Профилировка работы с памятью с Intel® VTune™ Amplifier XE
Неэффективный доступ к памяти, пожалуй, одна из наиболее частых проблем производительности программ. Скорость загрузки данных из памяти традиционно отстаёт от скорости их обработки процессором. Для уменьшения времени доступа к данным в современных процессорах реализуются специальные блоки и многоуровневые системы кэшей, позволяющие сократить время простоя процессора при загрузке данных, однако, в некоторых случаях, процессорная логика работает не эффективно. В этом посте поговорим о том, как можно исследовать работу с памятью вашего приложения с помощью нового профиля Memory Access в VTune Amplifier XE.
Метрики, относящиеся к памяти, уже давно доступны в VTune Amplifier. Новый тип анализа Memory Access не только собрал их в одном месте, но и добавил несколько серьёзных улучшений.
Было раньше в других типах анализа:
- Промахи кэшей всех уровней
- Данные о трафике в локальную оперативную память (DRAM bandwidth)
- Количество обращений к локальной и удалённой оперативной памяти на NUMA машинах
Появилось в Intel VTune Amplifier XE 2016:
- Отслеживание объектов данных
- Данные о трафике в удаленную оперативную память на NUMA машинах (QPI bandwidth)
- Среднее время исполнения (Аverage Latency) инструкций обращения к памяти или загрузки данных из объектов приложения
Итак, запускаем анализ Memory Access, сразу включаем отслеживание объектов данных. Эта возможность пока доступна только на Linux.
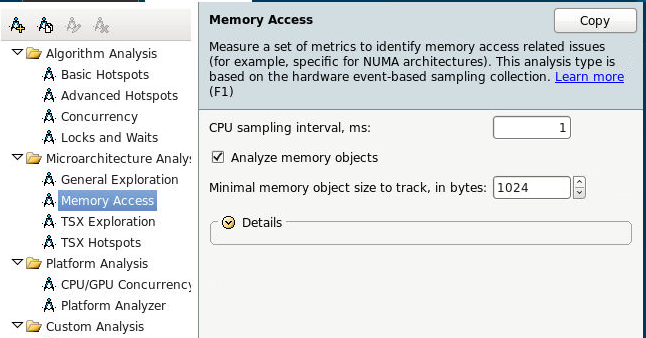
Или из командной строки:
amplxe-cl -c memory-access -knob analyze-mem-objects=true -knob mem-object-size-min-thres=1024 -- ./my_app
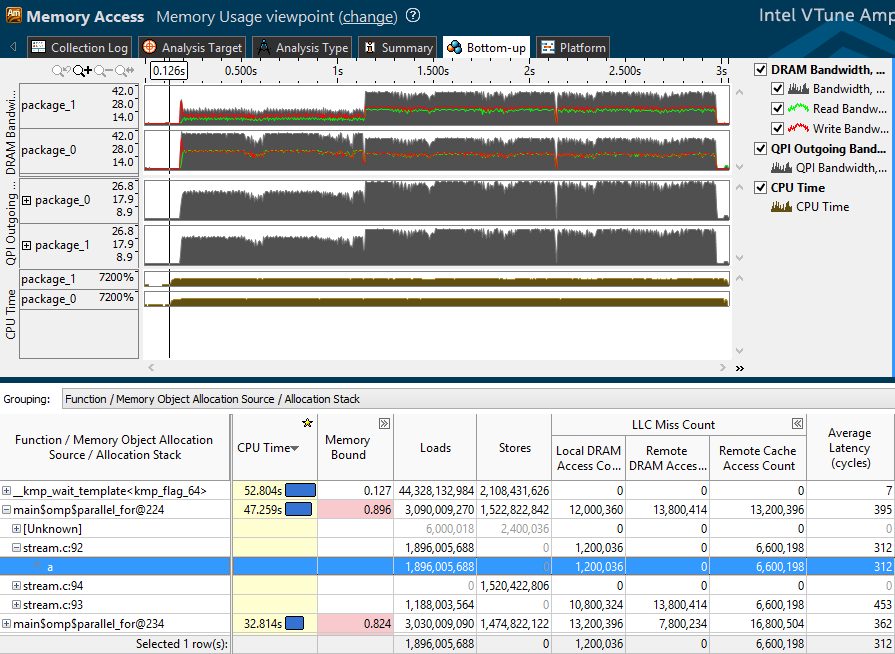
Итак, посмотрим на профиль, полученный после профилирования бенчмарка stream. В верхней половине окна Bottom-up отражён трафик, созданный нашим приложением:
- DRAM bandwidth – чтение (зелёным), запись (красным), и общий трафик в локальную оперативную память по каждому сокету (package).
- QPI outgoing bandwidth – исходящий трафик от одного сокета к другому.
Ниже представлена таблица, отражающая основные аппаратные метрики и счётчики обращений к памяти:
- Average Latency – среднее количество циклов процессора, затраченное на выполнение инструкций обращения к памяти или загрузку данных из объектов приложения. Это статистическое значение, может быть неточным на коротких замерах. Однако, если значение велико, стоит обратить внимание на остальные метрики.
- LLC Miss Count – количество промахов кэша верхнего уровня (обычно L3) – подразделяются на обращения к локальной оперативной памяти, удалённой оперативной памяти и удалённому кэшу, т.к. загружаемые данные могут находится в кэше другого процессора.
- Loads и Stores – количество исполненных инструкций чтения и записи данных
- Memory Bound – метрики эффективности операций с памятью
В Memory Bound входит отношение количества обращений к удалённой и локальной оперативной памяти, и метрики по тем же категориям, что и промахи кэша верхнего уровня (LLC):

Метрики Memory Bound это формулы, включающие количество тех или иных событий (например, промахов LLC) и их оценочной стоимости в циклах. Величина метрики сравнивается с некоторым эталонным значением, и подсвечивается розовым, если она превышает заданный порог. На выходе пользователь получает подсказку о том, на что стоит обратить внимание – большое количество промахов кэша может говорить о неэффективности расположения объектов данных, возможно, самые «горячие» объекты можно вынести в отдельный блок, который сможет дольше удерживаться в кэше.
Проблемы работы с памятью неразрывно связаны с объектами данных, которые раньше приходилось вычислять самому. Теперь можно просто выбрать группировку с Memory Object, и наблюдать, на какие конкретно объекты приходятся большая часть обращений, промахи кэша и т.д.:

При этом, если дважды кликнуть на функцию над объектом, то попадём на строку кода, осуществлявшую интересующую нас операцию с памятью:

А если сгруппироваться по Memory Object Allocation Source и дважды кликнуть на сам объект, то можно определить место его создания:
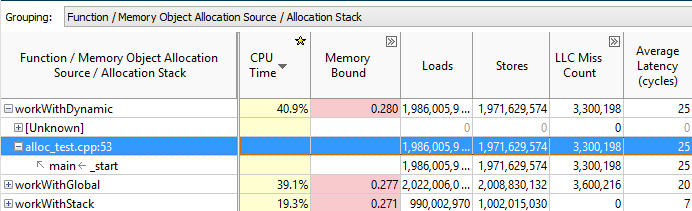
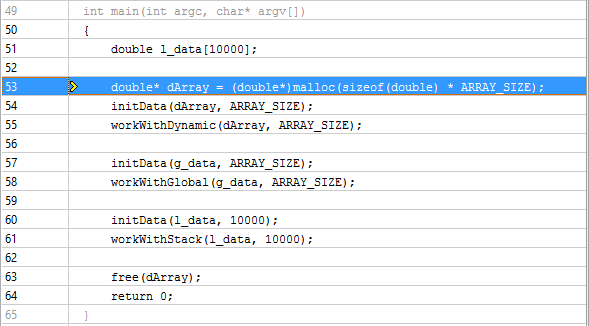
VTune Amplifier распознаёт динамически создаваемые объекты языков С и C++ и статические объекты С, С++ и Fortran.
На NUMA машинах обращения к локальной оперативной памяти выполняются быстрее, чем к удалённой, т.к. к оперативной памяти другого сокета приходится обращаться через QPI шину, которая медленнее, чем шина доступа к локальной оперативной памяти. Большое количество обращений к оперативной памяти или кэшу другого сокета, вкупе с высокими значениями Average Latency, может свидетельствовать о неэффективной локализации данных приложения. Если, например, глобальный объект данных создан в главном потоке, а другие потоки, возможно работающие на другом сокете, активно обращаются к нему, возможны простои процессора, обусловленные удалённым обращением к данным. Подобные проблемы можно решать с помощью локализации горячих данных в потоке, “пиннингом” (pinning) потоков, применением разных NUMA-aware библиотек.
Обнаружить NUMA проблемы в VTune Amplifier теперь достаточно просто. Для начала, смотрим все метрики со словом Remote, например, Remote/Local DRAM ratio – относительное количество удалённых обращений:

Можно отфильтровать функции и объекты с высоким QPI трафиком. На вкладке Summary в Bandwidth Utilization Histogram двигаем ползунки, определяя, какие значения мы считаем Low, Medium и High:

В Bottom-up группируемся по Bandwidth Domain, и смотрим, какие объекты использовались (или какой код исполнялся) во времена высокой QPI нагрузки:

Ну и традиционно для Bandwidth анализа, всплески трафика бывают наглядно видны на временной шкале. Выделяем такой участок и фильтруемся (клик правой кнопкой, Filter In by selection). Список функций в таблице внизу отразит только код, исполнявшийся в выбранном промежутке времени:

Ниже приведён результат профиля другого бенчмарка – Intel Memory Latency Checker:

Выделенный фрагмент имеет большой трафик на чтение и низкий на запись из локальной оперативной памяти сокета 1. Т.е. сокет 1 что-то активно читает. Также сокет 1 имеет большой исходящий трафик QPI, т.е. он активно что-то шлёт сокету 0 (больше некому, их всего два. Если сокетов 4 и больше, можно тоже определить направление по UNIT-ам, конкретным QPI линкам). При этом на сокете 0 наблюдается высокая активность процессора. Всё это наталкивает на мысль, что сокет 0 активно обращается к данным, которые расположены в оперативной памяти сокета 1, что подкрепляется данными о количестве удалённых обращений в таблице. Дальше можно разбивать таблицу до уровня функций и находить конкретные места в коде, ответственные за выявленный шаблон доступа.
Новый тип анализа Memory Access помогает увидеть, как исполнение кода приложения соотносится с физической топологией памяти машины. Какие уровни памяти задействованы (кэши, DRAM, удалённая DRAM), как распределялся трафик памяти. И, что самое главное, какой код исполнялся во время долгих обращений к памяти, и к каким объектам данных эти обращения происходили.
Да, и если кто не слышал – Intel Parallel Studio можно скачать бесплатно для разных некоммерческих нужд – детали здесь.
