Проблемы с производительностью в игре XCOM 2
Привет! Меня зовут Александр, я руководитель программистов компьютерной графики в Gaijin в проектах CRSED и Enlisted. Иногда, в свободное время, я исследую как устроена графика в других играх и нахожу там что-то интересное.
Недавно я решил разобраться, почему XCOM 2 тормозит на моём ноутбуке. В ходе изучения рендера этой игры я нашёл ряд мест, которые можно было бы без проблем ускорить. Результаты моего небольшого исследования вылились в видео: https://www.youtube.com/watch? v=CuPPc2Z8lTk
Ниже представлена расшифровка этого видео.
Добрый день!
Вероятно, вы играли в игру XCOM 2 или хотя бы слышали о ней. Она вышла в 2016 году. Сделана на движке Unreal Engine 3.5. Если оценивать XCOM как игру в целом, мне она понравилась. Увлекательный геймплей, приятная картинка, интересная история.
Единственная проблема, с которой я столкнулся, — это низкий FPS, в особенности на кадрах с выстрелами крупным планом. На базе и в тактическом виде эта проблема менее заметна. Средний FPS у меня был в районе 25–30. И мне стало интересно, выжимает ли игра все доступные мощности из моей ноутбучной GTX 1050 или можно сделать лучше. Сейчас я покажу вам 6 оптимизаций, которые могли помочь разработчикам улучшить производительность данной игры.
Захват кадров
Для анализа графики я использовал RenderDoc версии 1.12. Он без проблем захватил несколько кадров, которые я потом просмотрел. Я взял один кадр из меню, кадр базы, кадр на тактической карте и кадр с выстрелом.
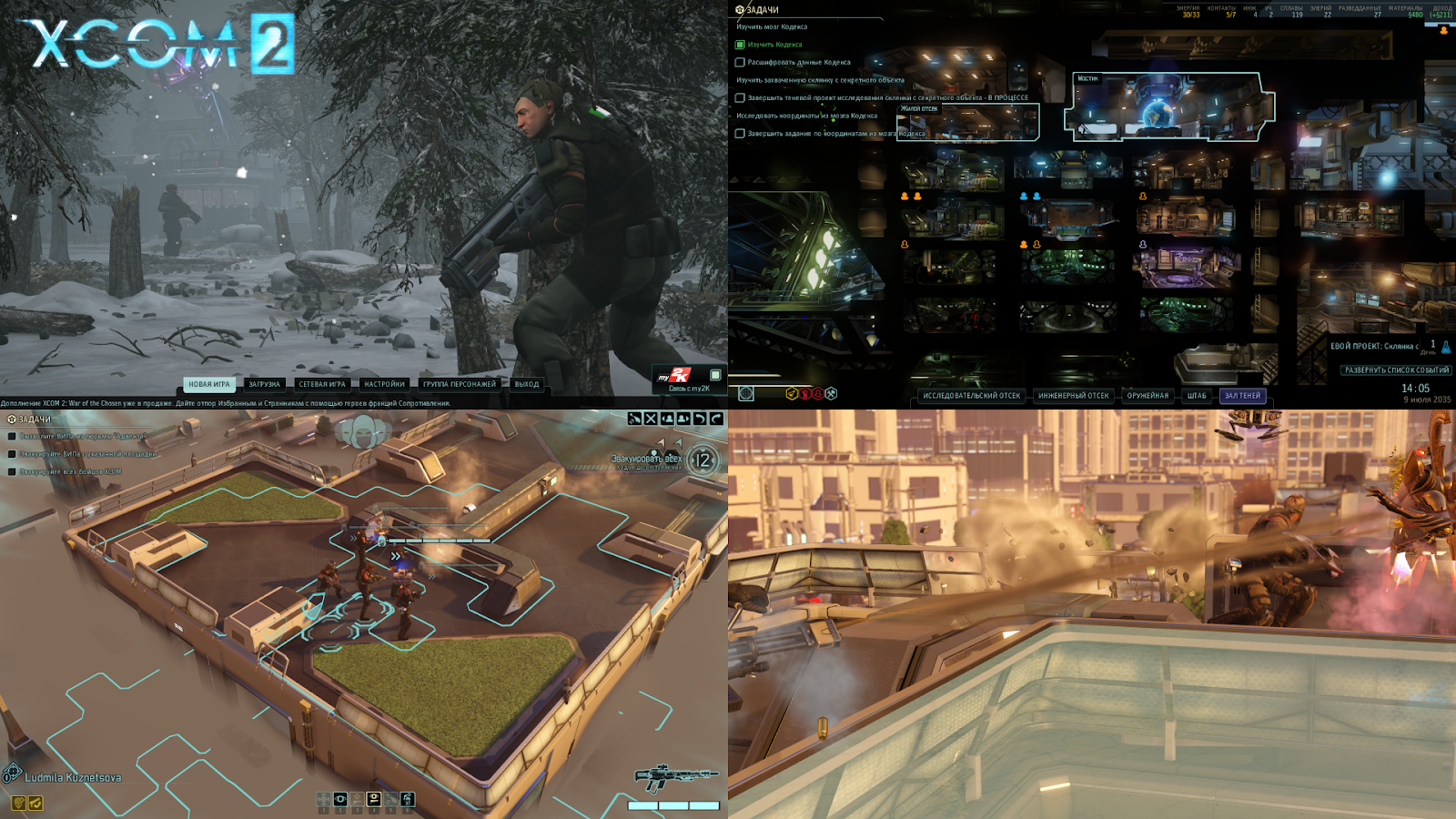
Во всех них наблюдаются общие проблемы с производительностью. Проходы, которые вы здесь видите (скриншот ниже), это последовательные вызовы отрисовки, для которых выставлены одни и те же рендертаргеты, т.е. текстуры, в которые рисуется результат.
«Жирный» G-buffer
Первая оптимизация связана с уменьшением размера G-buffer’а. Самый долгий проход — это заполнение G-buffer’а (>16 мс). Это видно как на таймингах различных проходов, так и на общем таймлайне.
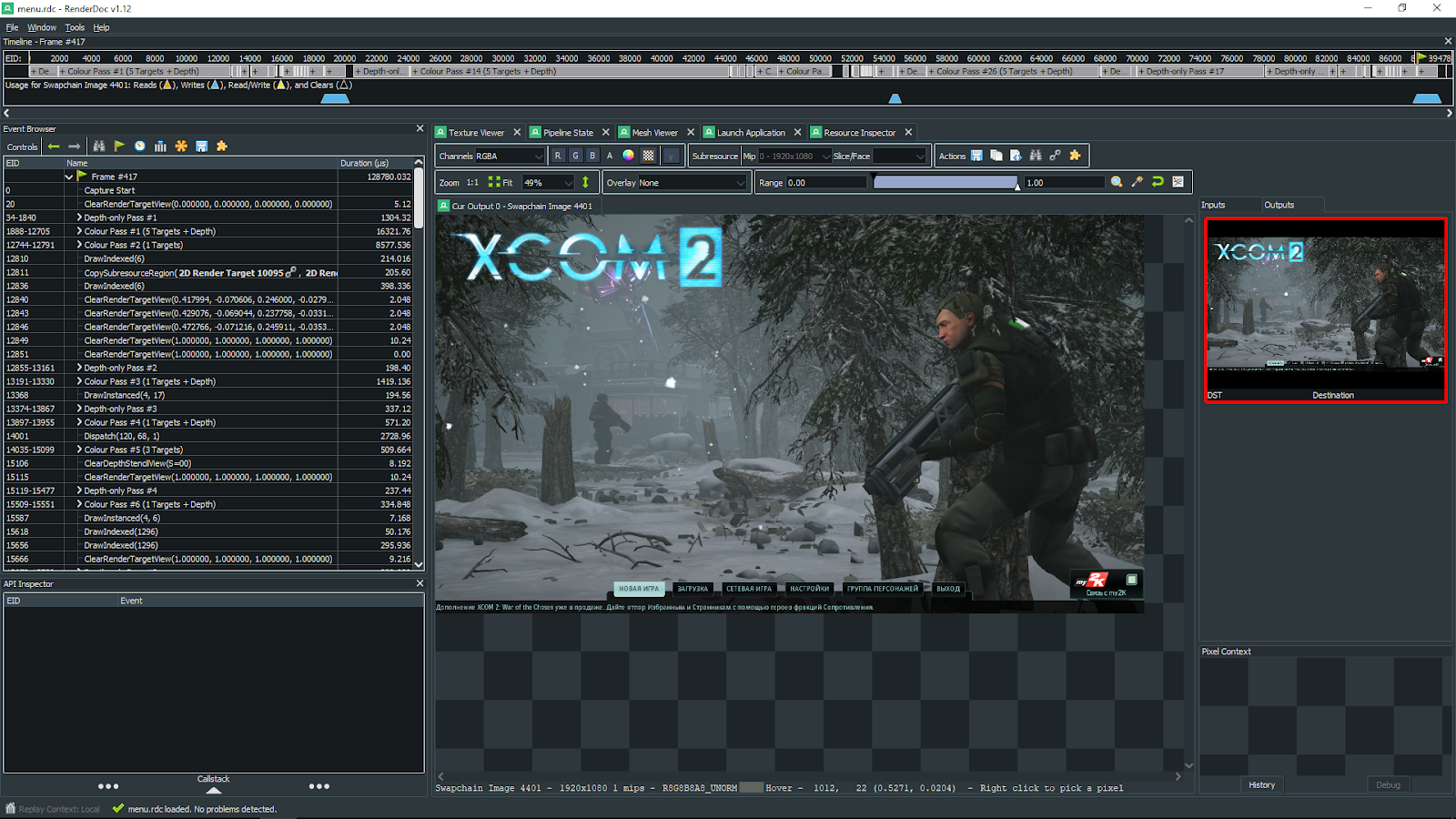
Всего в G-buffer входит 5 текстур в формате RGBA16F, то есть текстуры имеют 4 16-битных канала и содержат вещественные числа.
Для разрешения 1080 требуется около 80 Мбайт видеопамяти для всего этого, что не так уж и много для современных видеокарт, но проблема в том, что все эти текстуры нужно заполнить. Запись в текстуру намного дороже чем чтение, поэтому много используемых текстур — это норма, а много рендертаргетов — уже не очень хорошо.
Итак, G-buffer содержит следующие текстуры:
Цвета эмиссивных (т.е. светящихся) материалов (причём альфа-канал этой текстуры пустой).
Альбедо или просто цвет без учета освещения (альфа-канал содержит Ambient Occlusion).
Нормали (в альфа-канале хранится номер одного из 4 материалов)
Параметры материалов (цвет металла + roughness).
Дополнительные нормали для анизотропных материалов (транслюсентность в альфа-канале — это параметр, показывающий насколько поверхность пропускает свет сквозь себя)

У текстуры эмиссива можно было бы удалить четвертый канал. И тем самым вместо 16 Мб потребуется 12 Мб.
Текстуру альбедо вполне можно было бы хранить как 4 8-битных канала с нормализованными вещественными числами (то есть числами от 0 до 1). Это уменьшило бы эту текстуру в 2 раза. До 8 Мб.
Нормали хранятся в сыром виде. Можно упаковывать их при записи, тем самым снижая количество данных, и распаковывать при чтении [Подробнее можно прочитать тут]. Это, конечно, требует больше времени на выполнение кода, но существенно снижает количество требуемых данных.
Материал принимает всего 4 различных значения, значит, отлично пакуется в 2 бита. Предположим, что эти два бита мы положили к параметрам материалов. Тогда для нормалей остаются 2 канала по 16 бит каждый. Всего 8 Мб для моего разрешения экрана.
Параметры материалов оставим без изменения, за исключением кодирования номера материала в эту же текстуру.
Последняя текстура — параметры для транслюсентных материалов. Первые 3 компоненты — это единичные векторы, значит, их тоже можно закодировать в 2 вещественных числа. Остаётся 3 канала. Причём транслюсентные материалы не эмиссивные. По крайней мере, в захваченных кадрах я такого не видел. Значит, можно объединить эту текстуру с текстурой эмиссива, и на неё мы теперь тратим 0 Мб.
Итого, нам нужно 12 Мб для эмиссива и транслюсентности, 8 Мб для диффуза, 8 Мб для нормалей и 16 для параметров материалов. Всего 44 Мб. Почти в два раза меньше памяти. Думаю, это сильно бы ускорило проход для заполнения G-buffer.
Отсутствие объектов в предварительном проходе
Другая оптимизация, которая могла бы уменьшить количество записываемых данных в G-buffer, — это более агрессивное использование предварительного прохода (prepass). Prepass — это предварительная отрисовка сцены в буфер глубины. Выполняется она с целью уменьшить количество перезаписей пикселей G-buffer’а за счёт отбрасывания пикселей, не прошедших тест глубины. Текущий предварительный проход оптимизирует отрисовку, но можно добиться и лучших результатов.
При записи G-buffer’а некоторые пиксели перерисовываются до 24 раз.

Судя по вызовам драйвера, между prepass«ом и G-buffer пассом нет никаких копирований текстуры глубины или чтений этой текстуры на CPU. Значит, теоретически, всю геометрию, которая рисуется в G-buffer, можно было нарисовать в prepass«е. Таким образом, можно было бы сделать ещё быстрее. И учитывая, что это самый долгий проход во всём кадре, оптимизация не была бы лишней.
Не используется инстанцирование
Оставим пиксельные оптимизации и обратимся к геометрии. Как вы могли заметить (обратите внимание на вызовы DrawIndexed на предыдущем скриншоте), объекты рисуются строго по одному. Это связано с тем, что для отрисовки используется вызов DrawIndexed вместо DrawIndexedInstanced, который позволяет рисовать несколько одинаковых объектов за раз.
А одинаковых объектов тут много. Не вдаваясь в подробности выполнения отдельных вызовов отрисовки и того, в каком порядке и как видеокарта их выполняет, хочу отметить, что при использовании инстанцирования потребовалось бы намного меньше вызовов функций DirectX, а значит меньше команд отправлялось бы на видеокарту. Уже это могло бы дать прирост FPS.
Level of Details
И последняя оптимизация связанная с рисованием сцены — это система level of details. Нет смысла рисовать детализированную геометрию, если она вдалеке и занимает пару десятков пикселей.
Во-первых, субпиксельные треугольники замедляют рендер. Подробнее можете прочитать в данной статье. Во-вторых, в этом нет практического смысла. Например, из почти тысячи треугольников этого объекта мы увидим разве что пару десятков.

Использование менее детальной геометрии могло бы заметно уменьшить количество рисуемых треугольников. Естественно, это ускорило бы рендер.
Полноэкранный SSAO (Screen Space Ambient Occlusion)
Второй по длительности проход после заполнения G-buffer’а — это подготовка текстуры SSAO. Она занимает от 8 до 10 мс. И проблема этого прохода в том, что он полноэкранный.
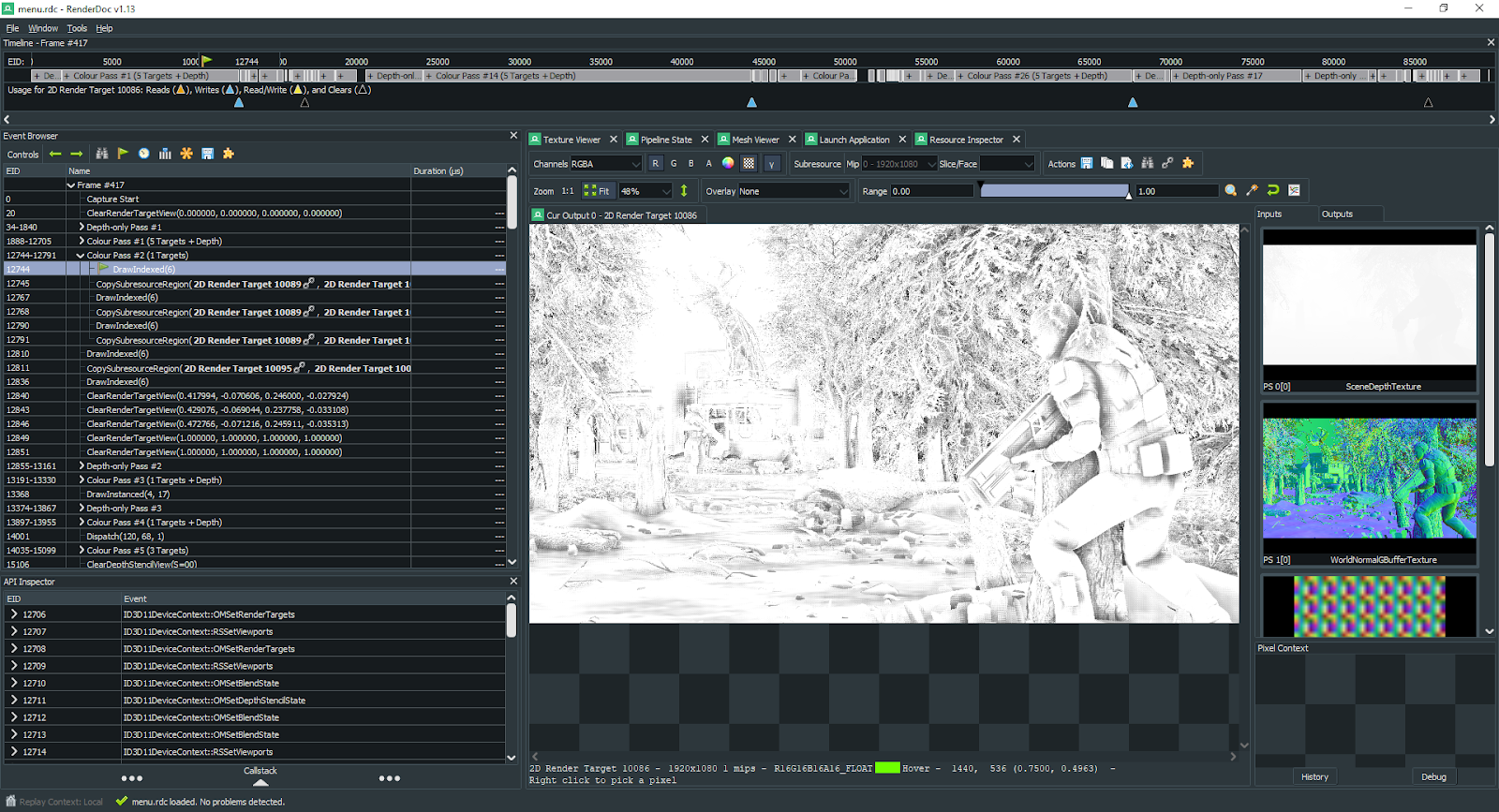
Как я рассказывал на стриме по GTAO, подобные эффекты лучше делать в половинном разрешении экрана. У профессионалов из Activision Blizzard получилось уместить отрисовку AO в половину миллисекунды. Они замеряли на PlayStation 4, а я на ноутбуке и сравнивать время таким образом не до конца корректно. Тем не менее отмечу, что у моей видеокарты в 2.5 раза меньше GFLOPS, а вычисление AO в игре медленнее в 20 раз чем в статье от Blizzard. В общем, думаю можно сделать вывод, что полноэкранный проход для AO может быть значительно ускорен.
Depth of Field
И последнее очевидное узкое место — это depth of field. В XCOM реализован очень интересный подход к этому эффекту. Рисуются 3 миллиона треугольников. Каждый из них соответствует пикселю текстуры в половинном разрешении экрана.

В зависимости от глубины, соответствующей пикселю, выбирается позиция треугольника. И треугольник рисуется в левую или правую часть итоговой текстуры. Таким образом, исходная картинка делится на две на основании глубины.
Огромное количество субпиксельных треугольников, скорее всего, и приводит к долгому времени выполнения этого вызова отрисовки. Проблема в том, что для треугольника, который покрывает только один пиксель, шейдер выполняется для 4 пикселей. Кому интересны подробности, снова рекомендую прочитать эту статью.
Чтобы ускорить данный алгоритм, можно использовать компьют шейдер. Тогда для каждого текселя шейдер будет выполнен один раз.
