Процесс запуска и проведения АВ-тестов
Приветствую, уважаемые читатели Хабра. Меня зовут Николай Французов, я digital-аналитик в компании Tele2, занимаюсь сбором и анализом данных, построением дашбордов и проведением А/В-тестов.
Я хотел бы рассказать вам о том, как мы проводим тесты в нашем проекте, и поделиться опытом, возможно, логикой проведения и приведенными процессами вы сможете воспользоваться в ваших проектах, а python-фишечки по расчету fixed horizon и анализу результатов пригодятся в ваших исследованиях.
Структура
Кратко про АВ-тесты
Процесс проведения — первая часть, работа аналитика данных. Расчет fixed horizon и формирование ТЗ;
Процесс проведения — вторая часть, работа аналитика стрима проекта. Настройка;
Процесс проведения — третья часть, сбор данных, анализ результатов и выводы.
Кратко про АВ-тесты
А/В-тестирование это где…
Проверяется два и более варианта (контроль и тест) с целью определения наиболее эффективного;
Степень эффективности «измеряется» с помощью посчитанных вероятностей ложноположительных и ложноотрицательных случаев;
Суть исследования заключается в том, чтобы разделить аудиторию на равные части и показать им разные версии одной и той же страницы. Чтобы найти ту, которая принесет наиболее высокий эффект, например, конверсию в целевое действие.
Например, вариант А — с оригинальной кнопкой зеленого цвета, и вариант В — новая версия с кнопкой фиолетового цвета.

В нашем проекте мы используем ААВ-тест, то есть, делим группы на три равные части, двум из которых показываем оригинальную версию (без изменений), а другой — версию с изменениями. В таком случае, группы с версиями без изменений (одинаковые) выступают у нас контрольной и валидационной группой, а с изменениями — тестовой. Контрольная и валидационная группа нужны нам для проведения А/А-теста. Он позволяет проверить сплит-систему и убедиться, что инструмент «деления» трафика работает безошибочно. Также позволяет определить, что данные во всех группах отправляются в системы аналитики одинаково.
Далее мы сравниваем один из вариантов контрольной группы с тестовой, в целях нахождения стат.значимого результата.
Проведение А/В-тестов
В нашем проекте процесс проведения А/В-тестирования делится на две целевые части, в которых задействованы аналитик данных и аналитик стрима проекта.
Главное о проведении А/В-тестов:
Умение делить аудиторию на равные части и показывать разный контент;
Умение собирать данные и корректно использовать инструменты для анализа результатов.
Еще неплохо, конечно же, изначально строить хорошие гипотезы.
Проводим тест. Первая часть: работа аналитика данных
Для нас, аналитиков данных, процесс А/В-тестирования начинается с заказа стейкхолдера, которому необходимо что-то с чем-то сравнить, подтвердить или опровергнуть свою гипотезу.
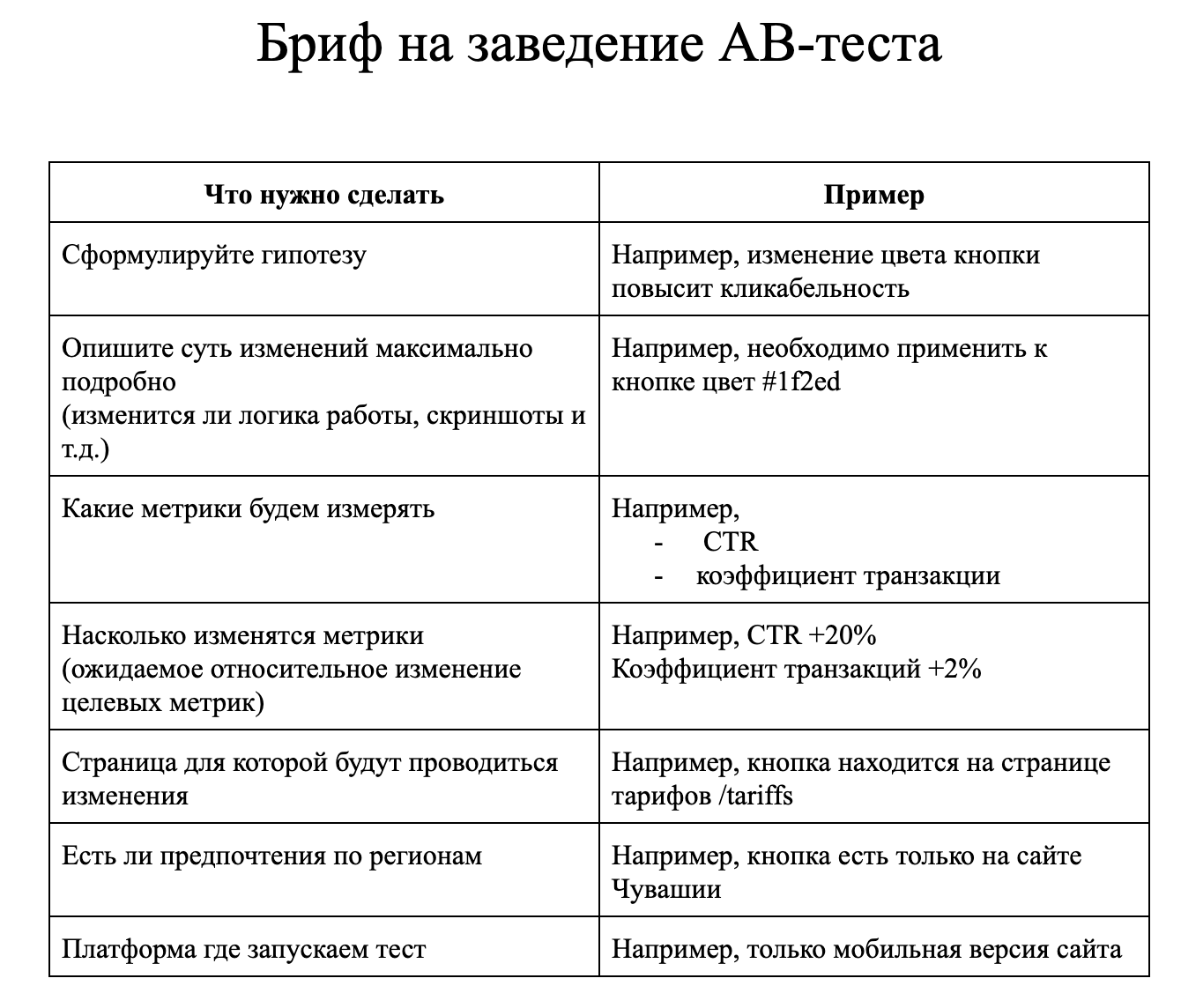
При заведении такой задачи мы предоставляем бриф для заведения А/В-теста, суть которого заключается в сборе основных требований и сформулированной гипотезе. Заявка приходит через BPM (система управления бизнес-процессами), в которой при заполнении подтягивается наш бриф.
Вот пример:
Хотя обычно заказчик старается сделать все по своему и его запрос выглядит вот так:
Запрос от стейкхолдера
Для страницы /lk будут отображаться два визуальных варианта уведомлений от Миа (мобильный искусственный интеллект)
Гипотеза: Мы увеличим CTR
Текущий CTR?

Но мы не отступаем от процесса, так как из-за некачественного планирования многократно повышается вероятность провалить исследование и запустить не то, что нужно. Также мы ведем реестр А/В-тестов, в котором проводим оценку гипотез и синхронизируем очередность запуска. Об этом я расскажу в следующий раз.
Далее по процессу для достижения эффективности проведения теста мы встречаемся с заказчиком и помогаем сформулировать правильную статистическую гипотезу, продумать ход эксперимента и сформулировать метрики для оценки эффективности оцениваемого кейса.
Здесь же и возникают вопросы:
Сколько времени ждать для достижения % изменения метрики?
На какую длительность запускать тест?
Будет ли стат. значимый результат по итогу?
Справка: Статистическая значимость — оценка, позволяющая определить, существует ли реальное основание в разнице между выбранными для исследования показателями или это случайность.
Для этого мы как аналитики данных предлагаем следующие решение:
Рассчитываем среднее кол-во трафика на исследуемой странице/экране;
Рассчитываем baseline для измеряемых метрик;
Рассчитываем MDE (Minimum Detectable Effect) и длительность проведения теста и кол-во выборки для достижения MDE;
Как мы производим все расчеты:
На нашем сайте установлен GTM — сервис, позволяющий размещать теги (фрагменты кода) и управлять ими.
При загрузке любой страницы срабатывает тег, с помощью которого мы собираем общие события с фронта: userId страницы, юзер агент и пр. И формируем из них объект.
Дальше мы достаем параметры события из DataLayer, которые прежде разметили, и дополняем данный объект с помощью переменных GTM.

В результате получаем набор данных, который передаем в GA. Далее с помощью BigQuery мы обращаемся к нашим БД и взаимодействуем с хитами, агрегируем до понятных: посещение страницы, кол-во уникальных пользователей, конверсия в целевое действие и прочие метрики.
Обратившись через SQL и собрав необходимые данные, мы рассчитываем среднее кол-во трафика на странице и baseline искомой метрики, они пригодятся нам для дальнейших расчетов длительности проведения теста. Далее мы работаем в Jupyter Notebook на python. Мы подготовили скрипт, позволяющий рассчитать MDE и длительность проведения теста.
Скрипт по расчету длительности, размеру выборки, MDE и т.д. можно посмотреть здесь
*Справка: BigQuery — это бессерверное, масштабируемое облачное хранилище данных с мощной инфраструктурой от Google, которое имеет на борту RESTful веб-сервис. Имеет тесное взаимодействие с другими сервисами от Google. BigQuery поддерживает диалект Standard SQL. Доступ к BigQuery возможен через Google Cloud Console, с помощью внутренней консоли BigQuery, а также через вызовы BigQuery REST API как напрямую, так и через различные клиентские библиотеки java, python, .net и многие другие.
В результате мы формируем ТЗ в confluens, в котором указываем описание предполагаемых изменений, исследуемую гипотезу, кол-во групп, соотношение сегментов сплитования, аудиторию, на которой будет проводиться тест (например, авторизованные пользователи, все устройства, конкретные регионы и т.д.), время проведения теста и пр. Данное ТЗ мы передаем аналитику стрима проекта для заведения оформления технических правил, заведения заявки на контент на запуск данного теста.
Проводим тест. Вторая часть: работа аналитика стрима проекта
Деление аудитории
Данным умением обладает наш backend digital_sute. Каждый абонент, который заходит на наш сайт, случайным образом относится к одному из двенадцати сегментов.

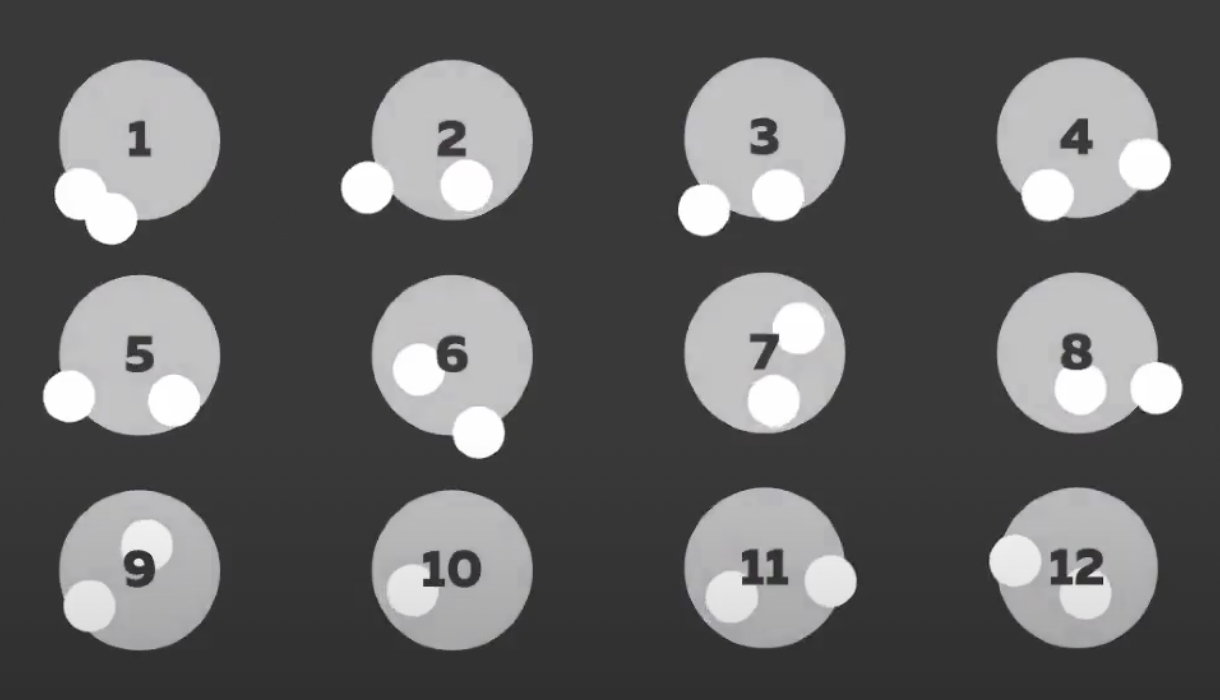
Сегменты — 12 частей, на которые backend делит случайным образом всю аудиторию.
Группы — это выборки/группы, которые мы выделяем для запускаемого теста и которым показываем разный контент.

12 сегментов выбраны не случайно, это очень удобное число, так как оно кратно двум и трем, оно кратно четырем и даже шести. В результате оно позволяет нам проводить 2–3 теста одновременно.
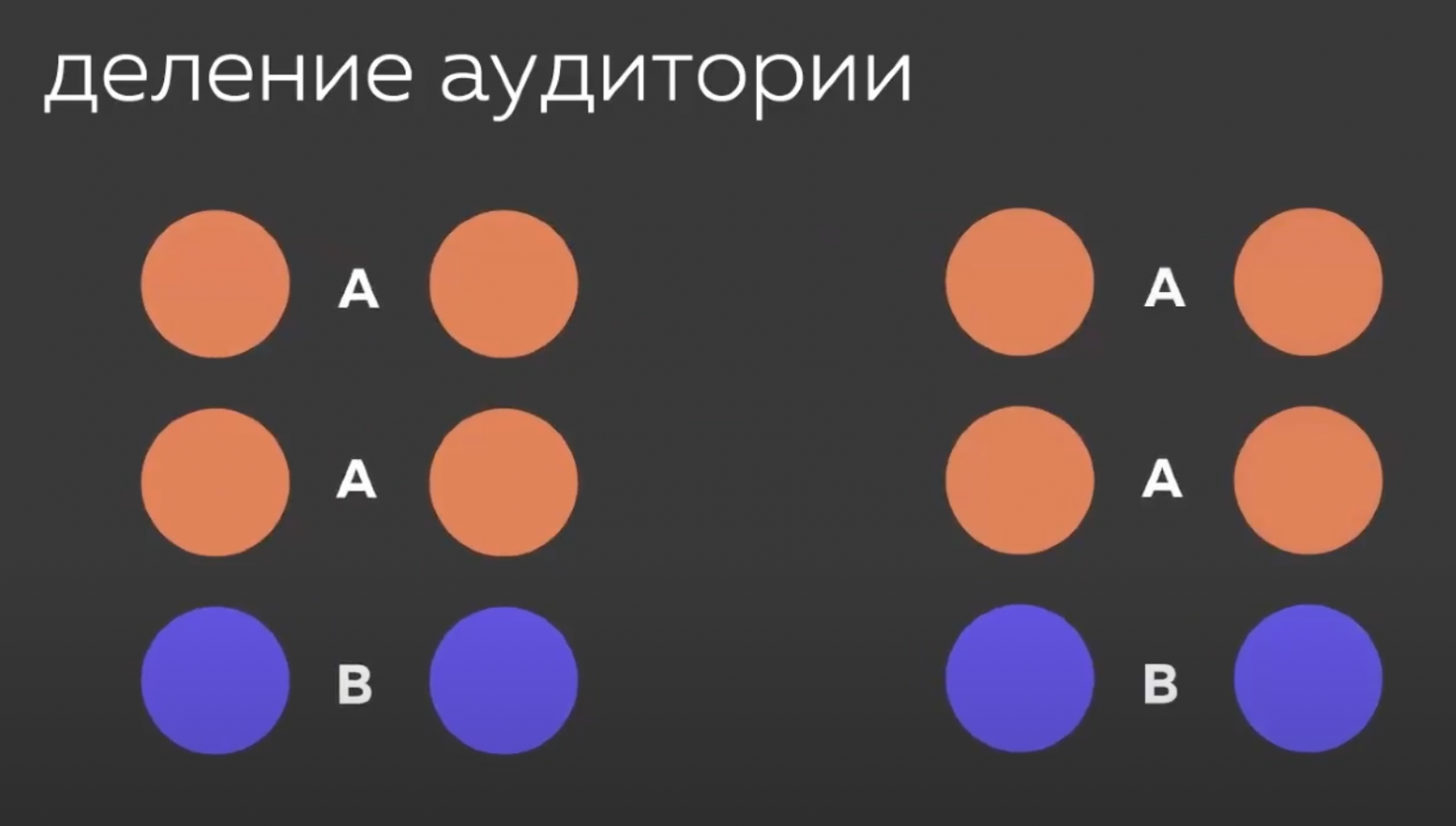
Можно отсекать неиспользуемые сегменты либо добавлять их в контрольные и тестовые группы для увеличения трафика (размер получаемой выборки влияющий на длительность проведения теста) или проводить несколько одновременных тестов.
Настройка и выделение групп
Механика и устройство
Изначально наш клиент присваивает и отправляет на фронте пользователю куку. Далее отправляет запрос на backend, после бэк проверяет запрос на наличие куки и выставляет атрибут сегменту по её значению.
*Справка: Атрибут — это такой список свойств, который присваивается пользователям сайта. Это может быть пол, тип клиента (b2b или b2c). Мы изначально создали такой же атрибут, который назвали segment, который выдается согласно куки.
Если кука изначально не найдена, то бэк выставляет ее самостоятельно.
Далее в BCC мы выставляем все сегменты пользователей.
После бэк запрашивает все подходящие пользователю сегменты BCC согласно его атрибутам и ролям. Далее отрабатывает EM, бэк запрашивает JSON странички согласно правилам и сегментам BCC. После он передает сформированный JSON на фронт. И фронт отрисовывает тот или иной вариант странички.
*Справка: BCC — грубо говоря графический интерфейс для базы данных. Система хранения справочников.
ЕМ — это кмс-ка, система управления контентом, аналог SAP.

Сегменты выставляются как атрибут пользователями BCC. При настройке А/В-теста мы создаем BCC сегменты, то есть некоторые правила отображения интерфейса, в некотором роде выставляем фильтры. Например, авторизованные пользователи, за исключением B2B, и все неавторизованные пользователи.

Подробнее на примере:
Допустим, мы решили поменять цвет кнопки «купить» в чекауте, с черного на розовый, предполагая, что за счет этого увеличим конверсию в покупку.
Мы должны разделить аудиторию на три равные части, первые две увидят оригинальную черную кнопку, третья тестовая группа увидит розовую.

Далее нам нужно настроить BCC-сегменты для каждой группы

Далее мы загоним данный проект в ЕМ и для чекаута создадим правила срабатывания настроенных сегментов. Для корректного отображения сегментов необходимо правильно задать поведение для выделенных групп.
Например, при такой настройке все будет работать корректно, но мы дополнительно создадим два лишних правила.

Условия теста от нас требуют показать ⅔ аудитории старый дизайн и ⅓ — новый. Следовательно, нам нужно создать только одно правило для тестовой группы и выставить его приоритет. Таким образом весь трафик странички будет получать первое правило — его получат только те, кто находится в тестовой группе (здесь, на картинке, я перепутал и должен был указать тестовую группу, а не контрольную).

А все, кто не состоит в этом правиле, будут проваливаться дальше и получать оригинальную страницу интерфейса, таким образом попадать в контрольную и валидационную группы. Так вот, для некоторых тестов мы настраиваем более частные сегменты и соответственно должны корректно расставлять приоритеты по срабатыванию данных правил (например, только для авторизованных пользователей Хабаровского края).
Итоги по запуску АВ-теста:
Для проведения теста нам нужно
Узнать у аналитиков данных условия и длительность проведения теста;
Ознакомиться с правилом странички на проде для определения или создания необходимых сегментов в BCC;
Убедиться в наличии необходимой веб-разметки на обновленной фиче. вероятно ивент должен быть аналогичен старому или хотя бы содержать ту же информацию, что и старый при наличии новой. Это наш способ общаться и передавать данные в GA;
Написать инструкцию к созданию необходимых правил в ЕМ с указанием начала и конца теста .Правила для тестовой группы всегда приоритетнее оригинального;
Убедиться, что все работает после настройки.
Проводим тест. Третья часть: сбор данных, анализ результатов и выводы.
После успешного запуска теста, аналитик данных должен убедиться в корректности запуска и сплитовки сегментов, в корректности отображения контрольных и тестовых вариантов.
Поскольку в GA каждому пользователю присваивается кука, по ним мы можем определить ту или иную группу.
С помощью инструмента разработчика мы проверяем правильность отображения сегментов через ручное переключение куки, во вкладке application.

Анализ результатов
При анализе результатов мы также работаем в jupyter.
Вот пример скрипта с анализом.
По шагам:
Загружаем необходимые библиотеки для анализа данных, визуализаций и стат. пакеты;
Через апишку (client) подключаемся к BQ, пишем SQL-запрос, в котором собираем наши сегменты и рассчитываем необходимые метрики;
Еще раз убеждаемся, что у нас прошла правильная сплитовка за счет группировки пользователей по тестовым группам и расчета их численности;
sns.set(font_scale=1.5)
explode = (0.1, 0.1, 0.1)
labels = ['control_group', 'test_group', 'valid_group']
plot = ex_group.plot(
kind='pie',
autopct='%1.1f%%',
labels = labels,
title='Распределние пользователей по группам',
y='кол-во пользователей',
legend=False,
explode=explode,
shadow=True, figsize=(12,8))
plt.ylabel('')
plt.show()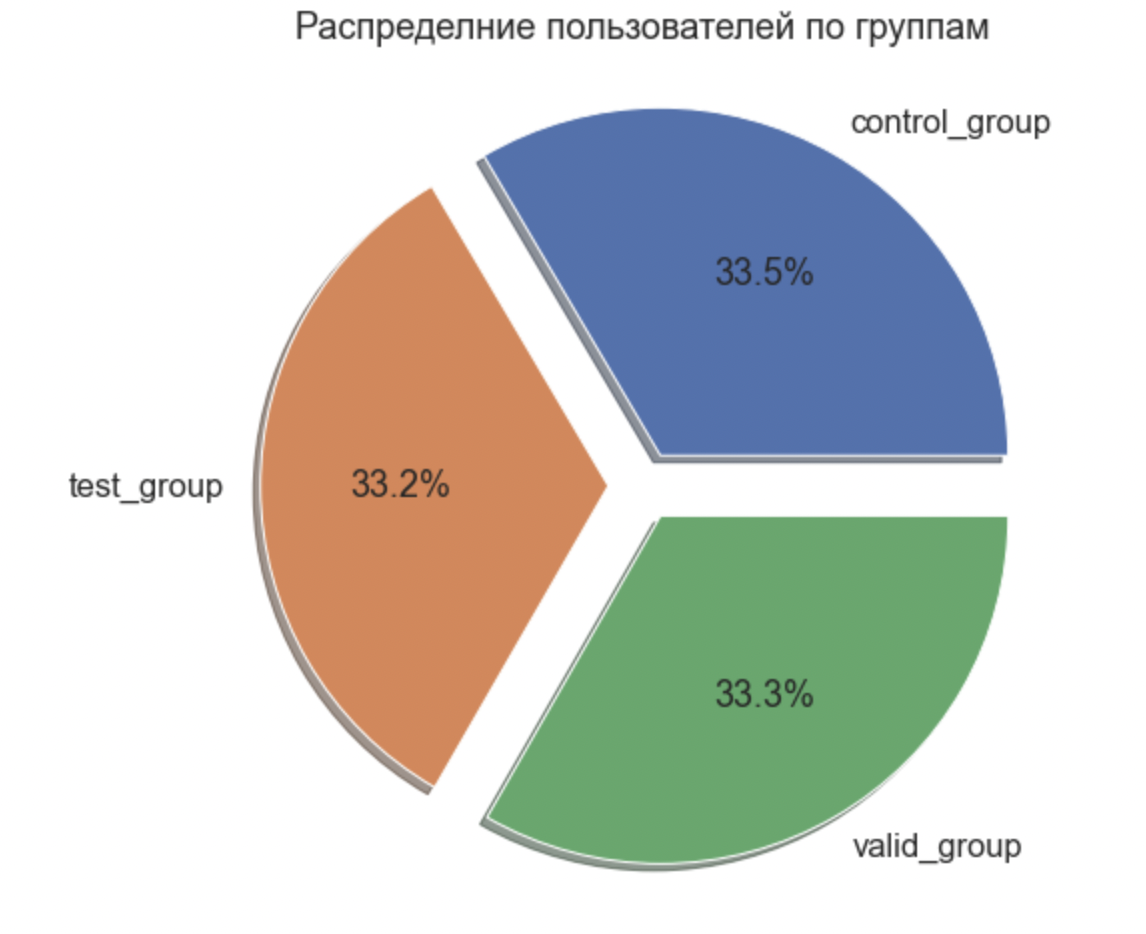
Рассчитываем распределение по искомой метрике и на его основе выбираем статистический метод для анализа, например критерий Стьюдента;
Рассчитываем метрики и визуализируем в виде boxplot для наглядности;
# Визуально сравниваем группы
sns.set(rc={'figure.figsize':(10,9)})
ax = (sns.boxplot(x="test_group", y="ctr", data= df)).set(xlabel='Группа', ylabel='ctr, %',
title='Распределение по группам')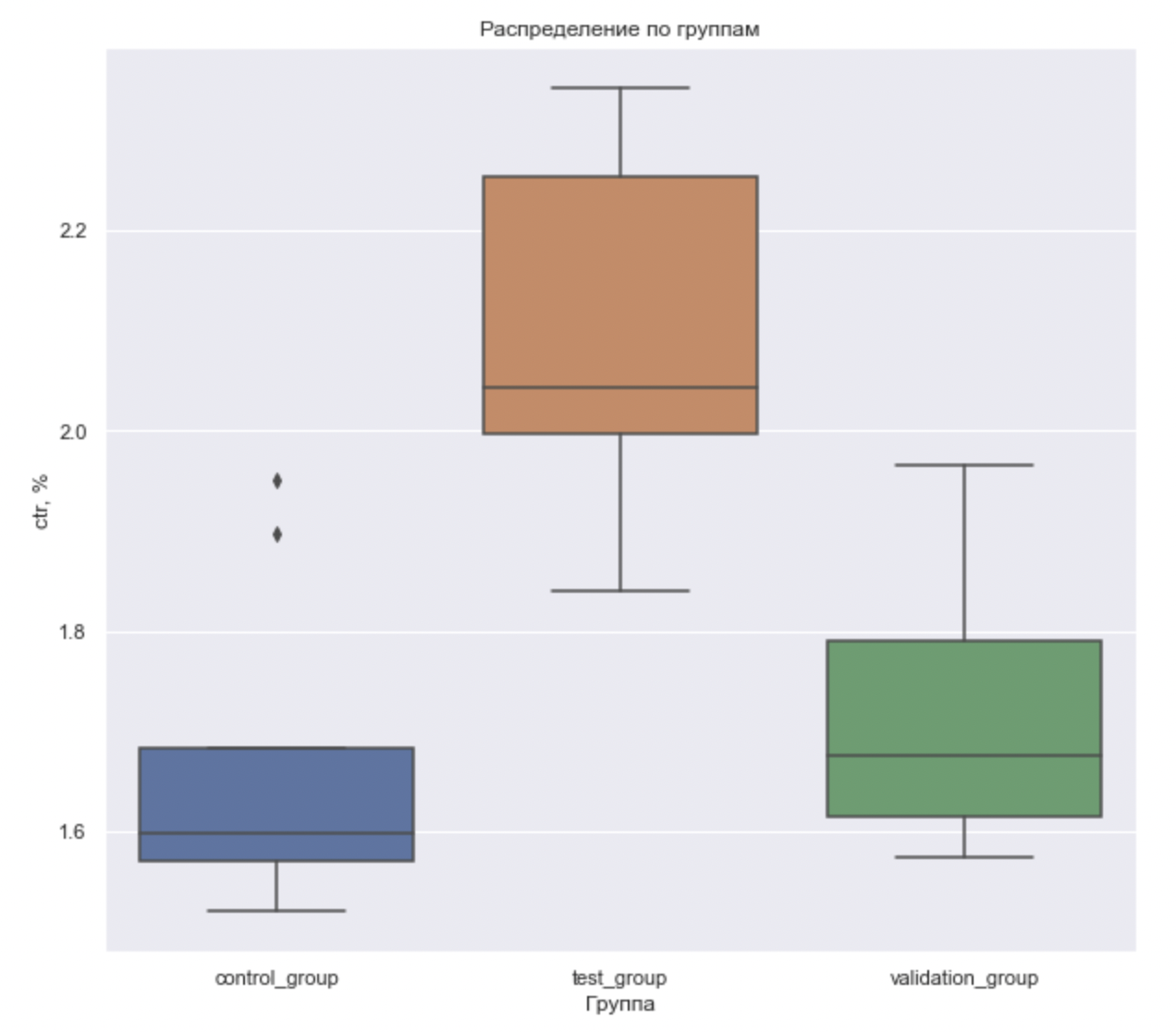
Сравниваем через скрипт стат. методом различие между метриками групп и делаем вывод на основе p-value;
Рассчитываем uplift и пишем отчет в confluens;
Примерно так мы и работаем!) Я постарался показать процесс на довольно простом кейсе, чтобы не вдаваться в подробности стат. анализа, рассказы про попарные сравнения, с которыми часто приходится иметь дело, с проблемами в получении данных и решении сложных кейсов через доверительные интервалы и bootstrap.
В целом, процесс A/B-тестирования в нашем проекте выглядит так, с помощью него мы довольно быстро запускаем тесты и настраиваем контент сайта под заданные сегменты, проводим А/А-тесты и, убедившись в корректности, анализируем результаты.
