QA на проде. Почему это круто
Многие считают тестирование на production окружении вредной практикой: оно не помогает предотвратить попадание проблем к конечным пользователям, а больше констатирует их наличие. Кроме этого, тестировщик отрывается от стандартного рабочего процесса и методик, применяемых на тестовом окружении. Меня зовут Оля Михальчук, я QA-инженер в финтех-компании ID Finance. В этом посте я расскажу почему тестирование на проде может существенно помочь вашему проекту.

Зачем нужно QA на проде, если есть пре-продакшн окружение
В процессе разработки ПО всегда есть несколько окружений, на которых развёрнуто приложение. Среда, которой пользуются конечные пользователи, как вы знаете, называется production. Обычно предполагается, что тестирование нужно проводить на отдельном окружении, чаще на QA environment или Staging (пре-прод), чтобы предотвратить попадание ошибок к пользователям. Но есть такая методика, как QA на проде, которая отлично помогает решить задачи, которые на тестовом окружении решить физически невозможно.
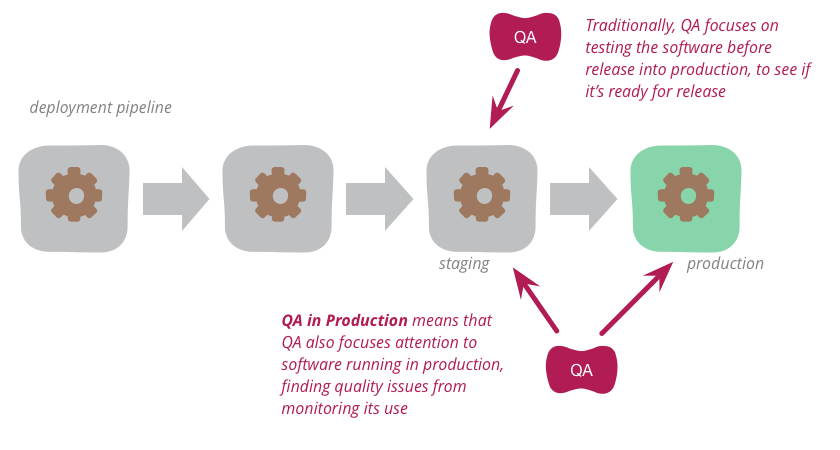
В каких задачах помогает QA на проде
1. Проблема различия Staging и Production окружений.
Staging часто считают копией продакшн среды, которая недоступна конечным пользователям, но максимально схожа с боевой средой. Когда приложение достаточно сложное, синхронизация и поддержание такой мини-копии становится трудоёмкой и не всегда рациональной задачей.
Например, на нашем проекте пре-прод используется больше для функционального тестирования на сделанных вручную тестовых сценариях. Он не обладает техническими ресурсами, сравнимыми с продакшн средой. Также мы обычно не делаем полную синхронизацию конфигураций и БД с продакшн средой, что никак не мешает проводить функциональные тесты. Почему мы не копируем прод среду? Представьте, сколько ресурсов бы ушло, чтобы создать копию, допустим, Facebook, с такими же супермощными серверами, сервисами, базой данных и конфигурациями как на production. Это фактически как развернуть ещё одно такое же приложение.
Кроме того, при интеграции со сторонними сервисами вы всегда имеете разные настройки для тестового и боевого окружения (то же самое API). Я не утверждаю, что тестовая и staging среды бессмысленны. Просто нельзя на 100% гарантировать, что при успешном прохождении определённых тестов на одной среде сервисы не упадут на другой. Помочь в решении этой проблемы как раз и может дополнительное тестирование на production.
2. Реальные уровни многозадачности и нагрузки.
Некоторые ошибки можно обнаружить только под продолжительным и реальным уровнем многозадачности и нагрузки. Это касается утечек памяти, стабильности, быстродействия и устойчивости системы. Например, у нас была ситуация, когда возникла проблема быстродействия системы из-за того, что две ресурсоемкие задачи выполнялись в один промежуток времени. Разработчики оптимизировали работу задач, команда сделала тесты на пре-прод окружении, изменения доставили, затем сделали проверку на production.
3. Ошибки развёртывания
Из определения развёртывание (deployment) — это установка рабочей группой новой версии программного кода сервиса в инфраструктуру продакшна. Соответственно лучший способ увидеть ошибки развёртывания — это тестирование в процессе самого развёртывания.
4. Недостаток мониторинга на пре-проде
Один из лучших и незаменимых способов контроля того, что приложение работает так, как мы ожидаем — это ведение мониторинга по определённым метрикам. Например, из простых и наиболее критичных примеров: ведение мониторинга на количество регистраций новых пользователей в час, на конверсию от одного целевого действия к другому, на количество выданных кредитов. Конечно, такой мониторинг имеет смысл только на боевом окружении.
5. Возможность анализа сценариев использования системы, которые осуществляют конечные пользователи
Продакшн — кладезь тест-кейсов для тестировщика. При возможности у тестировщика видеть и обрабатывать сценарии, которыми пользуются конечные пользователи, тестировщик может выявить наиболее критичные сценарии, или выяснить причину появившегося дефекта, или обратить внимание на нетривиальные кейсы при тестировании на пре-проде.
6. Возможность ведения более достоверной статистики и метрик качества ПО.
Например, количество ошибок в логах приложения или компонента, баг-репорты и другая отчётность, которую может делать прод-тестировщик, более реально демонстрирует качество ПО по сравнению с теми же отчётами из тестового окружения.
7. Всегда лучше, если ошибку на проде заметит «свой» тестировщик, чем конечный пользователь.
Обычно после доставки задачи тестировщик делает базовые проверки новой или изменившейся функциональности на проде. Кроме того у нас в компании есть отдельно выделенный человек — тестировщик на проде. Хочу ещё раз отметить, что я не позиционирую QA на проде как замену тестированию на пре-продакшне, и, конечно предотвращать появление багов и проводить превентивные меры обязательно нужно. Но такое тестирование может стать отличной дополнительной техникой в процессе обеспечения качества на вашем проекте.

Полезные практики QA на production, которые эффективно работают у нас на проекте
1. Проверка доставленных задач с целью убедиться, что они хорошо задеплоились и работают на новом окружении.
Например, когда мы вводим интеграцию с новым партнёром, кроме тестов на пре-проде мы обязательно проверяем интеграцию после доставки, т.к существуют очень много настроек, зависящих от среды (API, урлы, компоненты). Также имеют место 3rd party issues — ошибки не на нашей стороне, а на стороне интегрируемых сервисов.
2. Логирование и аудит.
Хорошее логирование помогает разработчикам и тестировщикам заметить проблему ещё до того, как о ней догадается конечный пользователь, а также заметить места, нуждающиеся в оптимизации. Аудит действий и изменений позволяет всегда без проблем выяснить причины того или иного поведения. Например, если компонент кредитной политики не может выдать решение по кредиту, для анализа, почему это произошло, мы в первую очередь обращаемся к логам. Этот пункт касается как prodcution, так и pre-production сред.
3. Мониторинг и система оповещений
Как я упоминала выше, ведение мониторинга по определённым метрикам — один из лучших способов контроля того, что с нашим приложением всё «ok». Причём при возникновении какой-либо проблемы, надо обязательно слать об этом оповещение заинтересованным лицам (например, количество заявок по кредиту на 20% меньше ожидаемого — шлём оповещение IT и бизнес-отделам, нагрузка на CPU выше нормы — оповещение админам и девам). Нужно следить, чтобы оповещения о проблемах были своевременными и актуальными, а также реально указывали на проблему.
4. Регрессия и проверка стабильности
Классной практикой является периодическое прохождение регрессионных тестов, с целью убедиться, что нигде ничего не вышло из строя. Может помочь в каких-то узких и специфичных случаях, когда мониторинг не видит проблем.
5. Отчётность и ведение статистики
Как и в любом тестировании, отчётность и ведение статистики о результатах прод-тестирования делает процесс прозрачнее, качество ПО и причины возникновения дефектов более обозримыми.
Все ошибки невозможно выявить на пре-проде, поэтому они будут попадать в боевую среду. Если их обнаружат пользователи, это скажется на репутации компании и, в конечном счете, на потере денег. Тестирование на проде поможет это предотвратить.
