Производительность сети малой латентности InfiniBand на виртуальном кластере HPC HUB

Моделирование сложных физических процессов в наши дни рассматривается как важная технологическая возможность многими современными компаниями. Широко используемым сейчас подходом для создания вычислителей, способных рассчитывать сложные модели, является создание кластерных систем, где вычислительный узел представляет собой сервер общего назначения, подключенный к сети малой латентности и управляемый своей собственной ОС (как правило, из семейства GNU/Linux).
Введение виртуализационного слоя в системное ПО вычислительных кластеров, позволяет в течение нескольких минут создавать «виртуальный кластер». Такие виртуальные кластера в рамках одной OpenStack инфраструктуры являются абсолютно независимыми. Пользовательские программы внутри них могут изменяться так, как нужно пользователю без каких-либо согласований с кем-либо, а логические устройства, на которых находятся пользовательские данные, недоступны другим виртуальным кластерам.
Поддержка сети малой латентности виртуализационными решениями представляет собой отдельную сложную проблему. Для прикладных программ в большинстве случаев современная виртуализация на основе KVM приводит к минимальным потерям вычислительной мощности (<1%). Однако специализированные тесты сетей малой латентности показывают накладные расходы от виртуализации не более 20% на операциях синхронизации.
Значение сетей малой латентности для HPC
Современные задачи моделирования физических процессов требуют больших объемов памяти и вычислительных мощностей для того, чтобы расчеты могли быть выполнены на практике за реалистичное время. Такие большие объемы оперативной памяти и такие большие количества вычислительных ядер совместить в одной системе под управлением одной классической ОС с использованием современных технологий сложно и дорого.
Гораздо более дешевым и широко используемым сейчас альтернативным подходом является создание кластерных систем, где вычислительный узел представляет собой компьютер общего назначения, управляемый своей собственной ОС. При этом вычислительные узлы кластера синхронизируются и совместно управляются специальным ПО, обеспечивающим запуск, сопровождение и остановку так называемых «параллельных приложений». Последние представляют собой независимые процессы в ОС узлов, синхронизирующихся друг с другом за счет взаимодействия в сети. Далее мы будем называть такие сети «вычислительными сетями», вычислительные узлы — «кластерными узлами» или просто «узлами», управляющее ПО — «кластерным ПО».
Современные концепции программирования используют два основных метода распараллеливания: по данным и по процессам. Для моделирования естественных явлений чаще всего используется распараллеливание по данным, а именно:
- в начале шага вычислений части данных раздаются разным вычислителям и они производят некоторые действия над этими частями
- затем вычислители обмениваются информацией согласно различных численных схем (как правило довольно жестко запрограммированных) для того, чтобы иметь исходные данные для следующего шага
С точки зрения практики программирования вычислителем может являться все что угодно, что имеет хотя бы один процессор, некий объем памяти и доступ к вычислительной сети для обменов с другими вычислителями. По сути вычислитель — это абонент вычислительной сети с какими-то (пусть и относительно небольшими) вычислительными мощностями. Вычислителем может быть и тред в рамках процесса, и процесс в рамках ОС, и виртуальная машина с одним или несколькими виртуальными процессорами, и аппаратный узел с какой-то урезанной специализированной ОС, и т.д.
Самым массовым стандартом API для создания современных параллельных приложений является MPI, существующий в нескольких реализациях. Также широко распространен стандарт Intel OpenMP API, предназначенный для создания параллельных приложений в рамках одной ОС на многопроцессорном узле. Поскольку современные кластерные узлы содержат многоядерные процессоры с большим объемом памяти, то возможно большое количество вариантов определения «вычислителя» в рамках парадигмы распараллеливания по данным и реализации этой парадигмы на базе подхода параллельных приложений. Самыми распространенными являются два подхода:
- одно процессорное ядро — один вычислитель
- один многопроцессорный узел — один вычислитель
Для реализации первого подхода достаточно использовать MPI, для которого он собственно и создавался. В рамках второго подхода часто используется связка MPI + OpenMP, где MPI используется для коммуникации между узлами, а OpenMP для распараллеливания внутри узла.
Естественно, что в ситуации, когда параллельные приложения работают на нескольких узлах, суммарная производительность зависит не только от процессоров и памяти, но и от производительности сети. Также понятно, что обмены по сети будут медленнее, чем обмены внутри многопроцессорных систем. Т.е. кластерные системы по сравнению с эквивалентными многопроцессорными системами (SMP) практически всегда работают медленнее. Для того, чтобы минимизировать деградацию скоростей обменов по сравнению с SMP машинами используются специальные вычислительные сети малой латентности.
Ключевые характеристики вычислительных сетей
Ключевыми характеристиками специализированных вычислительных сетей являются латентность и ширина канала (скорость обмена при больших объемах данных). Скорость передачи больших объемов данных важна для различных задач, например, когда узлам надо передавать друг другу результаты, полученные на текущем шаге расчета, чтобы собрать начальные данные для следующего шага. Латентность играет ключевую роль при передаче сообщений малого размера, например, синхронизационных сообщений, необходимых для того, чтобы узлы знали о состоянии других узлов, данные с которых им нужны. Синхронизационные сообщения как правило очень малы (типичный размер несколько десятков байт), но именно они используются для предотвращения логических гонок и тупиков (race condition, deadlock). Высокая скорость синхронизационных сообщений собственно отличает вычислительный кластер от его ближайшего родственника — вычислительной фермы, где сеть между узлами не обеспечивает свойства малой латентности.
Intel Infiniband является одним из самых массовых стандартов сетей малой латентности сегодня. Именно оборудование этого типа часто используется в качестве вычислительной сети для современных кластерных систем. Существует несколько поколений Infiniband сетей. Наиболее распространен сейчас стандарт Infiniband FDR (2011 год). По прежнему актуальным остается стандарт QDR (2008 год). Поставщиками оборудования сейчас активно продвигается следующий стандарт Infiniband EDR (2014 год). Порты Infiniband как правило состоят из агрегированных групп базовых двунаправленных шин. Наиболее распространены порты 4х.
Характеристики сети Infiniband последних поколений
| QDRx4 | FDRx4 | EDRx4 | |
| Полная пропускная способность, ГБит/c | 32 | 56 | 100 |
| Латентность порт-порт, мкс | 1.3 | 0.7 | 0.7 |
Как известно, виртуализация вносит некоторые свои специфические задержки при работе гостевых систем с устройствами. Не исключение в данном случае и сети малой латентности. Но из-за того, что малая латентность (задержка) является их самым важным свойством, то взаимодействие с виртуализациоными средами для таких сетей критически важно. При этом их пропускная способность, как правило, остается такой же, как и без виртуализации в широком диапазоне параметров соединений. Важным шагом в развитии Infiniband, сделанным относительно недавно (2011 год), является использование технологии SR-IOV. Эта технология позволяет физический сетевой адаптер Infiniband превратить в набор виртуальных устройств — виртуальных функций VF. Такие устройства, выглядят как независимые Infiniband адаптеры и, например, могут быть отданы в монопольное управление различным виртуальным машинам или каким-то высоконагруженным службам. Естественно, что адаптеры IB VF работают по другим алгоритмам, и их характеристики отличаются от оригинальных адаптеров IB без включенной поддержки SR-IOV.
Групповые операции обменов между узлами
Как уже упомянуто выше, самым популярным инструментальным HPC средством на текущий момент остается библиотека MPI. Существуют несколько основных вариантов реализации MPI API:
- MPICH
- MVAPICH
- OpenMPI
- Intel MPI
Библиотеки MPI содержат основные функции, необходимые для реализации параллельных вычислений. Критически важными для HPC приложений являются функции передачи сообщений между процессами, в особенности групповые функции синхронизации и передачи сообщений. Стоит отметить, что чаще всего под группой понимаются все процессы параллельного приложения. В сети легко найти подробные описания MPI API:
- https://computing.llnl.gov/tutorials/mpi/
- https://parallel.ru/docs/mpi2/mpi2-report.html.
Основы алгоритмов, использованных для реализации MPI, хорошо описаны в [1], также много статей на эту тему можно найти по ссылке. Оценки эффективности данных алгоритмов являются предметом большого количества работ [2, 3, 4, 5]. Чаще всего оценки строятся с помощью методов асимптотического анализа теории алгоритмов и оперируют понятиями
 время установления соединения,
время установления соединения,  скорость передачи единицы информации,
скорость передачи единицы информации,  количество передаваемых единиц информации,
количество передаваемых единиц информации,  количество задействованных процессоров.
количество задействованных процессоров.Естественно, что для современных многопроцессорных систем, объединенных сетью малой латентности, параметры и надо брать различными для процессоров, взаимодействующих внутри одного узла и находящихся на разных узлах, на одном многоядерном кристалле и на разных. Тем не менее, хорошим начальным оценочным приближением для и в случае задач, использующих несколько узлов вычислительного кластера, являются значения латентности и пропускной способности вычислительной сети.
Как легко понять, именно групповые операции синхронизации являются наиболее требовательными к свойству «малой латентности» сети и масштабируемости этого свойства. Для наших тестов мы, как и другие авторы [6], использовали следующие 3 операции:
broadcast
Самая простая из групповых операций — broadcast (широковещательная рассылка). Один процесс посылает одно и то же сообщение всем остальным (M обозначает буфер с данными. Взято из [1]).
В вычислительных программах broadcast часто применяется для распространения каких-то условий, параметров в начале счета и между итерациями. Broadcast часто является элементом реализации других, более сложных коллективных операций. Например, broadcast используют в некоторых реализациях функции barrier. Существуют несколько вариантов алгоритмов для реализации broadcast. Оптимальное время работы broadcast на неблокирующем коммутаторе полнодуплексных каналов без аппаратного ускорения составляет:

all-reduce
Операция all-reduce проводит указанную в параметрах ассоциативную операцию над данными, лежащими в памяти группы вычислителей, а затем сообщает результат всем вычислителям группы. (Знак
 означает указанную ассоциативную операцию. Взято из [1]).
означает указанную ассоциативную операцию. Взято из [1]).
С точки зрения структуры сетевых обменов all-reduce аналогична функции all-to-all broadcast. Эта операция применяется для суммирования или перемножения, поисков максимума или минимумов среди операндов, расположенных на разных вычислителях. Иногда эта функция используется в роли barrier. Оптимальное время работы all-reduce на неблокирующем коммутаторе полнодуплексных каналов без аппаратного ускорения составляет:
all-to-all
Операцию all-to-all еще иногда называют «personalized all-to-all» или «total exchange». Во время этой операции каждый вычислитель пересылает сообщение каждому другому вычислителю. Все сообщения могут быть уникальными (Взято из [1]).
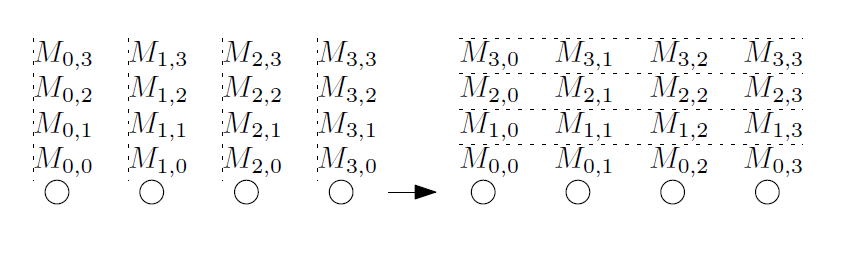
Эта операция интенсивно используется различными алгоритмами, такими как преобразование Фурье, матричными преобразованиями, сортировки, параллельными операциями над базами данных. Это одна из самых «тяжелых» коллективных операций. Для данной коллективной операции оптимальный алгоритм зависит от соотношений значений ключевых переменных , , и размера передаваемых сообщений . При использовании алгоритма гиперкуба, который не оптимален по объему пересылок и применяется для сообщений малого размера, оценка времени составляет:

Используются и другие подходы к тестированию HPC сред. Например, с помощью интегральных тестов, имитирующих вычисления широко распространенных задач. Одним из самых популярных наборов интегральных тестов является NAS parallel benchmarks. Этот тест также применялся и для тестирования виртуальных HPC сред [7].
Методика тестирования
Для тестов производительности, изложенных в этой работе, использовались сервера с процессорами Intel Xeon 64 Гб RAM и IB адаптерами ConnectX-3. На виртуальных и физических узлах был установлен OpenMPI, соединение узел-узел тестировалось с помощью утилит perftest и OSU benchmarks.
OS CentOS Linux release 7.2.1511 (CentOS 7.2), ядро 3.10.0–327.18.2.el7.x86_64, qemu/KVM кастомизированный на базе 2.3.0 (в дистрибутиве CentOS 7 используется версия 1.5.3), драйвера Mellanox OFED 3.3–1.0.4, qemu-kvm поддерживал NUMA режим.
Гостевая OS CentOS Linux release 7.1.1503 (CentOS 7.1), ядро 3.10.0–229.el7.x86_64, драйвера Mellanox ConnectX-3. Каждая виртуальная машина была единственной на своем физическом сервере и занимала на нем все процессоры и 48 Гб оперативной памяти, overcommit по процессорным ядрам был выключен.
Адаптеры IB были переключены в режим поддержки SR-IOV, и было создано 2 VF на адаптер. Одна из VF экспортировалась в KVM. Соответственно, в гостевой OS был виден лишь один адаптер Infiniband, а в хостовой два: mlx4_0 и mlx4_1 (VF).
На виртуальных и физических узлах был установлен OpenMPI версии 1.10.3rc4 (входит в состав пакетов Mellanox OFED 3.3–1.0.4). Соединение узел-узел тестировалось с помощью утилит perftest 0.19.g437c173.33100.
Групповые тесты производились с помощью OSU benchmarks версии 5.3.1, собранных с помощью gcc 4.8.5 и указанного выше OpenMPI. Каждый результат OSU benchmarks является усреднением 100 или 1000 измерений, в зависимости от ряда условий.
На физических узлах демоном tuned установлен профиль latency-performance. На виртуальных узлах он был выключен.
Тесты запускались на двух узлах (40 ядер). Измерения проводились сериями по 10–20 измерений. В качестве результата бралось среднее арифметическое трех самых меньших значений.
Результаты
Приведенные в таблице параметры сетей являются идеальными, и в реальной ситуации они недостижимы. Например, латентность между двумя узлами с адаптерами Infiniband FDR (режим datagram), измеренная с помощью ib_send_lat, составляет для малых сообщений 0.83 мкс, а полезная пропускная способность (без учета служебной информации) между двумя узлами, измеренная с помощью ib_send_bw, составляет 6116.40 МБ/с (~51.3 Гбит/с). Пенальти по латентности и пропускной способности в реальных системах обусловлена следующими факторами:
- дополнительной латентностью коммутатора
- задержками, обусловленными ОС узлов
- потери пропускной способности на обеспечение передачи служебной информации протоколов
Запуск осуществлялся на сервере командой:
ib_send_bw -F -a -d mlx4_0на клиенте:
ib_send_bw -F -a -d mlx4_0 Так ib_send_lat между парой гостевых ОС, расположенных на разных физических серверах, показывает латентность 1.10 мкс (рост задержки на 0.27 мкс, отношение латентностей нативного и виртуализированного IB составляет 0.75), а ib_send_bw показывает пропускную способность в 6053.6 МБ/с (~50.8 Гбит/с, 0.99 от полезной ширины канала без виртуализации). Данные результаты находятся в хорошем соответствии с результатами тестов других авторов, например [6].
Стоит заметить, что в хостовой ОС тест работал не с SR-IOV VF, а с самим адаптером. Результаты представлены тремя графиками:
- все размеры сообщений
- только сообщения до 256 байтов включительно
- отношение времен исполнения теста для нативного Infiniband и для VF
Тест broadcast запускался и в хостовой и в гостевой ОС как:
/usr/mpi/gcc/openmpi-1.10.3rc4/bin/mpirun --hostfile mh -N 20 -bind-to core -mca pml ob1 -mca btl_openib_if_include mlx4_0:1 /usr/local/libexec/osu-micro-benchmarks/mpi/collective/osu_bcastХудшее отношение времен — 0.55, для большинства тестов отношение не хуже 0.8.



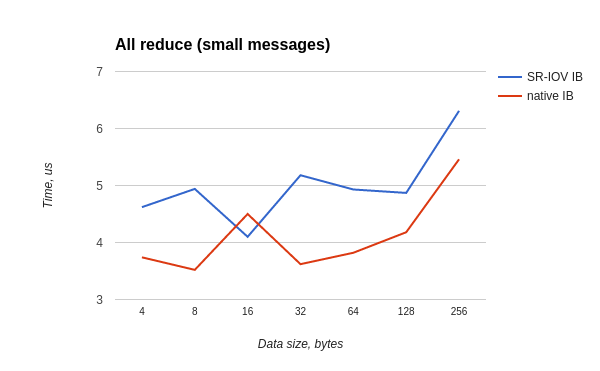
Тест all-reduce запускался и в хостовой и в гостевой OS как:
/usr/mpi/gcc/openmpi-1.10.3rc4/bin/mpirun --hostfile mh -N 20 -bind-to core -mca pml ob1 -mca btl_openib_if_include mlx4_0:1 /usr/local/libexec/osu-micro-benchmarks/mpi/collective/osu_allreduceХудшее отношение времен — 0.7, для большинства тестов отношение не хуже 0.8.


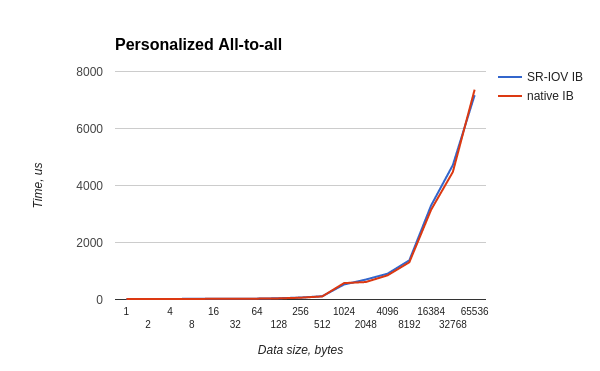
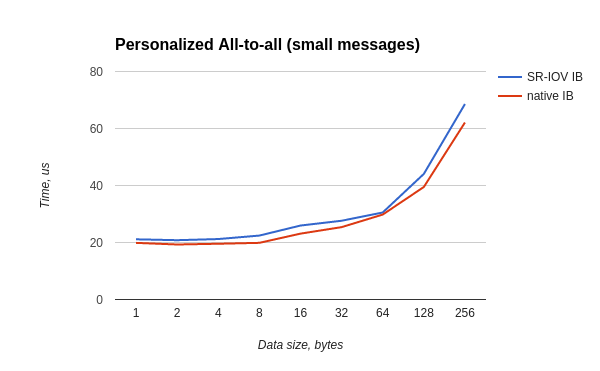
Тест all-to-all запускался и в хостовой и в гостевой OS как:
/usr/mpi/gcc/openmpi-1.10.3rc4/bin/mpirun --hostfile mh -N 20 -bind-to core -mca pml ob1 -mca btl_openib_if_include mlx4_0:1 /usr/local/libexec/osu-micro-benchmarks/mpi/collective/osu_alltoallХудшее отношение времен — 0.87, для большинства тестов отношение не хуже 0.88.

Обсуждение
Зубчатая форма представленных в тестах графиков с одной стороны обусловлена результатом не очень большой выборки тестов, но с другой стороны как раз является желанным эффектом метода отбора наименьших измеренных значений, используемого при профилировании программ. Обоснованием этого метода есть рассуждение, что фрагмент кода не может исполниться быстрее своей максимальной скорости, а все процессы, которые могут происходить в системе одновременно с исполнением тестового кода, либо не влияют на его скорость, либо замедляют его. Наличие кажущихся противоречивыми результатов, когда виртуализированный тест исполняется немного быстрее (2–5% ускорения), чем невиртуализированный следует отнести к особенностям драйверов и прошивки IB адаптеров, которые, во-первых, имеют свои оптимизационные схемы, а во-вторых, все же немного по-разному работают в обоих случаях (размеры буферов данных, особенности обработки прерываний и т.д.).
Особенности современных технологий виртуализации вносят дополнительные источники задержек по сравнению с ситуацией, где виртуализационного слоя нет. К существенными для HPC можно отнести три вида таких задержек:
- Замедление скорости работы сети малой латентности. В нашем конкретном случае — замедление Infiniband в режиме виртуальной функции SR-IOV. Это задержка является центральной темой данной работы и разобрана выше.
- Внешние по отношению к виртуализационной оболочке программы и службы будут эпизодически требовать процессорного времени, будут сбрасывать кэши счетных приложений. Это довольно сложным образом будет вносить разнообразную рассинхронизацию и задержки в счетные приложения, работающие под виртуализационной оболочкой. Такие систематические помехи могут быть крайне неприятны для всякого рода «экстремальных» программ, либо для неправильно оптимизированных. Разумеется стоит понимать, что без виртуализационной прослойки счетные программы будут работать быстрее. Однако в большинстве практически важных случаев пенальти по производительности из-за наличия управляющего кода вне виртуализационной оболочки на современных многоядерных узлах не превышает нескольких процентов, а чаще всего оно <1%. К тому же существует ряд подходов, позволяющих выделить и зафиксировать процессорные ядра, которые будут заниматься нагрузками вне виртуализационной оболочки, исключив их из виртуализированной среды. В результате воздействие на процессорные ядра и их кэши внутри виртуализационных оболочек можно минимизировать.
- При работе с виртуальным APIC возникают многочисленные выходы в гипервизор, что весьма накладно по задержке (десятки микросекунд). Эта проблема стала актуальной в последнее время в связи с ростом запросов на многоядерные виртуальные машины, и ей уделяется внимание на различных конференциях и в специализированных публикациях, например [8,9]. Такие задержки происходят при доставке прерываний, в том числе и от SR-IOV устройств (в нашем случае Infiniband) в госте, и при пробуждении ядра процессора из спящего состояния (IPI), например, при получении сообщения
Самым радикальными методами уменьшения виртуализационных пенальти для обработки прерываний, на взгляд авторов, является либо использование процессоров Intel с поддержкой vAPIC, либо использования контейнерной виртуализации (например LXC) для счетных узлов. На существенность задержки, возникающей при обработке прерываний в KVM, также косвенно указывается в [7], где авторы устанавливают связь между ростом количества прерываний и существенным уменьшением производительности виртуализированной версии теста.
Оценить данные задержки, кроме самой первой, с помощью простых формул, подобных приведенным в [1], сложно по нескольким причинам:
- Первая и основная из них та, что данные задержки проявляются асинхронно с алгоритмом счетной задачи, которая работает в виртуализированной среде
- Вторая причина заключается в том, что данные задержки зависят от «истории» вычислительного узла в целом, включая и алгоритм счетной задачи и ПО виртуализации — состояния кэшей, памяти, контроллеров
Также важно понимать, что при пересылках большого количества пакетов по сети малой латентности, в частности, при фрагментации больших сообщений, скорость генерации прерываний будет расти по сложному закону, что может привести к появлению нетривиальных зависимостей скорости передачи сообщений от их длины и опять же, истории стэка ПО виртуализации.
Создателями традиционных кластерных вычислительных систем прикладываются огромные усилия, чтобы устранить помехи для вычислительных задач:
- выключение всех ненужных служб ОС
- минимизация всех сетевых обменов
- минимизация любых других источников прерываний для узлов
В случае сочетания виртуализации и облачного ПО мы находимся только в начале этого пути оптимизации под высокопроизводительные вычисления.
Выводы
Сравнительные тесты набора из трех часто используемых операций MPI (broadcast, all-reduce, personalized all-to-all) показали, что виртуализационная среда на базе qemu/KVM и с использованием технологии SR-IOV демонстрирует увеличенное время тестов в среднем на 20% (в самом худшем случае на 80% при broadcast пакетов размерами 16 и 32Кб). Данное падение производительности хотя и заметно, однако не критично для большинства параллельных приложений, связанных с механикой сплошных сред, молекулярной динамикой, обработкой сигналов и т.д. Удобство использования виртуализованной среды, возможность быстрого расширения вычислительного поля и его настройки кратно компенсирует затраты на возможное увеличение счетного времени.
Для задач, требующих быстрого случайного доступа одного узла в память другого, такая задержка может быть критичной. Скорее всего она не позволит эффективно использовать виртуализированные кластера для решения подобных задач.
На практике деградация производительности вычислительных программ зачастую оказывается гораздо меньше указанных величин (max 20%). Это происходит потому, что большинство времени хорошо написанные и широко используемые программы все же считают и обрабатывают данные внутри вычислителя, а не совершают операции синхронизации или пересылки данных. Ведь авторы параллельного кода всегда стремятся выбрать такие алгоритмы и приемы реализации, которые минимизируют потребность в синхронизации и пересылках между вычислителями.
Литература
- A. Grama, A. Gupta, G. Karypis, V. Kumar. Introduction to Parallel Computing, Second Edition. Addison-Wesley, 2003
- R. Thakur, W. Gropp. Improving the Performance of Mpi Collective Communication on Switched Networks, 2003
- R. Thakur, R. Rabenseifner, W. Gropp. Optimization of Collective Communication Operations in MPICH. Int’l Journal of High Performance Computing Applications,-- 2005 — Vol 19(1) — pp. 49–66.
- J. Pješivac-Grbović, T. Angskun, G. Bosilca, G.E. Fagg, E. Gabriel, J.J. Dongarra. Performance analysis of MPI collective operations. Cluster Computing — 2007 — Vol. 10 — p.127.
- B.S. Parsons. Accelerating MPI collective communications through hierarchical algorithms with flexible inter-node communication and imbalance awareness. Ph. D. Thesis on Computer science, Purdue University, USA, 2015
- J. Jose, M. Li, X. Lu, K.C. Kandalla, M.D. Arnold, D.K. Panda. SR-IOV Support for Virtualization on InfiniBand Clusters: Early Experience. International Symposium on Cluster, May 2011
- A. Kudryavtsev, V. Koshelev, A. Avetisyan. Modern HPC cluster virtualization using KVM and Palacios. High Performance Computing (HiPC) Conference, 2012
- D. Matlack. KVM Message Passing Performance. KVM forum, 2015
- R. van Riel. KVM vs. Message Passing Throughput, Reducing Context Switching Overhead. Red Hat KVM Forum 2013
Материал подготовлен Андреем Николаевым, Денисом Луневым, Анной Субботиной, Вильгельмом Битнером.
