R как спасательный круг для системного администратора
Мотивом для этой публикации послужил доклад «Using the R Software for Log File Analysis» на конференции USENIX, который был обнаружен в интернете при поиске ответов на очередные вопросы. Поскольку была написана целая печатная статья, логично предположить, что тема обладает актуальность. Поэтому решил поделиться примерами решения подобного рода задач, решению которых не придавалось такого значения. Фактически, «заметки на полях».
R, действительно, очень хорошо подходит для подобных задач.
Является продолжением предыдущих публикаций.
Аналитика для Squid
Постановка задачи достаточно простая. Сетевому администратору необходимо оперативно знать, кто и сколько потребляют downlink трафика, какие сайты являются основными поглотителями и кто туда ходит. Большая история не нужна, нужен срез, максимум, за последнюю неделю. Эксперименты с различными опен-сорс анализаторами администратору радости не принесли (все чего-то не хватает).
Ок. Предоставляем к squid access.log файл свободный доступ по http, берем R и делаем интерактивное shiny приложение. К сожалению, специальный пакет webreadr на CRAN не заработал, но это не беда. tidyverse + руки решают задачку импорта в 5 строк. Для удобства публикуем полученное приложение на shiny free сервер.
3–4 часа работы и задача решена. Причем, с полноценным графическим UI, а не только хардкорной командной строкой. 2 кода экрана полностью решают существовавшую у администратора задачу.
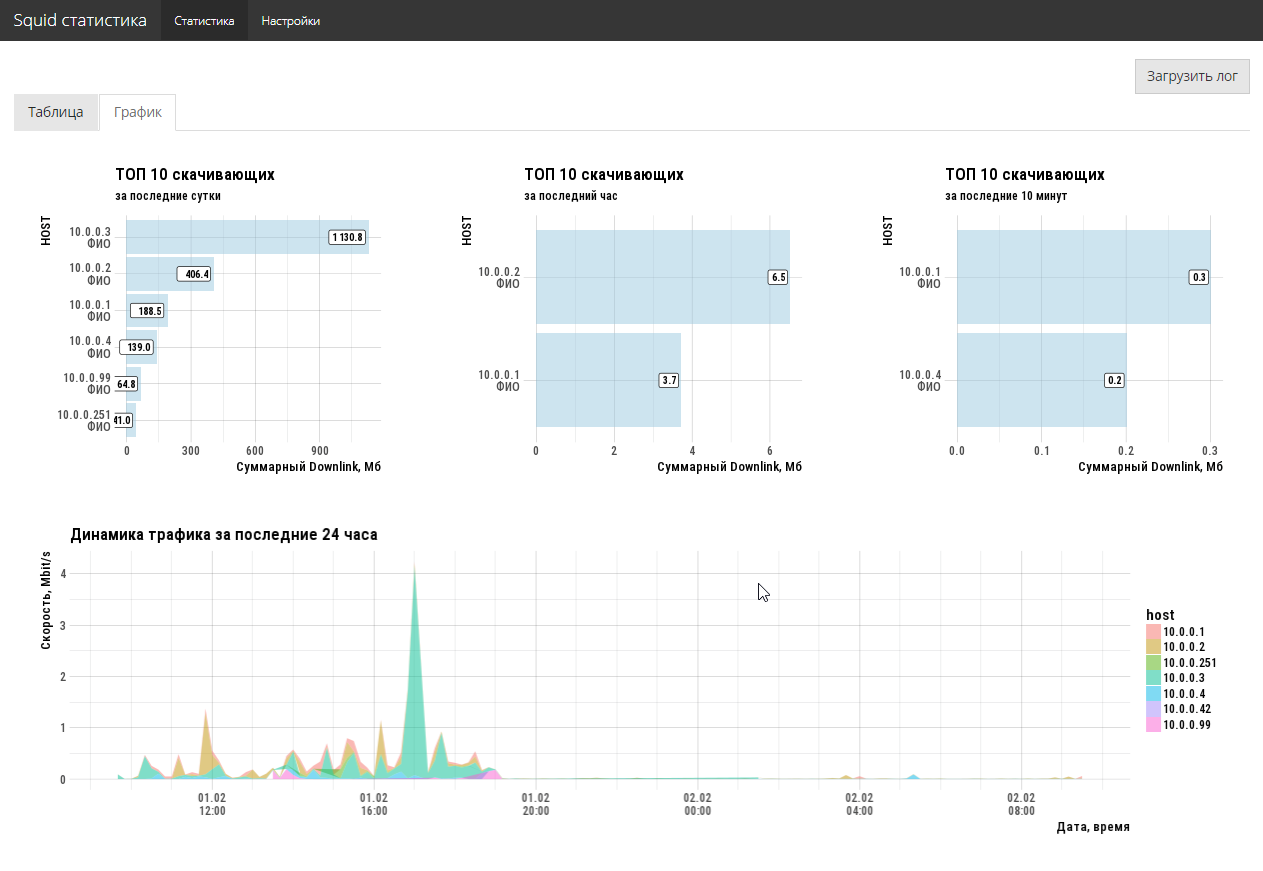
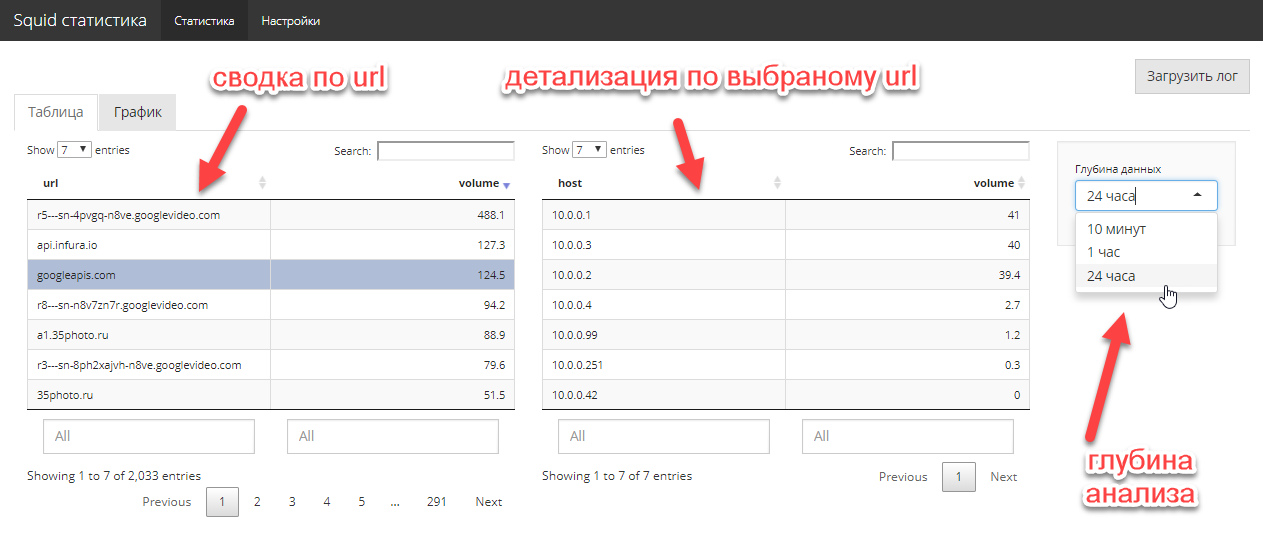
Код приложения здесь. Естественно, что код не оптимален, но и задачи такой не ставилось, надо было быстренько закрыть насущную проблему.
Аналитика кастомной Системы X
Задачка не стоила бы внимания, если бы несколько моментов:
- cистема X состоит из несколько компонент, которые пишут несколько различных видов лог-файлов;
- данные рассыпаны по нескольким десяткам тысяч файлов;
- вид лог-файла несколько далек от нормализованного вида и съесть его прямым потоком весьма затруднительно.
Фрагмент содержания одного из таких файлов (количество нод в общем виде может изменяться во времени):
2017-12-29 15:00:00;param_1;param_2;param_2;param_4;param_5;param_6;param_7;param_param_8;param_9;param_10;param_11;param_12
Node 1;20645;328;20308;651213;6258;644876;1926;714;1505;541713;75;541697
Node 2;1965;0;1967;89820;236;89605;419;242;396;27714;44;27620
2017-12-29 15:05:00;param_1;param_2;param_2;param_4;param_5;param_6;param_7;param_param_8;param_9;param_10;param_11;param_12
Node 1;20334;1039;19327;590983;2895;588234;1916;3673;1507;498059;347;497720
Node 2;1701;0;1701;89685;259;89417;490;424;419;26013;93;25967Наверное, автор подобного формата лог-файла руководствовался высокими мотивами, но вот анализировать на компьютере штатными инструментами подобное творчество крайне проблематично.
Но это не страшно, когда в руках есть R. Разбираться в мотивах и писать хитрый парсер на регулярках лень и некогда, используем лом data science. Тупо грузим все сырьем и используем инструменты tidyverse для срезания\трансформации. Всех делов на два экрана кода и пару часов работы (проанализировать, подумать, загрузить, нарисовать графики, сделать выводы).
loadMainData <- function(){
flist <- dir(path="./data/", pattern="stats_component1_.*[.]csv", full.names=TRUE)
raw_df <- flist %>%
purrr::map_dfr(read_delim, col_names=FALSE,
col_types=stri_flatten(rep("c", 13)),
delim=";", .id=NULL)
df0 <- raw_df %>%
# строка с датой и параметрами начинает новую запись
mutate(tms=ifelse(X2=="param_1", X1, NA)) %>%
fill(tms, .direction="down")
# вытащим первую строку в качестве имен
data_names <- df0 %>%
slice(1) %>%
unlist(., use.names=FALSE)
df1 <- df0 %>%
# проверили, что каждую первую в тройке можно выкинуть,
# но, в общем виде, лучше маркировать мусор по содержанию
purrr::set_names(c("node", data_names[2:13], "tms")) %>%
mutate(idx=row_number() %% 3) %>%
filter(idx!=1)
df2 <- df1 %>%
mutate(timestamp=anytime(tms, tz="Europe/Moscow", asUTC=FALSE)) %>%
mutate_at(vars(-node, -timestamp), as.numeric) %>%
select(-tms, -idx) %>%
select(timestamp, node, everything())
main_df <- df2 %>%
tidyr::gather(key="key", value="value", -timestamp, -node)
main_df
}На выходе получаем такую картинку (явно виден разбаланс системы), по которой инженер уже конкретно начинает разбираться с Системой X.
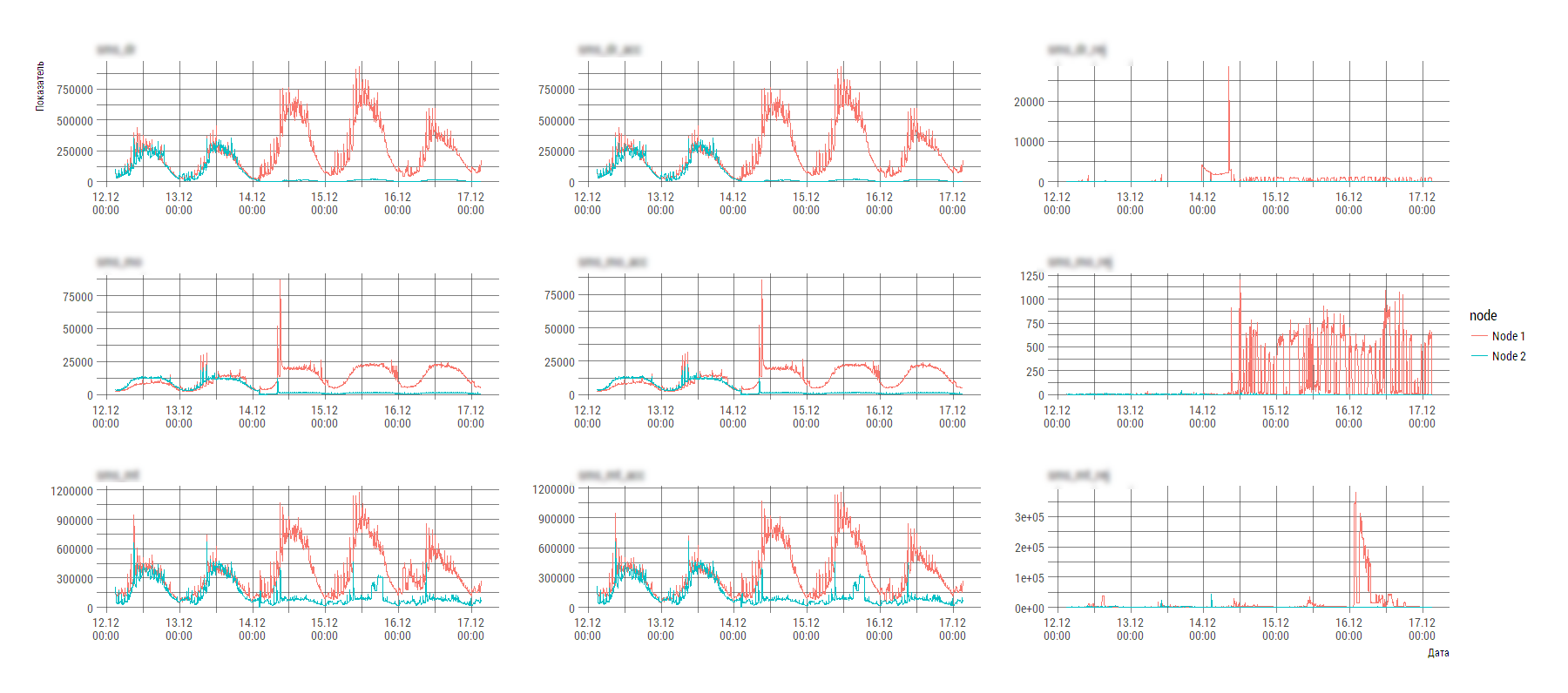
P.S. Техника нынче пошла такая, что можно пренебречь оптимизацией времени исполнения на этапе первичной разработки. Для работы с лог файлами с совокупным объемом несколько гиг вполне достаточно ноутбука с оперативкой от 8Гб и запастись одной-двумя минутами на процессинг, анализ и рисование.
Предыдущая публикация — «HR-аналитика» средствами R.
