Простейшее профилирование памяти на STM32 и других микроконтроллерах
«С опытом приходит стандартный, научный подход к вычислению правильного размера стека: взять случайное число и надеяться на лучшее»
— Jack Ganssle, «The Art of Designing Embedded Systems»
Привет, Хабр!
Как ни странно, но в абсолютном большинстве виденных мной «учебников для начинающих» по STM32 в частности и микроконтроллерам вообще нет, как правило, вообще ничего про такую вещь, как распределение памяти, размещение стека и, главное, недопущение переполнения памяти — в результате которого одна область перетирает другую и всё рушится, обычно с феерическими эффектами.
Отчасти это объясняется простотой учебных проектов, выполняемых при этом на отладочных платах с относительно жирными микроконтроллерами, на которых влететь в нехватку памяти, мигая светодиодом, довольно сложно — однако в последнее время даже у начинающих любителей мне всё чаще встречаются упоминания, например, контроллеров типа STM32F030F4P6, простых в монтаже, стоящих копейки, но и памяти имеющих единицы килобайт.
Такие контроллеры позволяют делать вполне себе серьёзные штуки (ну вот у нас, например, такая вполне себе годная измериловка сделана на STM32F042K6T6 с 6 КБ ОЗУ, от которых свободными остаются чуть больле 100 байт), но при обращении с памятью при работе с ними нужна определённая аккуратность.
Об этой аккуратности и хочу поговорить. Статья будет короткая, профессионалы ничего нового не узнают —, но начинающим эти знания очень рекомендуется иметь.
В типовом проекте на микроконтроллере на ядре Cortex-M оперативная память имеет условное разделение на четыре секции:
- data — данные, инициализируемые конкретным значением
- bss — данные, инициализируемые нулём
- heap — куча (динамическая область, из которой память выделяется явным образом с помощью malloc)
- stack — стек (динамическая область, из которой память выделяется компилятором неявным образом)
Изредка может также встречаться область noinit (неинициализируемые переменные — они удобны тем, что сохраняют значение между перезагрузками), ещё реже — какие-то иные области, выделенные под конкретные задачи.
Расположены они в физической памяти довольно специфическим образом — дело в том, что стек в микроконтроллерах на ядрах ARM растёт сверху внизу. Поэтому он располагается отдельно от остальных блоков памяти, в конце ОЗУ:
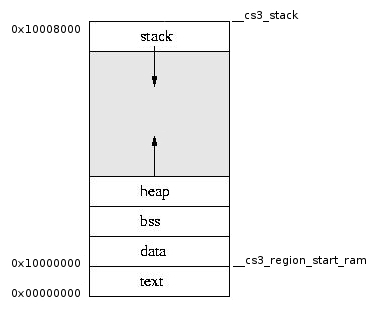
По умолчанию его адрес обычно равен самому последнему адресу ОЗУ, и оттуда он по мере роста опускается вниз — и из этого растёт одна крайне неприятная особенность стека: он может дотянуться до bss и перезаписать его верхушку, причём никаким явным образом вы про это не узнаете.
Статические и динамические области памяти
Вся память делится на две категории — статически выделяемая, т.е. память, общий объём который очевиден из текста программы и не зависит от порядка её выполнения, и динамически выделяемая, потребный объём которой зависит от хода выполнения программы.
К последней относятся куча (из которой мы берём куски с помощью malloc и возвращаем с помощью free) и стек, который растёт и уменьшается «сам по себе».
Вообще говоря, использовать malloc на микроконтроллерах настоятельно не рекомендуется, если вы не знаете абсолютно точно, что вы делаете. Основной привносимой им проблемой является фрагментация памяти — если вы выделите 10 кусочков по 10 байт, а потом освободите каждый второй, то вы не получите свободных 50 байт. Вы получите 5 свободных кусков по 10 байт.
Кроме того, на этапе компиляции программы компилятор не сможет автоматически определить, сколько памяти потребует ваш malloc (тем более — с учётом фрагментации, которая зависит не просто от размера запрошенных кусков, а от последовательности их выделения и освобождения), и потому не сможет вас предупредить, если памяти в итоге не хватит.
Методы обхода этой проблемы есть — специальные реализации malloc, которые работают в рамках статически выделенной области, а не всего ОЗУ, аккуратное употребление malloc с учётом возможной фрагментации на уровне логики программы и т.п. —, но в общем и целом malloc лучше не трогать.
Все области памяти с границами и адресами прописаны в файле с расширением LD, на который ориентируется линковщик при сборке проекта.
Статически выделяемая память
Итак, из статически выделяемой памяти у нас есть две области — bss и data, отличающиеся только формально. При инициализации системы блок data копируется из флэша, где для него сохранены нужные значения инициализации, блок bss просто заполняется нулями (по крайней мере, заполнить его нулями считается хорошим тоном).
Обе вещи — копирование из флэша и заполнение нулями — делаются в коде программы в явном виде, но не в вашем main (), а в отдельном файле, который выполняется первым, пишется один раз и просто таскается из проекта в проект.
Впрочем, интересует нас сейчас не это —, а то, как мы поймём, влезают ли вообще наши данные в ОЗУ нашего контроллера.
Это узнаётся очень просто — утилитой arm-none-eabi-size с единственным параметром — скомпилированным ELF-файлом нашей программы (часто её вызов вставляют в конец Makefile, потому что удобно):

Здесь text — это объём данных программы, лежащих во флэше, а bss и data — наши статически выделенные области в ОЗУ. Последние две колонки нас не волнуют — это сумма первых трёх, она не имеет практического смысла.
Итого, статически в ОЗУ нам нужны bss + data байт, в данном случае — 5324 байта. У контроллера есть 6144 байта ОЗУ, malloc мы не используем, остаётся 820 байт.
Которых нам должно хватить на стек.
Но хватит ли? Потому что если нет — наш стек дорастёт до наших же данных, и далее сначала он затрёт данные, потом данные затрут его, а потом всё рухнет. Причём между первым и вторым пунктами программа может продолжать работать, не осознавая, что в обрабатываемых ей данных — мусор. В худшем случае это будут данные, которые вы записали, когда со стеком было всё в порядке, а теперь только читаете — например, калибровочные параметры какого-нибудь датчика — и тогда у вас вообще нет очевидного способа понять, что с ними всё плохо, при этом программа продолжит выполняться, как ни в чём не бывало, выдавая вам на выходе мусор.
Динамически выделяемая память
И вот тут начинается самое интересное — если сократить сказку до одной фразы, то заранее определить размер стека практически невозможно.
Чисто теоретически, вы можете попросить компилятор выдать вам размер стека, используемый каждой отдельной функцией, потом попросить его же выдать дерево выполнения вашей программы, и для каждой ветви в нём просчитать сумму стеков всех присутствующих в этом дереве функций. Одно это для любой более-менее сложной программы займёт у вас крайне немалое время.
Потом вы вспомните, что в любой момент может случиться прерывание, обработчику которого тоже нужна память.
Потом — что могут случиться два или три вложенных прерывания, обработчикам которых…
В общем, вы поняли. Попробовать посчитать стек для конкретной программы — занятие увлекательное и в целом полезное, но часто вы это делать не будете.
Поэтому на практике используется один приём, позволяющий хоть как-то понять, всё ли у нас в жизни складывается хорошо — так называемая «окраска памяти» (memory painting).
Что удобно в этом методе — так это то, что он никак не зависит от используемых вами средств отладки, и при наличии у системы хоть каких-то средств вывода информации позволяет обойтись без средств отладки вообще.
Суть его в том, что мы заливаем весь массив от конца bss до начала стека где-то на самой ранней стадии выполнения программы, когда стек ещё точно маленький, одним и тем же значением.
Далее, проверяя, на каком адресе это значение уже пропало, мы понимаем, куда опускался стек. Так как однажды стёртая окраска сама не восстановится, то проверку можно делать эпизодически — она покажет максимальный достигавшийся размер стека.
Определим цвет краски — конкретное значение неважно, ниже я просто настучал двумя пальцами левой руки. Главное — не выбирать 0 и FF:
#define STACK_CANARY_WORD (0xCACACACAUL)
В самом-самом начале программы, вот прямо в стартап-файле, зальём всю свободную память этой краской:
volatile unsigned *top, *start;
__asm__ volatile ("mov %[top], sp" : [top] "=r" (top) : : );
start = &_ebss;
while (start < top) {
*(star++) = STACK_CANARY_WORD;
}
Что мы тут сделали? Ассемблерная вставка присвоила переменной top значение, равное текущему адресу стека — чтобы его случайно не затереть; в переменной start — адрес конца блока bss (переменную, в которой он хранится, я подсмотрел в скрипте линковщика *.ld — в данном случае он от библиотеки libopencm3). Далее мы просто заливаем всё от конца bss до начала стека одним и тем же значением.
После этого мы в любой момент можем сделать так:
unsigned check_stack_size(void) {
/* top of data section */
unsigned *addr = &_ebss;
/* look for the canary word till the end of RAM */
while ((addr < &_stack) && (*addr == STACK_CANARY_WORD)) {
addr++;
}
return ((unsigned)&_stack - (unsigned)addr);
}
Здесь переменная _ebss нам уже знакома, а переменная _stack — из того же скрипта линковщика, в нём она означает верхний адрес стека, то есть, в данном случае, просто конец ОЗУ.
Вернёт эта функция максимальный зафиксированный размера стека в байтах.
Дальнейшая логика достаточно проста — где-нибудь в теле программы периодически вызываем check_stack_size () и выводим его выхлоп в консоль, на экран или куда нам удобно его вывести, и запускаем устройство в боевую эксплуатацию на период, который считаем достаточно продолжительным.
Периодически смотрим на размер стека.
В данном случае различными хаотическими действиями с устройством его удаётся довести до 712 байт — то есть из имевшихся изначально 6 Кбайт ОЗУ у нас остаётся запас ещё в целых 108 байт.
Word of caution
Экспериментальный метод определения размера стека — простой, эффективный, но не 100-% надёжный. Всегда может сложиться ситуация, когда очень редкое стечение обстоятельств, наблюдаемое, например, раз в год, приведёт к незапланированному повышению этого размера. Впрочем, в общем случае и при грамотно написанной прошивке можно считать, что вряд ли у вас случится что-то, перехлёстывающие зафиксированный размер более чем на 10–20%, так что мы с нашими 108 байтами запаса с высокой степенью уверенности находимся в безопасности.
В большинстве же случаев такое квазипрофилирование, легко и просто выполняемое практически на любой системе и независимо от используемых средств разработки, позволяет с высокой достоверностью определить эффективность использования памяти и поймать проблему со стеком на ранних стадиях, особенно при работе на младших контроллерах с ОЗУ размером в единицы килобайт.
P.S. В многозадачных системах на RTOS стеков в большинстве случаев много — помимо главного стека MSP, растущего от верхнего края ОЗУ вниз, есть отдельные стеки процессов PSP. Размер их явно задаётся программистом, что не уберегает процесс от выхода за их границы — поэтому методы контроля в них используются такие же.
