Принимаем 10 000 ивентов в Яндекс.Облаке. Часть 1
Привет всем, друзья!
* Эта статья написана по мотивам открытого практикума REBRAIN & Yandex.Cloud, если вам больше нравится смотреть видео, можете найти его по этой ссылке — https://youtu.be/cZLezUm0ekE
Недавно нам представилась возможность пощупать вживую Яндекс.Облако. Поскольку щупать хотелось долго и плотно, то мы сразу отказались от идеи запуска простого wordpress блога с облачной базой — слишком скучно. После непродолжительных раздумий решили развернуть что-то похожее на продакшн архитектуру сервиса для приема и анализа ивентов в near real time режиме.
Я абсолютно уверен, что подавляющее большинство онлайн (и не только) бизнесов так или иначе собирают гору информации о своих пользователях и их действиях. Как минимум, это необходимо для принятия определенных решений — например, если вы управляете онлайн-игрой — то можете посмотреть статистику, на каком уровне пользователи чаще всего застревают и удаляют вашу игрушку. Или почему пользователи уходят с вашего сайта, так ничего и не купив (привет, Яндекс.Метрика).
Итак, наша история: как мы писали приложение на golang, тестировали kafka vs rabbitmq vs yqs, писали стриминг данных в Clickhouse кластер и визуализировали данные с помощью yandex datalens. Естественно, все это было приправлено инфраструктурными изысками в виде docker, terraform, gitlab ci и, конечно же, prometheus. Погнали!
Сразу хочется оговориться, что настроить все за один присест мы не сможем — для этого нам понадобится несколько статей в серии. Немного о структуре:
1 часть (вы ее читаете). Мы определимся с ТЗ и архитектурой решения, а также напишем приложение на golang.
2 часть. Выливаем наше приложение на прод, делаем масштабируемым и тестируем нагрузку.
3 часть. Попробуем разобраться, зачем нам нужно хранить сообщения в буфере, а не в файлах, а также сравним между собой kafka, rabbitmq и yandex queue service.
4 часть. Будем разворачивать Clickhouse кластер, писать стриминг для перекладывания туда данных из буфера, настроим визуализацию в datalens.
5 часть. Приведем всю инфраструктуру в должный вид — настроим ci/cd, используя gitlab ci, подключим мониторинг и service discovery с помощью prometheus и consul.
ТЗ
Сперва сформулируем техзадание — что именно мы хотим получить на выходе.
1. Мы хотим иметь endpoint вида events.kis.im (kis.im — тестовый домен, который будем использовать на протяжении всех статей), который должен принимать event-ы с помощью HTTPS.
2. События — это простая json«ка вида: {«event»: «view», «os»: «linux», «browser»: «chrome»}. На финальном этапе мы добавим чуть больше полей, но большой роли это не сыграет. Если есть желание — можно переключиться на protobuf.
3. Сервис должен уметь обрабатывать 10 000 событий в секунду.
4. Должна быть возможность масштабироваться горизонтально — простым добавлением новых инстансов в наше решение. И будет неплохо, если мы сможем выносить фронт-часть в различные геолокации для уменьшения latency при запросах клиентов.
5. Отказоустойчивость. Решение должно быть достаточно стабильным и уметь выживать при падении любых частей (до определенного количества, естественно).
Архитектура
Вообще для такого вида задач давно придуманы классические архитектуры, которые позволяют эффективно масштабироваться. На рисунке приведен пример нашего решения.

Итак, что у нас есть:
1. Слева изображены наши устройства, которые генерируют различные события, будь то прохождения уровня игроков в игрушке на смартфоне или создание заказа в интернет-магазине через обычный браузер. Событие, как указано в ТЗ, — простой json, который отправляется на наш endpoint — events.kis.im.
2. Первые два сервера — простые балансировщики, их основные задачи:
- Быть постоянно доступными. Для этого можно использовать, например, keepalived, который будет переключать виртуальный IP между нодами в случае проблем.
- Терминировать TLS. Да, терминировать TLS мы будем именно на них. Во-первых, чтобы наше решение соответствовало ТЗ, а во-вторых, для того, чтобы снять нагрузку по установлению шифрованного соединения с наших backend серверов.
- Балансировать входящие запросы на доступные backend сервера. Ключевое слово здесь — доступные. Исходя из этого, мы приходим к пониманию, что load balancer«ы должны уметь мониторить наши сервера с приложениями и переставать балансировать трафик на упавшие ноды.
3. За балансировщиками у нас идут application сервера, на которых запущено достаточно простое приложение. Оно должно уметь принимать входящие запросы по HTTP, валидировать присланный json и складывать данные в буфер.
4. В качестве буфера на схеме изображена kafka, хотя, конечно, на этом уровне можно использовать и другие похожие сервисы. Kafka, rabbitmq и yqs мы сравним в третьей статье.
5. Предпоследней точкой нашей архитектуры является Clickhouse — колоночная база данных, которая позволяет хранить и обрабатывать огромный объем данных. На данном уровне нам необходимо перенести данные из буфера в, собственно, систему хранения (об этом — в 4 статье).
Такая схема позволяет нам независимо горизонтально масштабировать каждый слой. Не справляются backend сервера — добавим еще — ведь они являются stateless приложениями, а следовательно, это можно сделать хоть в автоматическом режиме. Не тянет буфер в виде кафки — докинем еще серверов и перенесем на них часть партиций нашего топика. Не справляется кликхаус — это невозможно :) На самом деле также докинем серверов и зашардируем данные.
Кстати, если вы захотите реализовать опциональную часть нашего ТЗ и сделать масштабирование в различных геолокациях, то нет ничего проще:
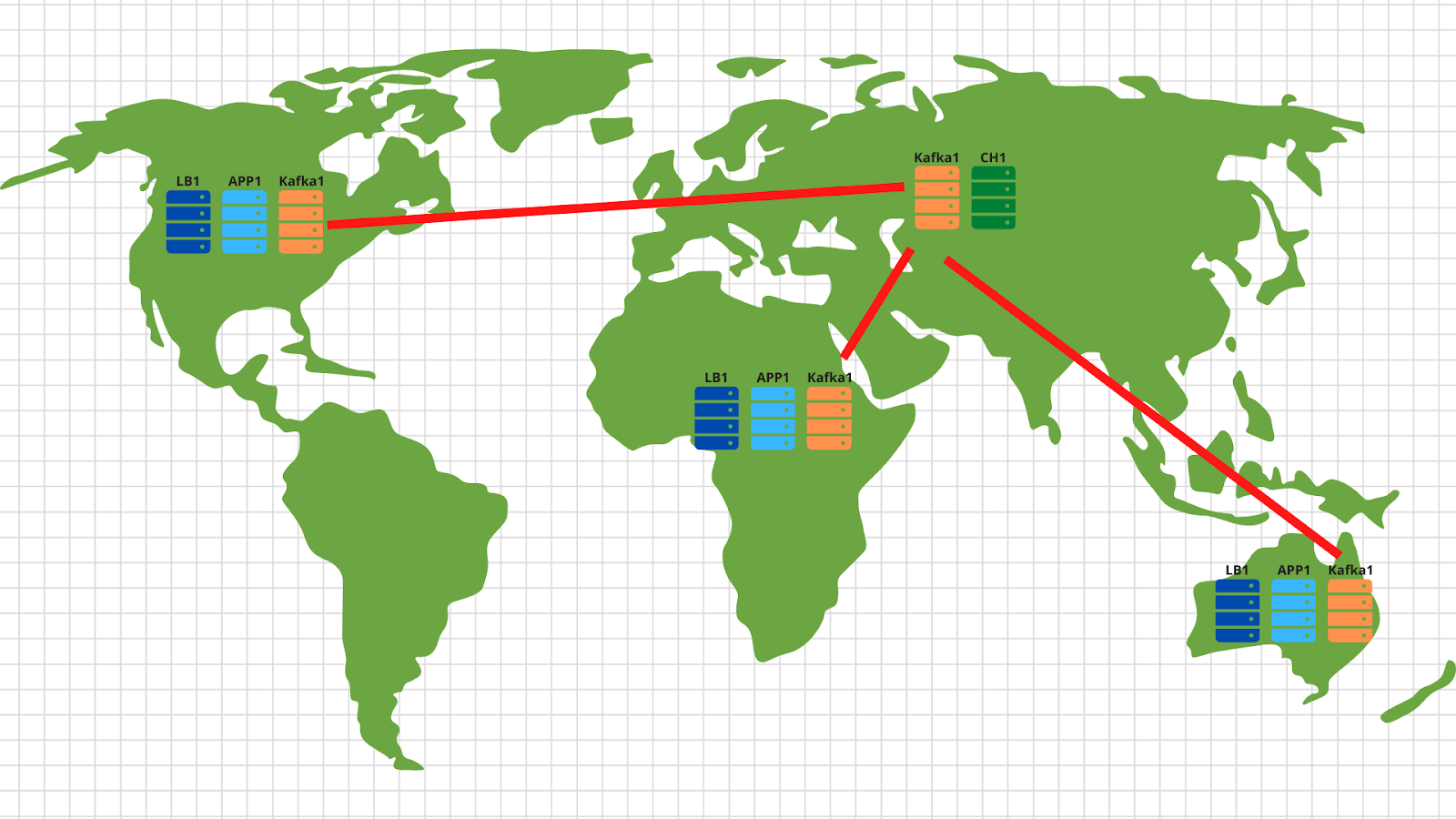
В каждой геолокации мы разворачиваем load balancer с application и kafka. В целом, достаточно 2 application сервера, 3 kafka ноды и облачного балансировщика, например, cloudflare, который будет проверять доступность нод приложения и балансировать запросы по геолокациям на основе исходного IP-адреса клиента. Таким образом данные, отправленные американским клиентом, приземлятся на американских серверах. А данные из Африки — на африканских.
Дальше все совсем просто — используем mirror tool из набора кафки и копируем все данные из всех локаций в наш центральный дата-центр, расположенный в России. Внутри мы разбираем данные и записываем их в Clickhouse для последующей визуализации.
Итак, с архитектурой разобрались — начинаем шатать Яндекс.Облако!
Пишем приложение
До Облака еще придется немножко потерпеть и написать достаточно простой сервис для обработки входящих событий. Использовать мы будем golang, потому что он очень хорошо себя зарекомендовал как язык для написания сетевых приложений.
Потратив час времени (может, и пару часов), получаем примерно такую штуку: https://github.com/RebrainMe/yandex-cloud-events/blob/master/app/main.go.
Какие основные моменты здесь хотелось бы отметить:
1. При старте приложения можно указать два флага. Один отвечает за порт, на котором мы будем слушать входящие http запросы (-addr). Второй — за адрес kafka сервера, куда мы будем записывать наши события (-kafka):
addr = flag.String("addr", ":8080", "TCP address to listen to")
kafka = flag.String("kafka", "127.0.0.1:9092", "Kafka endpoints”)2. Приложение использует библиотеку sarama ([] github.com/Shopify/sarama) для отправки сообщений в kafka кластер. Мы сразу выставили настройки, ориентированные на максимальную скорость обработки:
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForLocal
config.Producer.Compression = sarama.CompressionSnappy
config.Producer.Return.Successes = true3. Также в наше приложение встроен клиент prometheus, который собирает различные метрики, такие как:
- количество запросов к нашему приложению;
- количество ошибок при выполнении запроса (невозможно прочитать post запрос, битый json, невозможно записать в кафку);
- время обработки одного запроса от клиента, включая время записи сообщения в кафку.
4. Три endpoint«а, которые обрабатывает наше приложение:
- /status — просто возвращаем ok, чтобы показать, что мы живы. Хотя можно и добавить некоторые проверки, типа доступности кафка кластера.
- /metrics — по этому url prometheus client будет возвращать собранные им метрики.
- /post — основной endpoint, куда будут приходить POST запросы с json внутри. Наше приложение проверяет json на валидность и если все ок — записывает данные в кафка-кластер.
Оговорюсь, что код не идеален — его можно (и нужно!) допиливать. К примеру, можно отказаться от использования встроенного net/http и переключиться на более быстрый fasthttp. Или же выиграть время обработки и cpu ресурсы, вынеся проверку валидности json на более поздний этап — когда данные будут перекладываться из буфера в кликхаус кластер.
Помимо разработческой стороны вопроса, мы сразу подумали о нашей будущей инфраструктуре и приняли решение разворачивать наше приложение через docker. Итоговый Dockerfile для сборки приложения — https://github.com/RebrainMe/yandex-cloud-events/blob/master/app/Dockerfile. В целом, он достаточно простой, единственный момент, на который хочется обратить внимание, — это multistage сборка, которая позволяет уменьшить итоговый образ нашего контейнера.
Первые шаги в облаке
Первым делом регистрируемся на cloud.yandex.ru. После заполнения всех необходимых полей нам создадут аккаунт и выдадут грант на некоторую сумму денег, которую можно использовать для тестирования сервисов облака. Если вы захотите повторить все шаги из нашей статьи, этого гранта вам должно хватить.
После регистрации для вас будет создано отдельное облако и каталог default, в котором можно начать создавать облачные ресурсы. Вообще в Яндекс.Облаке взаимосвязь ресурсов выглядит следующим образом:

На один аккаунт вы можете создать несколько облаков. А внутри облака сделать разные каталоги для разных проектов компании. Подробнее об этом можно почитать в документации — https://cloud.yandex.ru/docs/resource-manager/concepts/resources-hierarchy. Кстати, ниже по тексту я буду часто на нее ссылаться. Когда я настраивал всю инфраструктуру с нуля — документация выручала меня не раз, так что советую поизучать.
Для управления облаком можно использовать как веб-интерфейс, так и консольную утилиту — yc. Установка выполняется одной командой (для Linux и Mac Os):
curl https://storage.yandexcloud.net/yandexcloud-yc/install.sh | bashЕсли по поводу запуска скриптов из интернета внутри вас разбушевался внутренний безопасник — то, во-первых, можете открыть скриптик и прочитать его, а во-вторых, мы запускаем его под своим пользователем — без рутовых прав.
Если вы хотите установить клиента для windows, то можно воспользоваться инструкцией здесь и затем выполнить yc init, чтобы полностью ее настроить:
vozerov@mba:~ $ yc init
Welcome! This command will take you through the configuration process.
Please go to https://oauth.yandex.ru/authorize?response_type=token&client_id= in order to obtain OAuth token.
Please enter OAuth token:
Please select cloud to use:
[1] cloud-b1gv67ihgfu3bp (id = b1gv67ihgfu3bpt24o0q)
[2] fevlake-cloud (id = b1g6bvup3toribomnh30)
Please enter your numeric choice: 2
Your current cloud has been set to 'fevlake-cloud' (id = b1g6bvup3toribomnh30).
Please choose folder to use:
[1] default (id = b1g5r6h11knotfr8vjp7)
[2] Create a new folder
Please enter your numeric choice: 1
Your current folder has been set to 'default' (id = b1g5r6h11knotfr8vjp7).
Do you want to configure a default Compute zone? [Y/n]
Which zone do you want to use as a profile default?
[1] ru-central1-a
[2] ru-central1-b
[3] ru-central1-c
[4] Don't set default zone
Please enter your numeric choice: 1
Your profile default Compute zone has been set to 'ru-central1-a'.
vozerov@mba:~ $В принципе, процесс несложный — сначала нужно получить oauth токен для управления облаком, выбрать облако и папку, которую будете использовать.
Если у вас несколько аккаунтов или папок внутри одного облака, можете создать дополнительные профили с отдельными настройками через yc config profile create и переключаться между ними.
Помимо вышеперечисленных способов, команда Яндекс.Облака написала очень хороший плагин для terraform для управления облачными ресурсами. Со своей стороны, я подготовил git-репозиторий, где описал все ресурсы, которые будут созданы в рамках статьи — https://github.com/rebrainme/yandex-cloud-events/. Нас интересует ветка master, давайте склонируем ее себе локально:
vozerov@mba:~ $ git clone https://github.com/rebrainme/yandex-cloud-events/ events
Cloning into 'events'...
remote: Enumerating objects: 100, done.
remote: Counting objects: 100% (100/100), done.
remote: Compressing objects: 100% (68/68), done.
remote: Total 100 (delta 37), reused 89 (delta 26), pack-reused 0
Receiving objects: 100% (100/100), 25.65 KiB | 168.00 KiB/s, done.
Resolving deltas: 100% (37/37), done.
vozerov@mba:~ $ cd events/terraform/Все основные переменные, которые используются в terraform, прописаны в файле main.tf. Для начала работы создаем в папке terraform файл private.auto.tfvars следующего содержания:
# Yandex Cloud Oauth token
yc_token = ""
# Yandex Cloud ID
yc_cloud_id = ""
# Yandex Cloud folder ID
yc_folder_id = ""
# Default Yandex Cloud Region
yc_region = "ru-central1-a"
# Cloudflare email
cf_email = ""
# Cloudflare token
cf_token = ""
# Cloudflare zone id
cf_zone_id = ""Все переменные можно взять из yc config list, так как консольную утилиту мы уже настроили. Советую сразу добавить private.auto.tfvars в .gitignore, чтобы ненароком не опубликовать приватные данные.
В private.auto.tfvars мы также указали данные от Cloudflare — для создания dns-записей и проксирования основного домена events.kis.im на наши сервера. Если вы не хотите использовать cloudflare, то удалите инициализацию провайдера cloudflare в main.tf и файл dns.tf, который отвечает за создание необходимых dns записей.
Мы в своей работе будем комбинировать все три способа — и веб-интерфейс, и консольную утилиту, и terraform.
Виртуальные сети
Честно говоря, этот шаг можно было бы и пропустить, поскольку при создании нового облака у вас автоматически создастся отдельная сеть и 3 подсети — по одной на каждую зону доступности. Но все же хотелось бы сделать для нашего проекта отдельную сеть со своей адресацией. Общая схема работы сети в Яндекс.Облаке представлена на рисунке ниже (честно взята с https://cloud.yandex.ru/docs/vpc/concepts/)
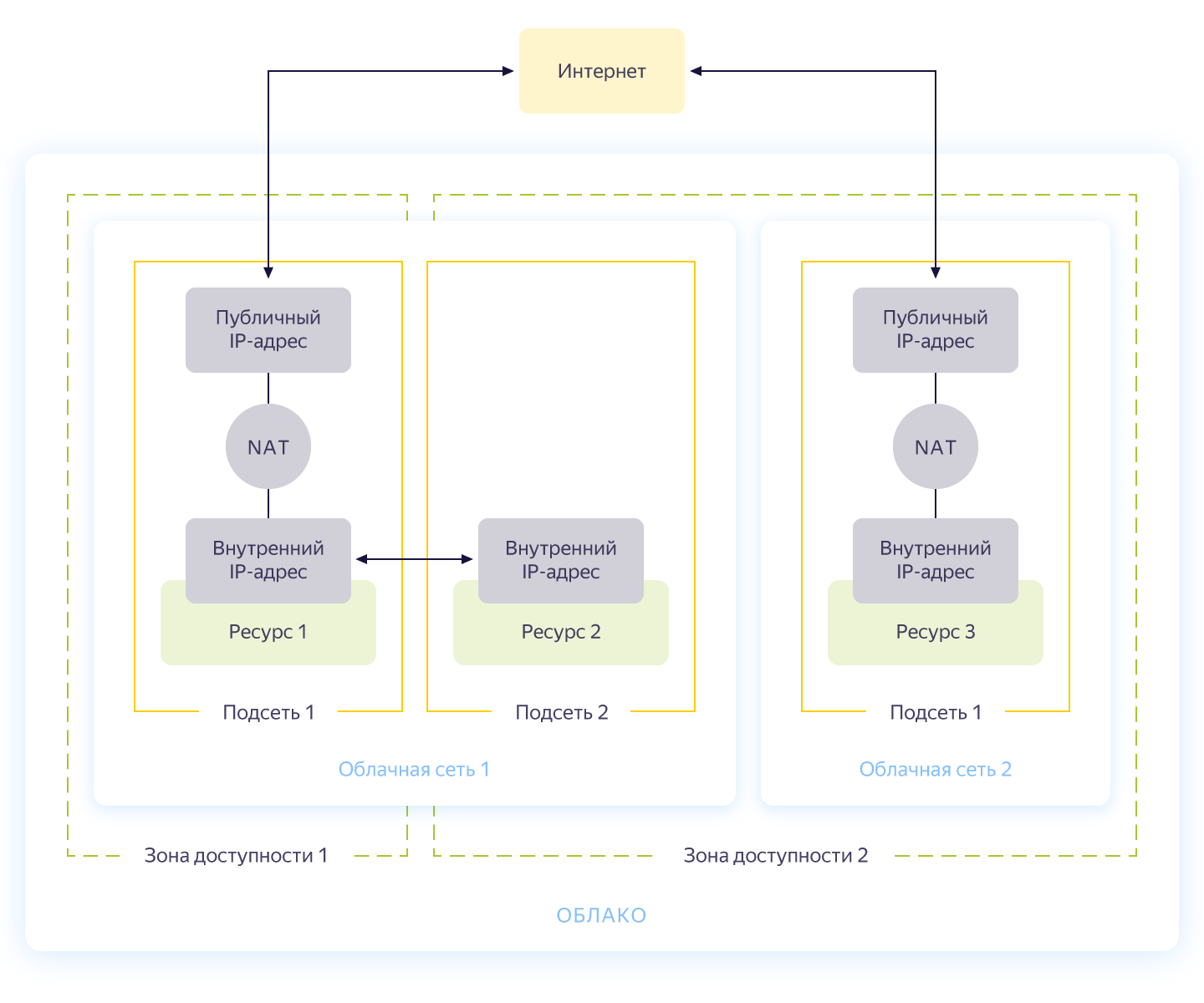
Итак, вы создаете общую сеть, внутри которой ресурсы смогут общаться между собой. Для каждой зоны доступности делается подсеть со своей адресацией и подключается к общей сети. В итоге, все облачные ресурсы в ней могут общаться, даже находясь в разных зонах доступности. Ресурсы, подключенные к разным облачным сетям, могут увидеть друг друга только через внешние адреса. Кстати, как эта магия работает внутри, было хорошо описано на хабре — https://habr.com/en/company/yandex/blog/487694/.
Создание сети описано в файле network.tf из репозитория. Там мы создаем одну общую приватную сеть internal и подключаем к ней три подсети в разных зонах доступности — internal-a (172.16.1.0/24), internal-b (172.16.2.0/24), internal-c (172.16.3.0/24).
Инициализируем terraform и создаем сети:
vozerov@mba:~/events/terraform (master) $ terraform init
... skipped ..
vozerov@mba:~/events/terraform (master) $ terraform apply -target yandex_vpc_subnet.internal-a -target yandex_vpc_subnet.internal-b -target yandex_vpc_subnet.internal-c
... skipped ...
Plan: 4 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
yandex_vpc_network.internal: Creating...
yandex_vpc_network.internal: Creation complete after 3s [id=enp2g2rhile7gbqlbrkr]
yandex_vpc_subnet.internal-a: Creating...
yandex_vpc_subnet.internal-b: Creating...
yandex_vpc_subnet.internal-c: Creating...
yandex_vpc_subnet.internal-a: Creation complete after 6s [id=e9b1dad6mgoj2v4funog]
yandex_vpc_subnet.internal-b: Creation complete after 7s [id=e2liv5i4amu52p64ac9p]
yandex_vpc_subnet.internal-c: Still creating... [10s elapsed]
yandex_vpc_subnet.internal-c: Creation complete after 10s [id=b0c2qhsj2vranoc9vhcq]
Apply complete! Resources: 4 added, 0 changed, 0 destroyed.Отлично! Мы сделали свою сеть и теперь готовы к созданию наших внутренних сервисов.
Создание виртуальных машин
Для тестирования приложения нам будет достаточно создать две виртуалки — первая нам потребуется для сборки и запуска приложения, вторая — для запуска kafka, которую мы будем использовать для хранения входящих сообщений. И создадим еще одну машинку, где настроим prometheus для мониторинга приложения.
Настраиваться виртуалки будут с помощью ansible, так что перед запуском terraform убедитесь, что у вас стоит одна из последних версий ансибла. И установите необходимые роли с ansible galaxy:
vozerov@mba:~/events/terraform (master) $ cd ../ansible/
vozerov@mba:~/events/ansible (master) $ ansible-galaxy install -r requirements.yml
- cloudalchemy-prometheus (master) is already installed, skipping.
- cloudalchemy-grafana (master) is already installed, skipping.
- sansible.kafka (master) is already installed, skipping.
- sansible.zookeeper (master) is already installed, skipping.
- geerlingguy.docker (master) is already installed, skipping.
vozerov@mba:~/events/ansible (master) $Внутри папки ansible есть пример конфигурационного файла .ansible.cfg, который использую я. Возможно, пригодится.
Перед тем, как создавать виртуалки, убедитесь, что у вас запущен ssh-agent и добавлен ssh ключик, иначе terraform не сможет подключиться к созданным машинкам. Я, конечно же, наткнулся на багу в os x: https://github.com/ansible/ansible/issues/32499#issuecomment-341578864. Чтобы у вас не повторилась такая история, перед запуском Terraform добавьте небольшую переменную в env:
vozerov@mba:~/events/terraform (master) $ export OBJC_DISABLE_INITIALIZE_FORK_SAFETY=YESВ папке с терраформом создаем необходимые ресурсы:
vozerov@mba:~/events/terraform (master) $ terraform apply -target yandex_compute_instance.build -target yandex_compute_instance.monitoring -target yandex_compute_instance.kafka
yandex_vpc_network.internal: Refreshing state... [id=enp2g2rhile7gbqlbrkr]
data.yandex_compute_image.ubuntu_image: Refreshing state...
yandex_vpc_subnet.internal-a: Refreshing state... [id=e9b1dad6mgoj2v4funog]
An execution plan has been generated and is shown below.
Resource actions are indicated with the following symbols:
+ create
... skipped ...
Plan: 3 to add, 0 to change, 0 to destroy.
... skipped ...Если все завершилось удачно (а так и должно быть), то у нас появятся три виртуальные машины:
- build — машинка для тестирования и сборки приложения. Docker был установлен автоматически ansible«ом.
- monitoring — машинка для мониторинга — на нее установлен prometheus & grafana. Логин / пароль стандартный: admin / admin
- kafka — небольшая машинка с установленной kafka, доступная по порту 9092.
Убедимся, что все они на месте:
vozerov@mba:~/events (master) $ yc compute instance list
+----------------------+------------+---------------+---------+---------------+-------------+
| ID | NAME | ZONE ID | STATUS | EXTERNAL IP | INTERNAL IP |
+----------------------+------------+---------------+---------+---------------+-------------+
| fhm081u8bkbqf1pa5kgj | monitoring | ru-central1-a | RUNNING | 84.201.159.71 | 172.16.1.35 |
| fhmf37k03oobgu9jmd7p | kafka | ru-central1-a | RUNNING | 84.201.173.41 | 172.16.1.31 |
| fhmt9pl1i8sf7ga6flgp | build | ru-central1-a | RUNNING | 84.201.132.3 | 172.16.1.26 |
+----------------------+------------+---------------+---------+---------------+-------------+Ресурсы на месте, и отсюда можем вытащить их ip-адреса. Везде далее я буду использовать ip-адреса для подключения по ssh и тестирования приложения. Если у вас есть аккаунт на cloudflare, подключенный к terraform, — смело используйте свежесозданные DNS-имена.
Кстати, при создании виртуалке выдается внутренний ip и внутреннее DNS-имя, так что обращаться к серверам внутри сети можно по именам:
ubuntu@build:~$ ping kafka.ru-central1.internal
PING kafka.ru-central1.internal (172.16.1.31) 56(84) bytes of data.
64 bytes from kafka.ru-central1.internal (172.16.1.31): icmp_seq=1 ttl=63 time=1.23 ms
64 bytes from kafka.ru-central1.internal (172.16.1.31): icmp_seq=2 ttl=63 time=0.625 ms
^C
--- kafka.ru-central1.internal ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 0.625/0.931/1.238/0.308 msЭто нам пригодится для указания приложению endpoint«а с kafk«ой.
Собираем приложение
Отлично, сервачки есть, приложение есть — осталось только его собрать и опубликовать. Для сборки будем использовать обычный docker build, а вот в качестве хранилища образов возьмем сервис от яндекса — container registry. Но обо всем по порядку.
Копируем на build машинку приложение, заходим по ssh и собираем образ:
vozerov@mba:~/events/terraform (master) $ cd ..
vozerov@mba:~/events (master) $ rsync -av app/ ubuntu@84.201.132.3:app/
... skipped ...
sent 3849 bytes received 70 bytes 7838.00 bytes/sec
total size is 3644 speedup is 0.93
vozerov@mba:~/events (master) $ ssh 84.201.132.3 -l ubuntu
ubuntu@build:~$ cd app
ubuntu@build:~/app$ sudo docker build -t app .
Sending build context to Docker daemon 6.144kB
Step 1/9 : FROM golang:latest AS build
... skipped ...
Successfully built 9760afd8ef65
Successfully tagged app:latestПолдела сделано — теперь можно проверить работоспособность нашего приложения, запустив его и направив на kafka:
ubuntu@build:~/app$ sudo docker run --name app -d -p 8080:8080 app /app/app -kafka=kafka.ru-central1.internal:9092С локальной машинки можно отправить тестовый event и посмотреть на ответ:vozerov@mba:~/events (master) $ curl -D - -s -X POST -d '{"key1":"data1"}' http://84.201.132.3:8080/post HTTP/1.1 200 OK Content-Type: application/json Date: Mon, 13 Apr 2020 13:53:54 GMT Content-Length: 41 {"status":"ok","partition":0,"Offset":0} vozerov@mba:~/events (master) $
Приложение ответило успехом записи и указанием id партиции и оффсета, в который попало сообщение. Дело за малым — создать registry в Яндекс.Облаке и закинуть туда наш образ (как это сделать при помощи трех строчек, описано в registry.tf файле). Создаем хранилище:
vozerov@mba:~/events/terraform (master) $ terraform apply -target yandex_container_registry.events
... skipped ...
Plan: 1 to add, 0 to change, 0 to destroy.
... skipped ...
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.Для аутентификации в container registry есть несколько способов — с помощью oauth токена, iam токена или ключа сервисного аккаунта. Более подробно об этих способах — в документации https://cloud.yandex.ru/docs/container-registry/operations/authentication. Мы будем использовать ключ сервисного аккаунта, поэтому создаем аккаунт:
vozerov@mba:~/events/terraform (master) $ terraform apply -target yandex_iam_service_account.docker -target yandex_resourcemanager_folder_iam_binding.puller -target yandex_resourcemanager_folder_iam_binding.pusher
... skipped ...
Apply complete! Resources: 3 added, 0 changed, 0 destroyed.Теперь осталось сделать для него ключик:
vozerov@mba:~/events/terraform (master) $ yc iam key create --service-account-name docker -o key.json
id: ajej8a06kdfbehbrh91p
service_account_id: ajep6d38k895srp9osij
created_at: "2020-04-13T14:00:30Z"
key_algorithm: RSA_2048Получаем информацию об id нашего хранилища, перекидываем ключ и авторизуемся:
vozerov@mba:~/events/terraform (master) $ scp key.json ubuntu@84.201.132.3:
key.json 100% 2392 215.1KB/s 00:00
vozerov@mba:~/events/terraform (master) $ ssh 84.201.132.3 -l ubuntu
ubuntu@build:~$ cat key.json | sudo docker login --username json_key --password-stdin cr.yandex
WARNING! Your password will be stored unencrypted in /home/ubuntu/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
ubuntu@build:~$Для загрузки образа в реестр нам понадобится ID container registry, берем его из утилиты yc:
vozerov@mba:~ $ yc container registry get events
id: crpdgj6c9umdhgaqjfmm
folder_id:
name: events
status: ACTIVE
created_at: "2020-04-13T13:56:41.914Z"После этого тегируем наш образ новым именем и загружаем:
ubuntu@build:~$ sudo docker tag app cr.yandex/crpdgj6c9umdhgaqjfmm/events:v1
ubuntu@build:~$ sudo docker push cr.yandex/crpdgj6c9umdhgaqjfmm/events:v1
The push refers to repository [cr.yandex/crpdgj6c9umdhgaqjfmm/events]
8c286e154c6e: Pushed
477c318b05cb: Pushed
beee9f30bc1f: Pushed
v1: digest: sha256:1dd5aaa9dbdde2f60d833be0bed1c352724be3ea3158bcac3cdee41d47c5e380 size: 946Можем убедиться, что образ успешно загрузился:
vozerov@mba:~/events/terraform (master) $ yc container repository list
+----------------------+-----------------------------+
| ID | NAME |
+----------------------+-----------------------------+
| crpe8mqtrgmuq07accvn | crpdgj6c9umdhgaqjfmm/events |
+----------------------+-----------------------------+Кстати, если вы установите утилиту yc на машинку с linux, то можете использовать команду
yc container registry configure-dockerдля настройки докера.
Заключение
Мы проделали большую и трудную работу и в результате:
- Придумали архитектуру нашего будущего сервиса.
- Написали приложение на golang, которое реализует нашу бизнес-логику.
- Собрали его и вылили в приватный container registry.
В следующей части перейдем к интересному — выльем наше приложение в production и наконец запустим на него нагрузку. Не переключайтесь!
Этот материал есть в видеозаписи открытого практикума REBRAIN & Yandex.Cloud: Принимаем 10 000 запросов в секунду на Яндекс Облако — https://youtu.be/cZLezUm0ekE
Если вам интересно посещать такие мероприятия онлайн и задавать вопросы в режиме реального времени, подключайтесь к каналу DevOps by REBRAIN — https://rebrainme.com/channel
Отдельное спасибо хотим сказать Yandex.Cloud за возможность проведения такого мерпориятия. Ссылочка на них — https://cloud.yandex.ru/prices
Если вам нужен переезд в облако или есть вопросы по вашей инфраструктуре, смело оставляйте заявку — https://fevlake.com
P.S. У нас есть 2 бесплатных аудита в месяц, возможно, именно ваш проект будет в их числе.
