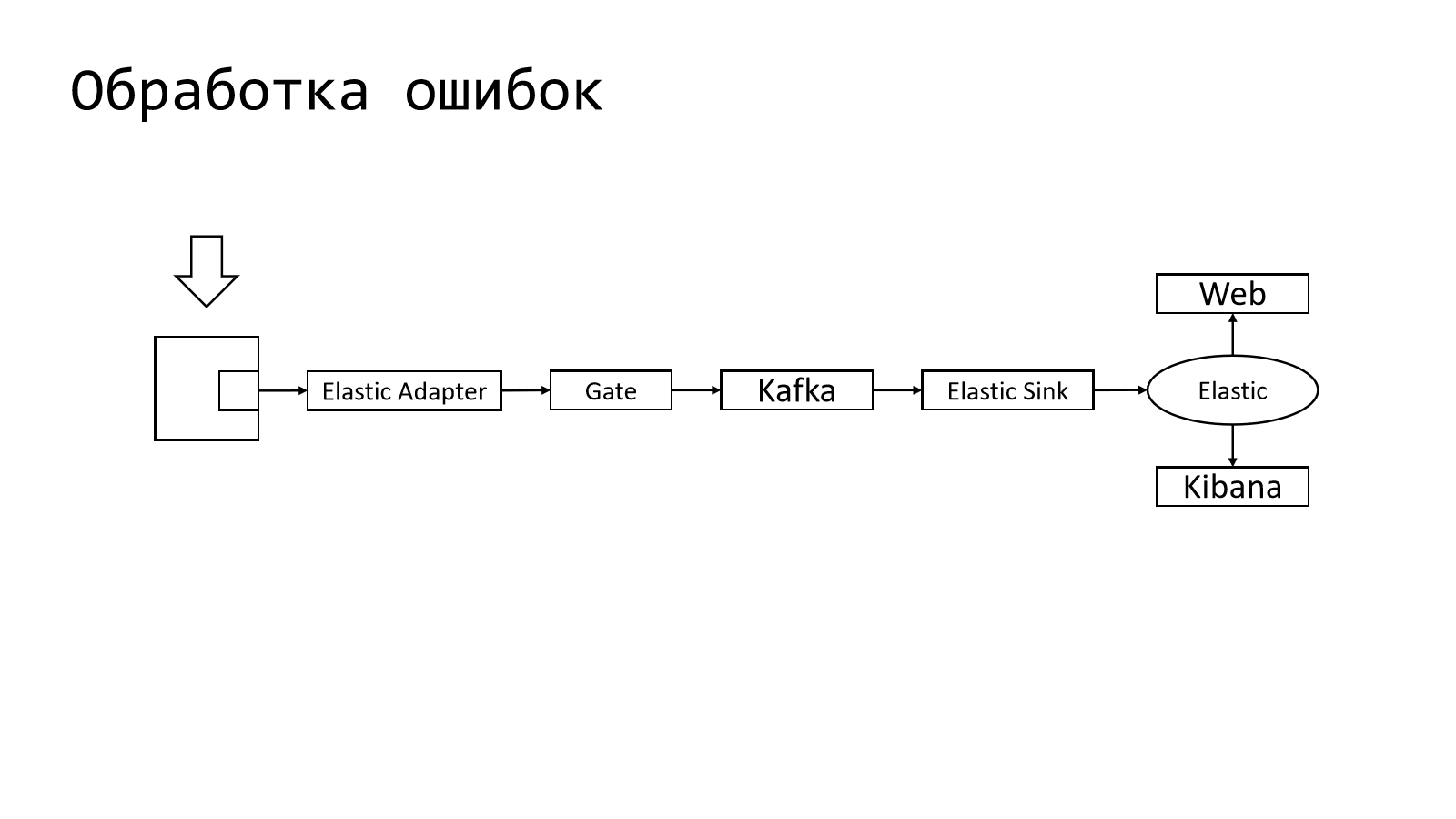
В целом pipeline устроен довольно просто. У нас есть некое приложение, есть микросервис, в котором есть компонент, который должен отправить лог записи куда-то дальше. Этим куда-то дальше на другом конце у нас является Elastic. Он является индустриальным стандартом. Многие его используют. Многие представляют, как его готовить.
Вопрос в том, как сделать передачу до Elastic. Это можно делать разными способами. Мы пошли своим путем. Мы сделали систему, которая занимается доставкой логов. Назвали ее Hercules. Эта штука в open source, поэтому можно будет пройти по ссылочке на GitHub и попробовать там потыкаться.
В правом верхнем углу — это то, как выглядит созвездие Hercules в нашем звездном небе.
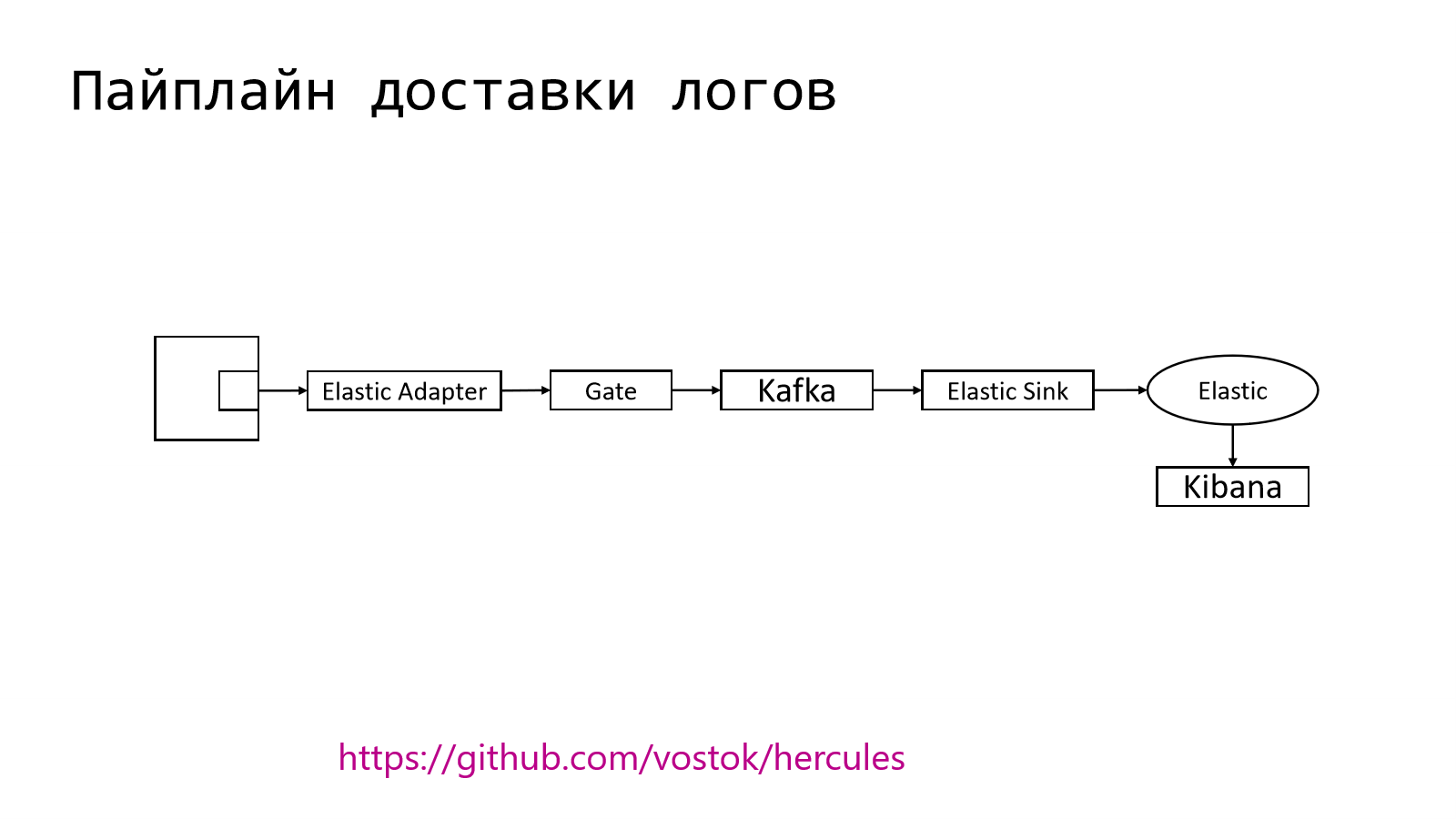
Pipeline внутри устроен следующим образом. Из приложения в специальный Elastic Adapter отправляется лог записи в том формате, в котором привык получать Elastic.
Дальше они перекладываются в специальный шлюз, который работает с Kafka. Kafka — это такая система, через которую можно очень много прокидывать событий. Дальше есть специальный daemon, который забирает логи из Kafka и складывает в Elastic.
Понятно, что Elastic мы используем не голый. Там рядом есть Kibana, которая позволяет эти логи ??? читать??? (наверное показывать).
В целом pipeline устроен таким образом. Почему столько компонентов и зачем так делать?
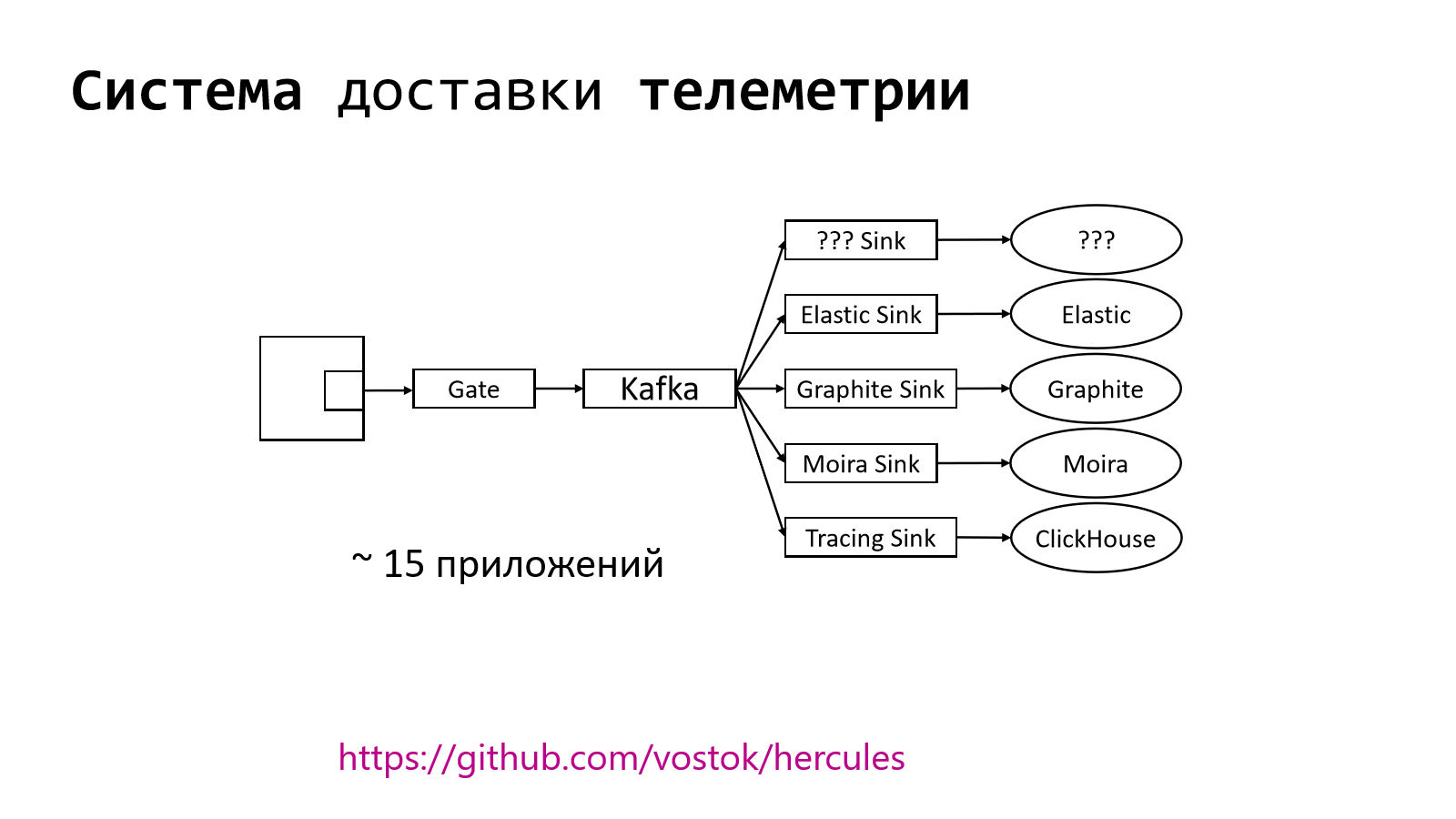
В действительности это не просто pipeline доставки логов, это целая система для надежной доставки телеметрии. У нас есть очень много различных daemons, которые умеют в разные типы телеметрии, т. е. это и логи, и метрики, и распределенные трассировки, и еще другие типы телеметрии. Всего там порядка 15 приложений.
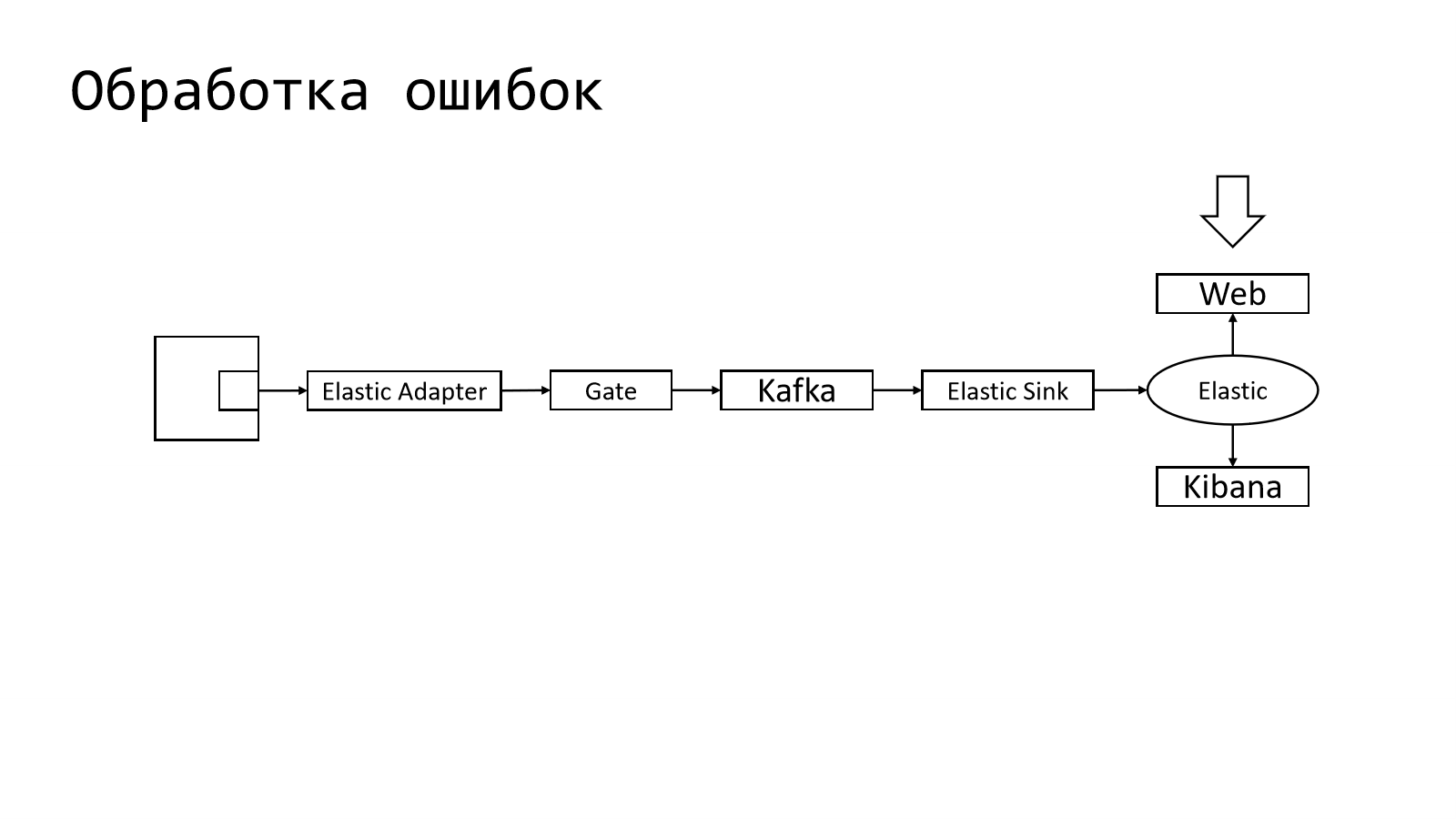
Где здесь обработка ошибок? И зачем она нужна?
Обработка ошибок — это, по сути, способ как-то понять, насколько хорошо наш сервис работает, какие ошибки у него возникают, как часто и т. д.
Раз у нас уже есть Elastic, то ничего не мешает нам эти данные забирать непосредственно из него. В Kibana нет удобных способов для агрегации, поэтому у нас когда-то был написан небольшой наколеночный Web, который позволял, используя данные Elastic, их вытаскивать и показывать в удобном для пользователя виде, т. е. конкретным индексом.

Какими фичами он обладал?
- Во-первых, он был не по всем ошибкам, а только там, где есть Exception с каким-то stacktrace.
- Чтобы группировать событие, там вычислялось специальное поле exc_stacktrace_hash, по которому можно было эти ошибки группировать.
- И в этом Web можно было еще отфильтровать ошибки, т. е. те, которые нам не очень интересны. Например, это какая-то незначимая ошибка в компоненте, который вообще не влияет на работу системы. И чтобы не видеть в общем списке эти ошибки, они отфильтровывались.
Оставалось только на клиентах доработать и вычислять hash, чтобы правильным образом их группировать.

Но у такого подхода есть существенный недостаток. Поскольку у нас единственное место, где мы группируем ошибки — это Web, т. е. serverless-приложение, то мы никакой статистики не имеем по ошибкам и не имеем никакого алертинга. А как мы узнаем чуть позже, эти вещи очень полезны.
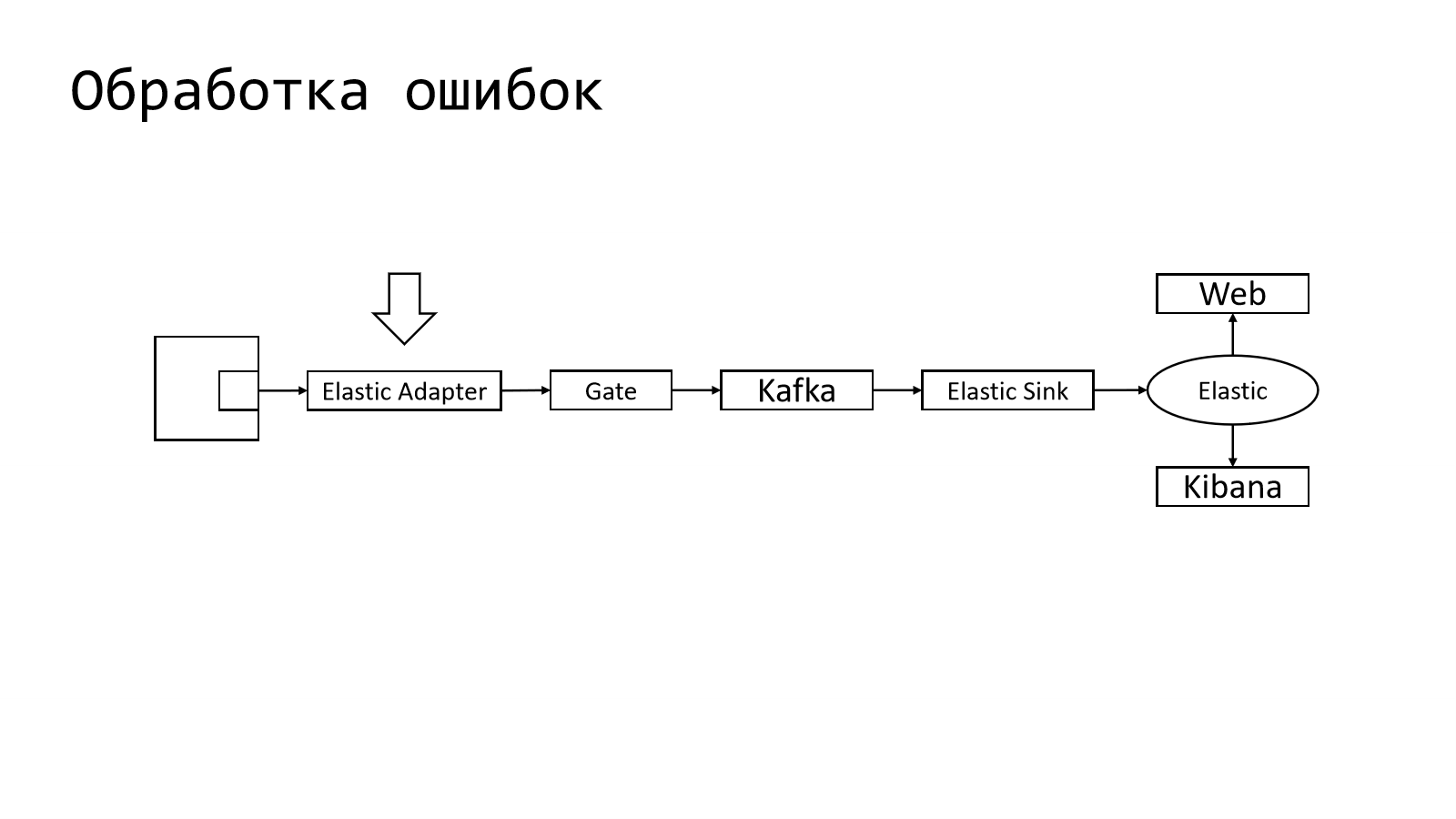
Что в таком pipeline сделать, чтобы это можно было завести?
Первое логичное место, куда можно было эту штуку вставить, это Elastic Adapter. И там это дело собирать.

Конкретно там можно сделать сбор метрик на какое-то общее количество, т. е. как часто они проявляются. Эту вещь можно там собрать.
При этом нам ничего не мешает настроить примитивный алертинг.
Например, мы можем отфильтровать ошибки по некоторым полям, т. е. по тем, которые действительно важны и по которым нужно уведомить пользователей.
А в качестве алертинга использовался email. Там раз в час можно было получить такой отчет.
Настройки фильтрации, а также что именно и как агрегировать — это тоже мы сделали в Web, чуть расширив его.

Как с этой штукой работали инженеры?
- Во-первых, дежурный мог зайти в почту и получить алерт об ошибках. И потом мог с ними разбираться. Это, может быть, не очень оперативный способ. Но это возможность в течение часа найти какую-то проблему и ее начинать исправлять.
- Во-вторых, чтобы не ждать этого часа, пока придет ошибка, использовался активный мониторинг.
В чем он заключался? Дежурный инженер, допустим, в момент релиза или в ближайшее время после него, или в течение дня смотрел глазками Web. Он смотрел, какие ошибки приходят. И если видел там какую-то аномалию, то начинал с этим что-то делать.
Такой активный мониторинг оказался хорошо применим для тестировщиков. Почему? Потому что у нас есть staging-окружение, на котором мы развернули нашу систему, погоняли какие-то тесты. И вроде бы все работает, но эти компоненты могут давать сбой. И как раз тестировщики могли просто зайти в такой мониторинг для staging-окружения, чтобы посмотреть, какие ошибки появились. И дальше они могли заводить дефекты, а потом улучшать софт.

Но в действительности не все так просто. И тут нам поможет аналитика факапов.
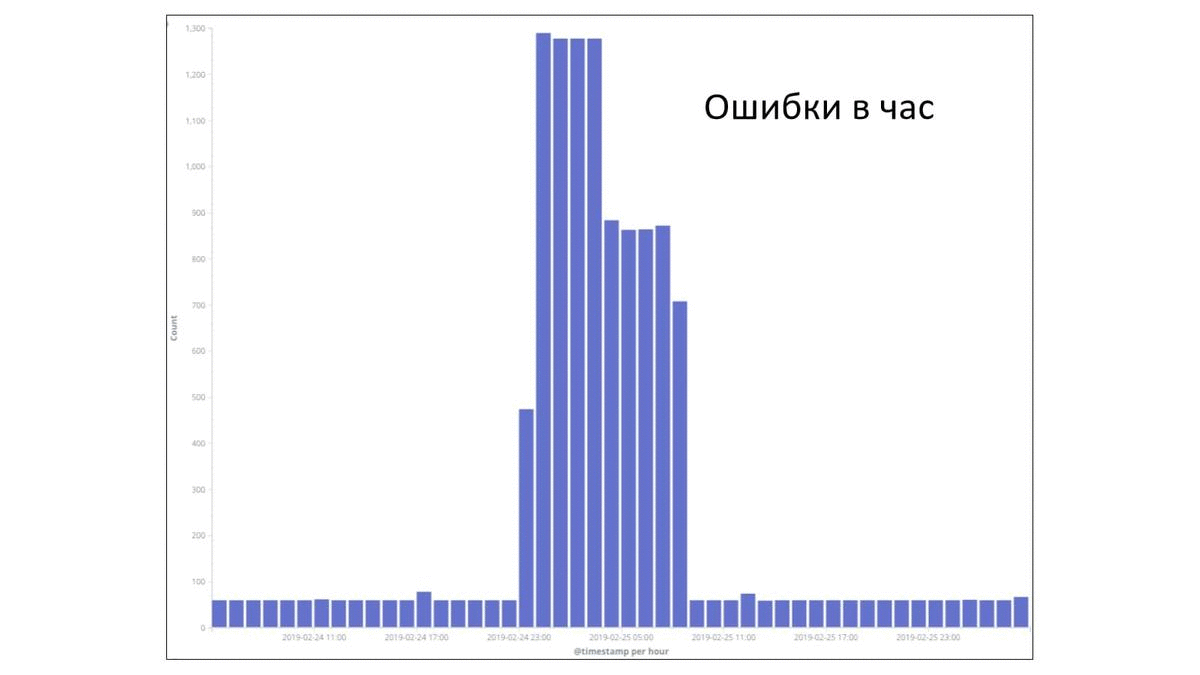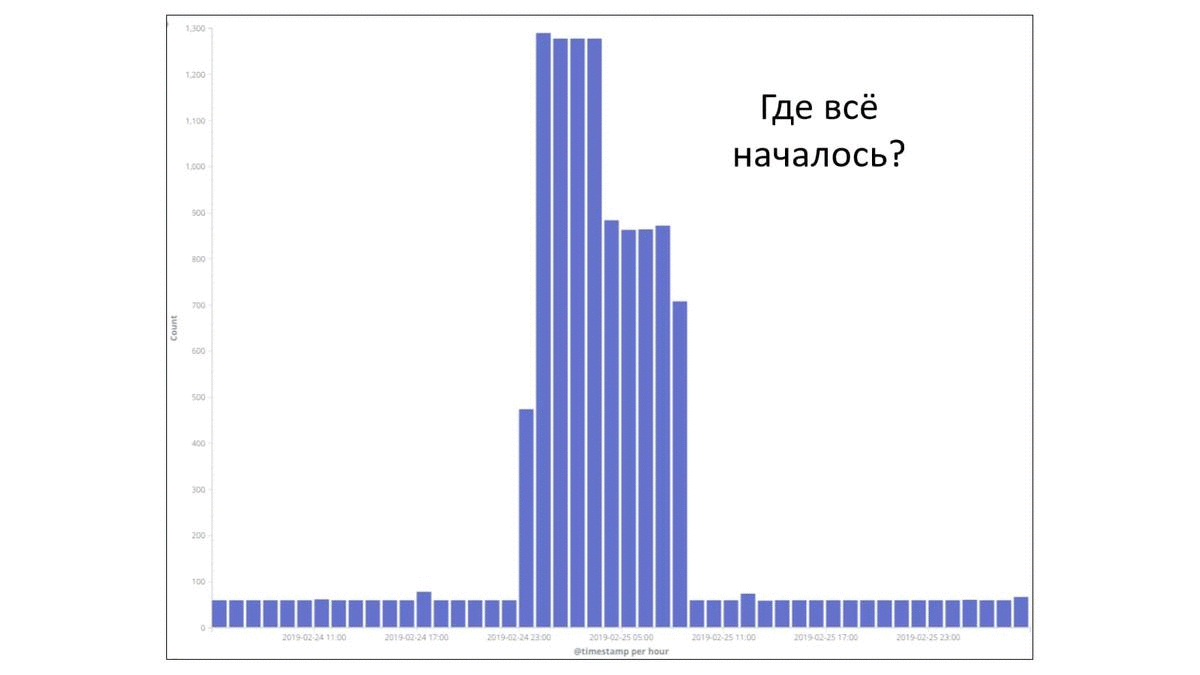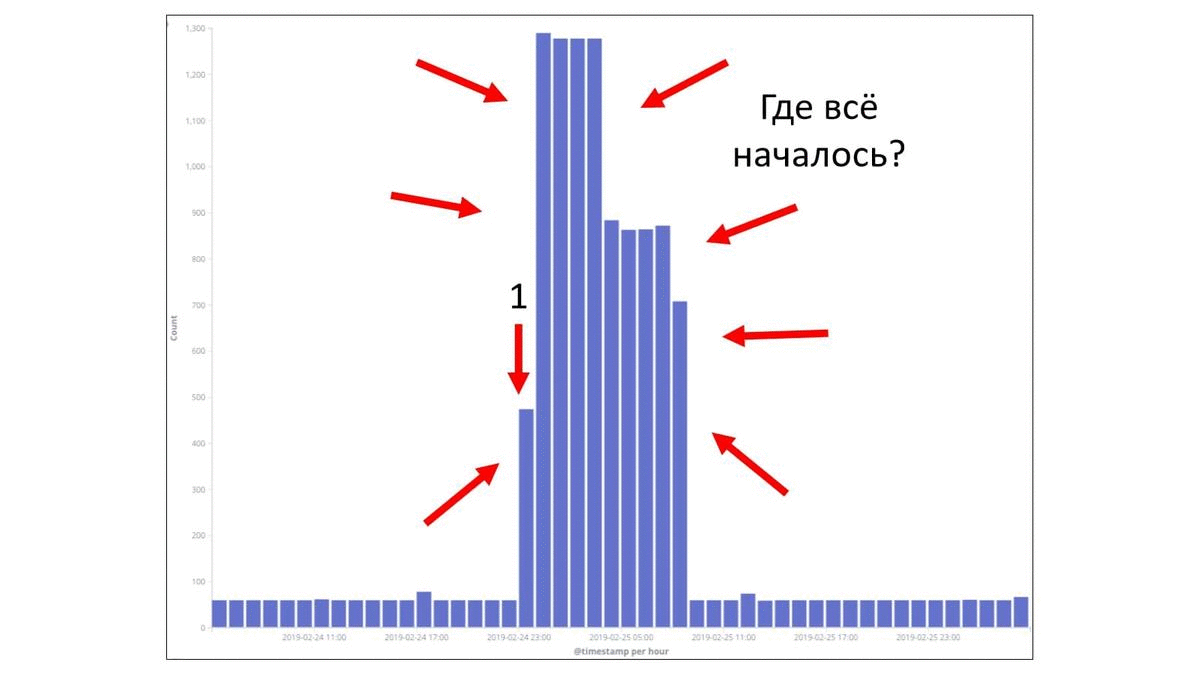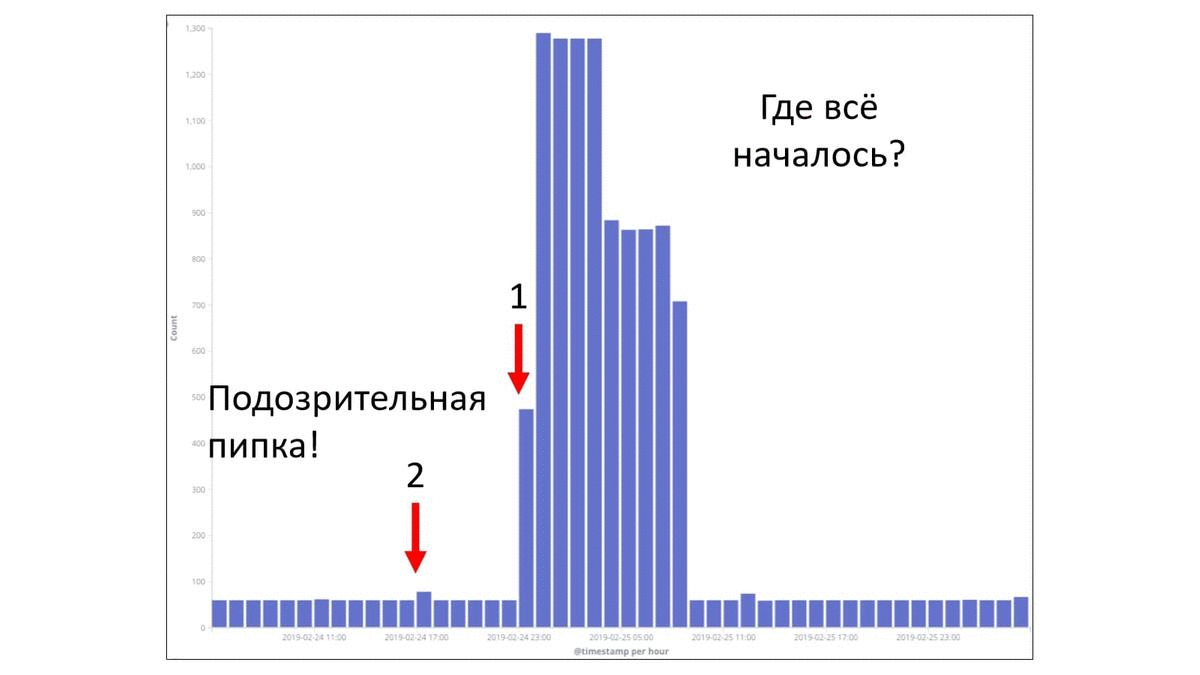
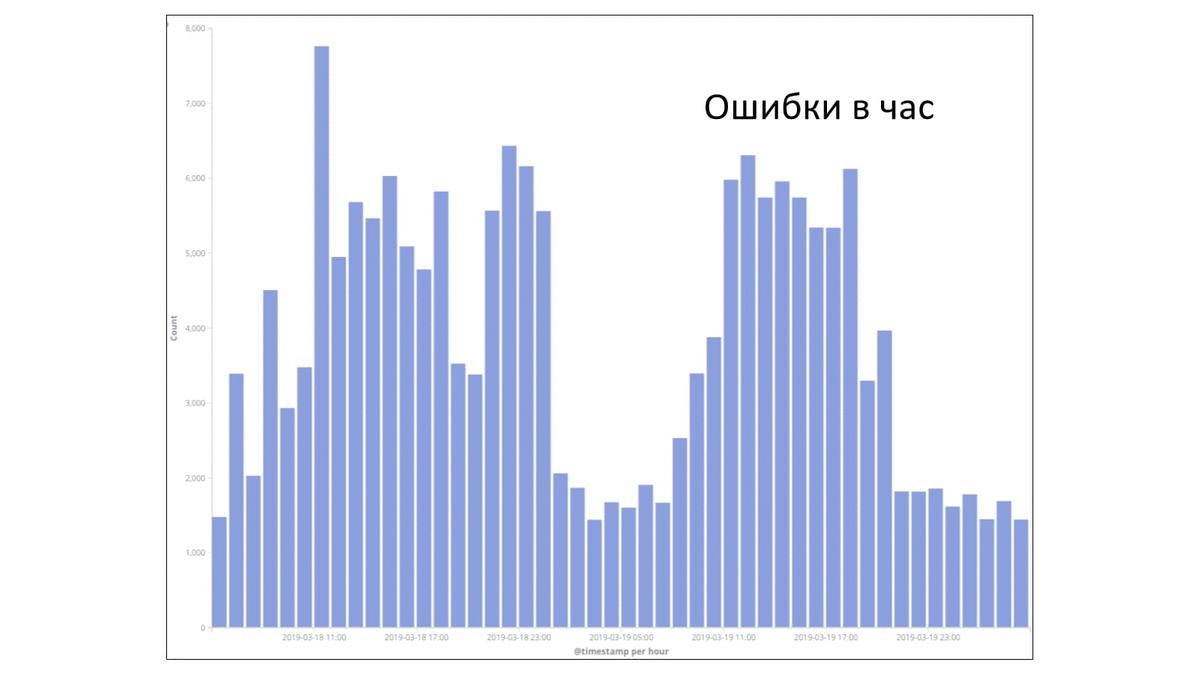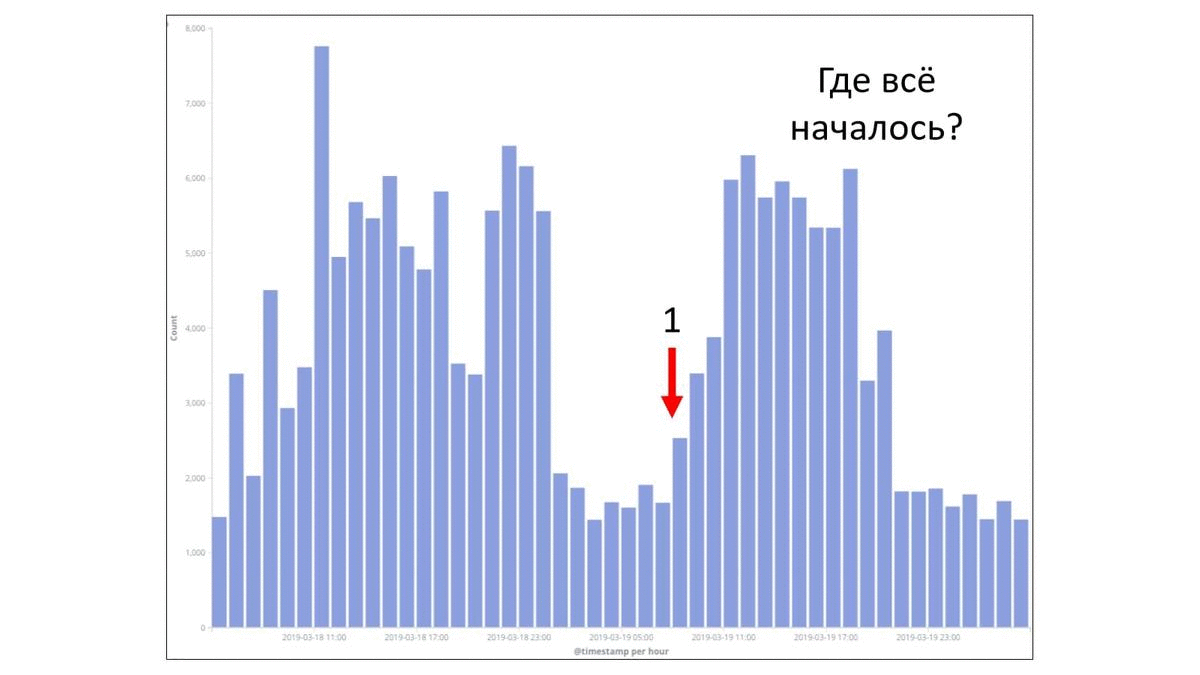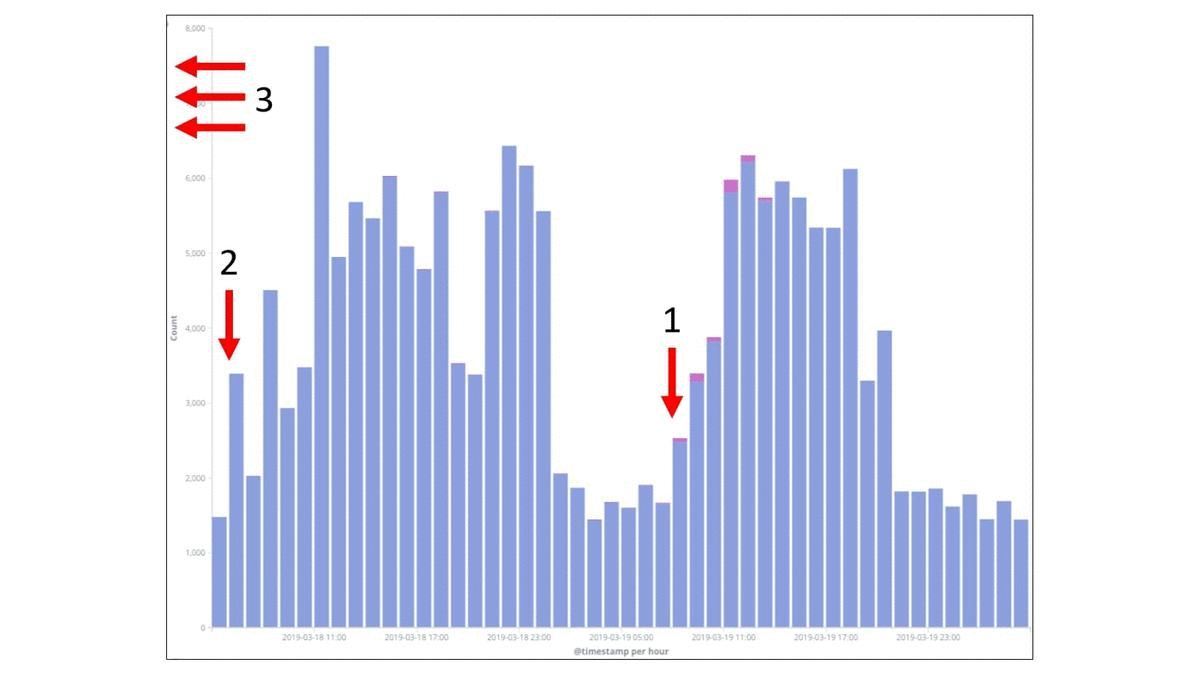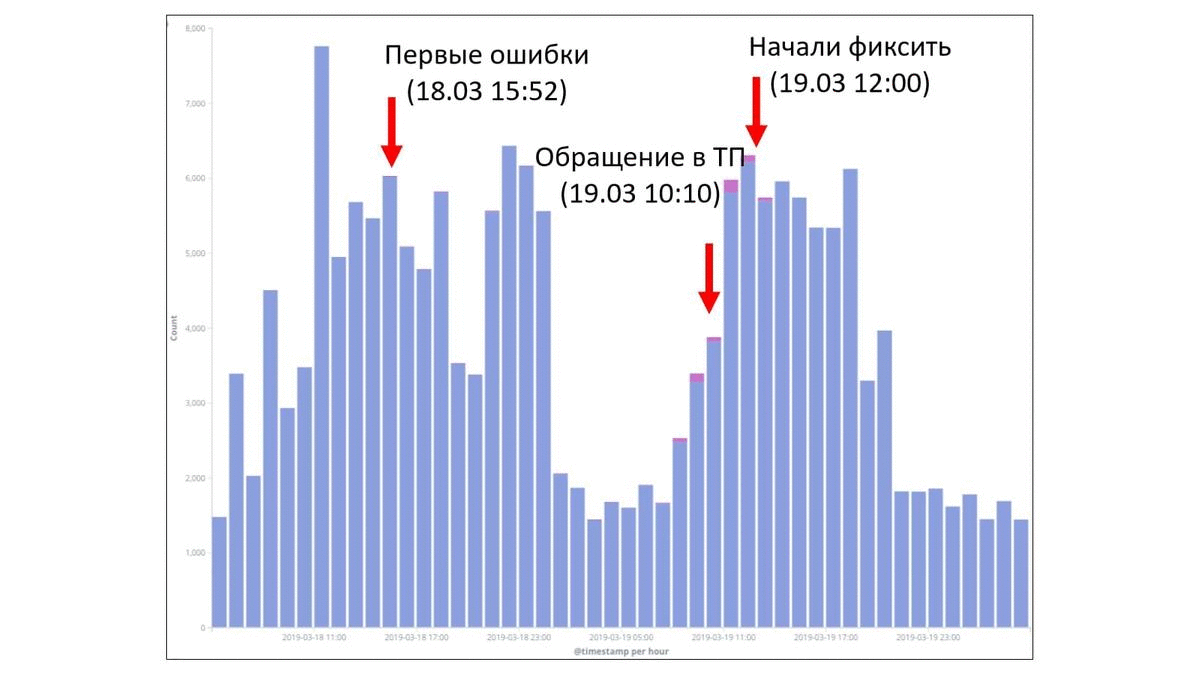
Есть у нас такая практика, когда мы собираем post mortem, и по ним делаем какие-то выводы. Для примера рассмотрим парочку факапов. Это реальные факапы, которые у нас были в компании в прошлом году в разных командах. В этом примере взят период времени — 2 суток. Каждый столбец — это ошибки в час. Видно, что потолок — 1 300 ошибок в час. И утверждается, что на этом графике есть период, когда произошел некий факап. Давайте попробуем понять, где все началось. Где-то с начала этого первого пика, потому что сложно не заметить вот этот всплеск. Но если присмотреться, то есть маленькая подозрительная пипка. И эта подозрительная пипка, может быть, тоже как-то относится к нашей проблеме. И если мы возьмем все наши логи и отфильтруем только по тем, которые действительно касались факапа, то мы получим такую картину:
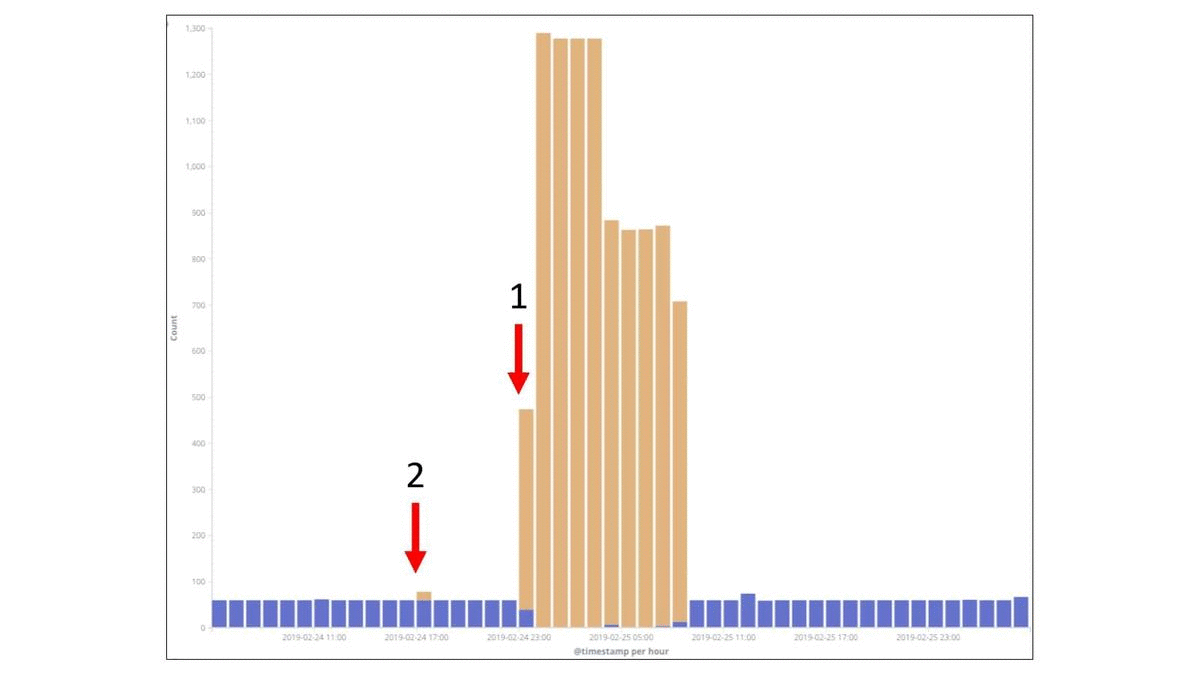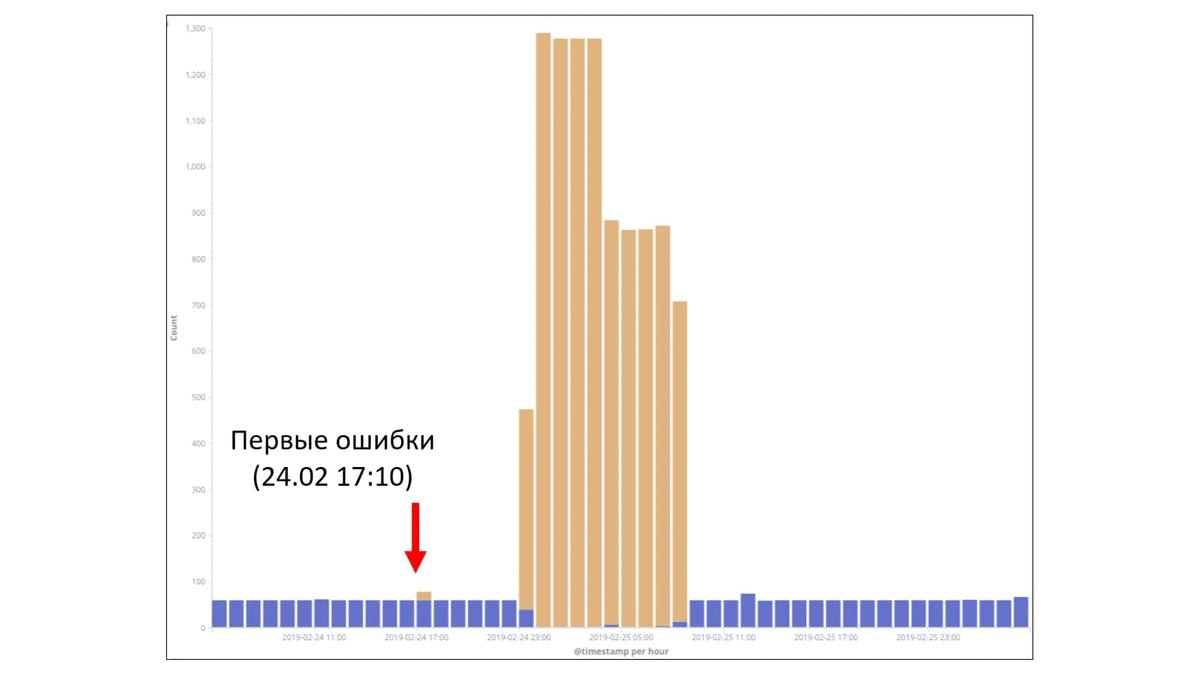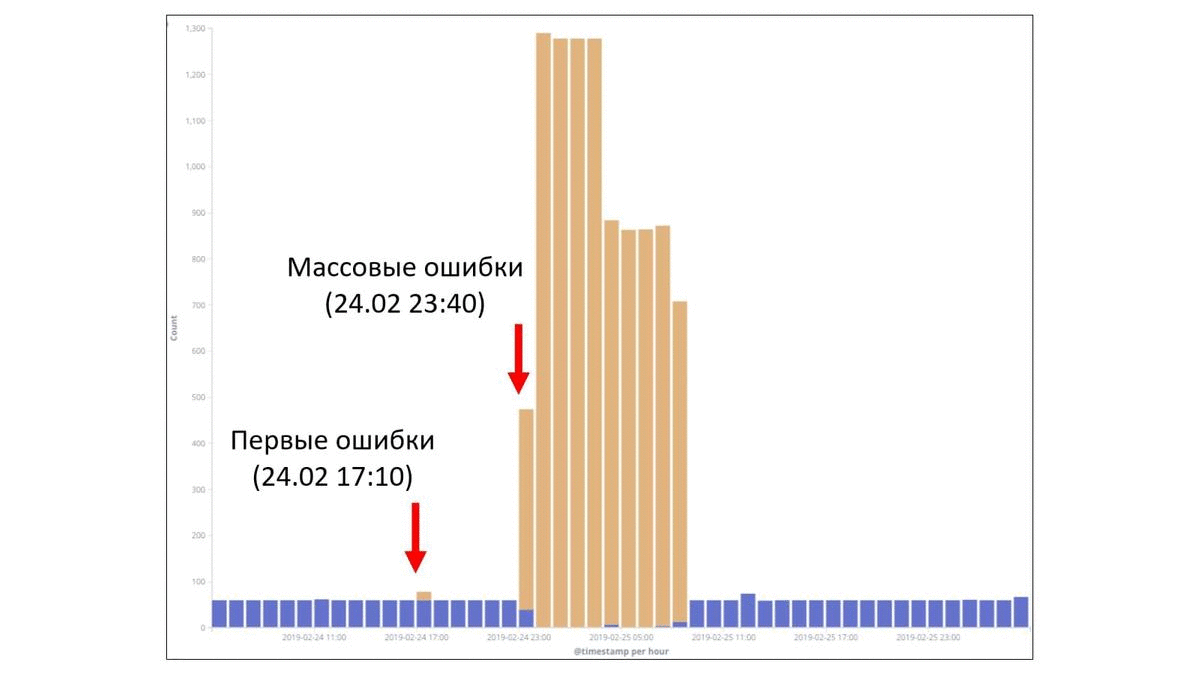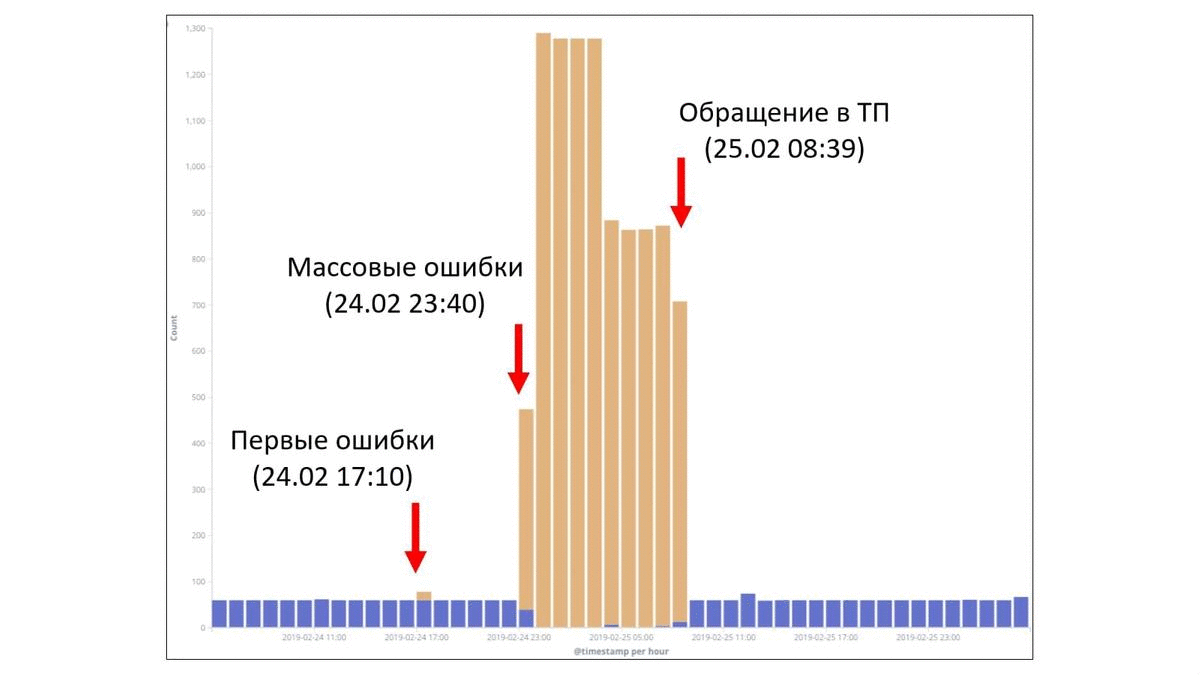
Вот этот маленький всплеск под цифрой 2 в действительности был связан с этим факапом. И это как раз первые ошибки, с которыми столкнулись наши пользователи. Это было вечером 24 февраля. Уже ближе к ночи начались массовые ошибки. И только уже под утро были обращения пользователей в техническую поддержку. И видно, что тут достаточно быстро все пофиксили путем отката и все стало хорошо.
В таком факапе можно было сказать, что когда вы что-то делаете, посмотрите на количество ошибок. Мониторьте активно и проблему решите. Вроде бы аргумент разумный и так можно сделать.
Но давайте посмотрим на другой пример. Это уже другая команда. У них произошел какой-то факап. Каждый столбик — это количество ошибок в час. Временной промежуток тоже 2 суток. И здесь потолок уже больше. Здесь до 8 000 ошибок в час доходило. Давайте попробуем понять, где все началось. Можно предположить, что перед вот этим вторым всплеском факап произошел. Но с другой стороны где-то вот здесь слева тоже ошибки в большом количестве возникали, стали столбики появляться. Может быть, ошибка тут. Кто-то, возможно, заподозрит, что что-то тут неладно. И на самом деле где-то в прошлом у ребят начались проблемы. Но если сейчас взять и попытаться посмотреть только те ошибки, которые относятся непосредственно к факапу, то можно заметить, что на несколько пикселей изменились какие-то столбики. Тут совсем не разглядеть. Но на самом деле первые ошибки начались вот здесь. В середине дня они начались. На следующий день были обращения в техническую поддержку. Там стали разбирались, в чем проблема. Через пару часов начали фиксить проблему. Быстро ее починили и все стало хорошо. Но в целом важно понимать, что примерно сутки какая-то часть сервиса была недоступна для пользователя.

https://habr.com/ru/company/ru_mts/blog/308044/
Что в этой ситуации делать? Я говорил про активный мониторинг. Можно обратиться к интернету и посмотреть, как такую проблему решают в других местах.
Вот это реальная фотография с блога одной крупной российской компании на Habr. Что мы здесь видим? Здесь достаточно много инженеров за мониторами. Они сидят и смотрят графики.
Но нужно понимать, что масштаб может измениться. Задач стало много. Много проектов, трафик большой, нагрузка большая. Логов, графиков, событий много. Что делать?

Наверное, нужно увеличивать количество инженеров и давать им еще больше мониторов. Если приглядеться, то можно посчитать количество мониторов. И можно заметить, что у одного инженера аж целых 12 мониторов.
И те, кто внимательно посмотрели первую картинку, заметили, что тот большой экран находится в конце этого open space. Т. е. огромное количество инженеров, которые только и делают, что сутками смотрят графики.
Вроде бы это решение.

Но если проанализировать факапы, которые мы собирали в течение года, то можно сделать вывод, что лишь имея алертинг по новым ошибкам, которые мы не видели раньше, можно избегать порядка 10–15% инцидентов. Это не то, чтобы быстро локализовать факап, а просто его избегать, т. е. он не случился бы вообще.
Понятно, что такая практика не возникнет сама по себе. Нужно использовать различные окружения типа staging, канареечный деплой и прочее. Но самое главное, что это действительно может помогать.

Подробней про то, какую аналитику факапов мы делаем и про культуру заполнения post mortem — это отсылка к докладу моего коллеги Леши Кирпичникова. Там он рассказывает, как мы к этому пришли и почему мы стали делать аналитики по факапам.
Миграция на Sentry
Давайте вернемся к нашей действительности, т. е. к тому, что нужно что-то менять. Тут, казалось бы, и должен появиться Sentry, который должен нас спасти.

Давайте для начала разберемся, почему именно Sentry, а не что-то другое. Самое главное, что Sentry — это тот инструмент, в котором есть алертинг по новым ошибкам. Эта та фича, которая нам была нужна. Вторая по списку, но не по значимости, вещь — это то, что можно делать инсталляцию Sentry на своем железе и не использовать cloud«ный Sentry. Почему это для нас важно? Об этом я расскажу чуть попозже.
Поскольку у нас компания очень большая, проектов очень много, их несколько десятков, некоторые команды идут в ногу со временем и находят свои инструменты. Были примеры в компании, когда отдельная команда начала использовать Sentry. Был положительный опыт. И вроде бы казалось, что у них меньше факапов происходит, что работа с ошибками действительно организовывается. И становится лучше жить не только инженеров, но и команде в целом. Поэтому мы решили взять Sentry и попробовать его на масштабах компании.
Но стоит понимать, что если мы берем какой-то инструмент, нужно его в плане инфраструктуры, которую мы хотим предлагать другим разработчикам, другим командам, суметь продать.
Для этого я как раз готовил демо.
Это демо показывается на примере реального факапа. Это один из факапов, который мы с вами сейчас разбирали. И нужно было закинуть все логи в наш pipeline и довести до Sentry и посмотреть, как все будет.
Давайте посмотрим коротенькое видео, как все работает. Видео начинается в 13.51
Получается, что есть какие-то ошибки, которые не относятся к текущему релизу. У нас релиз безошибочный. Здесь все хорошо. В целом у нас есть какие-то ошибки, которые трекались с предыдущих релизов, которые когда-то давно возникали. Их здесь можно смотреть.
Сейчас стало видно, что ошибок стало чуть-чуть побольше. Эти ошибки, которые мы закидываем, они как бы в реальном времени начинают наполняться-наполняться. И сейчас нам пришло уведомление от Sentry, что что-то пошло не так. На почту пришло сообщение, что вот такая-то у нас ошибка произошла. Даже можно посмотреть какой-то stacktrace. Но самое главное в том, что можно сразу из почты перейти в Sentry и увидеть эту ошибку. Можно увидеть контекст этой ошибки, т. е. что произошло.
Мы видим, что появился новый релиз. Пошли логи по новому релизу. И мы увидели ошибочку, которая в этот релиз попала. Эта та самая, которая здесь появилась. Ее можно с разных сторон найти. Это как раз та ошибка, которая самая последняя пришла.
В принципе, алерт получили. Это означает, что инженер уже не через сутки узнает о проблеме, а достаточно оперативно. Это будет зависеть от того, как мы настроим алерт в нашем инструменте. В данном случае он был настроен на 5 минут.

Мы решили использовать Sentry. Я уже говорил, что мы решили построить свой pipeline для логов. Но давайте поймем, почему бы не использовать Sentry SDK.
Есть библиотека, которую можно включить в приложение и с помощью нее сразу отправлять exception в Sentry. У такого подхода есть существенный недостаток. Самый первый — это то, что такой Sentry-клиент работает по модели fire-and-forget. Что это означает? Это означает, что он пытается отправить ошибку в Sentry. Если получилось, то она будет доставлена. Если что-то пошло где-то не по плану и где-то произошла ошибка, неважно на каком уровне, то мы эту информацию об ошибке потеряем.
Это звучит довольно неприятно, особенно, когда у нас инцидент или, например, вдруг Sentry не работает. Такой подход достаточно хрупкий.
Второй момент — это vendor lock. Если мы выбираем использование Sentry SDK, то это означает, что в каждый микросервис, в каждое наше приложение мы должны встроить библиотеку Sentry и ею пользоваться. Если вдруг нам что-то не понравится, а мы это делаем в масштабах компании, то это будет довольно неприятно. И заставлять разработчиков делать что-то другое — это плохо.
Почему это плохо? Заставлять людей что-то потом переделывать — это само по себе не очень. Кроме того, у нас таких микросервисов тысячи. У нас десятки команд. У каждой команды десятки микросервисов. В сумме накапливается в тысячу. И поменять для тысячи сервисов вот это не хотелось бы.
И самое главное, у нас есть под рукой труба, которая позволяет надежно доставку сделать. И вот эта вещь, которую надо сюда добавить. Эту проблему мы увидели не сразу, но она потом оказалась для нас очень существенной.
Когда команда использует SDK, то они напрямую отправляют в Sentry. И тогда мы не имеем никакого контроля со стороны инфраструктуры о том, что, кто и как отправляет в Sentry. А это очень важно.
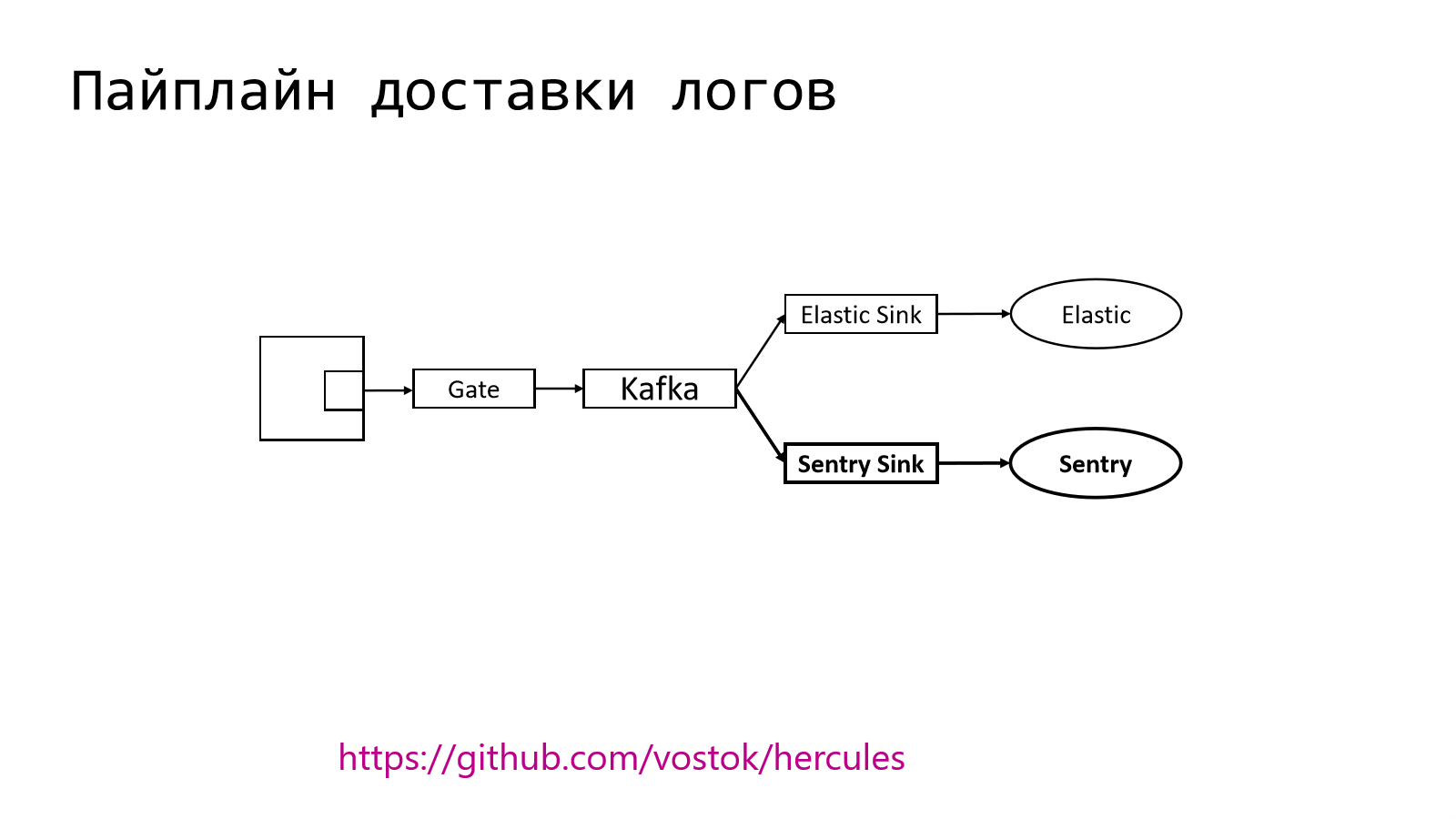
И тут глядя на эти причины понятно, зачем использовать ту трубу, которая у нас уже есть. И получить эти данные довольно просто. У нас уже есть pipeline, который отправляет данные в Elastic.
Нам просто нужно эти же самые данные перенаправить в другое русло и направить в Sentry.

Но, как вы понимаете, не все так просто, иначе этого доклада не было бы. С какими проблемами мы при этом сталкивались? Сталкивались с большим количеством проблем. Давайте разберем самые основные.
Первая — это группировка ошибок. Оказалось, что не все так просто с ней. Если в целом посмотреть, как устроена группировка ошибок в Sentry, то там есть несколько типов событий, которые туда попадают.
Если очень грубо, то есть 3 набора данных, по которым можно их группировать. Это:
- Stacktrace,
- Exception, т. е. тип exception, который возник,
- Message, т. е. тот message, который мы записали вместе с ошибкой.
Если со stacktrace все более-менее понятно, т. е. если 2 stacktraces совпадают, то, скорее всего, ошибка одна и ее можно сгруппировать. Тут вопросов нет.
Интересно, когда у нас есть message. Понятно, одинаковые messages будут группироваться в одну ошибку; messages разные, соответственно, группироваться не будут.

Давайте посмотрим пример реального лога записи. Этот message, который у нас слогировался в качестве ошибки. Что мы здесь видим? Здесь виден какой-то идентификатор. Сразу спойлер — это на самом деле префикс межсервисной трассировки. Здесь есть еще какое-то число, которое довольно уникальное между отдельными запросами. Есть еще какой-то идентификатор. Я понятия не имею, что это такое. Это взято из логов одной из команд.

Что с этим делать? В действительности эта строка будет всегда уникальной, потому что идентификатор трассировки меняется, внутренние идентификаторы добавляют команды к своим логам, тоже меняются.
На помощь нам приходит fingerprint. Это специальная технология, которая позволяет нам сказать, что у данной ошибки будет вот такой-то отпечаток и все ошибки, которые имеют такой же отпечаток, нужно сгруппировать.
Как его формировать? Достаточно взять и посчитать какой-нибудь hash, например, от шаблона нашего сообщения.
Если в лог записи вставлены все нужны значения, но поскольку мы используем структурированное логирование, то у нас есть шаблон, в который в какой-то момент подставляются нужные значения. А здесь мы сразу будем считать fingerprint целого шаблона. Это в целом решает эту проблему.

Вторая вещь, с которой мы столкнулись, это то, что ошибок в проектах может возникать внезапно довольно много.
И тут оказалось, что полезно сделать троттлинг и таким образом снизить пиковую нагрузку от проектов. А также изолировать таким образом влияние других проектов. А также влияние одних команд, которые пишут свои ошибки, от ошибок других команд.
Допустим, решили, что 500 ошибок — это мягкий троттлинг, который позволит срезать какие-то пики.

Но мы поняли, что мы ошиблись и этого недостаточно, потому что бывают «команды-плохиши», которым какой бы ты троттлинг не устанавливал, какую бы норму не делал, они все всегда будут в нее упираться. И это означает, что в Sentry будет приходить очень и очень много ошибок.
И 1 000 ошибок мы можем выдать в Sentry, а это не шутка, это реальность, с которой мы столкнулись. И это слишком много. Да, можно попотеть и попытаться домасштабировать Sentry до такой нагрузки, но, кажется, что здесь что-то не так и нужно фундаментально менять подход.
Ошибки: Хорошие, плохие, бесполезные
Поэтому здесь мы как раз поговорим о том, какие ошибки идут к нам.

Что такое ошибка в нашем pipeline? Это лог-запись с уровнем логирования ERROR или FATAL.
Но если хорошенько подумать, то окажется, что этот тезис, хоть он фактически соответствует действительности, но фундаментально он ошибочный.

И ошибка — это не то, что мы залогировали с каким-то уровнем, а это то событие, которое требует реакции инженера. Т. е. должен человек включиться, посмотреть, в чем проблема и начинать ее исправлять. В противном случае, это ошибкой считать не надо. Давайте посмотрим некоторые примеры, с которыми мы сталкивались.
Примеров таких уже довольно много. Самый типовой — это ошибка + успешный retry.

https://github.com/vostok/clusterclient.core/issues/7
В чем она заключается? Давайте попробуем посмотреть логи, которые у нас были в сервисе. Тут все логи, не только ошибки. Здесь сервис пытался сделать запрос по какому-то URL. А за этим URLстоит несколько сервисов. Он выбрал какую-то реплику. Сделал какой-то запрос и что-то не получилось. Закончился ошибкой. Но самое главное, сервис на этом не закончил свою работу. Он попытался отправить запрос на следующую реплику. И эта реплика вернула уже успешный ответ.
С одной стороны, ошибка у нас возникла, но мы сделали retry и все стало хорошо. Но тем не менее ошибка в лог упала. Соответственно, счетчик в Sentry сработал. И прилетит алерт разработчику. И он будет вынужден ночью просыпаться и разбираться с тем, что на самом деле и не нужно было делать.

Давайте посмотрим другой пример. Это реальные логи, которые вытащены из разных сервисов, из разных приложений у разных команд.
Отсутствуют необходимые права. Здесь сервис пытался сделать запрос на получение некоторого уведомления, но для конкретного пользователя он не смог этого сделать, потому что ему их нельзя показывать. У него 403 код ошибки.
Казалось бы, зачем здесь делать ошибку. У пользователя нет прав — это нормально. Почему бы нет?

Вот еще один пример из похожей серии — «протухла» сессия. В браузере сессия может «протухнуть». Например, пользователь может открыть ее в новой вкладке. Самое главное, что это вполне естественная ситуация для нашего приложения, когда вдруг token пользователя перестал быть действительным. Но тем не менее эта штука логировалась с уровнем error.

Давайте еще посмотрим пример. Это тоже довольно частая штука, когда что-то мы не нашли в каком-то кэше. В данном случае здесь был кэш организации. И в нем мы не смогли найти нужного абонента с каким-то идентификатором.
Что значит, что данные не нашли в кэше? Это значит, что мы в какой-то момент пойдем в другое хранилище. Из него, может быть, помедленней прочитаем данные, но в целом мы сможем эту ситуацию разрулить.

Каких ошибок может быть много? Например, ошибки валидации. Это ошибки пользовательских данных. Нам отправили что-то нехорошее. Мы поняли, что это что-то нехорошее, но зачем-то залогировали с уровней error.

Вот еще пример довольно хитрой ошибки. Не очень очевидно, почему не нужно логировать как error.
Давайте представим, что это у нас не один сервис, а некая цепочка сервисов. У нас есть API-сервис, куда приходят пользовательские запросы. Далее запрос направляется в backend. Из этого backend запрос идет, например, в storage service.

Предположим в storage-сервисе произошел отказ. Все, этот сервис не работает.

Соответственно, в цепочке, перед которым стоял сервис, он тоже не может адекватно обработать запрос пользователя. И тоже запрос завершается ошибкой.

Здесь целые 3 ошибки, хотя, казалось бы, что то, что есть проблема можно было понять по одному сервису.

И таких примеров разнообразных очень много.
Классификация (не)ошибок
И если попытаться их все классифицировать, то можно выделить следующие.

Первое — сервис самостоятельно «поборол» ошибку. Это то, что мы видели на примере непопадания в кэш, когда данные выпали из него, а также когда мы сделали успешный retry, т. е. это те вещи, когда сервис столкнулся с какой-то проблемой и сам с ней справился. Зачем будить разработчика, зачем его трогать, когда сервис самостоятельно может это разрулить?
Дальше — это часть сценария. Когда ошибка в сценарии — это нормальная ситуация. Например, то, что у пользователя нет прав или то, что валидация не проходит. Это нормальная ситуация. И в этой ситуации тоже нет смысла логировать это как ошибку.
И то, что чаще всего любят использовать инженеры, это то, что проблема не на нашей стороне. Например, два сервиса. Наш сервис работает. Мы делаем запрос к тому, который не работает и находится в зоне ответственности другой команды. У них проблема возникла, зачем нам просыпаться и реагировать на проблему, когда это должен делать кто-то другой? Это логично.

Но что в этой ситуации нужно делать? Если ошибки такие возникают, то понятно, что мы промахиваемся в кэш очень часто и об этом было бы неплохо узнать. Помогают в этом нам метрики.
Я бы сделал отсылку к двум методологиям. Это USE-методология и RED-методология. Обе эти методологии содержат метрики по ошибкам, которые позволяют нам понять по типам ошибок, по их частоте возникновения, по количеству. Эти метрики позволят нам как-то ретроспективно (не обязательно ночью вставать и чинить) посмотреть, в чем у нас конкретно проблемы, какие настройки надо потюнить и, может быть, исправить какие-то баги.
Возможно, когда у пользователя не оказалось прав — это просто баг в коде. Мы не должны были делать запрос, когда уже понятно, что у пользователя нет соответствующих прав. Это вопрос уже к тому, как написан код.

Хороший пример для цепочки микросервисов — это использование трассировок.
Трассировками у нас инструментированы все наши микросервисы. Они позволяют по идентификатору трассировки построить дерево запросов и понять, где проблема возникла.
Если у нас в каком-то месте есть ошибка, то мы информацию о ней можем потом собрать вместе и полный контекст построить. Этого будет достаточно.
Но как с такими не ошибками надо бороться?
Рефакторинг логирования
Бороться можно рефакторингом логирования. В чем он заключается?

Мы открываем наш репозиторий, ищем по нему вхождения, когда мы логировали с уровнем ERROR и меняем на WARNING там, где действительно есть смысл это сделать. Плюс такого подхода в том, что это очень быстро. Вы открыли кодовую базу, нашли все использования вашего логирования. Быстро пробежались. По контексту поняли — делать или нет.
Но здесь есть подводный камень. Качество кода при этом не изменится. Если у вас действительно был в коде баг, а вы его просто замаскировали под WARNING, то ничего не поменяется. Да, ошибок у вас будет меньше. Да, у вас меньше будут просыпаться инженеры по ночам, что хорошо, но качество кода не изменится, что несомненно плохо.

Поэтому есть более продвинутый способ. Я бы его назвал итеративным подходом. Он уже более нацелен на работу дежурного. Когда дежурный вступает на дежурство, ему на первое время доверяем такую задачу, как брать топ ошибок, смотреть, в чем их суть. Если это баги, то, соответственно, их исправлять. Если еще остались какие-то ошибки, то возвращаться в начало и продолжать-продолжать по этому циклу идти, пока не станет совсем хорошо. Плюс очевидный — это улучшение качества кода. Закрываем баги. Это здорово. Но есть существенный минус. Баги бывают сложными, баги бывают непростыми. И это очень медленный процесс, очень долгий путь нужно пройти. При этом надо понимать, что софт при этом продолжает у нас развиваться. С добавлением новых фич мы естественным путем добавляем новые баги. И нужно понимать, что такой путь может продолжаться до бесконечности. Особенно, когда есть хитрые баги, которые вроде и баги, а вроде и нет. И тут важно руководствоваться принципом Парето. Т. е. не пытаться сделать нулевой фон ошибок, но сделать его таким, чтобы жить стало комфортно.
Проблемы
Какие у таких подходов есть проблемы? На самом деле не все так просто, как может в начале показаться.
Проблемы: Ошибки в общих библиотеках и клиентах
Ошибки, которые возникают в нашем коде. Понятно, что поправили баги, поменяли уровень логирования. Все как бы здорово. Но что делать, если код находится в общих библиотеках и в общих клиентах?
Например, вы пользуетесь такой библиотекой и там залогировалась какая-то запись с уровнем error, но вставать ночью на алерт, который пришел, придется вам, а не автору этой библиотеки. И здесь вам нужно привести все свои доводы, чтобы разработчик сменил уровень логирования или что-то поправил. Каждый пытается решить эту проблему по своему.

Давайте посмотрим на примере, как это проявляется и почему, в некоторых ситуациях эти errors для прикладных разработчиков какого-то нашего продукта могут оказаться бесполезными. Это конкретный пример лога. Вот здесь у нас залогировалось как error. Подчеркиваю, что это код из общей библиотеки. И мы видим, то не смогли здесь прочитать какой-то кусочек. С каким-то идентификатором. Из какой-то тачки. Из какого-то дата-центра. С каким-то смещением. И вот почему это произошло. Потому что там 450 код ошибки. Нам, как разработчику, из этого всего полезно только время, когда произошла ошибка. Больше нам из этого ничего не извлечь. Если ERROR перейдет в WARNING, то этого нам будет достаточно.
Нам нужно смотреть на то, что реально влияет на наш прикладной код. Если у нас сервис не сломался, то все хорошо. Если у нас сервис сломался, то по идее логировать ошибку мы должны на своем уровне, на том, который нам будет понятен. Когда мы в алерте прочитаем, что случилось, тогда нам будет понятно, что нам делать. И не нужно будить в данном случае разработчика этой библиотеки или сервиса, к которому мы обращаемся и спрашивать: «Что здесь произошло? Что с этим дальше делать?».

Еще один пример на уровне взаимодействия команд. Если мы говорим про большую продуктовую команду, которая, может быть, поделена на подкоманды, или это взаимодействие на уровне разных проектов, т. е. когда взаимодействий очень много, то это означает, что какие-то сервисы, которые находятся в одной цепочке, находятся в зоне ответственности разных команд.
Теперь представьте ситуацию, что у этих команд разная культура, у них разные практики, у них разная развитость инструментов, которыми они пользуются. И несмотря на то, что мы какие-то общие инструменты предлагаем, все равно так или иначе команды отличаются в своей работе.
Например, вы пользуетесь чужим сервисом. У вас очень хорошо развиты инструменты. Вы очень быстро узнаете о всех проблемах. А у команды того сервиса, который вы используете, ничего этого нет. И это означает, что вы о проблемах будете узнавать раньше, чем ваши коллеги. И, соответственно, вся польза от этих инструментов сводится на нет. Потому что вам придется идти к другой команде и говорить: «Ребята, у вас есть проблема». Они: «Сейчас будем разбираться». И этот процесс может затянуться.
Поэтому очень здорово, когда уровень развитости этих инструментов и культура одинаковые. На практике такое, конечно, встречается очень редко, поэтому это нужно иметь в виду.
В этой истории есть еще и обратная сторона. Не только проблема в том, что мы раньше узнали о какой-то проблеме, а также в том, что какие-то разработчики позаботились о том, чтобы получить нужные алерты и понимать, что есть ошибка, а что нет, а другая команда может это по-разному интерпретировать.
Например, вы рассчитываете, что другой сервис будет работать и у него всегда будет возвращаться успешное выполнение какого-то запроса. А другая команда считает, что она может позволить себе довольно больш
