Приручаем многопоточность в Node.js (часть 3: разделяемая память, атомарные операции и блокировки)
В предыдущей части мы остановились на мысли, что минимизировать простой вспомогательных потоков нашего приложения можно, если заставить их самих получать себе задачи, не дожидаясь, пока их загрузит кто-то другой со стороны.
 Threads в разделяемой памяти
Threads в разделяемой памяти
Но тут возникает две проблемы:
как эффективно доставить данные в обрабатывающий поток;
как распределять задачи между активными потоками, чтобы ничего не пропустить, но и дважды не обработать
В этом нам как раз и помогут два рассматриваемых в этой статье концепта работы с многопоточностью: разделяемая (shared) память и потокобезопасные (thread-safe, Atomics) операции над ней.
Разделяемая память
Все наши предыдущие способы обмена информацией с потоками базировались на событийной модели с передачей данных через IPC. Но в такой реализации мы заведомо теряем в производительности, когда должны «звать» какую-то функцию, чтобы что-то передать или получить. А нельзя ли как-то получить прямой доступ к данным, без вот этой избыточной обвязки?
Именно для этого и существует механизм разделяемой памяти, когда одна и та же область физической памяти может быть доступна под разными именами в разных процессах или потоках. В JavaScript за реализацию этого концепта отвечает объект SharedArrayBuffer.
 Схема работы с разделяемой памятью в JavaScript
Схема работы с разделяемой памятью в JavaScript
Воспользуемся тем фактом, что все «задачи» в нашем примере идеально сериализуемы, имеют одинаковый размер и суммарно занимают относительно небольшое пространство 4K x 64KB = 256MB, которое мы можем сделать доступным целиком во вспомогательных потоках.
Для распределения задач между потоками заведем в другом сегменте разделяемой памяти счетчик, который будет хранить «номер» следующей задачи. То есть каждый поток делает n++, на этом счетчике и идет выполнять задачу #n.
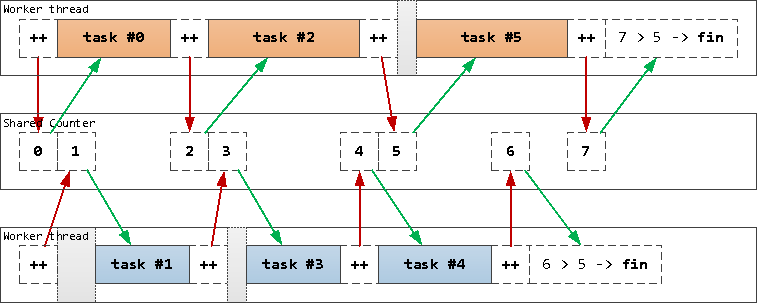 Общий счетчик номера «следующей» задачи
Общий счетчик номера «следующей» задачи
Для работы с разделяемой памятью нам потребуется зафиксировать размеры SharedArrayBuffer-сегментов и передать их вспомогательным потокам:
// ...
const tasksCount = 1 << 12;
const taskSize = 1 << 16;
if (isMainThread) {
// ...
const sharedBufferData = new SharedArrayBuffer(tasksCount * taskSize);
const sharedBufferNext = new SharedArrayBuffer(Uint32Array.BYTES_PER_ELEMENT);
const sharedData = new Uint8Array(sharedBufferData);
const sharedNext = new Uint32Array(sharedBufferNext);
// ...
const worker = new Worker(__filename,
{
workerData : {
data : sharedBufferData
, next : sharedBufferNext
}
}
);
// ...
}
else {
const {data, next} = workerData;
const sharedData = new Uint8Array(data);
const sharedNext = new Uint32Array(next);
// ...
}Обратите внимание, что при порождении потока и передаче ему разделяемого буфера, мы не добавляем его в transferList для не-копирования, поскольку он и так представляет из себя ссылку на сегмент памяти.
Атомарные операции
Теперь давайте разберемся со счетчиком в разделяемой памяти, точнее, с его инкрементом.
Поскольку современные процессоры «любят» очень быстрые, короткие и предсказуемые микрооперации, то наш инкремент разделится на load — загрузку значения из ячейки памяти в регистр, inc — увеличение значения регистра и store — выгрузку значения из регистра в память.
Очень грубо происходящее можно представить такой схемой:
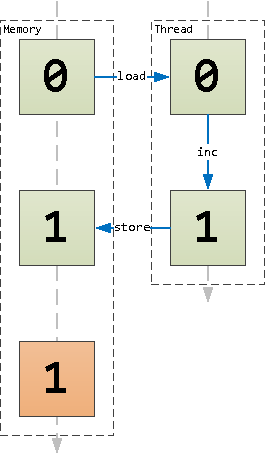 Схема инкремента значения в ячейке памяти
Схема инкремента значения в ячейке памяти
Но как только появляется хотя бы еще один активный поток, мы уже не можем гарантировать, что все микрооперации пройдут в заранее определенном порядке — соответственно, получаем недетерминированный результат:
 В результате двух инкрементов переменная увеличивается на 2… или на 1
В результате двух инкрементов переменная увеличивается на 2… или на 1
Так вот, для получения заведомо понятного результата, и были реализованы операции из модуля Atomics, которые на аппаратном уровне гарантируют последовательность операций над одной и той же ячейкой памяти. Фактически, каждая такая операция пытается предварительно наложить блокировку на ячейку памяти: получилось — проводим операцию и снимаем блокировку, не вышло — ждем, пока не сможем блокировку наложить:
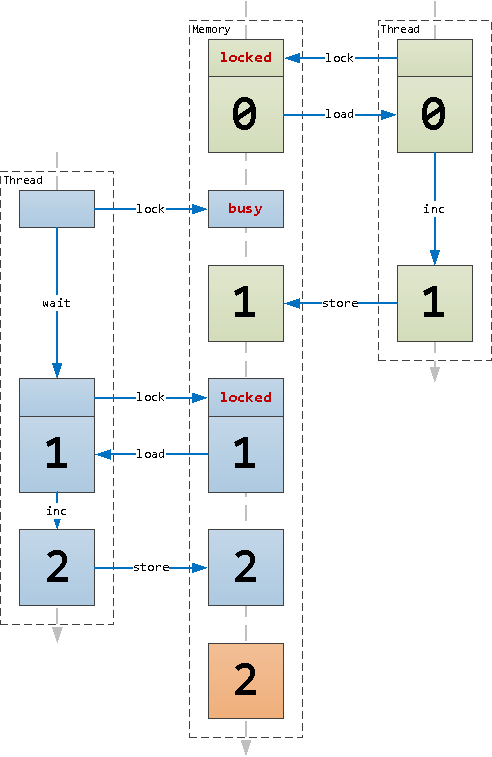 Блокировка ячейки памяти при Atomics-операциях
Блокировка ячейки памяти при Atomics-операциях
Операции модуля Atomics делятся на:
арифметико-логические:
add, sub, and, or, xorобменные:
exchange, compareExchangeчтения-записи:
load, storeработы с блокировками:
isLockFree, notify, wait, waitAsync
Назначение первых трех групп достаточно очевидно, а как можно использовать последнюю, хорошо описано в блоге разработчиков V8.
Получается, что нам надо использовать внутри потока не «просто инкремент», а Atomics.add:
parentPort.on('message', () => {
do {
const id = Atomics.add(sharedNext, 0, 1); // потокобезопасный инкремент
if (id >= tasksCount) { // обработали все задачи
break;
}
processMessage({id, data : sharedData.subarray(id * taskSize, (id + 1) * taskSize)});
}
while (true); // бесконечный цикл обработки, пока задачи есть
});Обратите внимание, что для получения из общей памяти тела нашего сообщения, мы используем метод .subarray (), а не .slice (), поскольку второй копирует контент, а первый — просто предоставляет новую ссылку на тот же буфер.
Достаточно очевидно, что если потоки вынуждены ждать друг друга при атомарной операции (на первой схеме с потоками это как раз серые интервалы), мы должны заметить некоторое падение производительности при их совместной работе. Соберем все вместе и проверим:
Полный код и результаты тестов
const {
Worker
, isMainThread
, parentPort
, workerData
} = require('node:worker_threads');
const {
randomBytes
, createHash
} = require('node:crypto');
const hrtime = process.hrtime.bigint;
const tasksCount = 1 << 12;
const taskSize = 1 << 16;
if (isMainThread) {
const tsg = hrtime();
const messages = Array(tasksCount).fill().map(_ => randomBytes(taskSize));
console.log('generated:', Number(hrtime() - tsg)/1e6 | 0, 'ms');
const hashes = messages.map(() => undefined);
let remain;
const workers = [];
let active = 1;
let tsh;
// выделяем сегменты разделяемой памяти
const sharedBufferData = new SharedArrayBuffer(tasksCount * taskSize);
const sharedBufferNext = new SharedArrayBuffer(Uint32Array.BYTES_PER_ELEMENT);
const sharedData = new Uint8Array(sharedBufferData);
const sharedNext = new Uint32Array(sharedBufferNext);
process
.on('test:start', () => {
hashes.fill();
remain = hashes.length;
// очищаем общую память данных и обнуляем счетчик задач
sharedData.fill(0);
Atomics.store(sharedNext, 0, 0);
workers.forEach(worker => worker.eLU = worker.performance.eventLoopUtilization());
tsh = hrtime();
// заполняем сегмент данных телами сообщений
messages.forEach((data, id) => {
sharedData.set(data, id * taskSize);
});
// "дергаем" все нужные потоки
workers.slice(0, active).forEach(worker => worker.postMessage(undefined));
})
.on('test:end', () => {
const duration = hrtime() - tsh;
workers.forEach(worker => worker.util = worker.performance.eventLoopUtilization(worker.eLU).utilization);
const avg = workers.slice(0, active).reduce((sum, worker) => sum + worker.util, 0)/active;
console.log(
'hashed ' + active.toString().padStart(2) + ':'
, (Number(duration)/1e6 | 0).toString().padStart(4)
, 'ms | ' + (avg * 100 | 0) + ' | '
, workers.map(
worker => (worker.util * 100 | 0).toString().padStart(2)
).join(' ')
);
if (active < n) {
active++;
process.emit('test:start');
}
else {
process.exit();
}
});
const n = 16;
Promise.all(
Array(n).fill().map(_ => new Promise((resolve, reject) => {
// передаем в поток ссылки на сегменты разделяемой памяти
const worker = new Worker(__filename,
{
workerData : {
data : sharedBufferData
, next : sharedBufferNext
}
}
);
worker
.on('online', () => resolve(worker))
.on('message', ({id, hash}) => {
hashes[id] = hash;
if (!--remain) {
process.emit('test:end');
}
});
}))
)
.then((result) => {
workers.push(...result);
process.emit('test:start');
});
}
else {
// восстанавливаем TypedArray на разделяемых сегментах
const {data, next} = workerData;
const sharedData = new Uint8Array(data);
const sharedNext = new Uint32Array(next);
const processMessage = ({id, data}) => parentPort.postMessage({id, hash : createHash('sha256').update(data).digest('hex')});
parentPort.on('message', () => {
do {
const id = Atomics.add(sharedNext, 0, 1); // потокобезопасный инкремент
if (id >= tasksCount) { // обработали все задачи
break;
}
processMessage({id, data : sharedData.subarray(id * taskSize, (id + 1) * taskSize)}); // не .slice()!
}
while (true); // бесконечный цикл обработки, пока задачи есть
});
}generated: 278 ms
hashed 1: 996 ms | 95 | 95 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
hashed 2: 523 ms | 91 | 91 91 0 0 0 0 0 0 0 0 0 0 0 0 0 0
hashed 3: 374 ms | 86 | 86 86 86 0 0 0 0 0 0 0 0 0 0 0 0 0
hashed 4: 297 ms | 82 | 82 82 82 82 0 0 0 0 0 0 0 0 0 0 0 0
hashed 5: 308 ms | 81 | 83 83 83 83 73 0 0 0 0 0 0 0 0 0 0 0
hashed 6: 287 ms | 79 | 82 82 82 82 71 71 0 0 0 0 0 0 0 0 0 0
hashed 7: 291 ms | 77 | 82 82 82 82 71 71 71 0 0 0 0 0 0 0 0 0
hashed 8: 290 ms | 77 | 83 83 83 83 72 72 71 71 0 0 0 0 0 0 0 0
hashed 9: 295 ms | 76 | 83 83 83 83 72 72 72 72 62 0 0 0 0 0 0 0
hashed 10: 299 ms | 73 | 82 82 82 80 72 72 72 68 61 61 0 0 0 0 0 0
hashed 11: 290 ms | 72 | 82 82 82 82 71 71 70 70 60 60 59 0 0 0 0 0
hashed 12: 307 ms | 71 | 82 82 82 81 71 71 71 71 61 60 60 60 0 0 0 0
hashed 13: 296 ms | 67 | 80 80 80 80 69 69 69 67 59 58 58 57 48 0 0 0
hashed 14: 301 ms | 67 | 82 81 81 81 70 70 70 70 60 60 59 59 49 49 0 0
hashed 15: 299 ms | 67 | 82 82 82 82 72 71 71 71 61 61 61 61 50 49 50 0
hashed 16: 296 ms | 63 | 80 80 80 80 69 69 69 69 58 58 58 57 47 47 46 45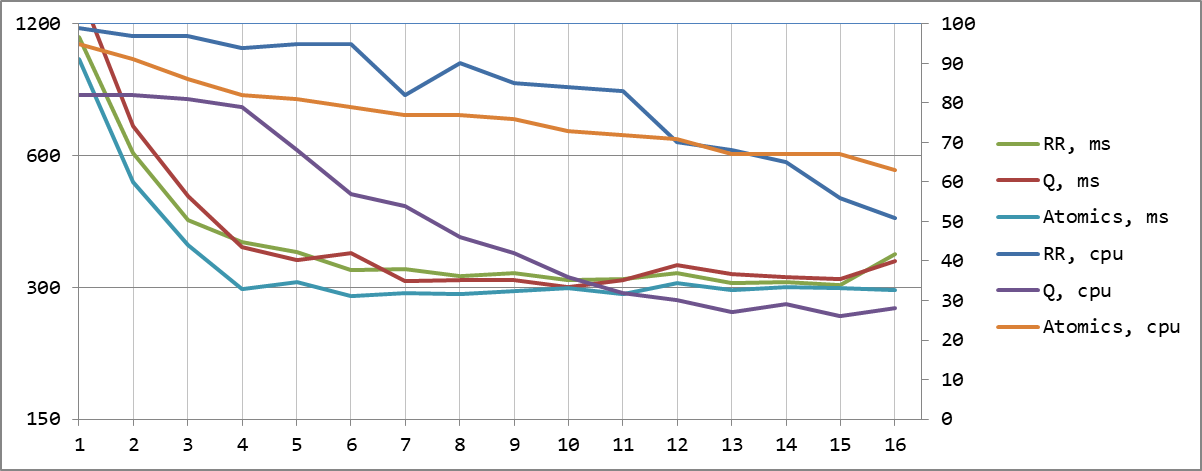 Atomics-счетчик номера задачи и доступ через разделяемую память
Atomics-счетчик номера задачи и доступ через разделяемую память
Теперь мы смогли получить не только минимальное абсолютное время обработки, но и сделали это наиболее эффективно именно при 4 потоках, по числу ядер CPU. А дальнейшее их увеличение уже не дает никакого эффекта, кроме роста суммарной нагрузки, вызванной необходимостью ждать все дольше и дольше.
Если мы построим графики результирующего времени и суммарного времени работы всех потоков, результат станет еще нагляднее. До количества ядер суммарное время не меняется, а итоговое существенно падает, а потом, наоборот, общее не меняется, а суммарное (duration * cpuN * cpuAvg%) начинает расти:
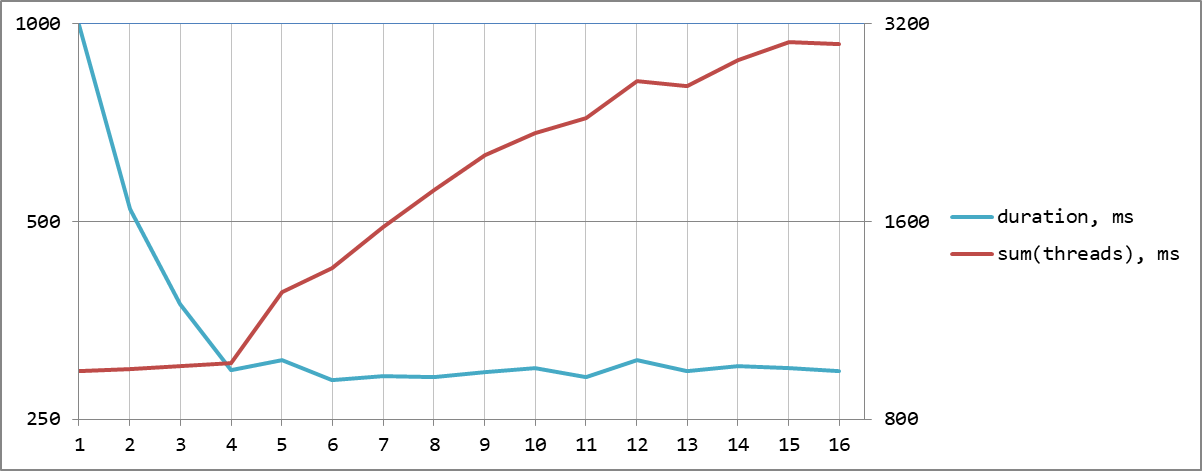 Итоговое и суммарное время активности всех потоков, 4 ядраПро распределение нагрузки между потоками
Итоговое и суммарное время активности всех потоков, 4 ядраПро распределение нагрузки между потоками
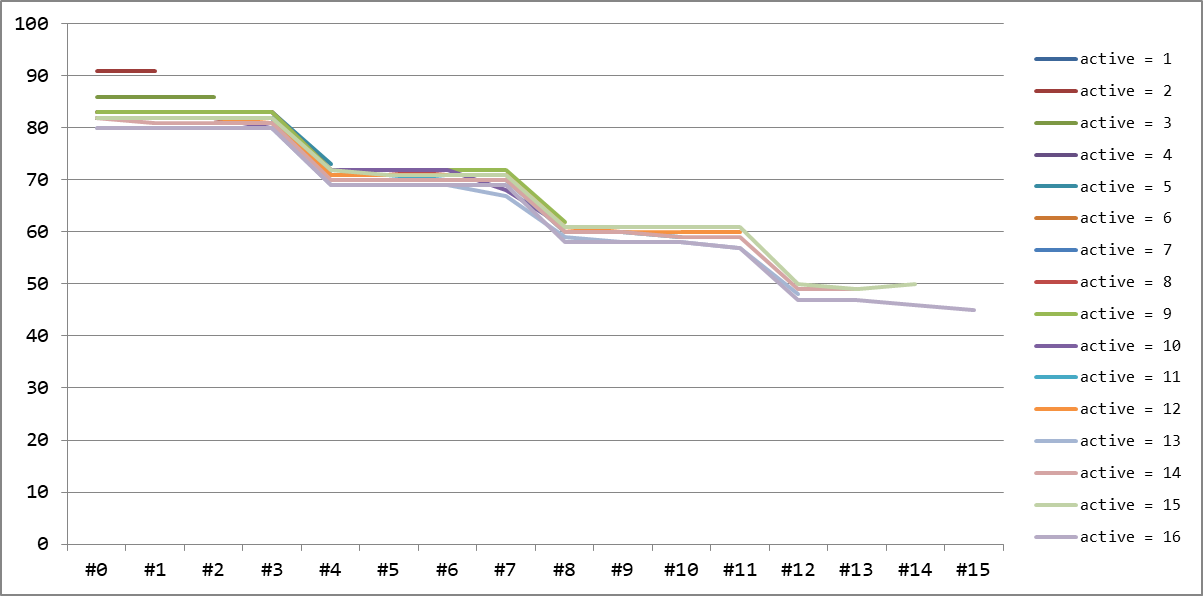 Загрузка каждого потока от количества одновременно активных
Загрузка каждого потока от количества одновременно активныхПо графику распределения загрузки достаточно хорошо видно, что если первые 4 потока работают всегда на 80–85%, то следующие — 70–75%, дальше 55–60% и потом уже только 45–50%. То есть все равно основную долю работы выполняют именно первые 4 потока, соответствующие ядрам процессора, а остальным приходится лишь ждать.
Про влияние копирования памяти: .subarray () vs .slice ()
Выше я акцентировал внимание на использовании функции .subarray(), поскольку при этом не производится копирования данных указанного сегмента массива. Давайте оценим, насколько это действительно дорого.
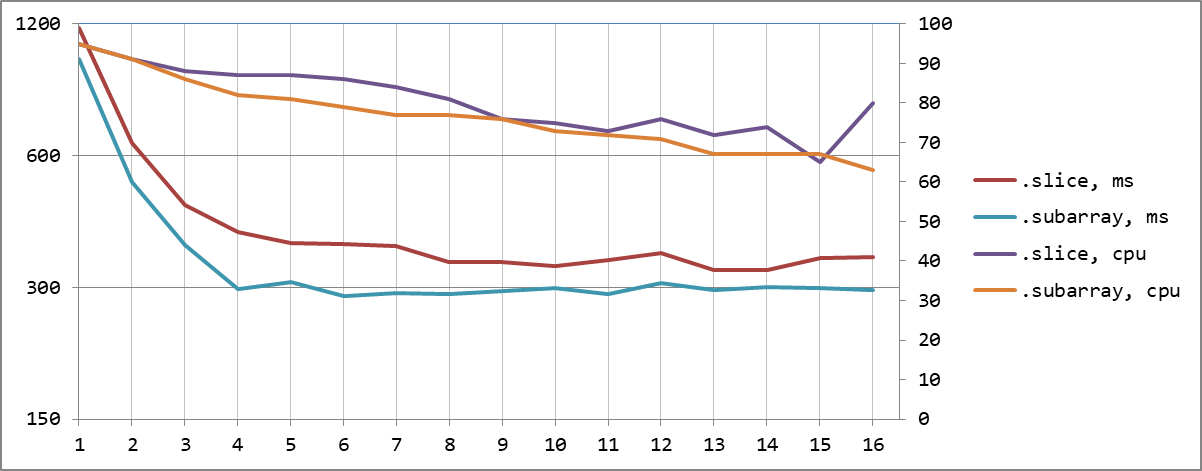 .slice копирует память, .subarray — нет
.slice копирует память, .subarray — нетПри 4 потоках на копировании внутри.slice мы теряем до 35% времени!
Использование блокировок
Конечно, у нас тут получился максимально «нечестный» тест, когда все данные заранее идеально размещаются в разделяемой памяти (и требуется ее для этого много-много). В работе реальных приложений такого практически не встречается, поэтому давайте рассмотрим более жизненную модель — когда каждый из потоков «владеет» своим собственным, разделяемым только с основным, сегментом памяти.
При такой схеме у потоков нет причины для ожидания на общем счетчике — поскольку у них нет вообще ничего общего. Так давайте заставим поток просто ждать, пока ему не дадут хоть какую-то работу — для этого нам отлично подойдет Atomics.wait ():
const THREAD_FREE = -1;
// ...
// код вспомогательного потока
else {
const {data, lock} = workerData;
const sharedData = new Uint8Array(data);
const sharedLock = new Int32Array(lock);
do {
const lock = Atomics.wait(sharedLock, 0, THREAD_FREE); // ждем на блокировке до уведомления
parentPort.postMessage({id : sharedLock[0], hash : createHash('sha256').update(sharedData).digest('hex')});
sharedLock[0] = THREAD_FREE; // восстанавливаем значение блокировки
Atomics.notify(sharedLock, 0, 1); // уведомляем основной поток о своей готовности
}
while (true); // бесконечный цикл
}Данный код является классическим JavaScript-антипаттерном: бесконечный синхронный цикл. Но, поскольку он происходит внутри вспомогательного потока, на работу самого приложения он не сказывается, поэтому вполне допустим.
По схеме, аналогичной предыдущему варианту, мы используем тут два разделяемых сегмента: под данные и под блокировку вместо счетчика. На ячейке с блокировкой мы ждем появления в ней id следующей задачи.
То есть в момент начала ожидания блокировки у нас может оказаться два варианта:
там уже стоит не
THREAD_FREE-значение, которое мы поставили при завершении предыдущей итерации — значит, основной поток уже успел отработать и положить нам туда работу;там все еще стоит
THREAD_FREE, и мы просто подождем, пока к нам не придет уведомление.
Фактически, этот код не создает никаких конфликтов на разделяемой памяти, поскольку обмен .wait/.notify разрешает работу с данными только одному потоку — поэтому вместо Atomics.store() мы используем «обычные» операции.
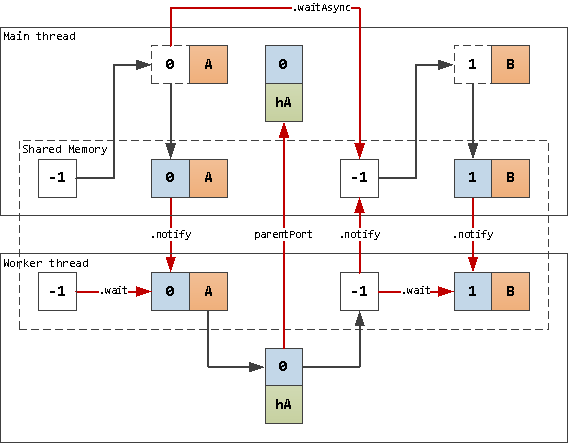 Схема с обменом блокировками
Схема с обменом блокировками
Заметим, что на стороне основного потока мы не можем позволить себе блокировать все выполнение синхронным Atomics.wait (), поскольку ждать мы должны сразу несколько блокировок от разных потоков, поэтому используем появившийся в Node.js 16 асинхронный вариант Atomics.waitAsync ().
В результате, в нем получается почти такая же модель с очередью и пулом потоков из предыдущей статьи, где вместо .postMessage/.on('message') мы используем .notify/.wait:
#shareMessage(worker, {id, data}) {
// передаем ID и тело задачи через разделяемую память конкретного потока
worker.data.set(data, 0);
worker.lock[0] = id;
// уведомляем его, что можно поработать
Atomics.notify(worker.lock, 0, 1);
const lock = Atomics.waitAsync(worker.lock, 0, id);
if (lock.value === 'not-equal') {
// если значение изменилось, то поток уже обработал задачу, и реагируем сразу
this.#onMessage(worker);
}
else {
// иначе ждем разрешения Promise блокировки
lock.value.then(result => {
this.#onMessage(worker);
});
}
}Полный код и результаты тестов
const {
Worker
, isMainThread
, parentPort
, workerData
} = require('node:worker_threads');
const {
randomBytes
, createHash
} = require('node:crypto');
const hrtime = process.hrtime.bigint;
const THREAD_FREE = -1;
const EventEmitter = require('events');
class WorkersPool extends EventEmitter {
#queue;
#workersPool;
constructor({queue, workersPool}) {
super();
this.#queue = queue;
this.#workersPool = [...workersPool];
}
#shareMessage(worker, {id, data}) {
// передаем ID и тело задачи через разделяемую память конкретного потока
worker.data.set(data, 0);
worker.lock[0] = id;
// уведомляем его, что можно поработать
Atomics.notify(worker.lock, 0, 1);
const lock = Atomics.waitAsync(worker.lock, 0, id);
if (lock.value === 'not-equal') {
// если значение изменилось, то поток уже обработал задачу, и реагируем сразу
this.#onMessage(worker);
}
else {
// иначе ждем разрешения Promise блокировки
lock.value.then(result => {
this.#onMessage(worker);
});
}
}
#onMessage(worker) {
const msg = this.#queue.shift();
if (msg) {
this.#shareMessage(worker, msg);
}
else {
this.#workersPool.push(worker);
}
}
postMessage(msg) {
const worker = this.#workersPool.pop();
if (worker) {
this.#shareMessage(worker, msg);
}
else {
this.#queue.push(msg);
}
}
}
if (isMainThread) {
const taskSize = 1 << 16;
const tsg = hrtime();
const messages = Array(1 << 12).fill().map(_ => randomBytes(taskSize));
console.log('generated:', Number(hrtime() - tsg)/1e6 | 0, 'ms');
const hashes = messages.map(() => undefined);
let remain;
const workers = [];
let active = 1;
let tsh;
process
.on('test:start', () => {
hashes.fill();
remain = hashes.length;
workers.forEach(worker => worker.eLU = worker.performance.eventLoopUtilization());
tsh = hrtime();
// пул потоков с эффективной очередью
const Pow2Buffer = require('./Pow2Buffer');
pool = new WorkersPool({
queue : new Pow2Buffer(8, 16)
, workersPool : workers.slice(0, active)
});
// сообщения отправляем в пул
messages.forEach((data, id) => {
pool.postMessage({id, data});
});
})
.on('test:end', () => {
const duration = hrtime() - tsh;
workers.forEach(worker => worker.util = worker.performance.eventLoopUtilization(worker.eLU).utilization);
const avg = workers.slice(0, active).reduce((sum, worker) => sum + worker.util, 0)/active;
console.log(
'hashed ' + active.toString().padStart(2) + ':'
, (Number(duration)/1e6 | 0).toString().padStart(4)
, 'ms | ' + (avg * 100 | 0) + ' | '
, workers.map(
worker => (worker.util * 100 | 0).toString().padStart(2)
).join(' ')
);
if (active < n) {
active++;
process.emit('test:start');
}
else {
process.exit();
}
});
const n = 16;
Promise.all(
Array(n).fill().map((_, idx) => new Promise((resolve, reject) => {
// выделяем сегменты разделяемой памяти
const sharedBufferData = new SharedArrayBuffer(taskSize);
const sharedBufferLock = new SharedArrayBuffer(Int32Array.BYTES_PER_ELEMENT);
// инициализируем "пустое" состояние блокировки
const lock = new Int32Array(sharedBufferLock);
lock.fill(THREAD_FREE);
// передаем в поток ссылки на сегменты разделяемой памяти
const worker = new Worker(__filename,
{
workerData : {
data : sharedBufferData
, lock : sharedBufferLock
}
}
);
worker.data = new Uint8Array(sharedBufferData);
worker.lock = lock;
worker
.on('online', () => resolve(worker))
.on('message', ({id, hash}) => {
hashes[id] = hash;
if (!--remain) {
process.emit('test:end');
}
});
}))
)
.then((result) => {
workers.push(...result);
process.emit('test:start');
});
}
else {
const {data, lock} = workerData;
const sharedData = new Uint8Array(data);
const sharedLock = new Int32Array(lock);
do {
const lock = Atomics.wait(sharedLock, 0, THREAD_FREE); // ждем на блокировке до уведомления
parentPort.postMessage({id : sharedLock[0], hash : createHash('sha256').update(sharedData).digest('hex')});
sharedLock[0] = THREAD_FREE; // восстанавливаем значение блокировки
Atomics.notify(sharedLock, 0, 1); // уведомляем основной поток о своей готовности
}
while (true); // бесконечный цикл
}generated: 280 ms
hashed 1: 1212 ms | 100 | 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100
hashed 2: 595 ms | 100 | 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100
hashed 3: 433 ms | 100 | 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100
hashed 4: 303 ms | 100 | 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100
hashed 5: 307 ms | 100 | 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100
hashed 6: 326 ms | 100 | 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100
hashed 7: 302 ms | 100 | 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100
hashed 8: 308 ms | 100 | 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100
hashed 9: 323 ms | 100 | 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100
hashed 10: 317 ms | 100 | 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100
hashed 11: 292 ms | 100 | 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100
hashed 12: 311 ms | 100 | 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100
hashed 13: 316 ms | 100 | 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100
hashed 14: 324 ms | 100 | 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100
hashed 15: 306 ms | 100 | 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100
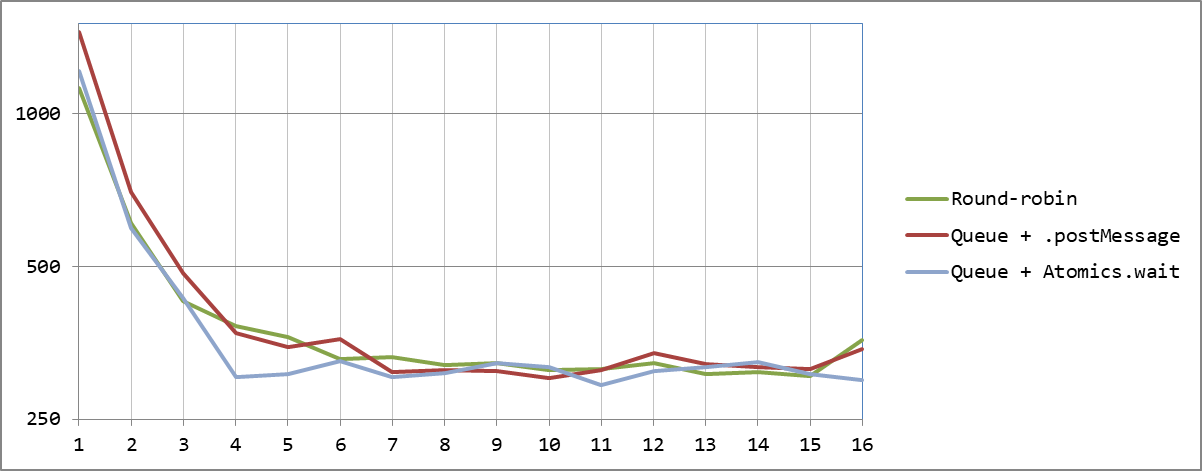
hashed 16: 298 ms | 100 | 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100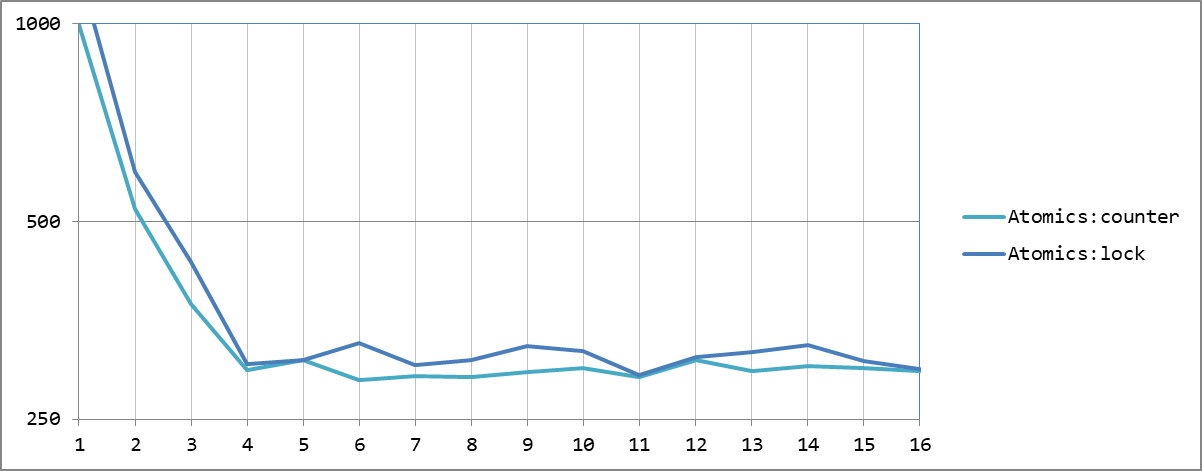 .wait/.notify против разделяемого счетчика
.wait/.notify против разделяемого счетчика
Все-таки потери на необходимости «подсовывать» следующую задачу со стороны основного потока есть, но при количестве потоков, совпадающем с количеством ядер, они практически незаметны. Так что результат становится наиболее эффективным среди всех рассмотренных нами методов:
Зато оценка загрузки потоков преподносит нам сюрприз — они все загружены на 100%! Так что, это самый «тяжелый» способ?… Вовсе нет! Ведь мы оценивали степень загрузки Event Loop, а для полностью синхронного кода она вполне ожидаемо равна 100%, хотя существенную долю времени поток не делал ничего, не грузил CPU, а просто ждал на блокировке.
Было бы неплохо использовать Atomics.waitAsync и во вспомогательных потоках, но MDN говорит нам…
Unlike
Atomics.wait(),waitAsyncis non-blocking and usable on the main thread.
Как еще можно уменьшить простой потоков в схеме с блокировками? Ну, например, писать сразу до двух задач в буфер и иметь две ячейки блокировок для каждого потока. Но это уже существенное усложнение кода, и история для другой статьи. А эта серия рассказов про варианты построения многопоточных приложений в Node.js — завершена.
