Пример программирования FPGA-ускорителя

Не так давно мы рассказали о новой услуге Selectel — облачных высокопроизводительных вычислениях на FPGA-ускорителях. В новой статье на эту тему рассмотрим пример программирования FPGA для построения множества Мандельброта, — известного математического алгоритма для визуализации фрактальных изображений. В статье использован материал с сайта Эйлер Проджект.
Вместо предисловия
Вначале немного терминов. Вычислительная система с FPGA-ускорителем — как правило, это PCIe-адаптер c микросхемой FPGA в составе сервера х64. Ускоритель принимает на себя отдельную ресурсоемкую задачу, в которой можно задействовать параллельные вычисления и выполняет ее на многие порядки быстрее, чем процессор x64, разгружая его и повышая производительность всей вычислительной системы. К примеру, цикл расчета со 100 тысячами повторов может быть выполнен на FPGA всего за один проход вместо последовательного выполнения 100 тысяч раз на классическом процессоре х64. Логические элементы, аппаратные ресурсы коммуникационные связи микросхемы FPGA программируются пользователем непосредственно под саму задачу, что позволяет реализовать задачу как имплементацию алгоритма в кремнии — Algorithm in Silicon и достичь тем самым высокого быстродействия, причем при очень скромном энергопотреблении.
Сегодня порог вхождения в технологию FPGA вполне доступен даже стартапам — сервер с FPGA-ускорителем и всем необходимым ПО (SDK) можно арендовать в облаке Selectel за разумные деньги (так называемый «облачный FPGA»), а поддержка стандарта Open CL в FPGA ведет к тому, что программист, умеющий работать с языком С, в состоянии подготовить и запустить программу на FPGA.
Забегая вперед: попробуйте FPGA в работе
Описываемый ниже пример программирования для построения множества Мандельброта уже реализован на тестовом сервере в лаборатории Selectel Lab, где оценить его быстродействие может любой желающий (потребуется регистрация).
Проект предоставлен в коде и подготовлен к компиляции. Selectel предлагает удаленный доступ к серверу с ускорителем Intel Arria 10 FPGA. На стороне сервера развернуты инструменты SDK и BSP для разработки, отладки и компиляции кода OpenCL, Visual Studio для подготовки хост-приложений (управляющих приложений для центрального процессора сервера).
Заметим, что какого-либо прикладного значения сам пример не имеет, он выбран из соображений наглядной демонстрации методов ускорения при помощи принципов параллелизма. На этом примере читатель знакомится с маршрутом проектирования приложения в гетерогенной вычислительной системы c FPGA, — впоследствии этот маршрут можно использовать для разработки собственных приложений с параллельными вычислениями.
UPDATE: Весной 2018 года Intel представила высокопроизводительный гибридный процессор Xeon Gold 6138P со встроенным чипом Arria 10 FPGA. Ожидается, что к концу 2018 года серийные процессоры этого типа станут доступны клиентам через партнеров Intel. Мы в Selectel с нетерпением ожидаем этот чип, и надеемся, что первыми в России предоставим нашим клиентам возможность тестирования этой уникальной новинки.
О стандарте OpenCL для программирования FPGA
Стандарт OpenCL разработан Khronos Group — ведущими мировыми производителями чипов и ПО в составе Intel, AMD, Apple, ARM, Nvidia, Sony Computer Entertainment и др. Он предназначен для написания приложений, в которых используются параллельные вычисления на различных типах процессоров, включая FPGA. В стандарт OpenCL входят язык программирования Си на основе версии языка C99 (последняя версия C99 — ISO/IEC 9899:1999/Cor 3:2007 от 2007–11–15) и среда программирования приложений.
Популярность применения OpenCL для программирования высокопроизводительных вычислений основана на том, что это открытый стандарт, и его использование не требует приобретения лицензии. Более того, OpenCL не ограничивает круг поддерживаемых устройств каким-либо конкретным брендом, позволяя использовать на одной программной платформе аппаратные средства разных производителей.
Дополнительно про OpenCL: Введение в OpenCL на Хабр.
Немного истории — маршрут проектирования FPGA, существовавший до стандарта OpenCL, был крайне специфичен и трудоемок, при этом по сложности превосходил даже проектирование заказных микросхем (ASIC, application-specific integrated circuit, «интегральная схема специального назначения»). Требовалось скрупулезное понимание аппаратной структуры FPGA, конфигурирование которой надо было проводить на низкоуровневом языке описания аппаратуры (HDL — hardware description language). Владение этим маршрутом проектирования и верификации было и остается искусством, которое ввиду чрезвычайной трудоемкости доступно ограниченному кругу разработчиков.
Появление инструментария поддержки OpenCL для FPGA от Intel отчасти сняло проблему доступности программирования FPGA для разработчиков ПО. Программист самостоятельно выделяет ту часть своего алгоритма, что подходит для обработки методом параллельных вычислений и описывает ее на языке С, далее компилятор OpenCL для FPGA от Intel создает бинарный конфигурационный файл для запуска этого фрагмента алгоритма на ускорителе.
Используя привычную среду Visual Studio или стандартный gcc-компилятор, готовится хостовое приложение (приложение типа .exe, исполняемое на основном процессоре х64), при этом все необходимые библиотеки поддержки включены в состав SDK. При запуске хостового приложения загружается прошивка FPGA, данные загрузятся в ядро чипа и начнется обработка в соответствии с задуманным алгоритмом.
Микросхема FPGA (ПЛИС) является перепрограммируемой пользователем массивно-параллельной аппаратной структурой с миллионами логических элементов, тысячами сигнальных блоков DSP и десятками мегабайт кэш-памяти для проведения расчетов «на борту», без обращения к модулям основной памяти сервера. Быстрые интерфейсы ввода-вывода (10GE, 40GE, 100GE, PCIe Gen 3, и т.д.) позволяют эффективно обмениваться данными с основным процессором сервера.
Стандарт OpenCL представляет собой среду для исполнения гетерогенного программного обеспечения. Среда состоит из двух отдельных частей:
- ПО хоста — приложение, выполняемое на основном центральном процессоре сервера, написанное на языке С/C++ и использующее в работе набор функций OpenCL API. Сервер хоста организует весь процесс вычислений, подачу исходных и получение выходных данных, осуществляет взаимодействие всех систем сервера с FPGA-ускорителем.
- ПО ускорителя — программа, написанная на языке OpenCL C (язык C с рядом ограничений), прошедшая компиляцию для выполнения на микросхеме FPGA.
Типовой сервер для параллельных вычислений — это компьютер на базе архитектуры x64 (для выполнения приложений хоста), имеющий в своем составе аппаратный FPGA-ускоритель, чаще всего подключенный по шине PCI-Express. К слову, именно такая система представлена в лаборатории Selectel Lab.
Последовательность программирования и компиляции кода для FPGA-ускорителя состоит из двух этапов. Код хостового приложения компилируется стандартным компилятором (Visual C++, GCC) с получением исполняемого файла в операционной системе сервера (например, *.exe). Исходный код FPGA-ускорителя (ядро, kernel) готовится компилятором AOC в составе SDK, — с получением двоичного файла (*.aocx). Этот файл как раз и предназначен для программирования ускорителя.
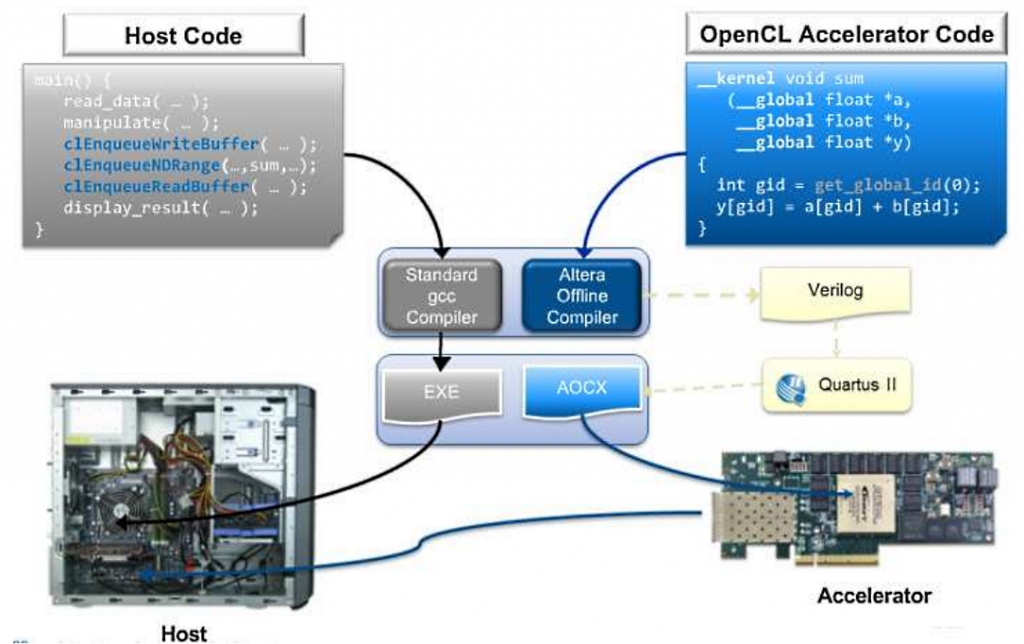
Рис. Архитектура среды компиляции программы на OpenCL
Рассмотрим некоторый пример кода для расчета большого вектора в двух вариантах
(P.S. Не стреляйте в пианиста — здесь и далее использован код с сайта Эйлер Проджект):
void inc (float *a, float c, int N)
{
for (int i = 0; i
_kernel
void inc (_global float *a, float c)
{
int i = get_global_id(0);
a[i] = a[i] + c;
}
void main() {
...
clEnqueueNDRangeKernel(...,&N,...)
...
}
Код вначале — пример того, как может выглядеть однопоточная реализация на С с применением метода последовательного вычисления скалярных элементов.
Второй вариант кода — это возможная реализация алгоритма на OpenCL в виде функции, вычисляемой на FPGA-ускорителе. Здесь отсутствует цикл, и вычисление происходит за одну итерацию цикла. Расчет векторного массива происходит как выполнение N копий данной функции. Каждая копия имеет свой индекс, подставляемый в итератор в цикле, а число повторов задается от хоста при выполнении кода. Действие итератора обеспечивает функция get_global_id (), работающая с индексом в пределах 0 ≤ index < N.
Ближе к делу: строим фрактал
Множество Мандельброта представляет собой массив точек «с» на комплексной плоскости, для которых рекуррентное соотношение Zn+1 = Zn² + c при Z0=0 задает ограниченную последовательность.
Определим Zn = Zn + IYn, и также с = p + iq.
Для каждой точки рассчитывается следующая последовательность:
Xn+1 = Xn² + Yn² + p
Yn+1 = 2XnYn + q
Расчет принадлежности точки множеству на каждой итерации выполняется как уравнение
Xn² + Yn²
Для отображения множества Мандельброта на экране определим правило:
- Если неравенство выполняется при любых итерациях, то точка входит в множество и будет показана черным цветом.
- Если неравенство не выполняется, начиная с некоторого значения итераций n = N, то цвет определяется числом итераций N.
Процесс расчета на хосте будет следующим:
- Расчет числа итераций для каждой точки внутри окна пиксел возложим на функцию mandel_pixel ().
- Последовательный перебор точек изображения обеспечит функция softwareCalculateFrame (). Параметры задают вещественный интервал вычисляемых точек, вещественный шаг алгоритма и указатель на цветовой буфер изображения размером (theWidth * theHeight).
- Цвет точки оправляется по палитре theSoftColorTable.
Перейдем к коду:
inline unsigned int mandel_pixel( double x0, double y0, unsigned int maxIterations ) {
// variables for the calculation
double x = 0.0; double y = 0.0; double xSqr = 0.0; double ySqr = 0.0;
unsigned int iterations = 0;
// perform up to the maximum number of iterations to solve
// the current point in the image
while ( xSqr + ySqr < 4.0 &&iterations < maxIterations )
{
// perform the current iteration
xSqr = x*x;
ySqr = y*y;
y = 2*x*y + y0;
x = xSqr - ySqr + x0;
// increment iteration count
iterations++;
}
// return the iteration count
return iterations;
}
int softwareCalculateFrame( double aStartX, double aStartY,
double aScale, unsigned int* aFrameBuffer )
{
// temporary pointer and index variables unsigned int * fb_ptr = aFrameBuffer; unsigned int j, k, pixel; // window position variables double x = aStartX; double y = aStartY; double cur_x, cur_y;
double cur_step_size = aScale;
// for each pixel in the y dimension window
for ( j = 0, cur_y = y; j < theHeight; j++, cur_y -= cur_step_size )
{
// for each pixel in the x dimension of the window
for ( cur_x = x, k = 0; k< theWidth; k++, cur_x += cur_step_size )
{
// set the value of the pixel in the window pixel = mandel_pixel(cur_x, cur_y, theSoftColorTableSize);
if ( pixel == theSoftColorTableSize )
*fb_ptr++ = 0x0;
else
*fb_ptr++ = theSoftColorTable[pixel];
}
}
return 0;
}
Каждый пиксел рассчитывается независимо от другого, и поэтому можно распараллелить этот процесс. При реализации алгоритма для FPGA-ускорителя создается SIMD-инструкция для вычисления числа для каждого пиксела итераций (определяя код цвета по палитре). Реализация двух вложенных циклов по буферу изображения оформлена через OpenCL запуском операции (theWidth * theHeight).
Экземпляры ядра в листинге ниже называются work-item, а множество всех экземпляров — индексным пространством. К особенностям аппаратной функции можно отнести следующие:
- Объявление функции начинается с ключевого слова __kernel.
- Тип аппаратной функции — тип возвращаемого значения всегда void.
- Возврат значений производится через буферы, передаваемые в качестве параметров.
- Первые три параметра задают вещественную сетку, узлы которой соответствуют пикселям изображения на выходе.
- Четвертый параметр ограничивает число итераций, предотвращающее зацикливание для точек, принадлежащий множеству Мандельброта.
- Пятый параметр — указатель на выходной цветовой буфер.
- Ключевое слово __global обозначает тип памяти, через которую буфер будет передаваться: это общая память DDR (QDR) на самом ускорителе.
- Ключевое слово restrict передает оптимизатору запрет на использование косвенных ссылок на буфер.
- В 6-м параметре передается указатель на палитру.
- Ключевое слово __constant оптимизирует обращения к буферу методом генерации кэша с атрибутом «только чтение».
Описание функции в листинге близко к реализации для процессора х64. Здесь определение текущего экземпляра ядра производится через функцию get_global_id, в которую передается номер размерности (0, 1) как параметр.Для лучшей оптимизации введено явное указание на запуск цикла. В отсутствие сведений о числе итераций на момент компиляции, явно указано количество шагов цикла, так как для них будут созданы свои аппаратные блоки. При подобном кодировании, следует «оглядываться» на емкость конкретного чипа, установленного на ускорителе, ввиду расхода ресурсов FPGA на большее число циклов.
//////////////////////////////////////////////////////////////////// // mandelbrot_kernel.cl : Hardware implementation of the mandelbrot algorithm //////////////////////////////////////////////////////////////////// // Amount of loop unrolling. #ifndef UNROLL #define UNROLL 20 #endif // Define the color black as 0 #define BLACK 0x00000000 __kernel void hw_mandelbrot_frame ( const double x0, const double y0, const double stepSize, const unsigned int maxIterations, __global unsigned int *restrict framebuffer, __constant const unsigned int *restrict colorLUT, const unsigned int windowWidth) { // Work-item position const size_t windowPosX = get_global_id(0); const size_t windowPosY = get_global_id(1); const double stepPosX = x0 + (windowPosX * stepSize); const double stepPosY = y0 - (windowPosY * stepSize); // Variables for the calculation double x = 0.0; double y = 0.0; double xSqr = 0.0; double ySqr = 0.0;unsigned #pragma while { int iterations = 0; // Perform up to the maximum number of iterations to solve // the current work-item's position in the image // The loop unrolling factor can be adjusted based on the amount of FPGA // resources available. unroll UNROLL xSqr + ySqr < 4.0 && iterations < maxIterations ) // Perform the current iteration xSqr = x*x; ySqr = y*y; y = 2*x*y + stepPosY; x = xSqr - ySqr + stepPosX; // Increment iteration count iterations++; } // Output black if we never finished, and a color from the look up table otherwise framebuffer[windowWidth * windowPosY + windowPosX] = (iterations == maxIterations) ? BLACK : colorLUT[iterations]; }
Пакет утилит Intel FPGA SDK for OpenCL потребуется инсталлировать на хосте до начала компиляции аппаратной реализации алгоритма. В число предварительно устанавливаемых программных средств надо включить BSP (Board Support Package) от производителя конкретной платы ускорителя. В примере установлен Intel Quartus Prime Pro 16.1 с поддержкой OpenCL и BSP ускорителя Euler Thread (Intel Arria 10).Ниже осуществляется настройка путей и переменных окружения. Переменная ALTERAOCLSDKROOT содержит путь к Intel FPGA SDK, переменная AOCL_BOARD_PACKAGE_ROOT — к BSP ускорителя.
set ALTERAOCLSDKROOT=C:\intelFPGA_pro\16.1\hld set AOCL_BOARD_PACKAGE_ROOT=C:\intelFPGA_pro\16.1\hld\board\euler_thread set path=%path%;C:\intelFPGA_pro\16.1\hld\bin set path=%path%;C:\intelFPGA_pro\16.1\quartus\bin64 set path=%path%;C:\intelFPGA_pro\16.1\hld\board\a10_ref\windows64\bin set path=%path%;C:\intelFPGA_pro\16.1\hld\host\windows64\bin set path=%path%;C:\intelFPGA_pro\16.1\qsys\bin set path=%path%;C:\Program Files (x86)\GnuWin32\bin\
Для компиляции используется компилятор aoc из состава SDK.aoc mandelbrot_kernel.cl -o mandelbrot_kernel.aocx --board thread -v -v --report
Расшифруем: mandelbrot_kernel.cl — файл с исходным текстом, mandelbrot_kernel.aocx — выходной объектный файл для программирования FPGA, thread — название ускорителя из пакета BSP. Ключ --report выводит отчет о расходе ресурсов FPGA. Ключ –v выводит диагностическую информацию при компиляции. Отчет о расходе ресурсов для kernel имеет следующий вид:±-------------------------------------------------------------------+
; Estimated Resource Usage Summary;
±---------------------------------------±--------------------------+
; Resource + Usage;
±---------------------------------------±--------------------------+
; Logic utilization; 49%;
; ALUTs; 26%;
; Dedicated logic registers; 25%;
; Memory blocks; 21%;
; DSP blocks; 16%;
±---------------------------------------±--------------------------;Для компиляции хостового приложения в примере использован пакет Microsoft Visual Studio 2010 Express с установленным Microsoft SDK 7.1. В настройках проекта выбрана конфигурация для x64. Далее следует подключить папку для внешних заголовочных файлов и в настройках компоновщика (linker) указать путь к дополнительным библиотекам Intel FPGA SDK.
Дополнительные каталоги включаемых файлов = $(ALTERAOCLSDKROOT)\host\include;
Дополнительные каталоги библиотек = $(AOCL_BOARD_PACKAGE_ROOT)\windows64\lib;$(ALTERAOCLSDKROOT)\host\windows64\lib;
Общий план действий для запуска ядра на ускорителе будет таким:- получить список платформ;
- получить список устройств;
- создать контекст;
- загрузить ядро в устройство;
- отправить входные буферы в устройство;
- запустить ядро на исполнение;
- прочитать выходной буфер из устройства;
- освободить контекст.
Рассмотрим некоторые моменты, связанные непосредственно с запуском ядра. Итак, одно ядро предназначено для обработки одного пиксела изображения. Таким образом, нужно запустить N экземпляров ядра, где N — общее количество пикселов в изображении.Ниже отметим случай, когда в составе сервера есть несколько плат ускорителей, — тогда задачу можно распределить между ними. В каждый из ускорителей нужно произвести загрузку ядра (файла mandelbrot_kernel.aocx). Предположим, число ускорителей равно numDevices, и строки изображения делятся между всеми ускорителями:
#define MAXDEV 10 static cl_context theContext; static cl_program theProgram; static cl_kernel theKernels[MAXDEV]; //.. // Create the program object theProgram = createProgramFromBinary( theContext, "mandelbrot_kernel.aocx", theDevices, numDevices); // Create the kernels for ( unsigned i = 0; i < numDevices; ++i ) theKernels[i] = clCreateKernel( theProgram, "hw_mandelbrot_frame", &theStatus ); // Create output pixel buffers for every kernel for( unsigned i = 0; i < numDevices; ++i ) thePixelData[i] = clCreateBuffer(theContext, CL_MEM_WRITE_ONLY, thePixelDataWidth*rowsPerDevice[i]*sizeof(unsigned int), NULL, &theStatus); // Preparing and writing palette buffer to every device theHardColorTable = clCreateBuffer(theContext, CL_MEM_READ_ONLY, aColorTableSize*sizeof(unsigned int), NULL, &theStatus); for( unsigned i = 0; i < numDevices; i++ ) theStatus = clEnqueueWriteBuffer(theQueues[i], theHardColorTable, CL_TRUE, 0, aColorTableSize*sizeof(unsigned int), aColorTable, 0, NULL, NULL); // Preparing kernels and run unsigned rowOffset = 0; for ( unsigned i = 0; i < numDevices; rowOffset += rowsPerDevice[i++] ) { // Create ND range size size_t globalSize[2] = { thePixelDataWidth, rowsPerDevice[i] }; // Set the arguments unsigned argi = 0; theStatus = clSetKernelArg (theKernels[i], argi++, sizeof(cl_double), (void*) &aStartX ); const double offsetedStartY = aStartY - rowOffset * aScale; theStatus = clSetKernelArg(theKernels[i], argi++, sizeof(cl_double), (void*)&offsetedStartY); theStatus = clSetKernelArg(theKernels[i], argi++, sizeof(cl_double), (void*)&aScale); theStatus = clSetKernelArg(theKernels[i], argi++, sizeof(cl_uint), (void*)&theHardColorTableSize); theStatus = clSetKernelArg(theKernels[i], argi++, sizeof(cl_mem), (void*)&thePixelData[i]); theStatus = clSetKernelArg(theKernels[i], argi++, sizeof(cl_mem), (void*)&theHardColorTable); theStatus = clSetKernelArg(theKernels[i], argi++, sizeof(cl_uint), (void*)&theWidth); // Launch kernel theStatus = clEnqueueNDRangeKernel(theQueues[i], theKernels[i], 2, NULL, globalSize, NULL, 0, NULL, NULL); } rowOffset = 0; for( unsigned i = 0; i < numDevices; rowOffset += rowsPerDevice[i++] ) { // Read the output theStatus = clEnqueueReadBuffer(theQueues[i], thePixelData[i], CL_TRUE, 0, thePixelDataWidth*rowsPerDevice[i]*sizeof(unsigned int), &aFrameBuffer[rowOffset * theWidth], 0, NULL, NULL); } / / . .- Функция createProgramFromBinary создает объект OpenCL-программы из объектного файла.
- Далее для каждого устройства создается ядро на основе объекта программы.
- Создаются буферы thePixelData для получения выходных данных из каждого ядра.
- Создается буфер для хранения цветовой палитры и загружается в каждый из ускорителей.
- Далее для каждого устройства задается привязка локальных параметров приложения и параметров ядра с помощью функции clSetKernelArg.
- Определение параметров производится по порядковым номерам в объявлении функции ядра, начиная с нуля.
Следующий важный момент — определение размера задачи на основе индексного пространства согласно массиву globalSize. Данный массив может быть одно-, двух- или трехмерным. Для каждого измерения задается размерность в виде целого числа. Размерность пространства будет определять порядок индексации work-item в ядре.В примере для каждого ядра задается двумерное пространство, где одна из осей — элементы строки пикселов, вторая — набор строк изображения, обрабатываемых на данном устройстве. В коде ядра номер пиксела в строке получается вызовом get_global_id (0), номер строки — get_global_id (1). Переменная globalSize передается в функцию clEnqueueNDRangeKernel для запуска требуемого количества экземпляров ядра на выполнение.
По завершении выполнения ядер — производится считывание пиксельных буферов из устройства в локальные массивы. Оценим быстродействие по количеству кадров в секунду — результат виден на демонстрации, осуществленной на конференции SelectelTechDay (см. начало статьи).
Заключение
Программирование FPGA-ускорителей на языке высокого уровня, несомненно, на порядок снизило порог доступа к этой технологии для разработчиков. К примеру, для тех, кто только осваивает этот инструментарий, существует даже FPGA-реализация знаменитого примера «Hello World».Но не все так просто. Написание, — и особенно, — отладка четко работающего алгоритма реальной прикладной задачи по-прежнему требуют высокого профессионализма. Еще одно ограничение — каждая микросхема FPGA может выполнить только одну вычислительную задачу в рамках работы приложения. Для другой задачи ее надо заново перепрограммировать.
К слову, модель использования платформы позволяет иметь больше чем один FPGA-ускоритель на хосте, хотя это довольно дорогое решение.
Хост (хостовое приложение) руководит процессом создания контекста (структуры данных для ускорителя) и очередью команд. Т.е. единое хостовое приложение, в котором есть различные подзадачи для параллельных вычислений на FPGA, может грузить их на разные ускорители:
KERNEL1 => ACCELERATOR A
KERNEL2 => ACCELERATOR B
Тем не менее, усилия по освоению FPGA-ускорителей стоят того — во многих прикладных областях эта технология становится незаменимой: телекоме, биотехнологиях, обработке больших данных, распознавании образов, обработке сигналов и изображений, в вычислительной математике и моделировании физических полей.Дополнительная информация к статье:
www.altera.com — основной ресурс по технологиям Intel FPGA.
www.eulerproject.com — официальный сайт компании Euler Project.
Altera + OpenCL: программируем под FPGA без знания VHDL/Verilog — статья на Хабр.
