Принимаем 10 000 ивентов в Яндекс.Облаке. Часть 2
И снова здравствуйте! Продолжаем нашу серию статей про то, как мы щупали Яндекс.Облако.
Давайте вспомним план, по которому мы с вами двигаемся:
1 часть. Мы определились с ТЗ и архитектурой решения, написали приложение на golang.
2 часть (вы сейчас здесь). Выливаем наше приложение на прод, делаем масштабируемым и тестируем нагрузку.
3 часть. Попробуем разобраться, зачем нам нужно хранить сообщения в буфере, а не в файлах, а также сравним между собой kafka, rabbitmq и yandex queue service.
4 часть. Будем разворачивать Clickhouse кластер, писать стриминг для перекладывания туда данных из буфера, настроим визуализацию в datalens.
5 часть. Приведем всю инфраструктуру в должный вид — настроим ci/cd, используя gitlab ci, подключим мониторинг и service discovery с помощью consul и prometheus.

Ну что, переходим к нашим задачкам.
Выливаемся в production
В 1 части мы собрали приложение, оттестировали его, а также загрузили образ в приватный container registry, готовый для развертывания.
Вообще следующие шаги должны быть практически очевидными — создаем виртуалки, настраиваем load balancer и прописываем DNS имя с проксированием на cloudflare. Но боюсь, такой вариант не сильно соответствует нашему техническому заданию. Мы хотим уметь масштабировать наш сервис в случае увеличения нагрузки и выкидывать из него битые ноды, которые не могут обслуживать запросы.
Для масштабирования мы будем использовать группы машин (instance groups), доступные в compute cloud. Они позволяют создавать виртуалки по шаблону, следить за их доступностью с помощью health check«ов, а также автоматически увеличивать количество узлов в случае возрастания нагрузки. Подробнее здесь.
Встает только один вопрос — какой шаблон использовать для виртуальной машины? Конечно, можно установить linux, настроить его, сделать образ и залить в хранилище образов в Яндекс.Облаке. Но для нас это долгий и непростой путь. В процессе рассмотрения различных образов, доступных при создании виртуалки, мы наткнулись на интересный экземпляр — container optimized image (https://cloud.yandex.ru/docs/cos/concepts/). Он позволяет запустить один docker контейнер в сетевом режиме host. То есть при создании виртуалки указывается примерно такая спецификация для образа container optimized image:
spec:
containers:
- name: api
image: vozerov/events-api:v1
command:
- /app/app
args:
- -kafka=kafka.ru-central1.internal:9092
securityContext:
privileged: false
tty: false
stdin: false
restartPolicy: Always
И после старта виртуальной машины этот контейнер будет скачан и запущен локально.
Схема вырисовывается вполне интересная:
- Мы создаем instance group с автоматическим масштабированием при превышении 60% cpu usage.
- В качестве шаблона указываем виртуальную машину с образом container optimized image и параметрами для запуска нашего Docker-контейнера.
- Создаем load balancer, который будет смотреть на нашу instance group и автоматически обновляться при добавлении или удалении виртуальных машин.
- Приложение будет мониториться и как instance group, и самим балансировщиком, который выкинет недоступные виртуалки из балансировки.
Звучит как план!
Попробуем создать instance group с помощью terraform. Все описание лежит в instance-group.tf, прокомментирую основные моменты:
- service account id будет использоваться для создания и удаления виртуалок. Кстати, нам его придется создать.
service_account_id = yandex_iam_service_account.instances.id - Данные для указания спецификации контейнера вынесены в отдельный файл spec.yml, где помимо прочего указывается образ, который необходимо запустить. Поскольку внутренний registry у нас появился во время написания данной статьи, а гит-репозиторий я выложил в паблик на гитхаб — на данный момент там прописан образ с публичного docker hub. Чтобы использовать образ из нашего репозитория, достаточно прописать путь до него —
metadata = { docker-container-declaration = file("spec.yml") ssh-keys = "ubuntu:${file("~/.ssh/id_rsa.pub")}" } - Укажем еще один service account id, он будет использоваться образом container optimized image, чтобы пройти аутентификацию в container registry и скачать образ нашего приложения. Сервисный аккаунт с доступом к registry мы уже создавали, поэтому будем использовать его:
service_account_id = yandex_iam_service_account.docker.id - Scale policy. Самая интересная часть:
autoscale { initialsize = 3 measurementduration = 60 cpuutilizationtarget = 60 minzonesize = 1 maxsize = 6 warmupduration = 60 stabilizationduration = 180 }
Здесь мы определяем политику масштабирования наших виртуалок. Есть два варианта — либо fixed_scale с фиксированным числом виртуальных машин, либо auth_scale.Основные параметры такие:
initial size — первоначальный размер группы;
measurement_duration — период изменения целевого показателя;
cpu_utilization_target — целевое значение показателя, при большем значении которого надо расширить группу;
min_zone_size — минимальное количество нод в одной зоне доступности — планировщик не будет удалять ноды, чтобы их количество стало ниже этого значения;
max_size — максимальное количество нод в группе;
warmup_duration — период прогрева, в течение которого планировщик не будет брать значения метрик с данной ноды, а будет использовать среднее значение в группе;
stabilization_duration — период стабилизации — после увеличения количества нод в группе в течение указанного промежутка времени балансировщик не будет удалять созданные машины, даже если целевой показатель опустился ниже порогового значения.Теперь простыми словами о наших параметрах. На начальном этапе создаем 3 машинки (initial_size), минимум по одной в каждой зоне доступности (min_zone_size). Измеряем показатель cpu раз в минуту на всех машинках (measurement_duration). Если среднее значение превышает 60% (cpu_utilization_target), то создаем новые виртуалки, но не больше шести (max_size). После создания в течение 60 секунд не собираем метрики с новой машинки (warmup_duration), поскольку во время старта она может использовать достаточно много cpu. А 120 секунд после создания новой машинки не удаляем ничего (stabilization_duration), даже если среднее значение метрик в группе стало ниже 60% (cpu_utilization_target).
Подробнее о масштабировании — https://cloud.yandex.ru/docs/compute/concepts/instance-groups/policies#auto-scale-policy
- Allocation policy. Указывает, в каких зонах доступности создавать наши виртуальные машины, — используем все три доступных зоны.
allocationpolicy { zones = ["ru-central1-a", "ru-central1-b", "ru-central1-c"] } - Политика деплоя машинок:
deploy_policy { maxunavailable = 1 maxcreating = 1 maxexpansion = 1 maxdeleting = 1 }
max_creating — максимальное число одновременно создаваемых машин;
max_deleting — максимальное число одновременно удаляемых машин;
max_expansion — на какое число виртуалок можно превысить размер группы при обновлении;
max_unavailable — максимальное число виртуалок в статусе RUNNING, которые могут быть удалены;Подробнее о параметрах — https://cloud.yandex.ru/docs/compute/concepts/instance-groups/policies#deploy-policy
- Настройки балансировщика:
load_balancer { target_group_name = "events-api-tg" }
При создании instance group можно создать и целевую группу для балансировщика нагрузки. Она будет направлена на относящиеся к ней виртуальные машины. В случае удаления ноды будут выводиться из балансировки, а при создании — добавляться в балансировку после прохождения проверок состояния.
Вроде все основное прописали — давайте создавать сервисный аккаунт для instance group и, собственно, саму группу.
vozerov@mba:~/events/terraform (master *) $ terraform apply -target yandex_iam_service_account.instances -target yandex_resourcemanager_folder_iam_binding.editor
... skipped ...
Apply complete! Resources: 2 added, 0 changed, 0 destroyed.
vozerov@mba:~/events/terraform (master *) $ terraform apply -target yandex_compute_instance_group.events_api_ig
... skipped ...
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
Группа создалась — можно посмотреть и проверить:
vozerov@mba:~/events/terraform (master *) $ yc compute instance-group list
+----------------------+---------------+------+
| ID | NAME | SIZE |
+----------------------+---------------+------+
| cl1s2tu8siei464pv1pn | events-api-ig | 3 |
+----------------------+---------------+------+
vozerov@mba:~/events/terraform (master *) $ yc compute instance list
+----------------------+---------------------------+---------------+---------+----------------+-------------+
| ID | NAME | ZONE ID | STATUS | EXTERNAL IP | INTERNAL IP |
+----------------------+---------------------------+---------------+---------+----------------+-------------+
| ef3huodj8g4gc6afl0jg | cl1s2tu8siei464pv1pn-ocih | ru-central1-c | RUNNING | 130.193.44.106 | 172.16.3.3 |
| epdli4s24on2ceel46sr | cl1s2tu8siei464pv1pn-ipym | ru-central1-b | RUNNING | 84.201.164.196 | 172.16.2.31 |
| fhmf37k03oobgu9jmd7p | kafka | ru-central1-a | RUNNING | 84.201.173.41 | 172.16.1.31 |
| fhmh4la5dj0m82ihoskd | cl1s2tu8siei464pv1pn-ahuj | ru-central1-a | RUNNING | 130.193.37.94 | 172.16.1.37 |
| fhmr401mknb8omfnlrc0 | monitoring | ru-central1-a | RUNNING | 84.201.159.71 | 172.16.1.14 |
| fhmt9pl1i8sf7ga6flgp | build | ru-central1-a | RUNNING | 84.201.132.3 | 172.16.1.26 |
+----------------------+---------------------------+---------------+---------+----------------+-------------+
vozerov@mba:~/events/terraform (master *) $
Три ноды с кривыми именами — это наша группа. Проверяем, что приложения на них доступны:
vozerov@mba:~/events/terraform (master *) $ curl -D - -s http://130.193.44.106:8080/status
HTTP/1.1 200 OK
Date: Mon, 13 Apr 2020 16:32:04 GMT
Content-Length: 3
Content-Type: text/plain; charset=utf-8
ok
vozerov@mba:~/events/terraform (master *) $ curl -D - -s http://84.201.164.196:8080/status
HTTP/1.1 200 OK
Date: Mon, 13 Apr 2020 16:32:09 GMT
Content-Length: 3
Content-Type: text/plain; charset=utf-8
ok
vozerov@mba:~/events/terraform (master *) $ curl -D - -s http://130.193.37.94:8080/status
HTTP/1.1 200 OK
Date: Mon, 13 Apr 2020 16:32:15 GMT
Content-Length: 3
Content-Type: text/plain; charset=utf-8
ok
vozerov@mba:~/events/terraform (master *) $
К слову, можно зайти на виртуалки с логином ubuntu и посмотреть логи контейнера и как он запущен.
Для балансировщика также создалась целевая группа, на которую можно отправлять запросы:
vozerov@mba:~/events/terraform (master *) $ yc load-balancer target-group list
+----------------------+---------------+---------------------+-------------+--------------+
| ID | NAME | CREATED | REGION ID | TARGET COUNT |
+----------------------+---------------+---------------------+-------------+--------------+
| b7rhh6d4assoqrvqfr9g | events-api-tg | 2020-04-13 16:23:53 | ru-central1 | 3 |
+----------------------+---------------+---------------------+-------------+--------------+
vozerov@mba:~/events/terraform (master *) $
Давайте уже создадим балансировщик и попробуем пустить на него трафик! Этот процесс описан в load-balancer.tf, ключевые моменты:
- Указываем, какой внешний порт будет слушать балансировщик и на какой порт отправлять запрос к виртуальным машинам. Указываем тип внешнего адреса — ip v4. На данный момент балансировщик работает на транспортном уровне, поэтому балансировать он может только tcp / udp соединения. Так что прикручивать ssl придется либо на своих виртуалках, либо на внешнем сервисе, который умеет https, — например, cloudflare.
listener { name = "events-api-listener" port = 80 target_port = 8080 external_address_spec { ipversion = "ipv4" } } healthcheck { name = "http" http_options { port = 8080 path = "/status" } }
Healthchecks. Здесь мы указываем параметры проверки наших узлов — проверяем по http url /status на порту 8080. Если проверка будет провалена, то машинка будет выкинута из балансировки.Подробнее про балансировщик нагрузки — cloud.yandex.ru/docs/load-balancer/concepts. Из интересного — вы можете подключить услугу защиты от DDOS на балансировщике. Тогда на ваши сервера будет приходить уже очищенный трафик.
Создаем:
vozerov@mba:~/events/terraform (master *) $ terraform apply -target yandex_lb_network_load_balancer.events_api_lb
... skipped ...
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
Вытаскиваем ip созданного балансировщика и тестируем работу:
vozerov@mba:~/events/terraform (master *) $ yc load-balancer network-load-balancer get events-api-lb
id:
folder_id:
created_at: "2020-04-13T16:34:28Z"
name: events-api-lb
region_id: ru-central1
status: ACTIVE
type: EXTERNAL
listeners:
- name: events-api-listener
address: 130.193.37.103
port: "80"
protocol: TCP
target_port: "8080"
attached_target_groups:
- target_group_id:
health_checks:
- name: http
interval: 2s
timeout: 1s
unhealthy_threshold: "2"
healthy_threshold: "2"
http_options:
port: "8080"
path: /status
Теперь можем покидать в него сообщения:
vozerov@mba:~/events/terraform (master *) $ curl -D - -s -X POST -d '{"key1":"data1"}' http://130.193.37.103/post
HTTP/1.1 200 OK
Content-Type: application/json
Date: Mon, 13 Apr 2020 16:42:57 GMT
Content-Length: 41
{"status":"ok","partition":0,"Offset":1}
vozerov@mba:~/events/terraform (master *) $ curl -D - -s -X POST -d '{"key1":"data1"}' http://130.193.37.103/post
HTTP/1.1 200 OK
Content-Type: application/json
Date: Mon, 13 Apr 2020 16:42:58 GMT
Content-Length: 41
{"status":"ok","partition":0,"Offset":2}
vozerov@mba:~/events/terraform (master *) $ curl -D - -s -X POST -d '{"key1":"data1"}' http://130.193.37.103/post
HTTP/1.1 200 OK
Content-Type: application/json
Date: Mon, 13 Apr 2020 16:43:00 GMT
Content-Length: 41
{"status":"ok","partition":0,"Offset":3}
vozerov@mba:~/events/terraform (master *) $
Отлично, все работает. Остался последний штрих, чтобы мы были доступны по https — подключим cloudflare с проксированием. Если вы решили обойтись без cloudflare, можете пропустить данный шаг.
vozerov@mba:~/events/terraform (master *) $ terraform apply -target cloudflare_record.events
... skipped ...
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
Тестируем через HTTPS:
vozerov@mba:~/events/terraform (master *) $ curl -D - -s -X POST -d '{"key1":"data1"}' https://events.kis.im/post
HTTP/2 200
date: Mon, 13 Apr 2020 16:45:01 GMT
content-type: application/json
content-length: 41
set-cookie: __cfduid=d7583eb5f791cd3c1bdd7ce2940c8a7981586796301; expires=Wed, 13-May-20 16:45:01 GMT; path=/; domain=.kis.im; HttpOnly; SameSite=Lax
cf-cache-status: DYNAMIC
expect-ct: max-age=604800, report-uri="https://report-uri.cloudflare.com/cdn-cgi/beacon/expect-ct"
server: cloudflare
cf-ray: 5836a7b1bb037b2b-DME
{"status":"ok","partition":0,"Offset":5}
vozerov@mba:~/events/terraform (master *) $
Все наконец-то работает.
Тестируем нагрузку
Нам остался, пожалуй, самый интересный шаг — провести нагрузочное тестирование нашего сервиса и получить некоторые цифры — например, 95 персентиль времени обработки одного запроса. Также было бы неплохо протестировать автомасштабирование нашей группы узлов.
Перед запуском тестирования стоит сделать одну простую штуку — добавить наши application ноды в prometheus, чтобы следить за количеством запросов и временем обработки одного запроса. Поскольку мы пока не добавляли никакого service discovery (мы сделаем это в 5 статье серии), просто пропишем static_configs на нашем monitoring сервере. Узнать его ip можно стандартным способом через yc compute instance list, после чего дописать в /etc/prometheus/prometheus.yml следующие настройки:
- job_name: api
metrics_path: /metrics
static_configs:
- targets:
- 172.16.3.3:8080
- 172.16.2.31:8080
- 172.16.1.37:8080
IP-адреса наших машинок также можно взять из yc compute instance list. Рестартуем prometheus через systemctl restart prometheus и проверяем, что ноды успешно опрашиваются, зайдя в веб-интерфейс, доступный на порту 9090 (84.201.159.71:9090).
Давайте еще добавим дашборд в графану из папки grafana. Заходим в Grafana по порту 3000 (84.201.159.71:3000) и с логином / паролем — admin / Password. Далее добавляем локальный prometheus и импортируем dashboard. Собственно, на этом моменте подготовка завершена — можно закидывать нашу инсталляцию запросами.
Для тестирования будем использовать yandex tank (https://yandex.ru/dev/tank/) с плагином для overload.yandex.net, который позволит нам визуализировать данные, полученные танком. Все необходимое для работы находится в папке load изначального гит-репозитория.
Немного о том, что там есть:
- token.txt — файл с API ключиком от overload.yandex.net — его можно получить, зарегистрировавшись на сервисе.
- load.yml — конфигурационный файл для танка, там прописан домен для тестирования — events.kis.im, тип нагрузки rps и количество запросов 15 000 в секунду в течение 3-х минут.
- data — специальный файл для генерации конфига в формате ammo.txt. В нем прописываем тип запроса, url, группу для отображения статистики и собственно данные, которые необходимо отправлять.
- makeammo.py — скрипт для генерации ammo.txt файла из data-файла. Подробнее про скрипт — yandextank.readthedocs.io/en/latest/ammo_generators.html
- ammo.txt — итоговый ammo файл, который будет использоваться для отправки запросов.
Для тестирования я взял виртуалку за пределами Яндекс.Облака (чтобы все было честно) и создал ей DNS запись load.kis.im. Накатил туда docker, поскольку танк мы будем запускать, используя образ https://hub.docker.com/r/direvius/yandex-tank/.
Ну что же, приступаем. Копируем нашу папку на сервер, добавляем токен и запускаем танк:
vozerov@mba:~/events (master *) $ rsync -av load/ cloud-user@load.kis.im:load/
... skipped ...
sent 2195 bytes received 136 bytes 1554.00 bytes/sec
total size is 1810 speedup is 0.78
vozerov@mba:~/events (master *) $ ssh load.kis.im -l cloud-user
cloud-user@load:~$ cd load/
cloud-user@load:~/load$ echo "TOKEN" > token.txt
cloud-user@load:~/load$ sudo docker run -v $(pwd):/var/loadtest --net host --rm -it direvius/yandex-tank -c load.yaml ammo.txt
No handlers could be found for logger "netort.resource"
17:25:25 [INFO] New test id 2020-04-13_17-25-25.355490
17:25:25 [INFO] Logging handler added
17:25:25 [INFO] Logging handler added
17:25:25 [INFO] Created a folder for the test. /var/loadtest/logs/2020-04-13_17-25-25.355490
17:25:25 [INFO] Configuring plugins...
17:25:25 [INFO] Loading plugins...
17:25:25 [INFO] Testing connection to resolved address 104.27.164.45 and port 80
17:25:25 [INFO] Resolved events.kis.im into 104.27.164.45:80
17:25:25 [INFO] Configuring StepperWrapper...
17:25:25 [INFO] Making stpd-file: /var/loadtest/ammo.stpd
17:25:25 [INFO] Default ammo type ('phantom') used, use 'phantom.ammo_type' option to override it
... skipped ...
Все, процесс запущен. В консоли это выглядит примерно так:

А мы ждем завершения процесса и наблюдаем за временем ответа, количеством запросов и, конечно, за автоматическим масштабированием нашей группы виртуальных машин. Мониторить группу виртуалок можно через веб-интерфейс, в настройках группы виртуальных машин есть вкладка «Мониторинг».
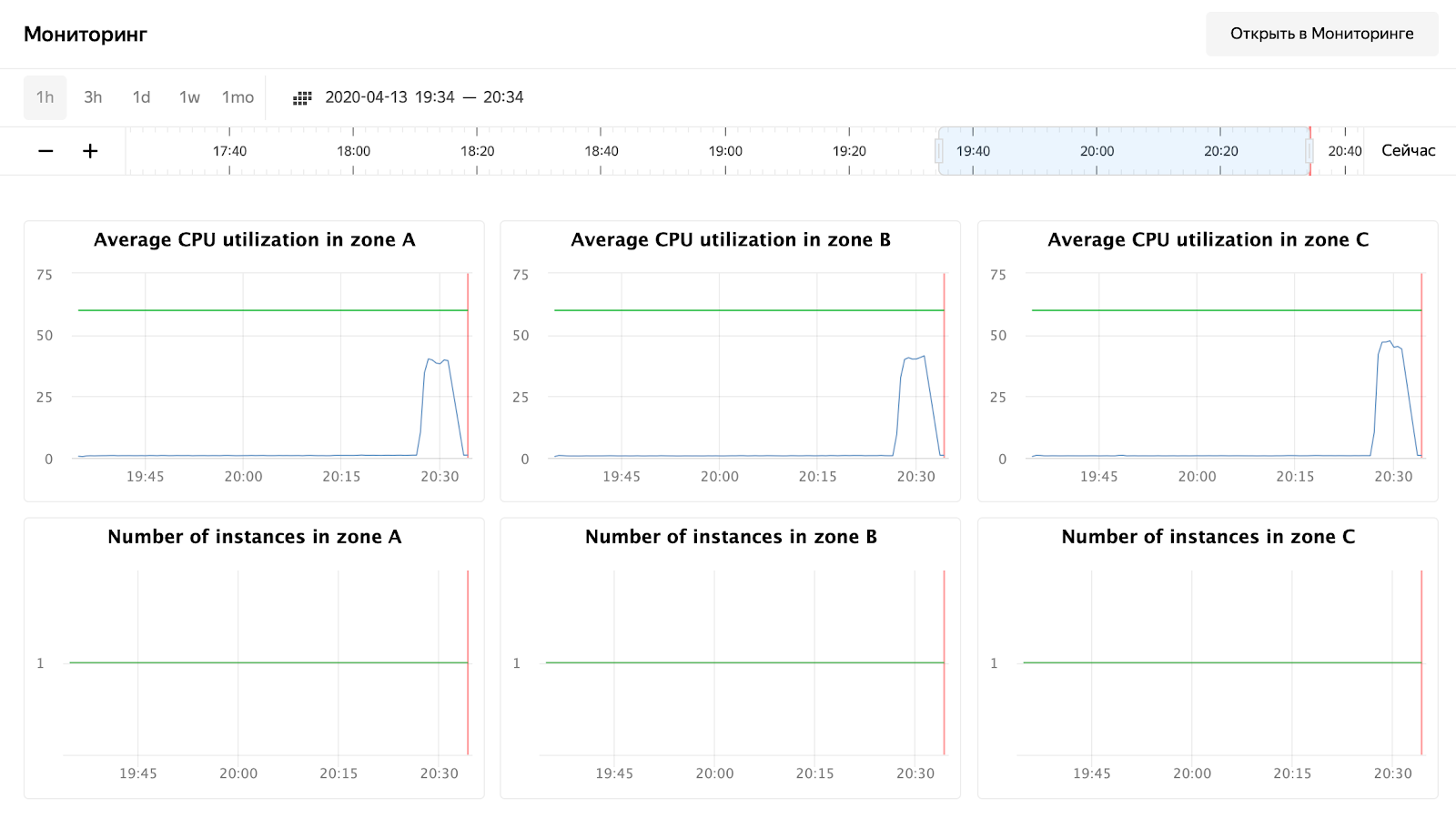
Как можно заметить — наши ноды не догрузились даже до 50% CPU, поэтому тест с автомасштабированием придется повторить. А пока глянем на время обработки запроса в Grafana:
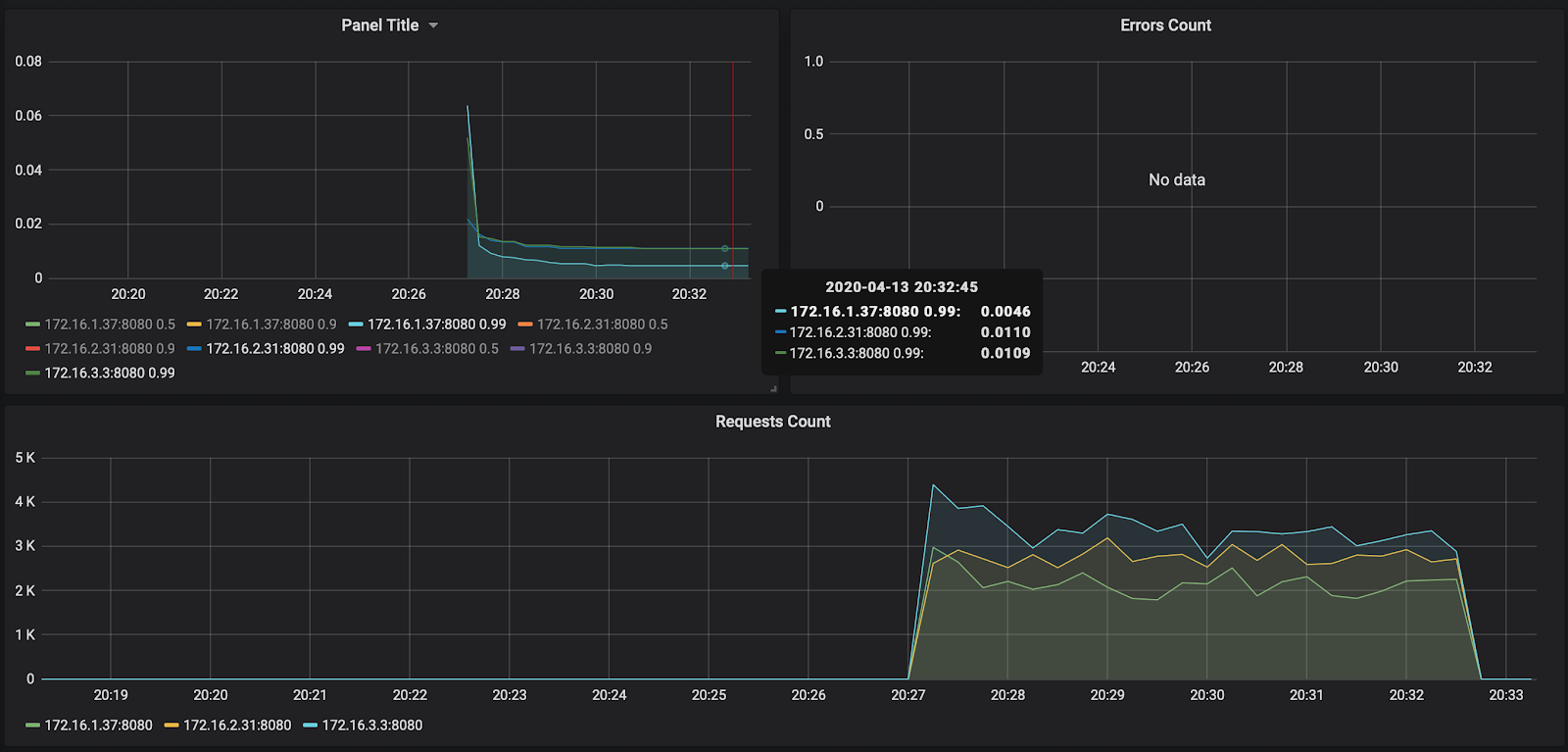
Количество запросов — порядка 3000 на одну ноду — немного до 10 000 не догрузили. Время ответа радует — порядка 11 ms на запрос. Единственный, кто выделяется, — 172.16.1.37 — у него время обработки запроса в два раза меньше. Но это и логично — он находится в той же зоне доступности ru-central1-a, что и kafka, которая сохраняет сообщения.
Кстати, отчет по первому запуску доступен по ссылке: https://overload.yandex.net/265967.
Итак, давайте запустим тест повеселее — добавим параметр instances: 2000, чтобы добиться 15 000 запросов в секунду, и увеличим время теста до 10 минут. Итоговый файл будет выглядеть так:
overload:
enabled: true
package: yandextank.plugins.DataUploader
token_file: "token.txt"
phantom:
address: 130.193.37.103
load_profile:
load_type: rps
schedule: const(15000, 10m)
instances: 2000
console:
enabled: true
telegraf:
enabled: false
Внимательный читатель обратит внимание, что я поменял адрес на IP балансировщика — связано это с тем, что cloudflare начал меня блочить за огромное количество запросов с одного ip. Пришлось натравить tank напрямую на балансер Яндекс.Облака. После запуска можно наблюдать такую картину:
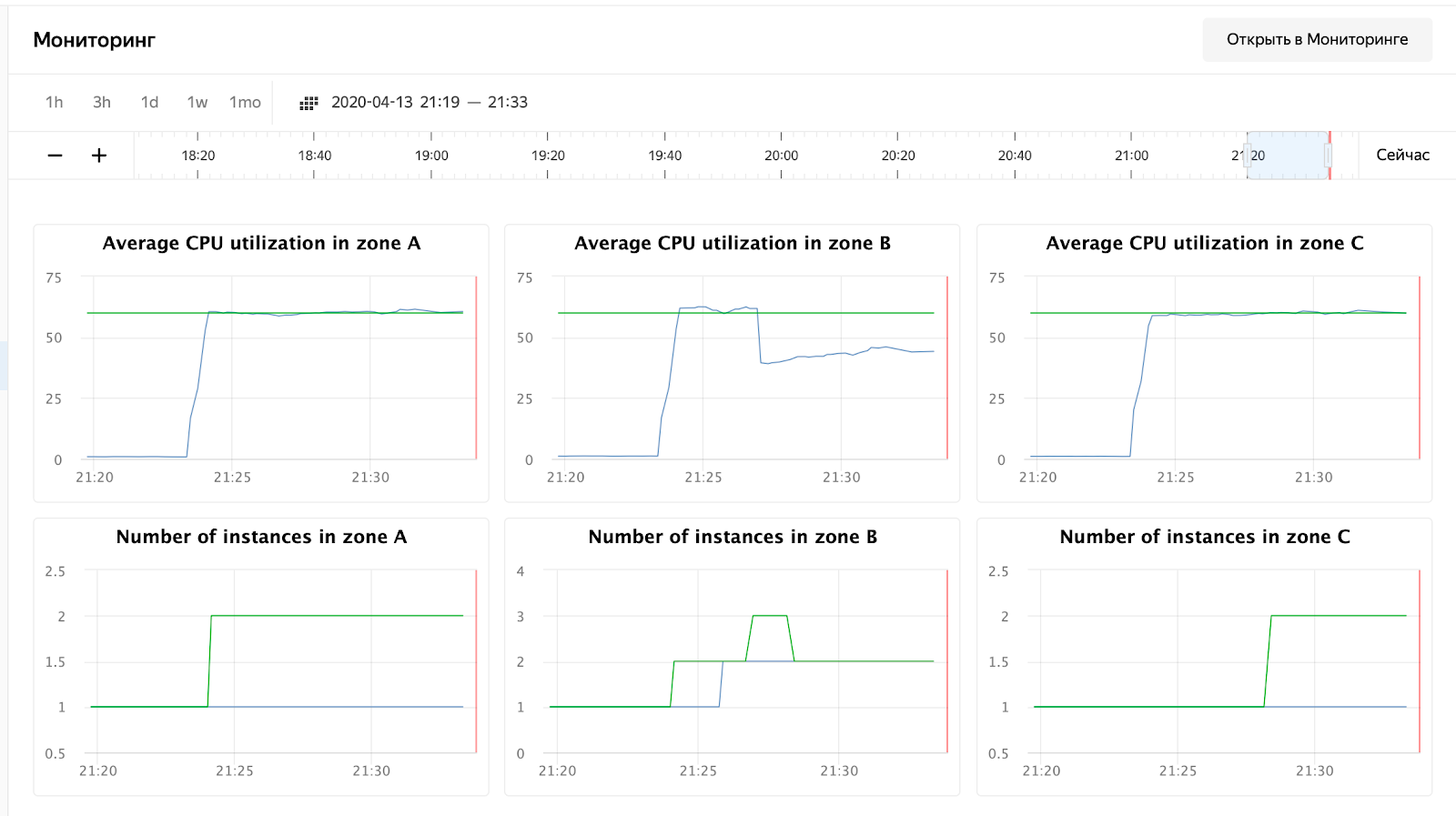
Использование CPU выросло, и планировщик принял решение увеличить количество нод в зоне B, что и сделал. Это можно увидеть по логам instance group:
vozerov@mba:~/events/load (master *) $ yc compute instance-group list-logs events-api-ig
2020-04-13 18:26:47 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 1m AWAITING_WARMUP_DURATION -> RUNNING_ACTUAL
2020-04-13 18:25:47 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 37s OPENING_TRAFFIC -> AWAITING_WARMUP_DURATION
2020-04-13 18:25:09 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 43s CREATING_INSTANCE -> OPENING_TRAFFIC
2020-04-13 18:24:26 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 6s DELETED -> CREATING_INSTANCE
2020-04-13 18:24:19 cl1s2tu8siei464pv1pn-ozix.ru-central1.internal 0s PREPARING_RESOURCES -> DELETED
2020-04-13 18:24:19 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 0s PREPARING_RESOURCES -> DELETED
2020-04-13 18:24:15 Target allocation changed in accordance with auto scale policy in zone ru-central1-a: 1 -> 2
2020-04-13 18:24:15 Target allocation changed in accordance with auto scale policy in zone ru-central1-b: 1 -> 2
... skipped ...
2020-04-13 16:23:57 Balancer target group b7rhh6d4assoqrvqfr9g created
2020-04-13 16:23:43 Going to create balancer target group
Также планировщик решил увеличить количество серверов и в других зонах, но у меня закончился лимит на внешние ip-адреса :) Их, кстати, можно увеличить через запрос в техподдержку, указав квоты и желаемые значения.
Заключение
Нелегкой выдалась статья — и по объему, и по количеству информации. Но самый трудный этап мы прошли и сделали следующее:
- Подняли мониторинг и кафку.
- Создали группу виртуалок с автомасштабированием, на которых запускается наше приложение.
- Подвязали к load balancer«у cloudflare для использования ssl сертификатов.
В следующий раз займемся сравнением и тестированием rabbitmq / kafka / yandex queue service.
Stay tuned!
*Этот материал есть в видеозаписи открытого практикума REBRAIN & Yandex.Cloud: Принимаем 10 000 запросов в секунду на Яндекс Облако — https://youtu.be/cZLezUm0ekE
Если вам интересно посещать такие мероприятия онлайн и задавать вопросы в режиме реального времени, подключайтесь к каналу DevOps by REBRAIN.
Отдельное спасибо хотим сказать Yandex.Cloud за возможность проведения такого мероприятия. Ссылочка на них
Если вам нужен переезд в облако или есть вопросы по вашей инфраструктуре, смело оставляйте заявку.
P.S. У нас есть 2 бесплатных аудита в месяц, возможно, именно ваш проект будет в их числе.
