Про износ SSD на реальных примерах
Год назад мы добавили в наш агент сбор метрик из S.M. A.R.T. атрибутов дисков на серверах клиентов. В тот момент мы не стали добавлять их в интерфейс и показывать клиентам. Дело в том, что метрики мы снимаем не через через smartctl, а дергаем ioctl прямо из кода, чтобы этот функционал работал без установки smartmontools на серверы клиентов.
Агент снимает не все доступные атрибуты, а только самые значимые на наш взгляд и наименее вендор-специфичные (иначе пришлось бы поддерживать базу дисков, аналогичную smartmontools).
Сейчас наконец дошли руки до того, чтобы проверить, что мы там наснимали. А начать было решено с атрибута «media wearout indicator», который показывает в процентах оставшийся ресурс записи SSD. Под катом несколько историй в картинках о том, как расходуется этот ресурс в реальной жизни на серверах.
Существуют ли убитые SSD?
Бытует мнение, что новые более производительные ssd выходят чаще, чем старые успевают убиться. Поэтому первым делом было интересно посмотреть на самый убитый с точки зрения ресурса записи диск. Минимальное значение по всем ssd всех клиентов — 1%.
Мы сразу же написали клиенту об этом, это оказался дедик в hetzner. Поддержка хостера сразу же заменила ssd:

Очень интересно было бы посмотреть, как выглядит с точки зрения операционной системы ситуация, когда ssd перестает обслуживать запись (мы сейчас ищем возможность провести умышленное издевательство над ssd, чтобы посмотреть на метрики этого сценария:)
Как быстро убиваются SSD?
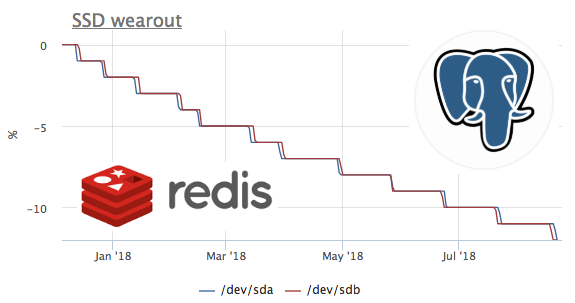
Так как сбор метрик мы начали год назад, а метрики мы не удаляем, есть возможность посмотреть на эту метрику во времени. К сожалению сервер с наибольшей скоростью расхода подключен к okmeter только 2 месяца назад.

На этом графике мы видим, как за 2 месяца сожгли 8% ресурса записи. То есть при таком же профиле записи, этих ssd хватит на 100/(8/2) = 25 месяцев. Много это или мало не знаю, но давайте посмотрим, что за нагрузка там такая?

Видим, что с диском работает только ceph, но мы же понимаем, что ceph это только прослойка. В данном случае у клиента ceph на нескольких нодах выступает хранилищем для кластера kubernetes, посмотрим, что внутри k8s генерирует больше всего записи на диск:

Абсолютные значения не совпадают скорее всего из-за того, что ceph работает в кластере и запись от redis приумножается из-за репликации данных. Но профиль нагрузки позволяет уверенно говорить, что запись иницирует именно redis. Давайте смотреть, что там в редисе происходит:

тут видно, что в среднем выполняется меньше 100 запросов в секунду, которые могут изменять данные. Вспоминаем, что у redis есть 2 способа записывать данные на диск:
- RDB — периодические снэпшоты всей баз на диск, при старте redis читаем последний дамп в память, а данные между дампами мы теряем
- AOF — пишем лог всех изменений, при старте redis проигрывает этот лог и в памяти оказываются все данные, теряем только данные между fsync этого лога
Как все наверное уже догадались в данном случае используется RDB с периодичность дампа 1 минута:

SSD + RAID
По нашим наблюдениям существуют три основных конфигурации дисковой подсистемы серверов с присутствием SSD:
- в сервере 2 SSD собраные в raid-1 и там живет всё
- в сервере есть HDD + raid-10 из ssd, обычно используется для классических РСУБД (система, WAL и часть данных на HDD, а на SSD самые горячие с точки зрения чтения данные)
- в сервере есть отдельностоящие SSD (JBOD), обычно используется для nosql типа кассандры
В случае, если ssd собраны в raid-1, запись идет на оба диска, соответственно износ идет с одинаковой скоростью:
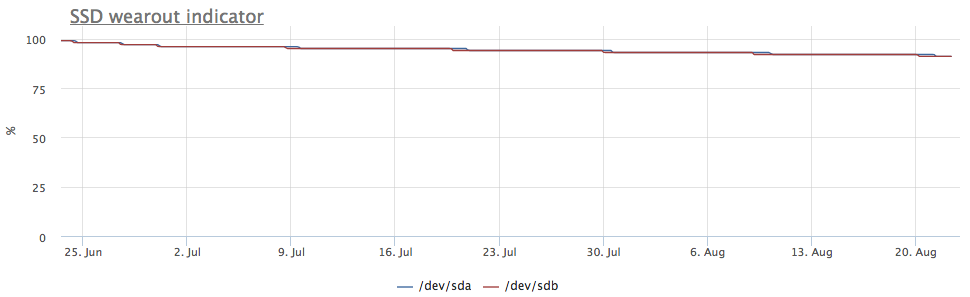
Но на глаза попался сервер, в котором картинка другая:

При этом cмонтированы только партиции mdraid (все массивы raid-1):

По метрикам записи тоже видно, что на /dev/sda долетает больше записи:

Оказалось, что одна из партиций на /dev/sda используется в качестве swap, а swap i/o на этом сервере достаточно заметно:

Износ SSD и PostgreSQL
На самом деле я хотел посмотреть скорость износа ssd при различных нагрузках на запись в Postgres, но как правило на нагруженных базах ssd используются очень аккуратно и массивная запись идет на HDD. Пока искал подходящий кейс, наткнулся на один очень интересный сервер:

Износ двух ssd в raid-1 за 3 месяца составил 4%, но судя по скорости записи WAL данный постгрес пишет меньше 100 Kb/s:
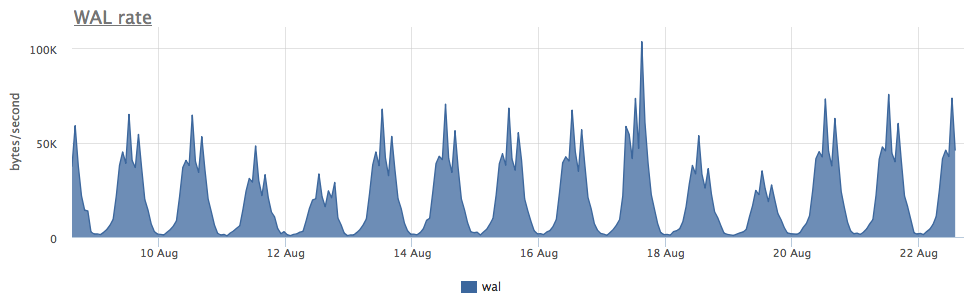
Оказалось, что постгрес активно использует временные файлы, работа с которыми и создает постоянный поток записи на диск:

Так как в postgresql с диагностикой достаточно неплохо, мы можем с точностью до запроса узнать, что именно нам нужно чинить:

Как вы видите тут, это какой-то конкретный SELECT порождает кучу временных файлов. А вообще в постгресе SELECT’ы иногда порождают запись и без всяких временных файлов — вот тут мы уже про это рассказывали.
Итого
- Количество записи на диск, которую создает Redis+RDB зависит не от количества модификаций в базе, а от размера базы + интервала дампов (и вообще, это наибольший уровень write amplification в известных мне хранилищах данных)
- Активно используемый swap на ssd — плохо, но если вам нужно внести jitter в износ ssd (для надежности raid-1), то может сойти за вариант:)
- Помимо WAL и datafiles базы данных могут ещё писать на диск всякие временные данные
Мы в okmeter.io считаем, что для того, чтобы докопаться до причины проблемы инженеру нужно много метрик про все слои инфраструктуры. Мы изо всех сил в этом помогаем:)
