Применение компьютерного зрения в морских исследованиях или 12 человек на сундук мертвеца

Горячо приветствую, уважаемые коллеги.
В сообществе OpenDataScience успешно развивается инициатива ML4SG — Machine Learning for Social Good. В её рамках стартовал целый ряд интересных проектов, которые в самых разных областях улучшают нашу с вами жизнь.
Мы хотели бы рассказать об одном из таких проектов под кодовым названием #proj_shipwrecks. Проект стартовал силами членов сообщества ODS, согласившимися в свое время поработать забесплатно над тем, что им нравится, но до чего по тем или иным причинам руки еще не дошли. Сейчас проект вырос в небольшой non-profit стартап, с целым рядом разных направлений исследований и разработки.
В рамках проекта мы стремимся помогать людям, занимающимся разного рода морскими исследованиями, от морских археологов, биологов и океанологов то команд спасения на воде, используя как свою экспертизу в области компьютерного зрения, так и придумывая новые, порой неожиданные ходы.
О чем это вообще?
Вкратце, наш проект нацелен на помощь морским биологам и археологам, командам по спасению на воде, а также морским исследователям всех мастей. Мы стремимся сократить время и затраты на целый ряд операций, автоматизируя работу с данными с сонаров, спутников, радаров с синтетической апертурой и просто визуальными изображениями и видео.
Наши исследования помогут не только обнаружить новые места для дайвинга, но и окажут помощь людям, чьи близкие пропали без вести в водной пучине. На очереди создание отдельной команды, которая будет помогать учёным-океанологам и биологам следить за популяциями морских обитателей, от тюленей до кораллов колоний, а также метеорологам следить за образованием и движением полярных циклонов.
Проект стартовал относительно недавно, активная фаза началась в феврале-марте сего года. С тех пор мы определились с концептом, у нас подобралась хорошая команда, мы организовались в некоторое подобие стартапа и научились делать всякие прикольные штуки. Но обо всем по порядку.
Кто мы такие
Мы — это 12 (±, структура команды несколько ликвидна) дата сатанистов разной степени юниорности. Кто-то шатает нейронки уже давно, кто-то лишь открывает для себя волшебный мир Deep Learning за пределами Курсеры. Кроме того, у нас в команде трудятся прокаченные девелоперы и мега-крутой дата инженер. Все пришли в разное время, в основном проект начинали уже действующие члены ОДС, но кто-то пришел туда только узнав о проекте. Больший буст по численности мы получили после прошедшего в начале мая ДатаФеста, когда команда выросла практически вдвое.
Мы работаем по аджайлу, у нас нет расписанного по дням плана, есть только видение концепта, куда мы хотим прийти и что получить в итоге, тактически же задачи меняются в зависимости от того, какие данные нам удалось собрать, сработала ли та или иная гипотеза, нужна ли та фича, над которой трудились весь недельный спринт или же она стала obsolete, т.к. кому-то прошла в голову более крутая идея.
В общем, у нас весело и непринуждённо:)

Что же мы делаем?
Как ясно из названия, мы работаем над применением компьютерного зрения в разных областях морских исследований, как for social good, так и напрямую для бизнеса.
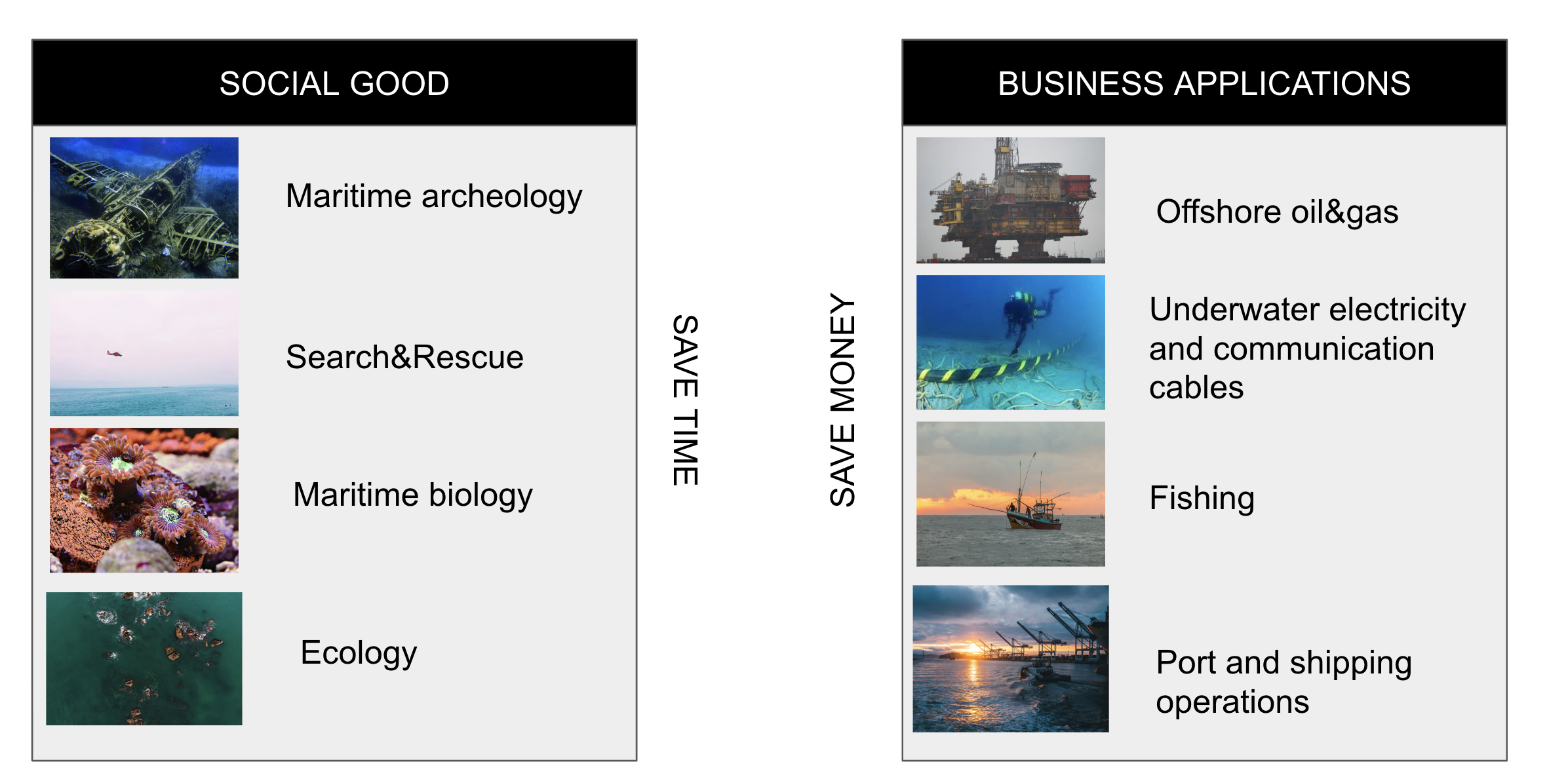
Давайте остановимся на задачах for social good и подробно обсудим первые два из них — морскую археологию и Search&Rescue
Морская археология
Википедия нам говорит, что Морская археология изучает взаимодействие человека с морем, озёрами и реками посредством изучения связанных с ними физических остатков, будь то суда, береговые сооружения, связанные с ними структуры, грузы, останки людей и подводные ландшафты. Связанной с ней дисциплиной является подводная археология, которая изучает прошлое через любые артефакты, находящиеся под водой.
Почему же так важно ей заниматься? Во-первых, благодаря археологии мы лучше узнаем свое наследие, в данном случае морское, находим артефакты, которые проливают свет на события из прошлого или даже серьёзно меняют взгляд на некоторые исторические моменты. Во-вторых, не стоит забывать, что у нас было 2 мировые войны с активным участием флотов, и души многих погибших моряков до сих пор ждут достойного упокоения останков на суше.
По данным ЮНЕСКО (ооочень приблизительным) в мире насчитывается порядка 3 миллионов затонувших судов, причем в одной только Битве за Атлантику в 1939 — 1945 годах погибло 3,500 грузовых и пассажирских судов (3,500, Карл!), 175 боевых кораблей и 783 субмарины. Найденного из всего этого великолепия дай бог процентов 10, а то и меньше.
Как же компьютерное зрение поможет в нахождение всего этого затонувшего великолепия?
Ведь, зачастую, о затонувшем корабле известно лишь очень приблизительное место гибели, некий квадрат в открытом море, да и то не точно.
Чтобы решить задачу, мы разделили её на 3 части.
- Сначала необходимо просканировать широкий квадрат, выделяя на снимках сонара и батиметрии аномалии
- Затем классифицировать найденную аномалию, чтобы понять, что же мы нашли
- И наконец провести визуальный осмотр объекта
В рамках первого направления мы решаем хорошо знакомую всем задачу Object detection на изображениях сонара (детектируем аномалию), а также задачу learning-to-rank — определяем «релевантность» этой аномалии, т.е., что аномалия это действительно корабль, или самолет, или еще что либо рукотворное, а не камень, например.

Следующей задачей этого направления является классификация найденной аномалии — это корабль, или все-таки самолет, или может контейнер. Для этого меняется частота работы сонара, что позволяет получить картинку более высокого разрешения и попробовать классифицировать объект.
Кстати, как работает side-scan сонар?
При боковом сканировании используется гидролокатор, который излучает конические или веерообразные импульсы вниз к морскому дну через широкий угол, перпендикулярный пути датчика. Интенсивность акустических отражений от морского дна этого веерообразного луча регистрируется в серии поперечных срезов. Сшитые вместе вдоль направления движения, эти кусочки формируют изображение морского дна в пределах полосы (ширина покрытия) луча. Частоты звука, используемые в гидролокаторе бокового обзора, обычно находятся в диапазоне от 100 до 500 кГц; более высокие частоты дают лучшее разрешение, но меньший диапазон.

Важной особенностью работы сонара является то, что «сканируемый» им объект имеет акустическую тень, shape которой является иногда более крутой фичей, чем shape самого объекта.
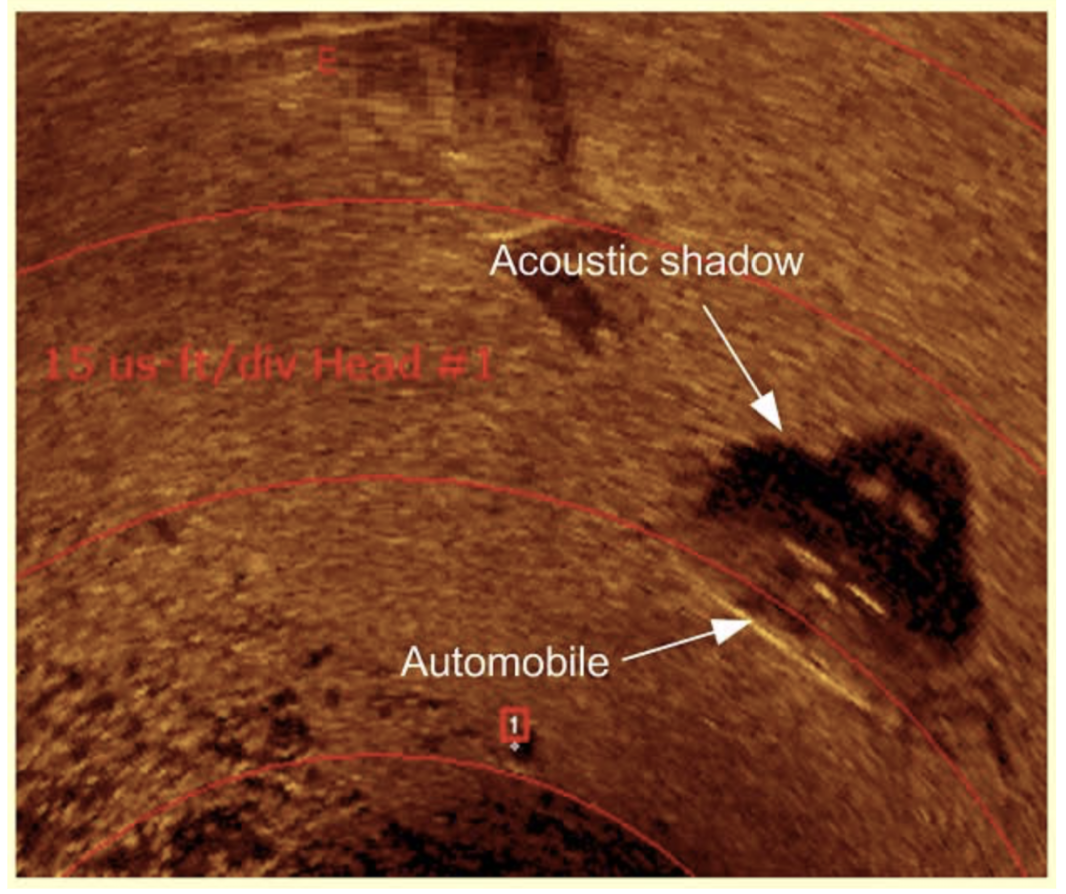
В рамках второго направления мы второй раз проходим сонаром над каждой аномалией с высоким рангом и решаем задачу классификации, пытаясь определить, что же за тип корабля или самолета нам попался.

Весь цимес в том, что сейчас подобный поиск производится вручную. Оператор сидит (иногда по 12 часов!) и смотрит на экран сонара, пытаясь определить, есть там что-то внизу или нет. Решение, над которым мы работаем, позволит максимально автоматизировать весь процесс.
Где деньги данные, Лебовски?
Главной проблемой, с которой мы столкнулись во время исследования, является тот незатейливый факт, что изображений с сонара в открытом доступе крайне мало. На собранном нами датасете из порядка 220 картинок хороший детектор и, тем более, классификатор обучить практически не реально. Тем не менее, нам удалось найти выход: мы просто генерируем свой датасет ;)
В двух словах, подход такой:
1) При затоплении, судно чаще всего ложится на дно килем вниз, реже бортом, совсем редко палубой.
2) Мы берем изображения еще живого судна (аэрофотосъемка, спутник, такие датасеты есть, тот же сет из соревнования Airbus на Kaggle, например) и «топим» его.
Для «затопления» мы используем CycleGAN — подвид Generative Adversarial Network, позволяющий осуществить style transfer одного изображения в другое. После обучения на порядка 400 эпох и ~220 парах A и B (живых и затонувших) уже возможно получить адекватную картинку.
Берем реальное изображение с сонара:
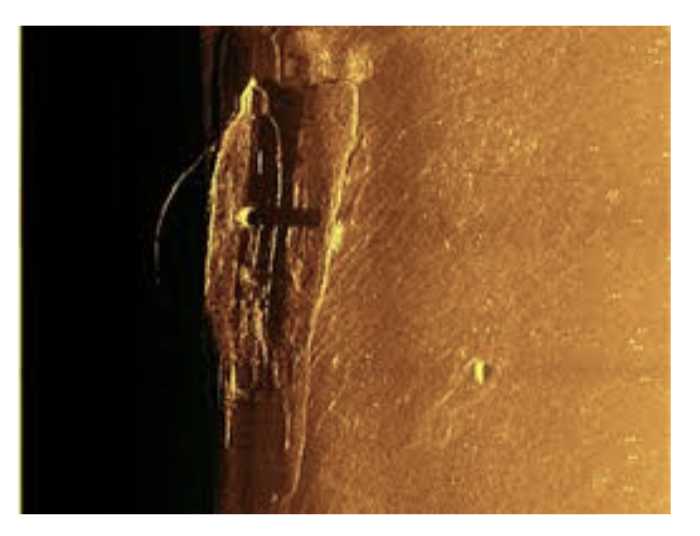
Изображение со спутника:

И получаем в конечном итоге вот такую картину:

И аккуратно выбираем валидационный сет, чтобы модель детектора или классификатора не переобучилась на искусственных картинках.
Наконец, в третьем направлении — визуальном осмотре и анализе — мы в числе прочего решаем задачи цветокоррекции изображений и видео, dehazing и super-resolution с помощью все тех же ГАНов, но на этот раз архитектур U-GAN, W-GAN и SRGAN.
Характер подводной съемки таков, что там крайне мало источников естественного света (если точнее, их нет вообще), а искусственный свет прожекторов глубоководных аппаратов довольно маломощный.
В итоге, снятая под водой картинка выглядит обычно как-то так:

Наш же пайплайн позволяет на данный момент получать такие изображения:

Это в равной степени относится и к видео (видео снято на телеуправляемый подводный аппарат Гном про):
Search&Rescue
Согласно статистике ЕС, с 2011 по 2017 в различных инцидентах участвовало более 20.000 судов, при этом пострадало почти 7.000 человек, из них 683 погибли.
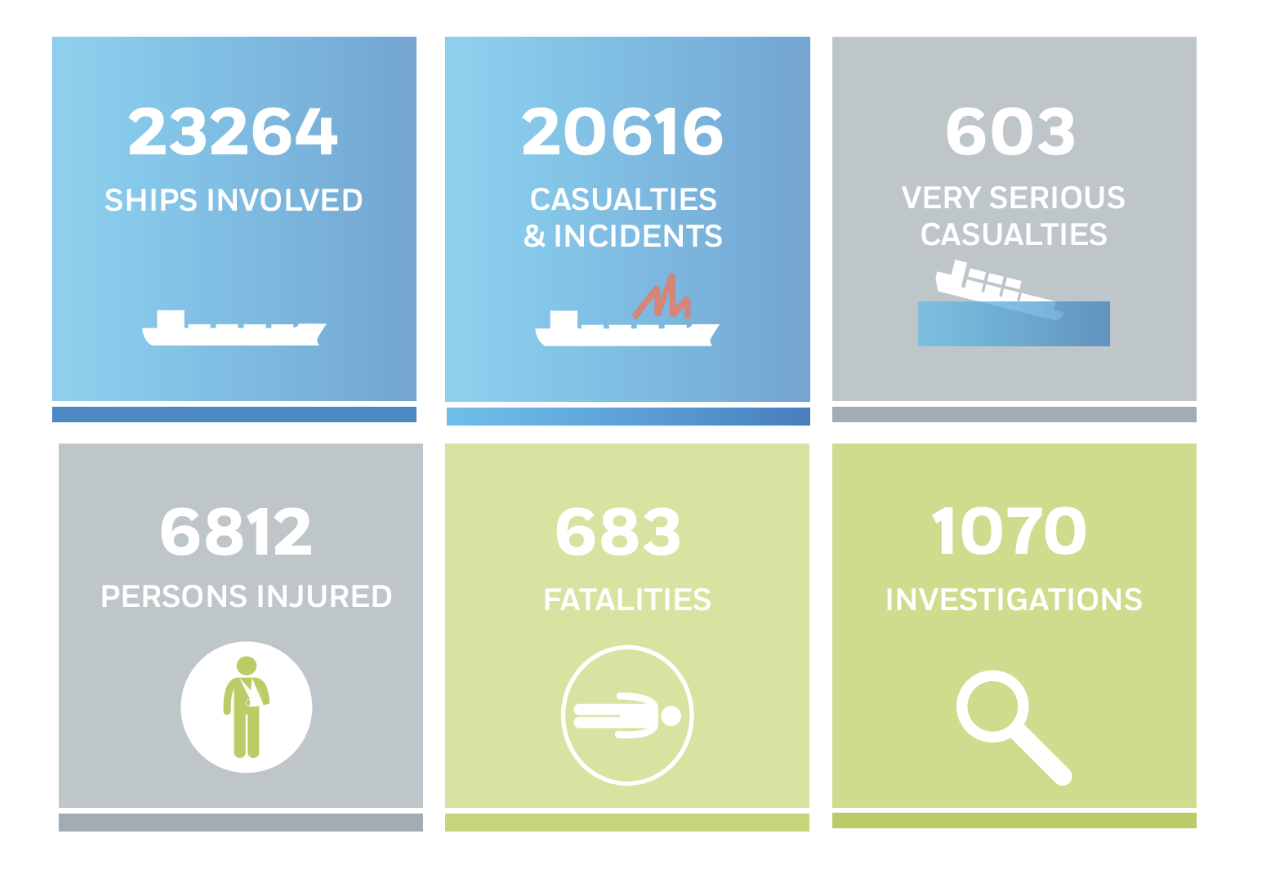
Инциденты были самые разные, по разным причинам: от потери управления судном до столкновений в темноте или в иных условиях плохой видимости. Суда теряются в открытом море при поломке транспондеров, выходят из строя силовые установки и корабль может быть обесточен, наконец, кого-то из команды может смыть набежавшей волной.
Мы поставили себе цель как-то повлиять на столь печальную статистику и для этого решаем следующие задачи:
1) Детекция и Классификация судна по изображению с Synthetic Aperture Radar
2) Детекция и Классификация судна по изображению со спутника \ самолета
3) Поисков утонувших людей и затонувшей техники и грузов по изображениям с сонара
Кроме того, мы также решаем задачу сегментации судна на изображении с сонара, что позволит определять точнее точки для последующего погружения.
Остановимся чуть подробнее на каждой задаче.
С детекцией на спутнике все более-менее понятно, подобную задачу решали уже на упомянутом выше конкурсе Airbus на Kaggle. Там же на kaggle можно скачать и хороший датасет.
С SAR изображениями тоже более-менее понятно, существует хороший датасет OpenSARShip, который находится в открытом доступе, благо с запуском Евросоюзом спутника Sentinel-1 разнородных данных в открытом доступе стало больше…
Быстрый бейзлайн даже на малом количестве эпох показывает приемлемый скор на архитектуре ResNet.
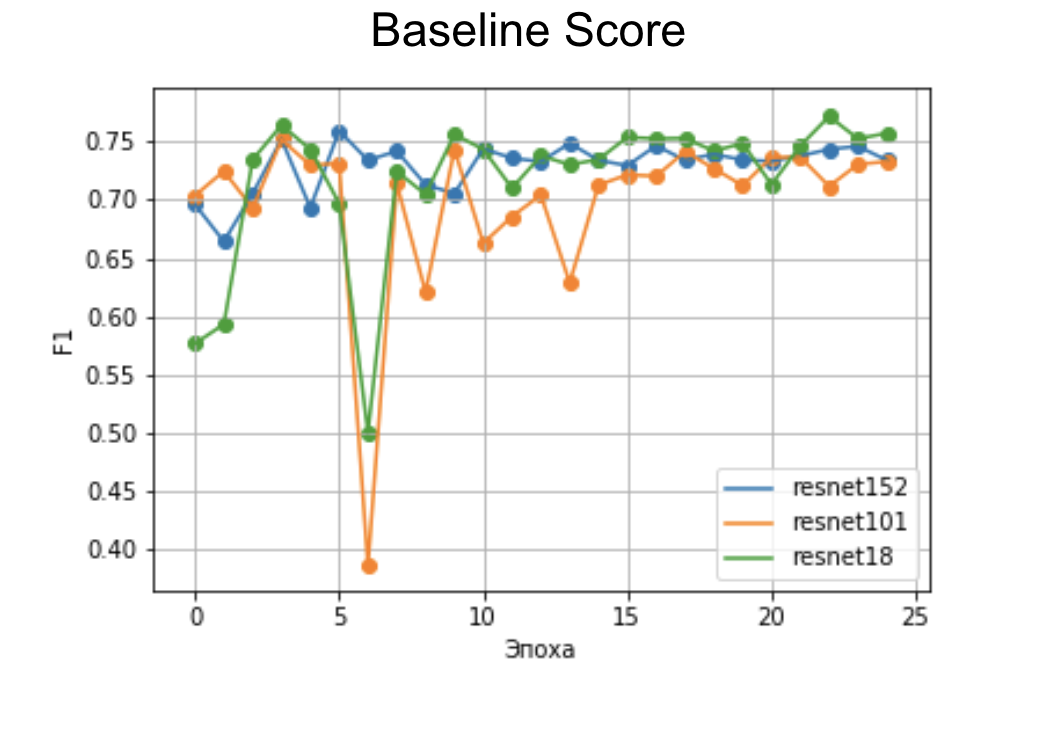
Дальнейшая классификация вызывает сложности разве только тем, что очень много человеко-часов уходит на разметку.
Несколько интереснее дело обстоит с инфракрасными изображениями. Пожалуй, существует только один неплохой датасет с инфракрасными изображениями судов — VAIS, но он относительно не большой.
Но, как вы могли бы догадаться, здесь тоже может зайти гипотеза по аугментации сета с помощью style transfer. Тем не менее, даже на изначальном датасете нам удалось получить неплохой (=лучше рандома) бейзлайн классификатора на Сиамских сетях.

Гораздо сложнее все с детекцией утонувших людей.
Во-первых, датасетов нет.
Во-вторых, их нет.
В-третьих, их нет совсем.
И тем не менее, задача решаема.
Утонувший человек на экране сонара виден как-то так:

Высота над дном может быть разной, в зависимости от срока, прошедшего с момента гибели.
Как же нам получить датасет с такими картинками? Можно, конечно, утопить несколько манекенов и сонаром снять изображения, но есть способ подешевле.
Мы можем набрать 3D моделей людей на бесплатных сайтах-банках изображений, при чем совсем не обязательно с текстурами или высокой детализацией. Потом либо нагенерить сцен с неровным дном, либо поместить 3D модель в один из опенсорсных симуляторов вроде UWSim или UUVSimulator, где вода, и все, что под ее поверхностью, просимулировано по всем канонам.

После чего можно нагенерить скриншотов этих сцен, на которые потом… правильно, применить style transfer. Больше ГАНов богу ГАНов!
В итоге пайплайн будет такой:
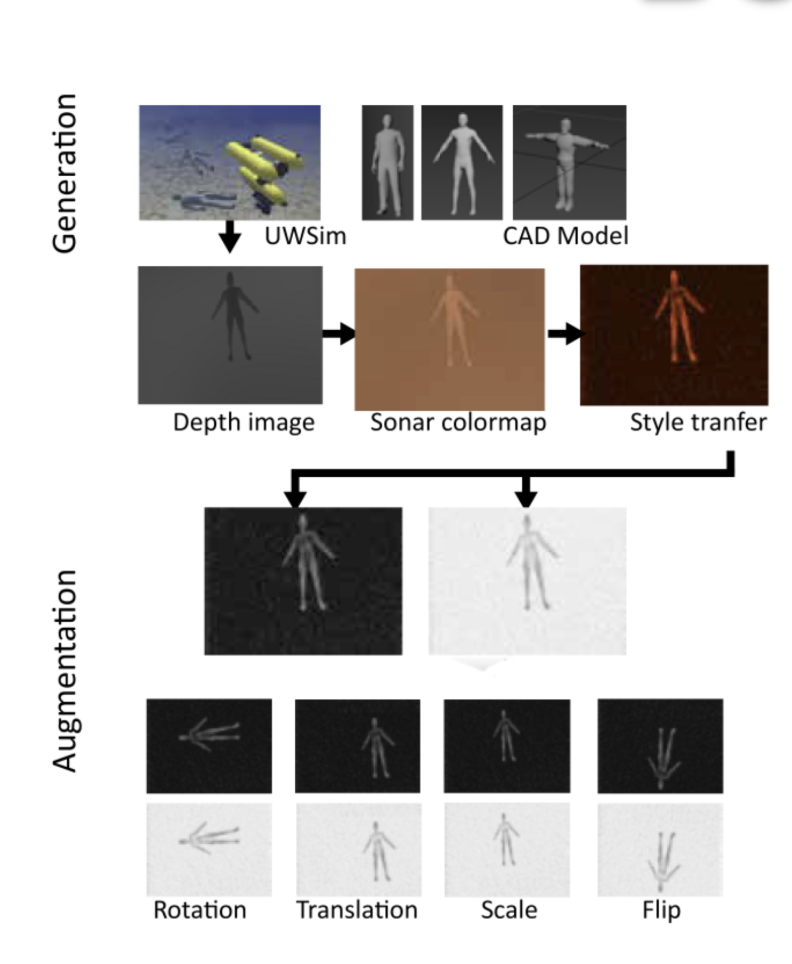
Этот подход позволяет получить годный датасет без необходимости лишних затрат.
Дальнейшие планы
А дальнейшие планы у нас большие:) Мы прорабатываем все указанные в начале статьи направления с использованием тех приемов и хаков, которым научились, работая для морской археологии и Search&Rescue.
Мы ведем переговоры с Центром Морских исследований МГУ, Национальным управлением океанических и атмосферных исследований США, эстонским агенством по мониторингу климатических и экологических проблем Climate4Media о партнерском сотрудничестве, а так же с производителями сонаров и государственным службами, отвечающими за поиск и спасение на воде.
И, конечно, мы ищем еще помощников и партнеров.
В первую очередь, мы будем рады морским биологам, экологам, археологам и океанологам — мы вас научим в Deep Learning, a вы нас всему остальному:)
Если у вас есть данные с сонаров, в .xtf или .dat форматах, или любые другие данные по нашей тематике, то мы также будем рады сотрудничеству.
Во-вторых, мы проводим много исследований (ГАНы, Карл! У нас еще 3D ГАНы на подходе, для генерации 3Д облаков точек), для которых необходимы значительные вычислительные мощности, в первую очередь GPU.
В-третьих, мы ищем потенциальных клиентов, чтобы опробовать наши решения в боевых условиях.
Ну и наконец мы ищем инвесторов, кому была бы интересна наша работа и перспективы использования ее результатов не только для social good, но и для бизнеса.
Самый главный наш план — уйти от режима «делаем по вечерам и выходным» к режиму «это наша работа и она нам нравится»:)
В силу обзорного характера статьи я не останавливался подробно на использованных технологиях. Если у вас есть вопросы — welcome в комменты, на страницу проекта, в личку, на почту (pavel.golubev@maritimeai.net), в слак ОДС, наконец! Еще можно посмотреть наш короткий доклад на секции ML4SG на прошедшем в мае ДатаФесте — вот тут. Если будет интересно рассмотреть какие-то технологии совсем подробно — пишите, запилим отдельный пост.
На этом пожалуй все, делайте добрые дела:)
